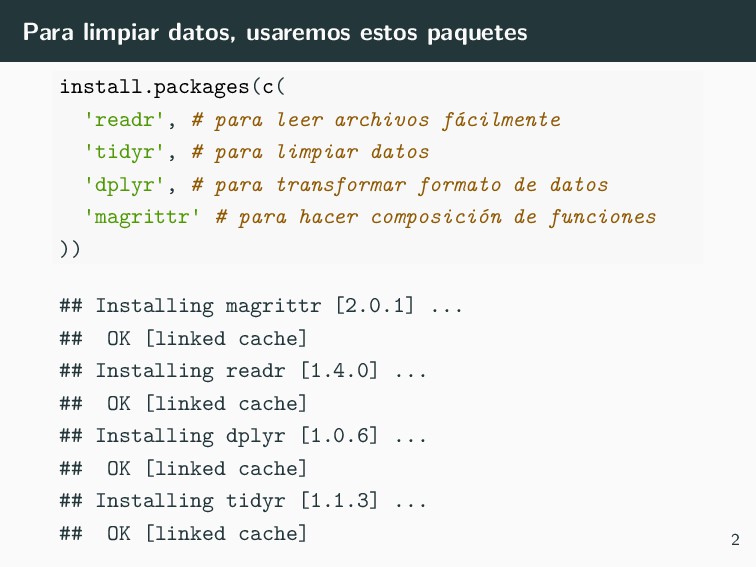
leer archivos fácilmente 'tidyr', # para limpiar datos 'dplyr', # para transformar formato de datos 'magrittr' # para hacer composición de funciones )) ## Installing magrittr [2.0.1] ... ## OK [linked cache] ## Installing readr [1.4.0] ... ## OK [linked cache] ## Installing dplyr [1.0.6] ... ## OK [linked cache] ## Installing tidyr [1.1.3] ... ## OK [linked cache] 2
comando no funciona, # sigue alguno de estos instructivos: # - https://stackoverflow.com/a/54086635 # - https://stat545.com/make-windows.html # system('make') system('make datos docs') 3
datos correctas y organizas bien las cosas, los algoritmos serán casi siempre evidentes. Las estructuras de datos, no los algoritmos, son lo central de la programación.” Rob Pike 7
se preocupan por las es- tructuras de datos y sus relaciones. De hecho, propongo que la diferencia entre un buen y un mal programador, es si considera más importante su código o sus estructuras de datos.” Linus Torvalds 8
primera calculadora mecánica. A.K.A. «La máquina» ”En dos ocasiones me preguntaron «Si pones información errónea en la máquina ¿te dará las respuestas correctas?» No soy capaz de entender qué confusión de ideas podría provocar tal pregunta.” Charles Babbage 9
(Fry 2008) “La ingeniería de características tiene más impacto en la precisión predictiva que cualquier cosa que hagas en la fase de modelado.” Maciek Wasiak 11
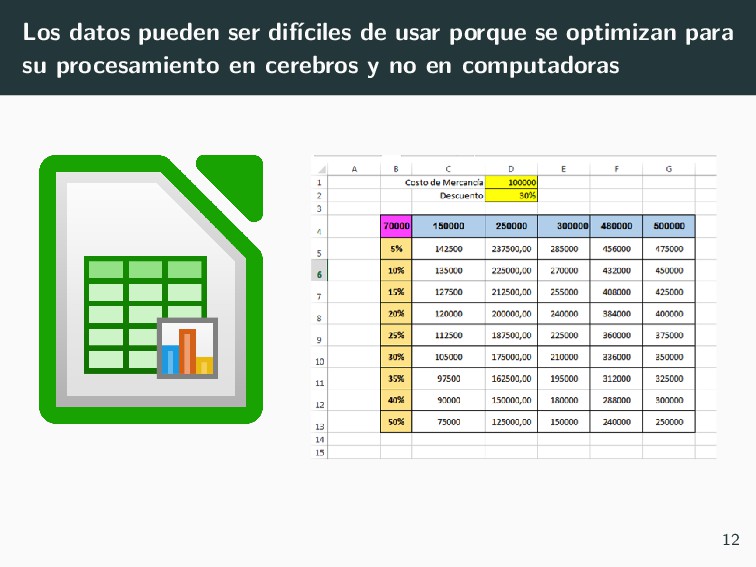
