'', '\u3000', '\u3000' '空白', '', '', '6330815488512', '', '10', '10', '20', '記号', '0', '1', '', '', '23', '', '\u3000', '', '', '', '17', '\u3000', '', '', '', '737', '188673', '10', '20-源氏1010_00001', '10', '20'] ['平安-仮名文学', '20-源氏1010_00001', '20', '50', 'I', 'いづれ', 'イズレ', 'イズレ', '何れ', 'いづれ', '代名詞', '', '', '534646253298176', '', '20', '20', '50', '和', '0', '1', 'イズレ', 'イヅ レ', '1945', '', 'いづれ', '', '', '', '17', '何れ', '', '', '', '62241', '15933700', '10', '20- 源氏1010_00001', '20', '50'] ['平安-仮名文学', '20-源氏1010_00001', '50', '60', 'I', 'の', 'ノ', 'ノ', 'の', 'の', '助詞-格助 詞', '', '', '7968444268028416', '', '30', '50', '60', '和', '0', '1', 'ノ', 'ノ', '28989', '', 'の', '', '', '', '17', 'の', '', '', '', '927649', '237478145', '10', '20-源氏1010_00001', '50', '60']
![通時コーパスシンポジウム 2025 発表 2025年3月8日 国立国語研究所・オンライン 近藤泰弘(青山学院大学) [email protected] 1 生成AIによるコーパスの操作方法](https://files.speakerdeck.com/presentations/169085a88251493c9275cd6d82b1f8ad/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
