Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Join Algorithm in Spark
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
yabooun
June 28, 2022
Technology
120
0
Share
Join Algorithm in Spark
Sparkを扱う上で最も重要な概念のひとつであるJoinについて、どういったアルゴリズムが使われているのかを解説します。
yabooun
June 28, 2022
More Decks by yabooun
See All by yabooun
データ分析基盤の要件分析の話(202201_JEDAI)
yabooun
1
1.1k
Other Decks in Technology
See All in Technology
美味しいスイスチーズを作ろう🧀🐭
taigamikami
1
230
AI Testing Talks: Challenges of Applying AI in Software Testing: From Hype to Practical Use
exactpro
PRO
1
120
Diagnosing performance problems without the guesswork
elenatanasoiu
0
160
EventBridge Connection
_kensh
2
300
Amazon Bedrock AgentCore ワークショップ JAWS UG TOHOKU / amazon-bedrock-agentcore-workshop-jawsug-tohoku-2026
gawa
5
170
「気づいたら仕事が終わっている」バクラクAIエージェント本番運用の裏側 / layerx-bakuraku-aie2026
yuya4
18
9.9k
生成 AI × MCP で切り拓く次世代 SRE!自律型運用への挑戦と開発者体験の進化
_awache
0
150
地元にいないローカルオーガナイザーの立ち回り
uvb_76
1
470
