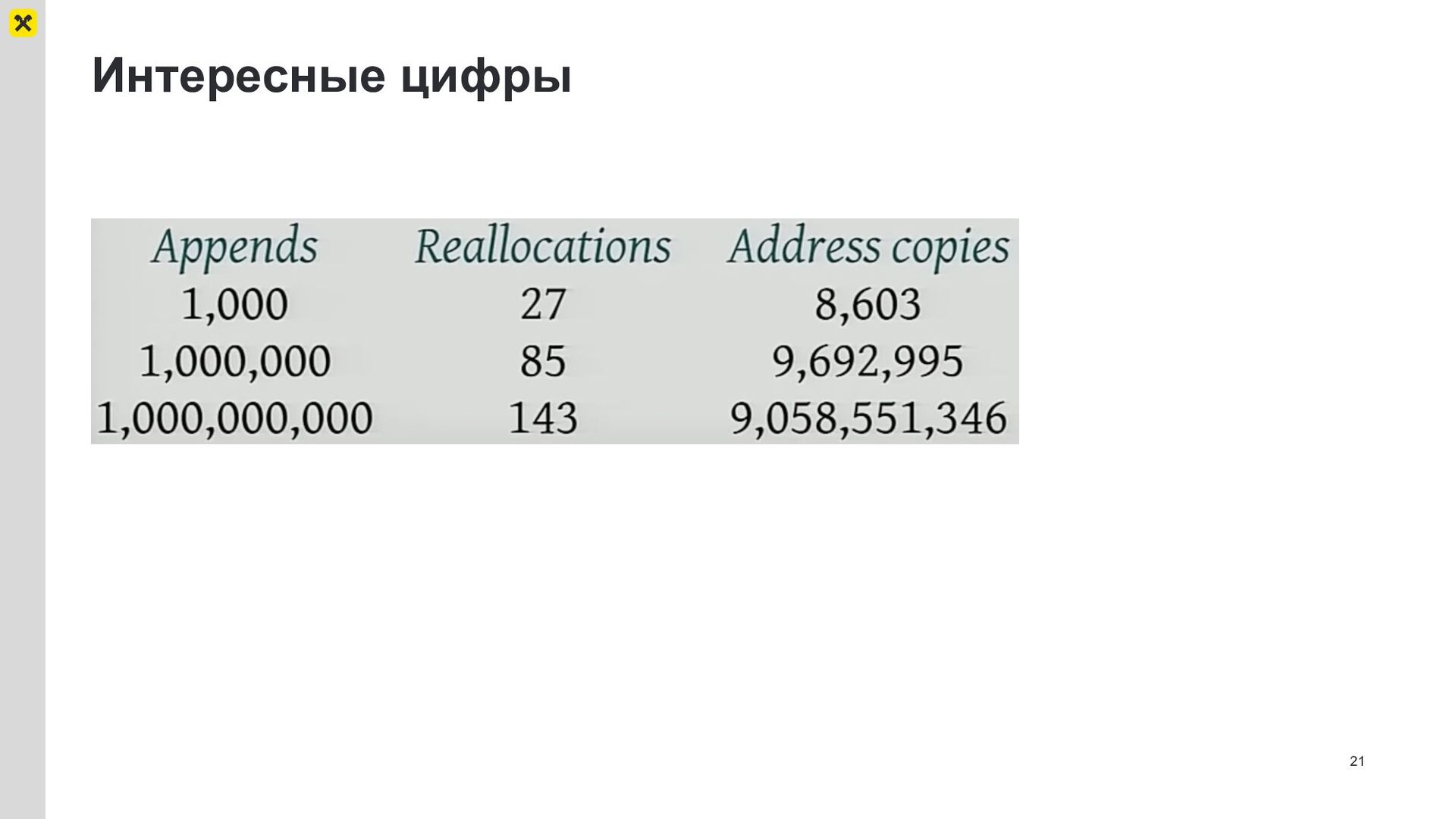
'--', '--'), (542403711206072985, 'two', 2), ('--', '--', '--'), (4677866115915370763, 'three', 3), ('--', '--', '--'), (-1182584047114089363, 