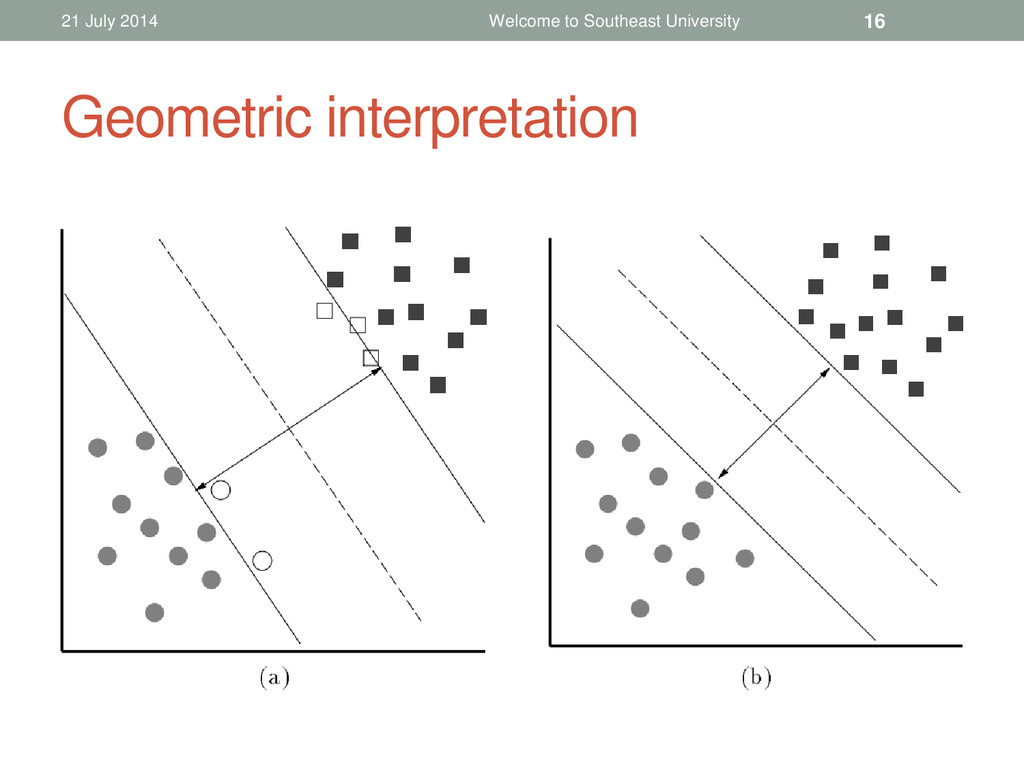
3 Choosing a proper C and solving the quadratic program The desired decision surface Λ* The quadratic form matrix D that appears in the objective function is completely dense and with size square in the number of data vectors. However, memory and computational constraints should be considered!
large data sets (above 5000 samples) is a very difficult problem to approach. The matrix D will has 2.5*10^9 entries, and 20GB of memory. Solution: We can solve iteratively the system. Only consider the support vectors, and therefore only optimizing over a reduced set of variables. Then we need to talk about: 1.Optimality conditions: these conditions allow us to decide computationally. 2.Strategy for Improvement: this strategy defines a way to improve the cost function and is frequently associated with variables that violate optimality conditions. 21 July 2014 Welcome to Southeast University 4
of Decomposition, where the working set only have 2 elements. • Each iteration, only λi and λj corresponds to (xi , yi ) and (xj , yj ) are changed. 21 July 2014 Welcome to Southeast University 5 Figure from Teng’s PPT.
and sufficient for optimality, they are: 21 July 2014 Welcome to Southeast University 6 0 < λi < C yi g(xi ) = 1 λi = C yi g(xi ) ≤ 1 λi = 0 yi g(xi ) ≥ 1 KKT
7 B will be referred to as the working set (index set) N will be the left part of the set (αN = 0) B and N partition the index set, and that the optimality conditions hold in the sub-problem defined only for the variables in B. Therefore, we can have - Replace , without changing the cost function or the feasibility of both the subproblem and the original problem. - The new subproblem is optimal if an only if yi g(Xi ) ≥ 1 (case λi = 0).
levels in the subproblem, with variables λj = 0, j ∈ N that violate the optimality condition yj g(xj ) ≥ 1, yields a subproblem that, when optimized, improves the cost function while maintaining feasibility. The following proposition states this idea formally. 21 July 2014 Welcome to Southeast University 8
University 9 Proof: Assume the existence of λp , 0 < λp < C yp = yj There is some Consider are the jth and pth unit vectors. The pivot operation can be handled implicitly by letting σ > 0 and by holding λi = 0. The new cost function can be written as:
with common standard notation for nonlinear optimization problems, the QP program can be rewritten in minimization form as: • However, training a SVM using large data sets (above 5000 samples ) is a very difficult problem to approach without some kind of data or problem decomposition. • It means that D has 2.5*10^9 entries, and 20 Gigabytes of memory! 21 July 2014 Welcome to Southeast University 11 D
α = Λ, H = D B will be referred to as the working set (index set) N will be the left part of the set (αN = 0) B and N partition the index set, therefore, we can also have Then, we can rewrite the QP problem
15 • A fixed-size working set B, s.t |B| ≤ L • It is big enough to contain all SVs (λi >0), but small enough for the computer to handle it and optimize it.
Choose a even number |B|, and B is the working set 3. Compute 4. Rearrange the sequence vi , choose the first |B|/2 elements, and the last |B|/2 elements to forming the working set B. 21 July 2014 Welcome to Southeast University 17
![SVM TRAINING IN LARGE DATA SETS Weiwei SUN [email protected]](https://files.speakerdeck.com/presentations/d254de9608f14c5cb6379bdadfe1662f/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}