storage costs are more cost-effective than managed tables. 1GB ~ AWS S3 On-demand Price $25.00 per TB / per month ($USD) [ AWS Tokyo First 50 TB / Month] Snowflake on AWS Tokyo Storage Price $25.00 per TB / per month ($USD) Comparison of Active Storage ( Time travel and failsafes are not included ) In Large data sizes, Iceberg is about 1%~30% cost-effective than the other 100GB (0.1TB) ~
Snowflake managed Iceberg Table, the FLOAT type is written as 32-bit single precision in the file according to the iceberg FLOAT type specification. 32-bit floating-point number (float): Because fewer bits are used, the range of numbers that can be stored is narrower and the precision is limited to approximately seven decimal digits. Snowflake Managed Table In the case of Snowflake Table, the stored FLOAT type is always treated as 64-bit double precision. 64-bit floating-point number (double): Uses more bits (especially the exponent and mantissa parts) to represent numbers, so a very wide range of numbers can be stored with a decimal precision of about 15 to 16 digits.
Internal Marketplace Catalog of Data Products Data Source Domain per Account Organization Account Zero Data Account Snowflake Data Cloud 3rd Party Analytics Service Access External Iceberg Table from Snowflake Access Snowflake Managed Iceberg Table from Spark Data Subscriber Comsumer Provide Data Products Subscribe Data Products Organization Account Zero Data Account Domain Self-Serviceを基本に高い柔軟性を 確保しつつ、適切なガバナンスを 通して Data ROIの最大化に繋げる
{kind=link}
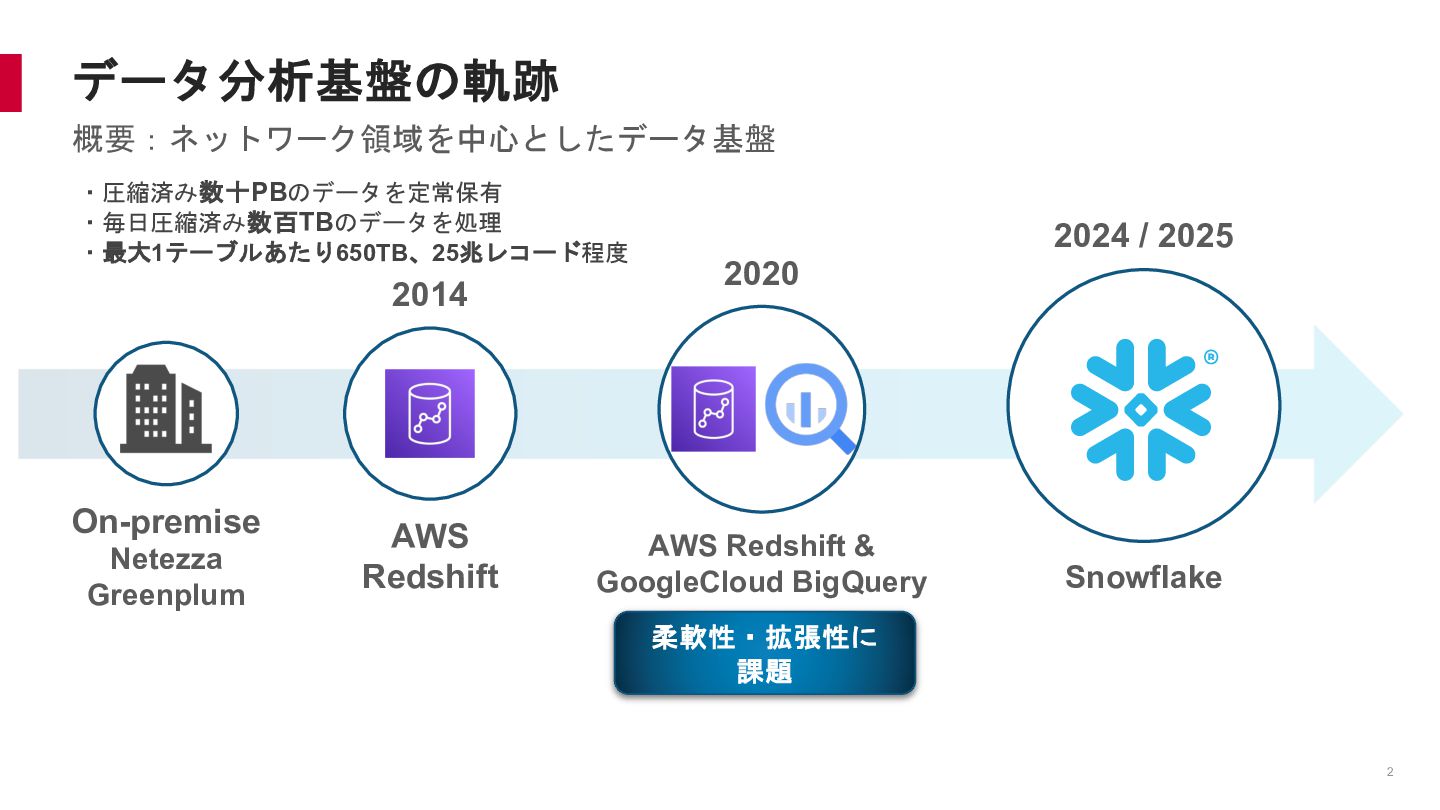{kind=link}
{kind=link}
{kind=link}
{kind=link}
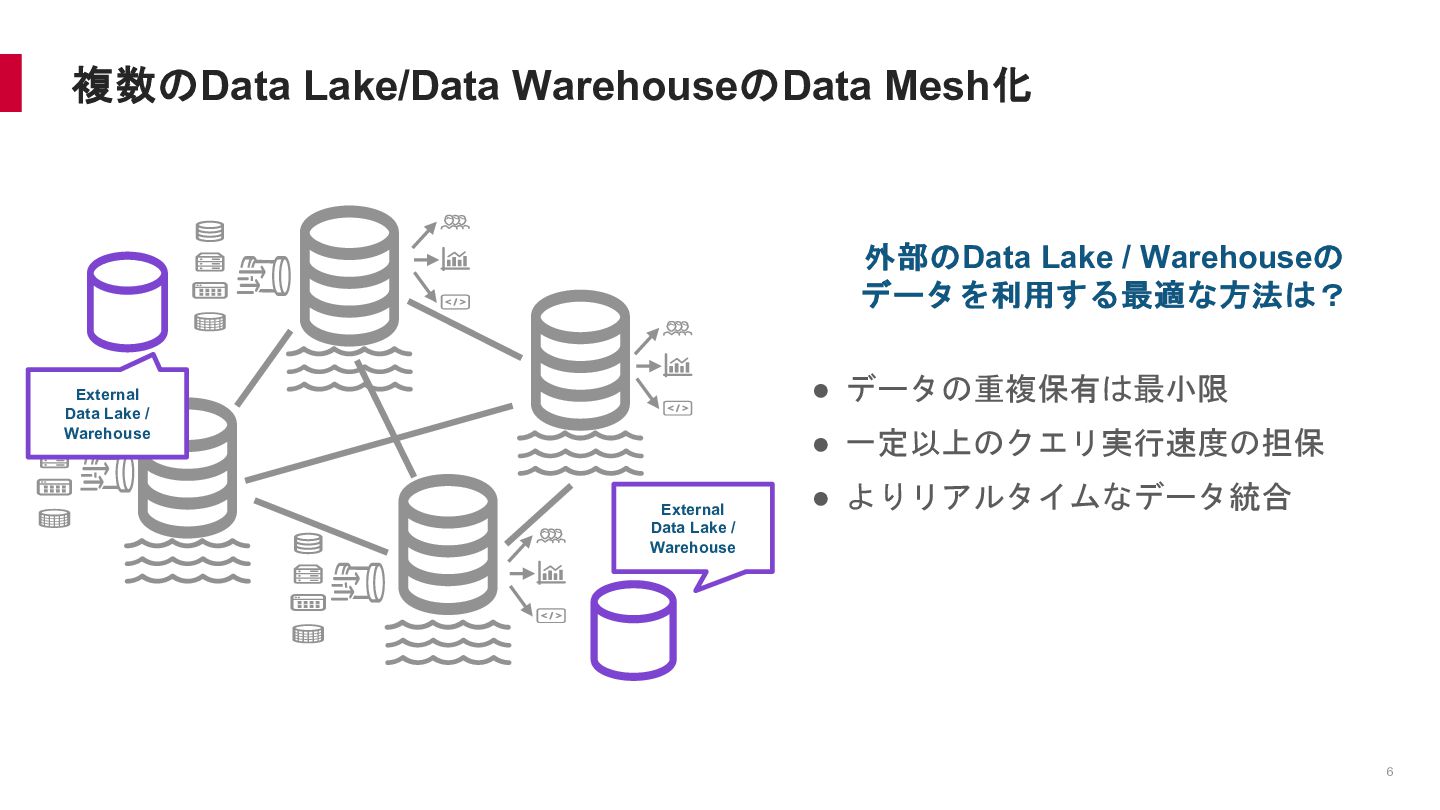{kind=link}
{kind=link}
{kind=link}
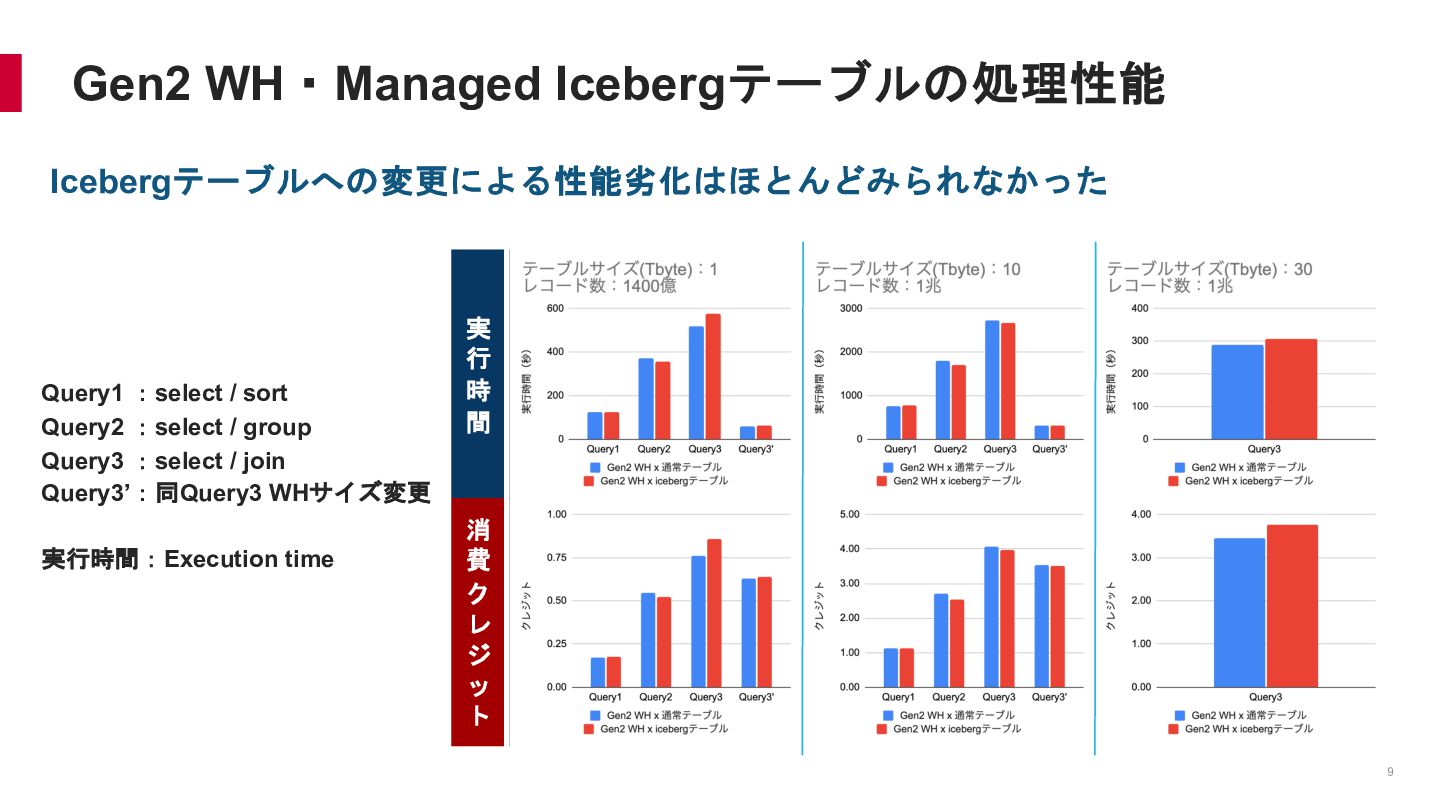{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}