Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Benetechコンペ参戦記
Search
YumeNeko
September 22, 2023
3.5k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Benetechコンペ参戦記
2023/9/23 関東kggler会の講演用資料です。
YumeNeko
September 22, 2023
More Decks by YumeNeko
See All by YumeNeko
IMC2025振り返り会 How can we win at IMC2025?
yumeneko
0
790
第2回関東kaggler会 LT コンペ振り返りのすすめ
yumeneko
2
4.1k
[第4回 Data-Centric AI勉強会] Benetechコンペ エラー分析によるデータ追加とアノテーションの工夫について
yumeneko
1
590
Featured
See All Featured
ラッコキーワード サービス紹介資料
rakko
1
3.8M
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
Exploring anti-patterns in Rails
aemeredith
3
440
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
Building Adaptive Systems
keathley
44
3.1k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
180
The Spectacular Lies of Maps
axbom
PRO
1
850
Believing is Seeing
oripsolob
1
160
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
180
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.1k
Transcript
Benetechコンペ参戦記 2023/9/23 関東kaggler会 @ゆめねこ
自己紹介 1 名前:ゆめねこ(@yume_neko92) 仕事:主に画像系のAIシステム開発 @東北 趣味:最近は狩りがブーム(モンハンnow) ドラマも好き(VIVANT面白かった) kaggle:kaggle歴は2年弱くらい Competitions Master