Ruby::Boxでできること、Refinementsでできること
joker1007
3
390
ルールやカスタム機能、どう使う?理想の出力を引き出すために今知りたいIBM Bob 5つの機能
muehara
1
330
サイバーセキュリティ概論 / Introduction to Cybersecurity
ks91
PRO
0
150
「嘘をつくテスト」の失敗例から学ぶ 良いテストコード #frontend_phpcon_do
asumikam
0
230
Featured
See All Featured
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
160
Mind Mapping
helmedeiros
PRO
1
230
Building the Perfect Custom Keyboard
takai
2
780
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
290
Code Reviewing Like a Champion
maltzj
528
40k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
200
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
1
150
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
HDC tutorial
michielstock
2
690
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
200
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Transcript
Join Algorithm in Spark 2022/06/28 @yabooun
自己紹介 藪本 晃輔 @yabooun 株式会社ジオロジック CTO 趣味: 登山、ピアノ、日本酒 晴れてると、空ばかり眺めてしまうので、今週末山に行ってきます。
Joinとは • 複数のテーブルを一定のルールに基づいて結合する処理 • SQLの基本的な構文のひとつ • LEFT JOIN, RIGHT JOIN,
INNER JOIN, CROSS JOIN, LEFT LATERAL JOIN, ・・・ • サブクエリも全部JOINで書ける • ただし、同じJOINでも、データ量やクエリによって違うアルゴリズムが使われる ◦ 使われるアルゴリズムは基本的に処理系が決める ◦ アルゴリズムによって全然速さが違う • RDBMSやHadoop/Spark等のビッグデータ系のシステムでは別のアルゴリズム ◦ ビッグデータ系はRDBMSより多くのアルゴリズムがある • 意外と奥が深いJOIN
RDBMSにおけるJOIN 1. Hash Join 2. Sort Merge Join 3. Nested
Loop Join
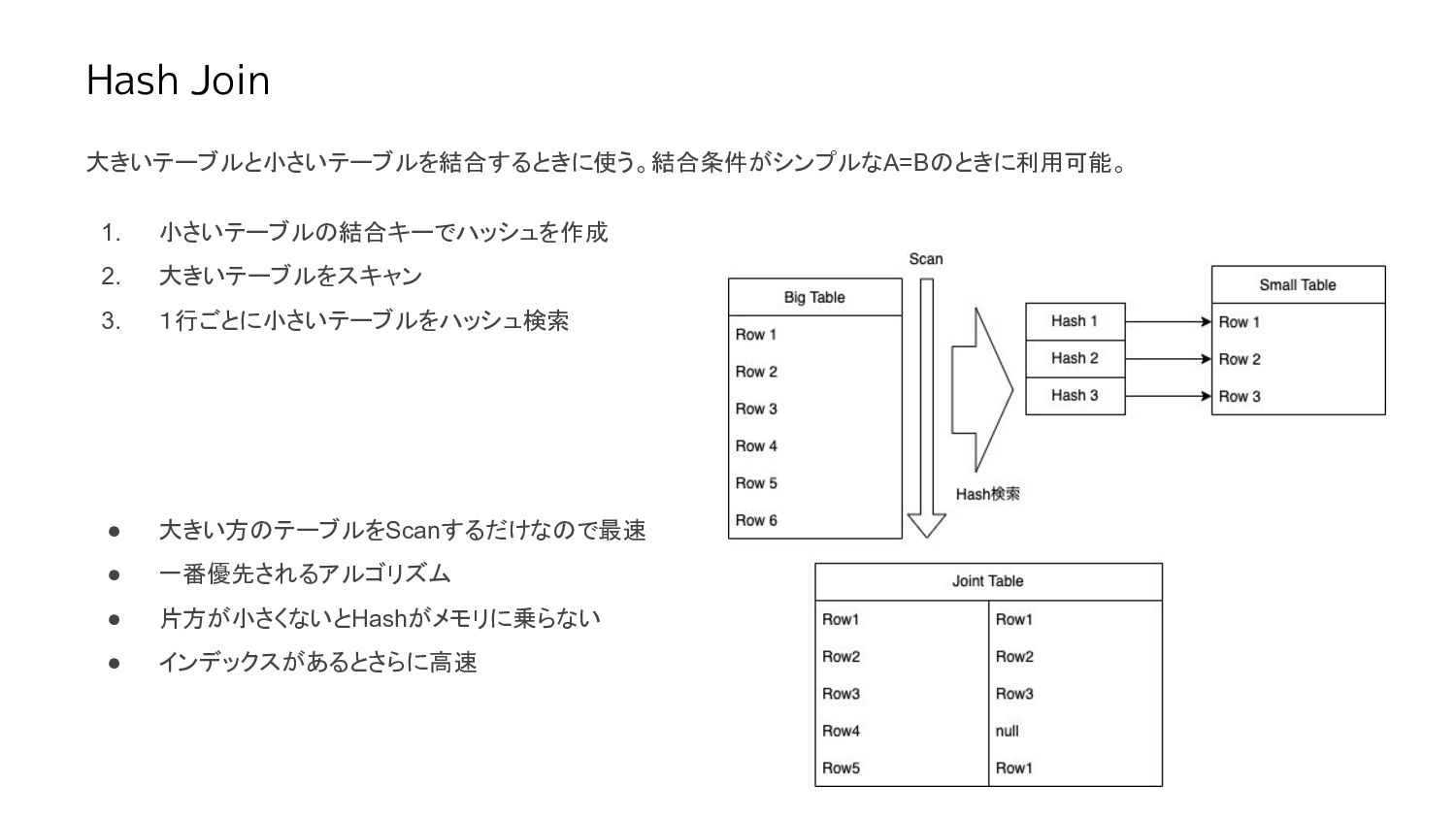
Hash Join 大きいテーブルと小さいテーブルを結合するときに使う。結合条件がシンプルなA=Bのときに利用可能。 1. 小さいテーブルの結合キーでハッシュを作成 2. 大きいテーブルをスキャン 3. 1行ごとに小さいテーブルをハッシュ検索 •
大きい方のテーブルをScanするだけなので最速 • 一番優先されるアルゴリズム • 片方が小さくないとHashがメモリに乗らない • インデックスがあるとさらに高速
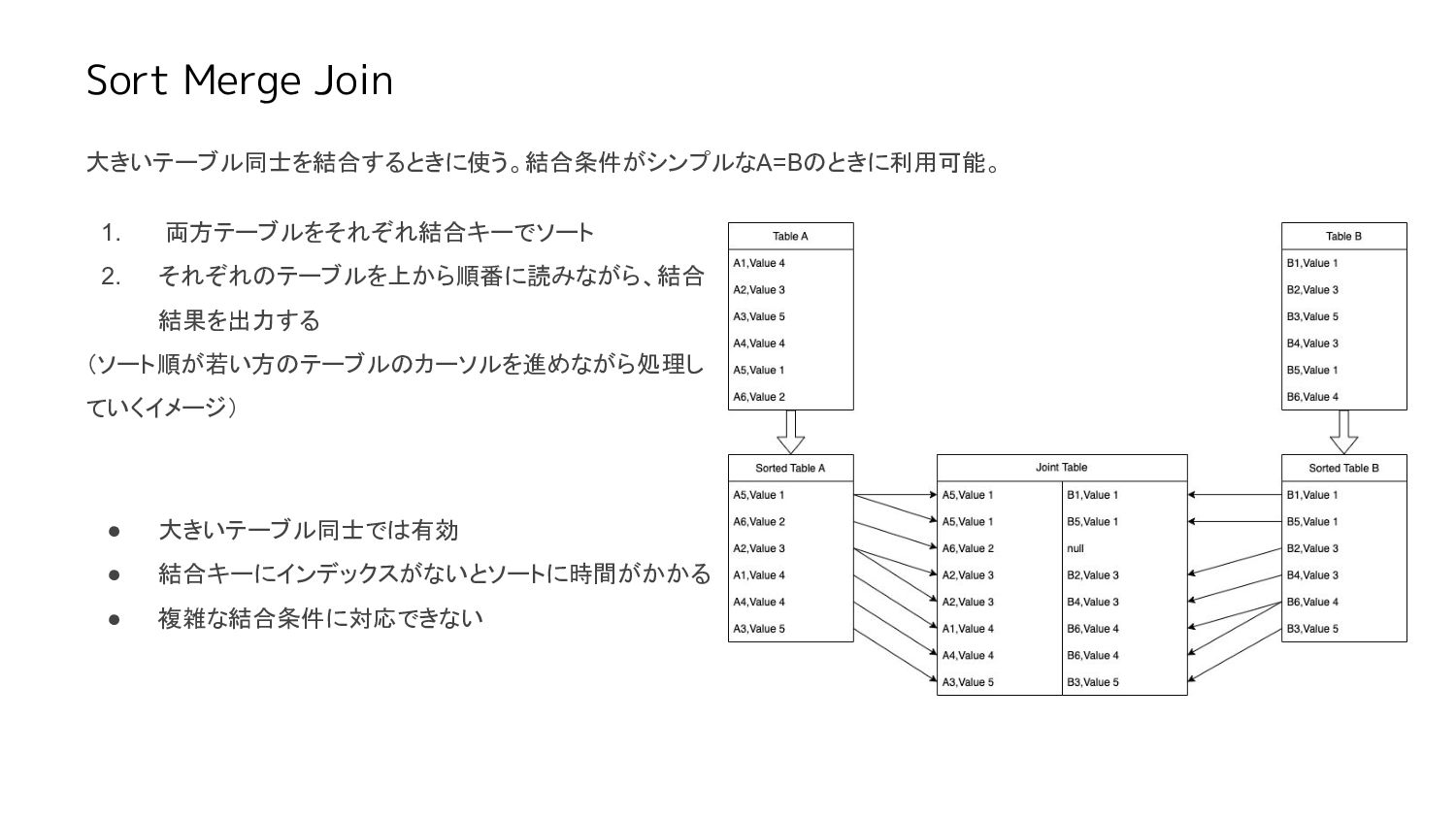
Sort Merge Join 大きいテーブル同士を結合するときに使う。結合条件がシンプルなA=Bのときに利用可能。 1. 両方テーブルをそれぞれ結合キーでソート 2. それぞれのテーブルを上から順番に読みながら、結合 結果を出力する (ソート順が若い方のテーブルのカーソルを進めながら処理し
ていくイメージ) • 大きいテーブル同士では有効 • 結合キーにインデックスがないとソートに時間がかかる • 複雑な結合条件に対応できない
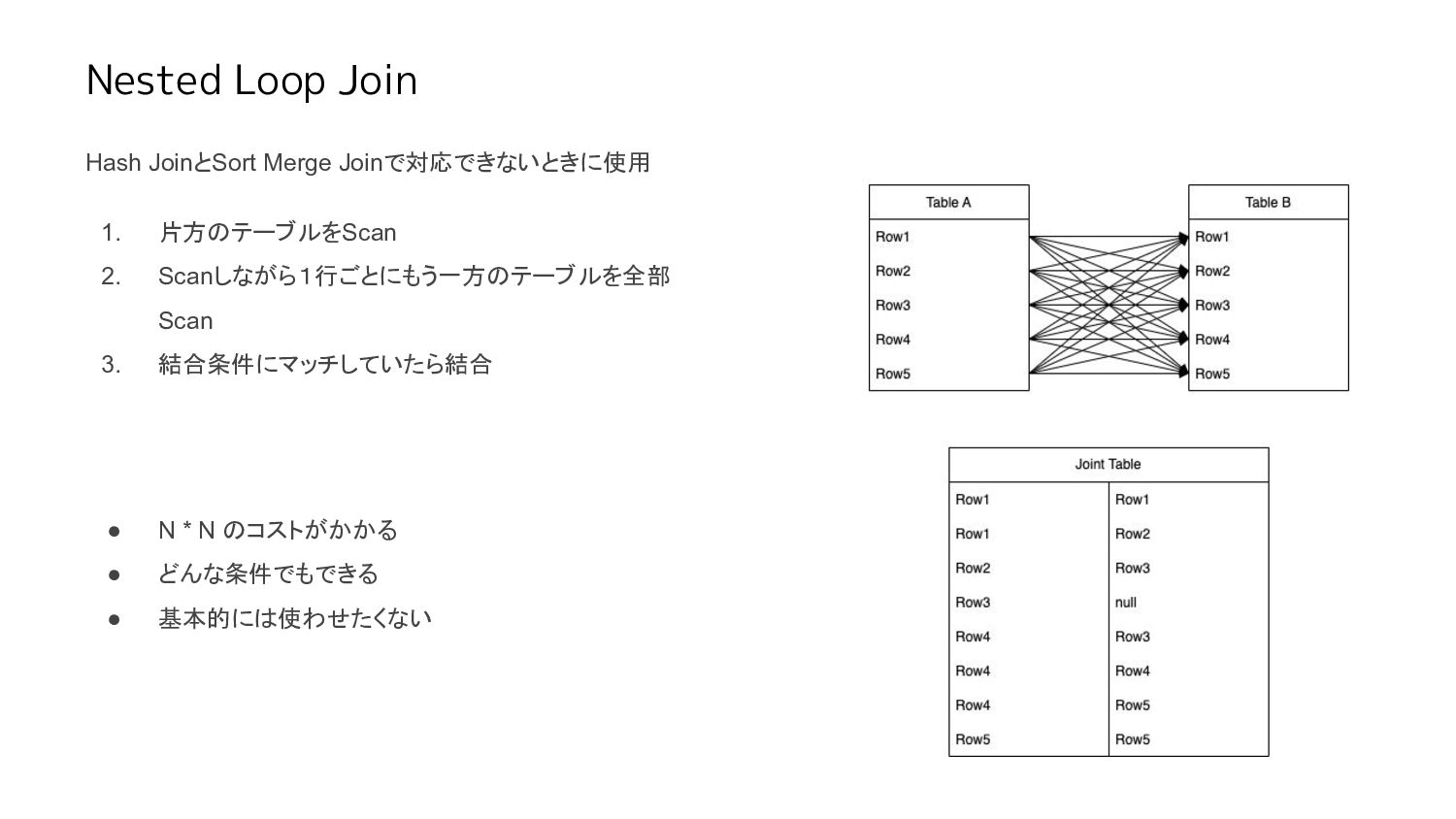
Nested Loop Join Hash JoinとSort Merge Joinで対応できないときに使用 1. 片方のテーブルをScan 2.
