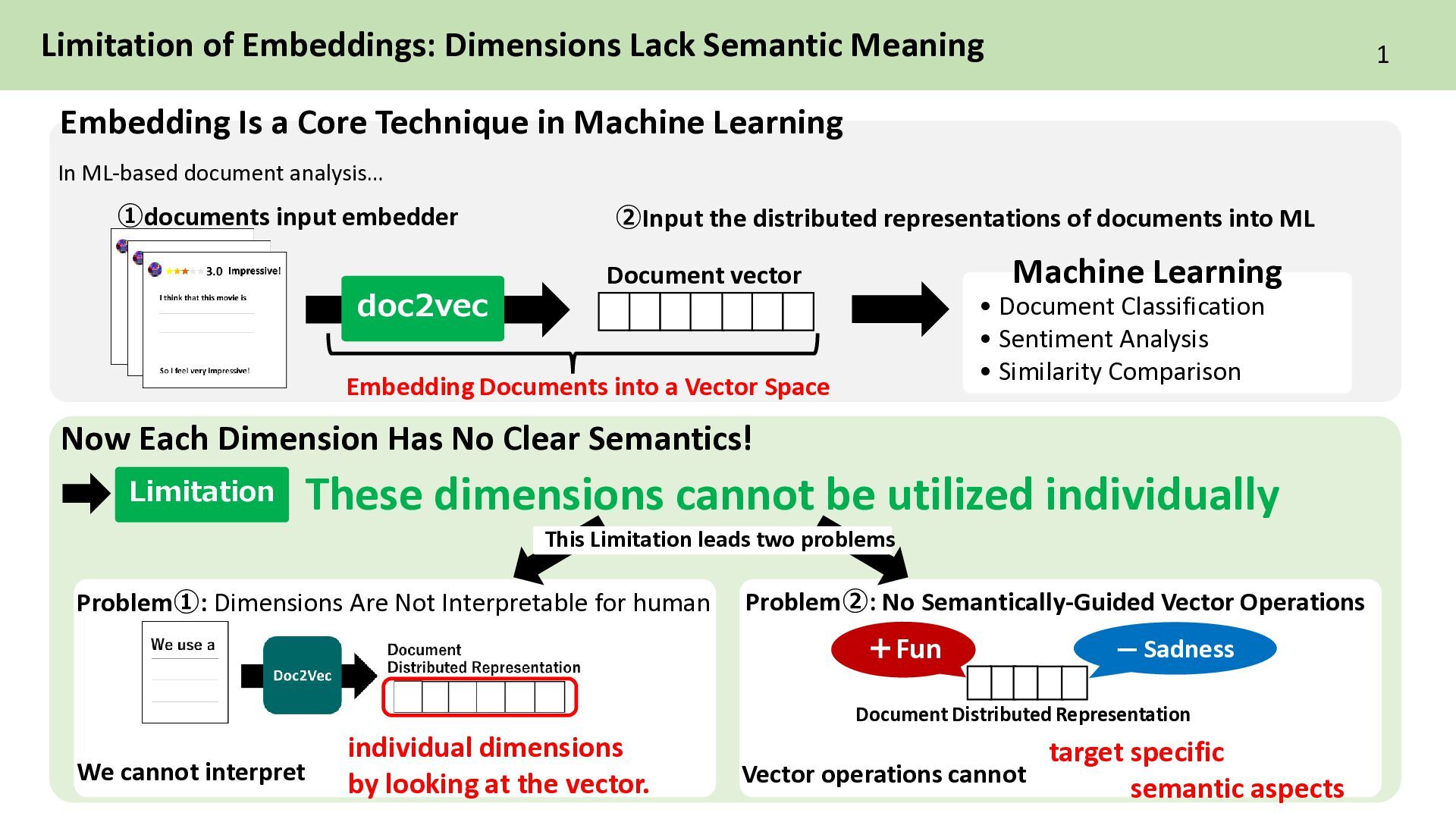
a Core Technique in Machine Learning Embedding Documents into a Vector Space These dimensions cannot be utilized individually doc2vec Document vector • Document Classification • Sentiment Analysis • Similarity Comparison Machine Learning Now Each Dimension Has No Clear Semantics! Problem➀: Dimensions Are Not Interpretable for human Problem➁: No Semantically-Guided Vector Operations We cannot interpret ー Sadness +Fun target specific semantic aspects In ML-based document analysis… ➀documents input embedder ➁Input the distributed representations of documents into ML Limitation individual dimensions by looking at the vector. Document Distributed Representation This Limitation leads two problems Vector operations cannot
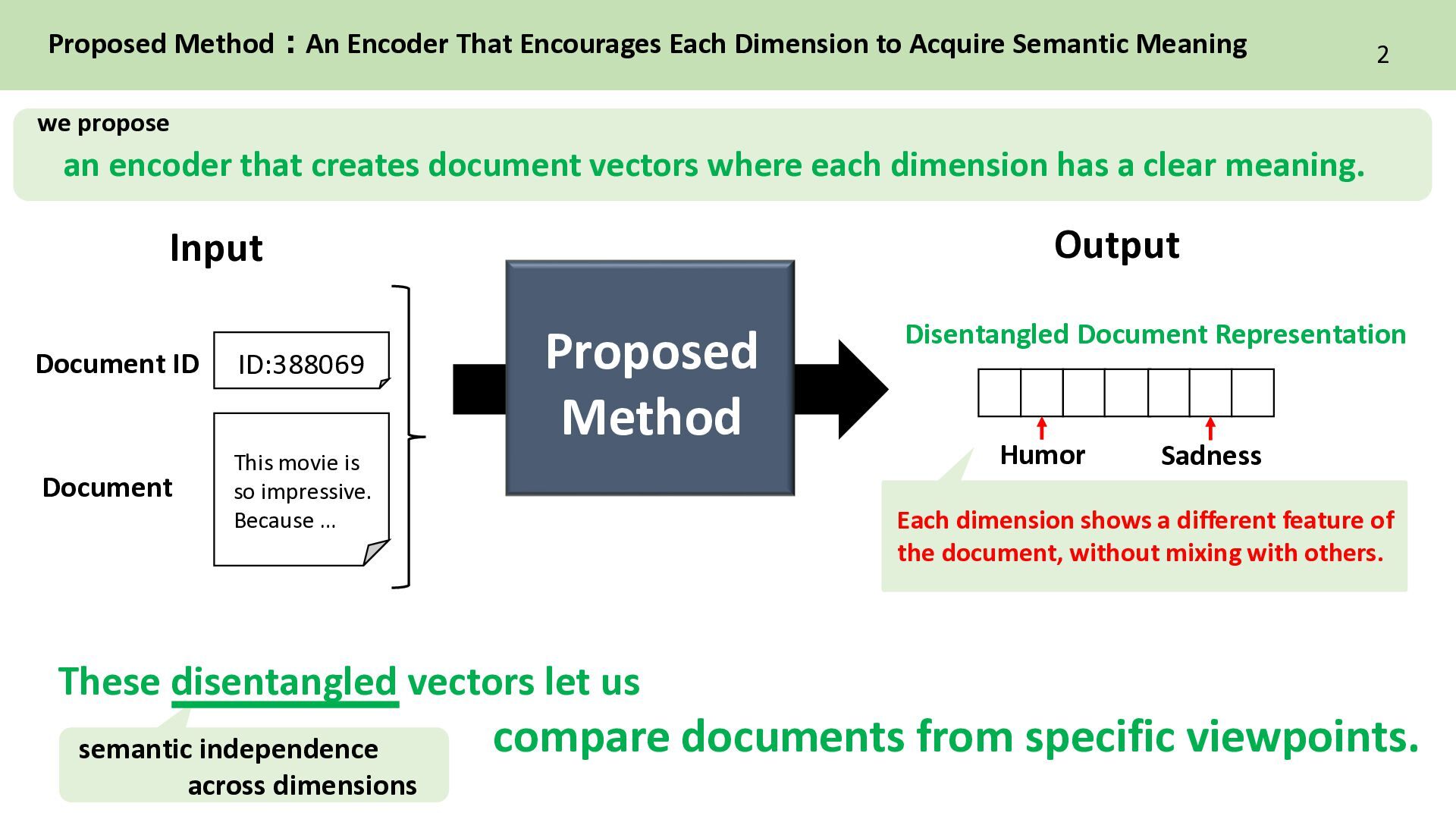
Dimension to Acquire Semantic Meaning ID:388069 This movie is so impressive. Because … Document ID Document Proposed Method Humor Sadness These disentangled vectors let us compare documents from specific viewpoints. Disentangled Document Representation 2 Input Output an encoder that creates document vectors where each dimension has a clear meaning. we propose Each dimension shows a different feature of the document, without mixing with others.