・HNの由来の親戚家のネコ。 ・とても可愛い。 ・ちゅ~るをちょこちょこ貢いでいる。 ・が、あまり懐いてもらえてない。悲しい。
参加コンペ遍歴 2
参加コンペ遍歴 3 今日はこのコンペの話をします
コンペ概要 4
コンペ概要:タスク • グラフ画像から、チャートタイプとデータ系列を予測するタスク • ざっくり言うと、グラフ版OCR • グラフ画像を入力、グラフの種類とX,Yのデータ値を出力 5
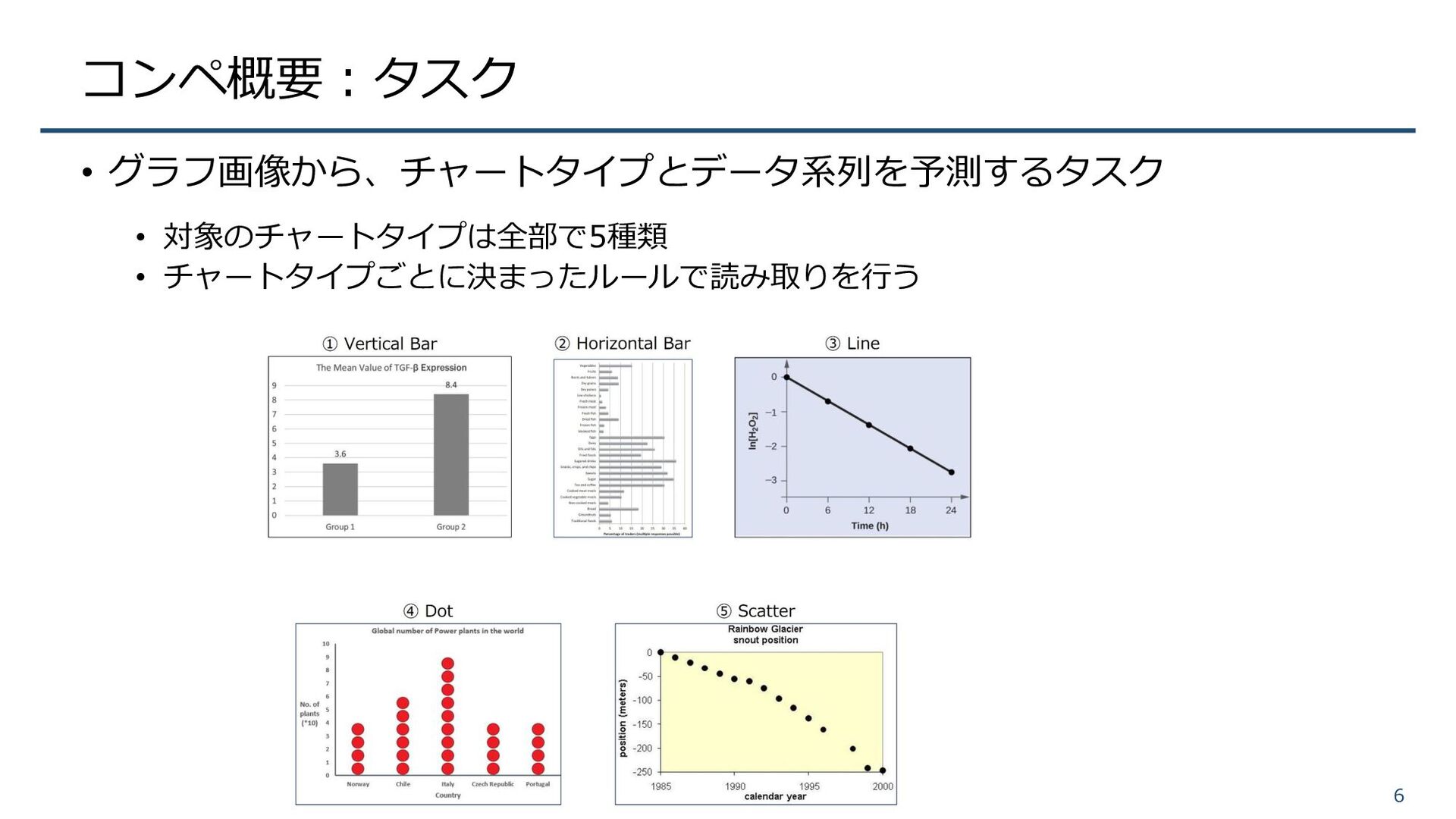
コンペ概要:タスク • グラフ画像から、チャートタイプとデータ系列を予測するタスク • 対象のチャートタイプは全部で5種類 • チャートタイプごとに決まったルールで読み取りを行う 6
コンペ概要:データ • コンペデータとして約60000枚の画像が提供 • 実際の論文から抽出された抽出画像は約1000枚 • 残りの59000枚は人工的に作成した生成画像 • テストデータはすべて抽出画像で構成される •
Publicは学習データと同じデータソースから収集された抽出画像 • Privateは学習データとは異なるデータソースから収集された抽出画像 • ロバスト性を保ちながら精度を上げる必要がある 7 抽出画像例 生成画像例
コンペ概要:評価指標 • 系列ごとの類似度スコアの平均が評価指標 • 類似度は系列が数値の場合はRMSE、文字列の場合はレーベンシュタイン距離で算出 • 0.0~1.0の範囲で出力されていて、1.0に近いほど良いスコアと思ってもらえればOK • チャートタイプの予測が一致していないとスコアは0 •
予測した点の数がGTと完全に一致していないとスコアは0 8 GT Type: VerticalBar X: [“Group1”, “Group2”] Pred1 Type: VerticalBar X: [“Grouq1”, “Gruop2”] X_gt: [“Group1”, “Group2”] X_pred: [“Grouq1”, “Gruop2”] Lev Dists 1 2 𝑠𝑐𝑜𝑟𝑒 = 𝑠𝑖𝑔𝑚𝑜𝑖𝑑 σ𝑖 𝐿𝑒𝑣𝑖 𝑙𝑒𝑛 𝑥𝑖 = 0.876 Pred2 Type: HorizontalBar X: [“Group1”, “Group2”] 𝑠𝑐𝑜𝑟𝑒 = 0.0 Pred3 Type: VerticalBar X: [“Group1”, “Group2”, “Group3”] 𝑠𝑐𝑜𝑟𝑒 = 0.0
