Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
(TA實作課程)MNIST_MLPCNNRNN
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Yi-Zhen, Chen
July 14, 2021
Programming
240
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
(TA實作課程)MNIST_MLPCNNRNN
Yi-Zhen, Chen
July 14, 2021
More Decks by Yi-Zhen, Chen
See All by Yi-Zhen, Chen
(學習護照)AI基礎課程
yizhen1223
2
210
(學習護照)樹莓派基礎教學
yizhen1223
0
130
運用文字探勘分析於圖書資訊檢索使用者行為與習慣-以中原大學張靜愚紀念圖書館為例
yizhen1223
0
170
Other Decks in Programming
See All in Programming
メソッドのジェネリクスでGoの夢は広がるか? / Kyoto.go #65
utgwkk
3
1k
The NotImplementedError Problem in Ruby
koic
1
1k
例外の正しい扱い方 そのエラー try-catchして大丈夫?
jinwatanabe
0
300
jQueryをバージョンアップする前に使いたいjQuery Migrate
matsuo_atsushi
0
620
「なぜそう決めたのか」を残し続ける仕組み ― Notion AI カスタムエージェント × Slack連携による設計判断の自動記録 - NIKKEI Tech Talk #47
niftycorp
PRO
0
250
The Bowling Game - From Imperative to Functional Programming - Part 1
philipschwarz
PRO
0
160
Vite+ Unified Toolchain for the Web
naokihaba
0
410
トークンをケチるな、設計しろ:GitHub Copilotを賢く使うコンテキスト戦略
ochtum
0
260
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
1
610
Contextとはなにか
chiroruxx
1
380
エンジニアと一緒にテストコードの設計と実装を改善した話
mototakatsu
0
230
不変条件と整合性境界—ビジネスが決める設計判断と実現パターン / Invariants and Consistency Boundaries
nrslib
14
6k
Featured
See All Featured
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Building the Perfect Custom Keyboard
takai
2
810
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
44k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
570
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
210
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
790
The Limits of Empathy - UXLibs8
cassininazir
1
380
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
KATA
mclloyd
PRO
35
15k
Mind Mapping
helmedeiros
PRO
1
270
Transcript
使用Tensorflow, Keras 實作MLP, CNN, RNN 圖片辨識MNIST數字資料集 助教 陳怡蓁
[email protected]
目錄 CONTENT 01 MLP, CNN, RNN介紹 02 Tensorflow, Keras介紹 03
在Windows環境中安裝 Tensorflow, Keras 04 實作MNIST辨識手寫數字
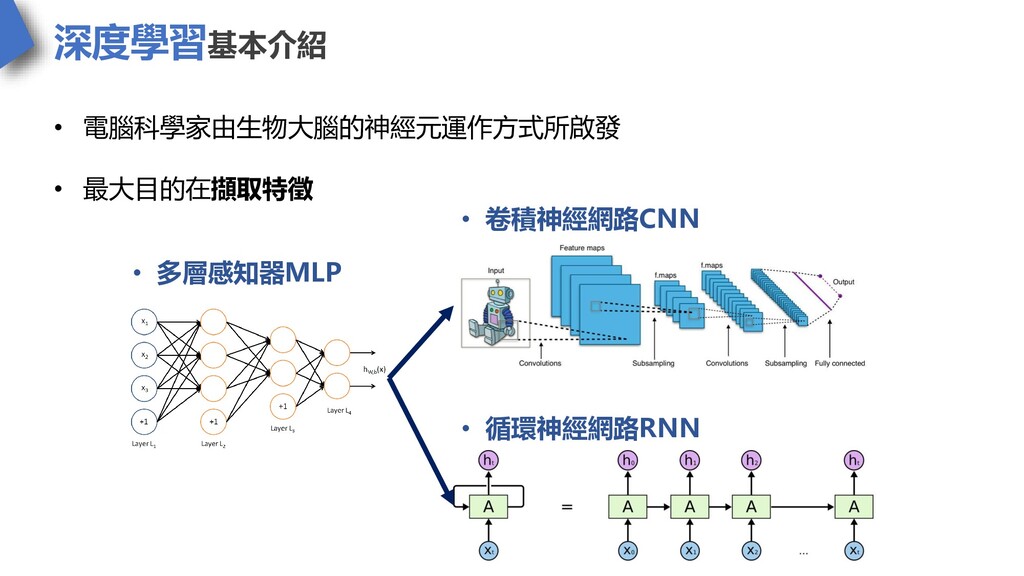
深度學習基本介紹 • 多層感知器MLP • 卷積神經網路CNN • 循環神經網路RNN • 電腦科學家由生物大腦的神經元運作方式所啟發 •
最大目的在擷取特徵
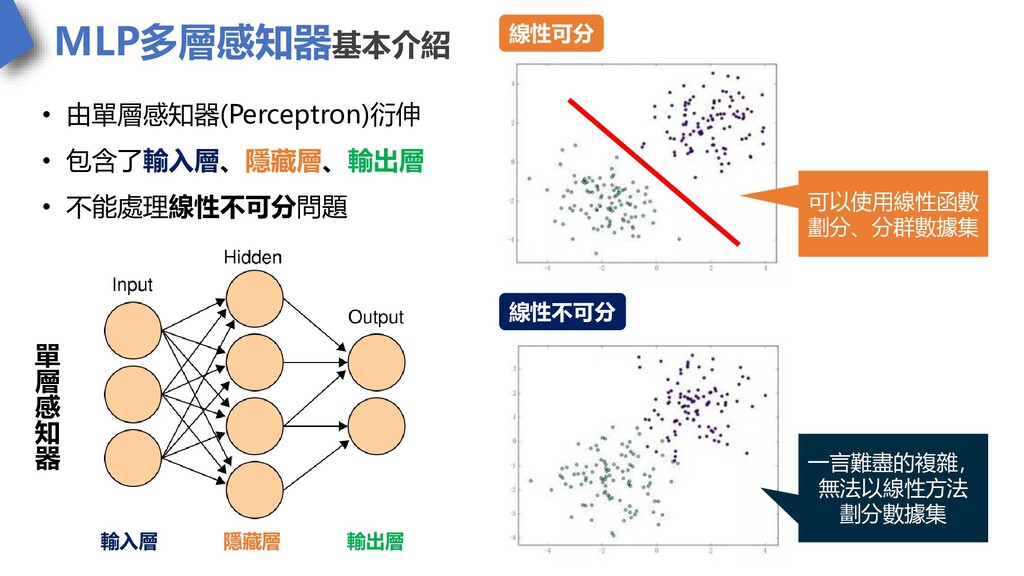
MLP多層感知器基本介紹 • 由單層感知器(Perceptron)衍伸 • 包含了輸入層、隱藏層、輸出層 • 不能處理線性不可分問題 輸入層 輸出層 隱藏層