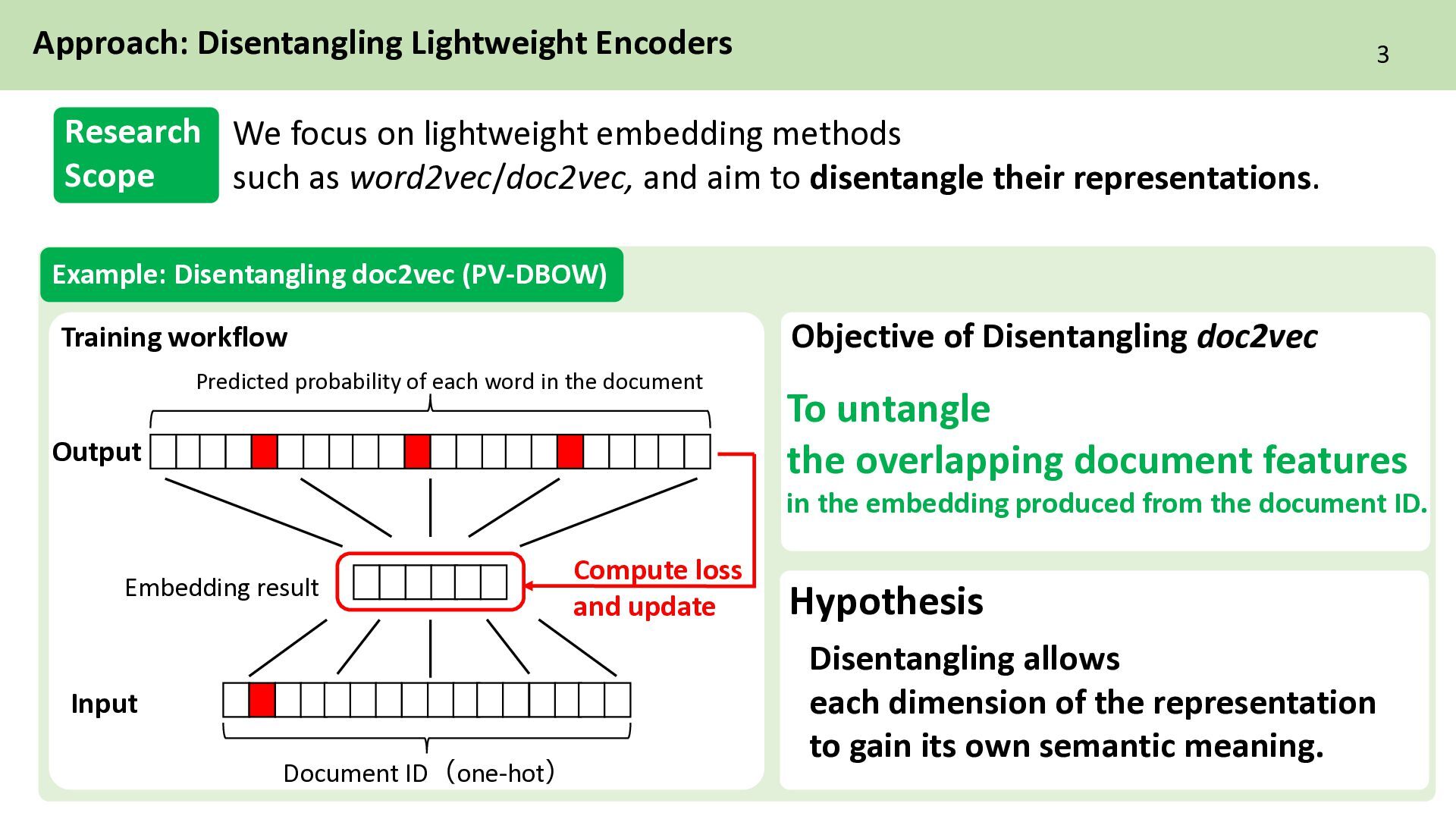
each word in the document Approach: Disentangling Lightweight Encoders Input Output We focus on lightweight embedding methods such as word2vec/doc2vec, and aim to disentangle their representations. Embedding result To untangle the overlapping document features in the embedding produced from the document ID. Objective of Disentangling doc2vec Disentangling allows each dimension of the representation to gain its own semantic meaning. Research Scope Training workflow Compute loss and update Hypothesis
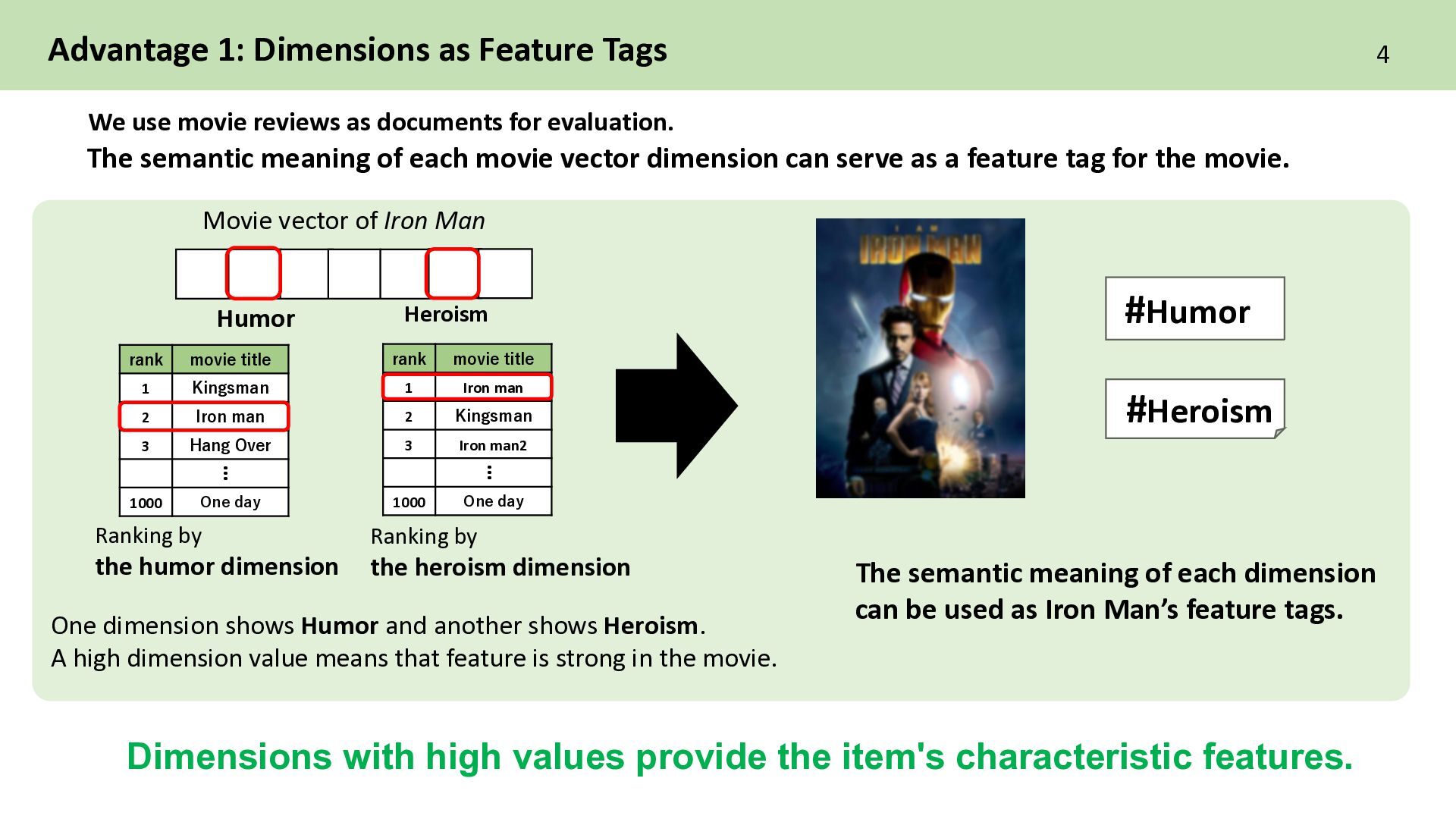
of Iron Man 4 #Heroism #Humor The semantic meaning of each movie vector dimension can serve as a feature tag for the movie. rank movie title 1 Iron man 2 Kingsman 3 Iron man2 1000 One day … rank movie title 1 Kingsman 2 Iron man 3 Hang Over 1000 One day … Ranking by the humor dimension We use movie reviews as documents for evaluation. One dimension shows Humor and another shows Heroism. A high dimension value means that feature is strong in the movie. The semantic meaning of each dimension can be used as Iron Man’s feature tags. Dimensions with high values provide the item's characteristic features. Ranking by the heroism dimension
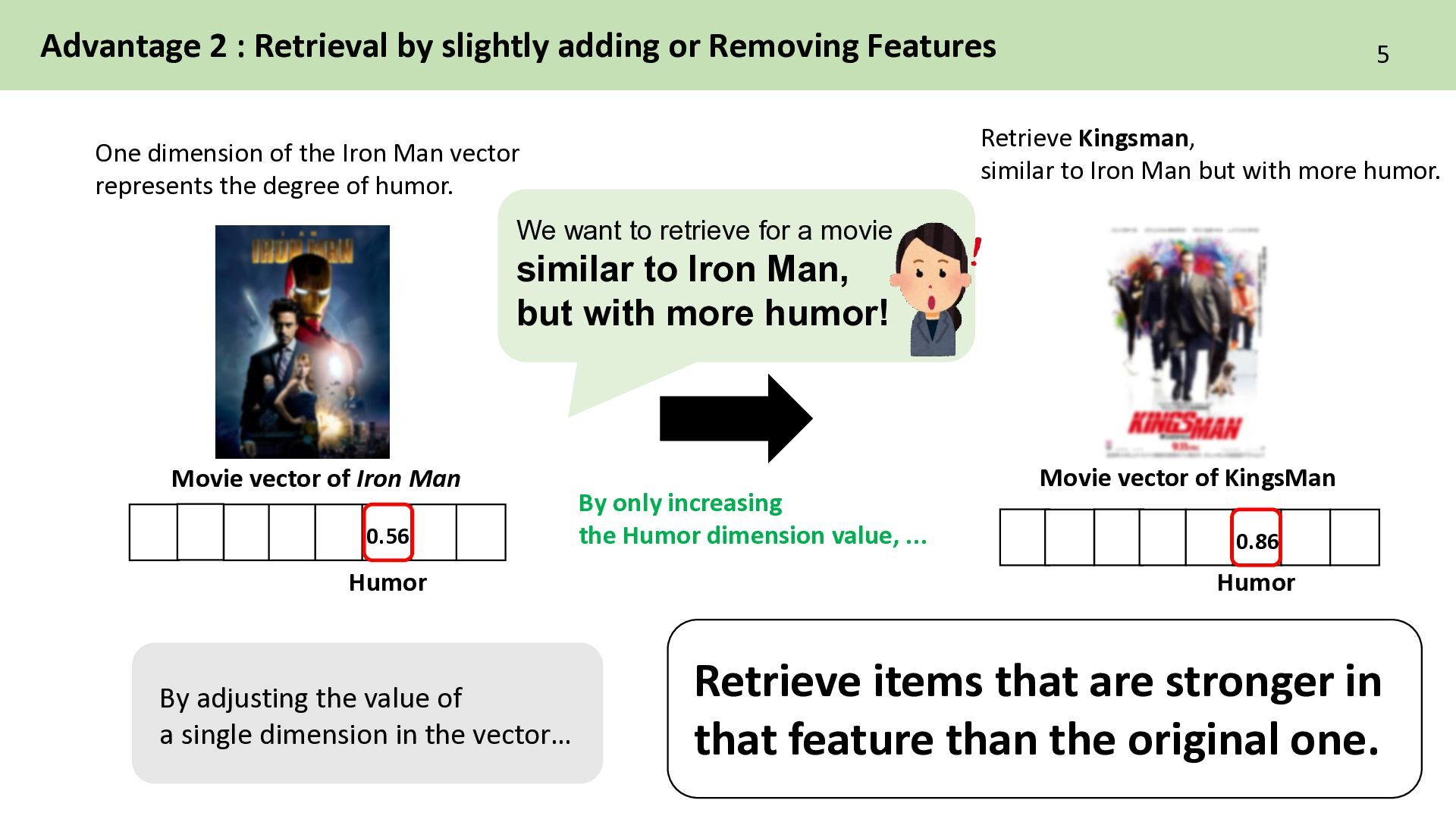