Scanしながら1行ごとにもう一方のテーブルを全部 Scan 3. 結合条件にマッチしていたら結合 • N * N のコストがかかる • どんな条件でもできる • 基本的には使わせたくない
RDBMSにおけるJOIN • 基本的にはHash Joinが使われるようにしよう • せめてSort Merge Joinが使われるようにしよう • Joinのキーはインデックス登録しておこう
• 文字列結合したり変な条件で Joinすると遅い
SparkにおけるJOIN • Sparkでもほとんど似た考え方の Joinが使われる • 複数のノードからなるクラスタで実行されるため、同じアルゴリズムでも複数パターン • アルゴリズムひとつ変わると、クエリの速度が 1,000倍くらい余裕で変わる
SparkにおけるJOIN 1. Broadcast Hash Join 2. Shuffle Hash Join 3.
Shuffle Sort Merge Join 4. Broadcast Nested Loop Join 5. Cartesian Join
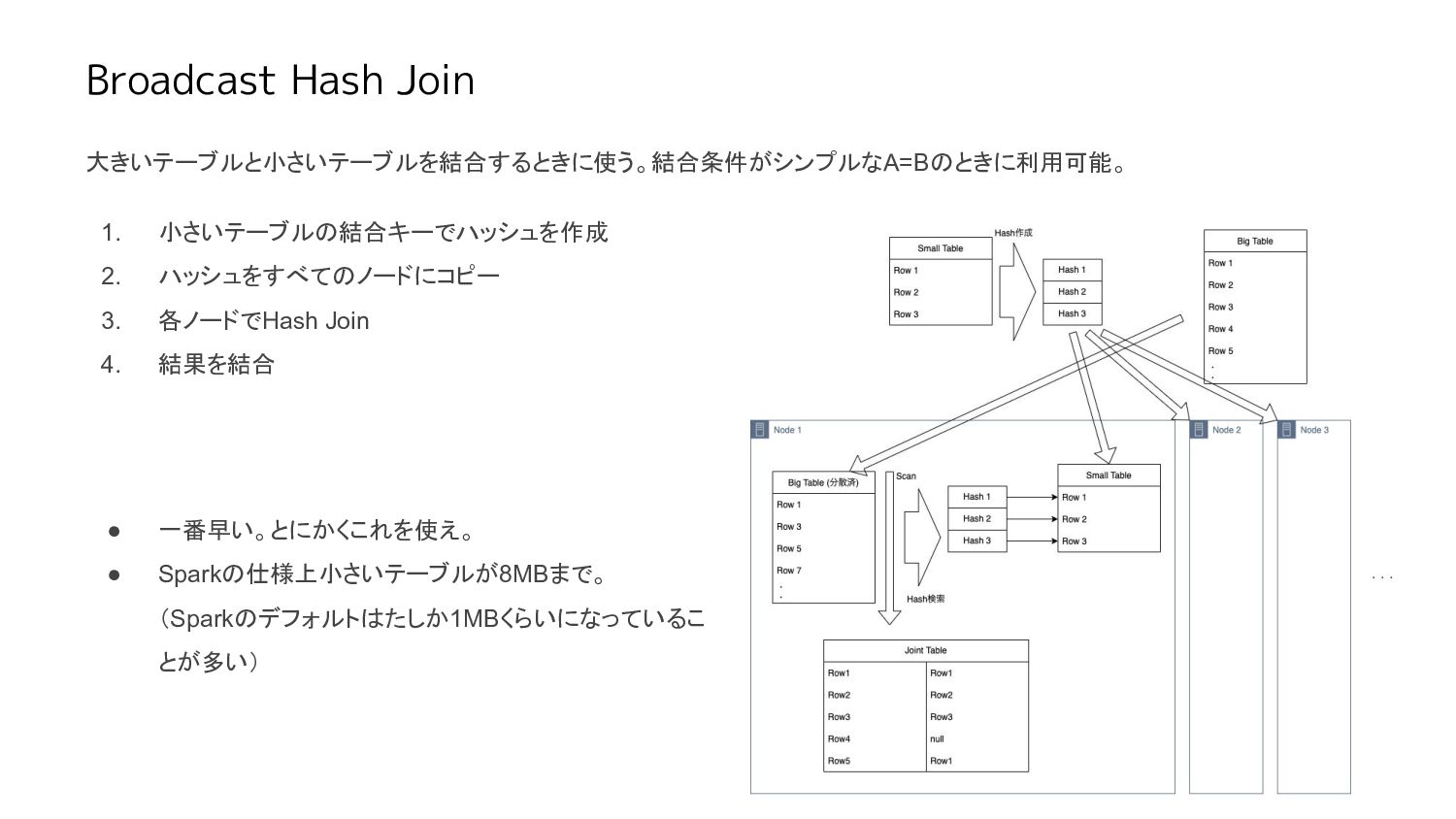
Broadcast Hash Join 大きいテーブルと小さいテーブルを結合するときに使う。結合条件がシンプルなA=Bのときに利用可能。 1. 小さいテーブルの結合キーでハッシュを作成 2. ハッシュをすべてのノードにコピー 3. 各ノードでHash
Join 4. 結果を結合 • 一番早い。とにかくこれを使え。 • Sparkの仕様上小さいテーブルが8MBまで。 (Sparkのデフォルトはたしか1MBくらいになっているこ とが多い)
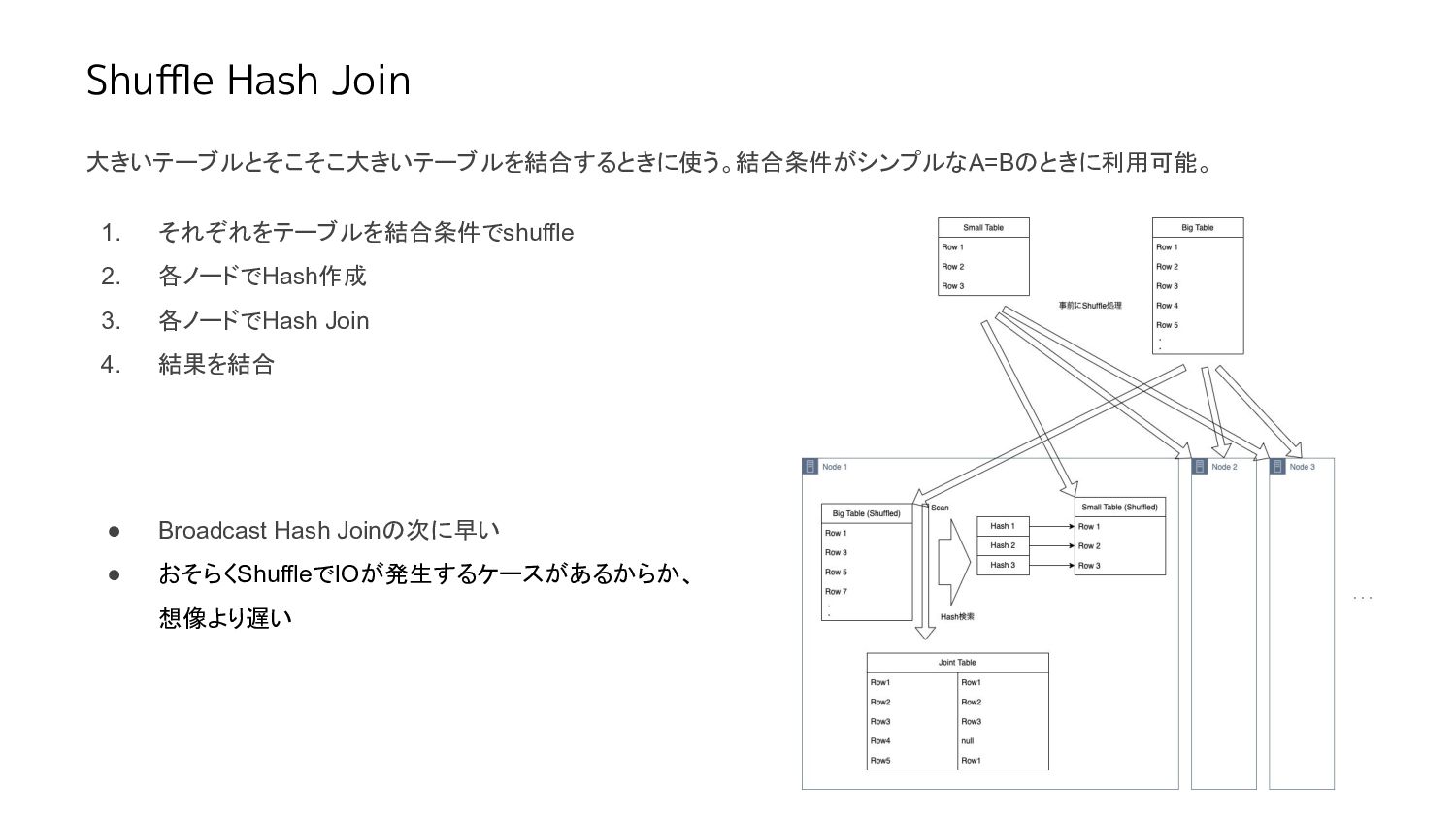
