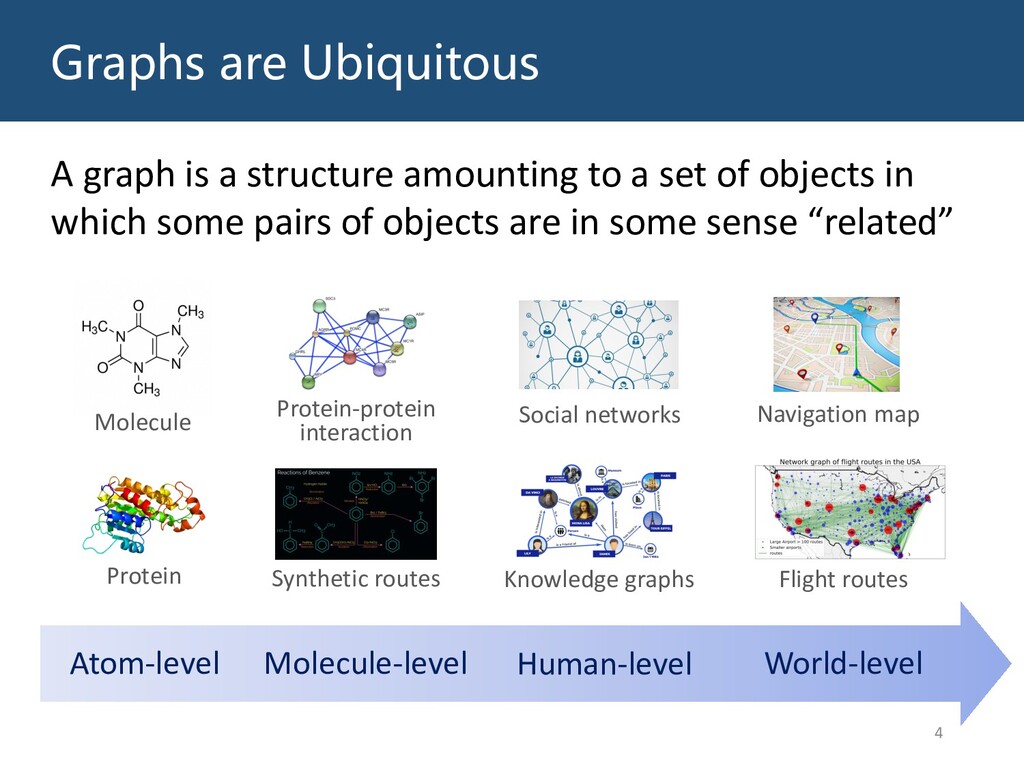
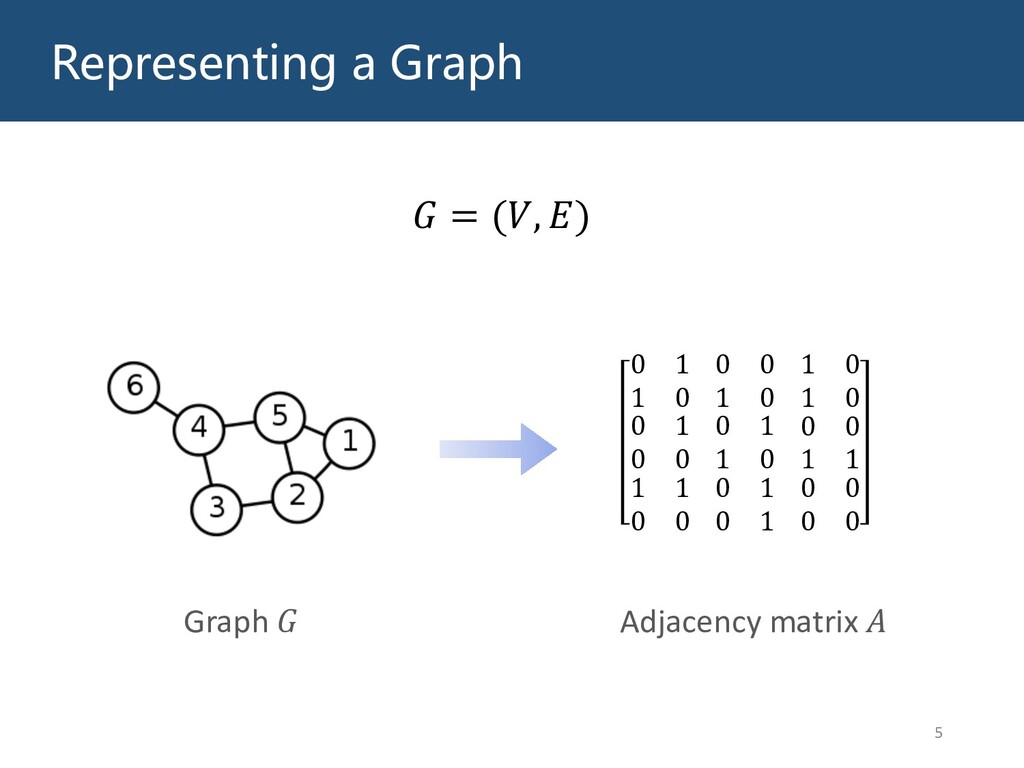
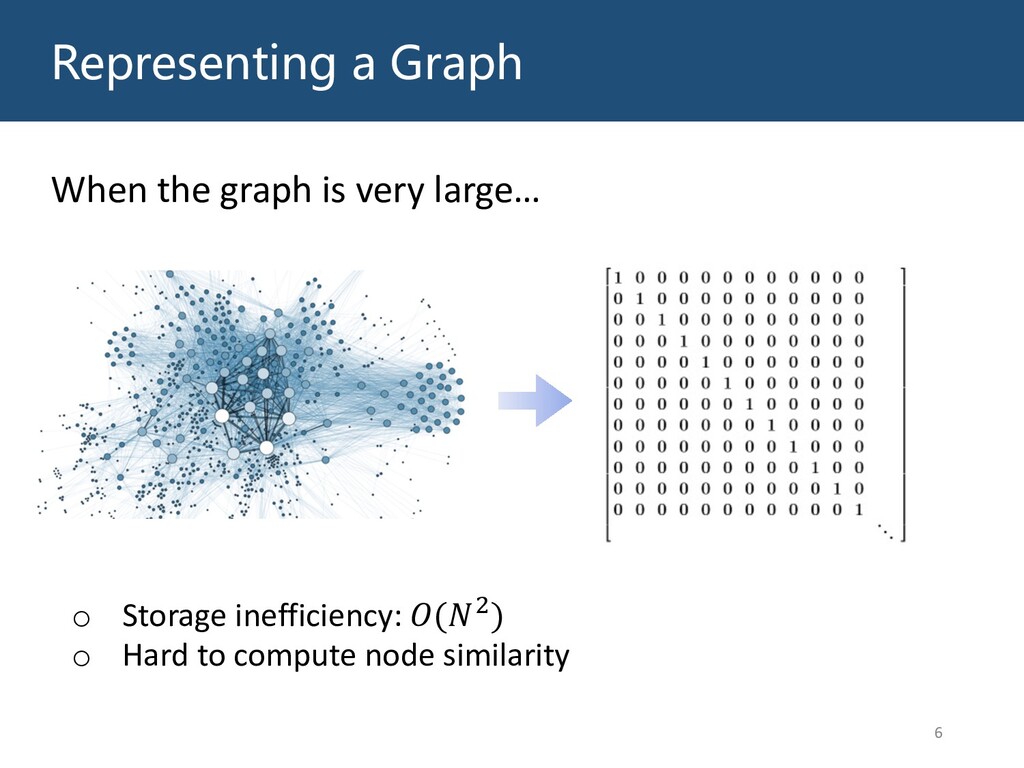
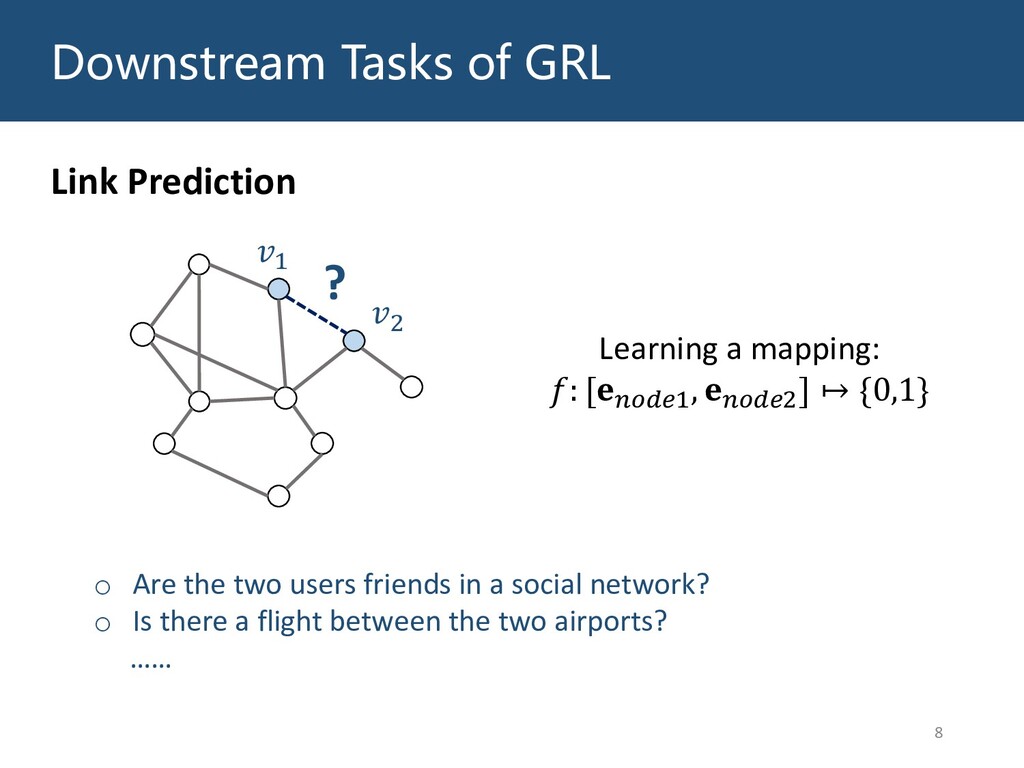
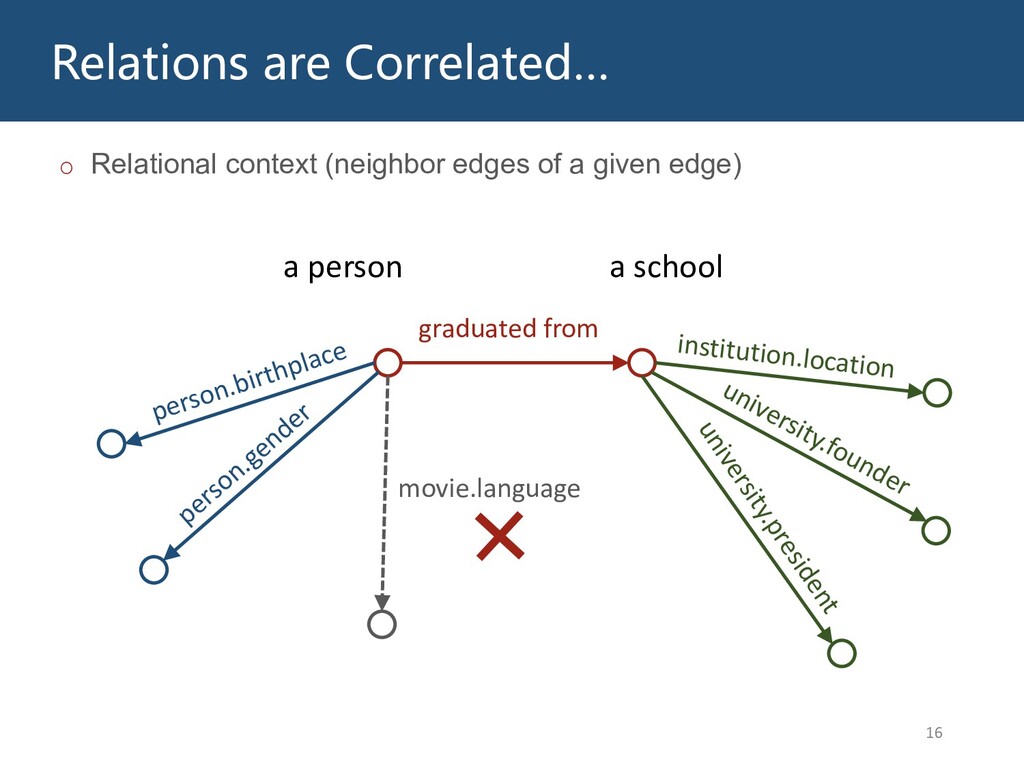
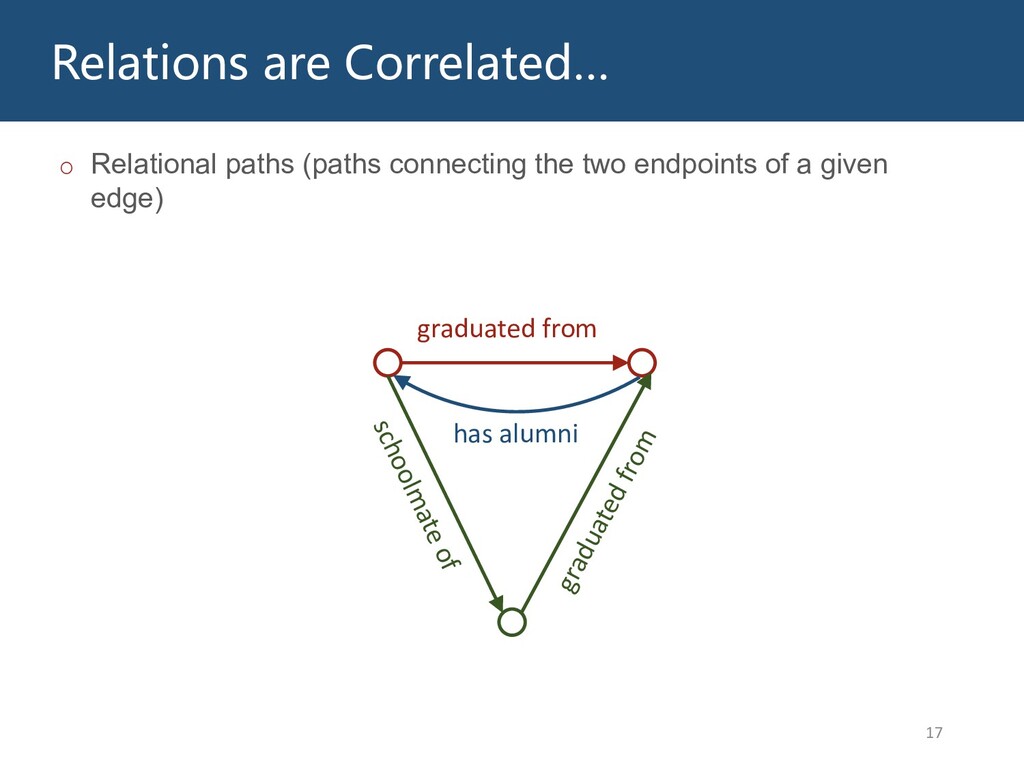
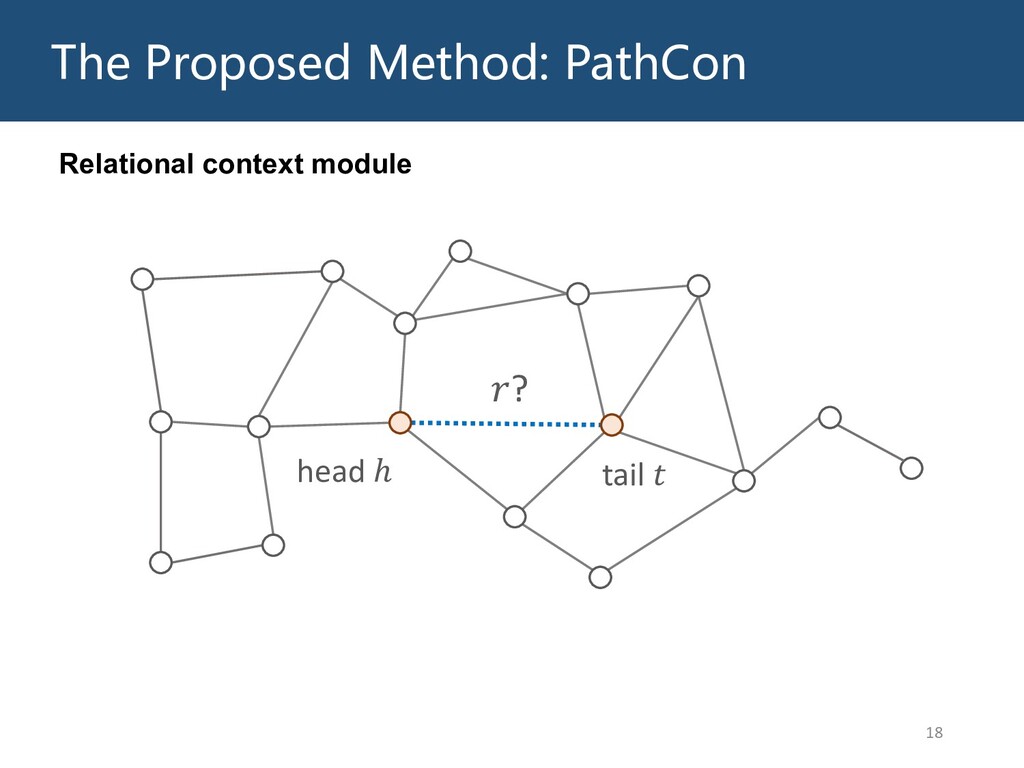
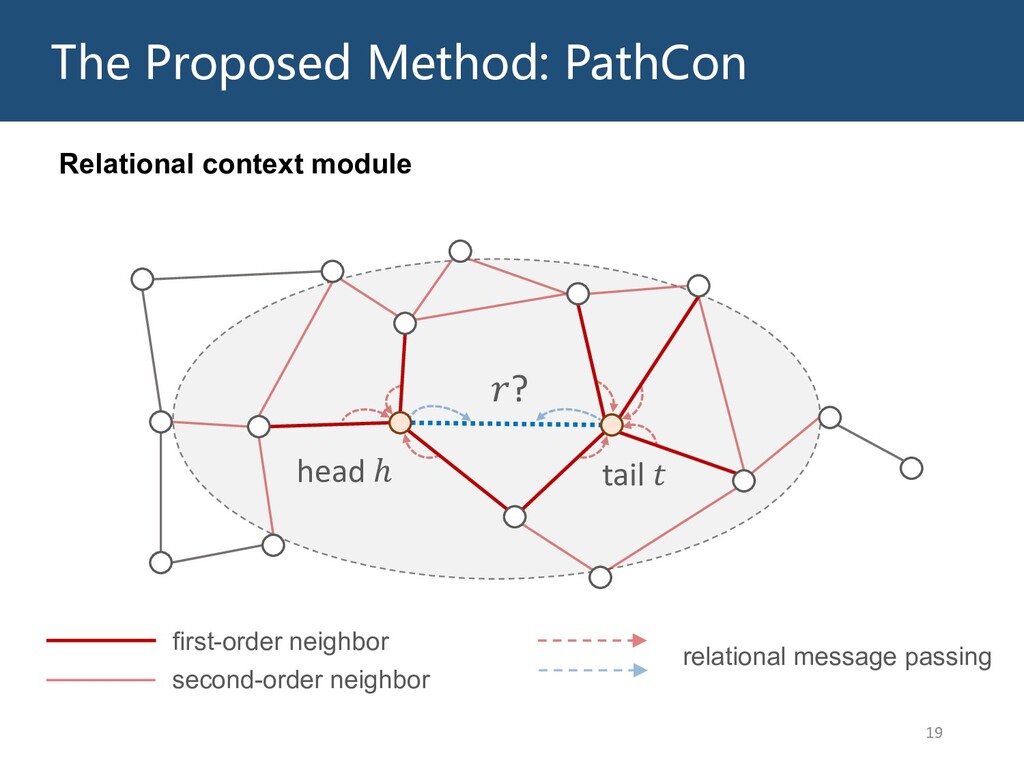
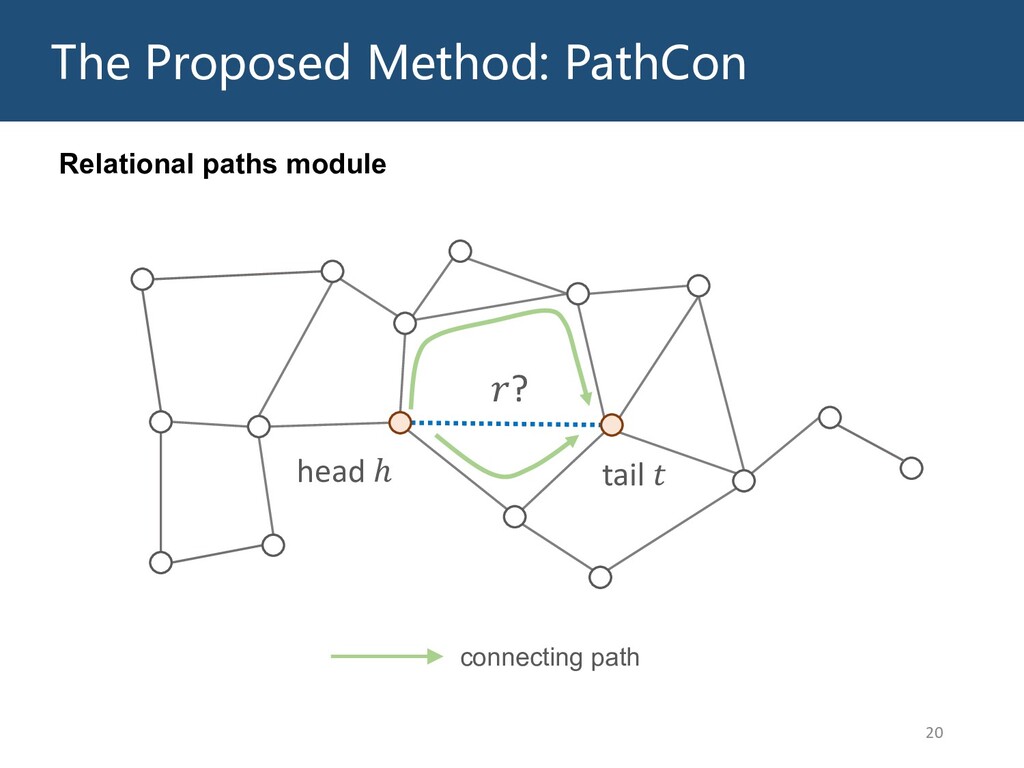
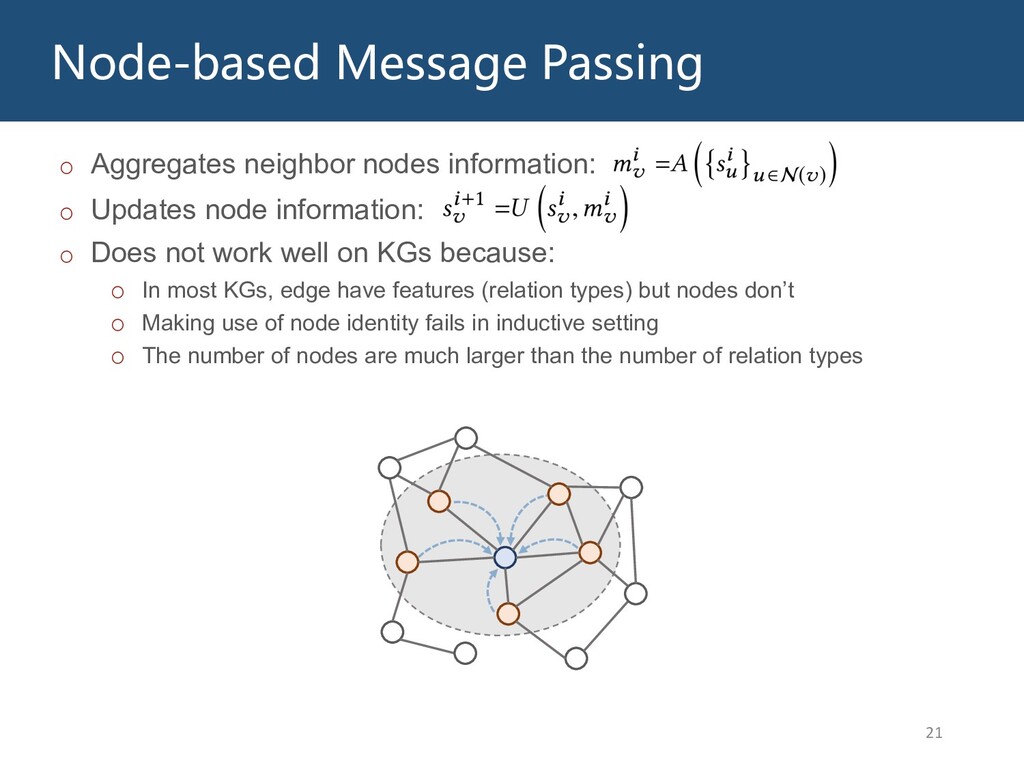
