FutureCon2022での登壇資料です。 エッジデバイスのような計算リソースの限られた環境上でDeepLearningモデルを可能な限り高速で動作させる工夫についてお話しました。 主なトピックとしては、TFLiteによるモデルの量子化手法と推論、Intel Neural Compute Stick2を用いた推論の2本立てになり、動作検証にはRaspberry Piを用います。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
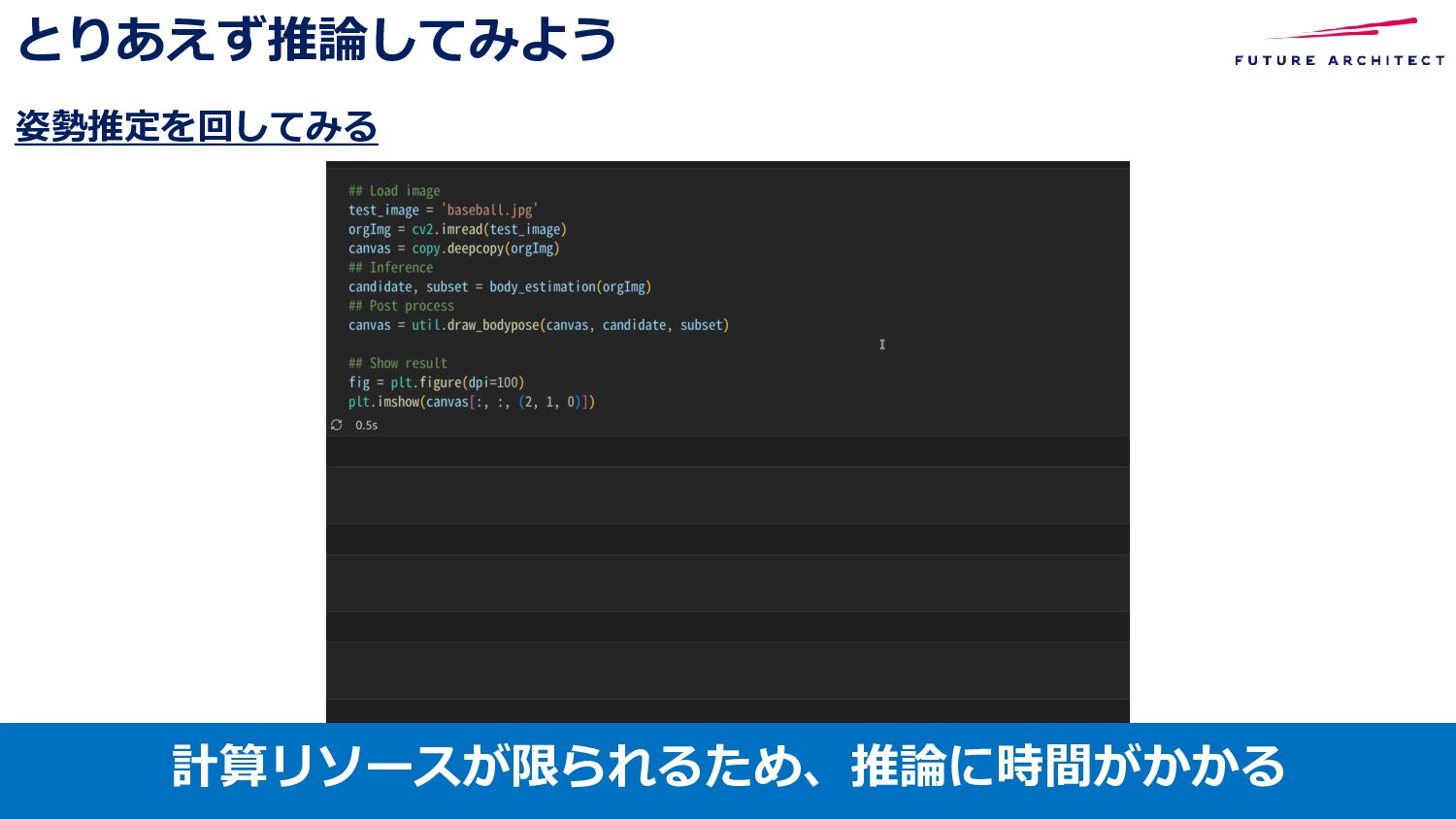{kind=link}
{kind=link}
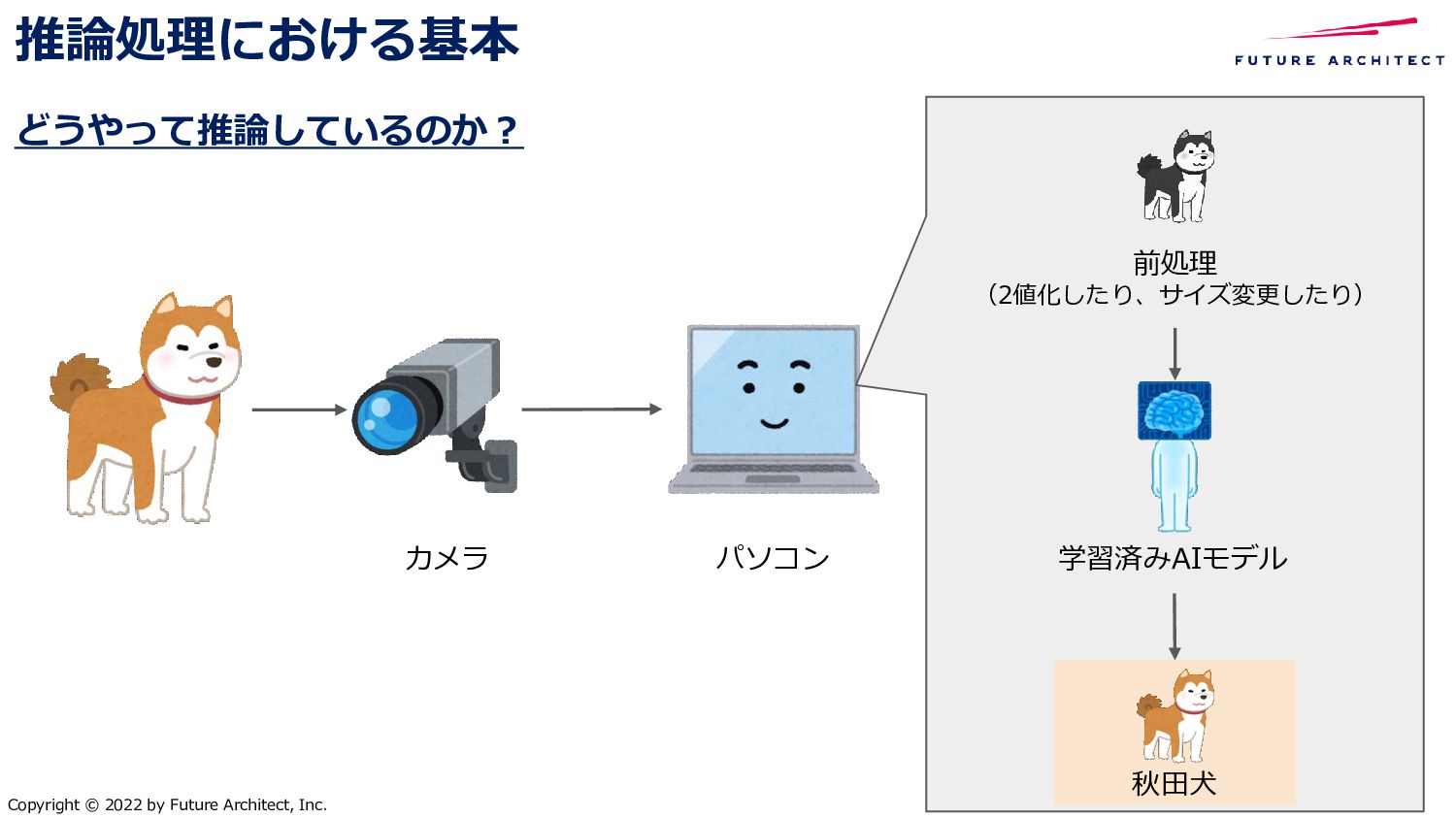{kind=link}
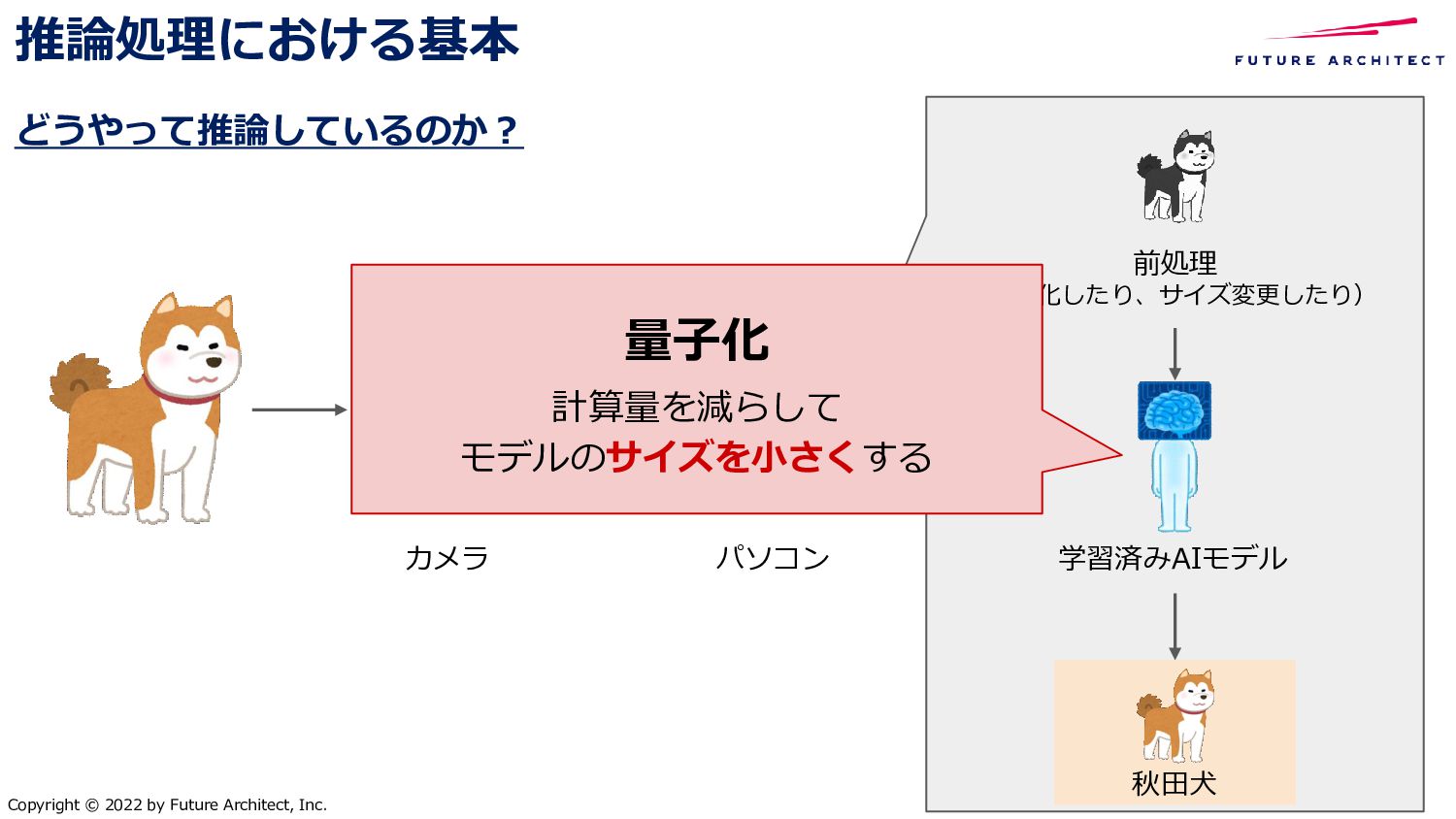