Shuffle Hash Join 大きいテーブルとそこそこ大きいテーブルを結合するときに使う。結合条件がシンプルなA=Bのときに利用可能。 1. それぞれをテーブルを結合条件でshuffle 2. 各ノードでHash作成 3. 各ノードでHash
Join 4. 結果を結合 • Broadcast Hash Joinの次に早い • おそらくShuffleでIOが発生するケースがあるからか、 想像より遅い
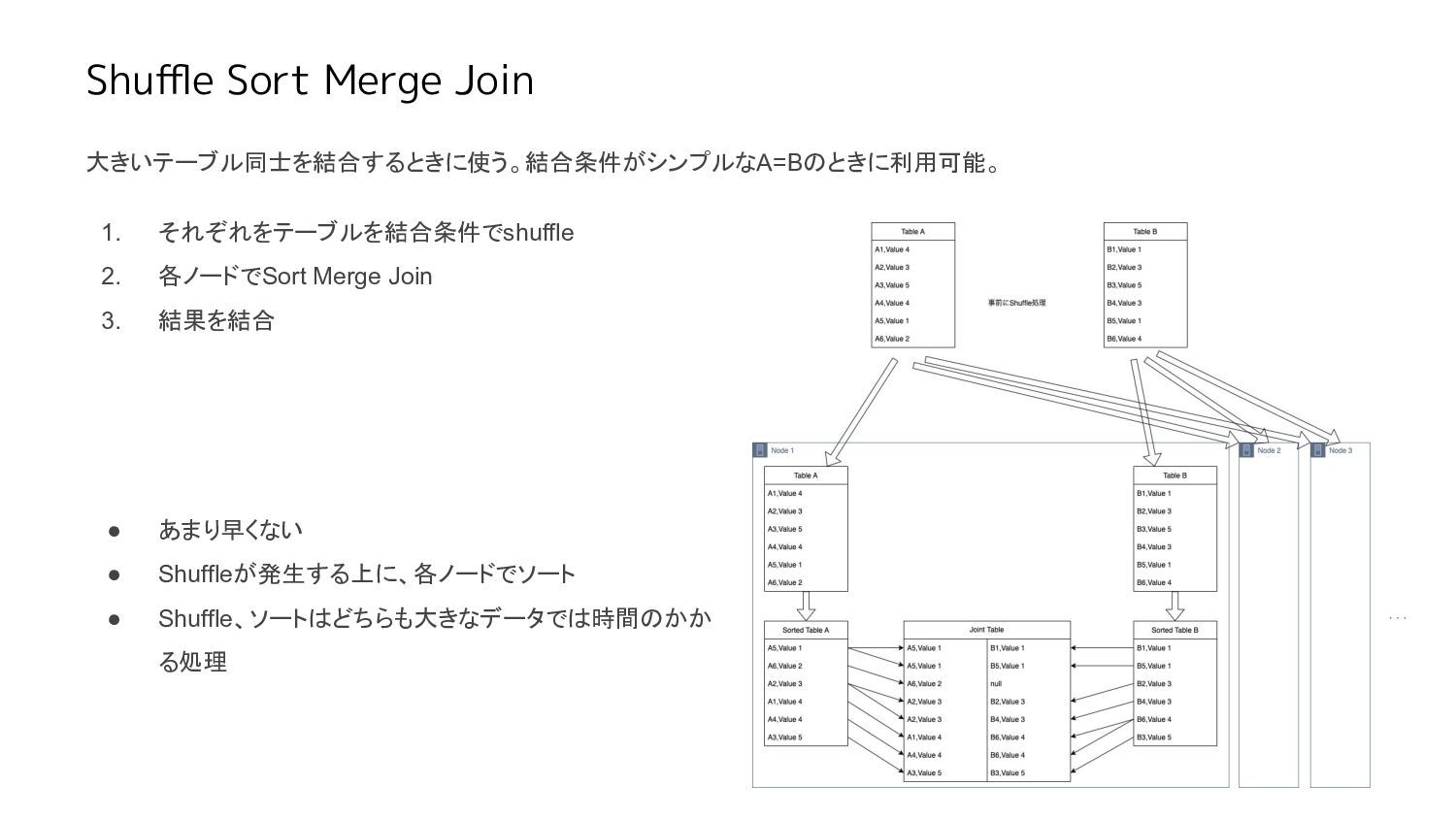
Shuffle Sort Merge Join 大きいテーブル同士を結合するときに使う。結合条件がシンプルなA=Bのときに利用可能。 1. それぞれをテーブルを結合条件でshuffle 2. 各ノードでSort Merge
Join 3. 結果を結合 • あまり早くない • Shuffleが発生する上に、各ノードでソート • Shuffle、ソートはどちらも大きなデータでは時間のかか る処理