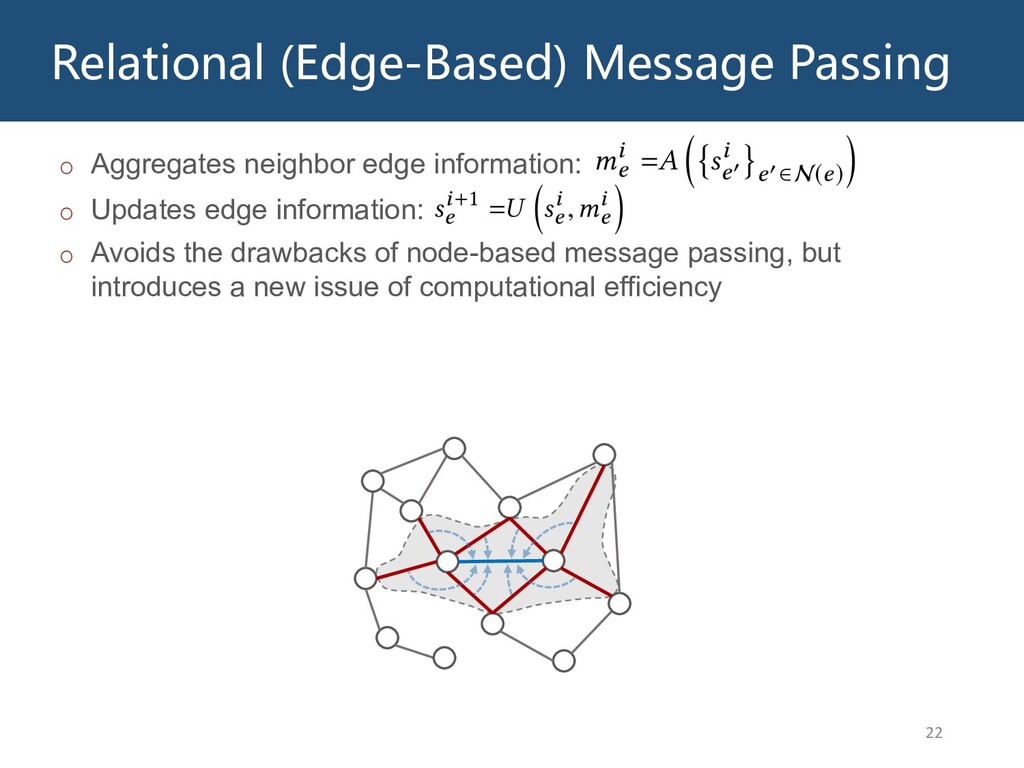
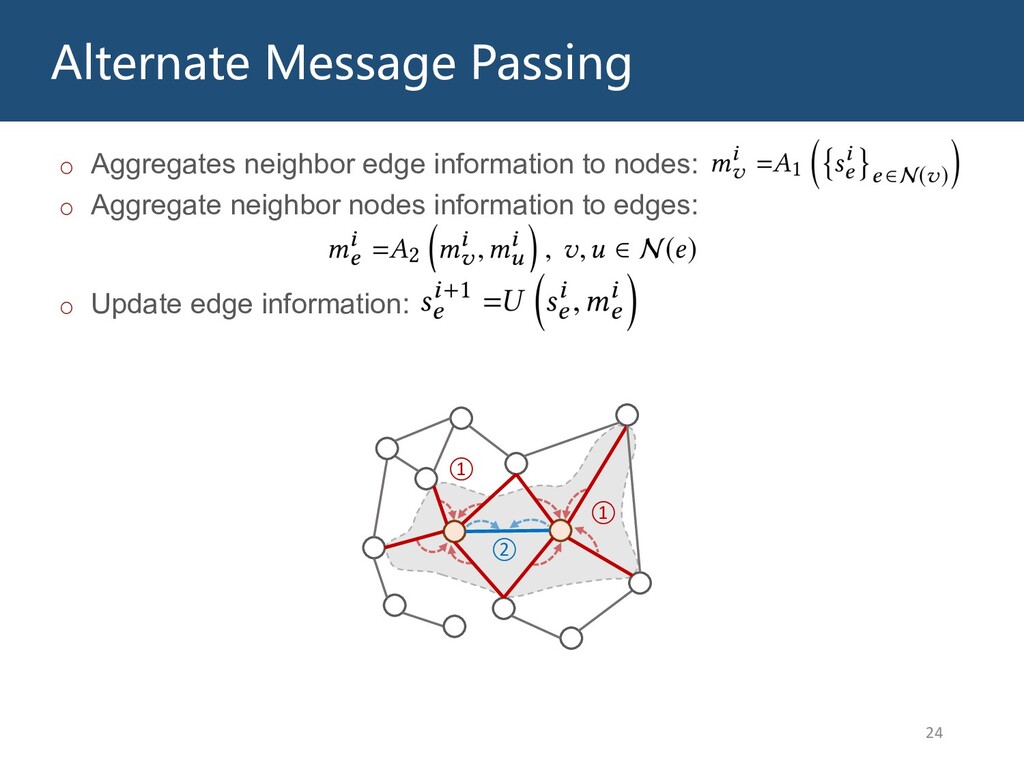
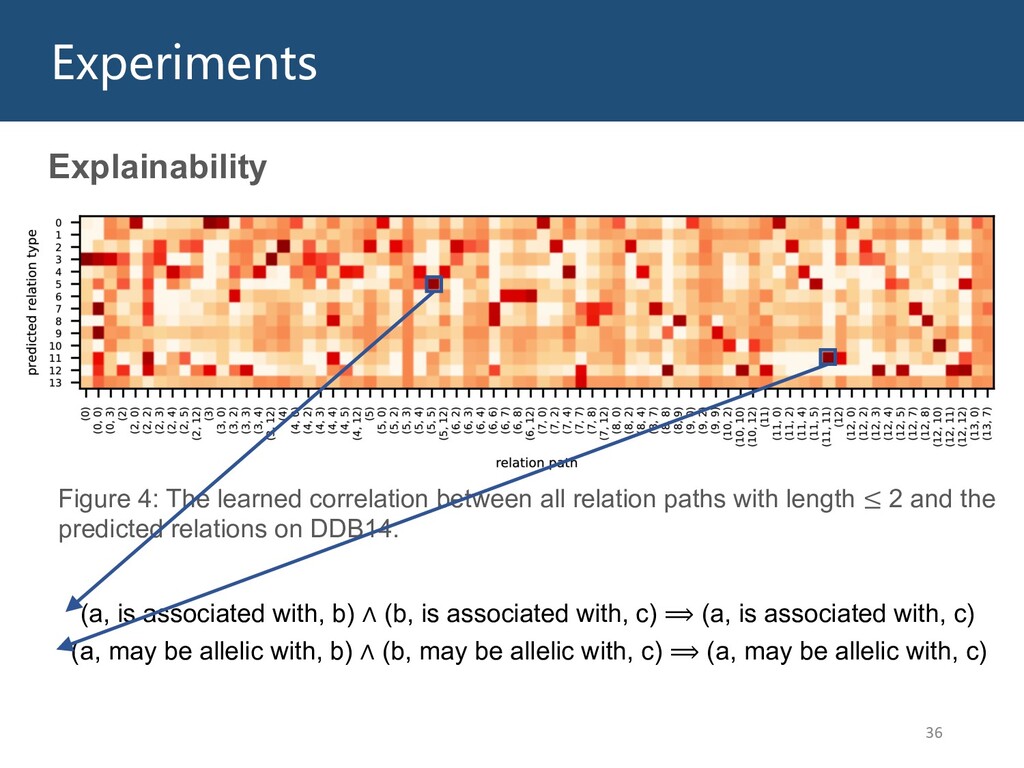
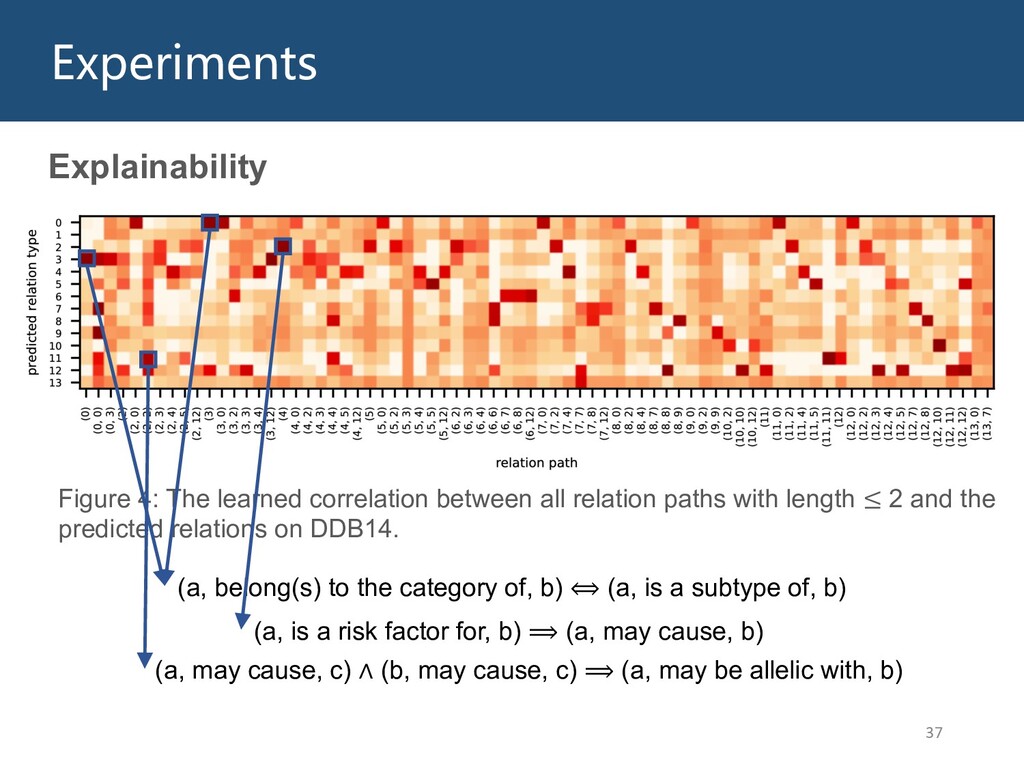
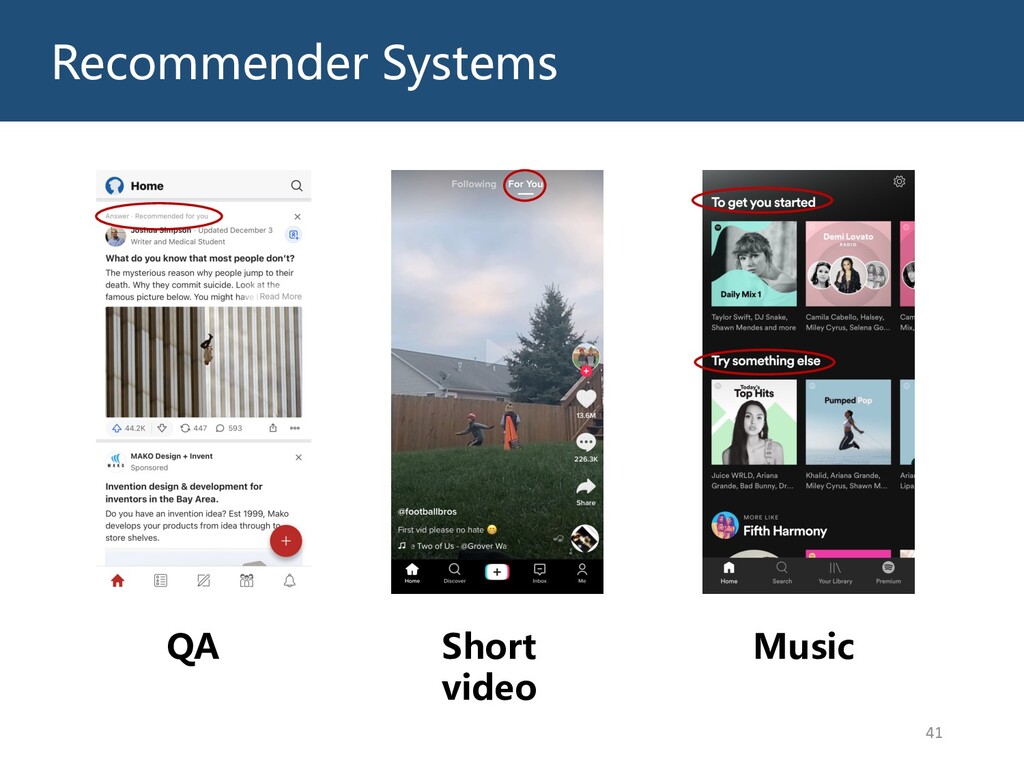
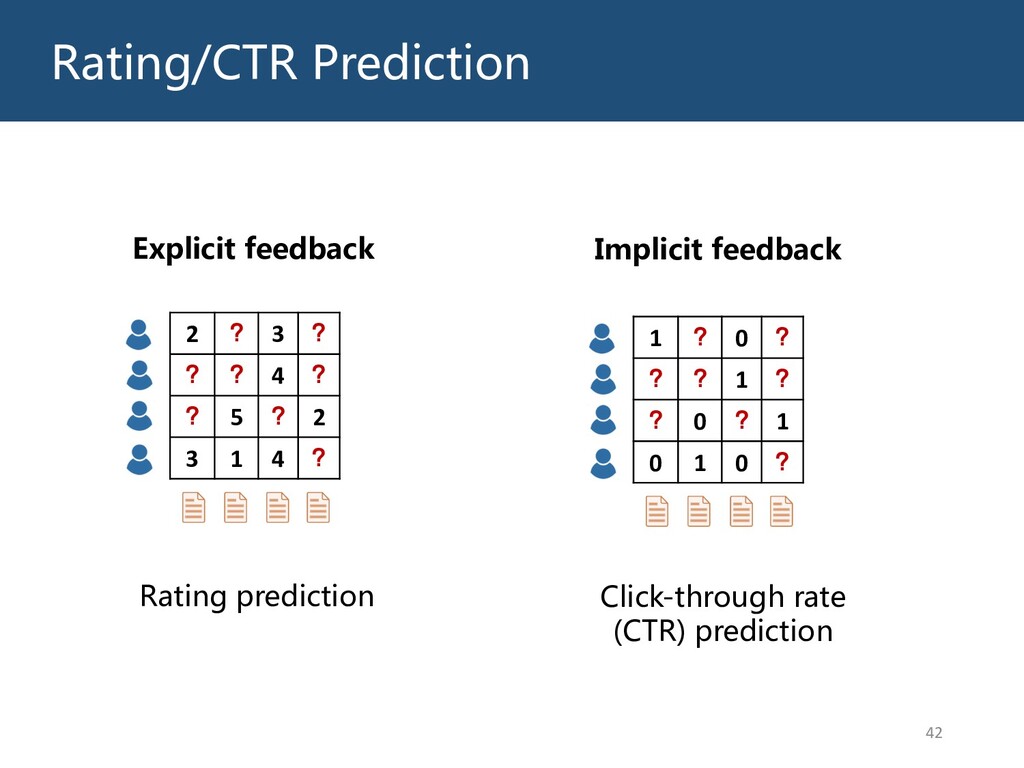
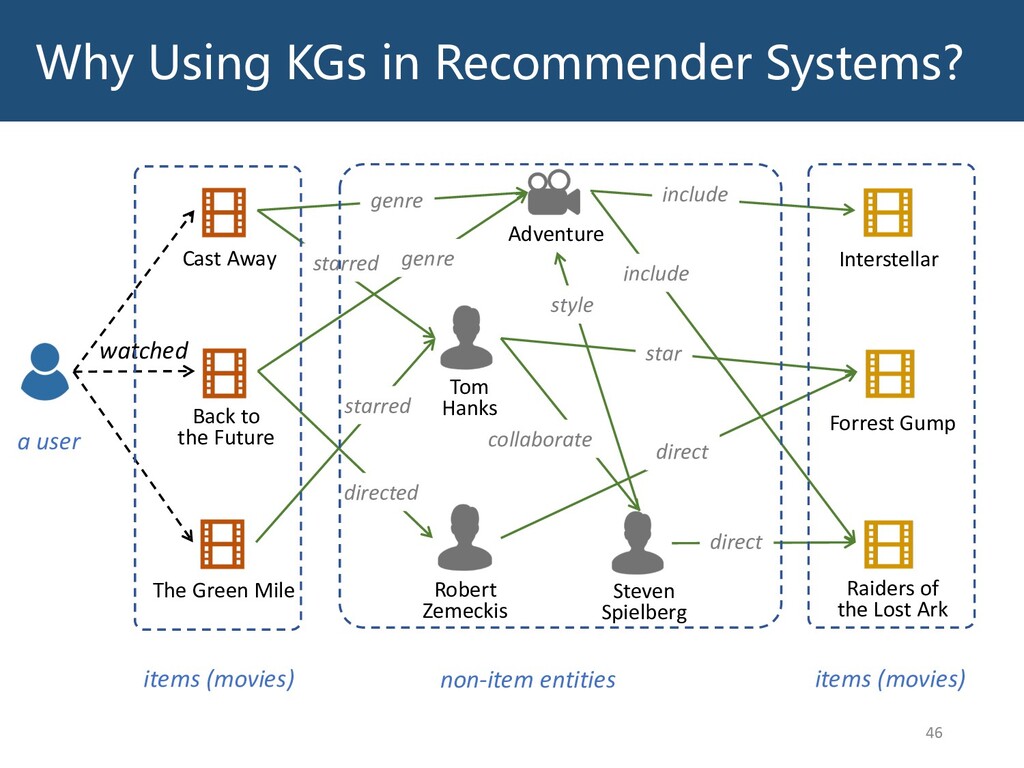
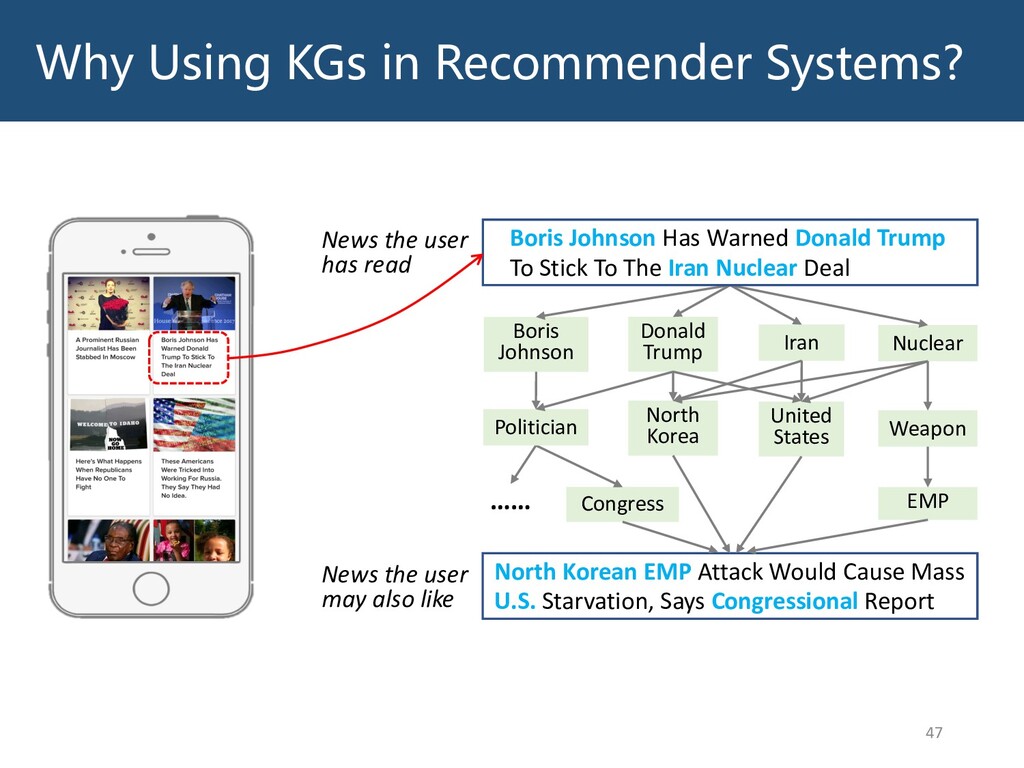
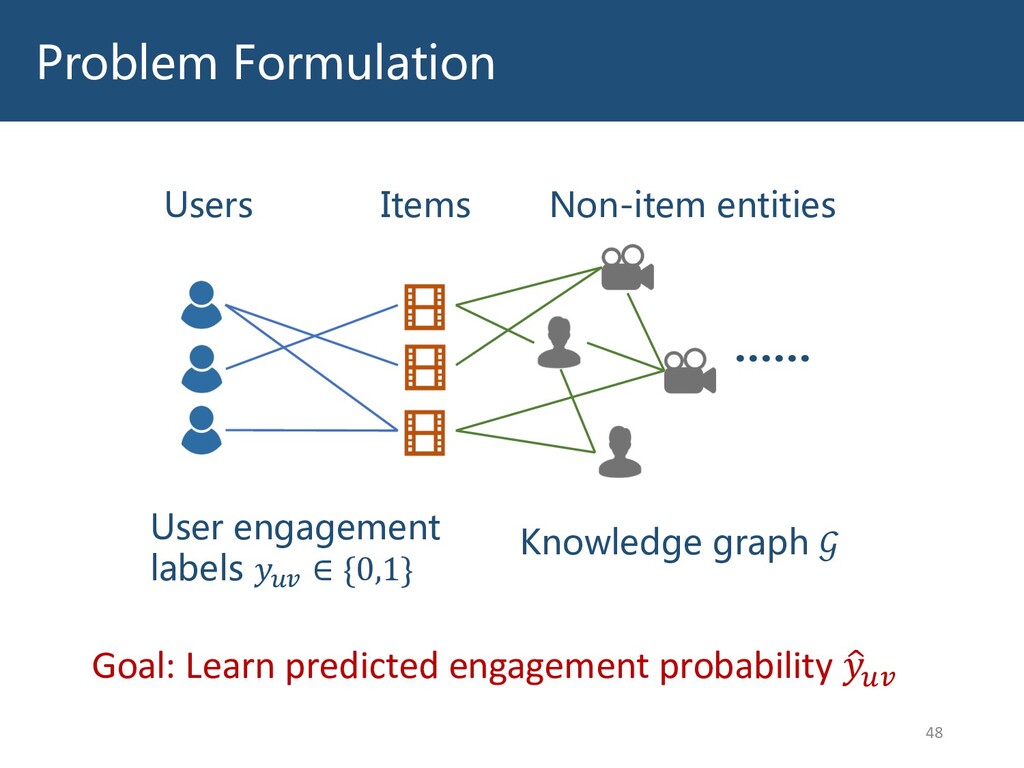
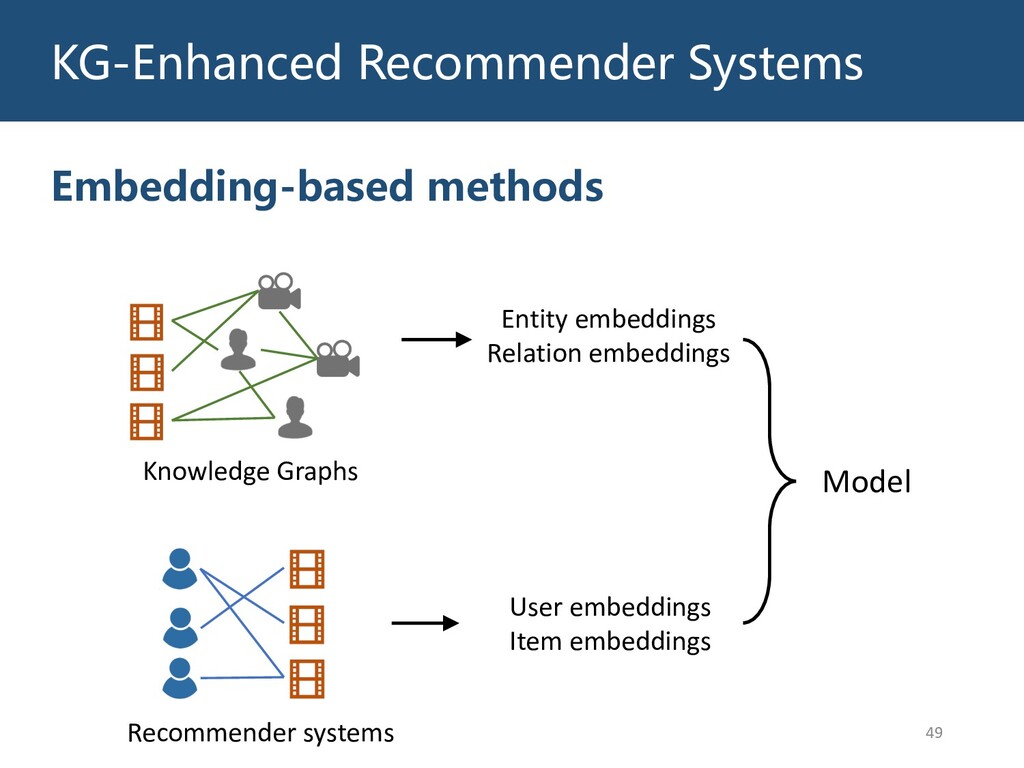