線性可分 線性不可分 可以使用線性函數 劃分、分群數據集 一言難盡的複雜, 無法以線性方法 劃分數據集 單 層 感 知 器
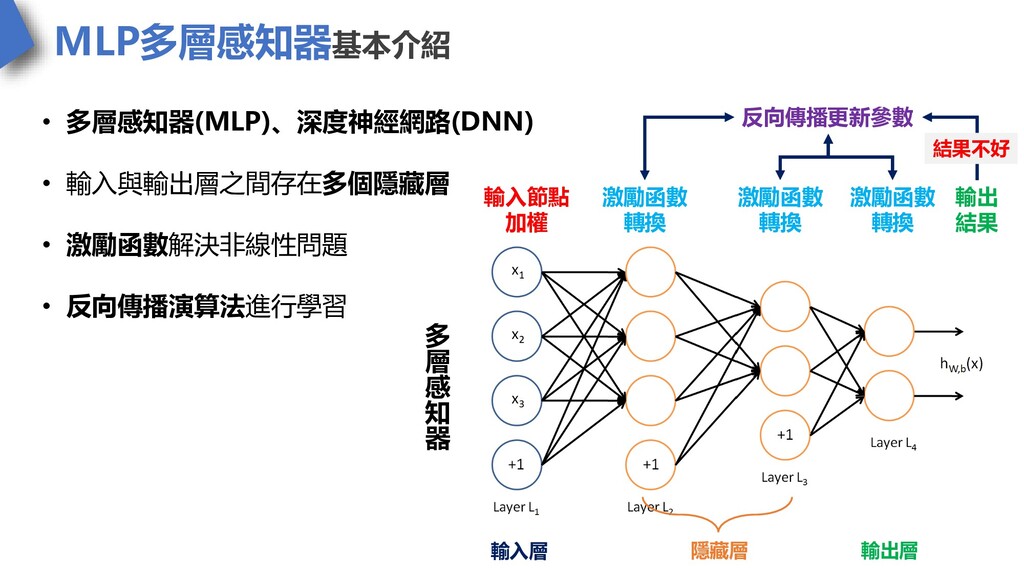
MLP多層感知器基本介紹 • 多層感知器(MLP)、深度神經網路(DNN) • 輸入與輸出層之間存在多個隱藏層 • 激勵函數解決非線性問題 • 反向傳播演算法進行學習 輸入層
輸出層 隱藏層 多 層 感 知 器 輸入節點 加權 激勵函數 轉換 激勵函數 轉換 激勵函數 轉換 輸出 結果 反向傳播更新參數 結果不好
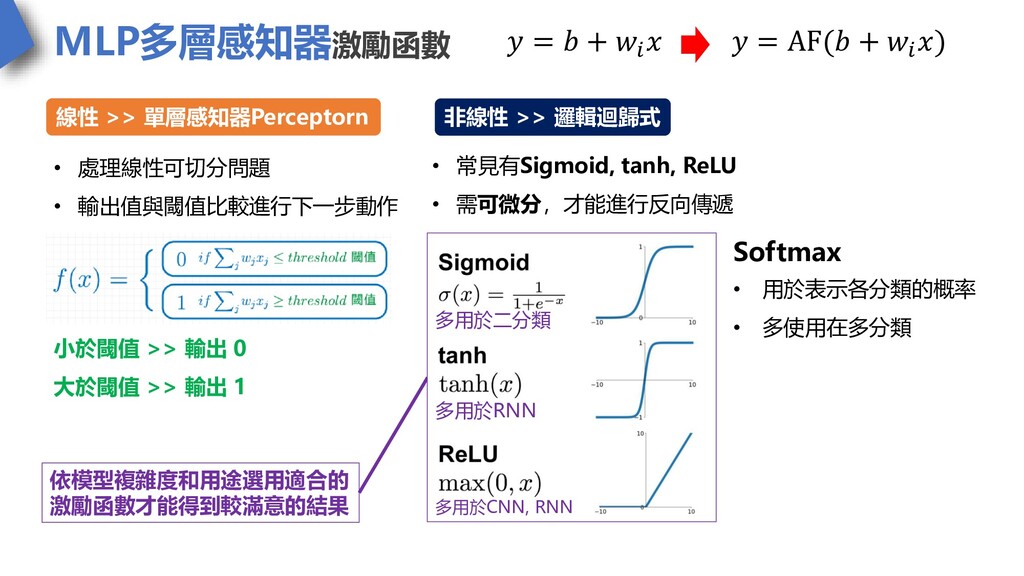
MLP多層感知器激勵函數 • 處理線性可切分問題 • 輸出值與閾值比較進行下一步動作 小於閾值 >> 輸出 0 大於閾值
>> 輸出 1 線性 >> 單層感知器Perceptorn 非線性 >> 邏輯迴歸式 • 常見有Sigmoid, tanh, ReLU • 需可微分,才能進行反向傳遞 𝑦 = 𝑏 + 𝑤𝑖 𝑥 𝑦 = AF(𝑏 + 𝑤𝑖 𝑥) 多用於RNN 多用於CNN, RNN 依模型複雜度和用途選用適合的 激勵函數才能得到較滿意的結果 多用於二分類 Softmax • 用於表示各分類的概率 • 多使用在多分類
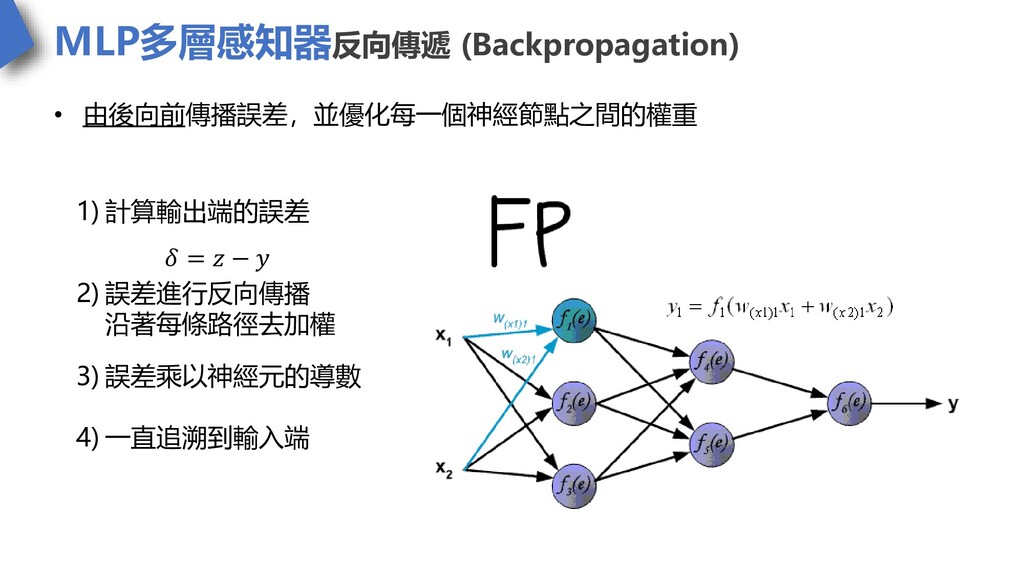
MLP多層感知器反向傳遞 (Backpropagation) • 由後向前傳播誤差,並優化每一個神經節點之間的權重 1) 計算輸出端的誤差 𝛿 = 𝑧 −
𝑦 2) 誤差進行反向傳播 沿著每條路徑去加權 3) 誤差乘以神經元的導數 4) 一直追溯到輸入端
MLP多層感知器反向傳遞 (Backpropagation) • 利用損失函數 𝒍𝒐𝒔𝒔 作為目標函數來進行參數更新 • 目標:找出最佳參數解,讓誤差值最小 • 梯度下降法
(Gradient Descent) 1) 隨機取初始點,分別計算參數進行對 𝒍𝒐𝒔𝒔 的微分 2) 往下走不斷更新參數,直到全域最低點 ※ 影片講解 01:48 -02:36
MLP多層感知器後續發展與缺陷 • 助於利用模型來刻劃現實世界的複雜情況 • MLP可解決基本的分類與預測問題 • 可能因為梯度爆炸、消失產生優化困難 後人發展出CNN 與 RNN
來改善MLP在不同領域下的應用
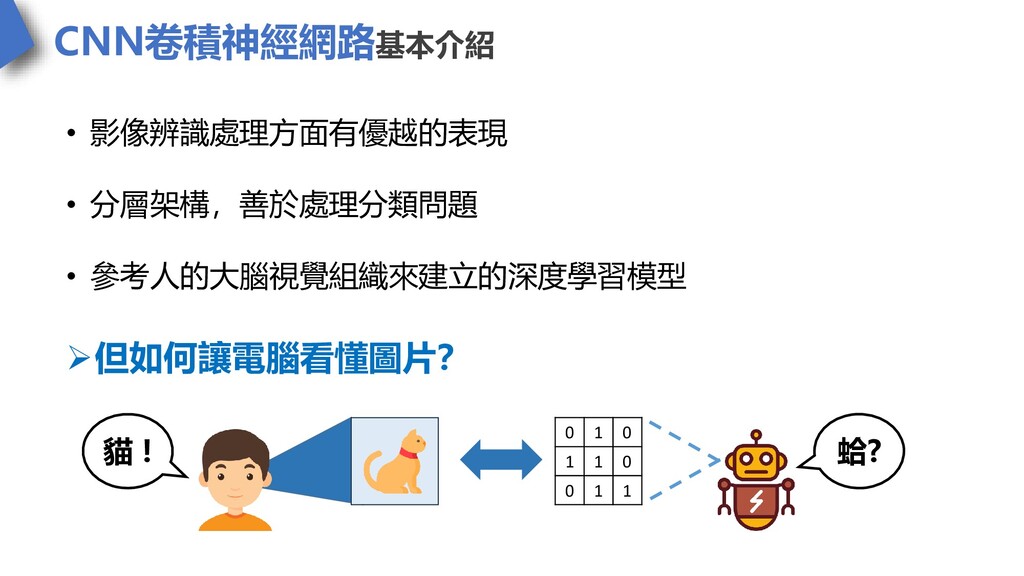
CNN卷積神經網路基本介紹 • 影像辨識處理方面有優越的表現 • 分層架構,善於處理分類問題 • 參考人的大腦視覺組織來建立的深度學習模型 但如何讓電腦看懂圖片? 0 1
0 1 1 0 0 1 1 蛤? 貓 !
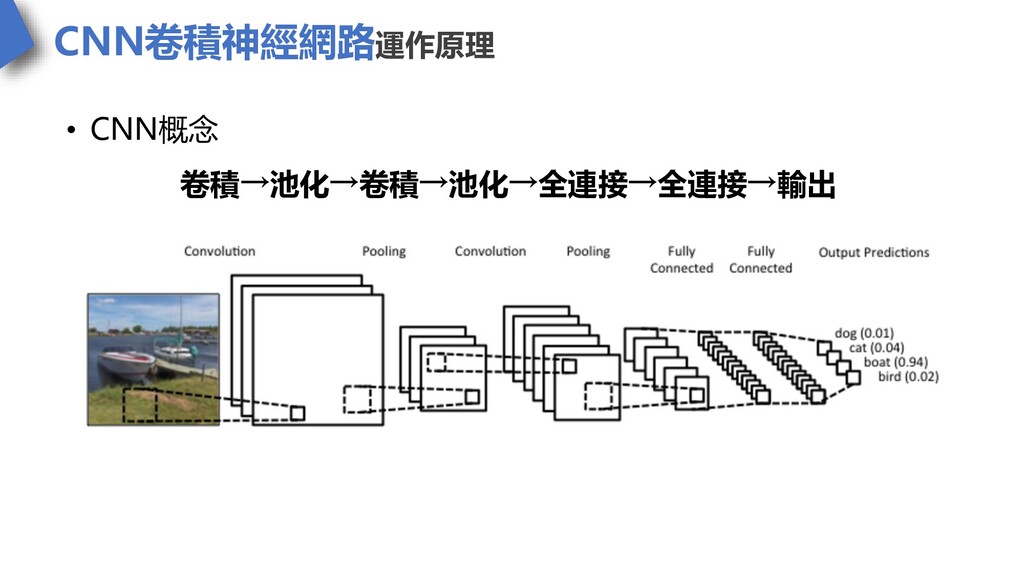
CNN卷積神經網路運作原理 • CNN概念 卷積→池化→卷積→池化→全連接→全連接→輸出
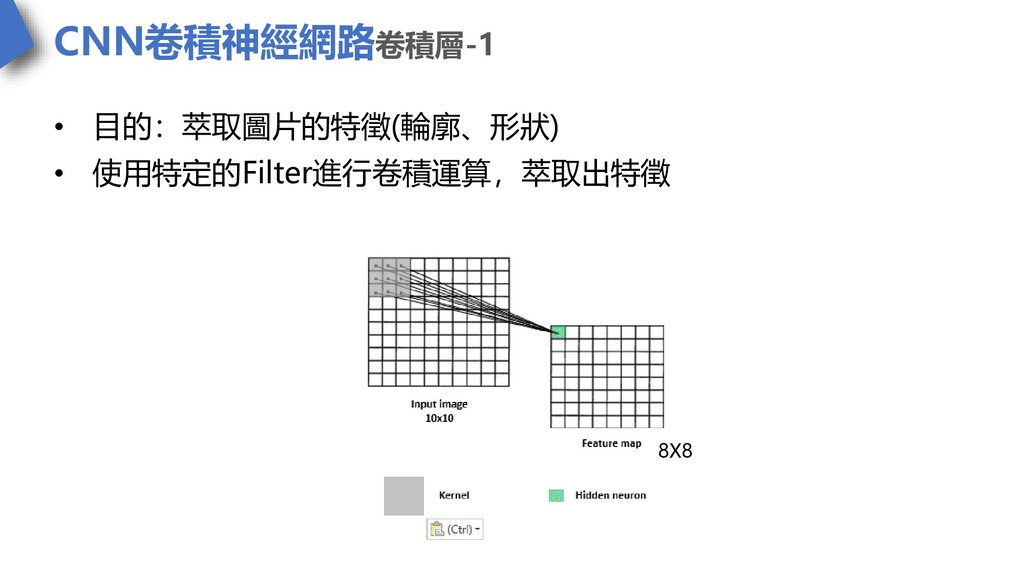
CNN卷積神經網路卷積層-1 • 目的:萃取圖片的特徵(輪廓、形狀) • 使用特定的Filter進行卷積運算,萃取出特徵 8X8
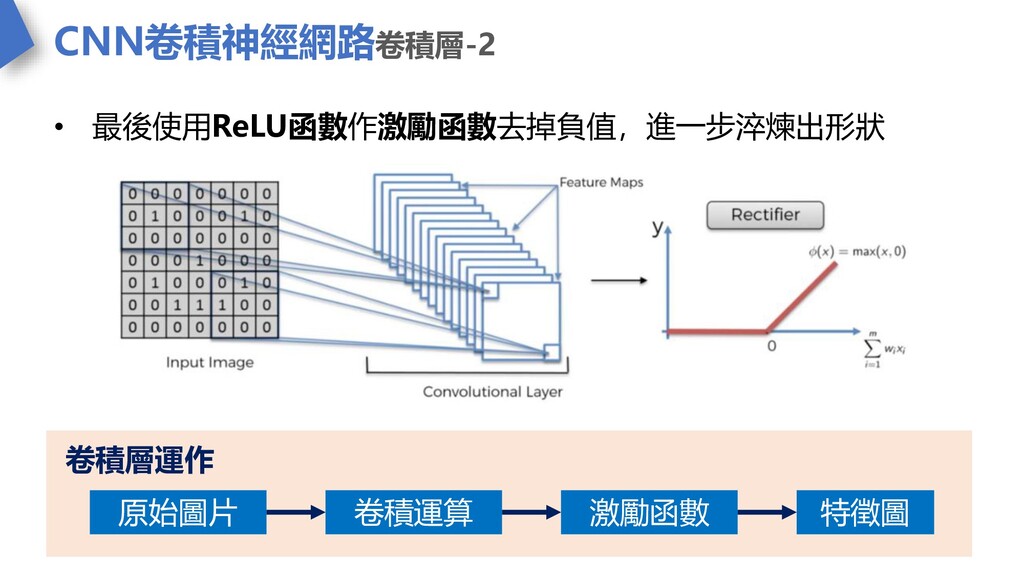
CNN卷積神經網路卷積層-2 • 最後使用ReLU函數作激勵函數去掉負值,進一步淬煉出形狀 原始圖片 卷積運算 激勵函數 特徵圖 卷積層運作
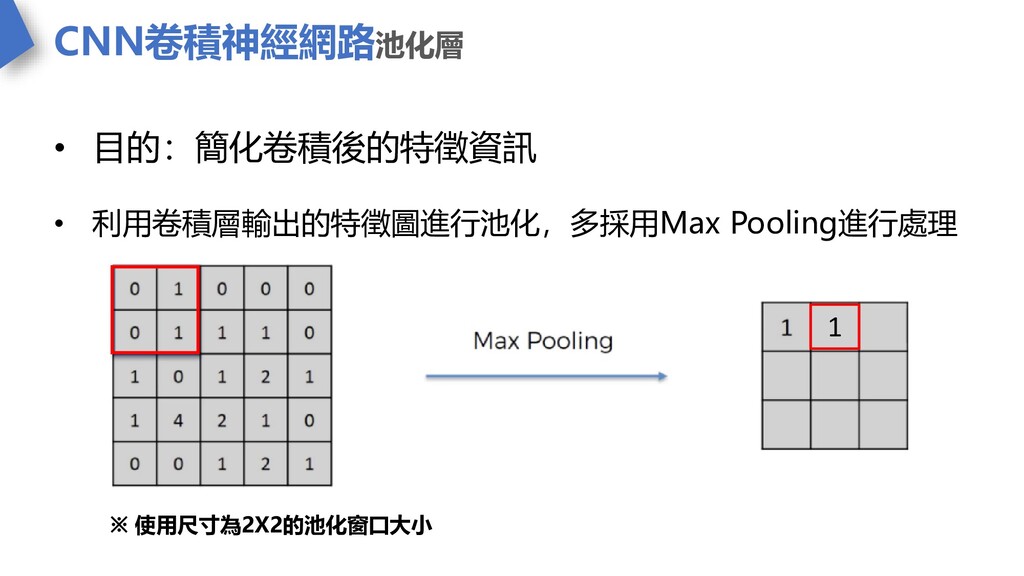
CNN卷積神經網路池化層 • 目的:簡化卷積後的特徵資訊 • 利用卷積層輸出的特徵圖進行池化,多採用Max Pooling進行處理 1 ※ 使用尺寸為2X2的池化窗口大小
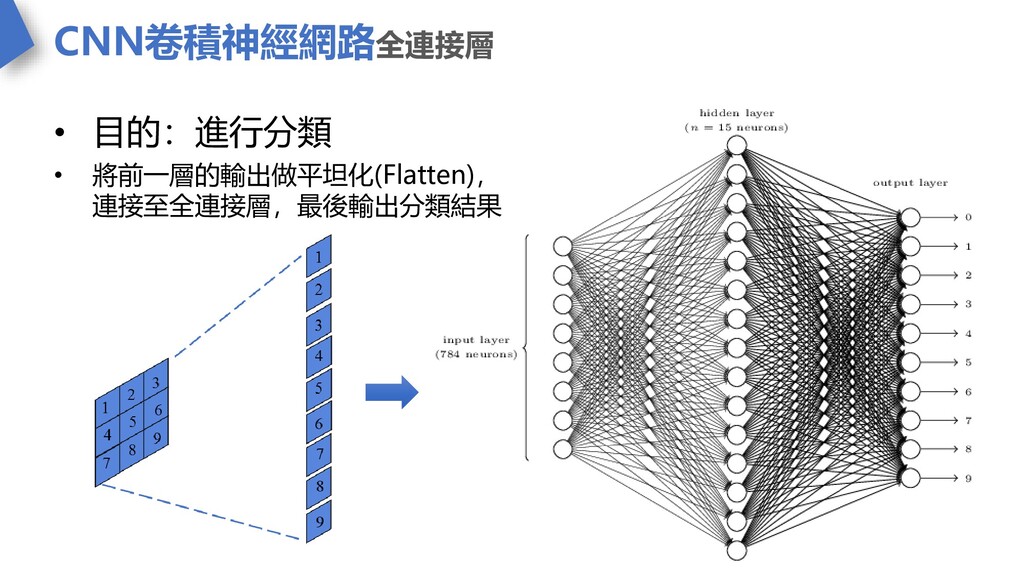
CNN卷積神經網路全連接層 • 目的:進行分類 • 將前一層的輸出做平坦化(Flatten), 連接至全連接層,最後輸出分類結果
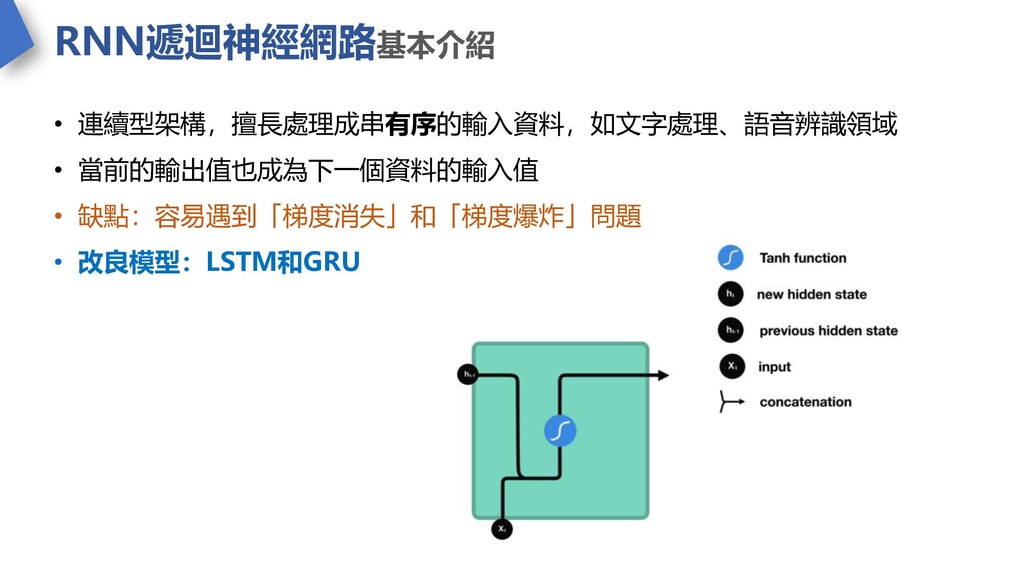
RNN遞迴神經網路基本介紹 • 連續型架構,擅長處理成串有序的輸入資料,如文字處理、語音辨識領域 • 當前的輸出值也成為下一個資料的輸入值 • 缺點:容易遇到「梯度消失」和「梯度爆炸」問題 • 改良模型:LSTM和GRU
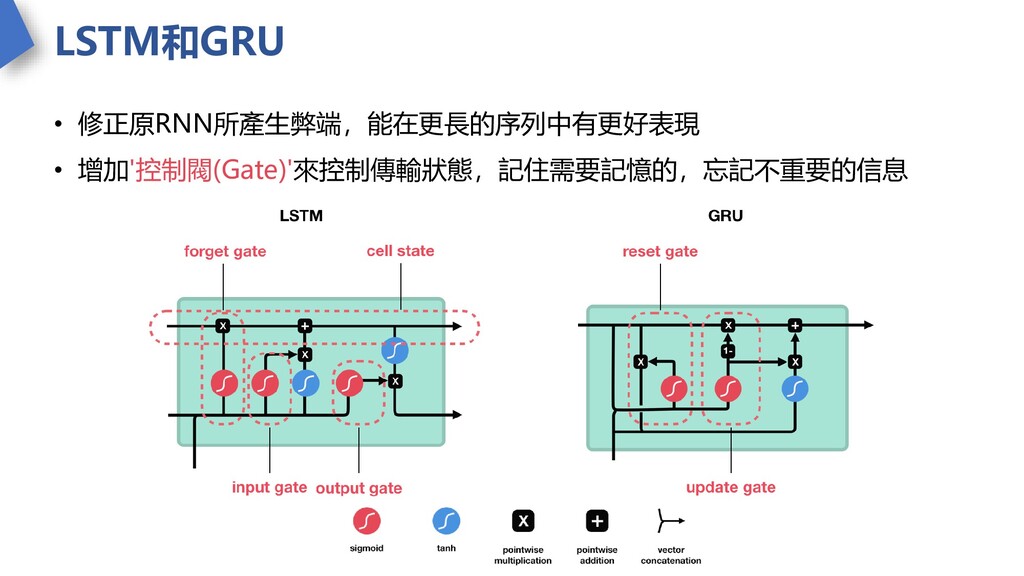
LSTM和GRU • 修正原RNN所產生弊端,能在更長的序列中有更好表現 • 增加'控制閥(Gate)'來控制傳輸狀態,記住需要記憶的,忘記不重要的信息
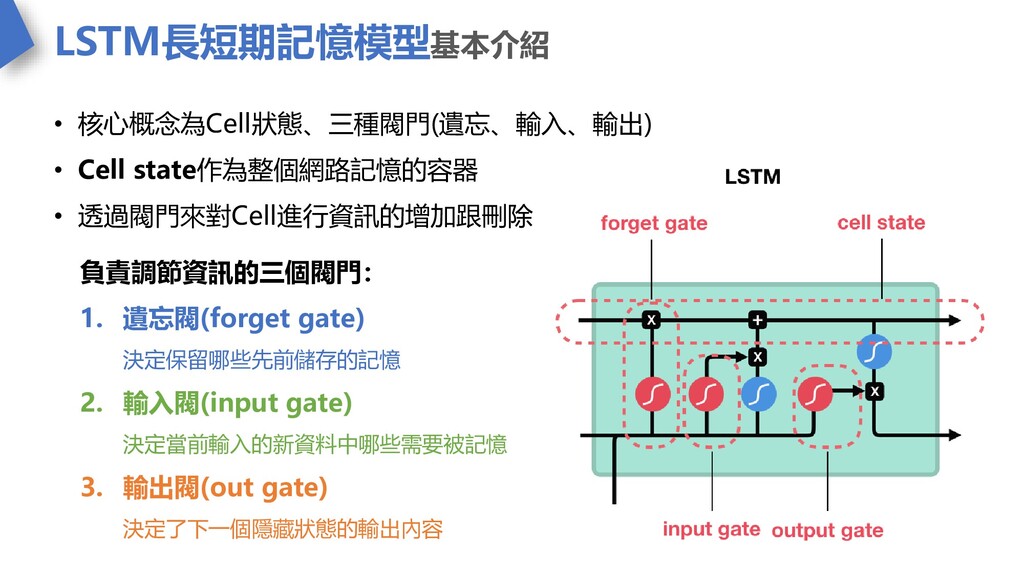
LSTM長短期記憶模型基本介紹 • 核心概念為Cell狀態、三種閥門(遺忘、輸入、輸出) • Cell state作為整個網路記憶的容器 • 透過閥門來對Cell進行資訊的增加跟刪除 負責調節資訊的三個閥門: 1.