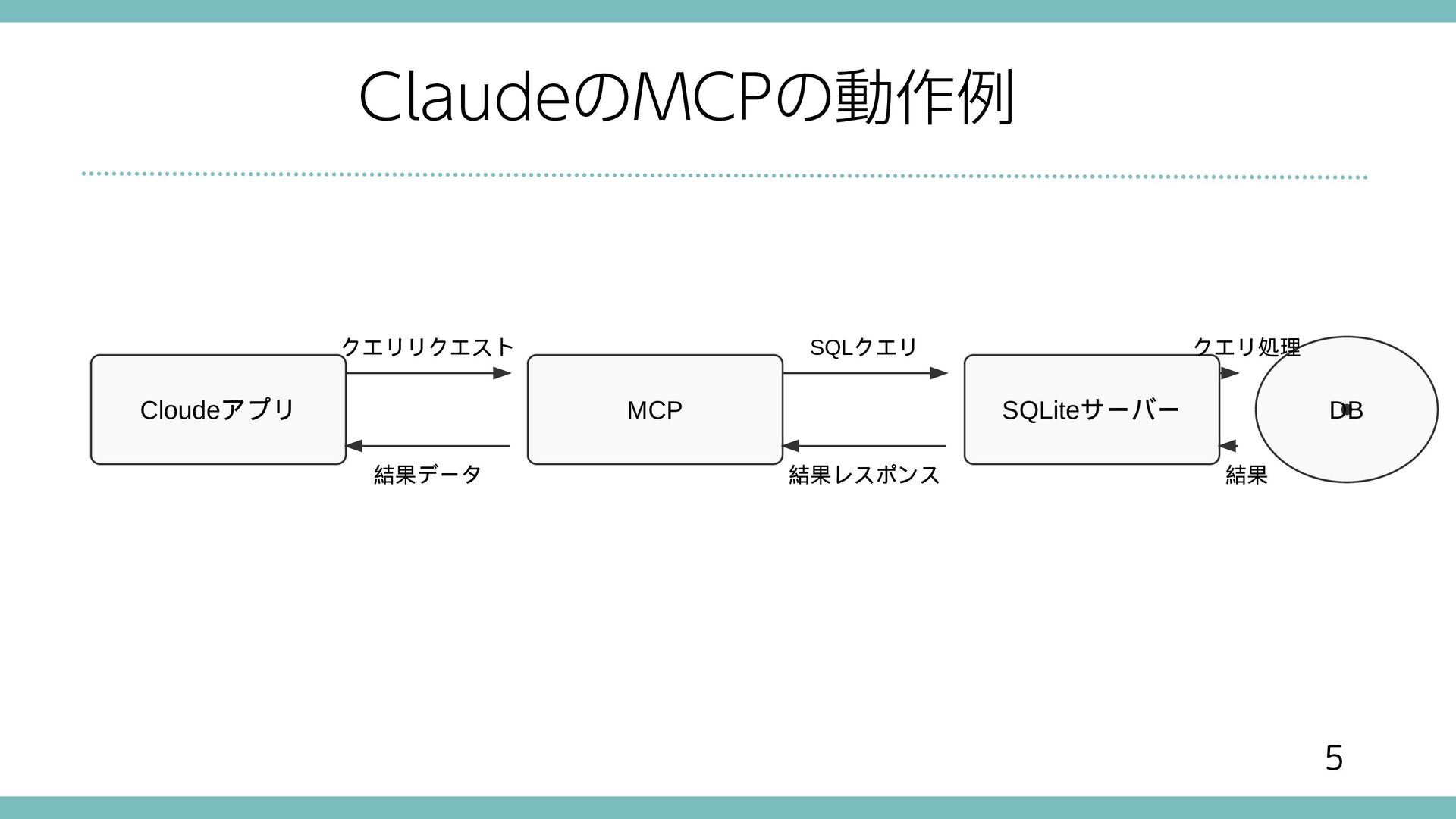{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
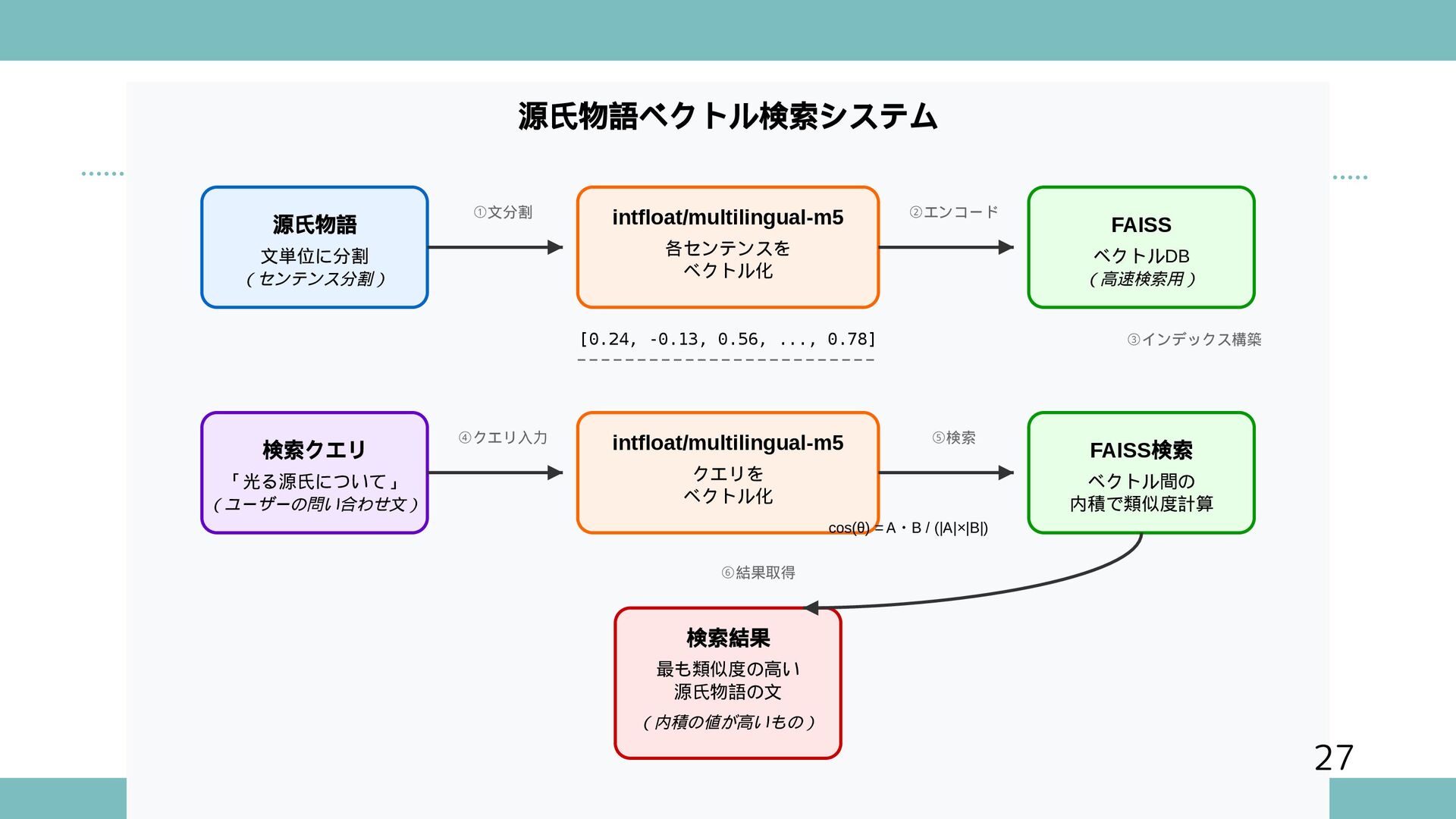{kind=link}
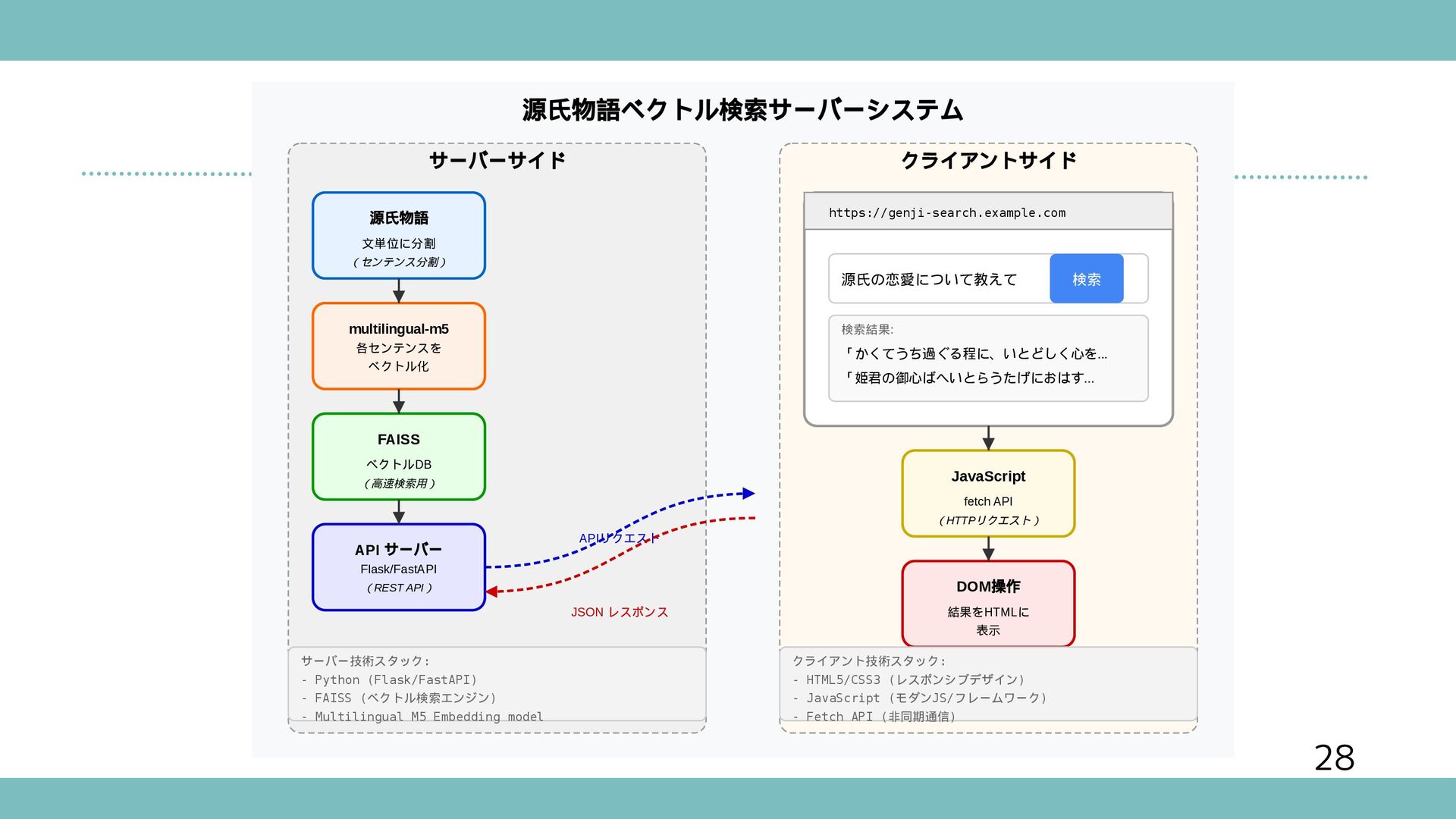{kind=link}
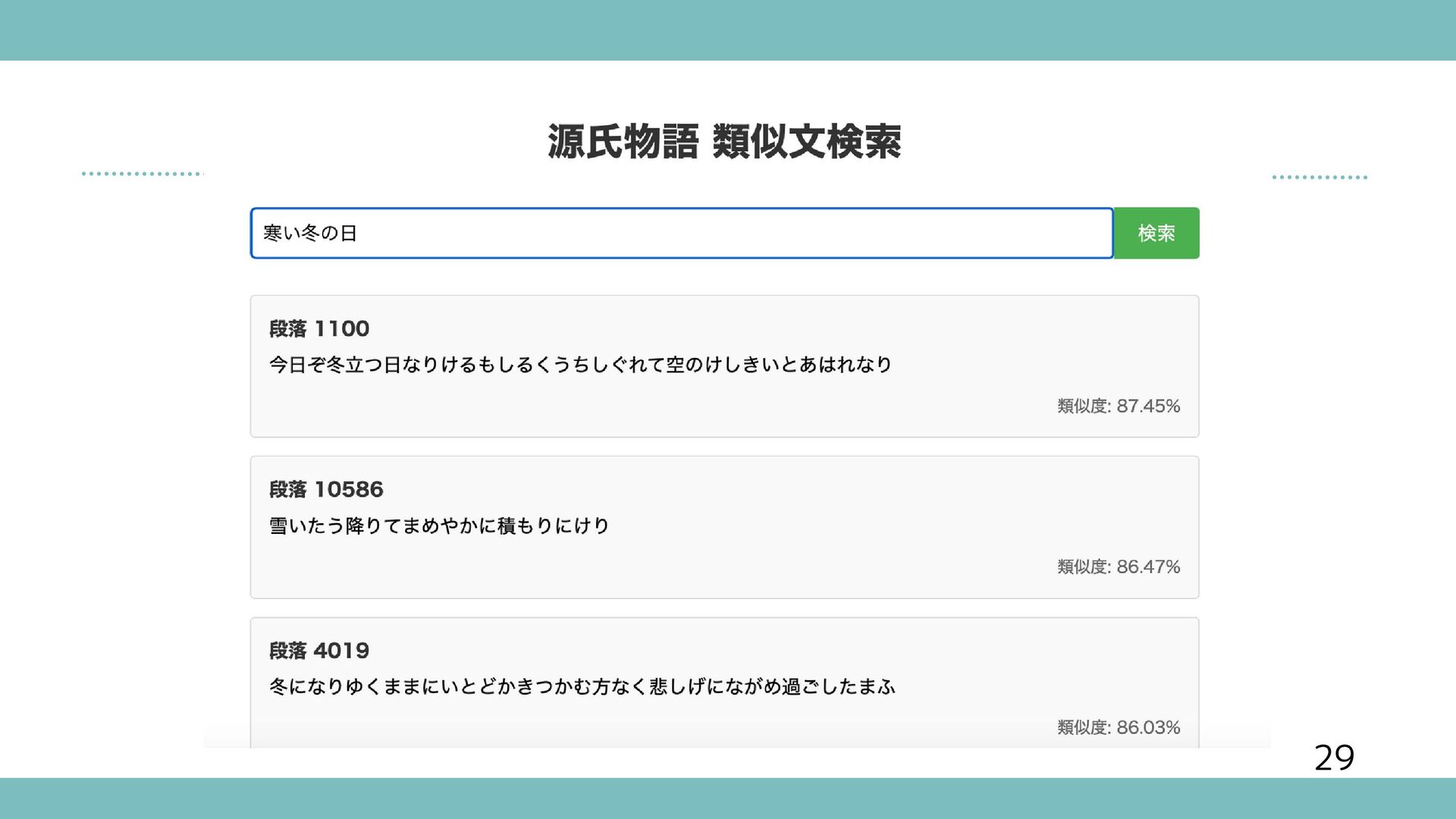{kind=link}
{kind=link}
{kind=link}