Graphs are ubiquitous in the real world. To facilitate machine learning algorithms making use of graph-structured data, researchers proposed graph representation learning (GRL) methods, which learns a real low-dimensional vector for each node in a graph. In this talk, I will first briefly introduce graph representation learning, graph neural networks (GNNs, a special type of GRL methods), and knowledge graphs (KGs, a special type of graphs). Then my talk will consist of two parts: (1) Knowledge graph completion. I will introduce PathCon, a GNN-based method that combines relational context and relational paths information to predict the relation type of an edge in a KG. (2) Knowledge-graph-aware recommendation. Knowledge graphs can provide additional item-item relationship and thus alleviate the cold start problem in recommender systems. I will introduce two KG-aware recommendation algorithms, including an embedding-based method DKN and two structure-based methods KGCN and KGNN-LS.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
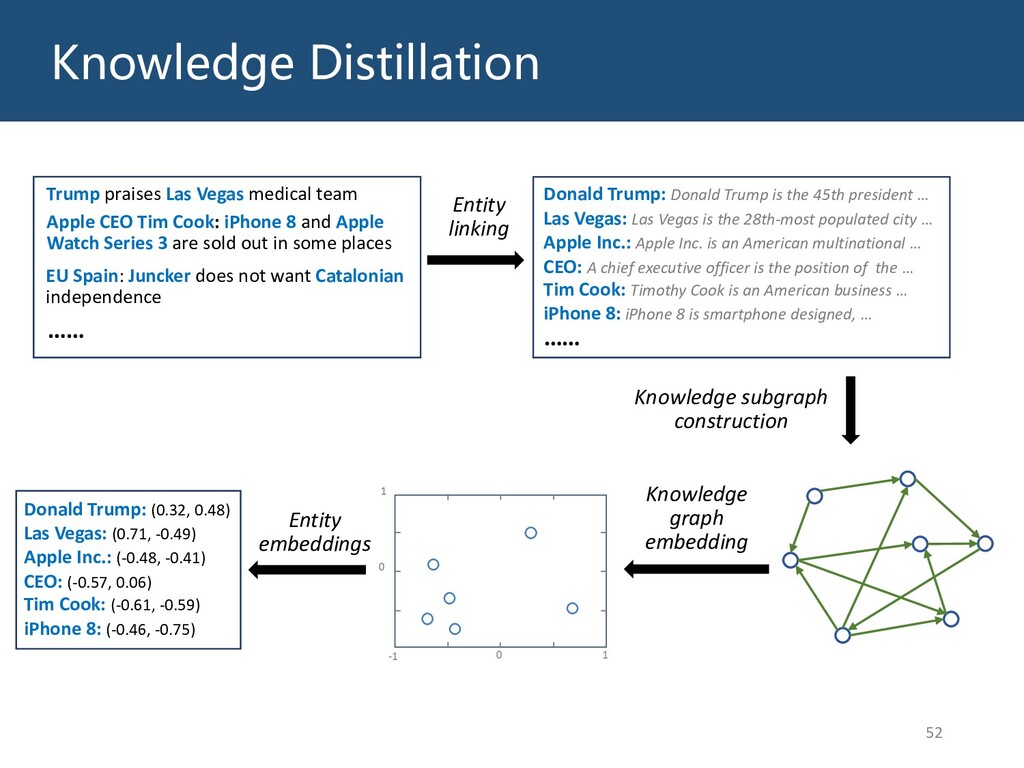
![54 𝑤&:( = [Donald Trump praises Las Vegas medical team]](https://files.speakerdeck.com/presentations/701ed3acf1cf49399289c25261c421f6/slide_53.jpg){kind=link}
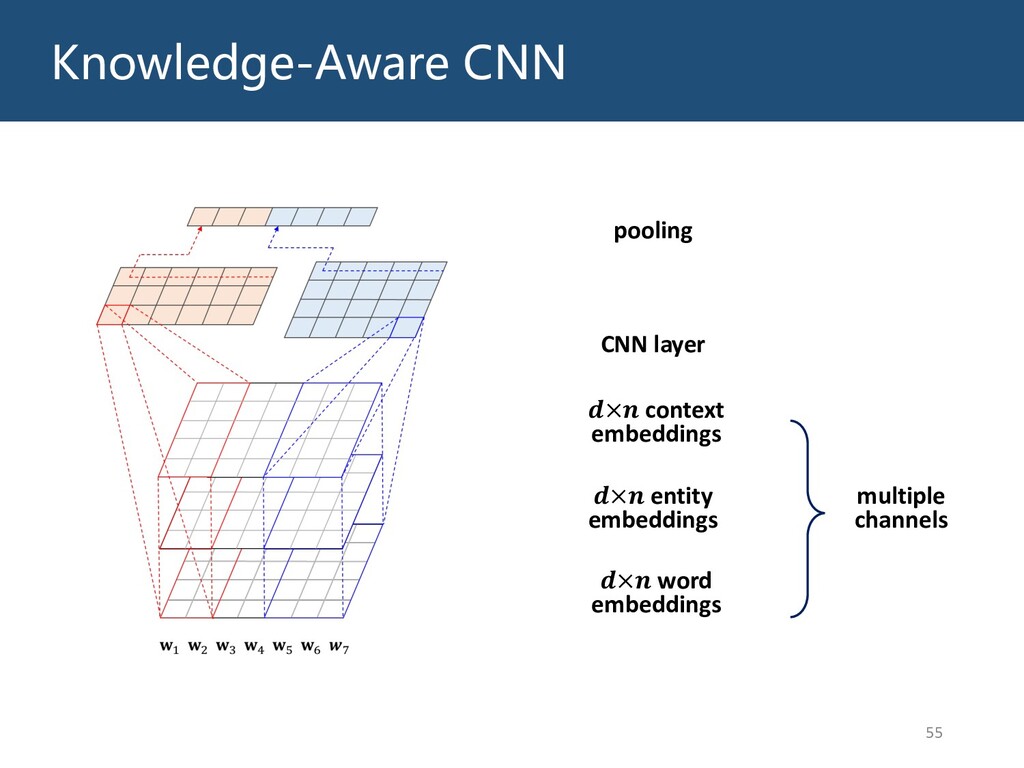{kind=link}