Movie vector of Iron Man By only increasing the Humor dimension value, ... 5 0.86 Humor 0.56 Retrieve items that are stronger in that feature than the original one. Humor Movie vector of KingsMan One dimension of the Iron Man vector represents the degree of humor. We want to retrieve for a movie similar to Iron Man, but with more humor! Retrieve Kingsman, similar to Iron Man but with more humor. By adjusting the value of a single dimension in the vector…
should reflect real-world relational distances. Each vector dimension should be independent. Each dimension should carry an interpretable semantic meaning. Defined three requirements that the resulting document vectors should satisfy. Our research to satisfy these three requirements.
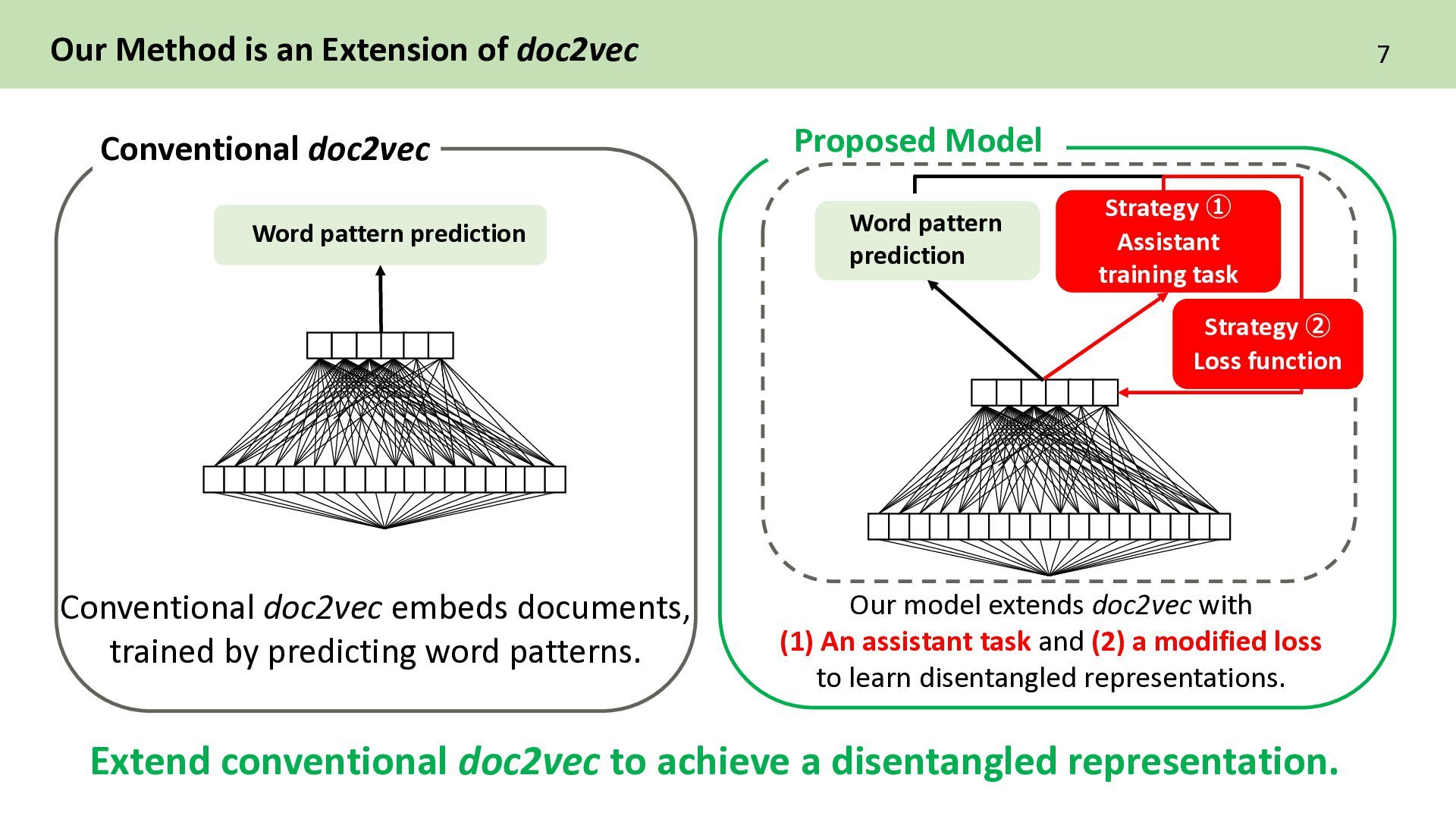
Proposed Model Strategy ① Assistant training task Strategy ② Loss function Extend conventional doc2vec to achieve a disentangled representation. Conventional doc2vec embeds documents, trained by predicting word patterns. Our model extends doc2vec with (1) An assistant task and (2) a modified loss to learn disentangled representations. Word pattern prediction Word pattern prediction
design the assistant training task ② How to design the loss function The two key strategies at the core of our method. This strategy helps the model reflect the document’s characteristics more clearly in its vector representation. This strategy encourages each dimension of the vector to become independent in meaning.