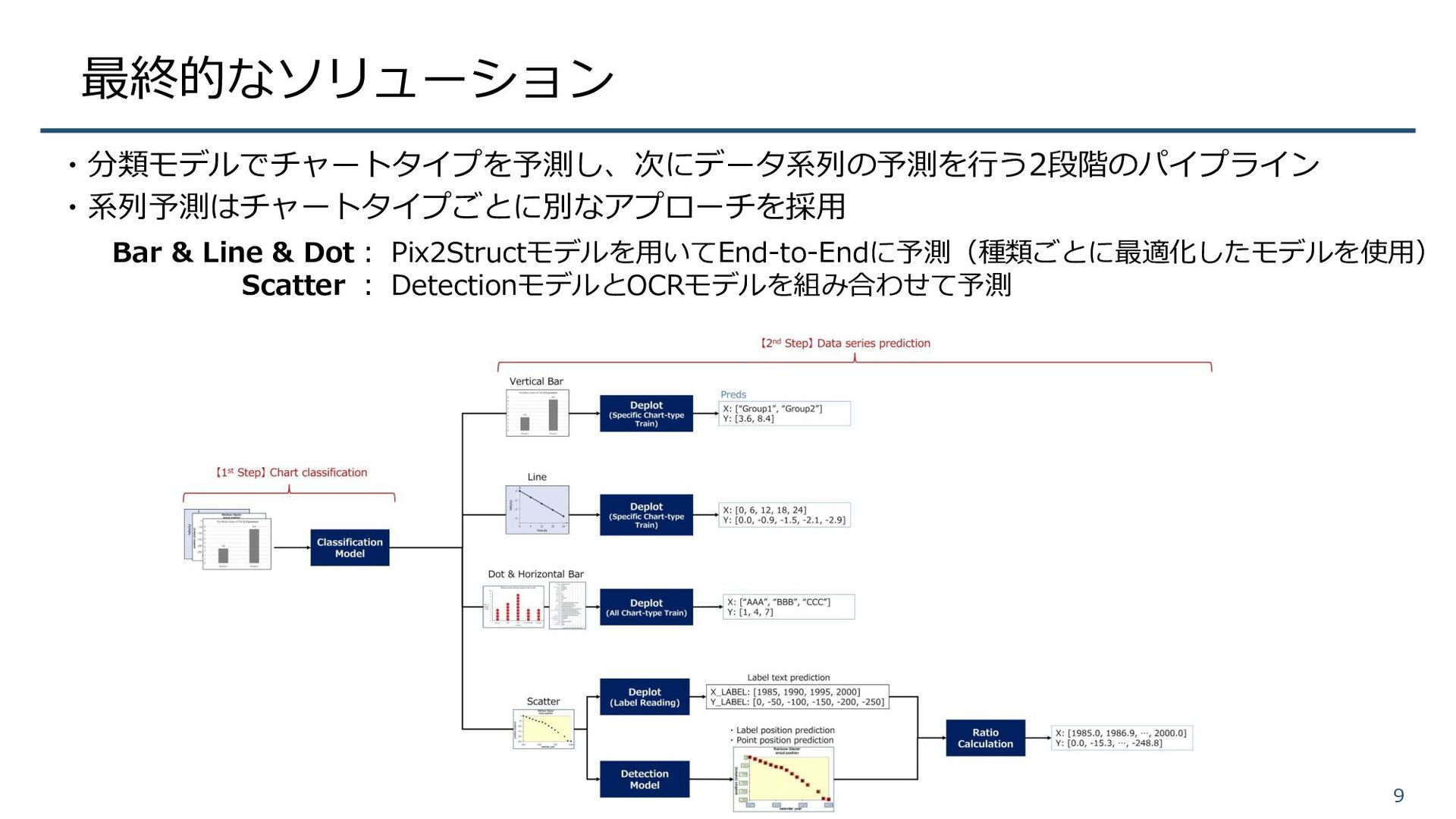
最終的なソリューション 9 ・分類モデルでチャートタイプを予測し、次にデータ系列の予測を行う2段階のパイプライン ・系列予測はチャートタイプごとに別なアプローチを採用 Bar & Line & Dot: Pix2Structモデルを用いてEnd-to-Endに予測(種類ごとに最適化したモデルを使用)
Scatter : DetectionモデルとOCRモデルを組み合わせて予測
コンペ参戦記 10
はじめに 11 • 今回はどんなことを考えてコンペに取り組んでいたか時系列的にお話しします [Public LBの推移] ベースライン作成 初期改善案検討 モデル変更による スコア改善
エラー解析による スコア改善 学習ログ解析による スコア改善 4/15 5/4 5/28 6/14 6/19
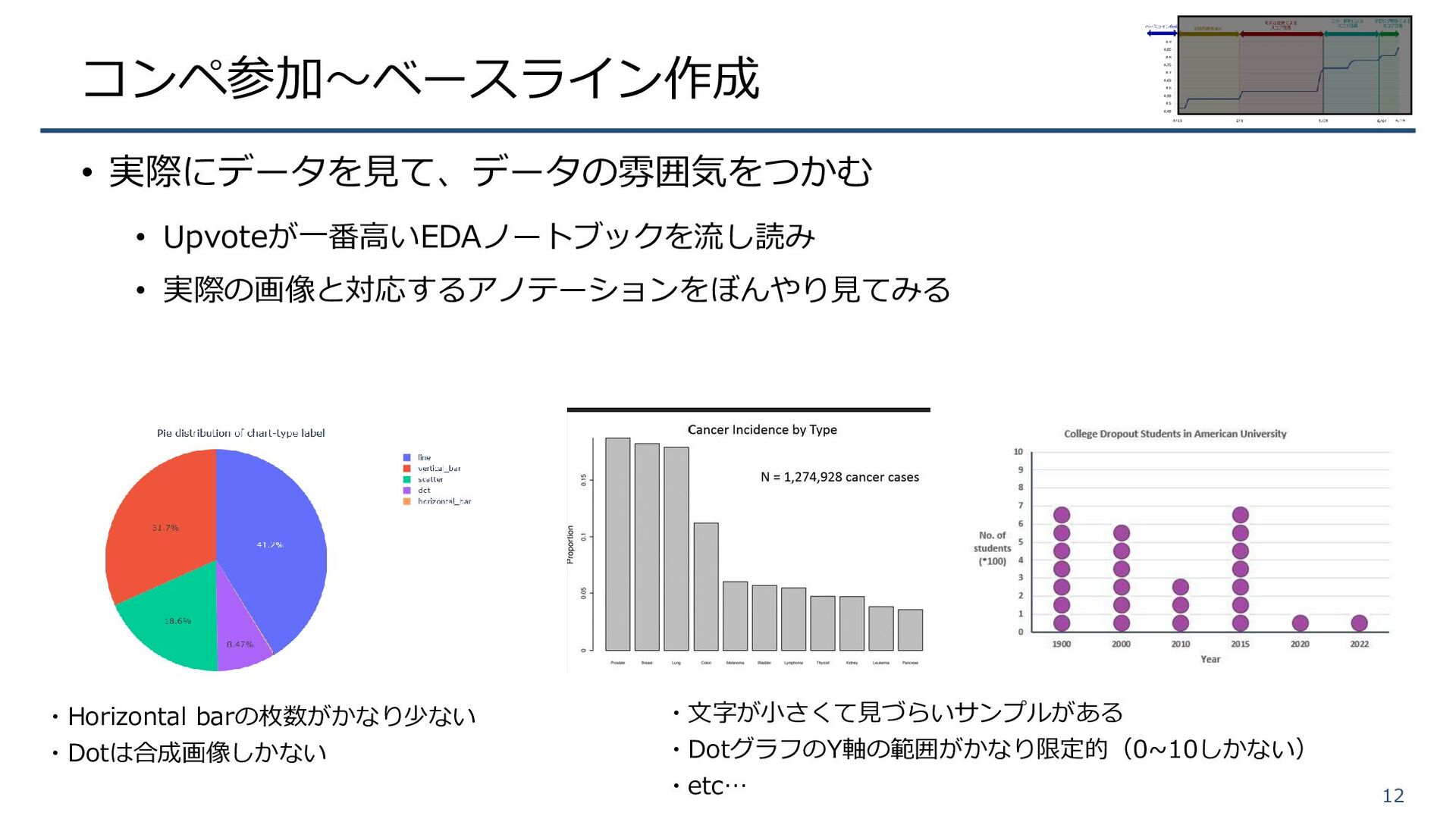
コンペ参加~ベースライン作成 • 実際にデータを見て、データの雰囲気をつかむ • Upvoteが一番高いEDAノートブックを流し読み • 実際の画像と対応するアノテーションをぼんやり見てみる 12 ・Horizontal barの枚数がかなり少ない
・Dotは合成画像しかない ・文字が小さくて見づらいサンプルがある ・DotグラフのY軸の範囲がかなり限定的(0~10しかない) ・etc…
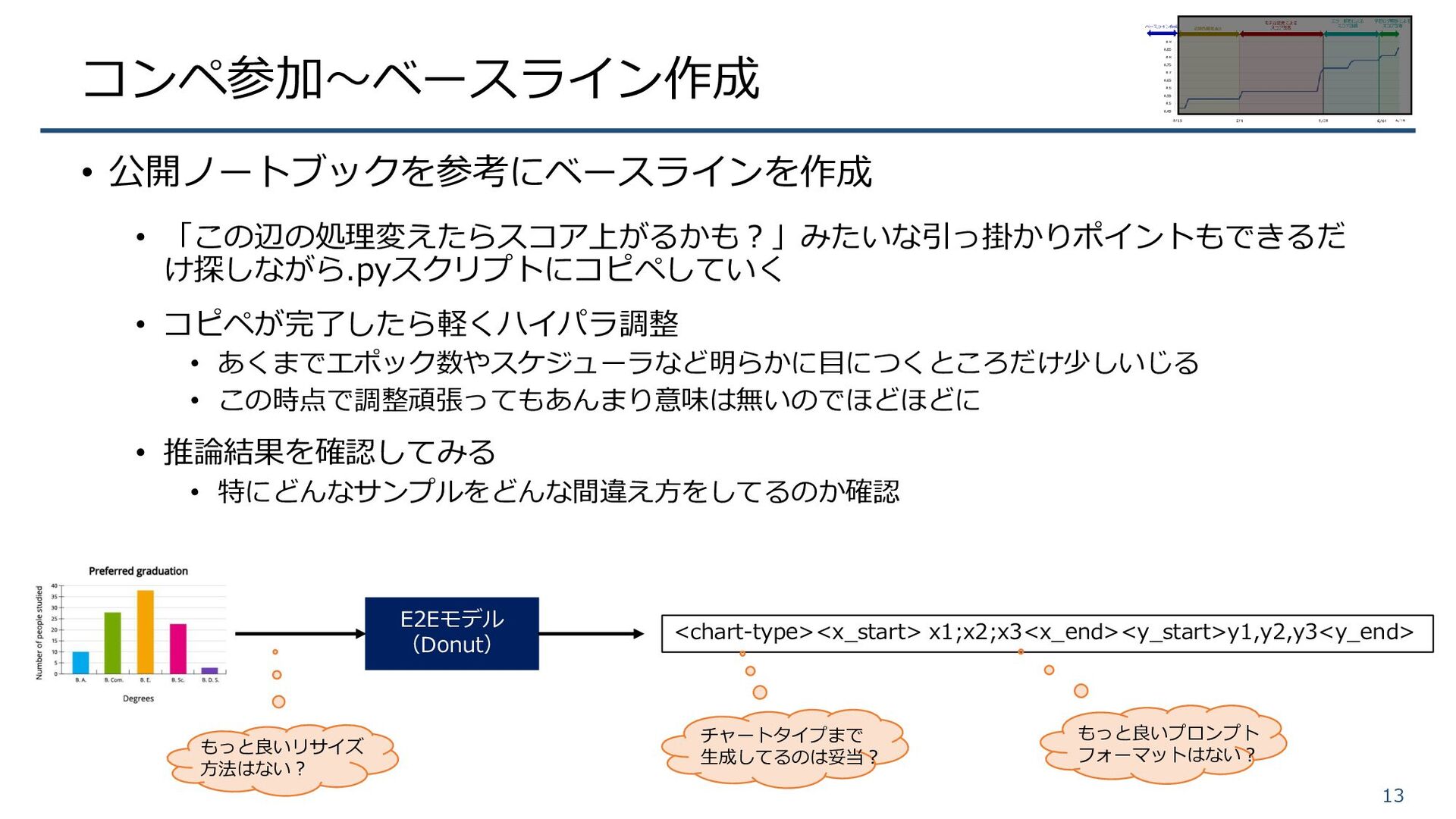
コンペ参加~ベースライン作成 • 公開ノートブックを参考にベースラインを作成 • 「この辺の処理変えたらスコア上がるかも?」みたいな引っ掛かりポイントもできるだ け探しながら.pyスクリプトにコピペしていく • コピペが完了したら軽くハイパラ調整 • あくまでエポック数やスケジューラなど明らかに目につくところだけ少しいじる
• この時点で調整頑張ってもあんまり意味は無いのでほどほどに • 推論結果を確認してみる • 特にどんなサンプルをどんな間違え方をしてるのか確認 13 E2Eモデル (Donut) <chart-type><x_start> x1;x2;x3<x_end><y_start>y1,y2,y3<y_end> もっと良いリサイズ 方法はない? チャートタイプまで 生成してるのは妥当? もっと良いプロンプト フォーマットはない?