遺忘閥(forget gate) 決定保留哪些先前儲存的記憶 2. 輸入閥(input gate) 決定當前輸入的新資料中哪些需要被記憶 3. 輸出閥(out gate) 決定了下一個隱藏狀態的輸出內容
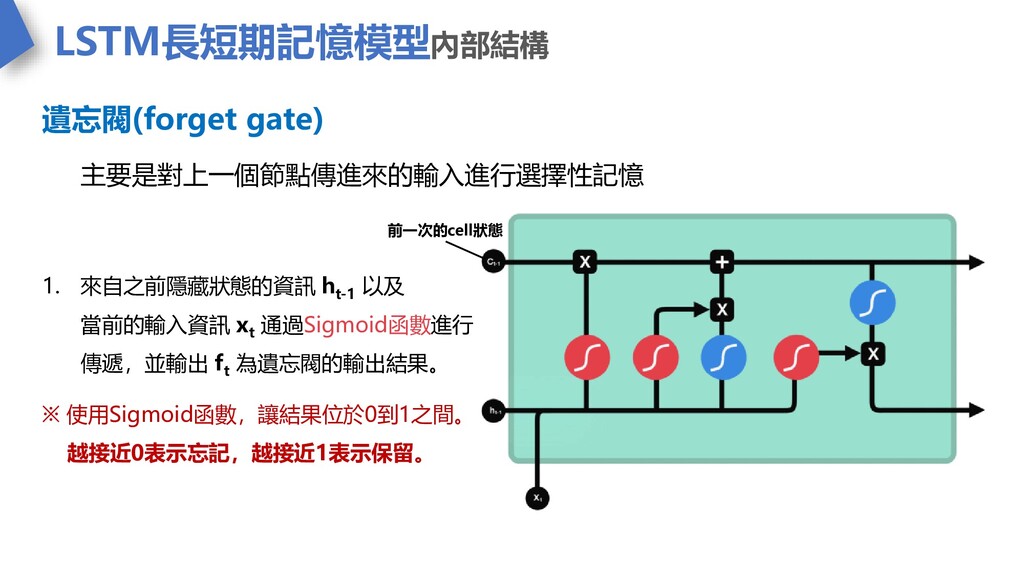
LSTM長短期記憶模型內部結構 遺忘閥(forget gate) 主要是對上一個節點傳進來的輸入進行選擇性記憶 前一次的cell狀態 1. 來自之前隱藏狀態的資訊 h t-1 以及
當前的輸入資訊 x t 通過Sigmoid函數進行 傳遞,並輸出 f t 為遺忘閥的輸出結果。 ※ 使用Sigmoid函數,讓結果位於0到1之間。 越接近0表示忘記,越接近1表示保留。
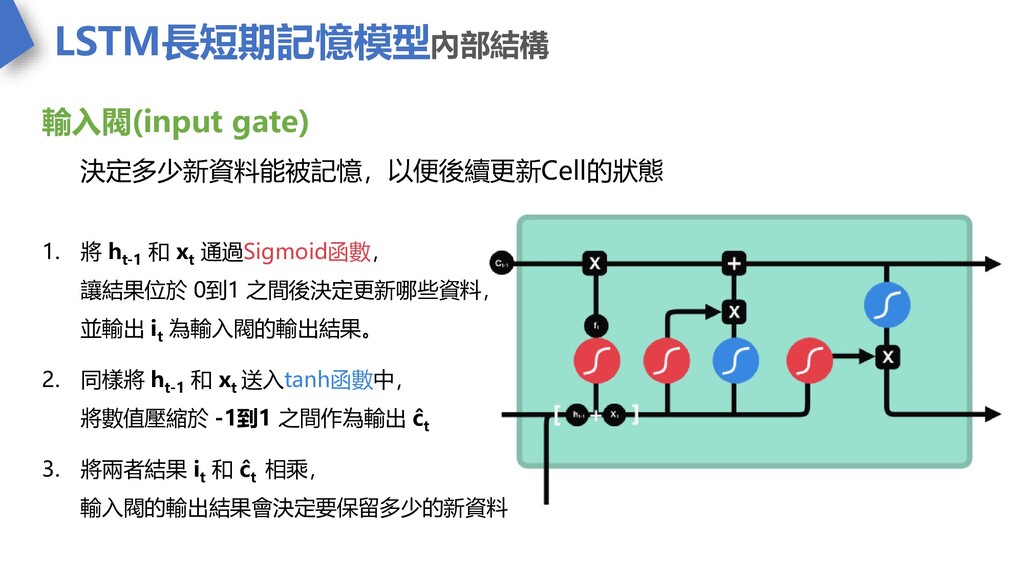
LSTM長短期記憶模型內部結構 輸入閥(input gate) 決定多少新資料能被記憶,以便後續更新Cell的狀態 1. 將 h t-1 和 x
t 通過Sigmoid函數, 讓結果位於 0到1 之間後決定更新哪些資料, 並輸出 i t 為輸入閥的輸出結果。 2. 同樣將 h t-1 和 x t 送入tanh函數中, 將數值壓縮於 -1到1 之間作為輸出 ĉ t 3. 將兩者結果 i t 和 ĉ t 相乘, 輸入閥的輸出結果會決定要保留多少的新資料
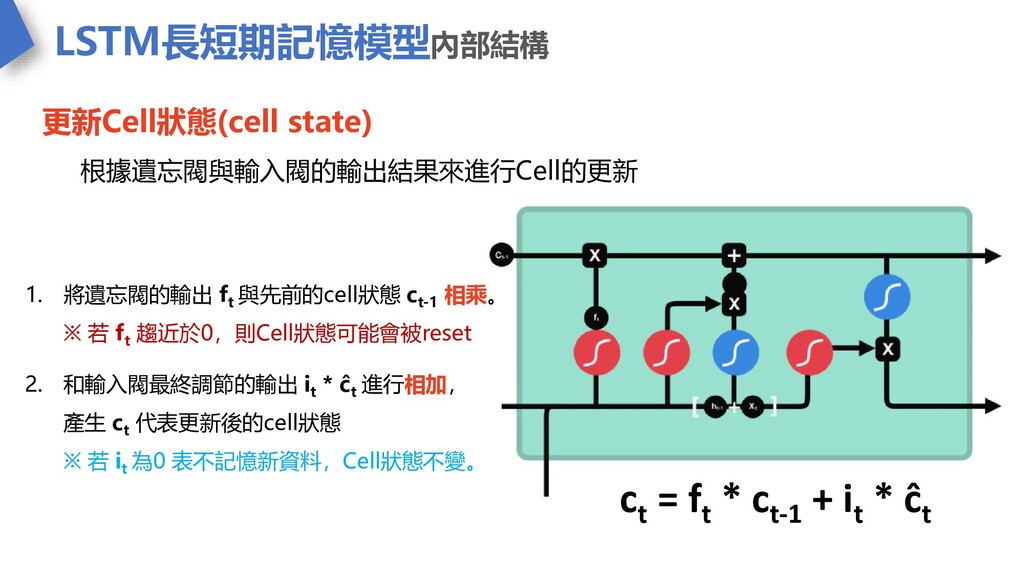
LSTM長短期記憶模型內部結構 更新Cell狀態(cell state) 根據遺忘閥與輸入閥的輸出結果來進行Cell的更新 1. 將遺忘閥的輸出 f t 與先前的cell狀態 c
t-1 相乘。 ※ 若 f t 趨近於0,則Cell狀態可能會被reset 2. 和輸入閥最終調節的輸出 i t * ĉ t 進行相加, 產生 c t 代表更新後的cell狀態 ※ 若 i t 為0 表不記憶新資料,Cell狀態不變。 ct = ft * ct-1 + it * ĉt
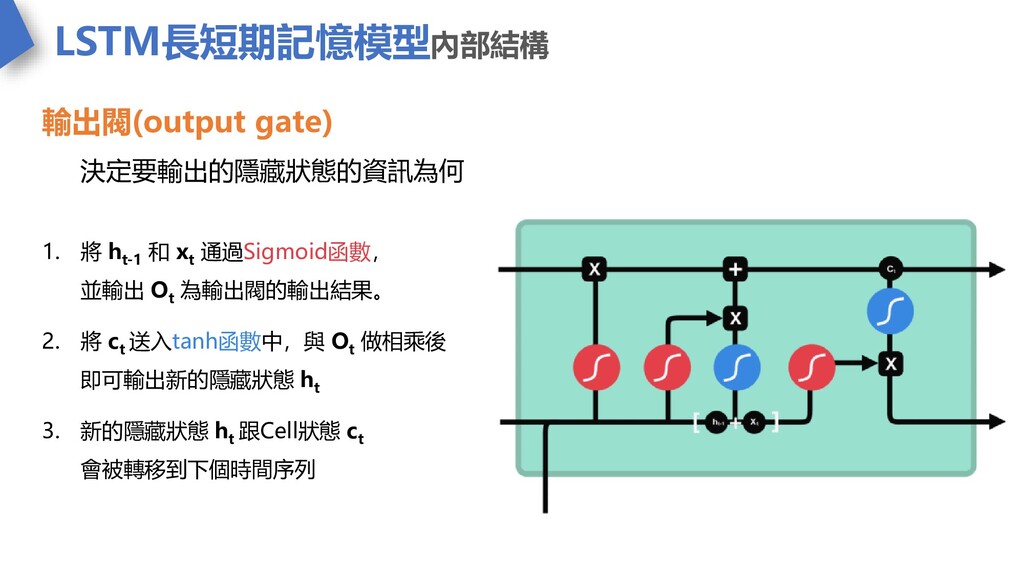
LSTM長短期記憶模型內部結構 輸出閥(output gate) 決定要輸出的隱藏狀態的資訊為何 1. 將 h t-1 和 x
t 通過Sigmoid函數, 並輸出 O t 為輸出閥的輸出結果。 2. 將 c t 送入tanh函數中,與 O t 做相乘後 即可輸出新的隱藏狀態 h t 3. 新的隱藏狀態 h t 跟Cell狀態 c t 會被轉移到下個時間序列
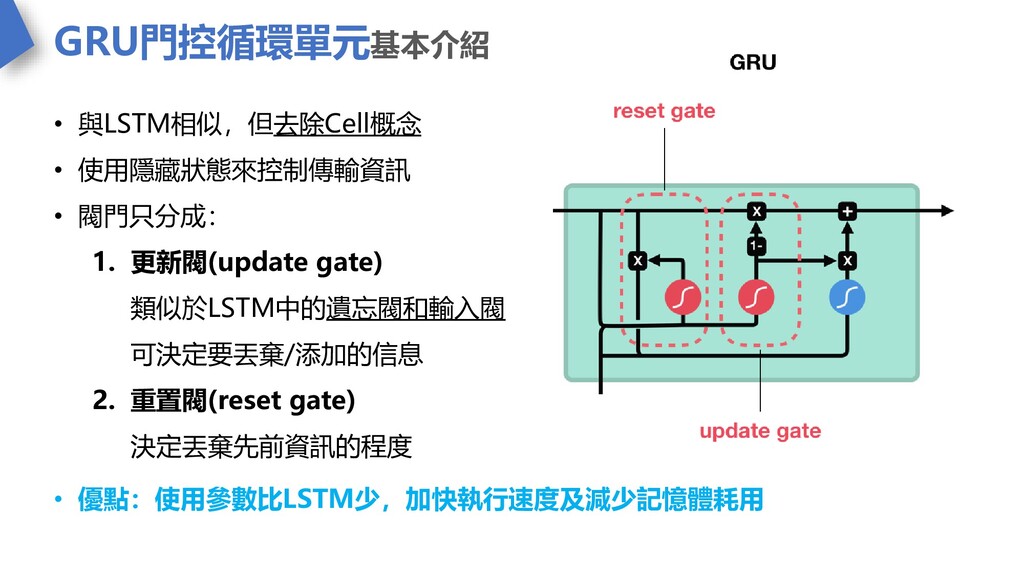
GRU門控循環單元基本介紹 • 與LSTM相似,但去除Cell概念 • 使用隱藏狀態來控制傳輸資訊 • 閥門只分成: 1. 更新閥(update gate)
類似於LSTM中的遺忘閥和輸入閥 可決定要丟棄/添加的信息 2. 重置閥(reset gate) 決定丟棄先前資訊的程度 • 優點:使用參數比LSTM少,加快執行速度及減少記憶體耗用
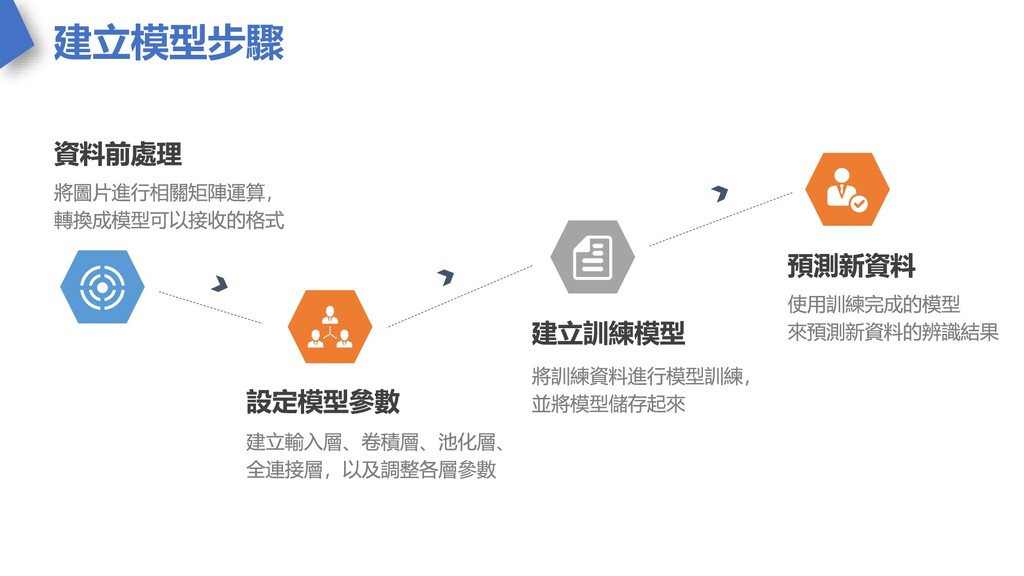
建立模型步驟
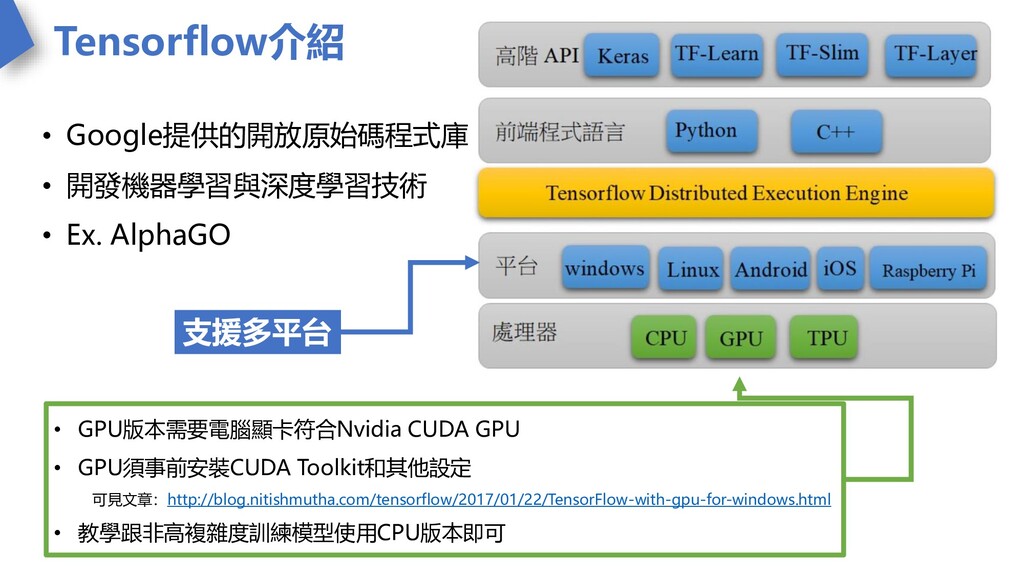
Tensorflow介紹 • Google提供的開放原始碼程式庫 • 開發機器學習與深度學習技術 • Ex. AlphaGO • GPU版本需要電腦顯卡符合Nvidia
CUDA GPU • GPU須事前安裝CUDA Toolkit和其他設定 可見文章:http://blog.nitishmutha.com/tensorflow/2017/01/22/TensorFlow-with-gpu-for-windows.html • 教學跟非高複雜度訓練模型使用CPU版本即可 支援多平台
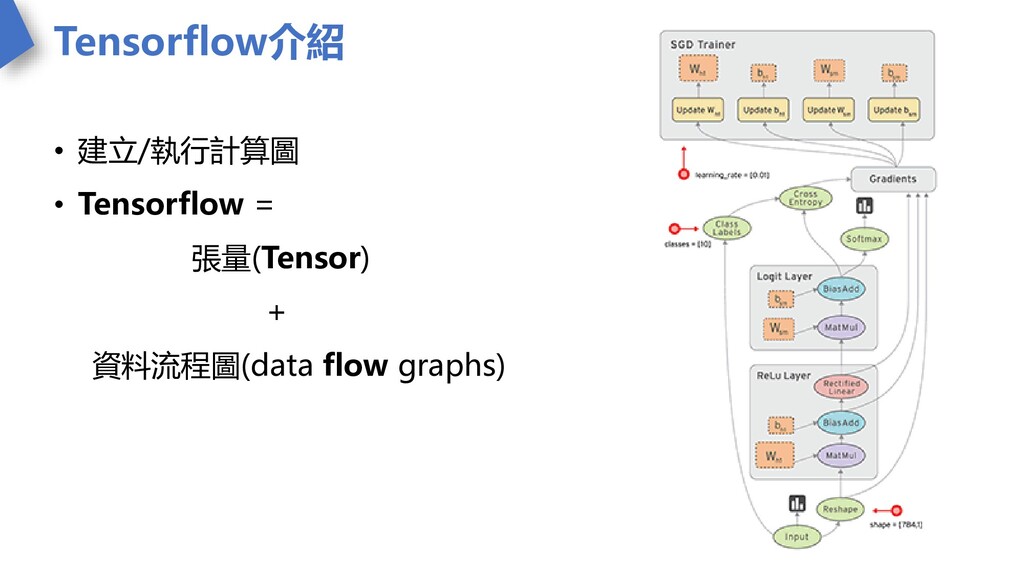
Tensorflow介紹 • 建立/執行計算圖 • Tensorflow = 張量(Tensor) + 資料流程圖(data flow
graphs)
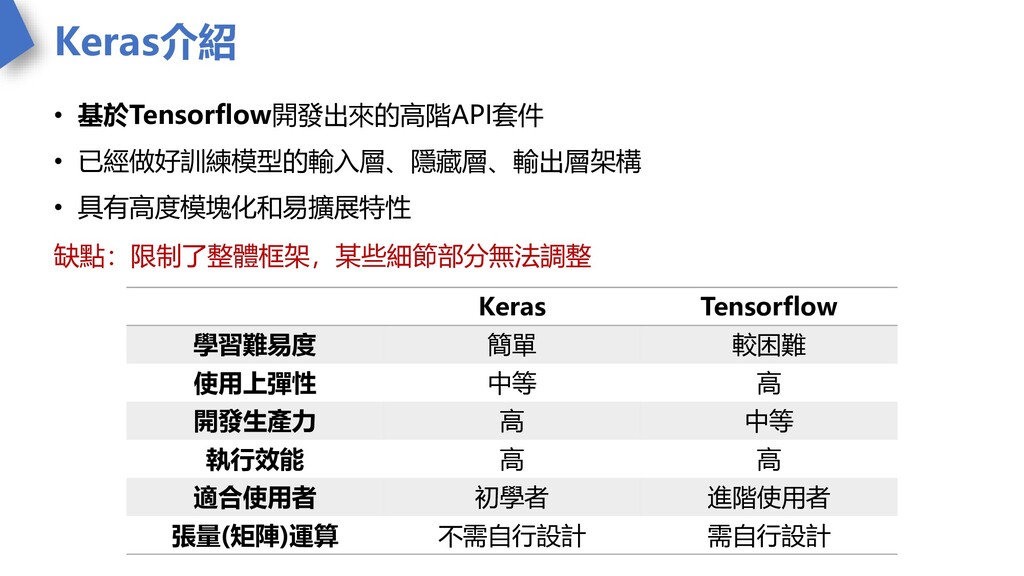
Keras介紹 • 基於Tensorflow開發出來的高階API套件 • 已經做好訓練模型的輸入層、隱藏層、輸出層架構 • 具有高度模塊化和易擴展特性 缺點:限制了整體框架,某些細節部分無法調整 Keras Tensorflow
學習難易度 簡單 較困難 使用上彈性 中等 高 開發生產力 高 中等 執行效能 高 高 適合使用者 初學者 進階使用者 張量(矩陣)運算 不需自行設計 需自行設計
Tensorflow、Keras安裝 • 建立python版本3.7的虛擬環境
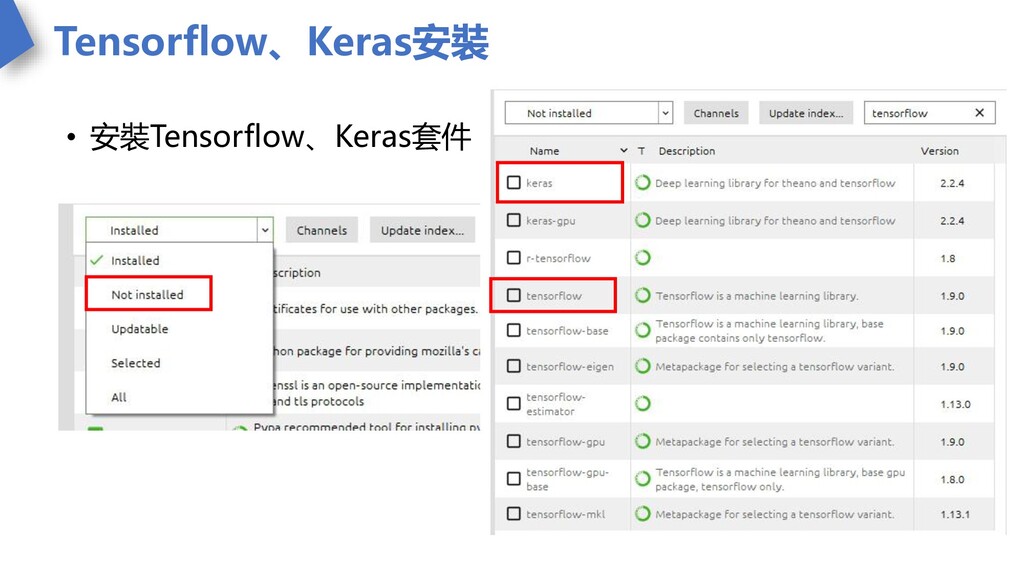
Tensorflow、Keras安裝 • 安裝Tensorflow、Keras套件
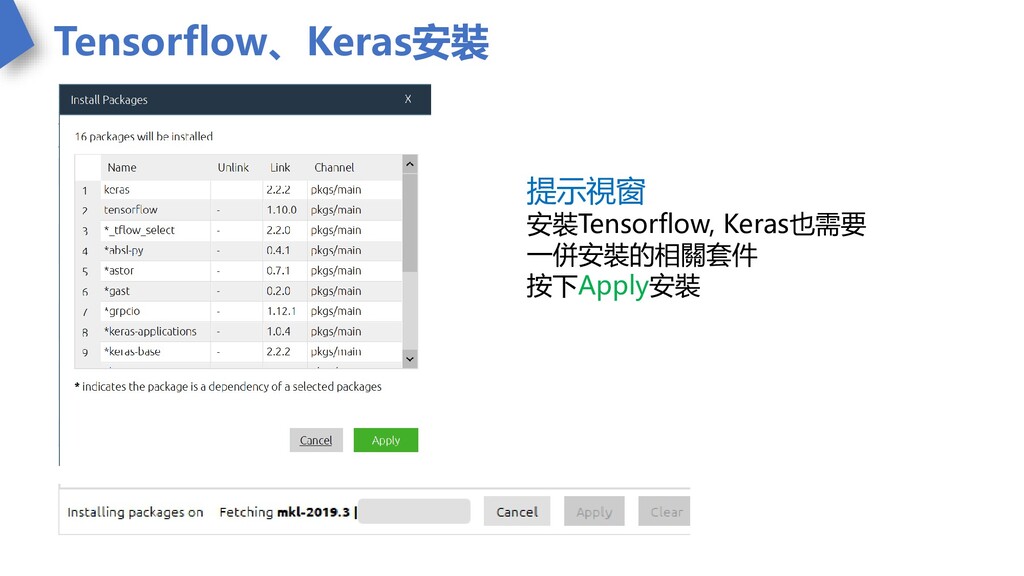