three following parts. Using movie examples ①Vectorization Framework ②Guiding Task That Reflects Movie-Specific Features ③Loss Function Considering the Degree of Disentanglement
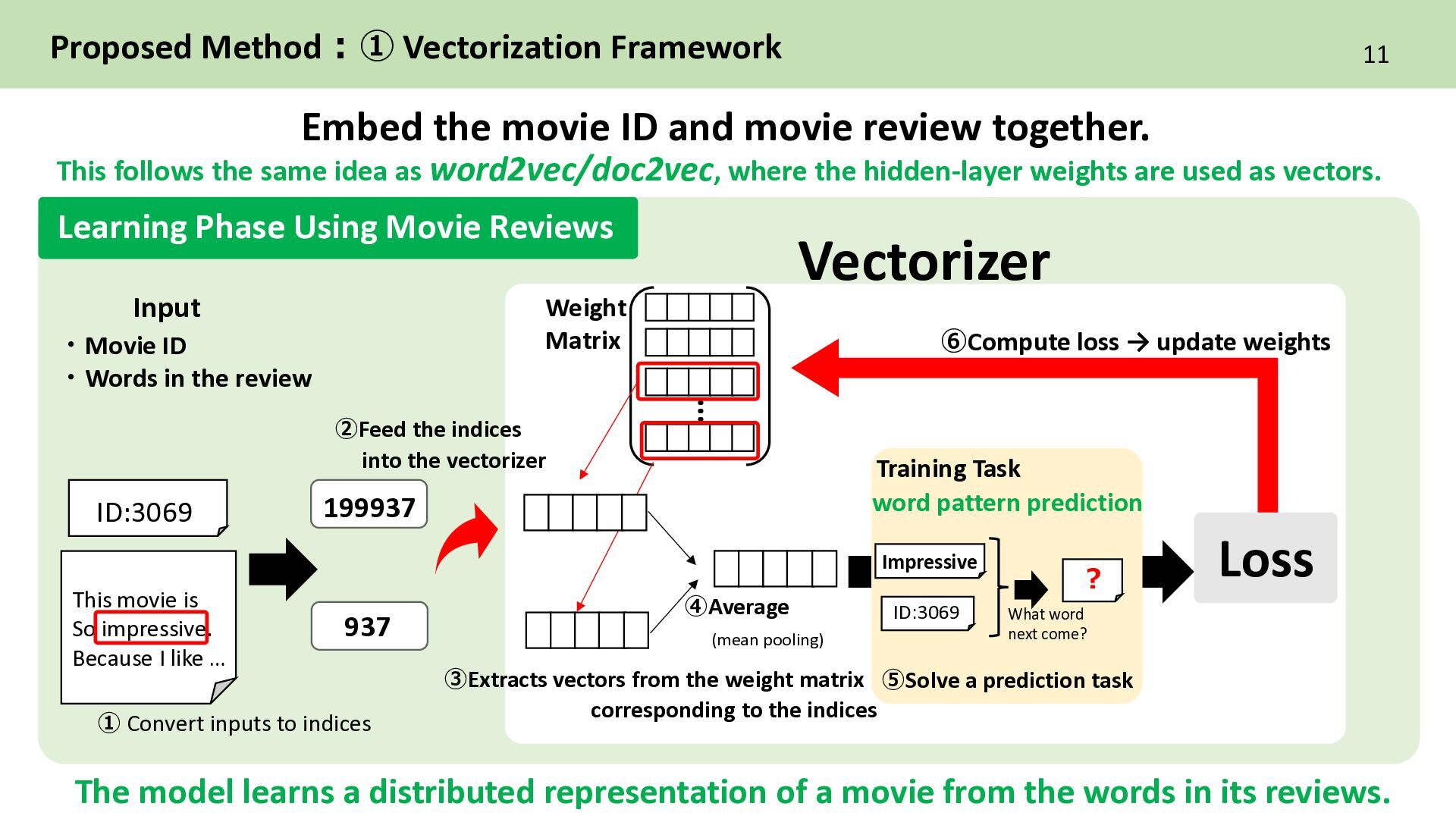
movie review together. ID:3069 This movie is So impressive. Because I like … Input ・Movie ID ・Words in the review This follows the same idea as word2vec/doc2vec, where the hidden-layer weights are used as vectors. Learning Phase Using Movie Reviews Vectorizer … 199937 937 ➀ Convert inputs to indices ③Extracts vectors from the weight matrix corresponding to the indices Weight Matrix ④Average (mean pooling) Training Task word pattern prediction Loss ID:3069 Impressive ? ⑥Compute loss → update weights The model learns a distributed representation of a movie from the words in its reviews. ➁Feed the indices into the vectorizer ⑤Solve a prediction task What word next come?
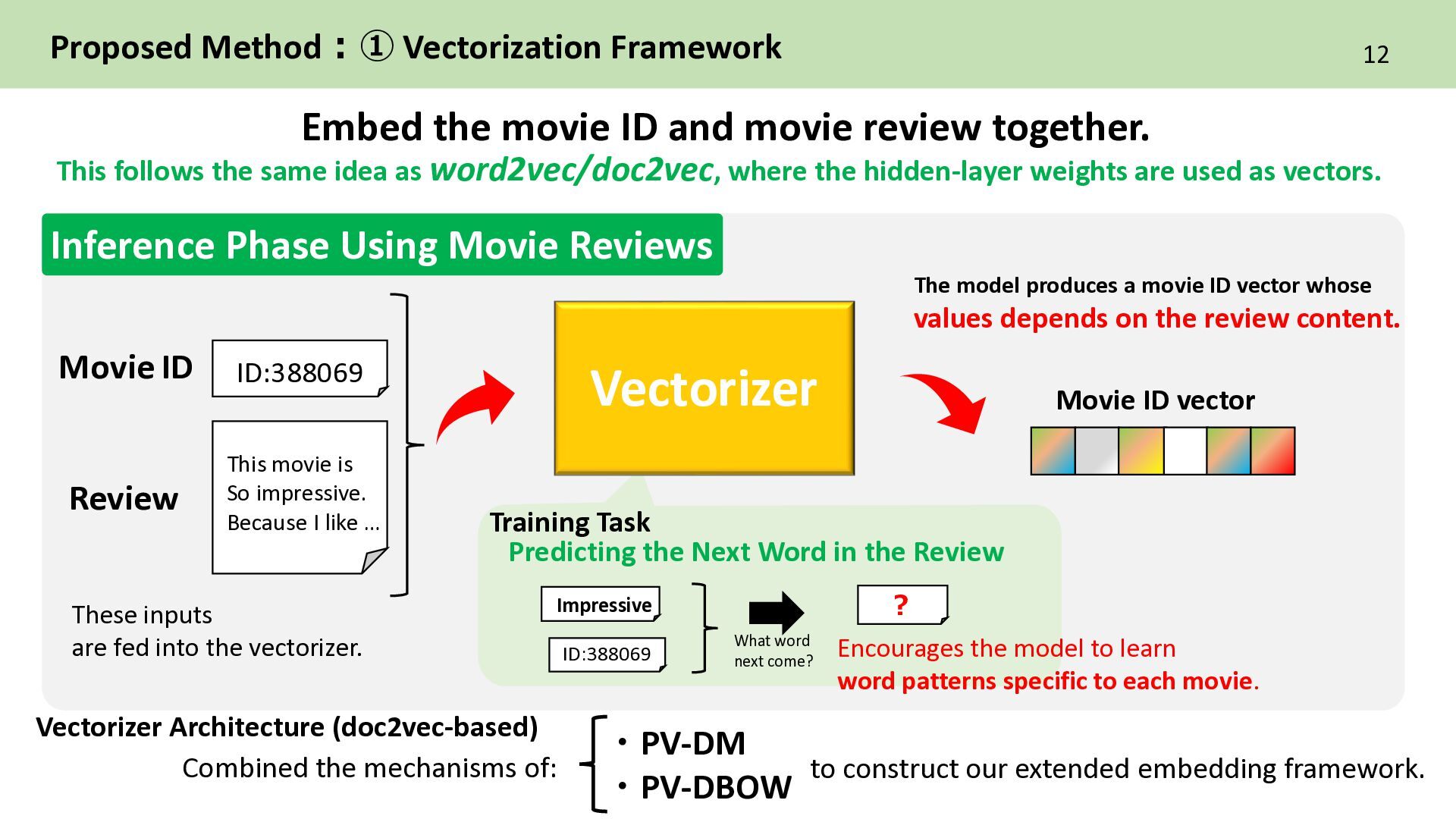
the mechanisms of: ID:388069 Impressive ? Predicting the Next Word in the Review Encourages the model to learn word patterns specific to each movie. Inference Phase Using Movie Reviews The model produces a movie ID vector whose values depends on the review content. ・PV-DM ・PV-DBOW to construct our extended embedding framework. Proposed Method:① Vectorization Framework This movie is So impressive. Because I like … These inputs are fed into the vectorizer. Training Task What word next come? Vectorizer Architecture (doc2vec-based) Embed the movie ID and movie review together. This follows the same idea as word2vec/doc2vec, where the hidden-layer weights are used as vectors.