初期改善案検討 • ベースライン作成までで気になった点から改善案を検討 • 効果が高そうなアイデア、やりやすそうなアイデアから順番に片っ端から実験 14 画像のリサイズ方法変更 プロンプトフォーマットの変更 超解像モデルで文字の鮮明化 学習データの追加
Augmentationの導入 誤字校正 チャートタイプごとに学習させてみる AWP ・ ・ ・ 当時考えてた改善案 それなりに効果があったもの 効果が無かった or 悪化したもの
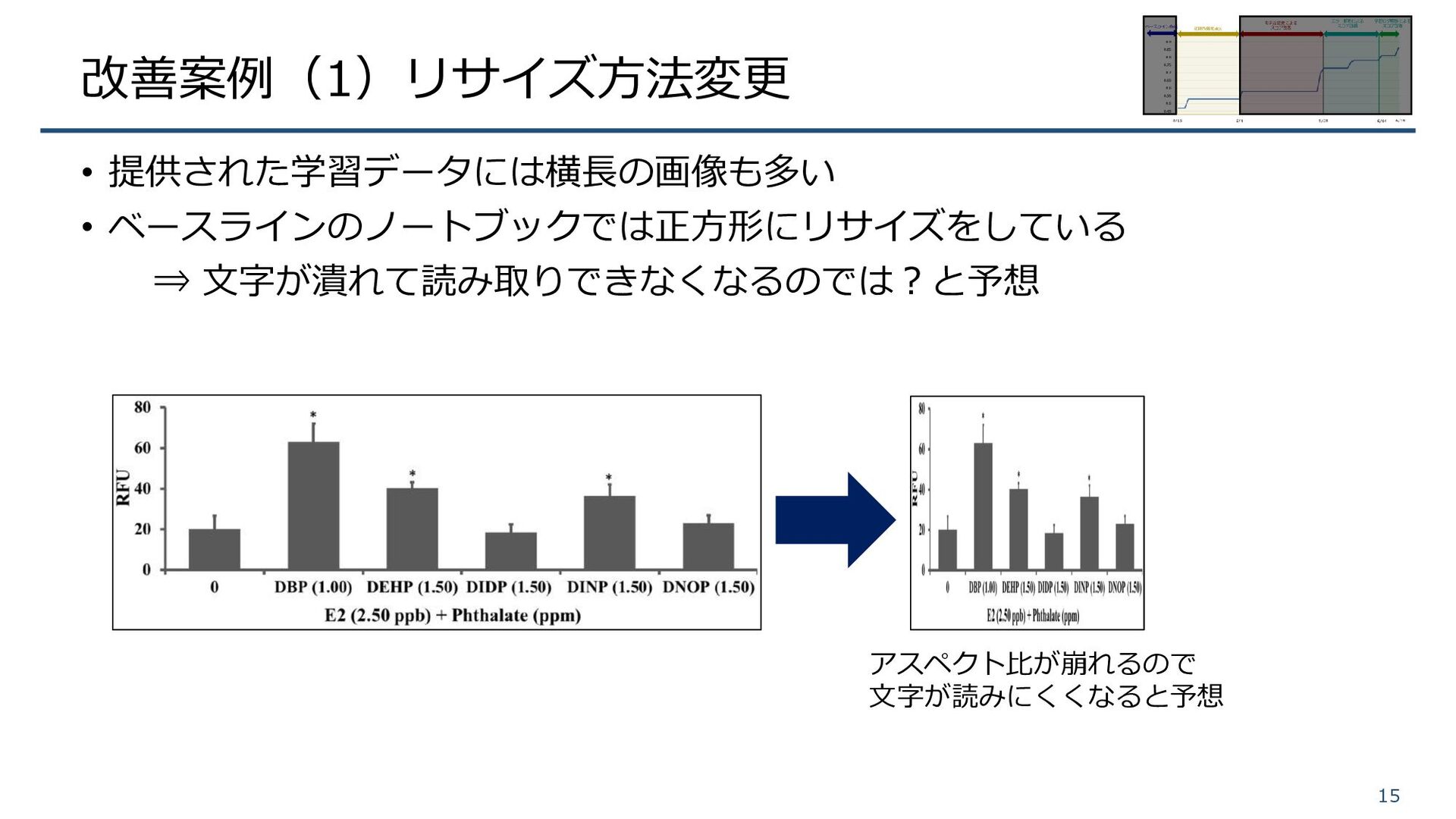
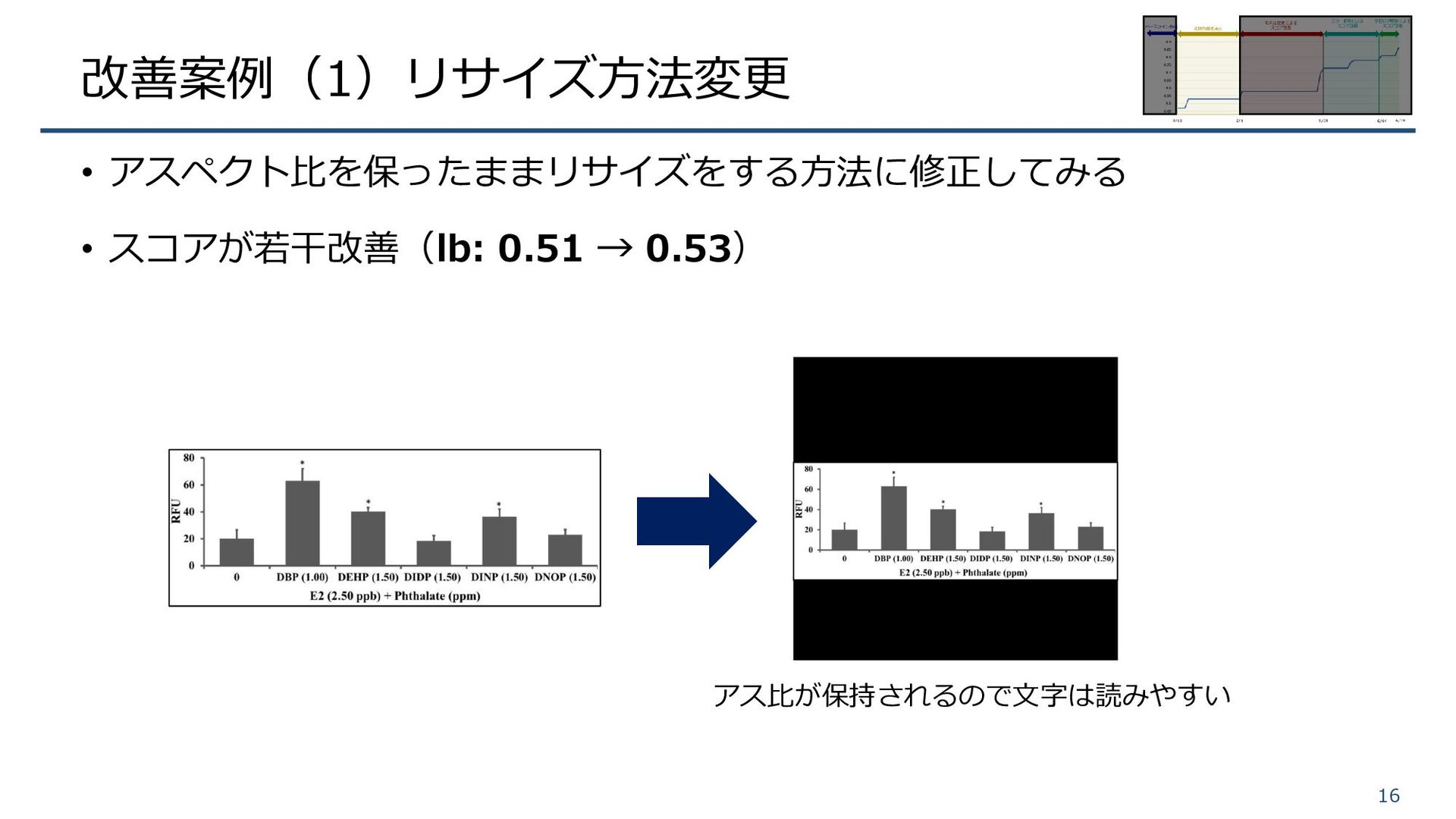
改善案例(1)リサイズ方法変更 • 提供された学習データには横長の画像も多い • ベースラインのノートブックでは正方形にリサイズをしている ⇒ 文字が潰れて読み取りできなくなるのでは?と予想 15 アスペクト比が崩れるので 文字が読みにくくなると予想
改善案例(1)リサイズ方法変更 • アスペクト比を保ったままリサイズをする方法に修正してみる • スコアが若干改善(lb: 0.51 → 0.53) 16 アス比が保持されるので文字は読みやすい
改善案例(2)データ追加 • Horizontal barの精度が著しく低い • EDAの結果からHorizontal barのデータは異常に少ない(抽出画像しかない) ⇒ Horizontal barデータを自作して学習に入れてみる