Tensorflow、Keras安裝 提示視窗 安裝Tensorflow, Keras也需要 一併安裝的相關套件 按下Apply安裝
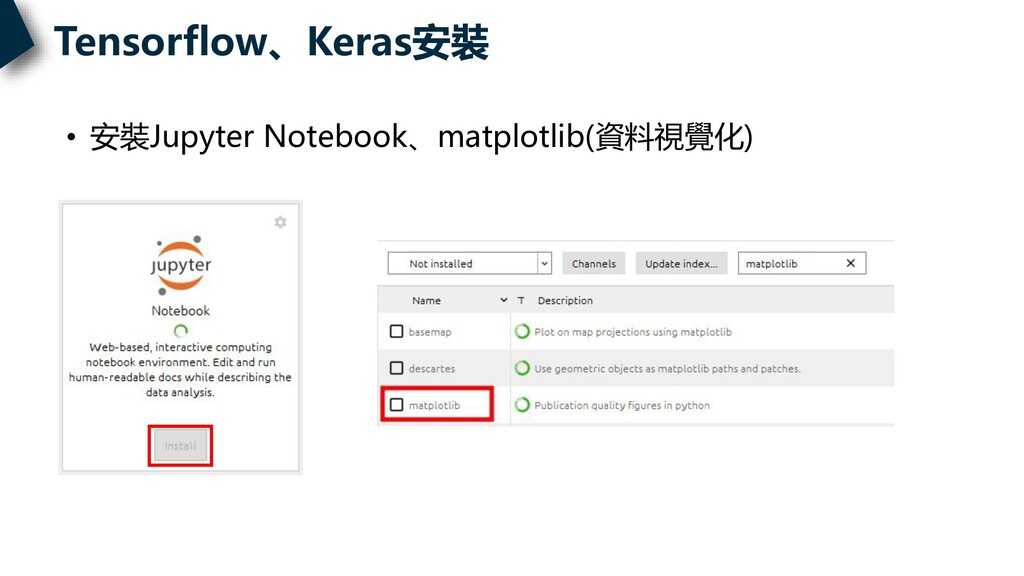
Tensorflow、Keras安裝 • 安裝Jupyter Notebook、matplotlib(資料視覺化)
測試運行 • 試執行以下程式碼 import tensorflow as tf Import keras hw
= tf.constant("Hello World") with tf.Session() as sess: print(sess.run(hw))
實作MLP 辨識MNIST圖片
MNIST辨識手寫數字 • 機器學習領域最有名的資料集之一 • 包含 70000 個 0~9 手寫阿拉伯數字的BMP格式圖檔 與其正確之標籤
(Label, 即圖檔對應之 0~9 數字), • 前 60000 個為訓練樣本, 用來訓練神經網路以建立模型 • 其餘 10000 個為測試樣本, 用來檢驗模型是否能正確預測圖片的數字 • 資料集的每張圖片解析度為 28*28 (784 pixel) • 皆為灰階影像, 每個像素為 0~255 之數值 28 28
from keras.models import Sequential from keras.layers import Dense, Activation, Dropout
from keras.utils import np_utils import numpy as np %matplotlib inline import matplotlib.pyplot as plt (x_train_image, y_train_label), (x_test_image, y_test_label) = mnist.load_data() MNIST辨識手寫數字-MLP資料準備 from keras.datasets import mnist # Keras:建立訓練模型 # keras.datasets:載入MNIST資料集 # 呼叫 load_data() 載入 MNIST 資料集 # Numpy:矩陣運算 # matplotlib.pyplot 將資料視覺化,可以圖表呈現結果 會自動檢查.keras 子目錄是否已有 mnist.npz 資料檔, 有的話就直接載入, 否則會自動下載資料檔並存放在.keras 子目錄 >目錄: C:\使用者\user_id\.keras\dataset\ load_data() 傳回值是兩組 tuple (其元素為串列), 第一組是訓練資料, 第二組是測試資料, 前為圖片 (image), 後為標籤 (label)
MNIST辨識手寫數字-MLP資料前處理 nb_classes = 10 # 類別的數目 x_train_image = x_train_image.reshape(60000, 784).astype('float32')
x_test_image = x_test_image.reshape(10000, 784).astype('float32') # 將 28*28 的圖片資料攤平 (784 = 28*28) label(數字的真實的值)以Onehot encoding轉換 y_train_cat = np_utils.to_categorical(y_train_label, nb_classes) y_test_cat = np_utils.to_categorical(y_test_label, nb_classes) 數字影像標準化:除以255 (因為圖像的像素點介於0~255之間,可讓所有的特徵值介於0與1之間) → 標準化除了可提昇模型預測的準確度,梯度運算時也能更快收斂。 x_train_image /= 255 x_test_image /= 255 # 將資料範圍縮減至 0 ~ 1
MNIST辨識手寫數字-MLP建立模型 model = Sequential() model.add(Dense(50, input_shape=(784,))) model.add(Dense(units=nb_classes)) model.add(Activation('softmax')) 先實例化一個優化器對象 設置隱藏層、激勵函數
Sequential 模型是多個網路的線性堆疊 可當作模型容器並使用.add()來快速推疊層級 # 模型第一層需要提供input_shape參數來指定輸入尺寸 # 設定輸出分類結果總數為10 (nb_classes=10) # 設置激勵函數為softmax,可表示這個樣本屬於各類的概率 Dense在Keras中真正意涵為全連接層,可以用來連接、整合前面的輸出, 最後目的為進行分類
MNIST辨識手寫數字-MLP建立模型 model.compile(loss=‘categorical_crossentropy’, optimizer='SGD', metrics=['accuracy']) 使用compile來定義損失函數、優化函數及成效衡量指標 model.summary() 模型做總結(打包的感覺) # 可以使用print()查看模型各層設定 #