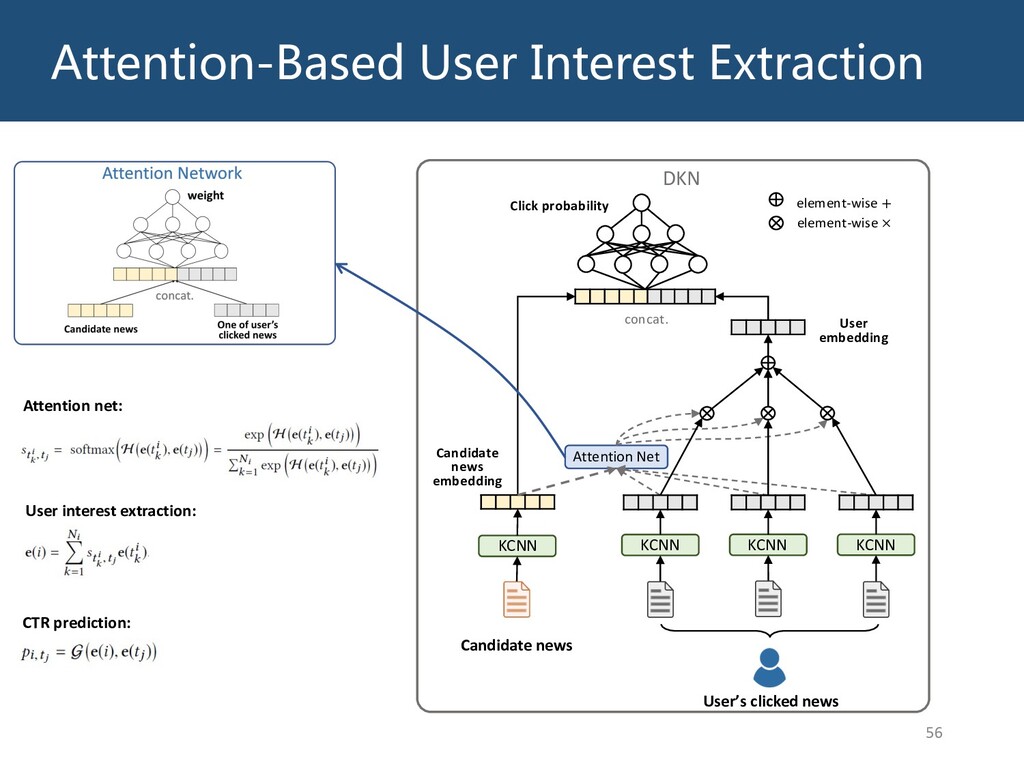{kind=link}
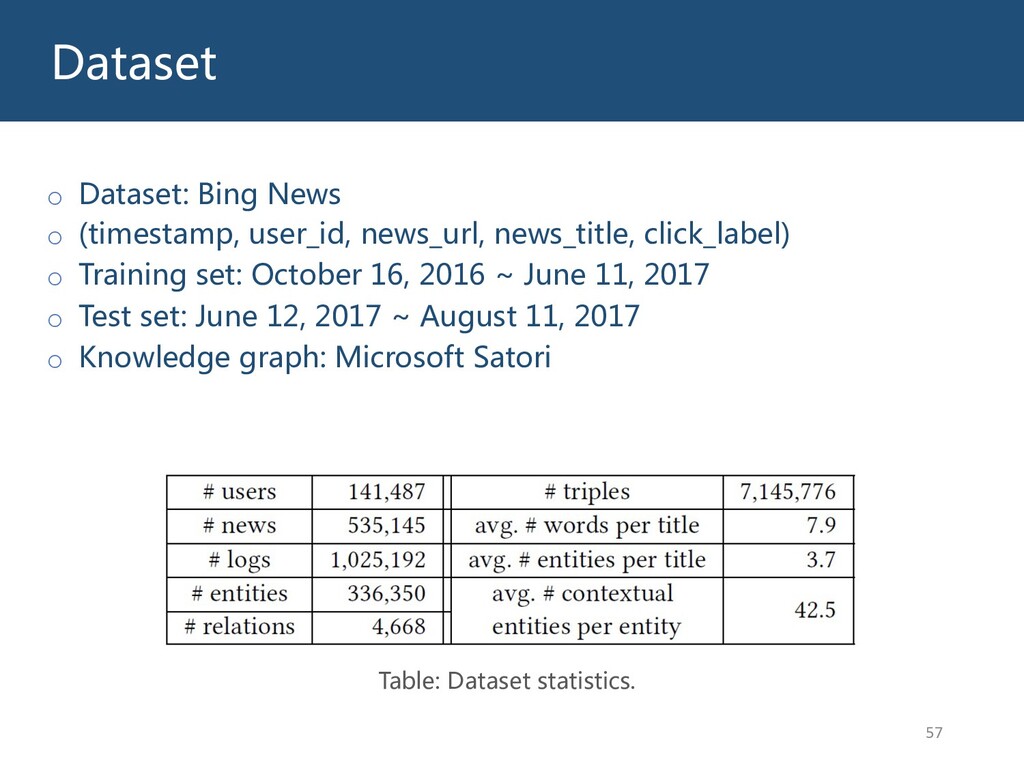{kind=link}
{kind=link}
{kind=link}
{kind=link}
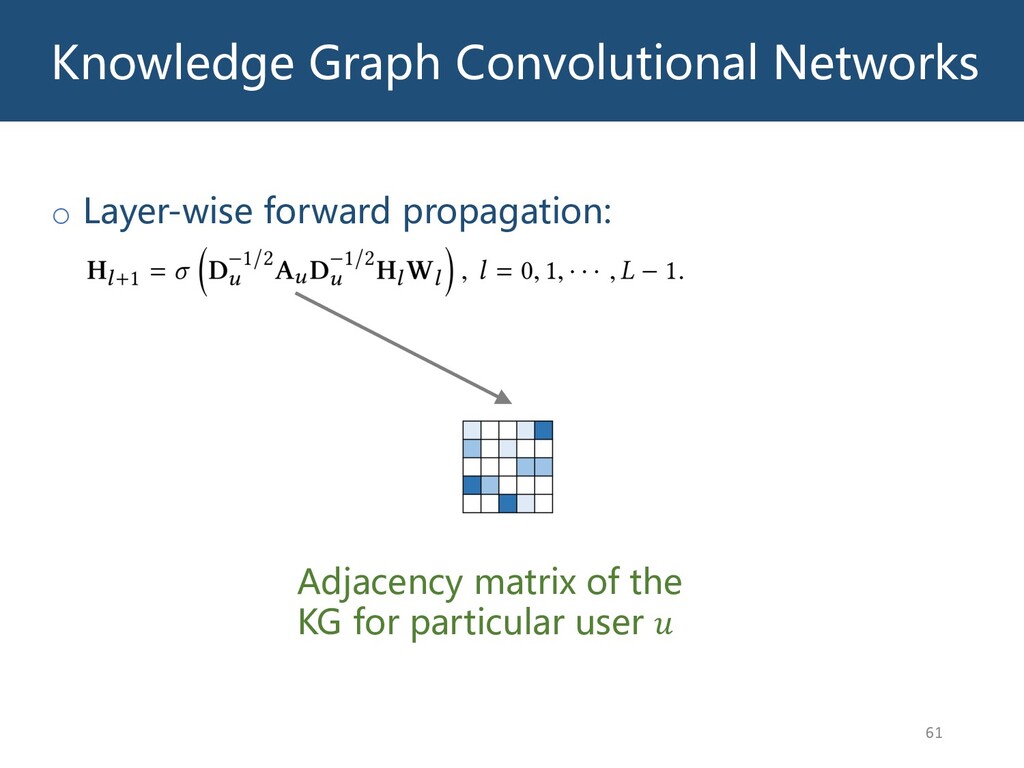{kind=link}
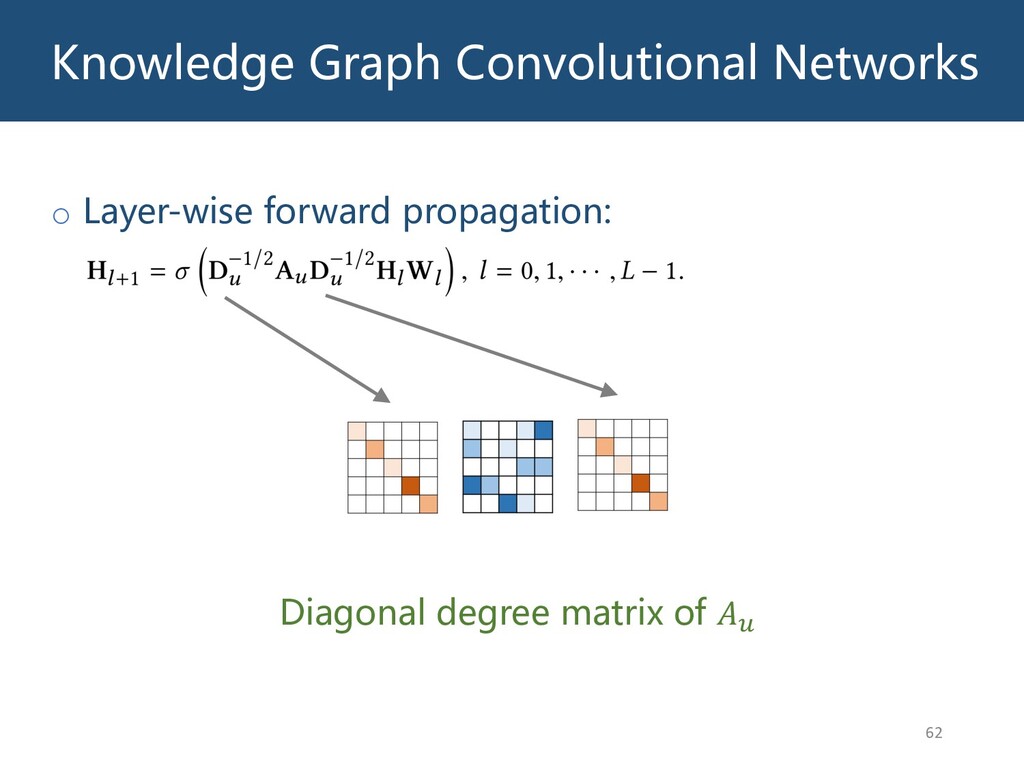{kind=link}
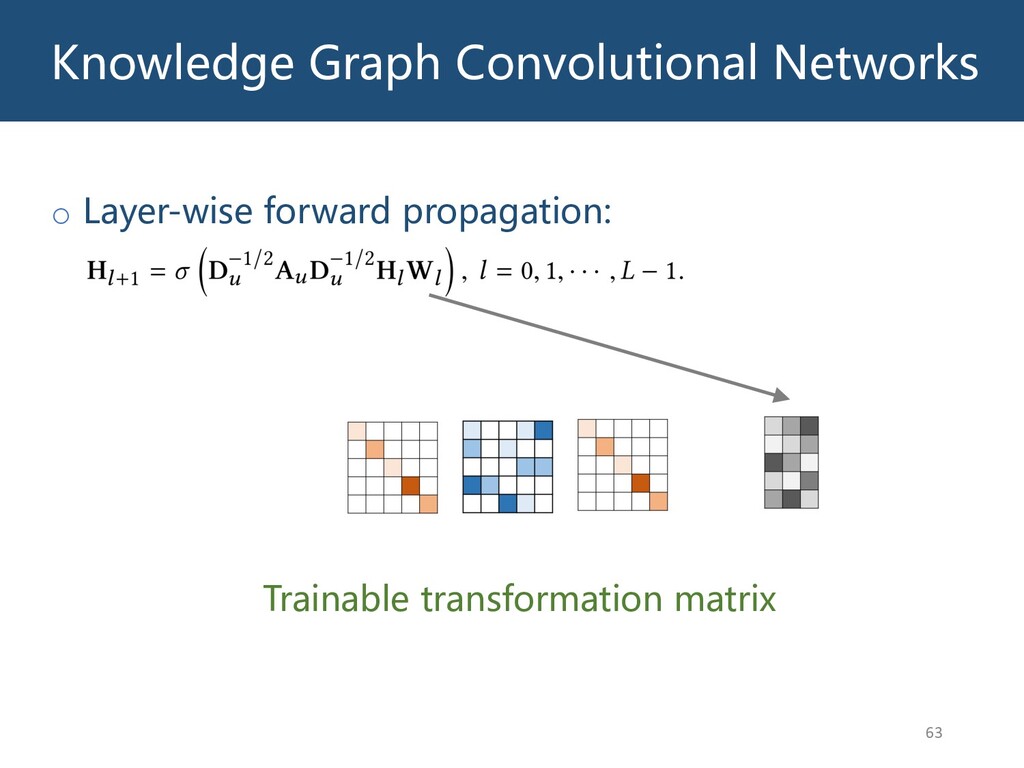{kind=link}
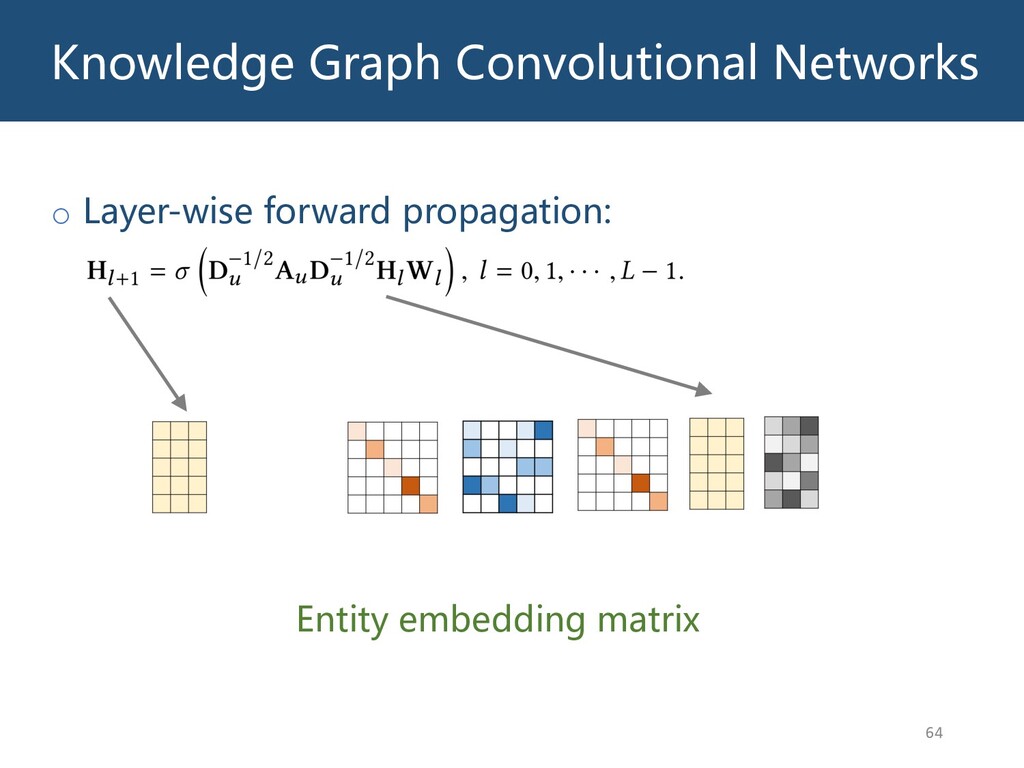{kind=link}
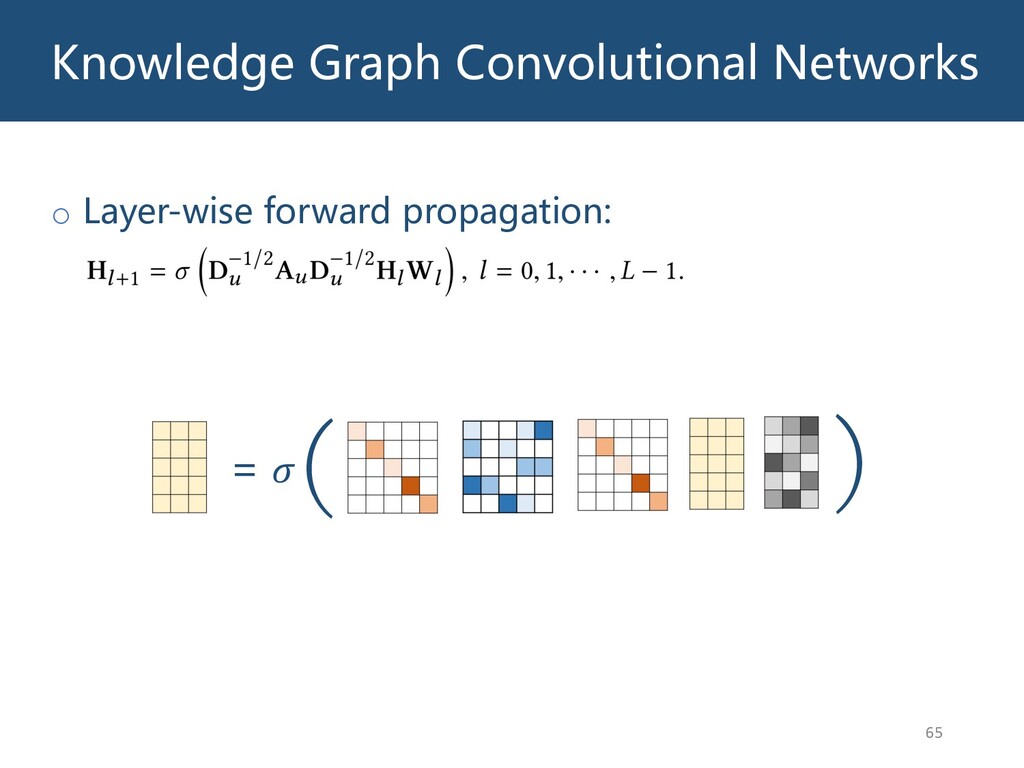{kind=link}
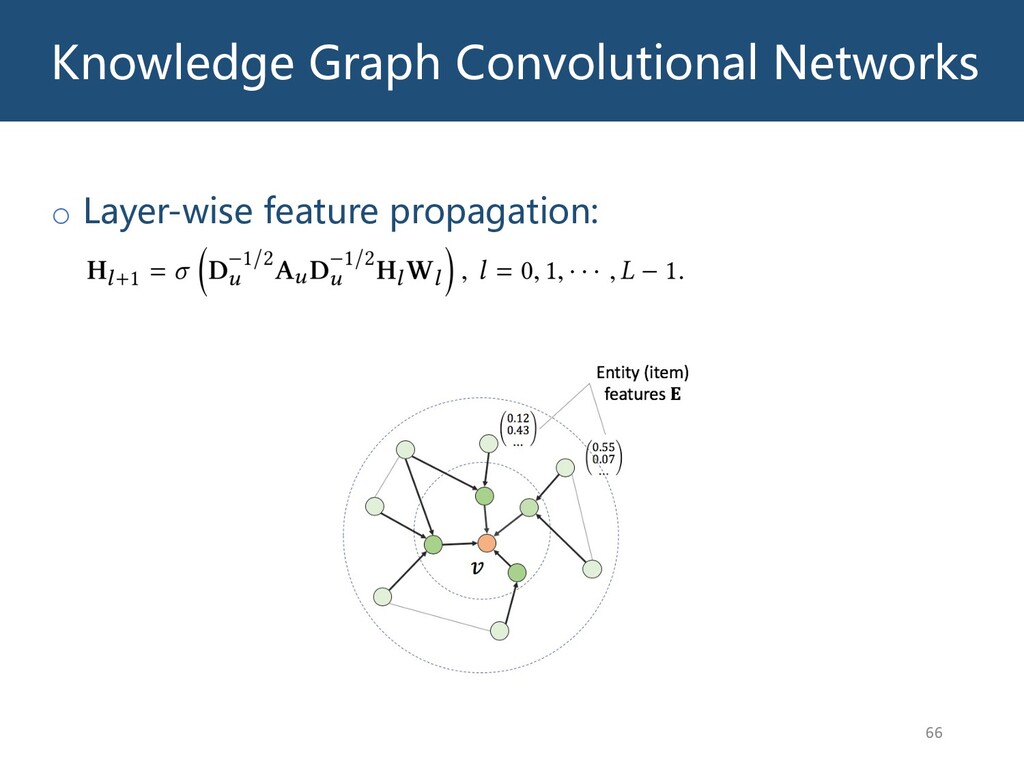{kind=link}