{kind=link}
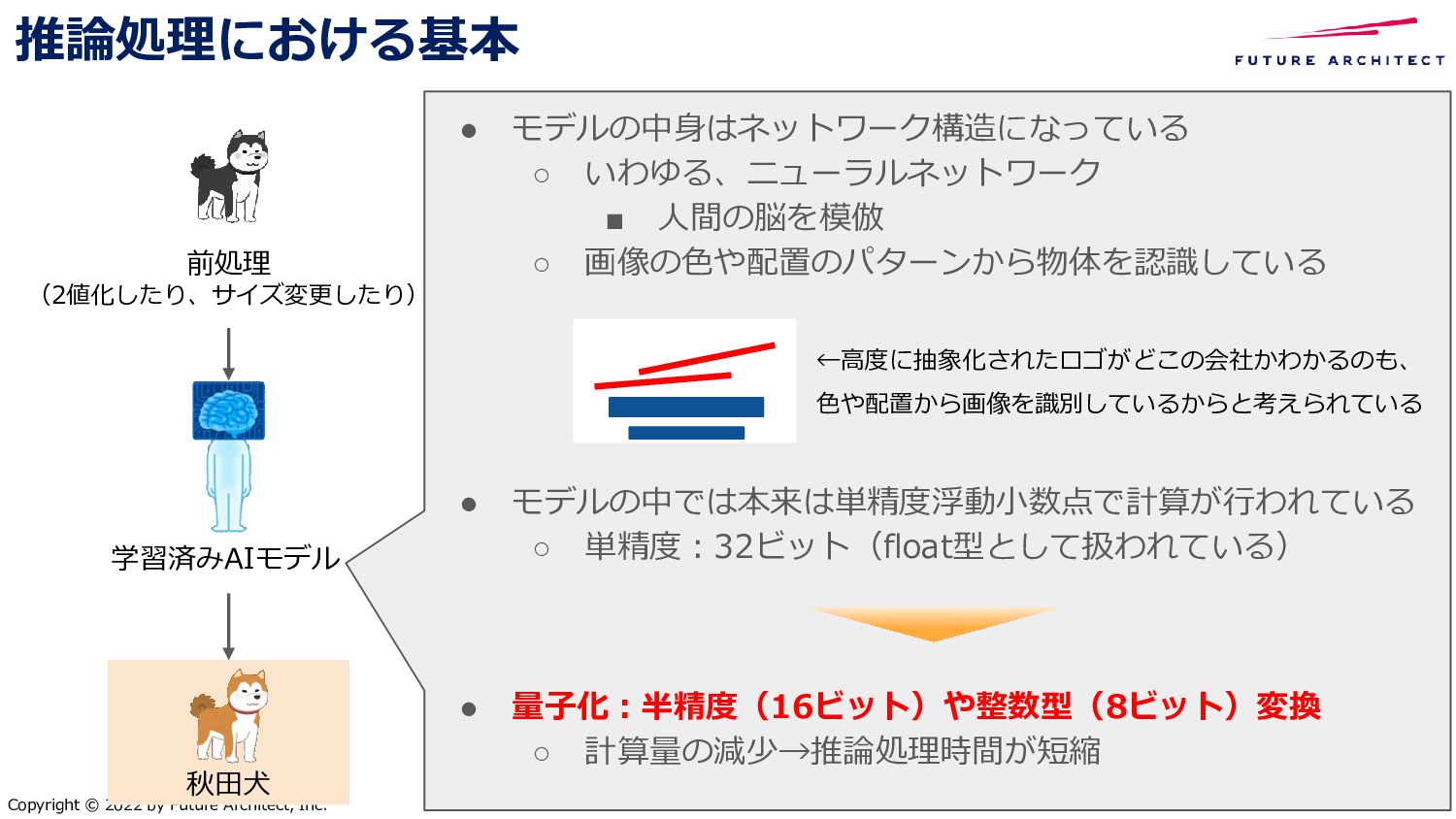{kind=link}
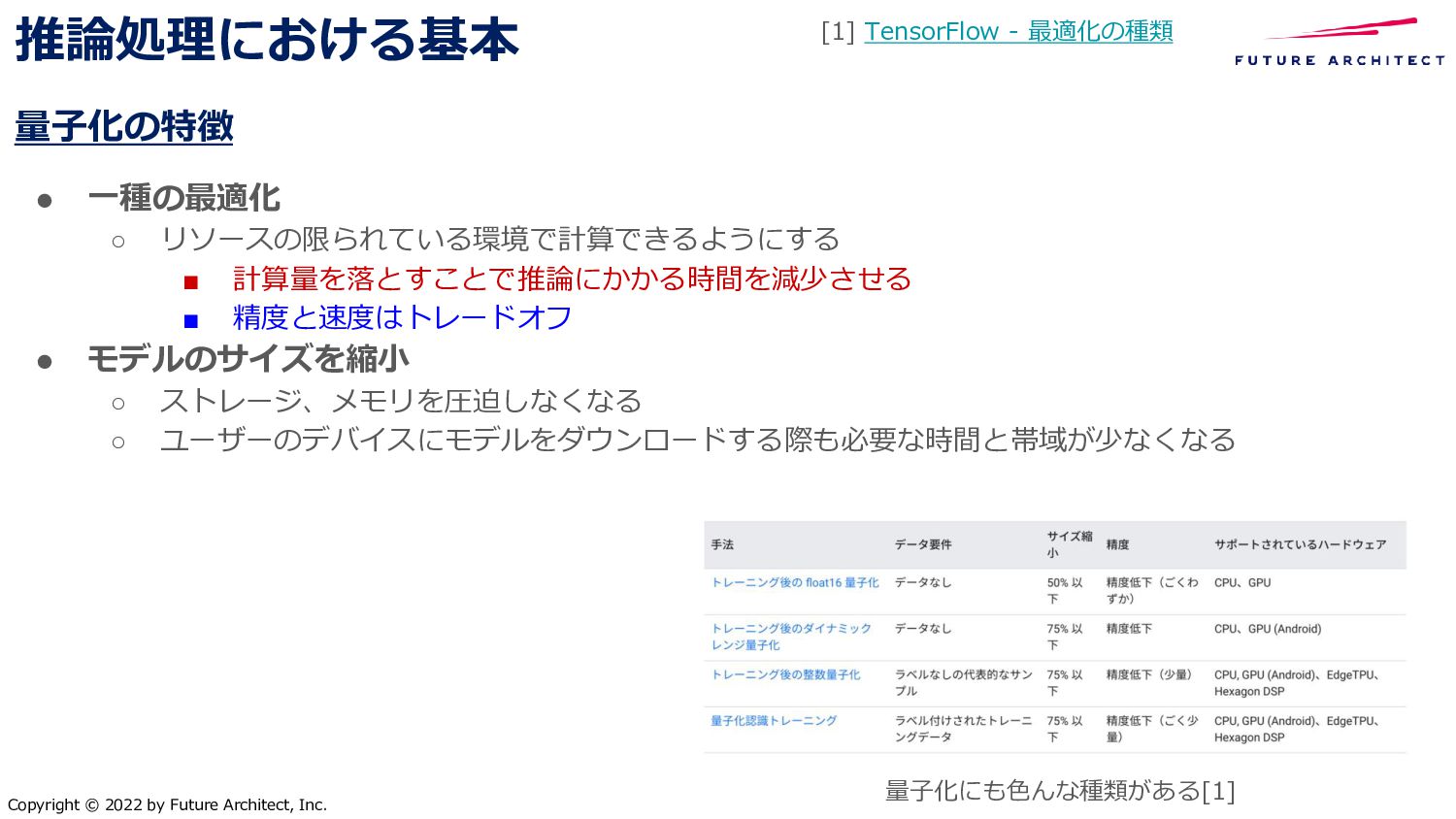{