para su almacenamiento y no su análisis • Se codifican para ocupar menos espacio (0,1,2,3,4 < “MALO,” “MEDIOCRE,” “BUENO,” “MUY BUENO,” “EXCELENTE”) 14
para su almacenamiento y no su análisis • Se codifican para ocupar menos espacio (0,1,2,3,4 < “MALO,” “MEDIOCRE,” “BUENO,” “MUY BUENO,” “EXCELENTE”) • Pero se separa los datos de su interpretación (¿1 es ROJO o AZUL?) 14
para su almacenamiento y no su análisis • Se codifican para ocupar menos espacio (0,1,2,3,4 < “MALO,” “MEDIOCRE,” “BUENO,” “MUY BUENO,” “EXCELENTE”) • Pero se separa los datos de su interpretación (¿1 es ROJO o AZUL?) • Se separan para hacer imposible la inconsistencia en los datos. 14
para su almacenamiento y no su análisis • Se codifican para ocupar menos espacio (0,1,2,3,4 < “MALO,” “MEDIOCRE,” “BUENO,” “MUY BUENO,” “EXCELENTE”) • Pero se separa los datos de su interpretación (¿1 es ROJO o AZUL?) • Se separan para hacer imposible la inconsistencia en los datos. • Pero se hace costoso unirlos. 14
para su almacenamiento y no su análisis • Se codifican para ocupar menos espacio (0,1,2,3,4 < “MALO,” “MEDIOCRE,” “BUENO,” “MUY BUENO,” “EXCELENTE”) • Pero se separa los datos de su interpretación (¿1 es ROJO o AZUL?) • Se separan para hacer imposible la inconsistencia en los datos. • Pero se hace costoso unirlos. • No se establece un buen sistema para exportar los datos a su formato correcto. 14
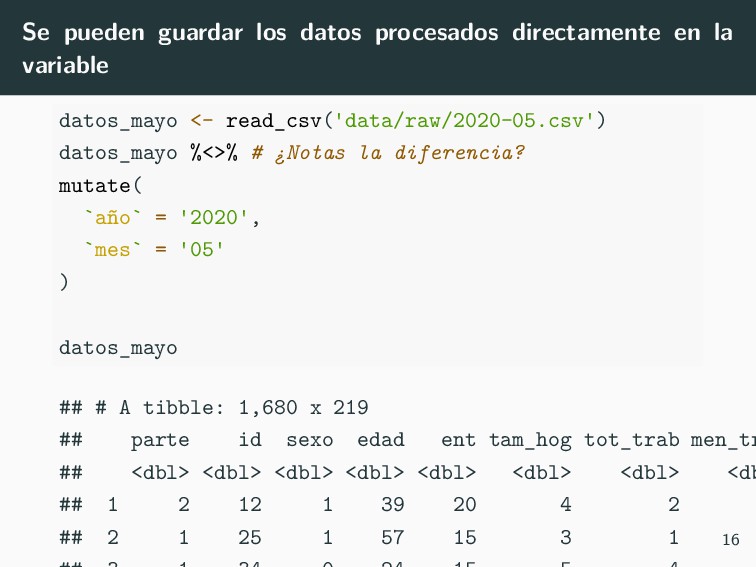
