de nuestro cerebro procesa estímulos visuales. • Por eso es mejor gráfica que tabla. • Explorar datos y presentarlos es diferente. • Mostrar los resultados de manera evidente (Fry 2008). 4
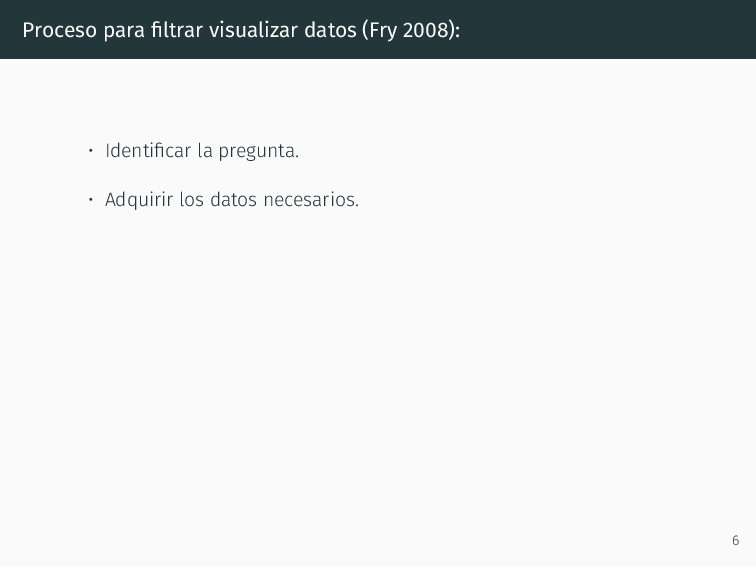
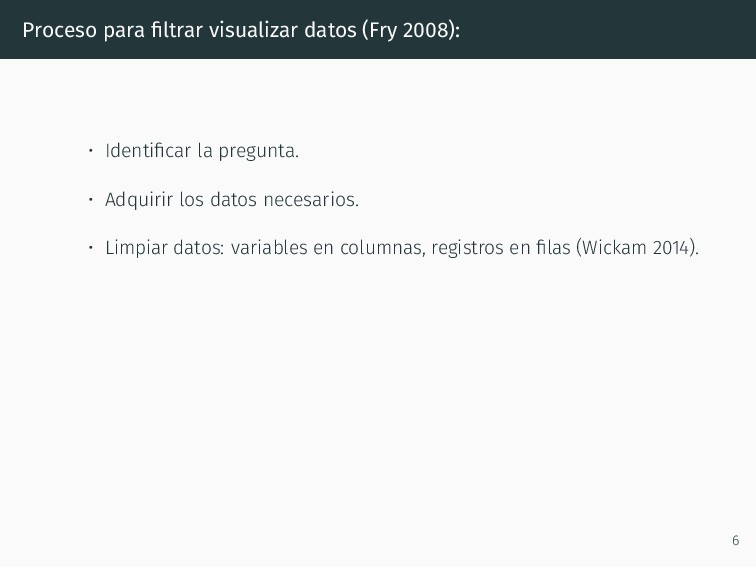
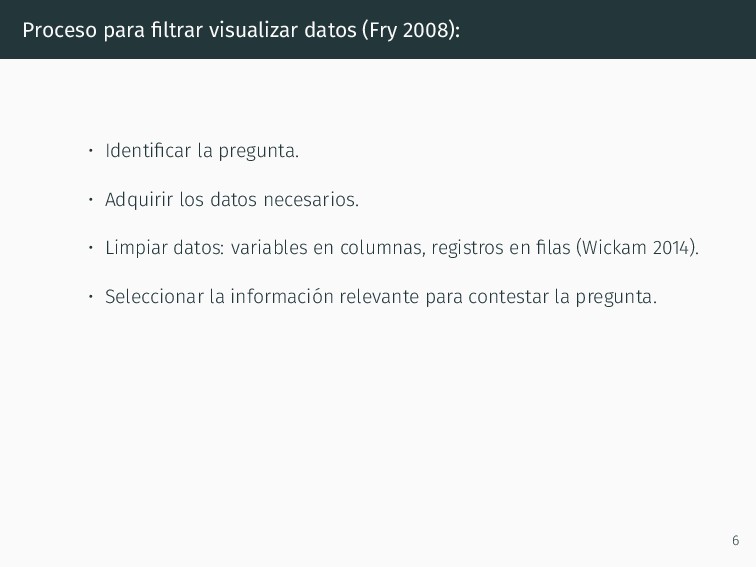
pregunta. • Adquirir los datos necesarios. • Limpiar datos: variables en columnas, registros en filas (Wickam 2014). • Seleccionar la información relevante para contestar la pregunta. 6
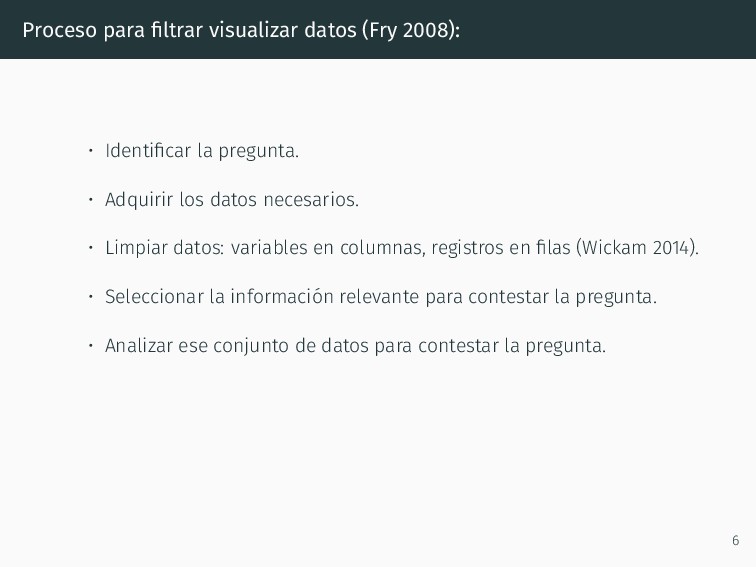
pregunta. • Adquirir los datos necesarios. • Limpiar datos: variables en columnas, registros en filas (Wickam 2014). • Seleccionar