loss:函數使用深度學習中常用的cross entropy(交叉熵) # optimizer:採用最基本的隨機梯度下降法SGD / # metrics:模型的評估方式則以accuracy為主
MNIST辨識手寫數字-MLP打印模型歷程 epochs = 10 history = model.fit(x_train_image, y_train_cat, epochs=epochs, batch_size=128,
verbose=1) 開始訓練,設定周期數與相關設定 # epochs 代表訓練的週期 (將6萬筆資料訓練過一次稱為1個epoch) # batch_size 代表每一批訓練了多少筆資料 # verbose 訓練日誌顯示模式 (0 =安靜模式, 1 =進度條, 2 =每輪一行)
MNIST辨識手寫數字-MLP打印圖表與評估準確率 開始訓練,設定周期數與相關設定 plt.figure(figsize=(5,3)) plt.plot(history.epoch,history.history['loss']) plt.title('loss') plt.figure(figsize=(5,3)) plt.plot(history.epoch,history.history['acc']) plt.title('accuracy'); #畫出accuracy的執行結果 #畫出loss誤差的執行結果
評估模型準確率:將測試資料放入model.evaluate()中評估模型準確率 scores = model.evaluate(x_test_image, y_test_cat, verbose=2) print("accuracy:", scores[1]*100, "%")
實作CNN 辨識MNIST圖片
MNIST辨識手寫數字-CNN資料準備 import numpy as np import pandas as pd from
keras.utils import np_utils Numpy:矩陣運算 pandas :混淆矩陣視覺呈現 Keras:建立訓練模型 from keras.datasets import mnist (x_Train , y_Train),(x_Test , y_Test) = mnist.load_data() keras.datasets:載入MNIST資料集 呼叫 load_data() 載入 MNIST 資料集
MNIST辨識手寫數字-CNN資料前處理 x_Train4D=x_Train.reshape(x_Train.shape[0],28,28,1).astype('float32') x_Test4D=x_Test.reshape(x_Test.shape[0],28,28,1).astype('float32') 將影像的特徵值轉換為4維矩陣以符合CNN要求格式:(ID, width, height, channel) # shape[0]代表第一維的長度:資料總數 #
一般RGB圖片格式為(width, height, channels) # channels為灰階,1代表單色 數字影像特徵值標準化 x_Train4D_normalize = x_Train4D / 255 x_Test4D_normalize = x_Test4D / 255 y_TrainOneHot = np_utils.to_categorical(y_Train) y_TestOneHot = np_utils.to_categorical(y_Test) label(數字的真實的值)以Onehot encoding轉換
MNIST辨識手寫數字-CNN建立模型 from keras.models import Sequential from keras.layers import Dense,Dropout,Flatten,Conv2D,MaxPooling2D model
= Sequential() model.add(Conv2D(filters=16, kernel_size=(5,5), padding=‘same’, input_shape=(28,28,1), activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) 先實例化一個優化器對象 新增一個卷積層 當使用該層作為模型第一層時,需要提供input_shape參數 # filiters 建立濾鏡(濾鏡數量,一個濾鏡會產生一個特徵圖) # kernel_size 濾鏡大小,本例設置成5X5 # padding=’same’ 卷積運算不改變圖片大小 # activation=’relu’ 設定激活函數relu 新增一個池化層:設定池化窗口為2X2
