Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
An issue of rejoining when restarting a node an...
Search
yito88
February 09, 2021
Technology
240
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
An issue of rejoining when restarting a node and the investigation
An issue of rejoining when restarting a node and the investigation
Cassandra study group #40
yito88
February 09, 2021
More Decks by yito88
See All by yito88
ACID transaction with Scalar DB on Cosmos DB
yito88
1
340
Database Lounge Tokyo #6 LT - Jepsen Test Introduction
yito88
0
1k
Other Decks in Technology
See All in Technology
書籍セキュアAPIについて
riiimparm
0
350
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
150
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
330
A Bag-of-Documents Model for Query Specificity
dtunkelang
0
110
AI工学特論: MLOps・継続的評価
asei
11
2.7k
大 AI 時代におけるC# の事情 ~ぶっちゃけトークを交えながら~
nenonaninu
1
210
Flutter研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
150
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.3k
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
450
データ活用研修 データマネジメント【MIXI 26新卒技術研修】
mixi_engineers
PRO
4
460
コンテナ・K8s研修【MIXI 26新卒技術研修】#2
mixi_engineers
PRO
1
200
Git 研修【MIXI 26新卒技術研修】#2
mixi_engineers
PRO
1
260
Featured
See All Featured
Ruling the World: When Life Gets Gamed
codingconduct
0
290
Joys of Absence: A Defence of Solitary Play
codingconduct
1
420
Utilizing Notion as your number one productivity tool
mfonobong
4
460
Designing Experiences People Love
moore
143
24k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Into the Great Unknown - MozCon
thekraken
41
2.6k
From π to Pie charts
rasagy
0
240
Optimizing for Happiness
mojombo
378
71k
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
420
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
Transcript
ノード再起動時に 復帰しない問題とその調査 9th Feb. 2021 第40回Cassandra勉強会 Yuji Ito
Contents 1. 問題 2. 調査 3. 修正検討 4. まとめ 2
• Cassandra 3.11.6 で調査 • https://issues.apache.org/jira/browse/CASSANDRA-15138 3
1. 問題 4
• リクエストを発行し続けながら、複数ノードを停止後、1ノードを再起動すると“たま に”クラスタへ復帰しない ◦ ノード再起動: 停止→起動 ▪ 発見した際は kill コマンドを用いてノードを停止させていた
• ただし、-9 オプション(強制終了)を追加すると問題は発生しない 5 1.1. 問題の挙動 Cluster Node
1.1. 問題の挙動 6 Cluster Node1 Node2 [node1]$ nodetool status Datacenter:
datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 10.42.2.90 241.88 MiB 256 100.0% d4d9d194-1c10-4ccf-bcc8-62b596dc5fb0 rack1 DN 10.42.2.190 241.98 MiB 256 100.0% 737f5158-1e06-405a-8f09-c9d2b308053f rack1 UN 10.42.2.16 326.41 KiB 256 100.0% 35d643fd-2a46-4aaa-b6fa-922a39e23d94 rack1 [node2]$ nodetool status Datacenter: datacenter1 ======================= Status=Up/Down |/ State=Normal/Leaving/Joining/Moving -- Address Load Tokens Owns (effective) Host ID Rack UN 10.42.2.90 241.88 MiB 256 100.0% d4d9d194-1c10-4ccf-bcc8-62b596dc5fb0 rack1 DN 10.42.2.190 241.98 MiB 256 100.0% 737f5158-1e06-405a-8f09-c9d2b308053f rack1 DN 10.42.2.16 326.41 KiB 256 100.0% 35d643fd-2a46-4aaa-b6fa-922a39e23d94 rack1 Node1 からは Node3 のみがダウンしているように見える (Node2 は生きているように見える ) Node2 からは Node1, Node3 両方がダウンしているように見える Node3
1.2. 問題後の挙動 • Node1 => Node2 のメッセージはすべてタイムアウト ◦ Node2 =>
Node1 は Node2 はそもそも Node1 がダウンとしていると思っている • Node2 => Node1 で状態を確認しようとする(Gossip)が、失敗 • 20~30分後に復帰する ◦ その間、問題のノードがリクエストを受け取っても失敗する (Consistency Level による) 7
2. 調査 8
2.1. 調査開始 • 問題を高確率で再現させる ◦ “たまに”しか起こらないので、できるだけ発生確率を上げたい ◦ ログを入れ込めると調査効率が段違いになる => 試行錯誤の結果、Stress
tool をノード上で走らせると起きやすいことが判 明 • 停止しないノード(前述の例では Node1 )にリクエストを投げ続けると起き やすい 9
2.2. 調査方針 • Nodetool status の結果およびログから、ノード状態監視に問題があると推測 => Gossip 処理周りを調査 10
2.3. Gossip • Gossip is a peer-to-peer communication protocol in
which nodes periodically exchange state information about themselves and about other nodes they know about. (https://docs.datastax.com/en/cassandra-oss/3.x/cassandra/architecture/archGossipAbout.html) ◦ 各ノードがメッセージを送り合い、お互いの状態情報を交換 11
