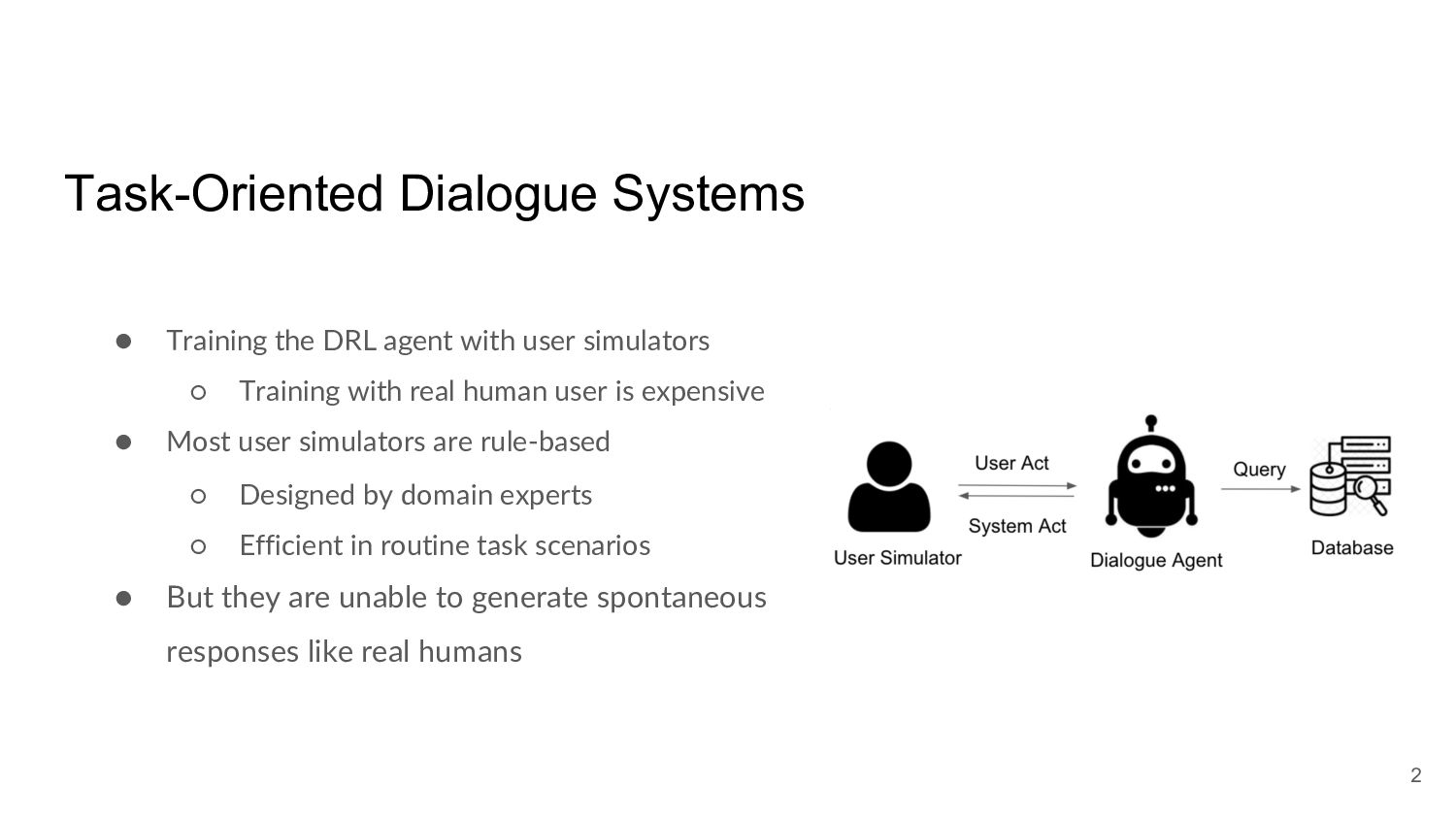
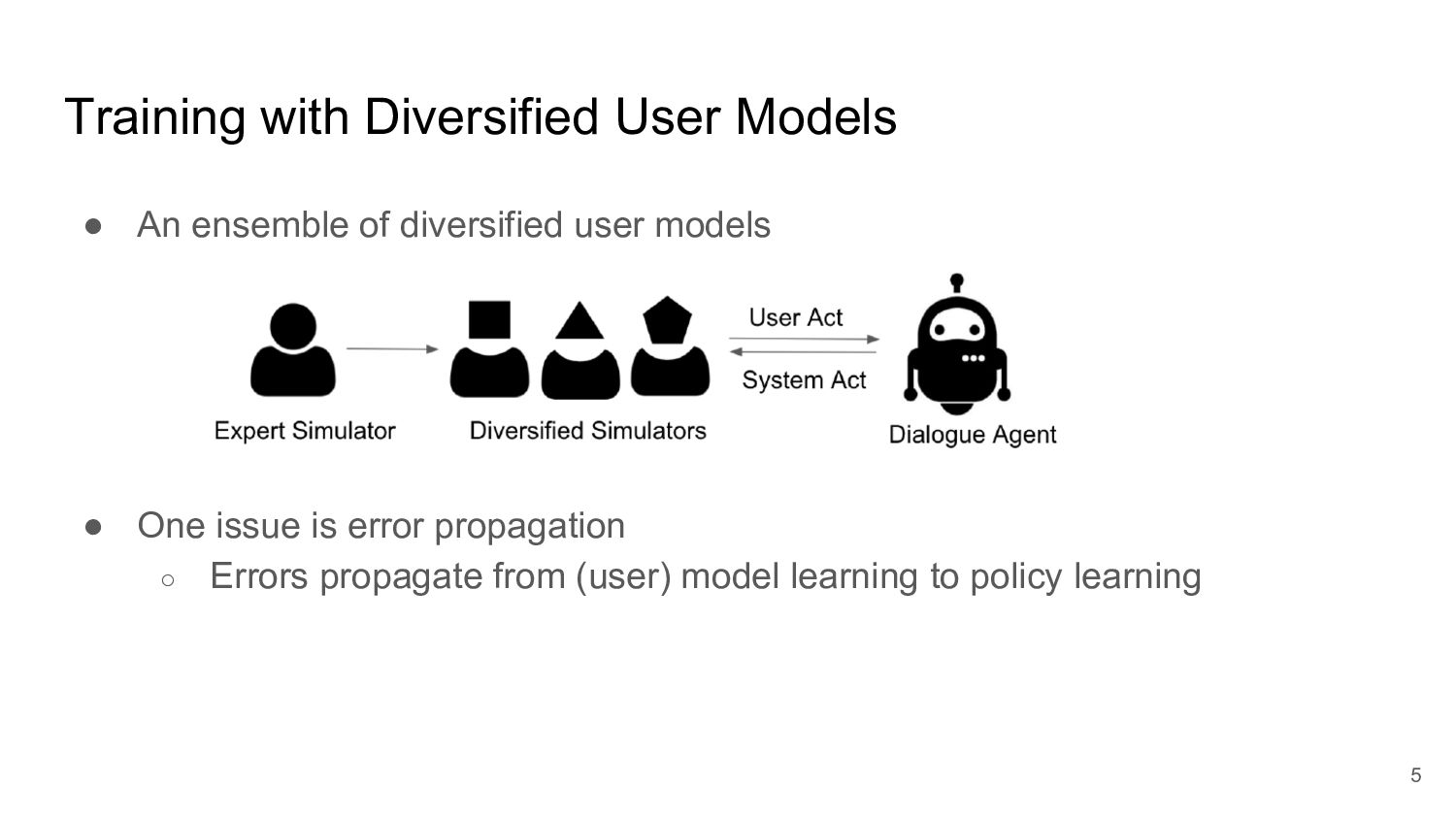
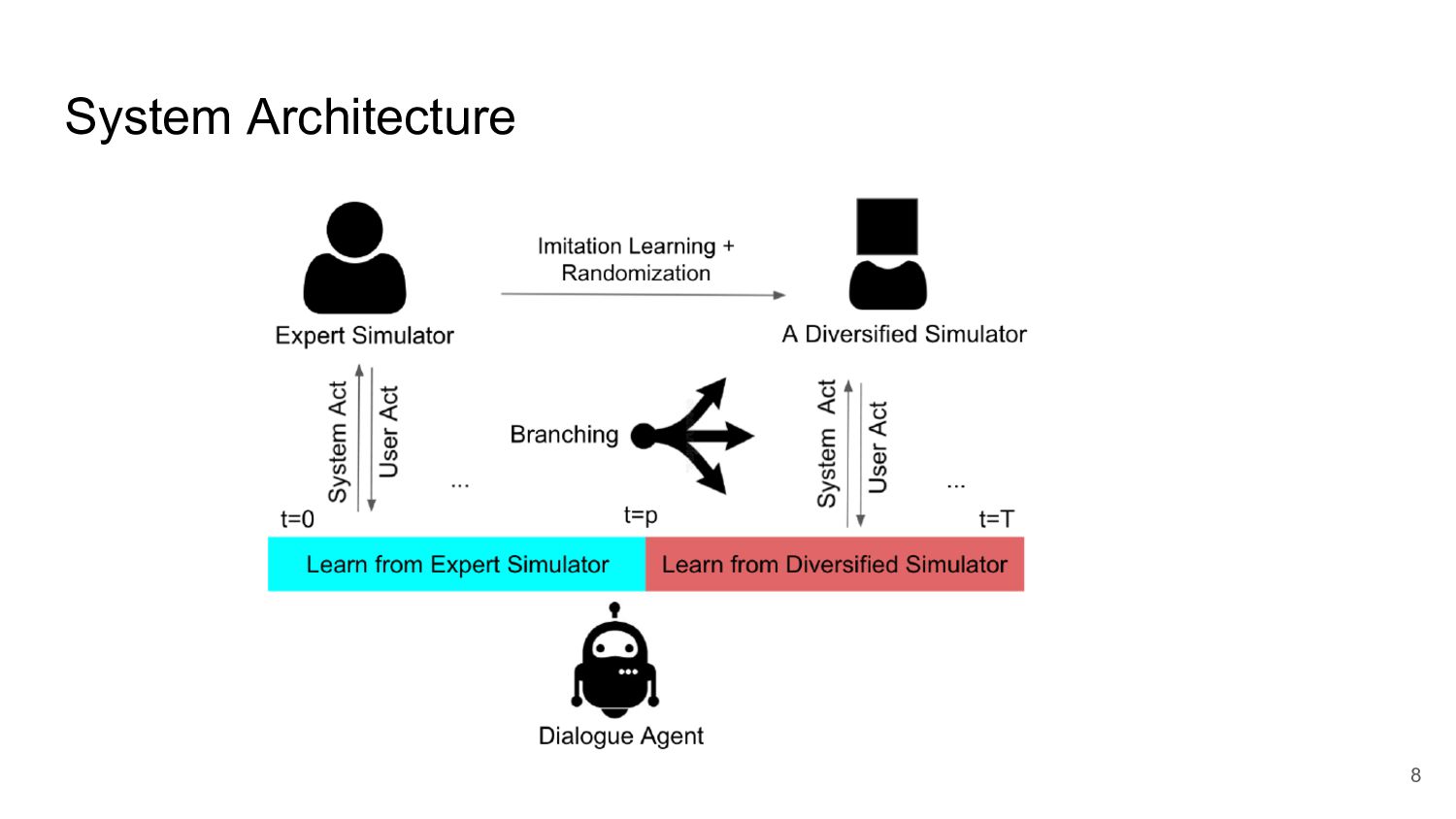
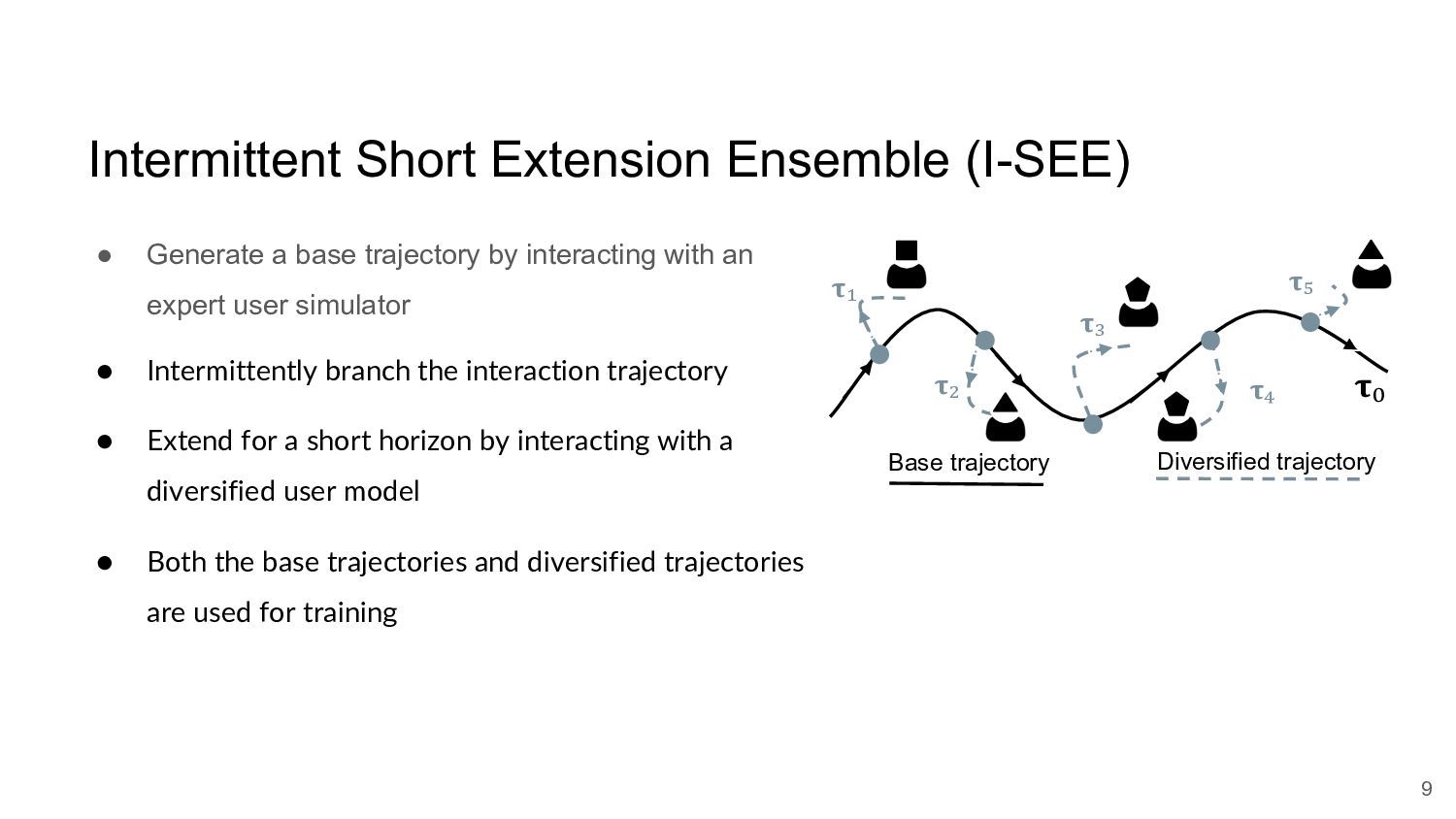
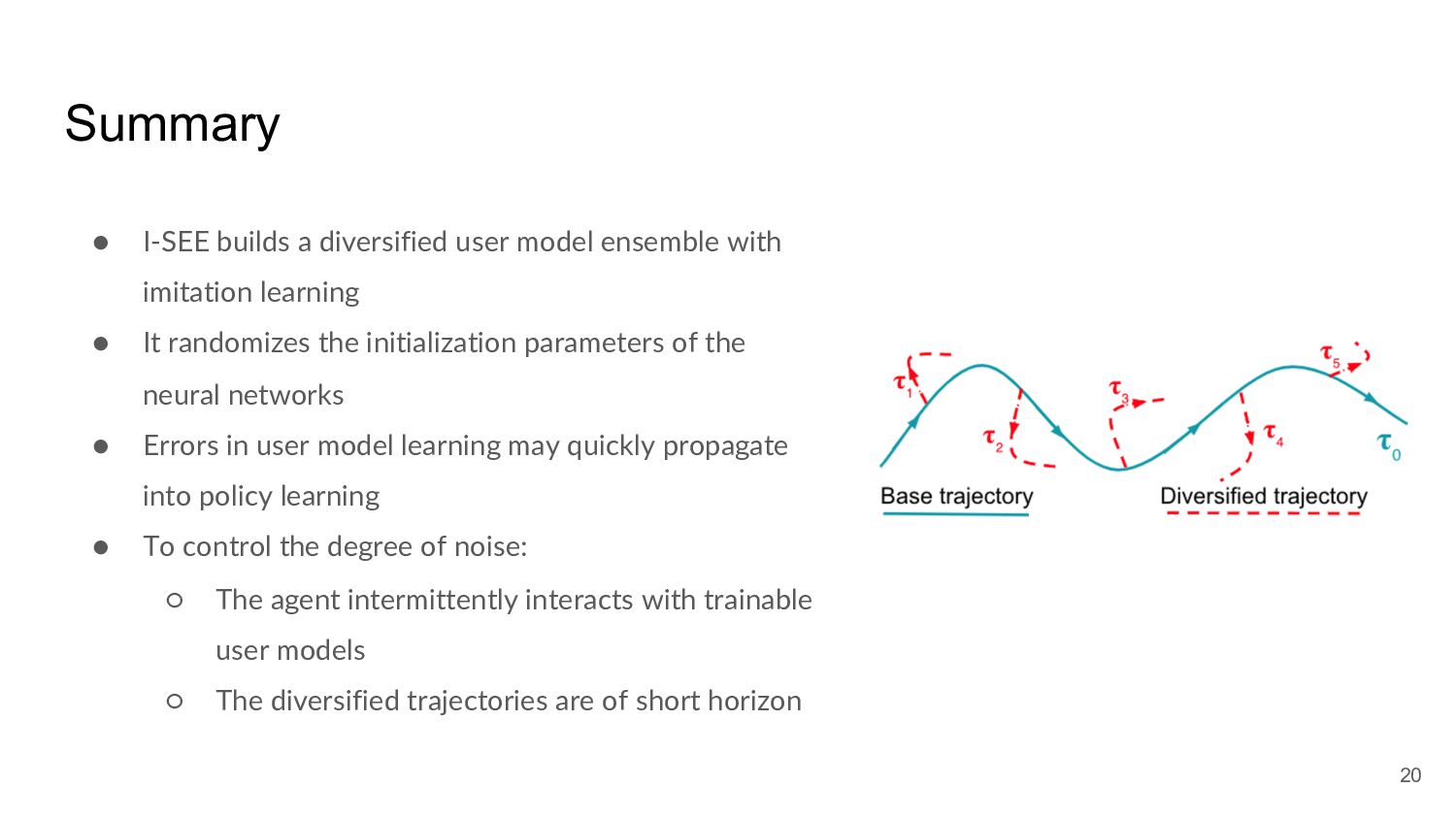
Many task-oriented dialogue systems use deep reinforcement learning (DRL) to learn policies that respond to the user appropriately and complete the tasks