'one', 1), ('--', '--', '--'), ('--', '--', '--') ] # стало hash_table = [None, 1, None, 2, None, 0, None, None] entries = [ (-1182584047114089363, 'one', 1), (542403711206072985, 'two', 2), (4677866115915370763, 'three', 3), ]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
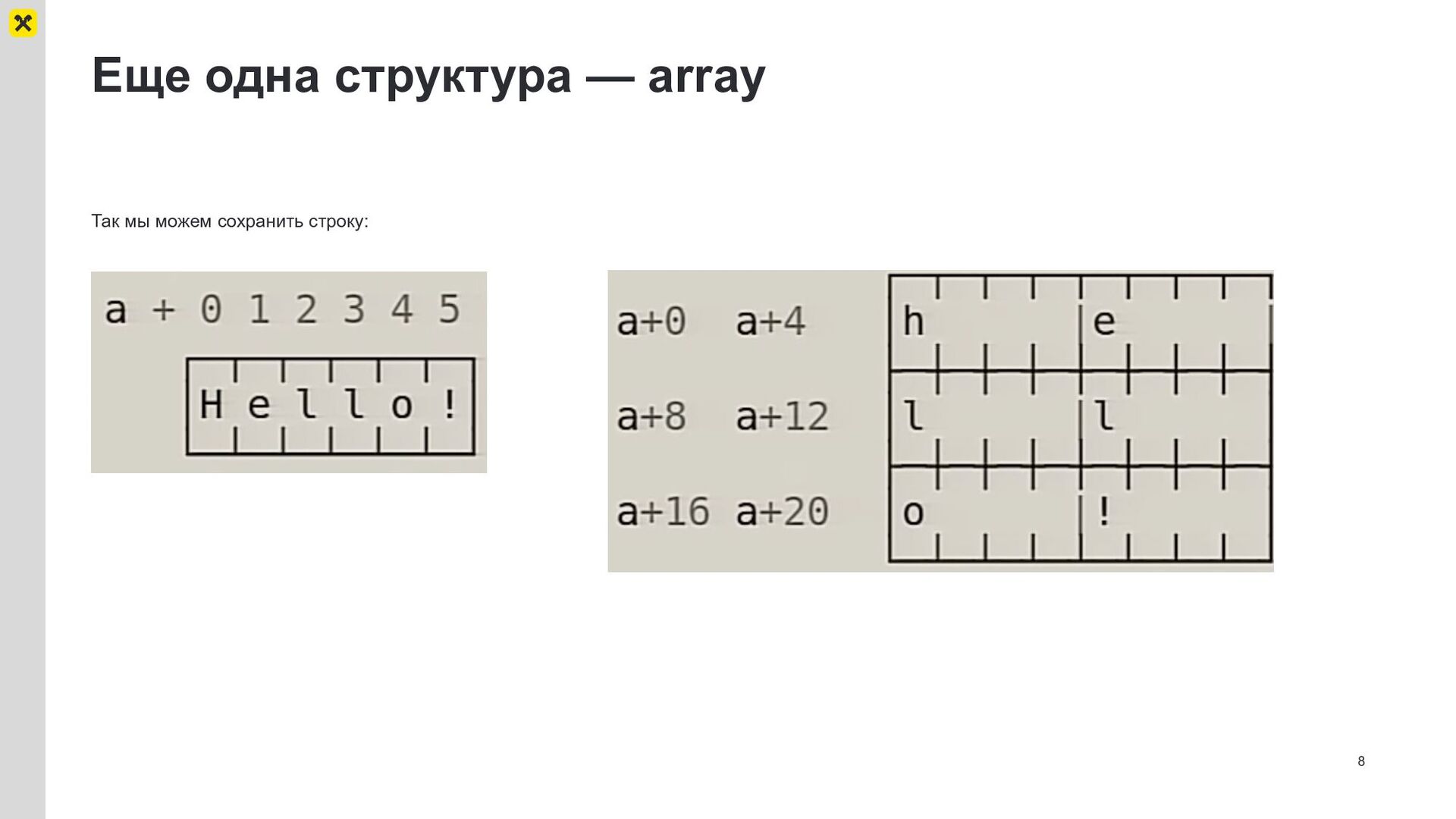{