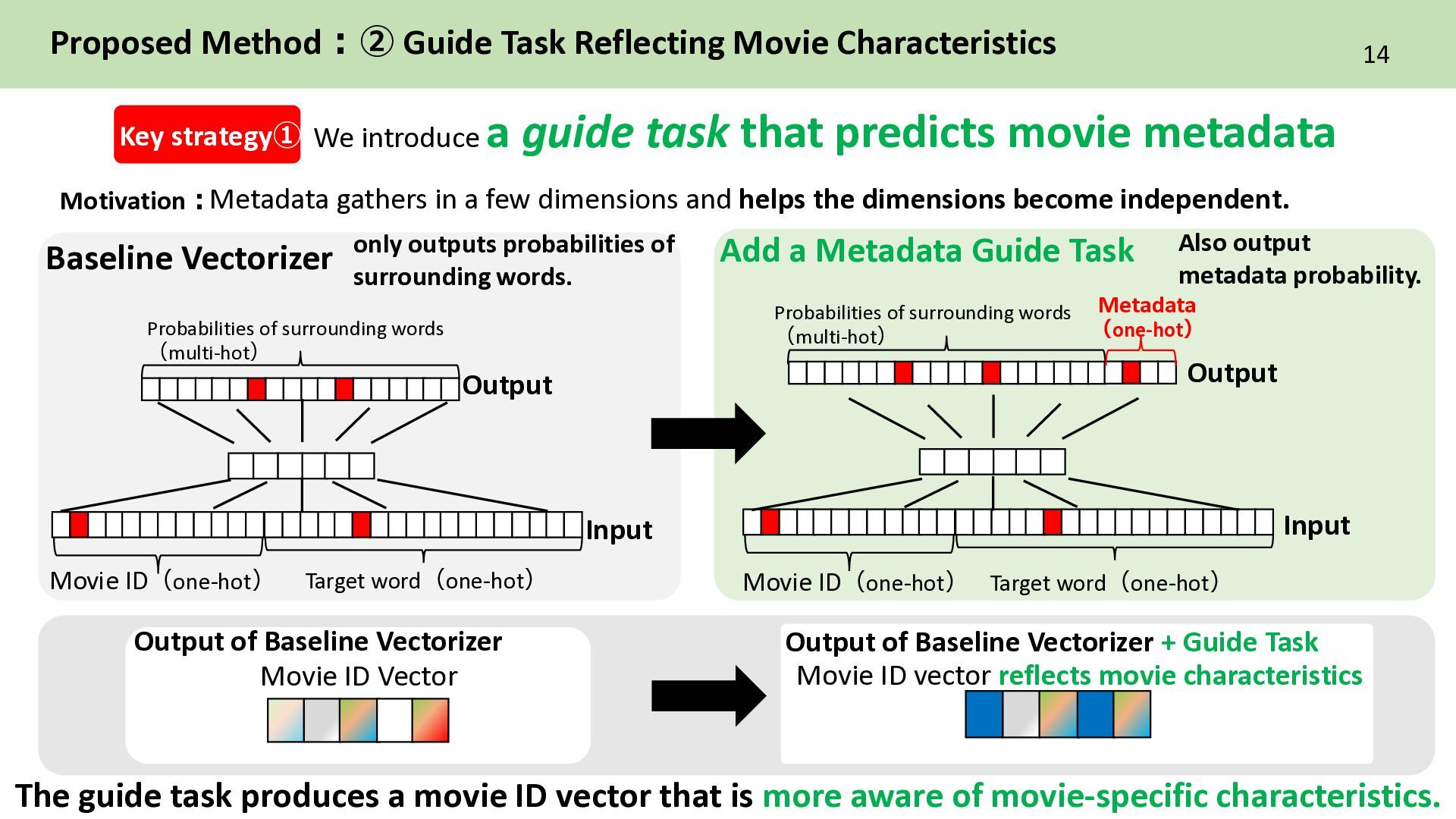
Proposed Method:② Guide Task Reflecting Movie Characteristics Key strategy➀ Movie ID vector reflects movie characteristics Output of Baseline Vectorizer + Guide Task Output of Baseline Vectorizer Movie ID Vector Metadata gathers in a few dimensions and helps the dimensions become independent. Target word(one-hot) Movie ID(one-hot) Probabilities of surrounding words (multi-hot) Output Baseline Vectorizer Input Add a Metadata Guide Task Probabilities of surrounding words (multi-hot) Output Input Metadata (one-hot) only outputs probabilities of surrounding words. Also output metadata probability. The guide task produces a movie ID vector that is more aware of movie-specific characteristics. Motivation: Target word(one-hot) Movie ID(one-hot)
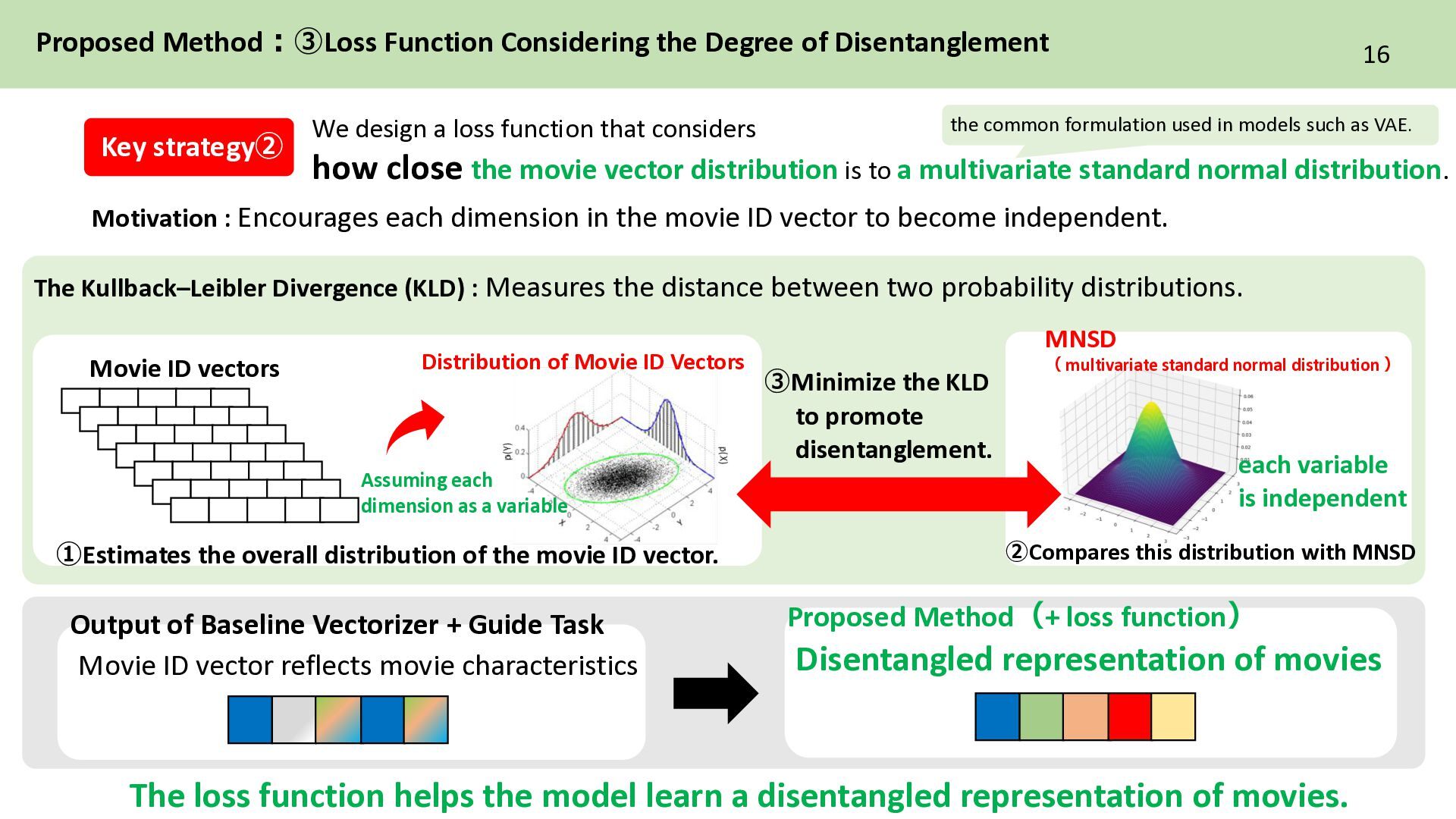
a loss function that considers how close the movie vector distribution is to a multivariate standard normal distribution. Disentangled representation of movies Proposed Method(+ loss function) The Kullback–Leibler Divergence (KLD) : Measures the distance between two probability distributions. Motivation : Encourages each dimension in the movie ID vector to become independent. MNSD ( multivariate standard normal distribution ) each variable is independent Movie ID vectors Distribution of Movie ID Vectors Assuming each dimension as a variable 16 the common formulation used in models such as VAE. Key strategy➁ ➀Estimates the overall distribution of the movie ID vector. ➁Compares this distribution with MNSD The loss function helps the model learn a disentangled representation of movies. ③Minimize the KLD to promote disentanglement. Output of Baseline Vectorizer + Guide Task Movie ID vector reflects movie characteristics
the interpretability of the vectors. 17 Effectiveness of the KLD Term Evaluated Using Toy Data Comparison Setting ・Randomly initialized vectors ・Vectors trained with the vectorizer (word prediction only) ・Vectors trained with the vectorizer + KLD term Dataset Toy dataset with topic labels • 10,000 documents • 20 words per document • 20 topic categories Adding the KLD term revealed that the document vectors: ➀Start to encode topic-specific information in each dimension ➁Show larger variance across dimensions, improving interpretability ③Exhibit lower information entropy, meaning that extra information is reduced Findings from the Toy Data Experiment We ran an ablation study to check the effect of the KLD term. We compare three methods.