successfully. Training DRL agents with diverse dialogue trajectories prepare them well for rare user requests and unseen situations. One effective diversification method is to let the agent interact with a diverse set of learned user models. However, trajectories created by these artificial user models may contain generation errors, which can quickly propagate into the agent’s policy. It is thus important to control the quality of the diversification and resist the noise. In this paper, we propose a novel dialogue diversification method for task-oriented dialogue systems trained in simulators. Our method, Intermittent Short Extension Ensemble (I-SEE), constrains the intensity to interact with an ensemble of diverse user models and effectively controls the quality of the diversification. Evaluations show that I-SEE successfully boosts the performance of several DRL dialogue agents.
Speaker's bio: Dr. Grace Hui Yang is an Associate Professor in the Department of Computer Science at Georgetown University. Dr. Yang is leading the InfoSense (Information Retrieval and Sense-Making) group at Georgetown University, Washington D.C. Dr. Yang obtained her Ph.D. from Carnegie Mellon University in 2011. Her current research interests include deep reinforcement learning, interactive agents, and human-centered AI. Prior to this, she conducted research on question answering, automatic ontology construction, near-duplicate detection, multimedia information retrieval, and opinion and sentiment detection. Dr. Yang's research has been supported by the Defense Advanced Research Projects Agency (DARPA) and the National Science Foundation (NSF). Dr. Yang co-organized the Text Retrieval Conference (TREC) Dynamic Domain Track from 2015 to 2017 and led the effort for SIGIR privacy-preserving information retrieval