• Horizontal barに対するcvがかなり改善される 17
改善案例(2)データ追加 • 更にデータを増やせばスコア上がるのでは?と思い追加実験 • ICDARデータセット • ホストが(当時)コンペページで紹介していた外部データセット • 数千枚の抽出画像のみで構成されている •
ただし、すべてのデータにアノテーションされているわけではない • お試しでアノテーションが付与されているデータだけを追加してみる ⇒ スコア改善(lb: 0.53 → 0.58) 18
モデル変更によるスコア改善 • Deplotを使用して高スコアが出たというDiscussionが投稿される • Notebookは公開されなかったので、試行錯誤しながらベースラインを改造 • 系列の予測は上手くいくが、チャートタイプの予測は上手くいかない • もともと生成モデルで分類をさせていることに違和感があったので、このタイミングで チャート予測は分類モデルで行う方針に変更
• スコアが大幅に上がる(lb: 0.58 → 0.73) 19
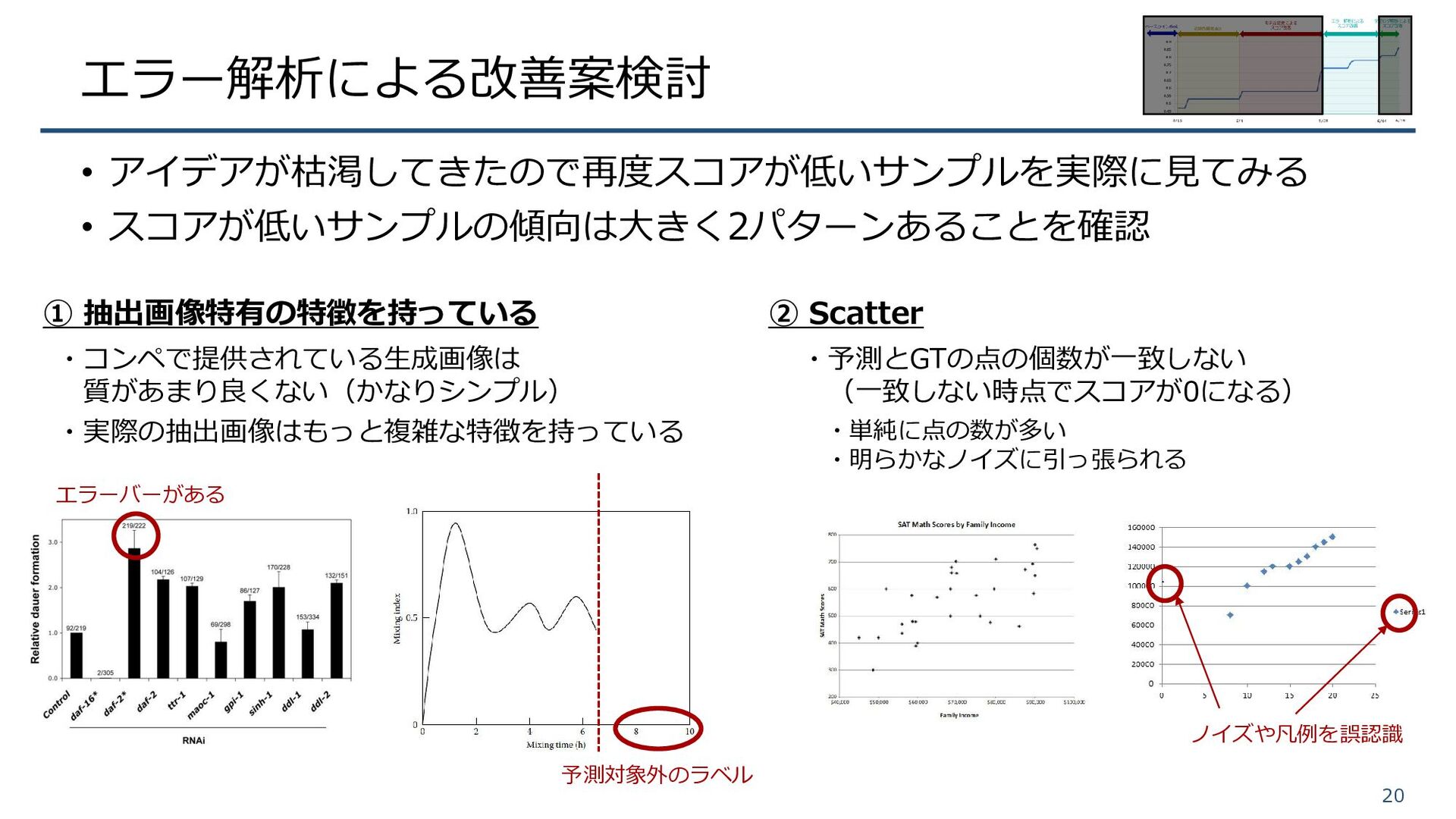
エラー解析による改善案検討 • アイデアが枯渇してきたので再度スコアが低いサンプルを実際に見てみる • スコアが低いサンプルの傾向は大きく2パターンあることを確認 20 ① 抽出画像特有の特徴を持っている ・コンペで提供されている生成画像は 質があまり良くない(かなりシンプル)