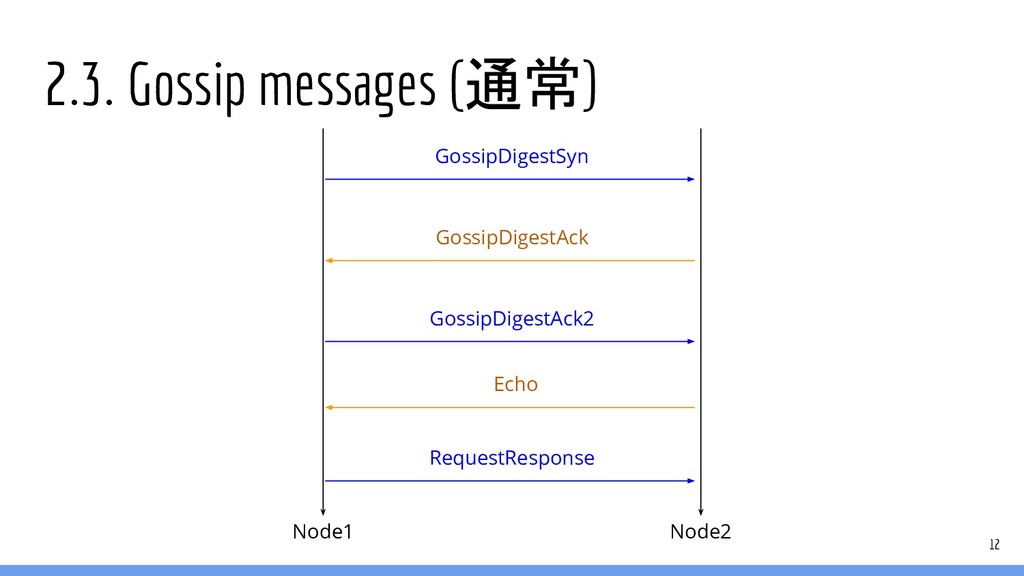
2.3. Gossip messages (通常) 12 Node1 Node2 GossipDigestSyn GossipDigestAck GossipDigestAck2
Echo RequestResponse
2.4. Gossip messages (問題発生時) 13 Node1 Node2 GossipDigestSyn GossipDigestAck GossipDigestAck2
Echo RequestResponse RequestResponse は送信済みだが、 Node2 が受け取っていない
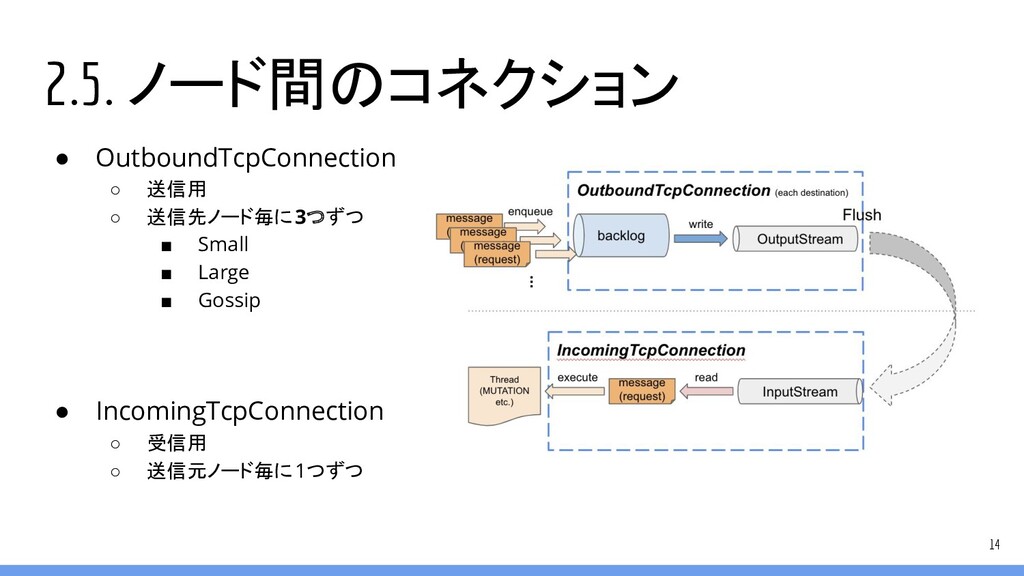
2.5. ノード間のコネクション 14 • OutboundTcpConnection ◦ 送信用 ◦ 送信先ノード毎に3つずつ ▪
Small ▪ Large ▪ Gossip • IncomingTcpConnection ◦ 受信用 ◦ 送信元ノード毎に1つずつ
2.6. RequestResponse が返らない原因 • RequestResponse メッセージだけ Small 送信用コネクションを使用 ◦ このコネクションに問題が発生している!
