why to use oracle bind value As tom says “ If I were to write a book about how to build non-scalable Oracle applications, “Don’t Use Bind Variables” would be the first and last chapter. Not using bind variables is a major cause of performance issues and a major inhibitor of scalability—not to mention a security risk of huge proportions. The way the Oracle shared pool (a very important shared-memory data structure) operates is predicated on developers using bind variables in most cases. If you want to make Oracle run slowly, even grind to a total halt, just refuse to use them. “ That’s if you don’t want to use bind values in your system. Your oracle database shared pool maybe fragmented seriously . All of cursor maybe fragmented into pieces . eg: Select * from emp where enpno=:val --- use bind value Or Select * from emp where enpno=123 -- not use bind value . In this SQL .if you put (456,789) into enpno oracle will just gather another cursor. So If you don’t use bind value your share pool may full of these cursors (think of rubbish cursors).
oracle system. (we run a bad PL/SQL procedure on user database some months ago . repeat execute one SQL for millions cause share pool’s insanity.) as you see, user database is a very powerful system running on IBM power machine of 256GB memory and NetAPP storage. But just one PL/SQL cause database crash immediate. So just one word “if you want to build a very bad system, pls don’t use bind values” 1.2 some oracle bind value tips 1.2.1 Peeking of User-Defined Bind Variables The query optimizer peeks at the values of user-defined bind variables on the first invocation of a cursor. This feature enables the optimizer to determine the selectivity of any where clause condition as if literals have been used instead of bind variables. Oracle determine the actual value for the first time. When we run the same sql again. The gathered SQL PLAN will used for this query. These behavior will cause problem on some system. Like on a extremely uneven division table (data is uneven) Bad SQL PLAN may gathered in the first time and will be used always.
setting : “_optim_peek_user_binds” =FALSE From oracle metalink docs For queries with range predicates using bind variables, we have no way of calculating the selectivity, so we use a hardcoded default value of 5% This is true irrespective of histograms as CBO does not know the value of the bind variable. Selectivity for bind variables with 'like' predicates defaults to 25% Selectivity ~~~~~~~~~~~ Selectivity is a measure of the proportion of a row source retrieved by application of a particular predicate or combination of predicates. Within the Oracle kernel it is expressed as a value between 0 and 1. The closer the value is to 0 the more selective the predicate is. Selectivity is only used by the CBO. Basic Selectivity formula: ~~~~~~~~~~~~~~~~~~~~~~~~~~ Number of records satisfying a condition Selectivity = -----------------------------------------
used to compare the usefulness of various predicates in combination with base object costs. Knowing the proportion of the total data set that a column predicate defines is very helpful in defining actual access costs. By default, column selectivity is based on the high and low values and the number of values in the column with an assumption of even distribution of data between these two points. Histogram data can give better selectivity estimates for unevenly distributed column data. There is more discussion regarding Histograms later. Selectivity is also used to define the cardinality of a particular row source once predicates have been applied. Cardinality is the expected number of rows that will be retrieved from a row source. Cardinality is useful in determining nested loop join and sort costs. Application of selectivity to the original cardinality of the row source will produce the expected (computed) cardinality for the row source. Glossary of Terms: ~~~~~~~~~~~~~~~~~~
Selectivity Proportion of a dataset returned by a particular predicate(or group of predicates) In the following illustrations there are 2 tables (T1 & T2) with columns (c1) and (c2) respectively. Selectivities: ~~~~~~~~~~~~~~ Without histograms ~~~~~~~~~~~~~~~~~~ c1 = '4076' 1/NDV c1 > '4076' 1 - (High - Value / High - Low) c1 >= '4076' 1 - (High - Value / High - Low) + 1/NDV c1 like '4076' 1/NDV Join selectivity ~~~~~~~~~~~~~~~~ The selectivity of a join is defined as the selectivity of the most selective join column adjusted by the proportion of not null values in each join column. Sel = 1/max[NDV(t1.c1),NDV(t2.c2)] * ( (Card t1 - # t1.c1 NULLs) / Card t1) * ( (Card t2 - # t2.c2 NULLs) / Card t2)
case because the optimizer has no idea what the bind variable value is prior to query optimization. This does not present a problem with equality predicates since a uniform distribution of data is assumed and the selectivity is taken as 1/NDV for the column. However for range predicates it presents a major issue because the optimizer does not know where the range starts or stops. Because of this the optimizer has to make some assumptions as follows: c1 = :bind1 1/NDV c1 > :bind1 Default of 5% c1 >= :bind1 Default of 5% c1 like :bind1 Default of 25% For more information on bind variables see Note:70075.1 Selectivity With Histograms ~~~~~~~~~~~~~~~~~~~~~~~~~~~ Histograms provide additional information about column selectivity for columns whose distribution is non uniform. Histograms store information about column data value ranges. Each range is stored in a single row and is often called a 'bucket'. There are 2 different methods for storing histograms in Oracle. If there are a small number of distinct column values (i.e. less than the number of buckets), the column value