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
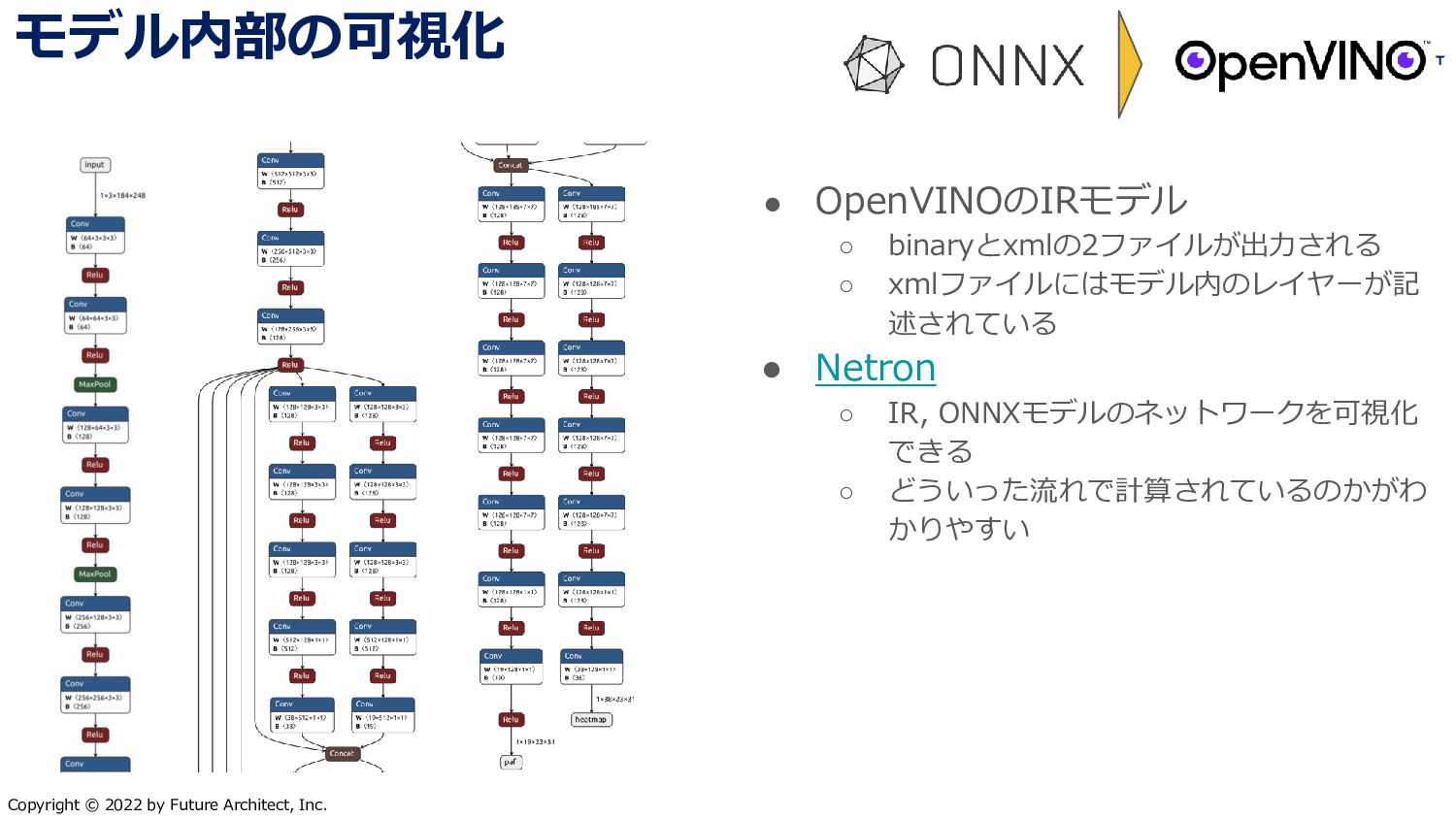{kind=link}
{kind=link}
![Copyright © 2022 by