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
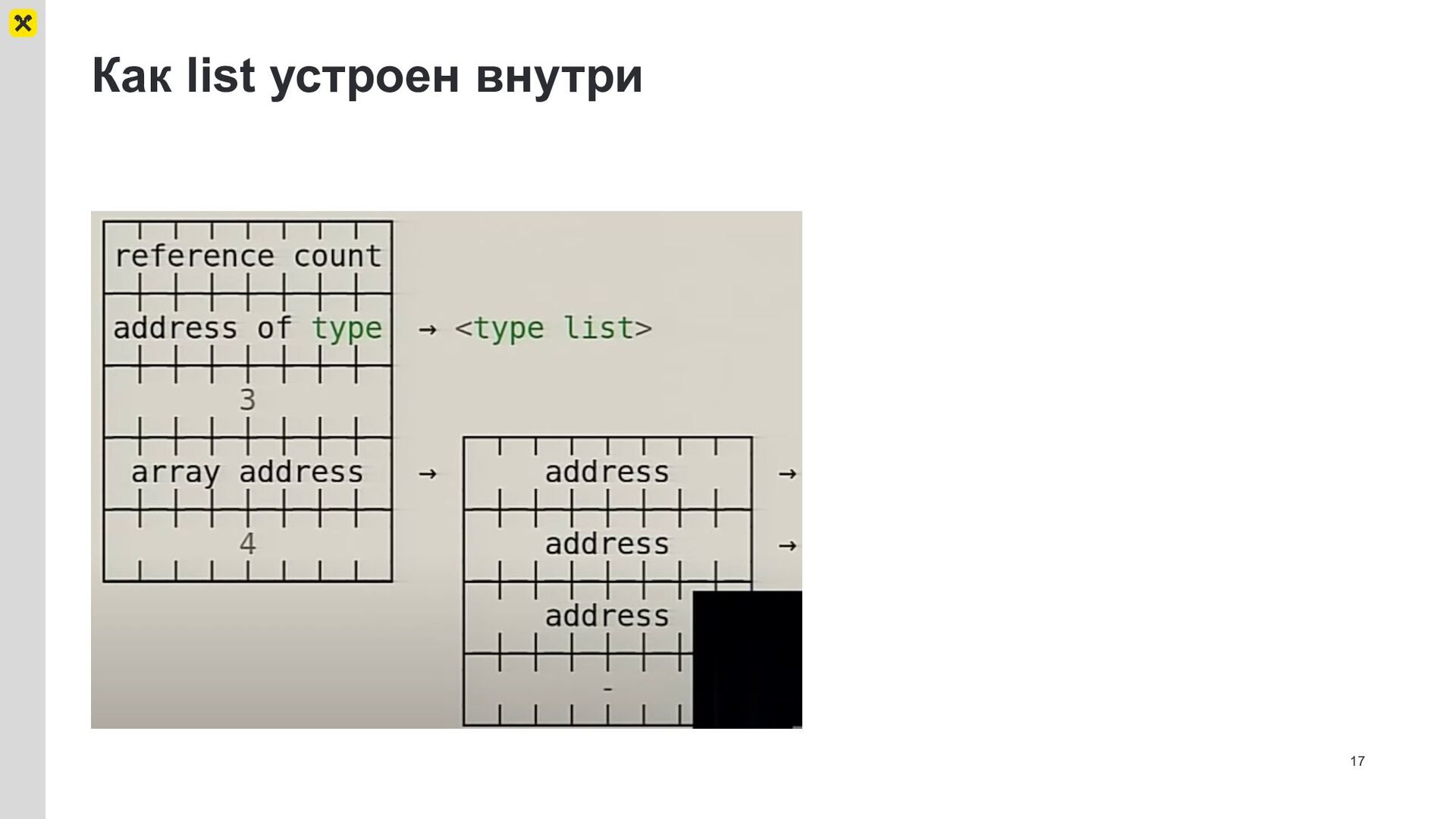{kind=link}
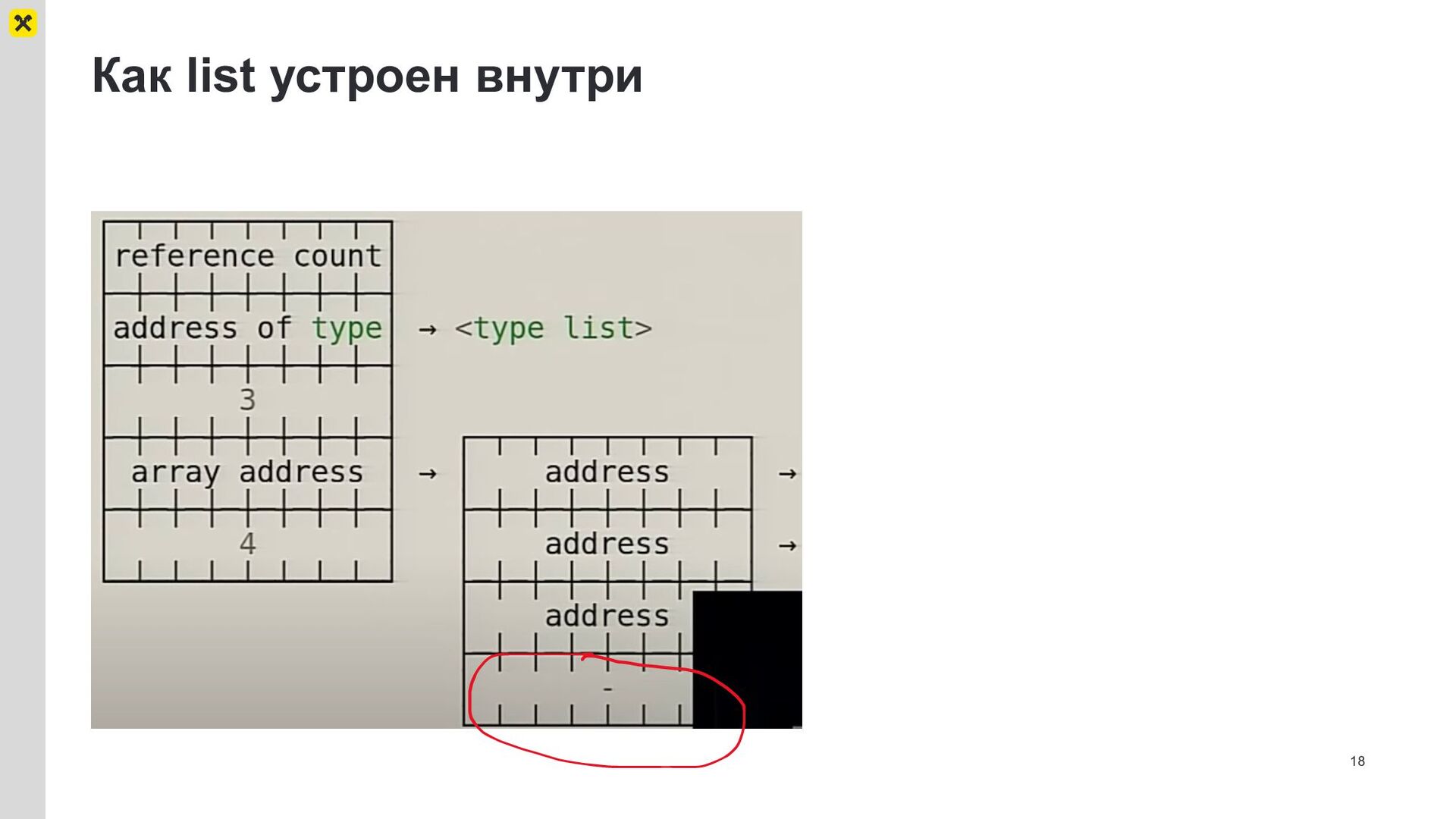{kind=link}
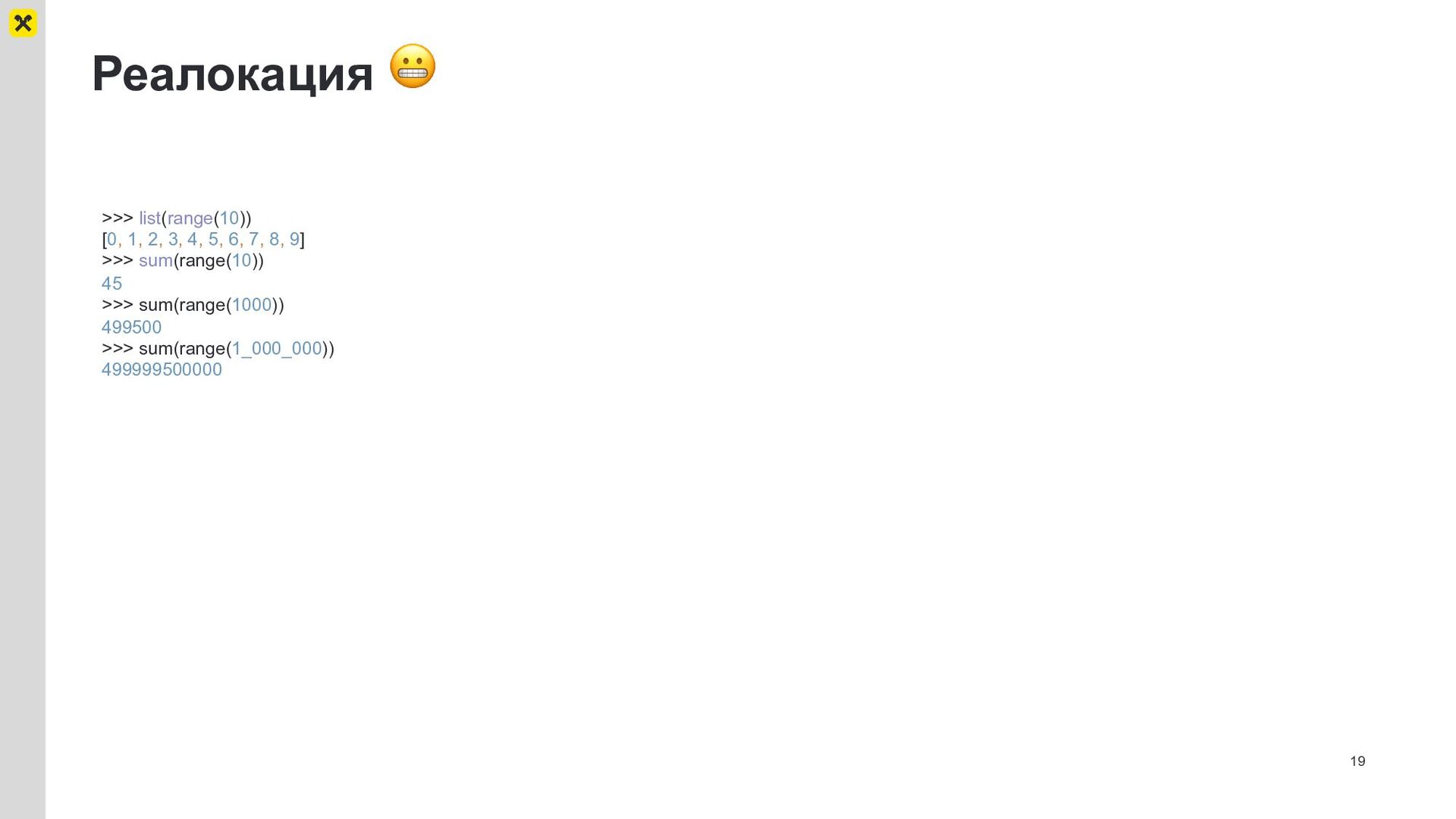