junto de datos Supongamos que tengo 2 archivos con información similar pero de diferente fecha. datos_abril <- read_csv('data/raw/2020-04.csv') datos_abril %>% # Mucho ojo, este es el paquete magrittr mutate( `año` = '2020', `mes` = '04' ) ## # A tibble: 833 x 93 ## id sexo edad ent p1_riesgo p2_riesgo p3_riesgo ## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> ## 1 1 1 47 1 1 1 2 ## 2 2 0 42 11 2 2 1 15
de ENCOVID Hoja de comandos útiles para limpiar datos en R Ejemplo de cómo limpiar datos desordenados Hoja de comandos útiles para transformar formato de datos Hoja de comandos útiles para importar datos Bonus: Una guía para organizar tus proyectos de ciencia de datos Un libro de acceso abierto acerca de la visualización 26
R que usan composición de funciones # con una gramática de análisis y visualización 'tidyverse' ) ## Installing tidyverse [1.3.1] ... ## OK [linked cache] 27
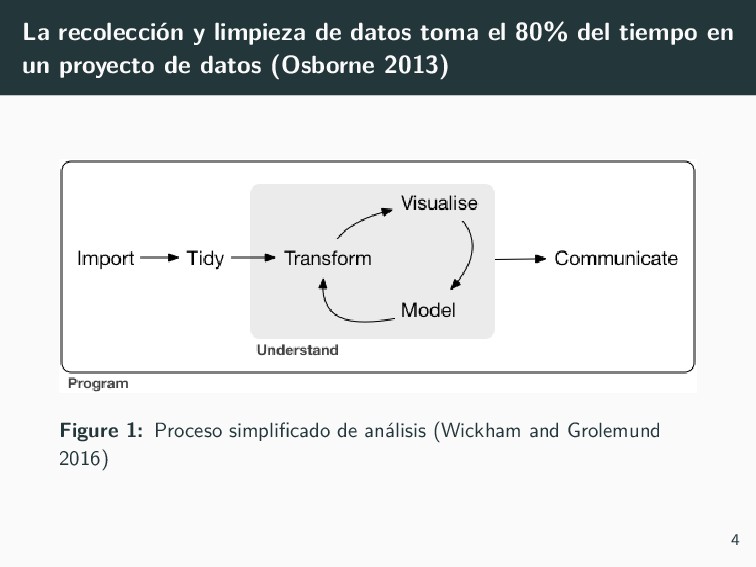
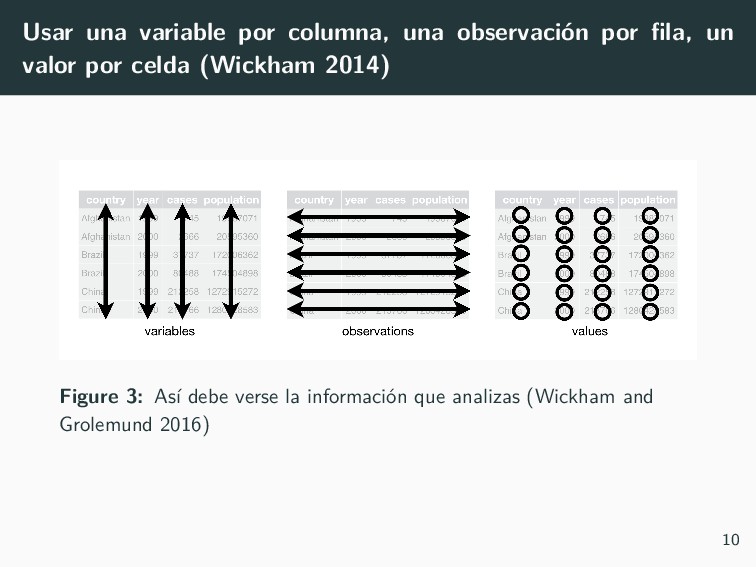
Media, Inc. Osborne, Jason W. 2013. Best Practices in Data Cleaning: A Complete Guide to Everything You Need to Do Before and After Collecting Your Data. Thousand Oaks, Calif: SAGE. Wickham, Hadley. 2014. “Tidy Data.” Journal of Statistical Software 59 (10). https://doi.org/10.18637/jss.v059.i10. Wickham, Hadley, and Garrett Grolemund. 2016. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. First edition. Sebastopol, CA: O’Reilly. 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}