la información relevante para contestar la pregunta. • Analizar ese conjunto de datos para contestar la pregunta. 6
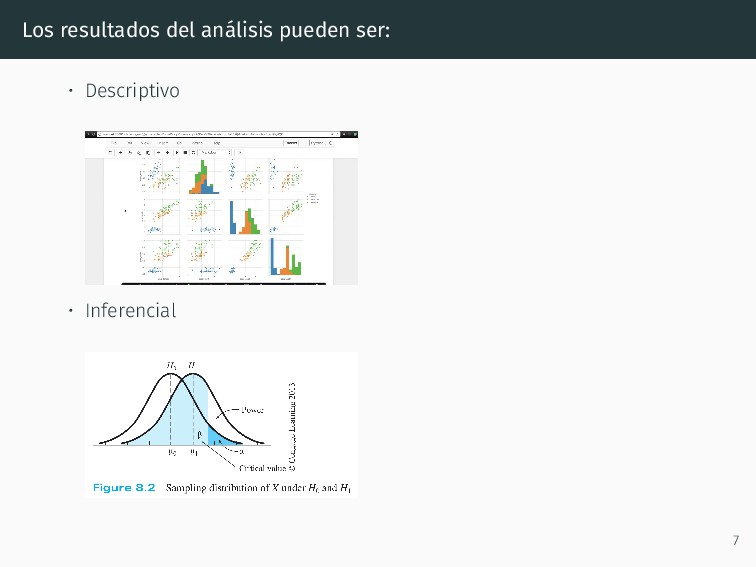
pregunta. • Adquirir los datos necesarios. • Limpiar datos: variables en columnas, registros en filas (Wickam 2014). • Seleccionar la información relevante para contestar la pregunta. • Analizar ese conjunto de datos para contestar la pregunta. • Representar las conclusiones. 6
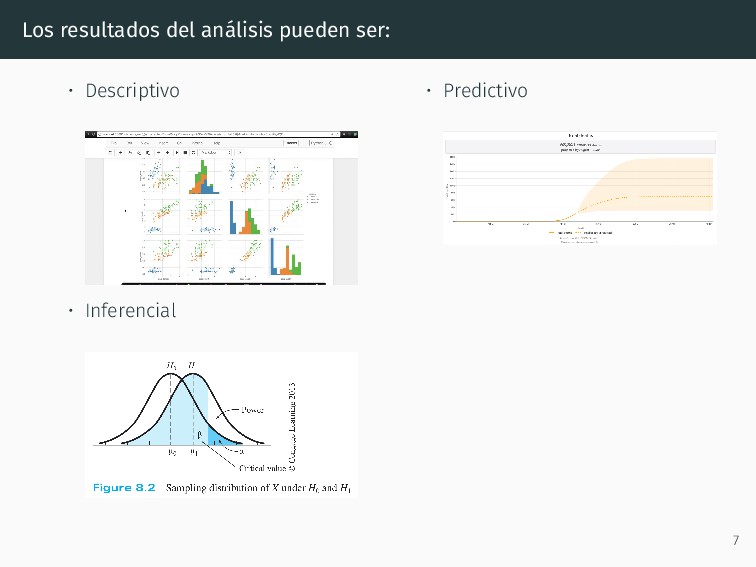
pregunta. • Adquirir los datos necesarios. • Limpiar datos: variables en columnas, registros en filas (Wickam 2014). • Seleccionar la información relevante para contestar la