◦ 他の Gossip メッセージは Gossip 送信用コネクションを用いて送信しているので成功 • Small 送信用コネクションが疎通していない? ◦ Gossip 送信用は疎通しているのに? => いつ閉じられて、いつ開けられるかをログ追加しつつ調査 15
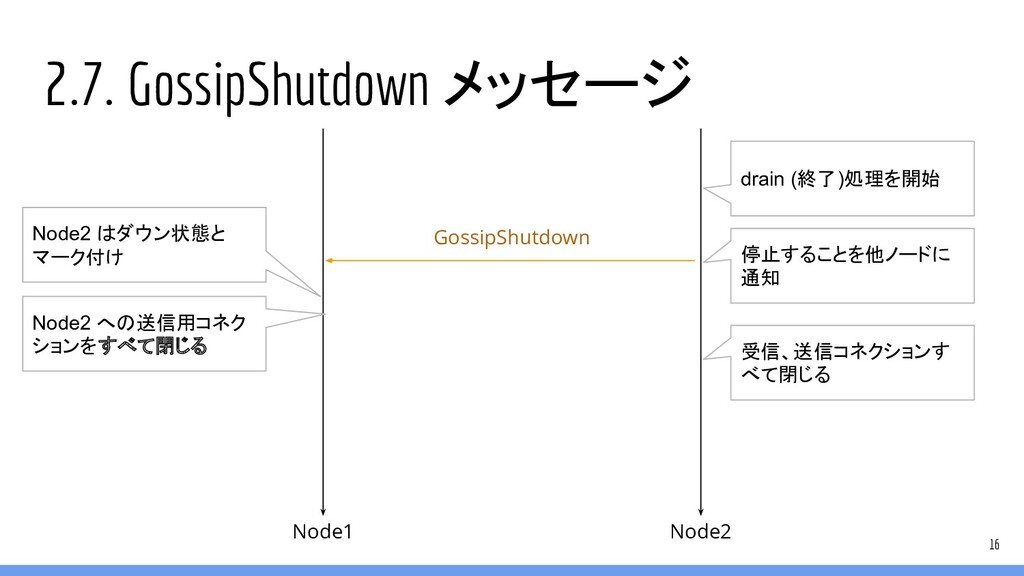
2.7. GossipShutdown メッセージ 16 Node1 Node2 GossipShutdown Node2 はダウン状態と マーク付け
Node2 への送信用コネク ションをすべて閉じる 停止することを他ノードに 通知 drain (終了)処理を開始 受信、送信コネクションす べて閉じる
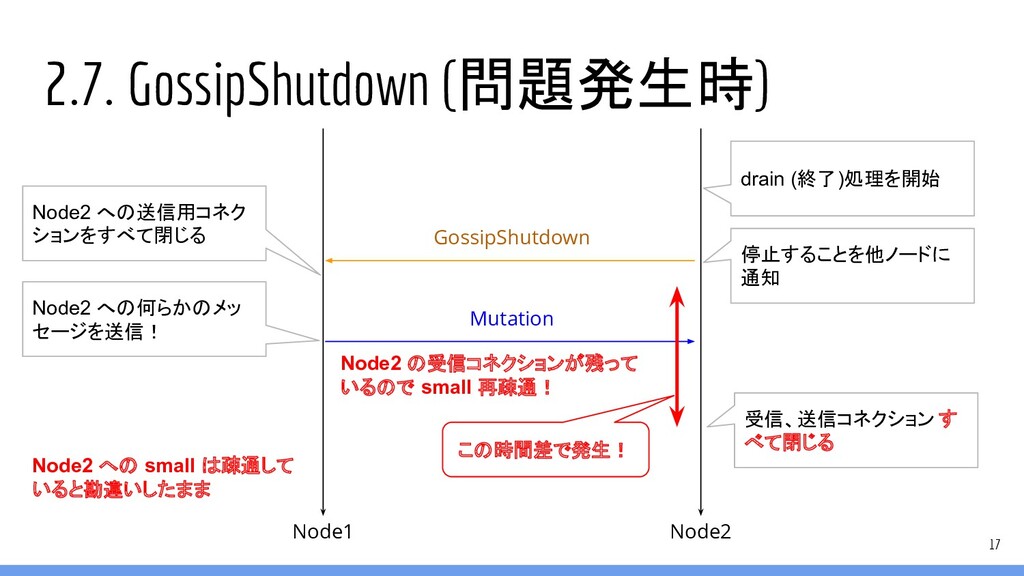
2.7. GossipShutdown (問題発生時) 17 Node1 Node2 GossipShutdown Mutation Node2 への送信用コネク
ションをすべて閉じる Node2 への何らかのメッ セージを送信! 受信、送信コネクション す べて閉じる 停止することを他ノードに 通知 drain (終了)処理を開始 Node2 の受信コネクションが残って いるので small 再疎通! Node2 への small は疎通して いると勘違いしたまま この時間差で発生!