・実際の抽出画像はもっと複雑な特徴を持っている ② Scatter ・予測とGTの点の個数が一致しない (一致しない時点でスコアが0になる) ・単純に点の数が多い ・明らかなノイズに引っ張られる 予測対象外のラベル エラーバーがある ノイズや凡例を誤認識
エラー解析による改善案検討 • 生成画像が抽出画像の特長を十分捉えられていないことが問題と予想 • 抽出画像に近いデータを増やす方法を検討 • より抽出画像に近い合成データを自作 • ICDARデータセットの未アノテーションデータを活用 •
これらのデータを追加して学習することでスコア向上(lb: 0.73 → 0.78) 21 ① 抽出画像特有の特徴を持っている
エラー解析による改善案検討 • Scatterだけで学習させてみる • 他のチャートタイプと比べて出力系列が長くなりやすいのが問題と仮定して、 scatterデータのみで学習させてみたが精度は改善せず • これ以上どうにもならない気がしたので根本的にアプローチから方針変更 ⇒ アプローチを変えたことで精度向上(scatterのlb:
0.06 → 0.10) 22 ② Scatter
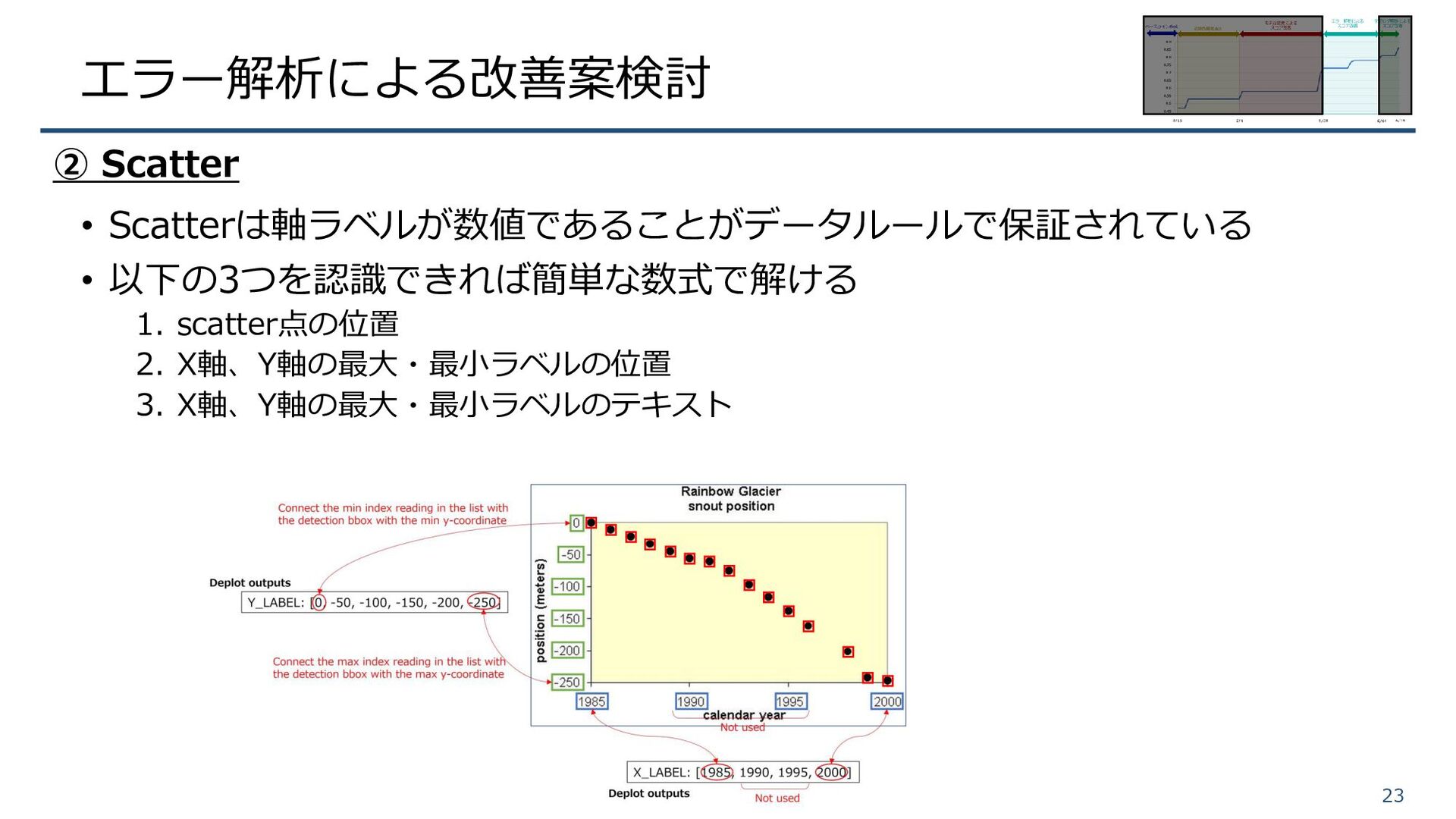
エラー解析による改善案検討 • Scatterは軸ラベルが数値であることがデータルールで保証されている • 以下の3つを認識できれば簡単な数式で解ける 1. scatter点の位置 2. X軸、Y軸の最大・最小ラベルの位置 3.