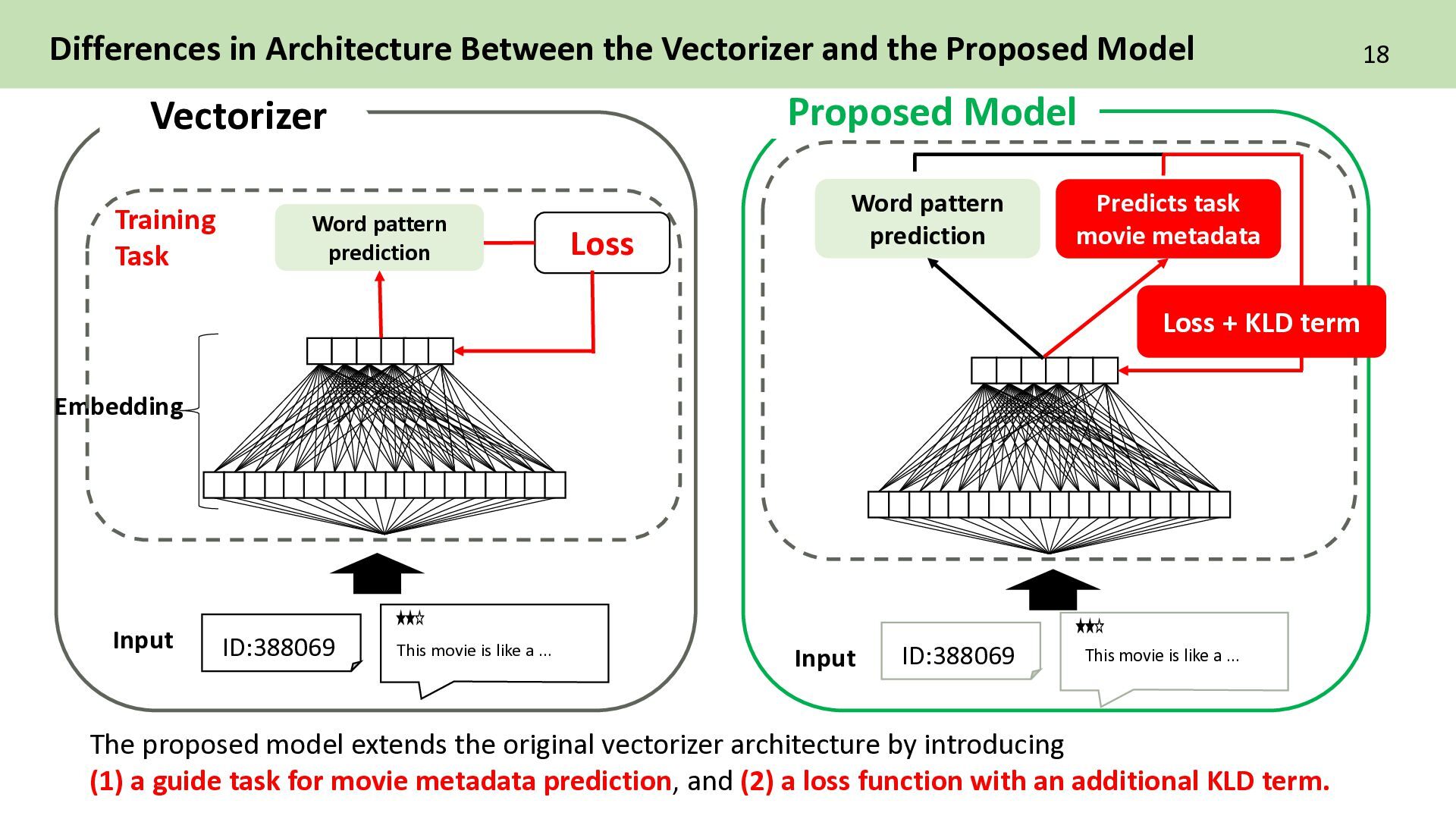
pattern prediction Training Task Vectorizer Embedding Differences in Architecture Between the Vectorizer and the Proposed Model ID:388069 Word pattern prediction Proposed Model Input ID:388069 Predicts task movie metadata Loss + KLD term This movie is like a … The proposed model extends the original vectorizer architecture by introducing (1) a guide task for movie metadata prediction, and (2) a loss function with an additional KLD term.
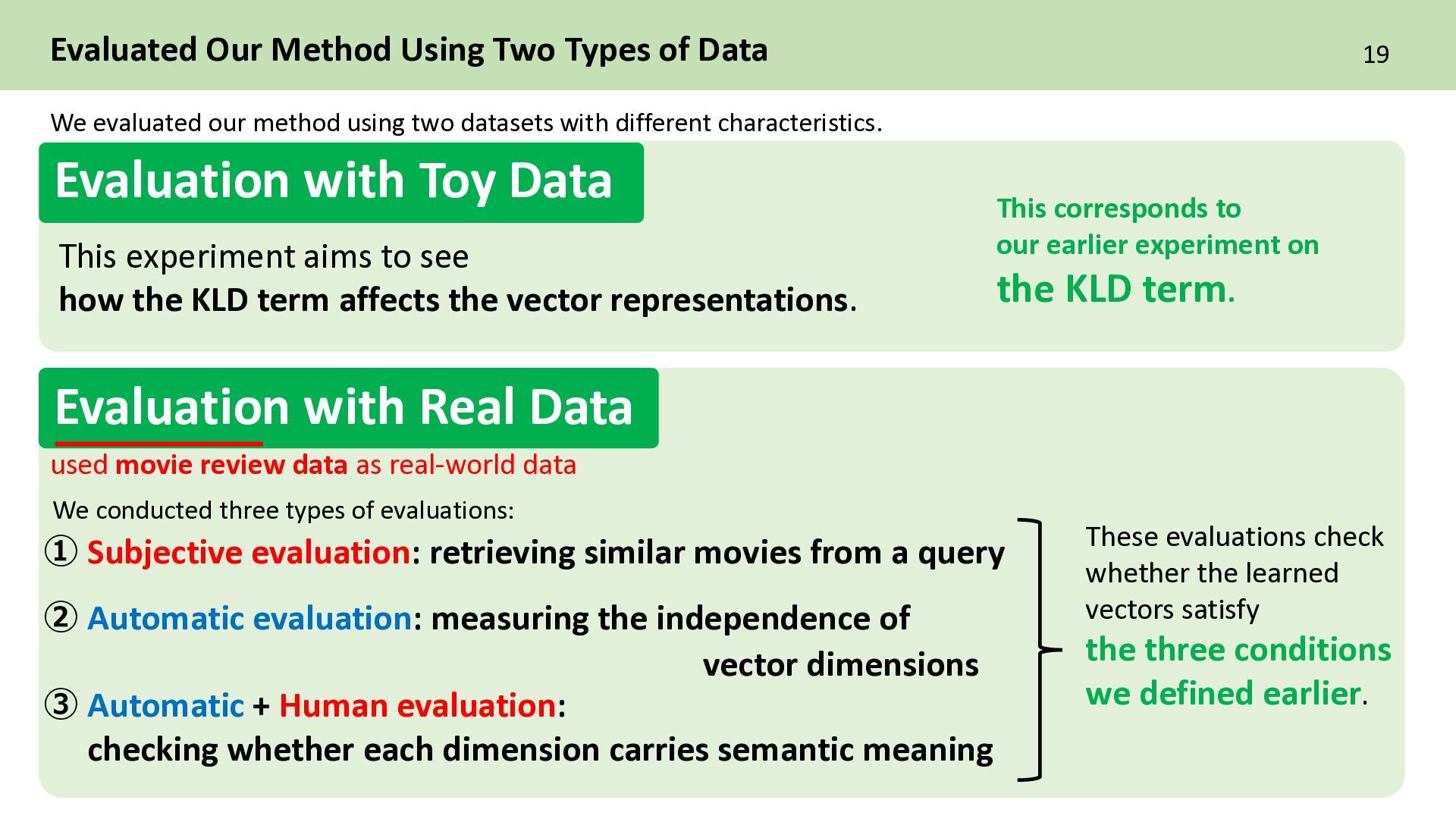
Subjective evaluation: retrieving similar movies from a query ➁ Automatic evaluation: measuring the independence of vector dimensions ③ Automatic + Human evaluation: checking whether each dimension carries semantic meaning These evaluations check whether the learned vectors satisfy the three conditions we defined earlier. This experiment aims to see how the KLD term affects the vector representations. This corresponds to our earlier experiment on the KLD term. used movie review data as real-world data Evaluation with Toy Data Evaluation with Real Data We evaluated our method using two datasets with different characteristics. We conducted three types of evaluations:
20 ➀ Subjective evaluation: retrieving similar movies from a query ➁ Automatic evaluation: measuring the independence of vector dimensions ③ Automatic + Human evaluation: checking whether each dimension carries semantic meaning The latent space should reflect real-world relational distances. Each vector dimension should be independent. Each dimension should carry an interpretable semantic meaning. Each evaluation is designed to match one of the three requirements for the document vectors.