MNIST辨識手寫數字-CNN建立模型 model.add(Conv2D( filters=36, kernel_size=(5,5), padding='same', activation='relu')) model.add(MaxPooling2D(pool_size=(2,2))) model.add(Flatten()) #建立平坦層 model.add(Dense(128,
activation='relu')) #建立隱藏層 model.add(Dropout(0.5)) #Dropout model.add(Dense(10, activation='softmax')) #建立輸出層 再新增一個卷積層跟池化層 # 這裡濾鏡filiters 改為36個 全連接層部分 model.add(Dropout(0.25)) 加入Droput可避免過擬合overfitting # 使用softmax激勵函數 可表示這個樣本屬於每個類的概率 因為輸入層輸入的資料維度通常為1 所以使用Flatten()扁平層將資料壓成1維 Dense() : 全連接層, 可以看做一個基本類神經網路
MNIST辨識手寫數字-CNN建立模型 model.summary() 模型做總結(打包的感覺) # 可以使用print()查看模型各層設定 model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy']) # loss:函數使用深度學習中常用的cross entropy(交叉熵)
# optimizer:採用梯度下降法採取最常用的演算法adam # metrics:模型的評估方式則以accuracy為主 使用compile來定義定義損失函數、優化函數及成效衡量指標
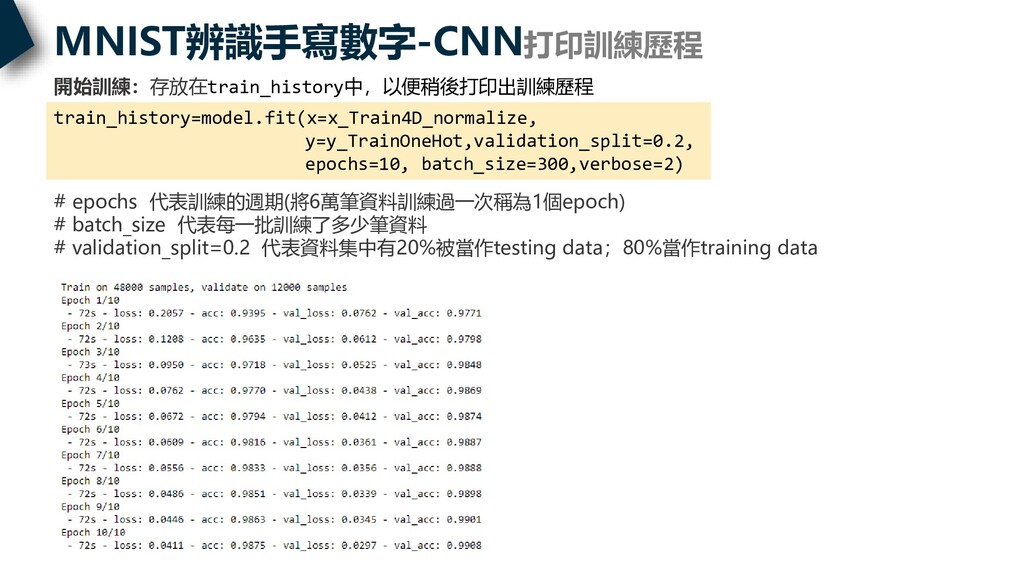
MNIST辨識手寫數字-CNN打印訓練歷程 開始訓練:存放在train_history中,以便稍後打印出訓練歷程 train_history=model.fit(x=x_Train4D_normalize, y=y_TrainOneHot,validation_split=0.2, epochs=10, batch_size=300,verbose=2) # epochs 代表訓練的週期(將6萬筆資料訓練過一次稱為1個epoch) #
batch_size 代表每一批訓練了多少筆資料 # validation_split=0.2 代表資料集中有20%被當作testing data;80%當作training data
MNIST辨識手寫數字-CNN打印訓練歷程 def show_train_history(train_history, train, validation): plt.plot(train_history.history[train]) plt.plot(train_history.history[validation]) plt.title('Train History') plt.ylabel('train')
plt.xlabel('Epoch') plt.legend(['train', 'validation'], loc='center right') plt.show() import matplotlib.pyplot as plt show_train_history(train_history, 'acc','val_acc') show_train_history(train_history, 'loss','val_loss') #畫出accuracy的執行結果 #畫出loss誤差的執行結果 matplotlib.pyplot : 將資料視覺化,可以圖表呈現結果 畫圖表 accuracy的執行結果 loss誤差的執行結果
MNIST辨識手寫數字-CNN評估準確率 評估模型準確率:將處理過的測試資料放入model.evaluate()中評估模型準確率 loss, accuracy = model.evaluate(x_Test4D_normalize , y_TestOneHot) print( "\nLoss:
%.2f, Accuracy: %.2f%%" % (loss, accuracy* 100 )) import pandas as pd prediction=model.predict_classes(x_Test4D_normalize) pd.crosstab(y_Test,prediction,rownames=['label'], colnames=['predict']) 顯示混淆矩陣:顯示測試資料預測結果統計與實際結果統計的差異 還是有些許誤判的情況 橫向為預測結果 縱向為實際結果
實作RNN 辨識MNIST圖片
MNIST辨識手寫數字-RNN資料準備 from keras.models import Sequential from keras.layers import Dense, Activation,