not then a series of endpoints are stored to enable more accurate selectivity to be determined. The first method allows the accurate figures to be used. However with inexact histograms the terms popular and non-popular value are introduced and are used to help determine selectivity. A popular value is a value that spans multiple endpoints whereas a non-popular value does not. See Note:72539.1 for more information on histograms. Exact histograms ~~~~~~~~~~~~~~~~ c1 = '4706' count of value '4076' / Total Number of Rows c1 > value count of values > '4076' / Total Number of Rows InExact Histograms ~~~~~~~~~~~~~~~~~~ col = pop value # popular buckets / # buckets col = non pop (Density) col > value # buckets > value / # buckets Rules for combining selectivity ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Let P1 and P2 be 2 distinct predicates of query Q
OR P2 S(P1|P2) = S(P1) + S(P2) -[S(P1) * S(P2)] So exact Histograms information is very important for oracle CBO to choose better SQL PLAN. We can check this post wrote by Huang wei for deep understand : http://www.hellodba.com/reader.php?ID=55&lang=cn 1.2.2 bind graduation “The aim of this feature is to minimize the number of child cursors by graduating bind variables (which vary in size) into four groups depending on their size. The first group contains the bind variables with up to 32 bytes, the second contains the bind variables between 33 and 128 bytes, the third contains the bind variables between 129 and 2,000 bytes, and the last contains these bind variables of more than 2,000 bytes. Bind variables of datatype NUMBER are graduated to their maximum length, which is 22 bytes. As the following example shows, the view v$sql_bind_metadata displays the maximum size of a group.” Bind graduation can cause more bind peeking .But these behavior may not be bad for oracle that can choose better SQL PLAN for particular SQL. Bind graduation can also cause some problem like more version count of child cursor.
(eg: in code directly declare varchar2(2000) for all) to avoid this problem. Ref : http://www.vmcd.org/2012/11/oracle-bind-graduation-%E6%B5%8B%E8%AF%95/ 1.2.3 Adaptive cursor sharing 11g In oracle 11g ,oracle introduce adaptive cursor sharing (ACS) to avoid some bind peeking problem With just bind peeking (prior to 11g),ACS will not just choose the first SQL Plan gathered by the first bind peeking but take more peeking to gather more efficient plan, and ACS also choose wrong SQL PLAN. The nature of ACS is --do more peeking for better SQL PLAN. is_bind_sensitive indicates not only whether bind variable peeking was used to generate the execution plan but also whether the execution plan depends on the peeked value. If this is the case, the column is set to Y; otherwise, it’s set to N. is_bind_aware indicates whether the cursor is using extended cursor sharing. If yes, the column is set to Y; if not, it’s set to N. If set to N, the cursor is obsolete, and it will no longer be used. is_shareable indicates whether the cursor can be shared. If it can, the column is set to Y; otherwise, it’s set to N. If set to N, the cursor is obsolete, and it will no longer be used. We use (v$sql_cs_statistics v$sql_cs_selectivity v$sql_cs_histogram) three views to check ACS statistics. In our system ACS and peeking bind both closed by setting: alter system set "_optim_peek_user_binds"=false; alter system set "_optimizer_extended_cursor_sharing_rel"=none; alter system set "_optimizer_extended_cursor_sharing"=none; alter system set "_optimizer_adaptive_cursor_sharing"=false; alter system set cursor_sharing=exact;
using peeking bind value , oracle maybe choose bad SQL PLAN .In that time use bind value may cause many problem. In this situation : http://www.hellodba.com/reader.php?ID=113&lang=cn Imagine that (one column 'A' just has two values 1,2 9999999999 for 1 and 1 for 2 and most query choose 2 for conditions , so in this situation oracle may choose FTS, seems that in 11g with ACS will solve this problem) Ref : BindPeeking.PPT When a user selects all rows that have an id of less than 990, the query optimizer knows (thanks to object statistics) that about 99 percent of the table is selected. Therefore, it chooses an execution plan with a full table scan. Also notice how the estimated cardinality (column Rows in the execution plan) corresponds to the number of rows returned by the query. “While using bind variables in WHERE clauses, crucial information is hidden from the query optimizer. With literals, it is able to improve its estimations. This is especially true when it checks whether a value is outside the range of available values (that is, lower than the minimum value or higher than the maximum value stored in the column) and when it takes advantage of histograms. To illustrate, let’s take a table t with 1,000 rows that store, in the column id, the values between 1 (the minimum value) and 1,000 (the maximum value): When a user selects all rows that have an id of less than 990, the query optimizer knows (thanks to object statistics) that about 99 percent of the table is selected. Therefore, it chooses an execution plan with a full table scan. Also notice how the estimated cardinality (column Rows in the execution plan) corresponds to the number of rows returned by the query.