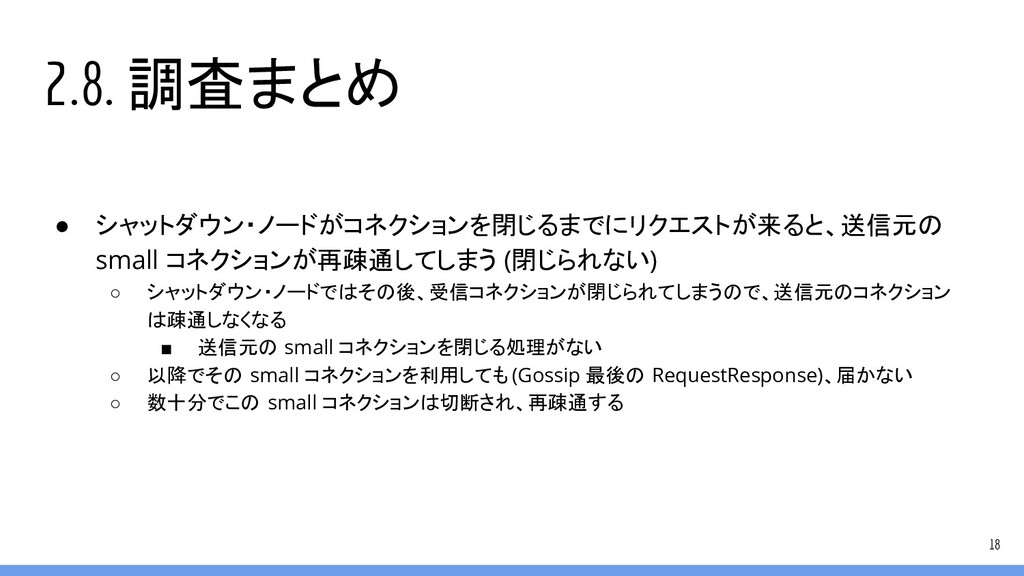
2.8. 調査まとめ • シャットダウン・ノードがコネクションを閉じるまでにリクエストが来ると、送信元の small コネクションが再疎通してしまう (閉じられない) ◦ シャットダウン・ノードではその後、受信コネクションが閉じられてしまうので、送信元のコネクション は疎通しなくなる
▪ 送信元の small コネクションを閉じる処理がない ◦ 以降でその small コネクションを利用しても (Gossip 最後の RequestResponse)、届かない ◦ 数十分でこの small コネクションは切断され、再疎通する 18
3. 修正検討 19
3. 修正検討 • 送信元ノード: ◦ ダウンしたノードへの通常メッセージ送信をしないようにする? • シャットダウンするノード: ◦ GossipShutdown
前に Gossip 送信以外のコネクションを閉じる? 20
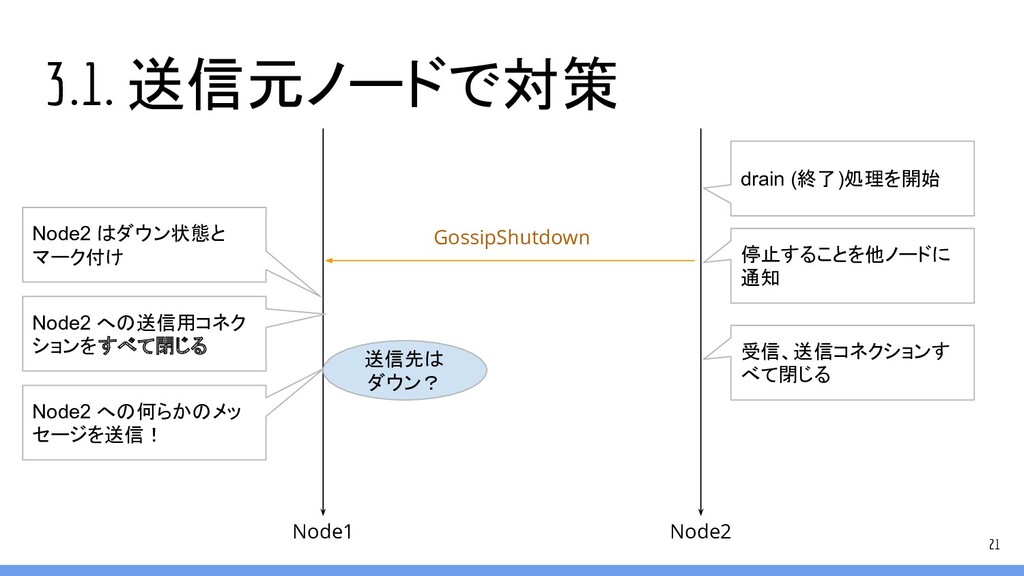
3.1. 送信元ノードで対策 21 Node1 Node2 GossipShutdown Node2 はダウン状態と マーク付け Node2
への送信用コネク ションをすべて閉じる 停止することを他ノードに 通知 drain (終了)処理を開始 受信、送信コネクションす べて閉じる Node2 への何らかのメッ セージを送信! 送信先は ダウン?