Dropout from keras.layers.recurrent import SimpleRNN, LSTM, GRU from keras.utils import np_utils %matplotlib inline import numpy as np import matplotlib.pyplot as plt 引入相關套件 from keras.datasets import mnist (x_Train , y_Train),(x_Test , y_Test) = mnist.load_data() nb_classes = 10 img_rows, img_cols = 28, 28 # 圖片的長與寬 一樣匯入資料集,設定分類數量、圖片尺寸
MNIST辨識手寫數字-RNN資料準備 X_train = X_train.astype('float32') X_test = X_test.astype('float32') X_train /= 255
X_test /= 255 壓縮圖片顏色至0~1 Y_train = np_utils.to_categorical(y_train, nb_classes) Y_test = np_utils.to_categorical(y_test, nb_classes) 根據分類數量,將圖片標籤轉成one-hot encoding格式的陣列(長度為10)
MNIST辨識手寫數字-RNN建立模型 nb_units = 50 model = Sequential() 新增雛形 model.add(LSTM(nb_units, input_shape=(img_rows,
img_cols))) 建立LSTM的模型 # 設定隱藏層節點50個 # 建立簡單的線性執行的模型 # 設定隱藏層節點50 # input_shape的二個維度 (time_steps, input_dim) model.add(Dense(units=nb_classes)) model.add(Activation('softmax')) 建立輸出層 timesteps 簡單的理解就是輸入序列的長度 (有幾個) input_dim 是序列的內容數目 設定分類數量還有激勵函數
MNIST辨識手寫數字-RNN模型訓練 model.compile(loss='categorical_crossentropy', optimizer='SGD', metrics=['accuracy']) print(model.summary()) 使用compile來定義定義損失函數、優化函數及成效衡量指標 並列出模型的各層設定 epochs = 10
history = model.fit(X_train, Y_train, epochs=epochs, batch_size=128, verbose=1) 設定週期數,開始訓練模型
MNIST辨識手寫數字-RNN模型訓練 plt.figure(figsize=(5,3)) plt.plot(history.epoch,history.history['loss']) plt.title('loss') plt.figure(figsize=(5,3)) plt.plot(history.epoch,history.history['acc']) plt.title('accuracy'); 打印圖表 scores =
model.evaluate(X_test, Y_test, verbose=2) print(scores[1]*100, "%") 顯示準確率 有點低,試著調參!
MNIST辨識手寫數字-RNN調整模型 nb_units = 128 提高隱藏層節點數量 model.add(LSTM(nb_units)) 新增第二層LSTM 準確率上升 model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy']) 改變優化函數設定為adam 影響最大
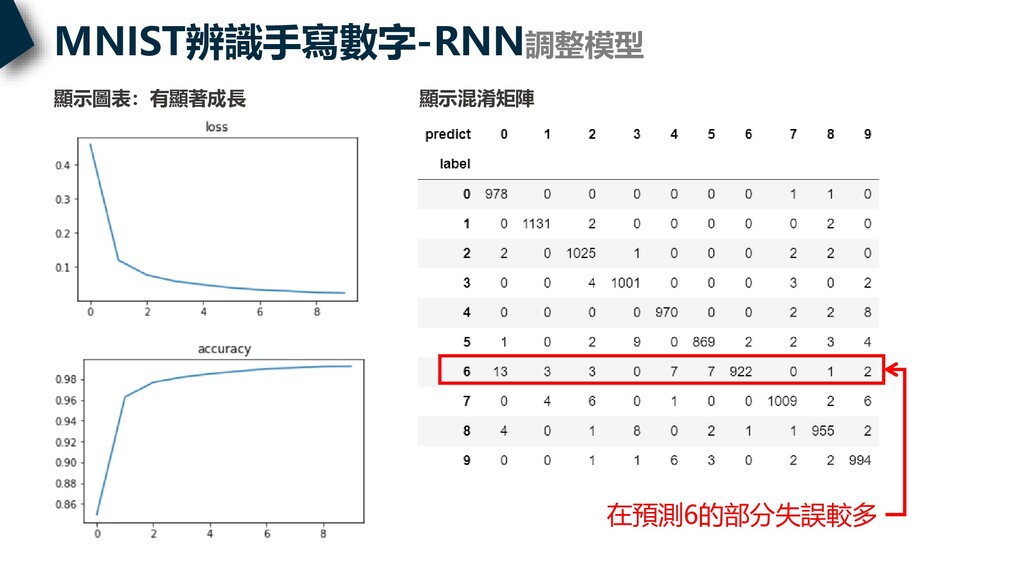
MNIST辨識手寫數字-RNN調整模型 顯示混淆矩陣 顯示圖表:有顯著成長 在預測6的部分失誤較多
![使用Tensorflow, Keras 實作MLP, CNN, RNN 圖片辨識MNIST數字資料集 助教 陳怡蓁 [email protected]](https://files.speakerdeck.com/presentations/ff0ee0fd464741879fff6caa59af34a6/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MNIST辨識手寫數字-MLP建立模型 model.compile(loss=‘categorical_crossentropy’, optimizer='SGD', metrics=['accuracy']) 使用compile來定義損失函數、優化函數及成效衡量指標 model.summary() 模型做總結(打包的感覺) # 可以使用print()查看模型各層設定 #](https://files.speakerdeck.com/presentations/ff0ee0fd464741879fff6caa59af34a6/slide_37.jpg){kind=link}