Future Architect, Inc. モデルの量子化手順 TensorFlow→TensorFlow Lite(int8量子化)[4]](https://files.speakerdeck.com/presentations/fc1ec14943194057b6be681502d365cf/slide_19.jpg){kind=link}
{kind=link}
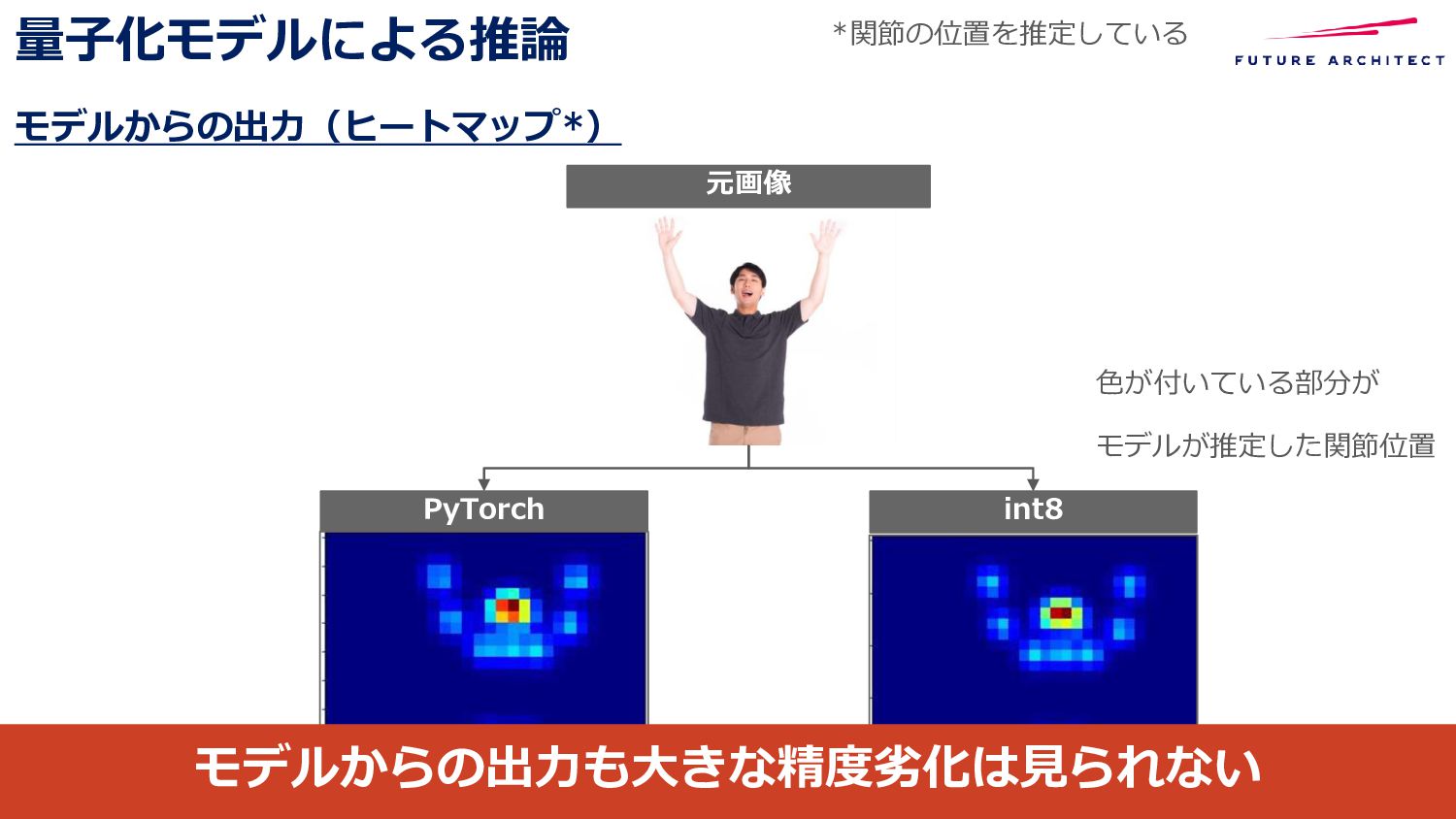{kind=link}