{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![List — опасен! 24 s = [1, 2, 3, …]](https://files.speakerdeck.com/presentations/f6512baa144f487699782fc35b8a9d3b/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
![List — опасен! 27 s = [1, 2, 3, …]](https://files.speakerdeck.com/presentations/f6512baa144f487699782fc35b8a9d3b/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
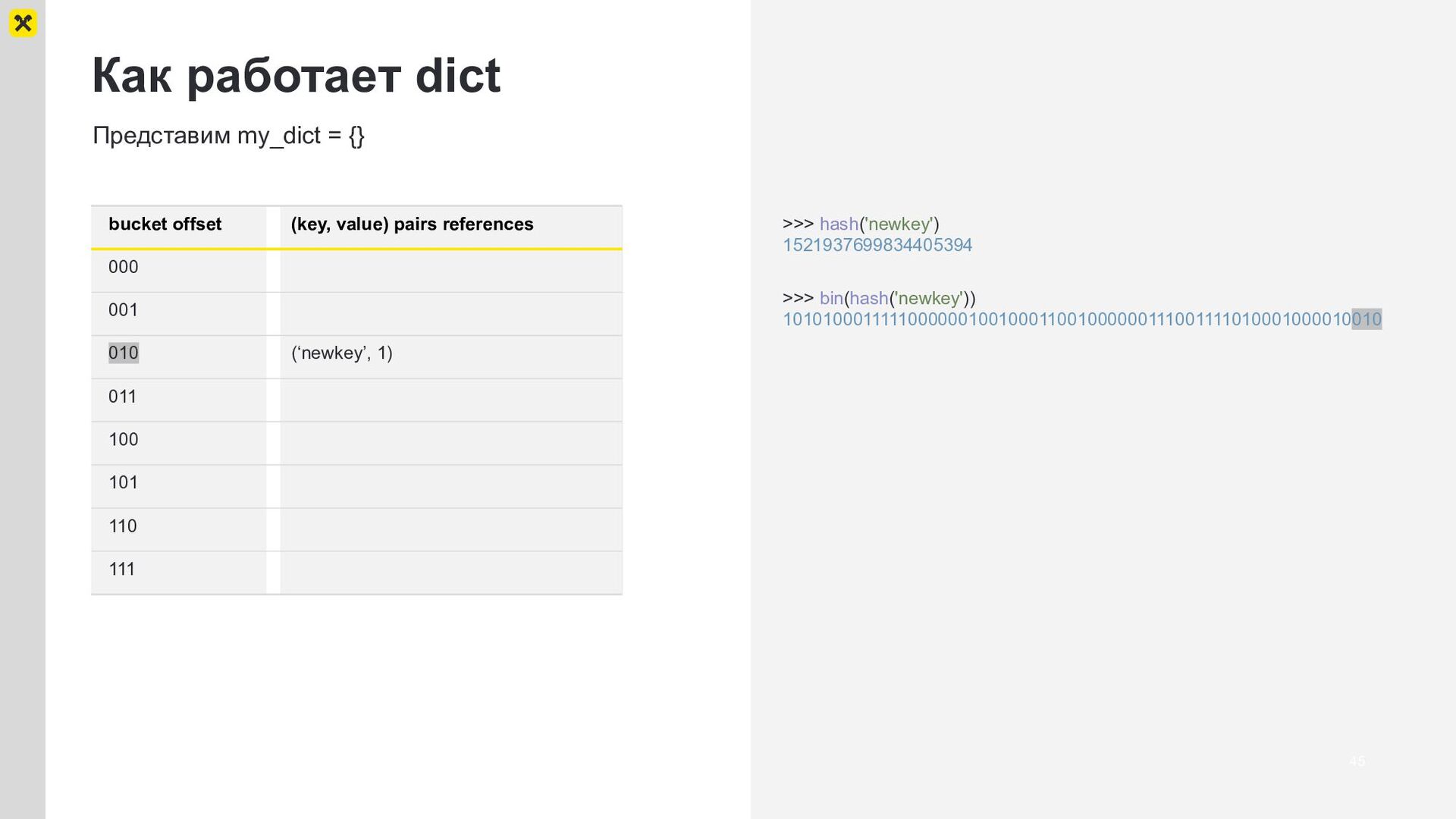{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