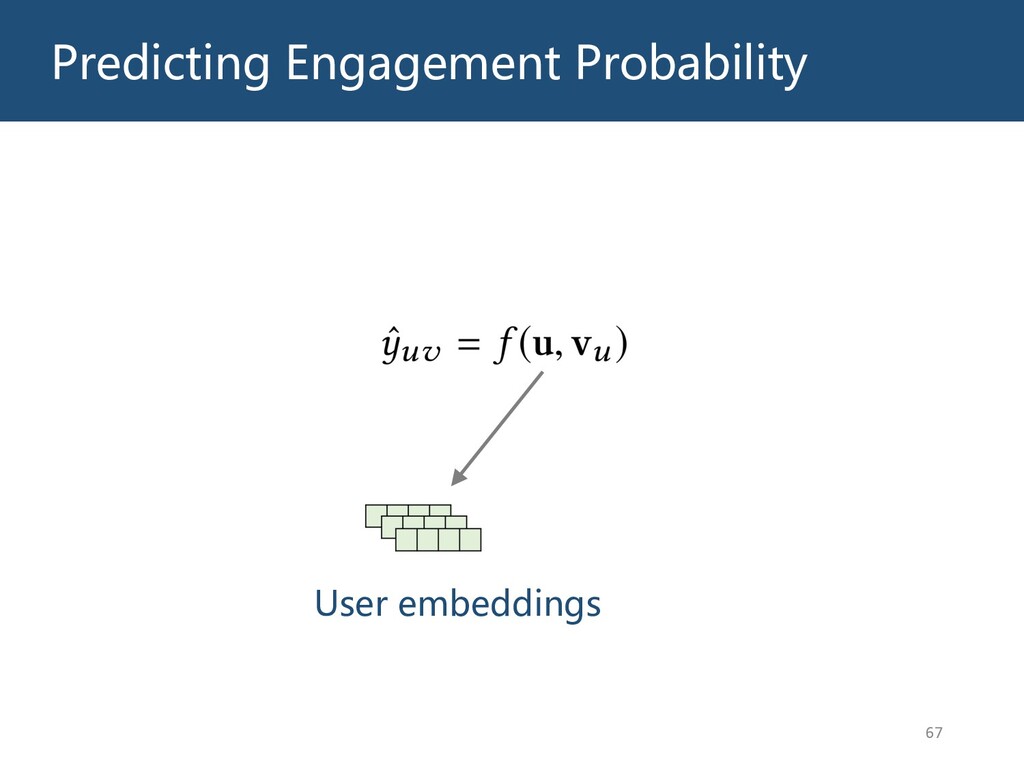{kind=link}
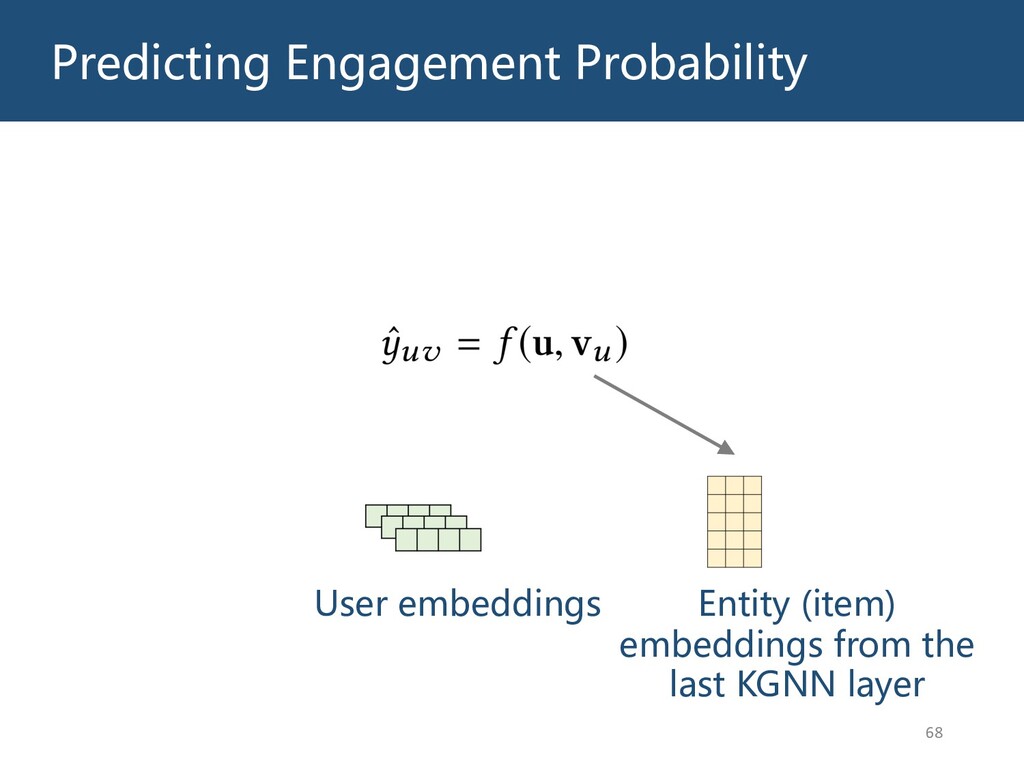{kind=link}
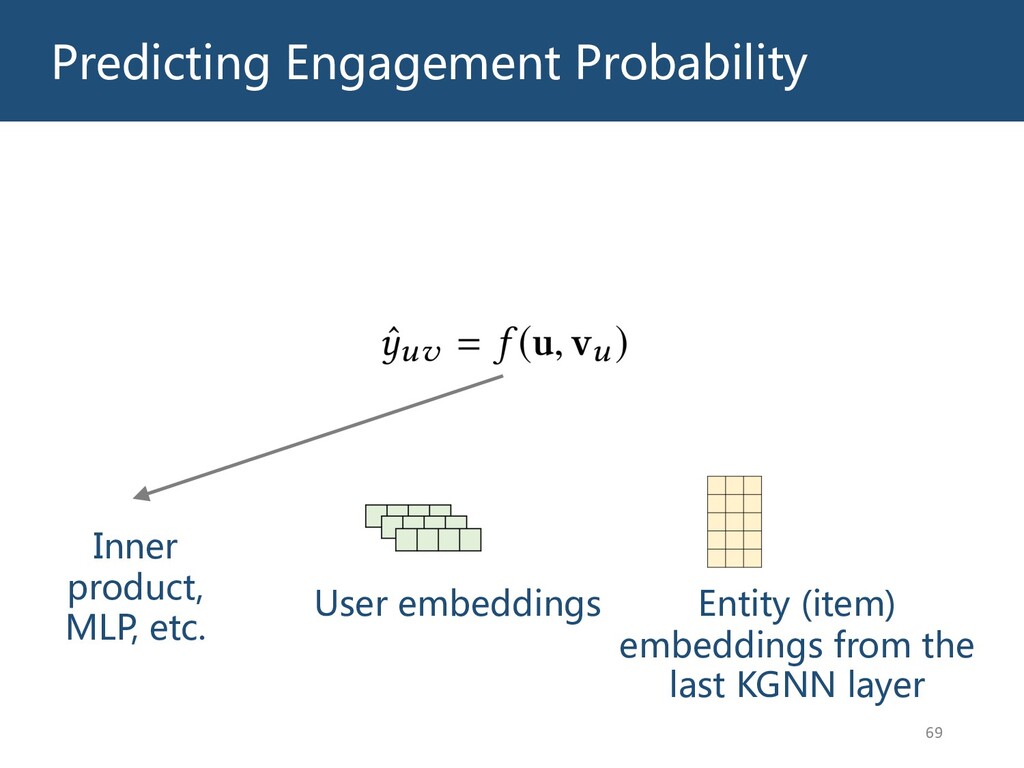{kind=link}
{kind=link}
{kind=link}
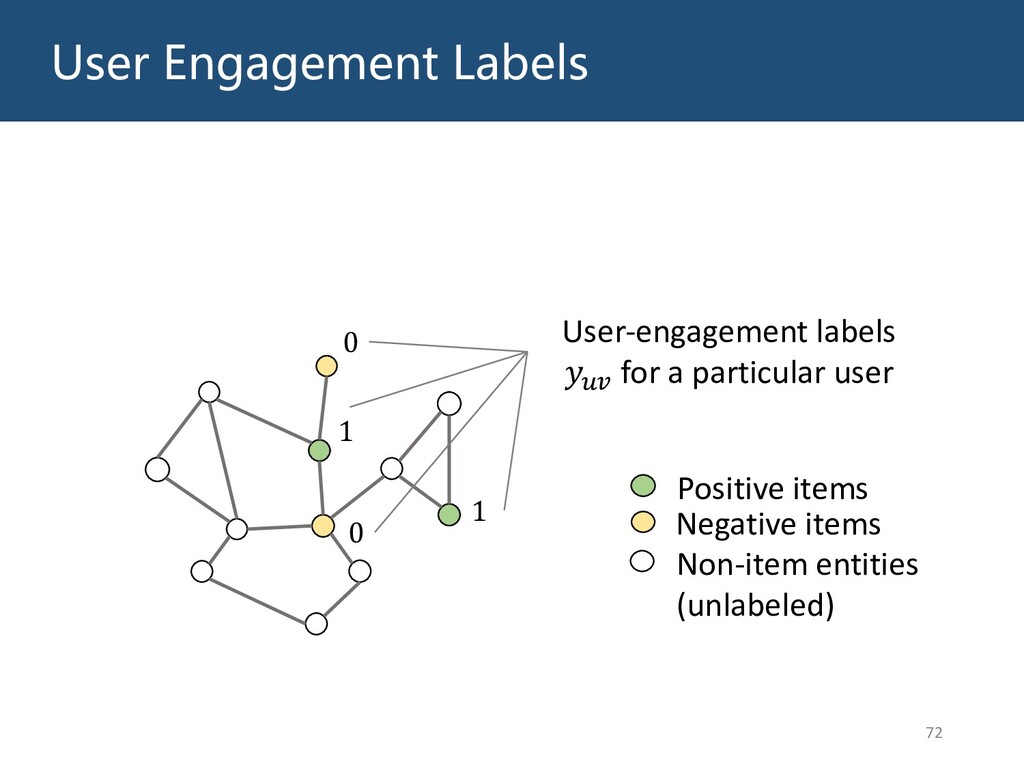{kind=link}
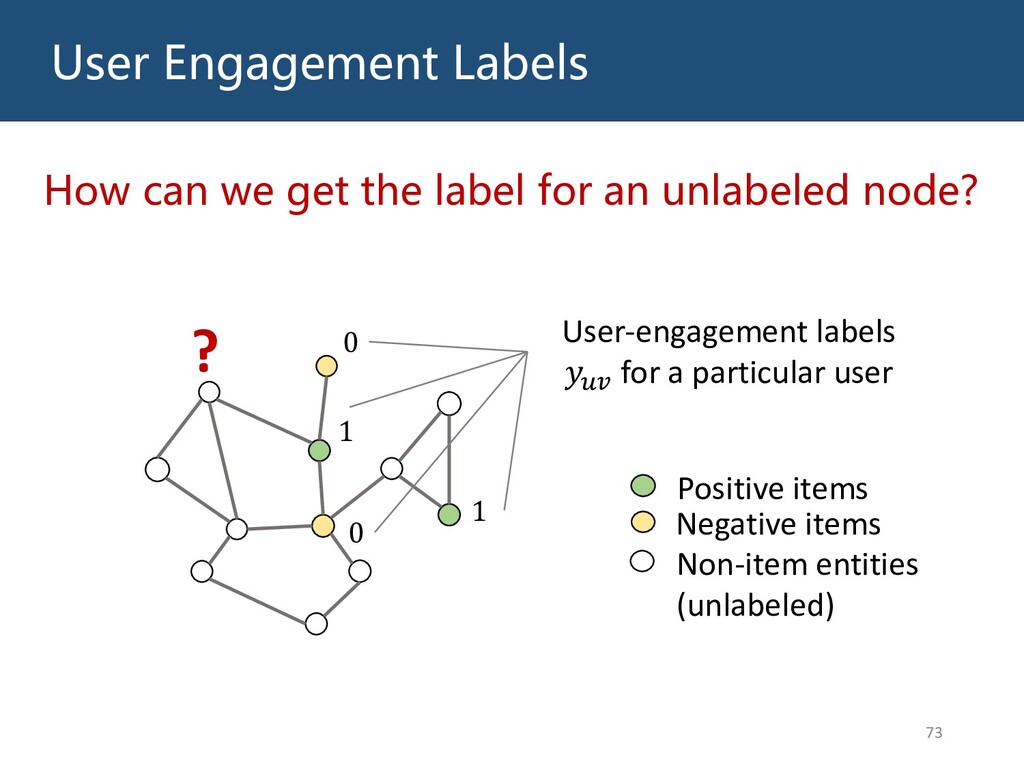{kind=link}
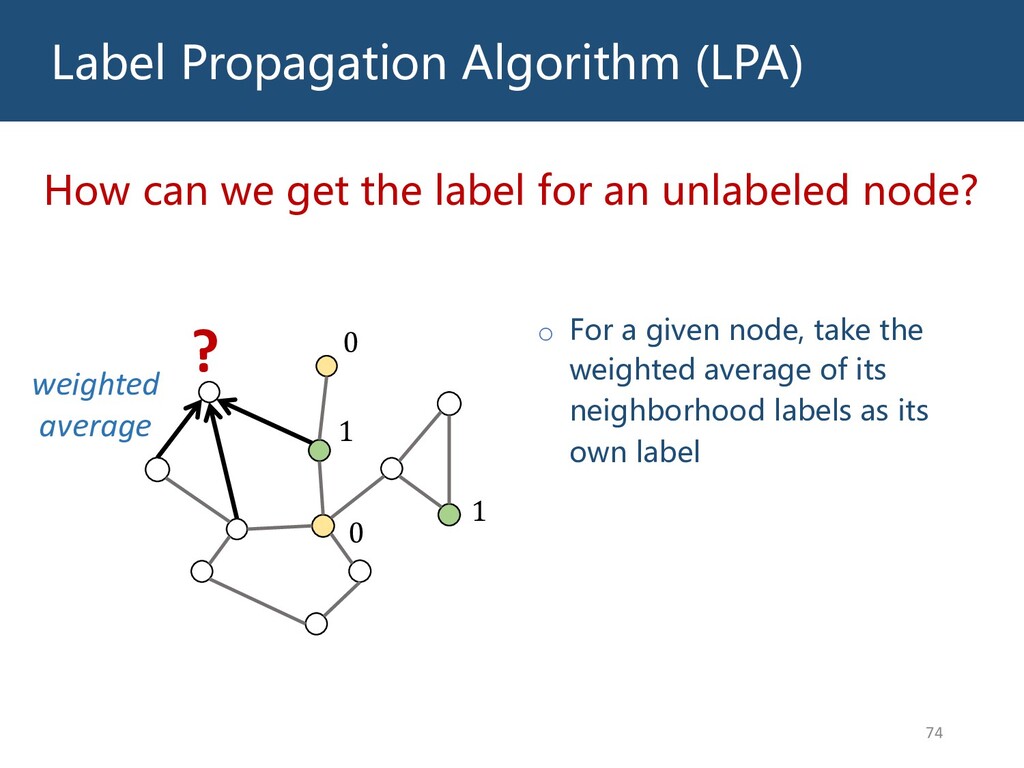{kind=link}
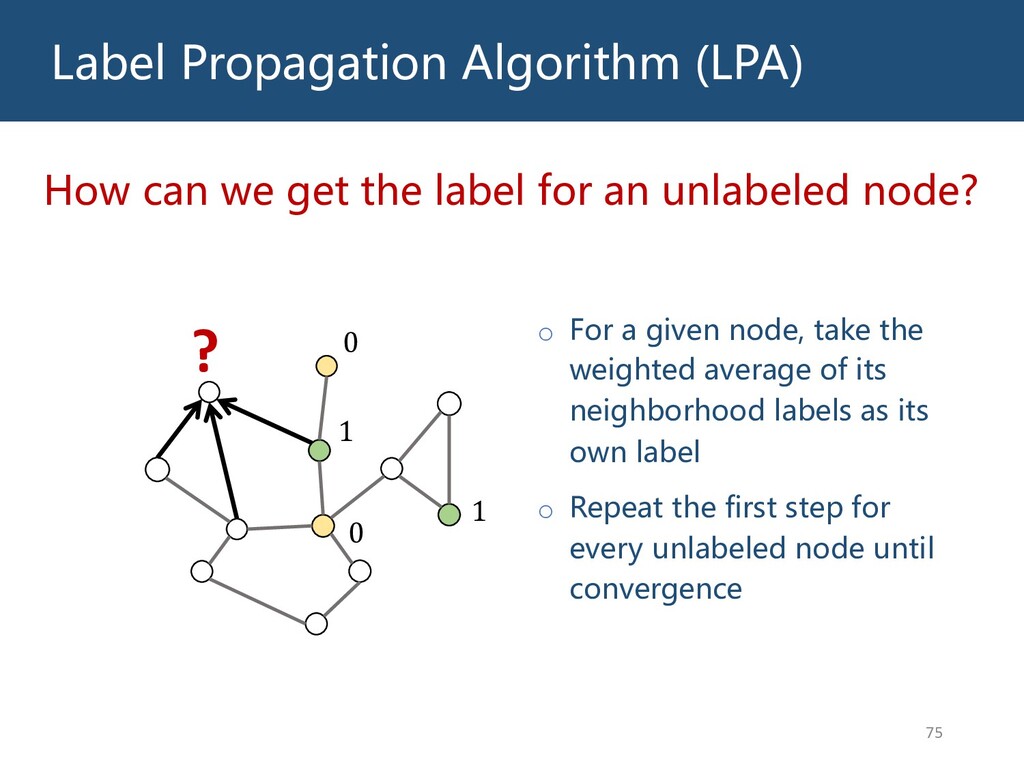{kind=link}
{kind=link}
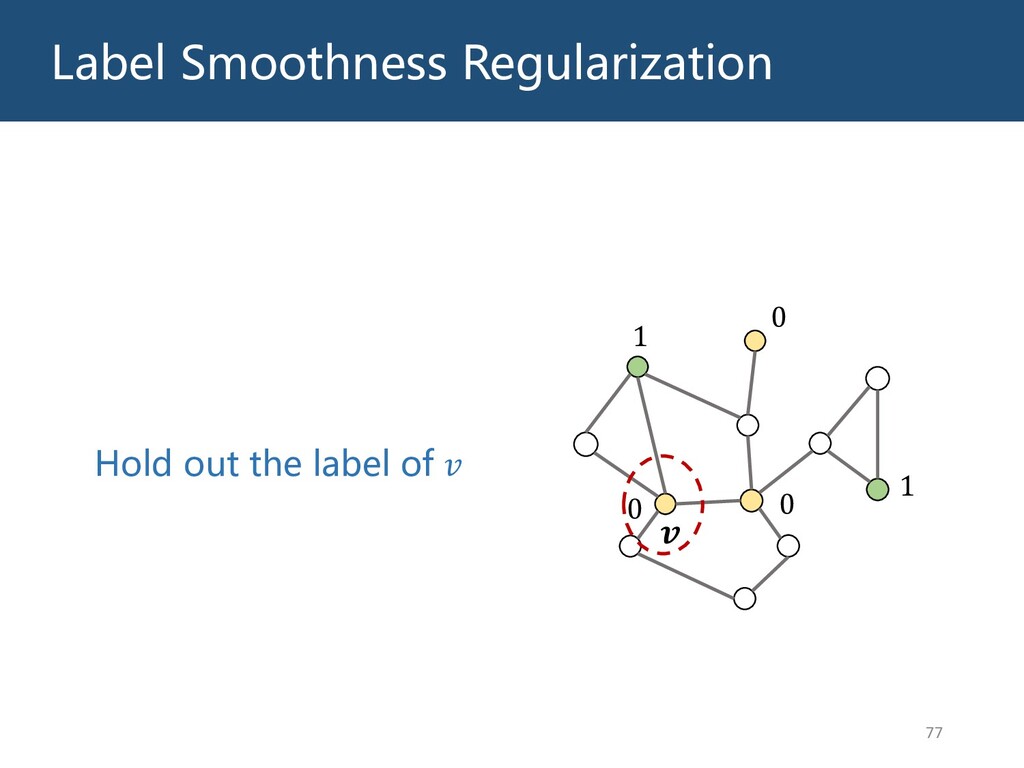{kind=link}