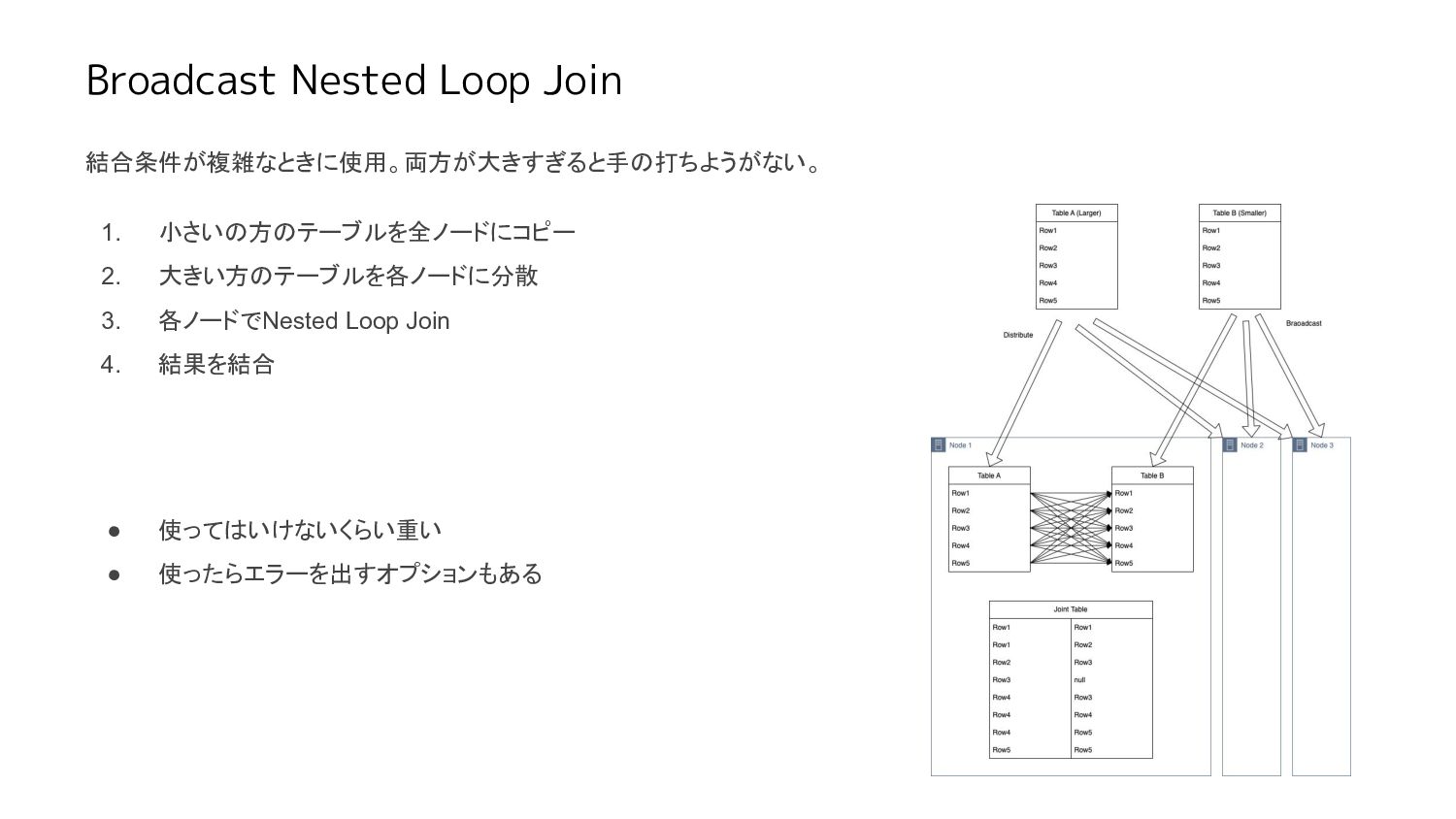
Broadcast Nested Loop Join 結合条件が複雑なときに使用。両方が大きすぎると手の打ちようがない。 1. 小さいの方のテーブルを全ノードにコピー 2. 大きい方のテーブルを各ノードに分散 3.
各ノードでNested Loop Join 4. 結果を結合 • 使ってはいけないくらい重い • 使ったらエラーを出すオプションもある
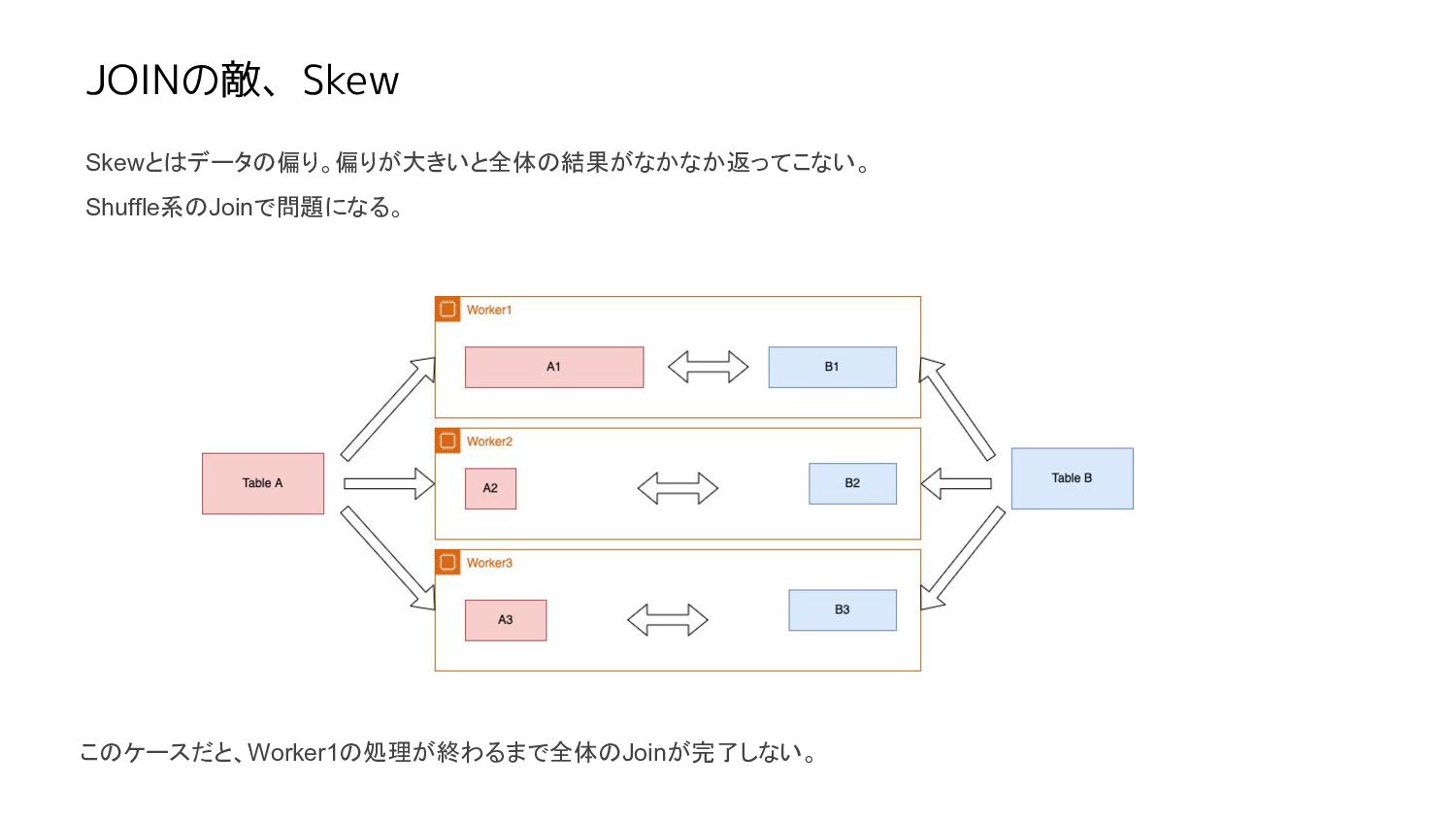
JOINの敵、Skew Skewとはデータの偏り。偏りが大きいと全体の結果がなかなか返ってこない。 Shuffle系のJoinで問題になる。 このケースだと、Worker1の処理が終わるまで全体のJoinが完了しない。
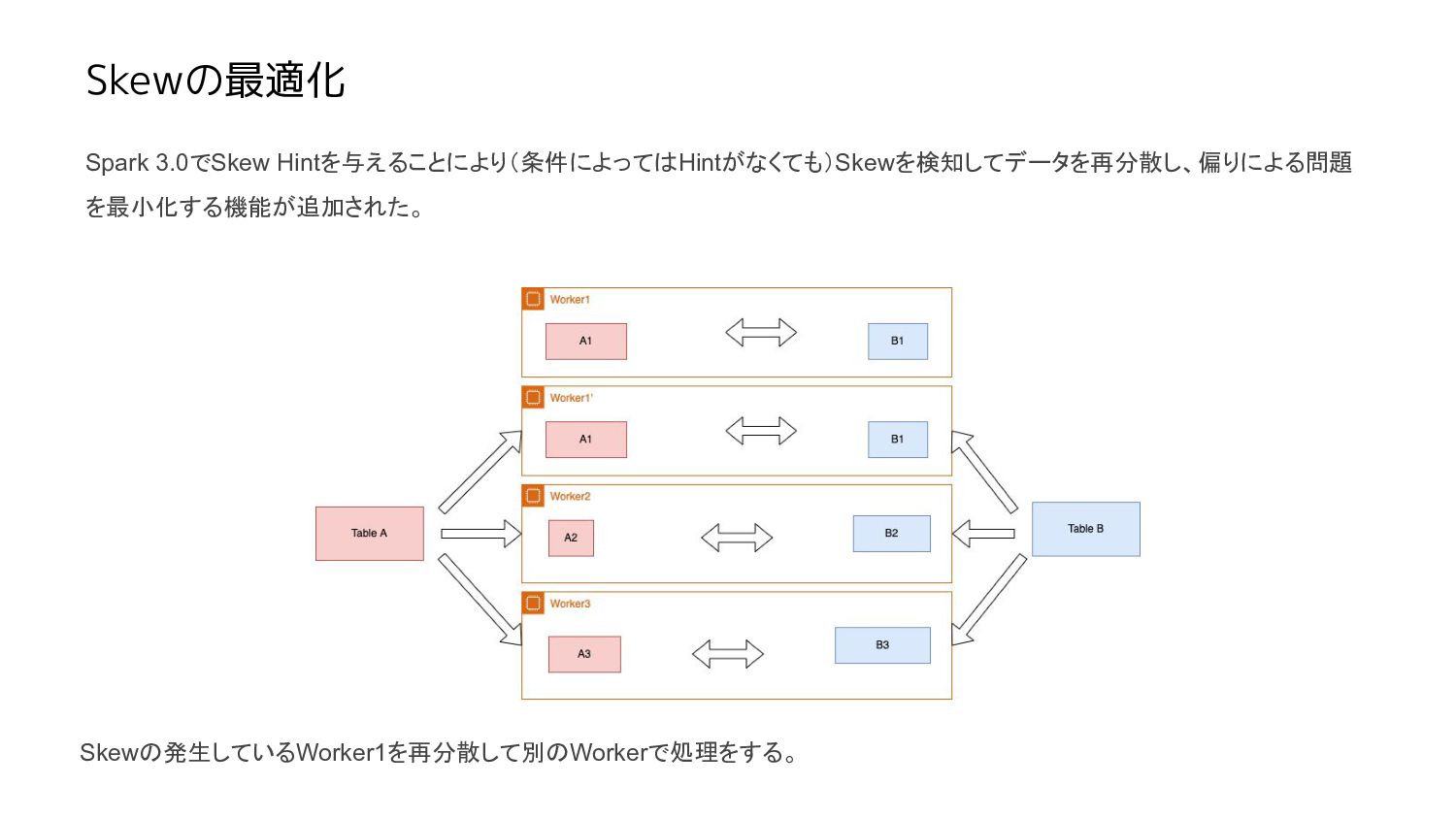
Skewの最適化 Spark 3.0でSkew Hintを与えることにより(条件によってはHintがなくても)Skewを検知してデータを再分散し、偏りによる問題 を最小化する機能が追加された。 Skewの発生しているWorker1を再分散して別のWorkerで処理をする。
結論 • できるだけBroadcast Joinを使おう ◦ マスタとの結合は明示的に Bradcast Hash Joinを使わせたりする •
どうしても出来ないときでも、複雑な条件では Joinしないようにしよう • Shuffle Joinが発生するカラムは均等に分散される設計にしよう ◦ IDFAやランダムな文字列などは基本的に偏りがない ◦ ステータスやtype系のものでJoinしようとするとSkewが発生しやすい • あとは実際どのJoinが使われているか、実行プランを確認しよう
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}