workshops from 2014 to 2016. Dr. Yang has served on the editorial boards of ACM TOIS and Information Retrieval Journal (from 2014 to 2017) and has actively served as an organizing or program committee member in many conferences such as SIGIR, ECIR, ACL, AAAI, ICTIR, CIKM, WSDM, and WWW. She is a recipient of the NSF Faculty Early Career Development Program (CAREER) Award.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
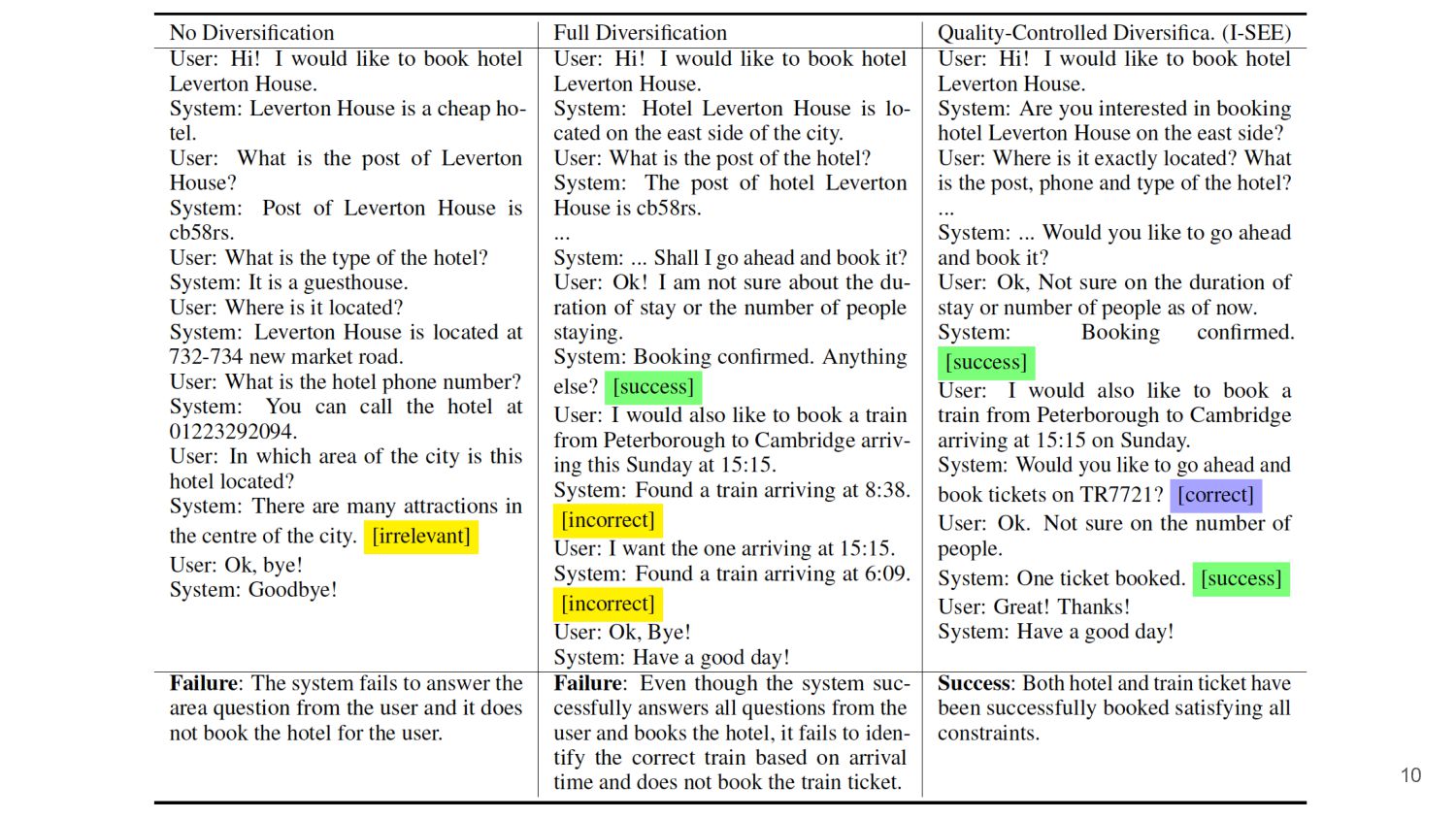{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
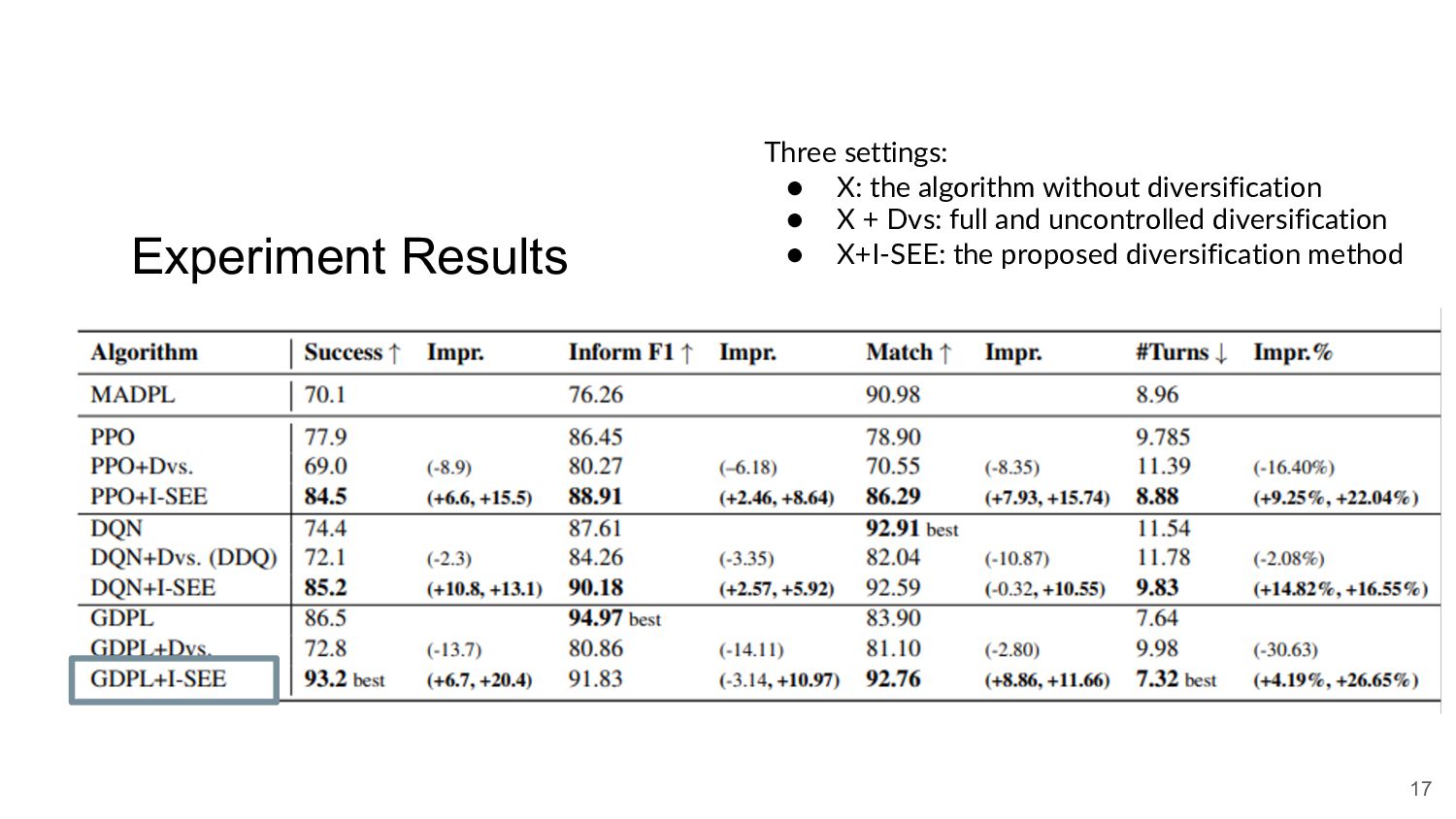{kind=link}
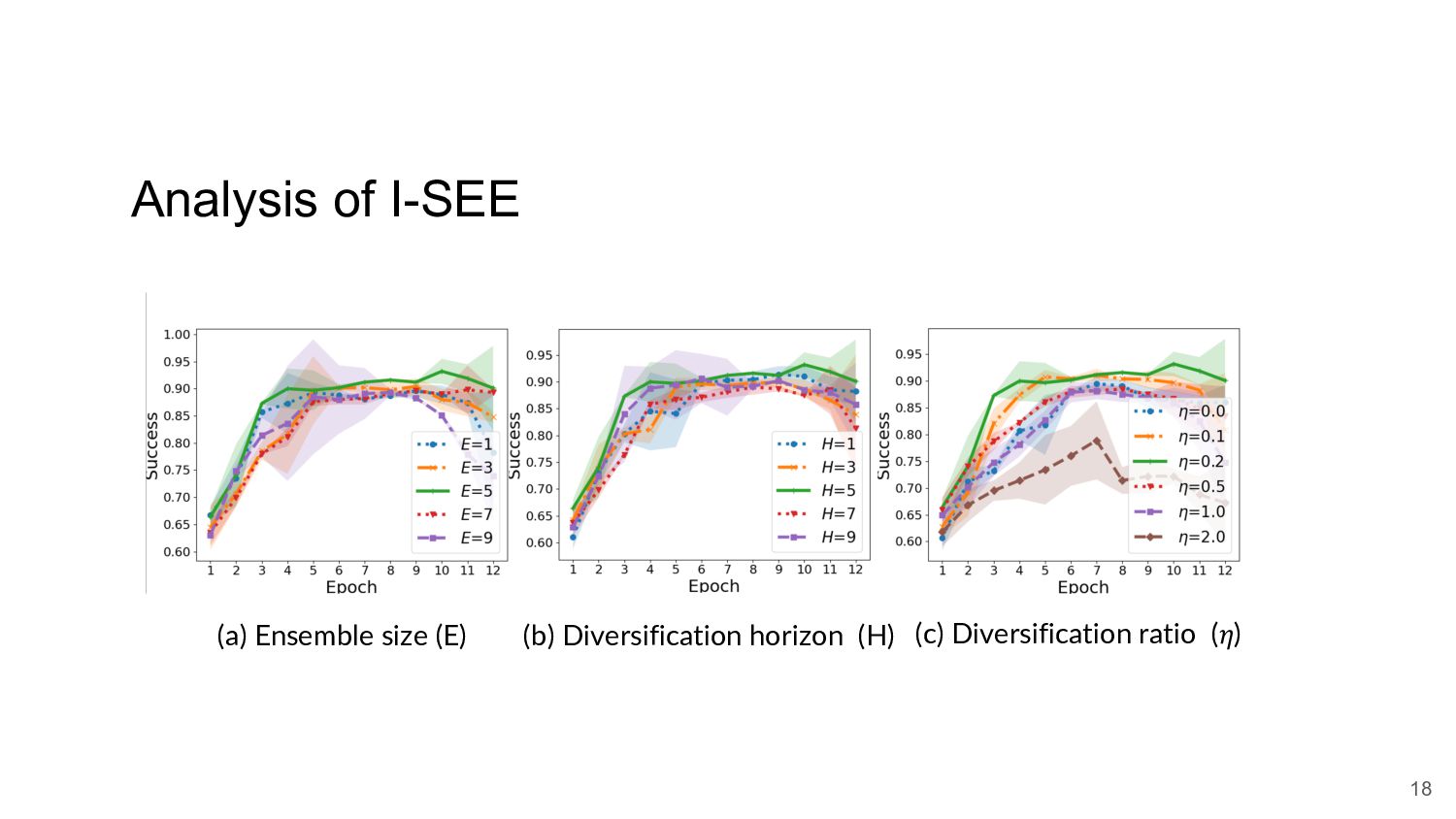{kind=link}
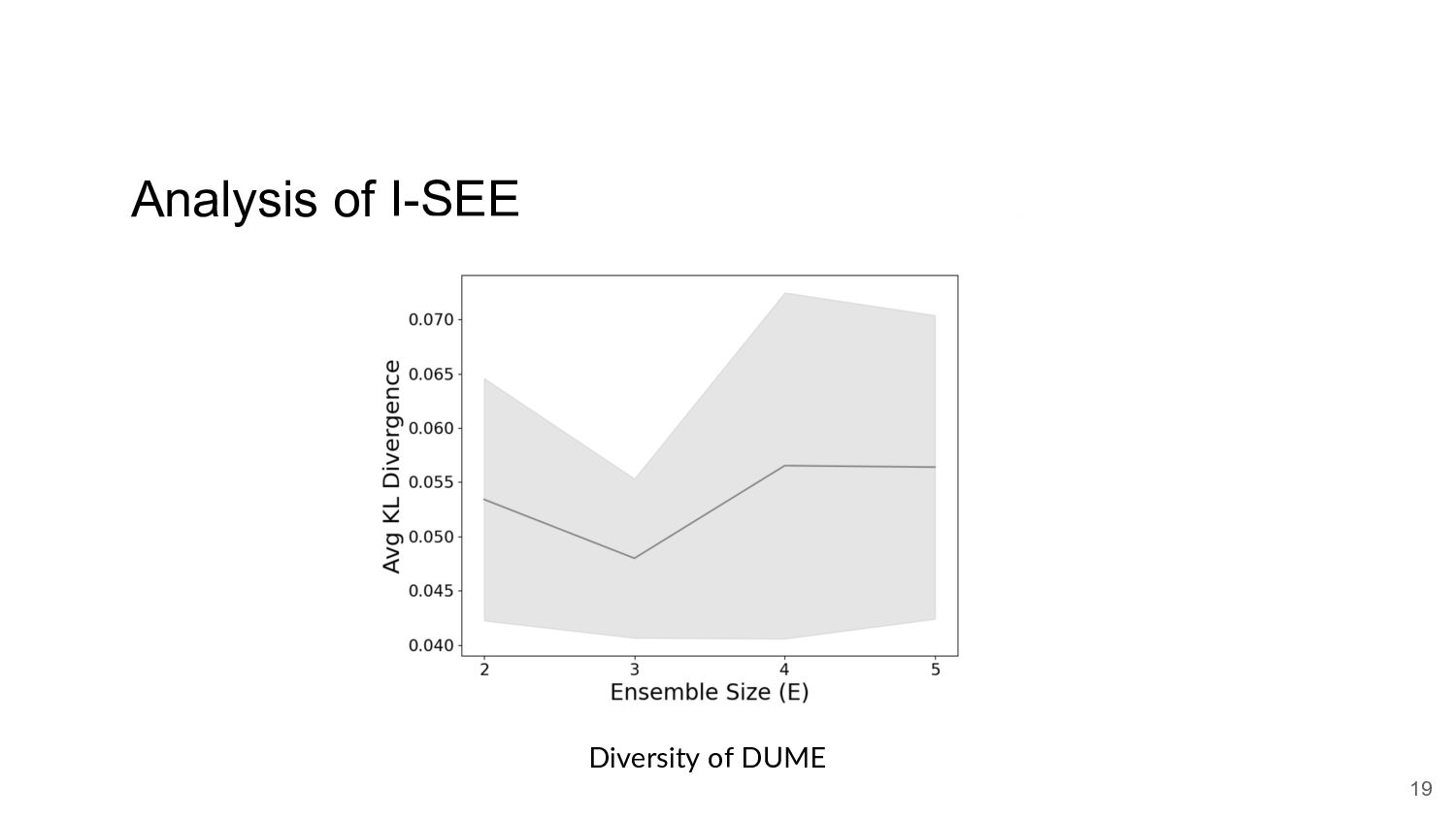{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}