X軸、Y軸の最大・最小ラベルのテキスト 23 ② Scatter
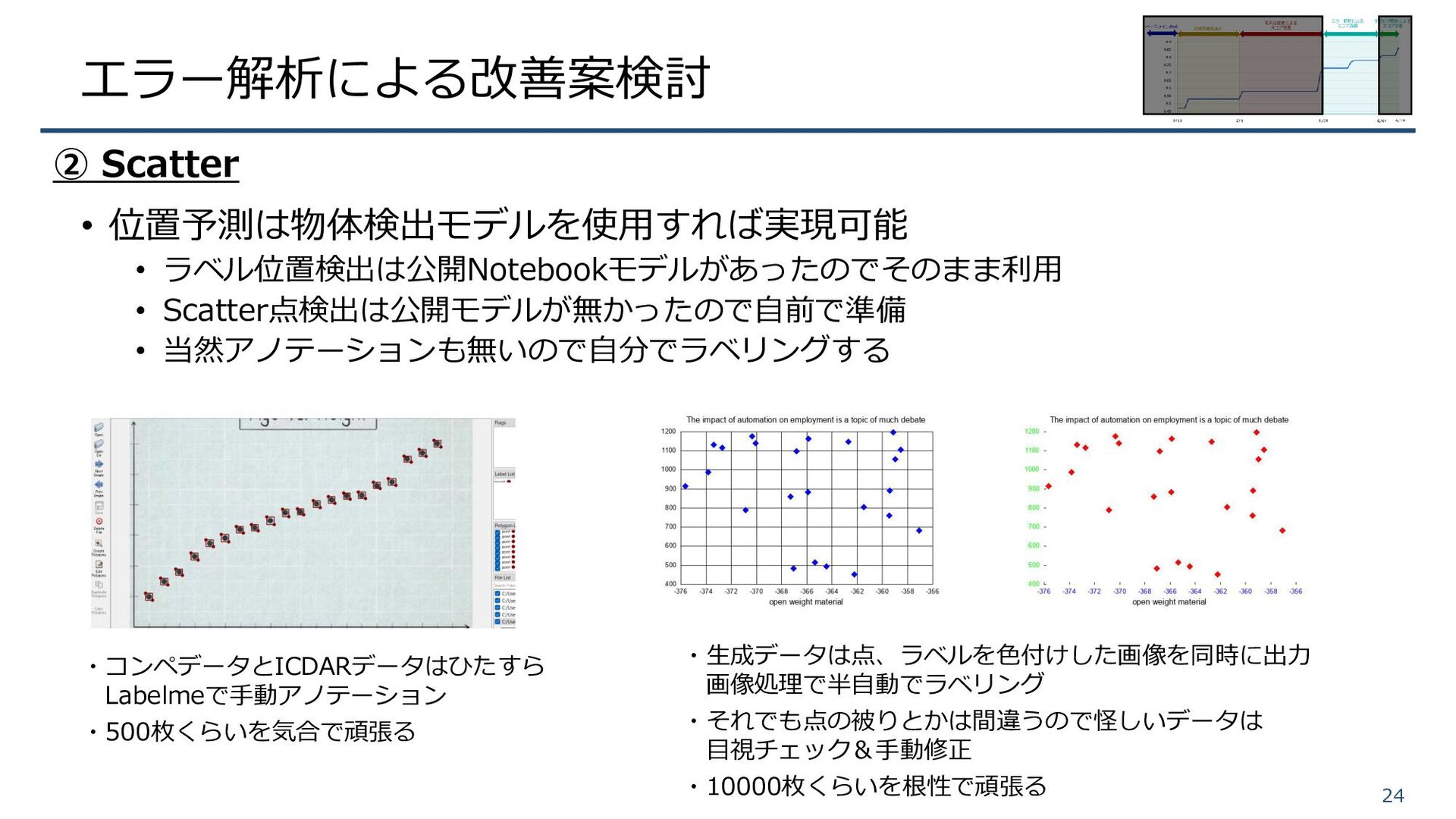
エラー解析による改善案検討 • 位置予測は物体検出モデルを使用すれば実現可能 • ラベル位置検出は公開Notebookモデルがあったのでそのまま利用 • Scatter点検出は公開モデルが無かったので自前で準備 • 当然アノテーションも無いので自分でラベリングする 24
② Scatter ・コンペデータとICDARデータはひたすら Labelmeで手動アノテーション ・500枚くらいを気合で頑張る ・生成データは点、ラベルを色付けした画像を同時に出力 画像処理で半自動でラベリング ・それでも点の被りとかは間違うので怪しいデータは 目視チェック&手動修正 ・10000枚くらいを根性で頑張る
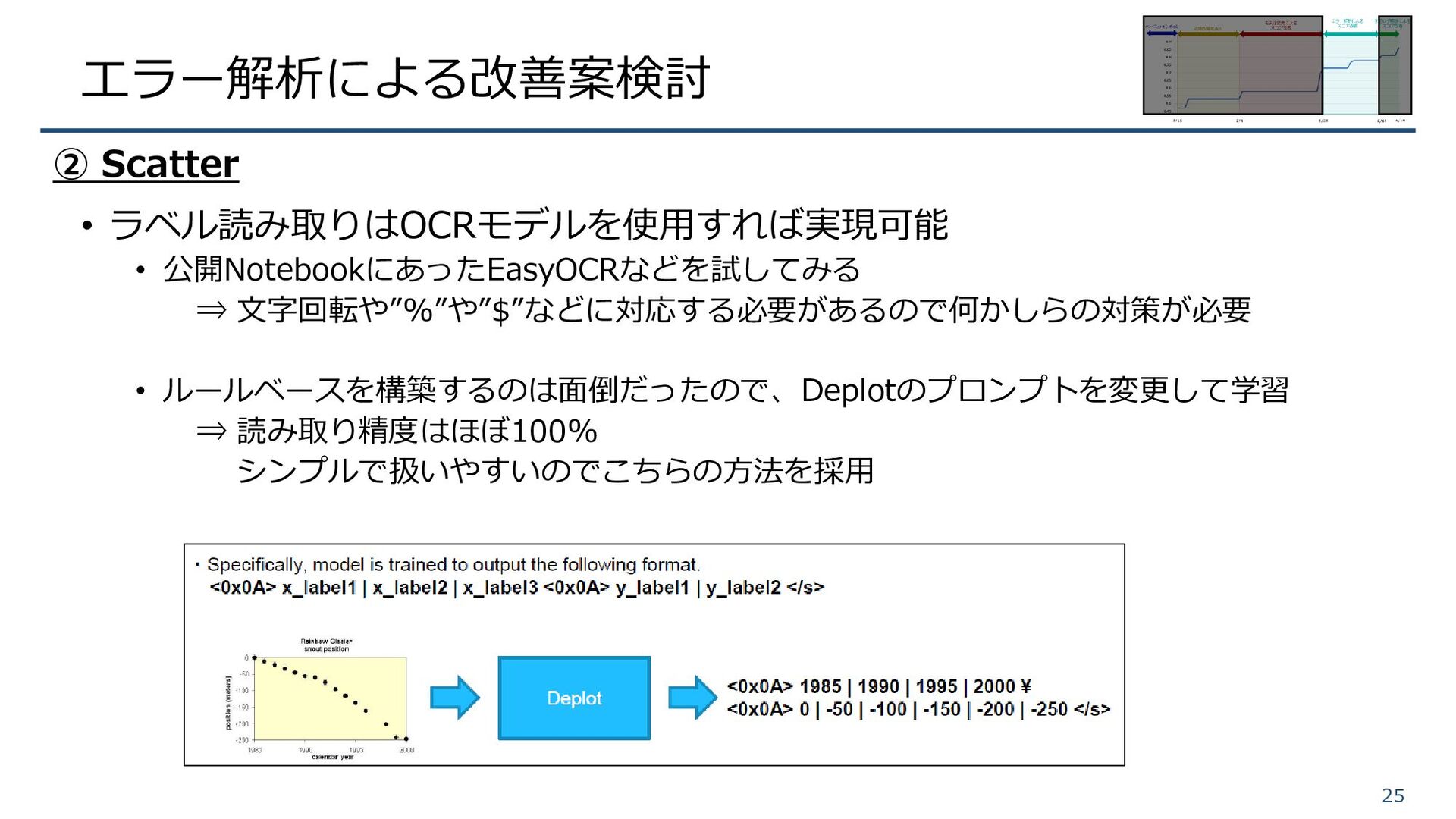
エラー解析による改善案検討 • ラベル読み取りはOCRモデルを使用すれば実現可能 • 公開NotebookにあったEasyOCRなどを試してみる ⇒ 文字回転や”%”や”$”などに対応する必要があるので何かしらの対策が必要 • ルールベースを構築するのは面倒だったので、Deplotのプロンプトを変更して学習 ⇒
読み取り精度はほぼ100% シンプルで扱いやすいのでこちらの方法を採用 25 ② Scatter
学習ログ解析による改善案検討 • チャートタイプごとに最適なエポックが違うことに気づく 26 全体のval_scoreの ベストはEpoch8 Vertical Barだけに着目すると ベストはEpoch4
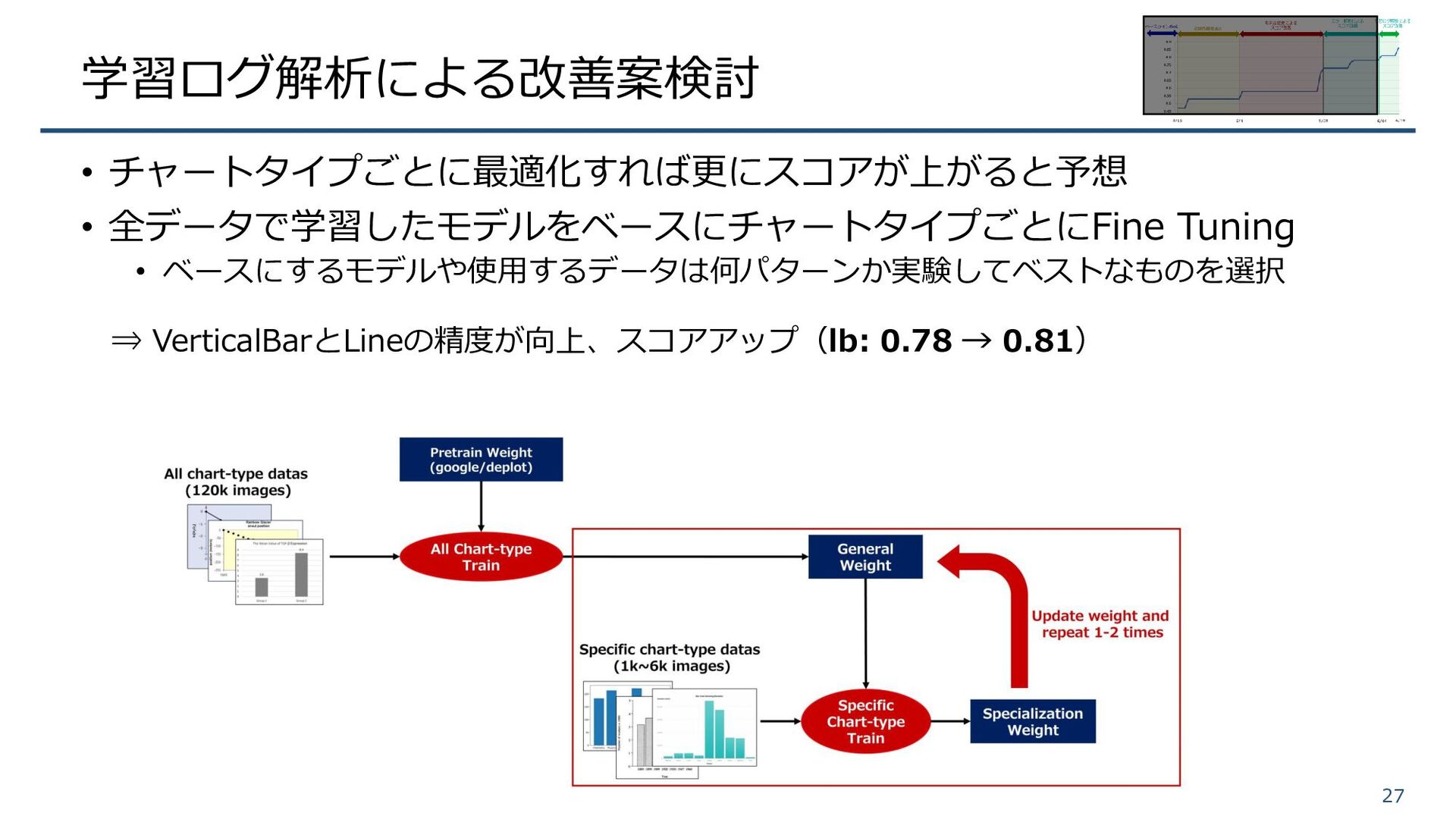