using vectors obtained from the following settings: ・Proposed Method (Vectorizer + Guide Task + KLD) ・Without KLD (Vectorizer + Guide Task) ・Without Guide Task (Vectorizer + KLD) ・Baseline (Vectorizer with only word prediction) Comparison Methods (Using Real Data) Dataset We used the IMDb Review Dataset released on Kaggle. From this dataset, we selected 1,000 movies that satisfy the following: ・Each movie has at least 50 reviews ・IMDb provides metadata for the movie Number of Movie IDs:1,000 Number of Reviews:50,000 Total Number of Words:4,673,717 Number of Metadata Categories (Genres):22 Hyperparameters Value Dimensionality of Vector Representation 50 Batch Size 800 Negative Sampling 5 Epochs 10 Window size 5 ・Used negative sampling to speed up training. ・Applied a sigmoid annealing scheduler to prevent training collapse in early epochs. Dataset Detail
a query Evaluation Criterion:Check whether movies similar to the query appear at the top of the ranking. Similarity ranking for the query movie rank title sim 1 Iron Man2 0.91 2 Iron Man3 0.89 3 Spider Man 0.88 4 Avengers 0.87 compute cosine similarity between all movie vectors. We manually evaluated the ranking results, following the qualitative evaluation style used in word2vec studies, focusing on the top-ranked items. Query Movie rank Proposed Method Without KLD Without Guide Task Baseline 1 Iron Man Three Iron Man Three Iron Man Three Iron Man Three 2 Avengers: Age of Ultron Spider-Man: Homecoming Avengers: Age of Ultron Avengers: Age of Ultron 3 Captain America: Civil War Captain Marvel Captain America: Civil War Captain America: The Winter Soldier rank Proposed Method Without KLD Without Guide Task Baseline 1 Rocketman (Ⅰ) Rocketman (Ⅰ) Rocketman (Ⅰ) Rocketman (Ⅰ) 2 Walk the Line Walk the Line Walk the Line Walk the Line 3 The Greatest Showman The Pianist Yesterday(Ⅲ) First Man Case Study➀ Query Movie 「Iron Man Ⅱ」 Case Study➁ Query Movie 「Bohemian Rhapsody」 All methods produced vectors that reflected real-world similarity in the latent space. Key Finding① Observation ① For all methods, movies from the Marvel series ranked at the top. Observation ② Across all methods, music-themed movies ranked at the top. We evaluate whether the vector space captures real-world similarity —that is, whether similar movies appear close in the latent space.
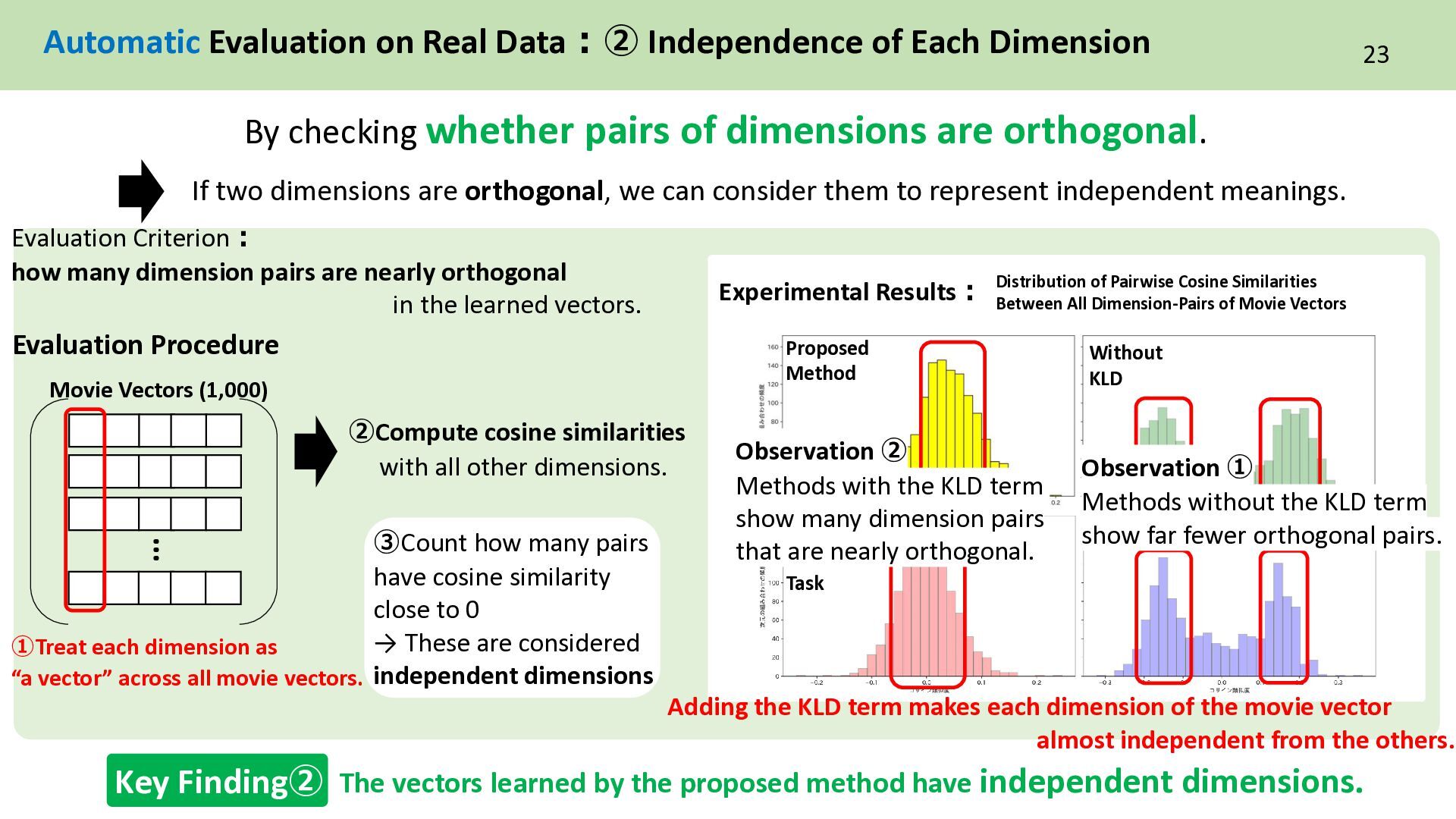
If two dimensions are orthogonal, we can consider them to represent independent meanings. … Movie Vectors (1,000) ➀Treat each dimension as “a vector” across all movie vectors. ➁Compute cosine similarities with all other dimensions. ③Count how many pairs have cosine similarity close to 0 → These are considered independent dimensions Adding the KLD term makes each dimension of the movie vector almost independent from the others. The vectors learned by the proposed method have independent dimensions. Key Finding② Experimental Results: Proposed Method Without KLD Without Guide Task Baseline Distribution of Pairwise Cosine Similarities Between All Dimension-Pairs of Movie Vectors By checking whether pairs of dimensions are orthogonal. Evaluation Criterion: how many dimension pairs are nearly orthogonal in the learned vectors. Observation ➁ Methods with the KLD term show many dimension pairs that are nearly orthogonal. Observation ① Methods without the KLD term show far fewer orthogonal pairs. Evaluation Procedure