{kind=link}
![MNIST辨識手寫數字-MLP打印圖表與評估準確率 開始訓練,設定周期數與相關設定 plt.figure(figsize=(5,3)) plt.plot(history.epoch,history.history['loss']) plt.title('loss') plt.figure(figsize=(5,3)) plt.plot(history.epoch,history.history['acc']) plt.title('accuracy'); #畫出accuracy的執行結果 #畫出loss誤差的執行結果](https://files.speakerdeck.com/presentations/ff0ee0fd464741879fff6caa59af34a6/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
![MNIST辨識手寫數字-CNN資料前處理 x_Train4D=x_Train.reshape(x_Train.shape[0],28,28,1).astype('float32') x_Test4D=x_Test.reshape(x_Test.shape[0],28,28,1).astype('float32') 將影像的特徵值轉換為4維矩陣以符合CNN要求格式:(ID, width, height, channel) # shape[0]代表第一維的長度:資料總數 #](https://files.speakerdeck.com/presentations/ff0ee0fd464741879fff6caa59af34a6/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
![MNIST辨識手寫數字-CNN建立模型 model.summary() 模型做總結(打包的感覺) # 可以使用print()查看模型各層設定 model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy']) # loss:函數使用深度學習中常用的cross entropy(交叉熵)](https://files.speakerdeck.com/presentations/ff0ee0fd464741879fff6caa59af34a6/slide_45.jpg){kind=link}
{kind=link}
![MNIST辨識手寫數字-CNN打印訓練歷程 def show_train_history(train_history, train, validation): plt.plot(train_history.history[train]) plt.plot(train_history.history[validation]) plt.title('Train History') plt.ylabel('train')](https://files.speakerdeck.com/presentations/ff0ee0fd464741879fff6caa59af34a6/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MNIST辨識手寫數字-RNN模型訓練 model.compile(loss='categorical_crossentropy', optimizer='SGD', metrics=['accuracy']) print(model.summary()) 使用compile來定義定義損失函數、優化函數及成效衡量指標 並列出模型的各層設定 epochs = 10](https://files.speakerdeck.com/presentations/ff0ee0fd464741879fff6caa59af34a6/slide_53.jpg){kind=link}
![MNIST辨識手寫數字-RNN模型訓練 plt.figure(figsize=(5,3)) plt.plot(history.epoch,history.history['loss']) plt.title('loss') plt.figure(figsize=(5,3)) plt.plot(history.epoch,history.history['acc']) plt.title('accuracy'); 打印圖表 scores =](https://files.speakerdeck.com/presentations/ff0ee0fd464741879fff6caa59af34a6/slide_54.jpg){kind=link}
{kind=link}
{kind=link}