id of less than 10, the query optimizer knows that only about 1 percent of the table is selected. Therefore, it chooses an execution plan with an index scan. Also in this case, notice the good estimation. Of course, as shown in the following example, if the first execution takes place with the value 10, the query optimizer chooses an execution plan with the index scan—and that, once more, occurs for both queries. Note that to avoid sharing the cursor used for the previous example, the queries were written in lowercase letters.“
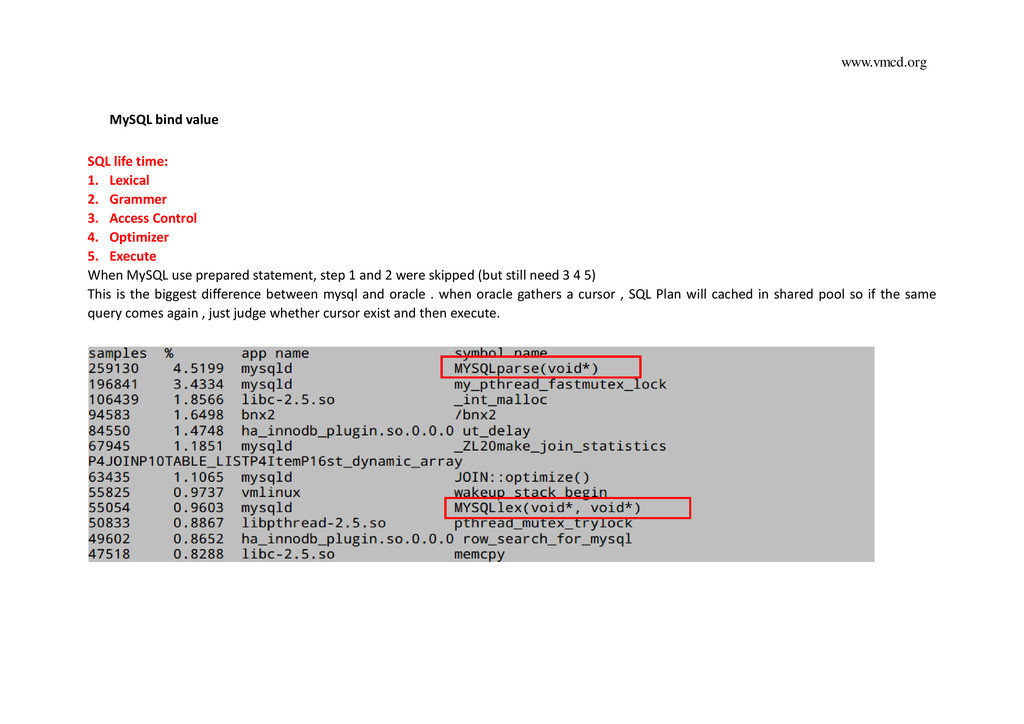
Grammer 3. Access Control 4. Optimizer 5. Execute When MySQL use prepared statement, step 1 and 2 were skipped (but still need 3 4 5) This is the biggest difference between mysql and oracle . when oracle gathers a cursor , SQL Plan will cached in shared pool so if the same query comes again , just judge whether cursor exist and then execute.
to cache sqlstatement on java site even avoid to use soft soft parse (cached on oracle PGA ) And in 11g oracle even support server-side cache(like mysql query cache) and client-side cache Ref : http://docs.oracle.com/cd/B28359_01/server.111/b28274/memory.htm#PFGRF10121 http://www.laoxiong.net/oracle-jdbc-statement-cache.html Server-side Cache Support for server-side Result Set caching has been introduced for both JDBC Thin and JDBC Oracle Call Interface (OCI) drivers since Oracle Database 11g Release 1 (11.1). The server-side result cache is used to cache the results of the current queries, query fragments, and PL/SQL functions in memory and then to use the cached results in future executions of the query, query fragment, or PL/SQL function. The cached results reside in the result cache memory portion of the SGA. A cached result is automatically invalidated whenever a database object used in its creation is successfully modified. The server-side caching can be of the following two types: SQL Query Result Cache PL/SQL Function Result Cache Client Result Cache Since Oracle Database 11g Release 1 (11.1), support for client result cache has been introduced for JDBC OCI driver. The client result cache improves performance of applications by caching query result sets in a way that subsequent query executions can access the cached result set without fetching rows from the server. This eliminates many round-trips to the server for cached results and reduces CPU usage on the server. The client cache transparently keeps the result set consistent with any session state or database changes that can affect its cached result sets. This allows significant improvements in response time for frequent client SQL query
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}