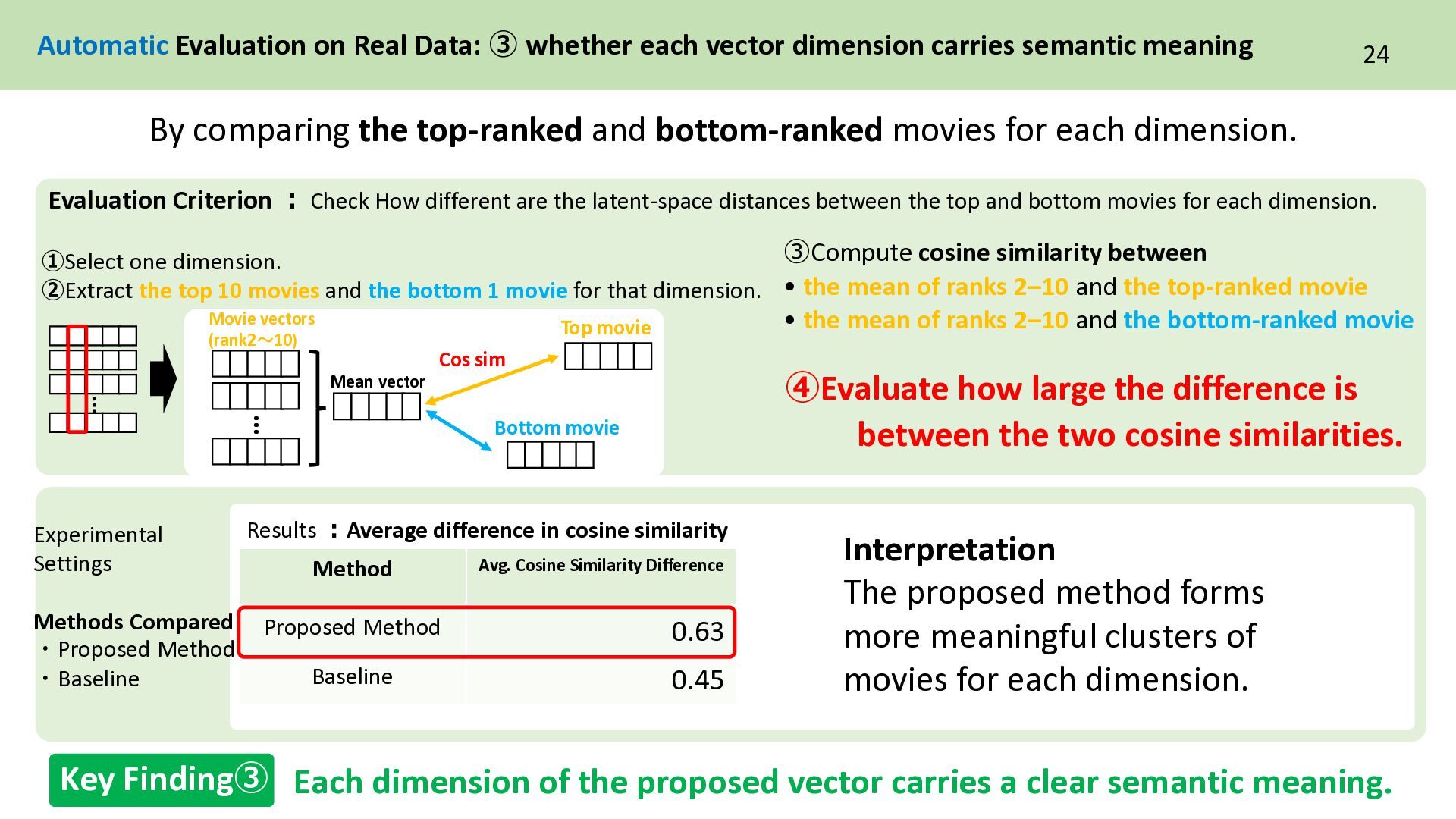
the bottom 1 movie for that dimension. … Movie vectors (rank2~10) Bottom movie Top movie ③Compute cosine similarity between • the mean of ranks 2–10 and the top-ranked movie • the mean of ranks 2–10 and the bottom-ranked movie Evaluation Criterion : Check How different are the latent-space distances between the top and bottom movies for each dimension. Experimental Settings Methods Compared ・Proposed Method ・Baseline Method Avg. Cosine Similarity Difference Proposed Method 0.63 Baseline 0.45 Interpretation The proposed method forms more meaningful clusters of movies for each dimension. Automatic Evaluation on Real Data: ③ whether each vector dimension carries semantic meaning … ④Evaluate how large the difference is between the two cosine similarities. Results :Average difference in cosine similarity Mean vector Cos sim Each dimension of the proposed vector carries a clear semantic meaning. Key Finding③ By comparing the top-ranked and bottom-ranked movies for each dimension.
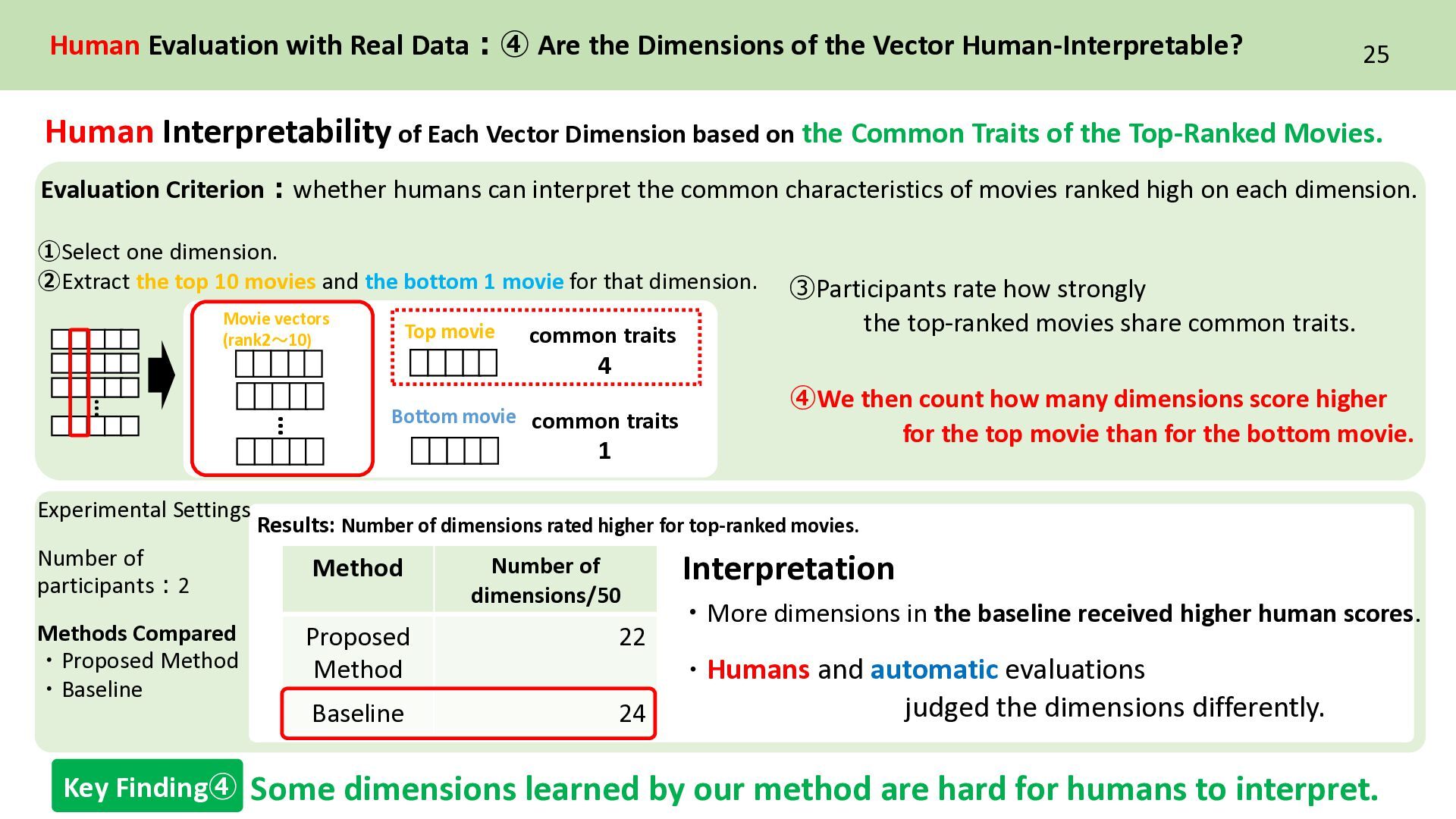
movies share common traits. Method Number of dimensions/50 Proposed Method 22 Baseline 24 ・More dimensions in the baseline received higher human scores. Human Evaluation with Real Data:④ Are the Dimensions of the Vector Human-Interpretable? … ④We then count how many dimensions score higher for the top movie than for the bottom movie. Results: Number of dimensions rated higher for top-ranked movies. common traits 4 1 Some dimensions learned by our method are hard for humans to interpret. Key Finding④ Evaluation Criterion:whether humans can interpret the common characteristics of movies ranked high on each dimension. ・Humans and automatic evaluations judged the dimensions differently. Human Interpretability of Each Vector Dimension based on the Common Traits of the Top-Ranked Movies. Movie vectors (rank2~10) Top movie common traits Experimental Settings Number of participants:2 Methods Compared ・Proposed Method ・Baseline Interpretation ➀Select one dimension. ➁Extract the top 10 movies and the bottom 1 movie for that dimension.
document vectors obtained by the proposed method: 1. reflect real-world distances; 2. exhibit dimensional independence; 3. potentially include dimensions that are difficult for humans to interpret.
which each dimension in the document embedding acquires semantic meaning. Evaluation of the Method ・Vector evaluation using toy data, ・Vector evaluation using real data. Experimental Findings ・Based on an extended doc2vec framework, ・Key Strategy 1: Guide task reflecting document characteristics, and ・Key Strategy 2: Loss function promoting the disentangled nature of the embedding. ・Our method learns document vectors with independent dimensions without sacrificing retrieval performance, ・Each vector dimension shows semantically coherent meaning, which can potentially be interpretable by humans.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}