学習ログ解析による改善案検討 • チャートタイプごとに最適化すれば更にスコアが上がると予想 • 全データで学習したモデルをベースにチャートタイプごとにFine Tuning • ベースにするモデルや使用するデータは何パターンか実験してベストなものを選択 ⇒ VerticalBarとLineの精度が向上、スコアアップ(lb:
0.78 → 0.81) 27
(おまけ)コンペ最終日 • 最終日の朝にベストモデルを組み合わせたとっておきをサブミットしてPublic3位まで上がる • 余裕かましてたら他の参加者もガンガン順位を上げてくる • LB覗くたびに自分の順位が下がっていって最終的に8位まで落ちる • 金圏も追い出されかける勢いで周りのスコアが上がっていくので気が気じゃなかった 28
おわりに • データや結果から仮説を立てて、地道に実験していくのが大事 • 基本的に上手くいかないことの方が多い • めげずにとにかくサイクルを回し続ける • 優勝できるかどうかは時の運(だと思う) •
どれだけ頑張っても最後は大なり小なり運が絡む • それでもやるべきことをちゃんとやって、できる限りの努力をするのがきっと大事 • 修行中の身なのでGM目指してこれからも精進します 29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![はじめに 11 • 今回はどんなことを考えてコンペに取り組んでいたか時系列的にお話しします [Public LBの推移] ベースライン作成 初期改善案検討 モデル変更による スコア改善](https://files.speakerdeck.com/presentations/e7e672d42bad43169c1a597403483e06/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}