pregunta. • Analizar ese conjunto de datos para contestar la pregunta. • Representar las conclusiones. • Refinar detalles. 6
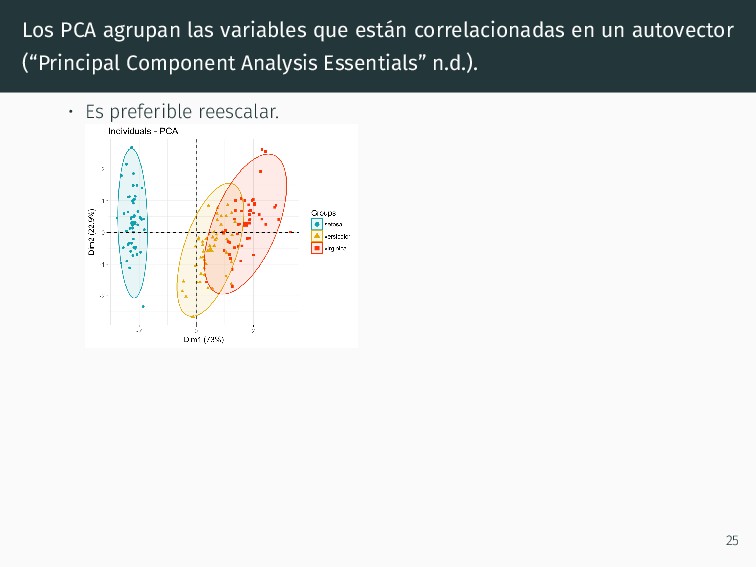
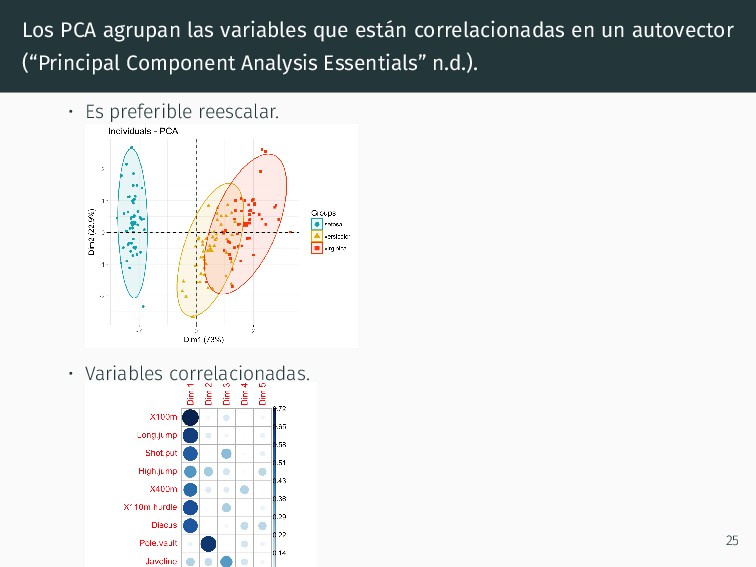
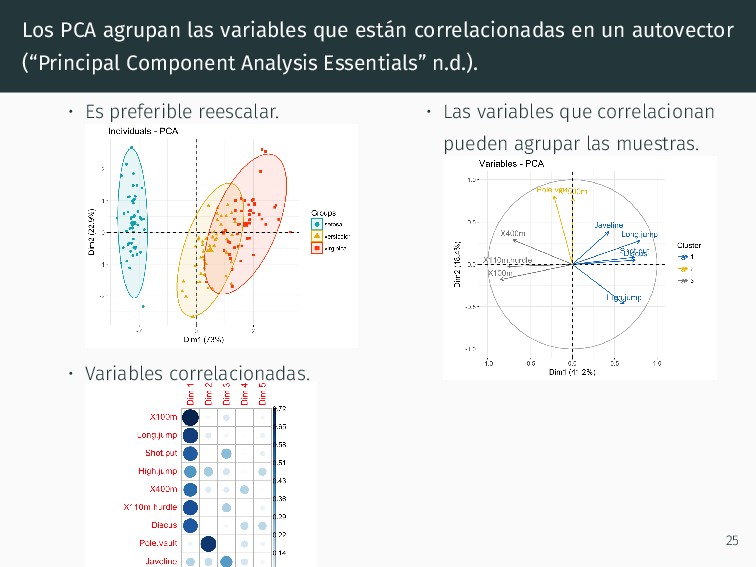
autovector (“Principal Component Analysis Essentials” n.d.). • Es preferible reescalar. • Variables correlacionadas. • Las variables que correlacionan pueden agrupar las muestras. 25
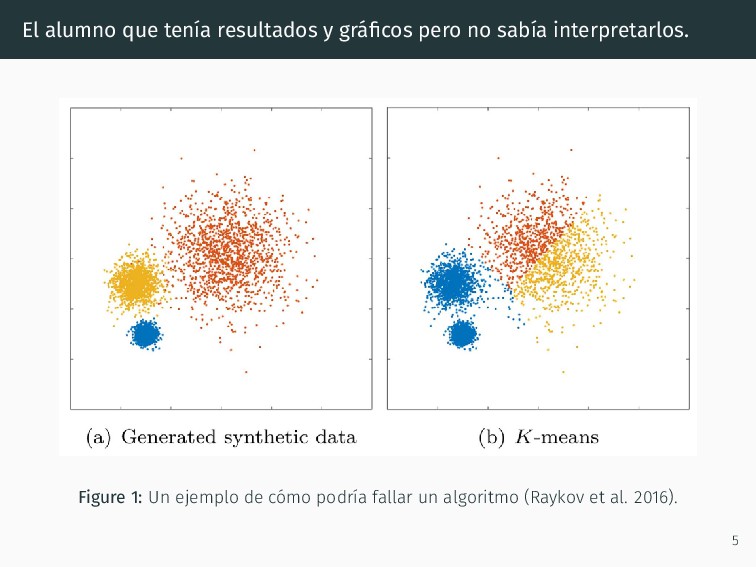
A. Rau, J. Aubert, C. Hennequet-Antier, M. Jeanmougin, N. Servant, C. Keime, et al. 2012. “A Comprehensive Evaluation of Normalization Methods for Illumina High-Throughput RNA Sequencing Data Analysis.” Briefings in Bioinformatics 14 (6): 671–83. https://doi.org/10.1093/bib/bbs046. Fry, Ben. 2008. Visualizing Data. Sebastopol, CA: O’Reilly Media, Inc. “Principal Component Analysis Essentials.” n.d. Accessed June 29, 2020. http://www.sthda.com/english/articles/31-principal-component-methods- in-r-practical-guide/112-pca-principal-component-analysis-essentials/. Raykov, Yordan P., Alexis Boukouvalas, Fahd Baig, and Max A. Little. 2016. “What to Do When K-Means Clustering Fails: A Simple yet Principled Alternative Algorithm.” PLOS ONE 11 (9): e0162259. https://doi.org/10.1371/journal.pone.0162259. 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}