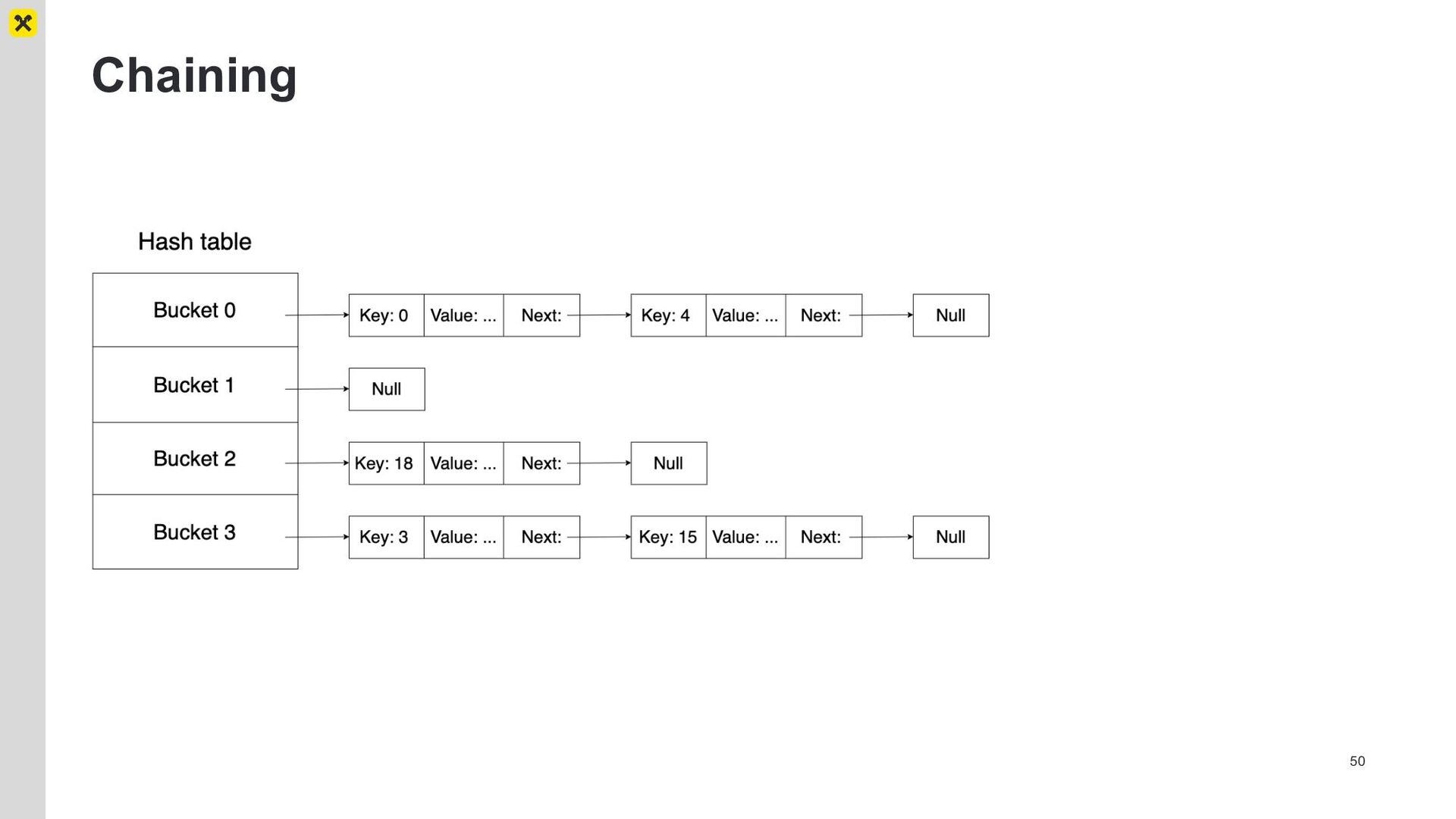{kind=link}
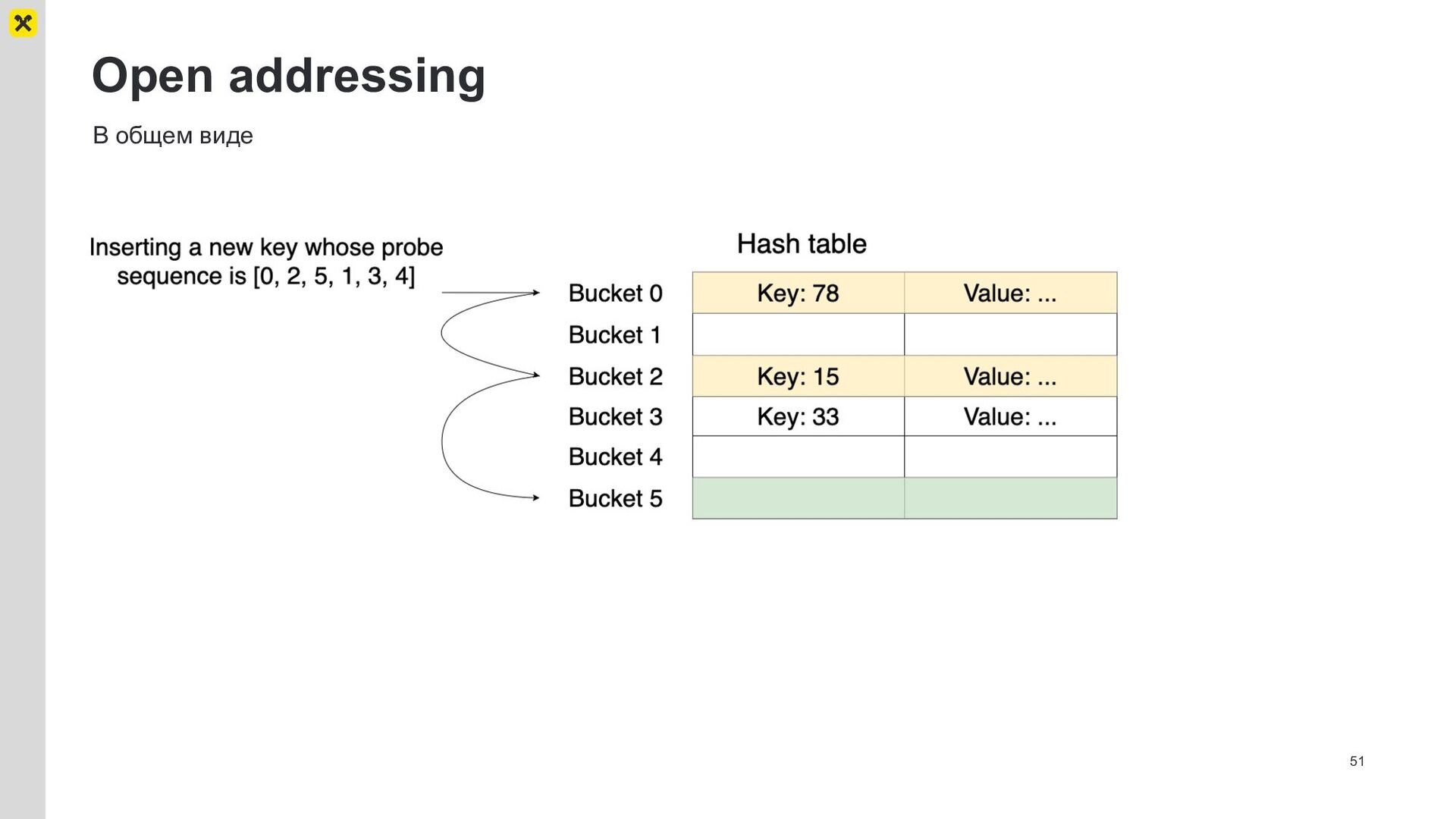{kind=link}
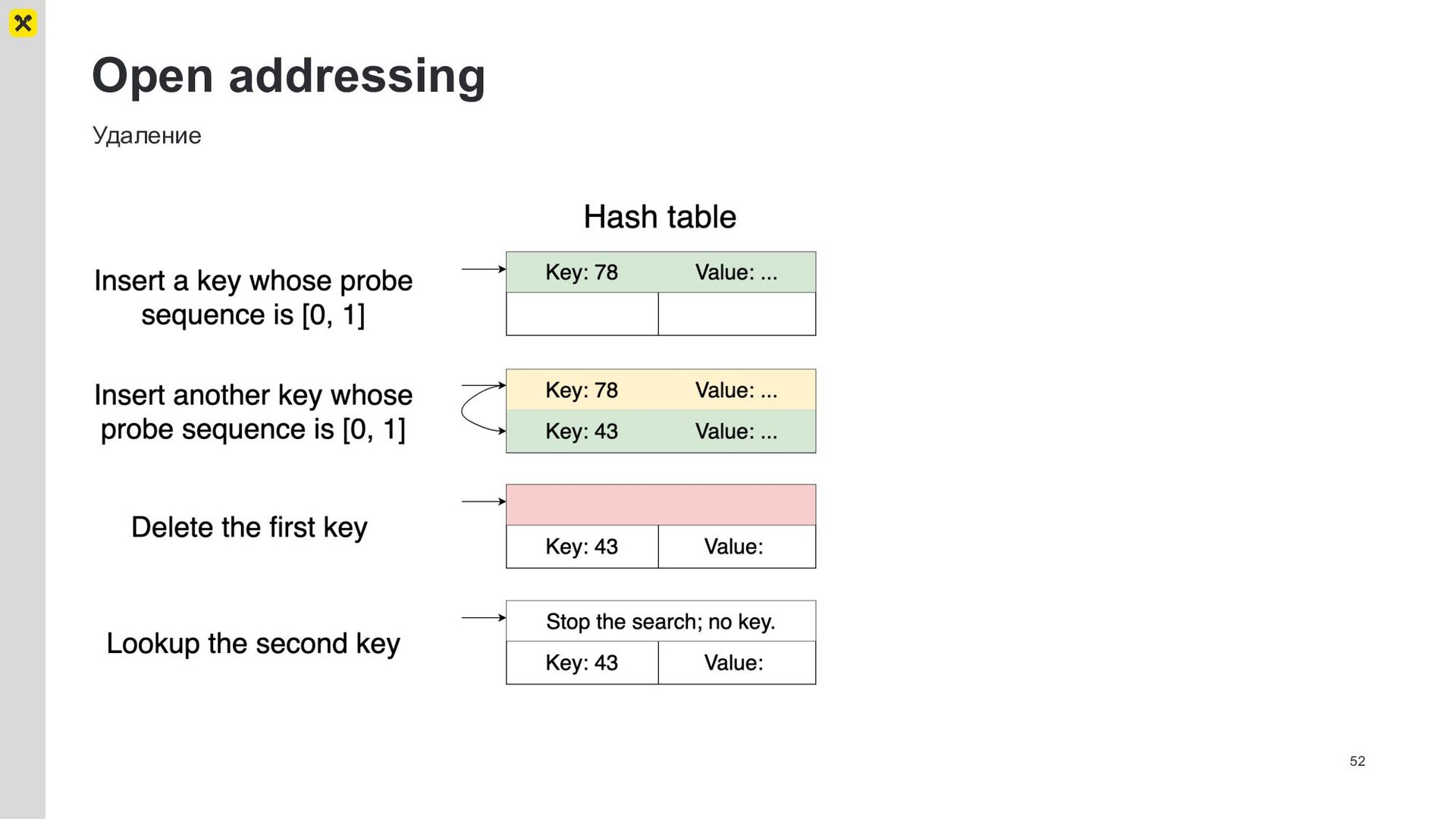{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}