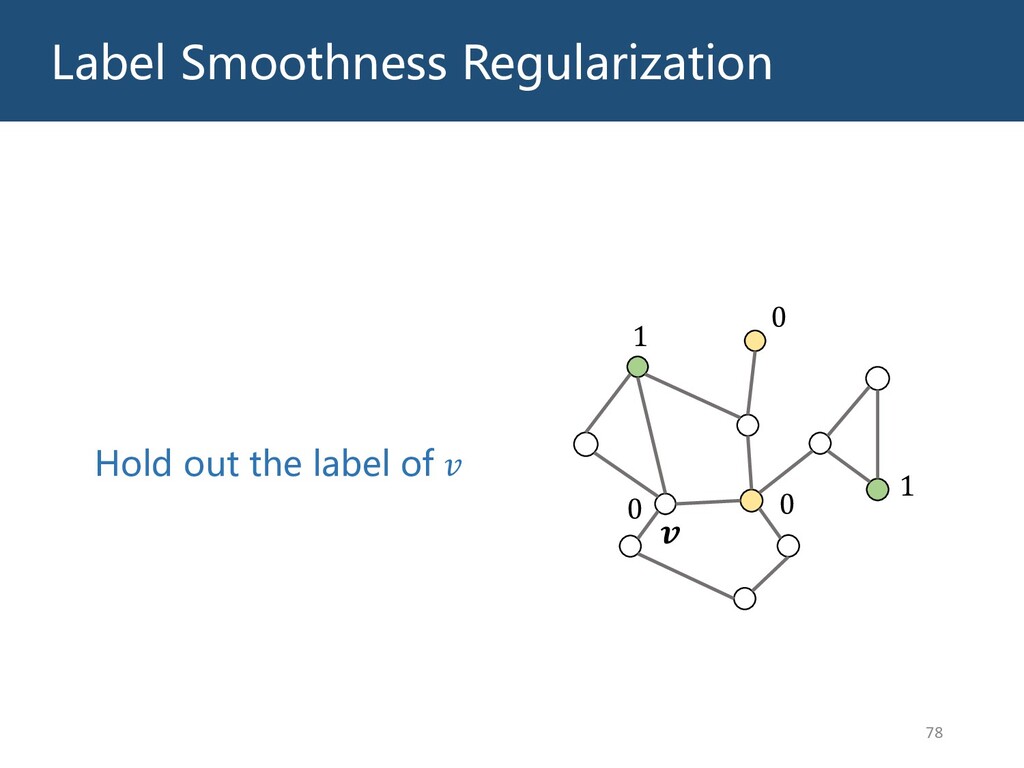{kind=link}
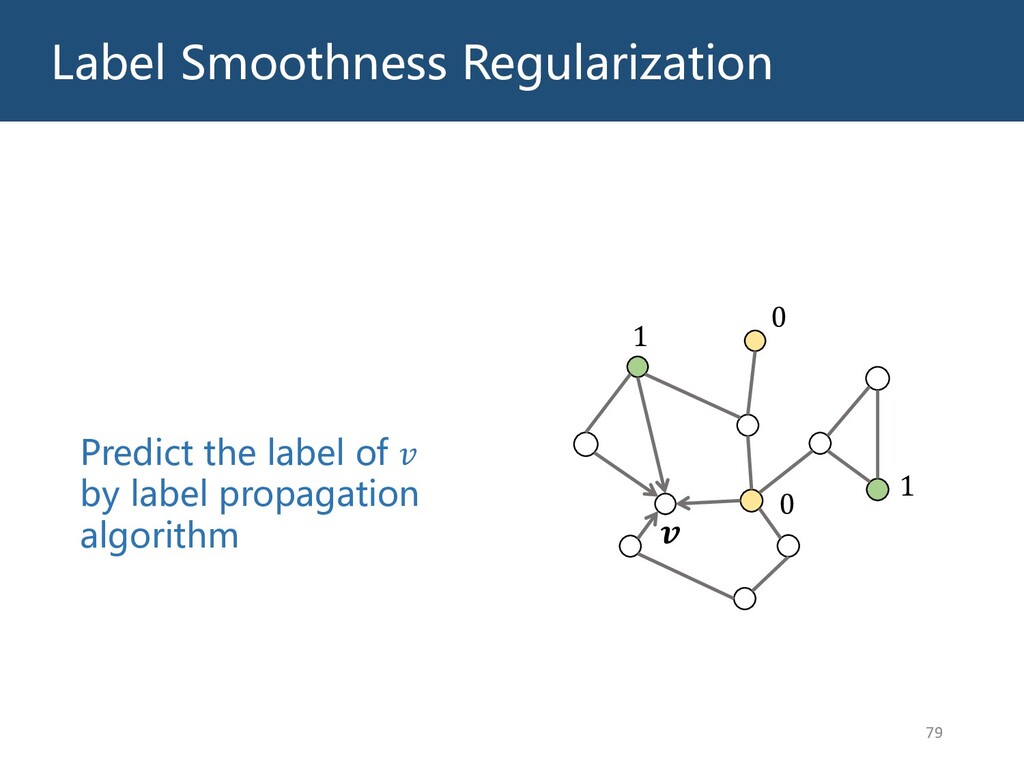{kind=link}
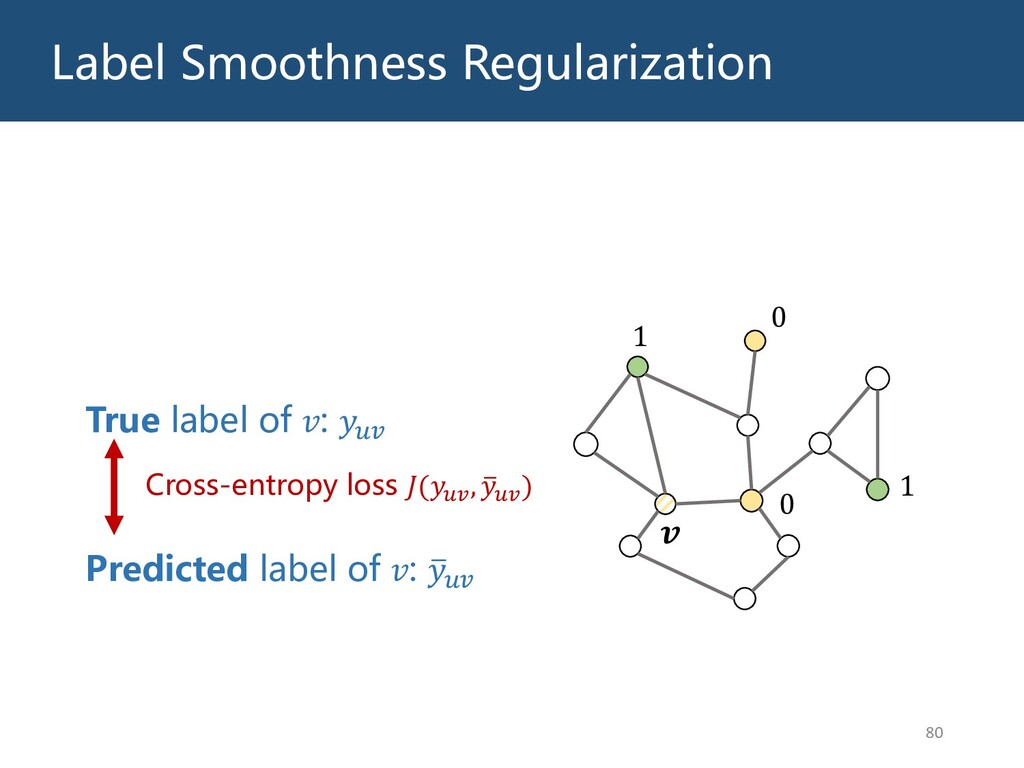{kind=link}
{kind=link}
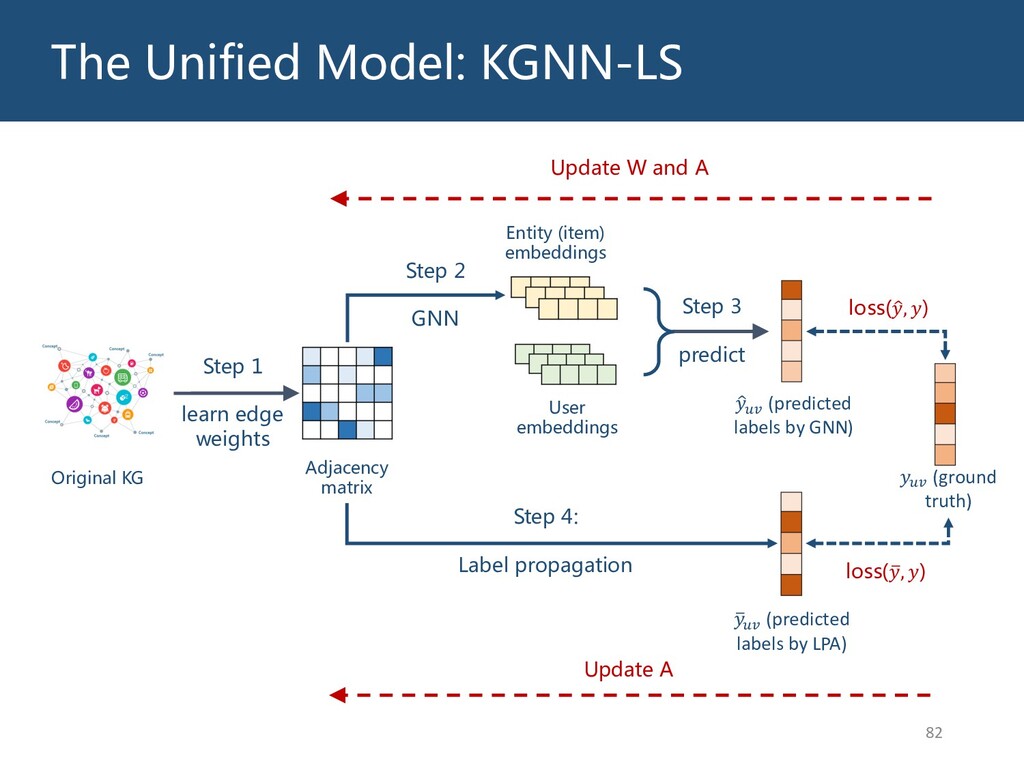{kind=link}
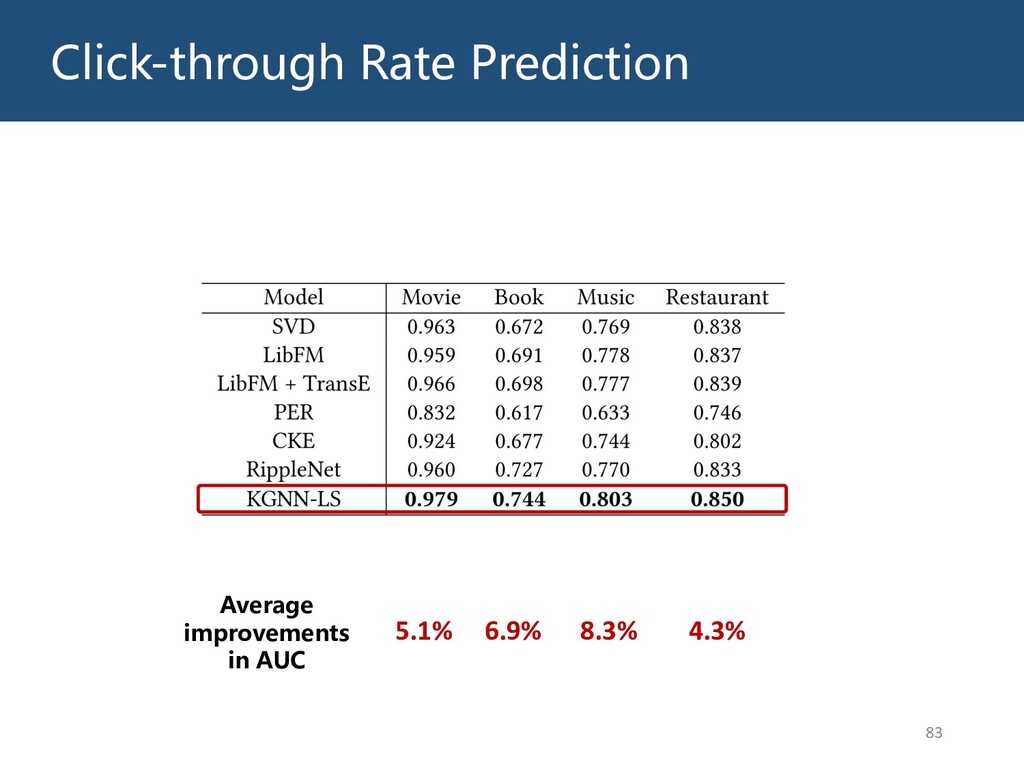{kind=link}
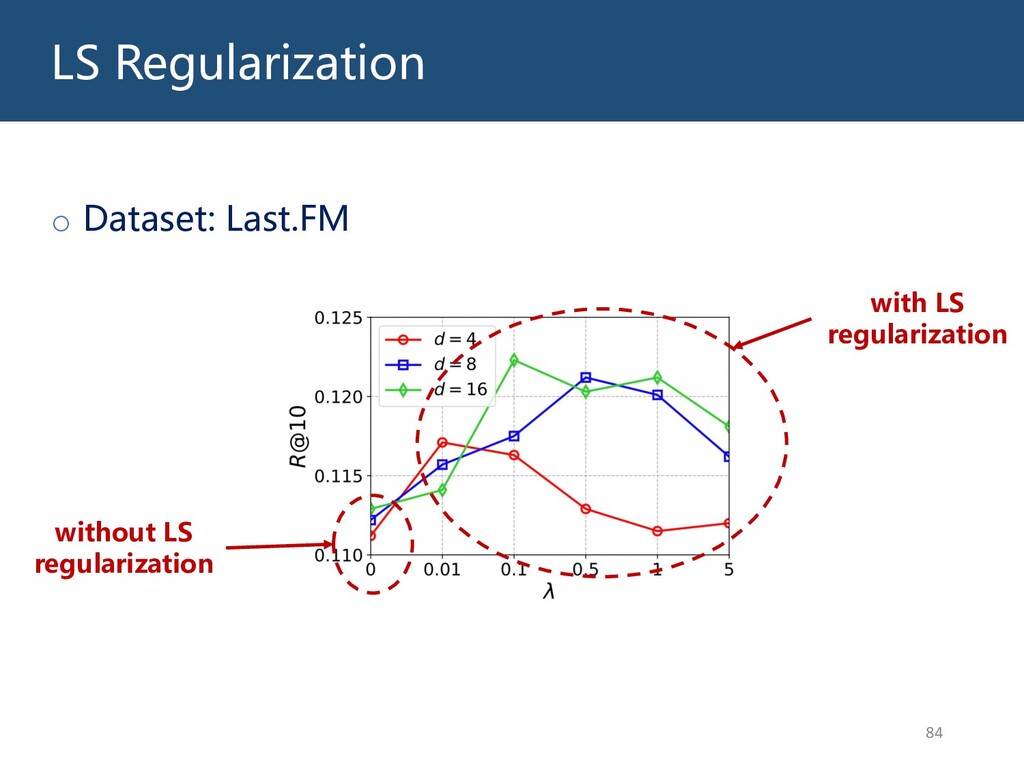{kind=link}
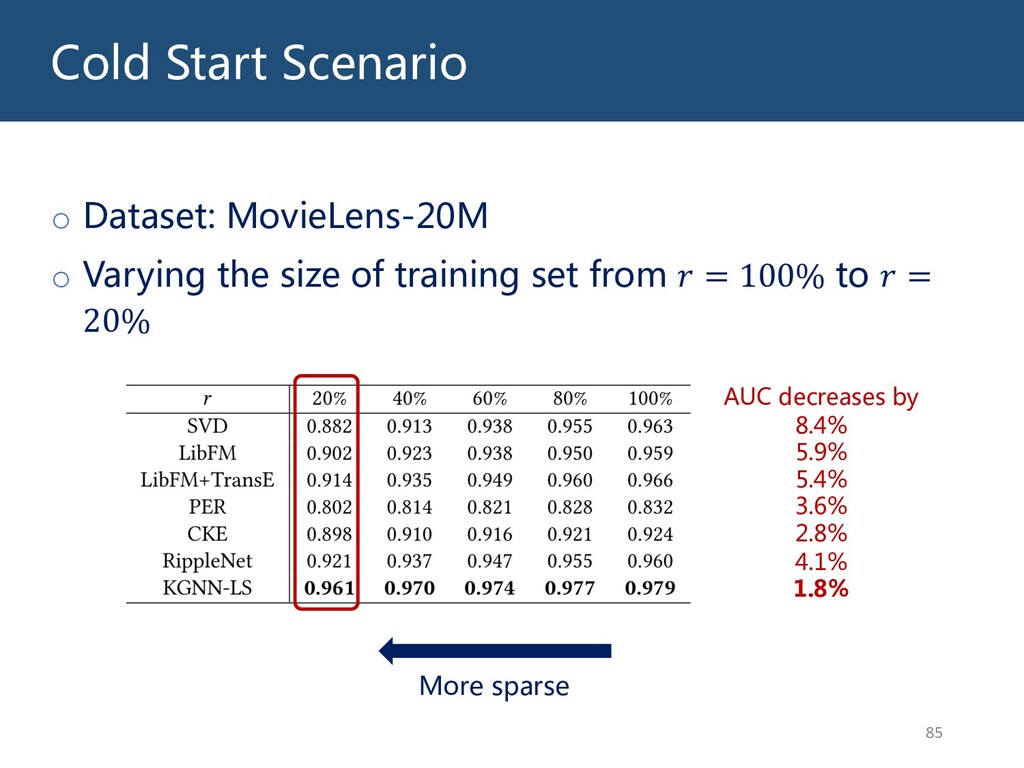{kind=link}
{kind=link}
{kind=link}
{kind=link}