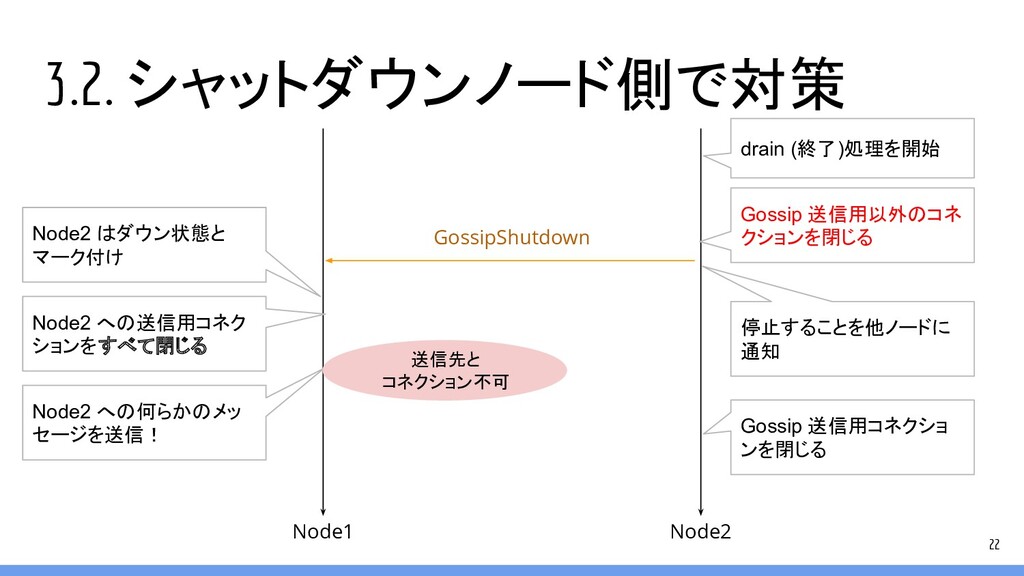
3.2. シャットダウンノード側で対策 22 Node1 Node2 GossipShutdown Node2 はダウン状態と マーク付け Node2
への送信用コネク ションをすべて閉じる 停止することを他ノードに 通知 drain (終了)処理を開始 Gossip 送信用コネクショ ンを閉じる Node2 への何らかのメッ セージを送信! 送信先と コネクション不可 Gossip 送信用以外のコネ クションを閉じる
4. まとめ 23
4. まとめ • ノード再起動時に復帰しない問題 ◦ 特定の条件で発生する • あるノードの正常終了処理中、コネクションが閉じられるまでに、別ノードと意図しな いコネクションが疎通してしまうことで発生 •
今後、修正を試みる ◦ コード確認では 4.0 でも発生する気もするが、未検証 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1.1. 問題の挙動 6 Cluster Node1 Node2 [node1]$ nodetool status Datacenter:](https://files.speakerdeck.com/presentations/b5a5ac2cbadf4c8caed1a67f0a0d546e/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}