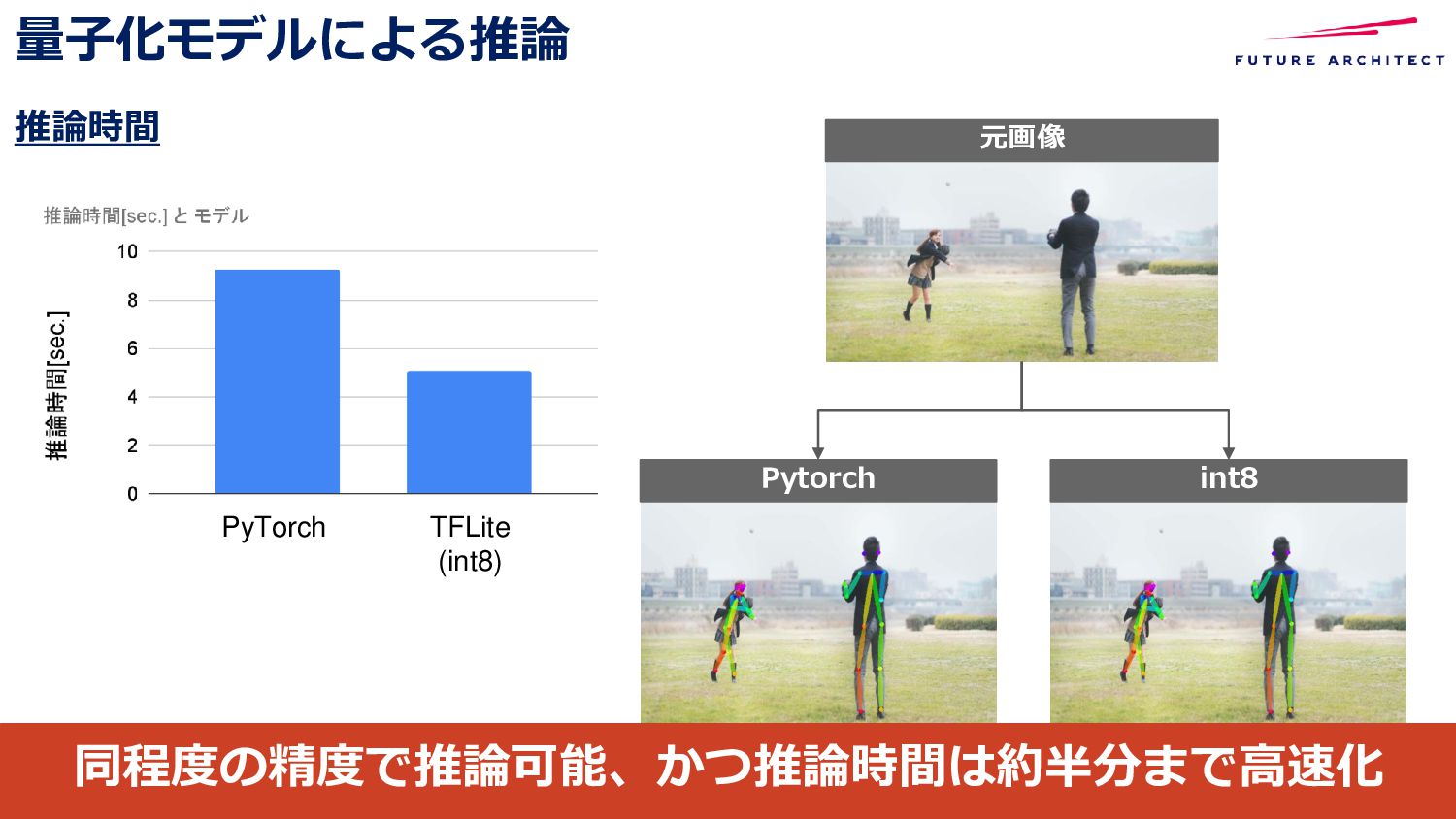{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
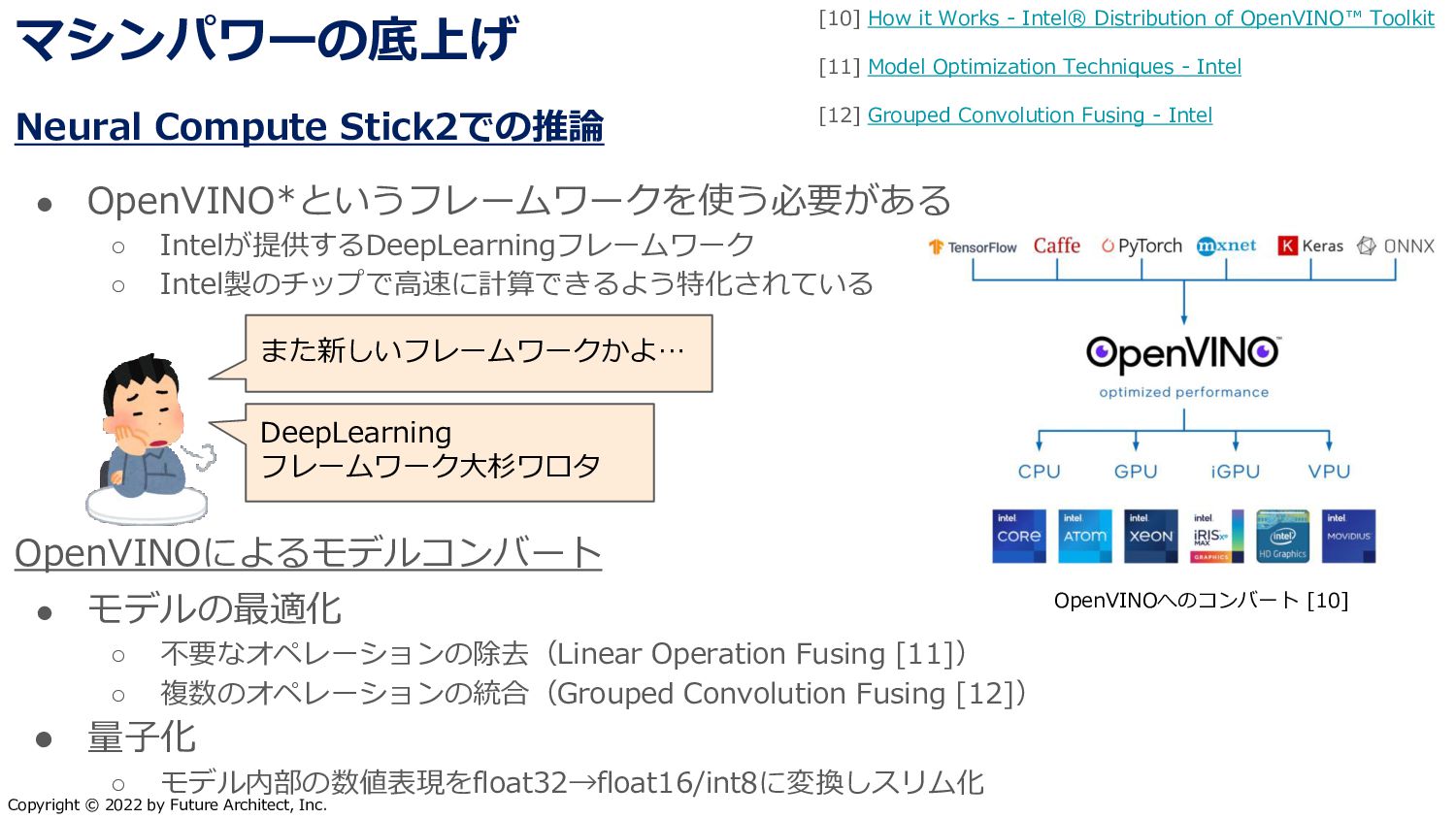{kind=link}
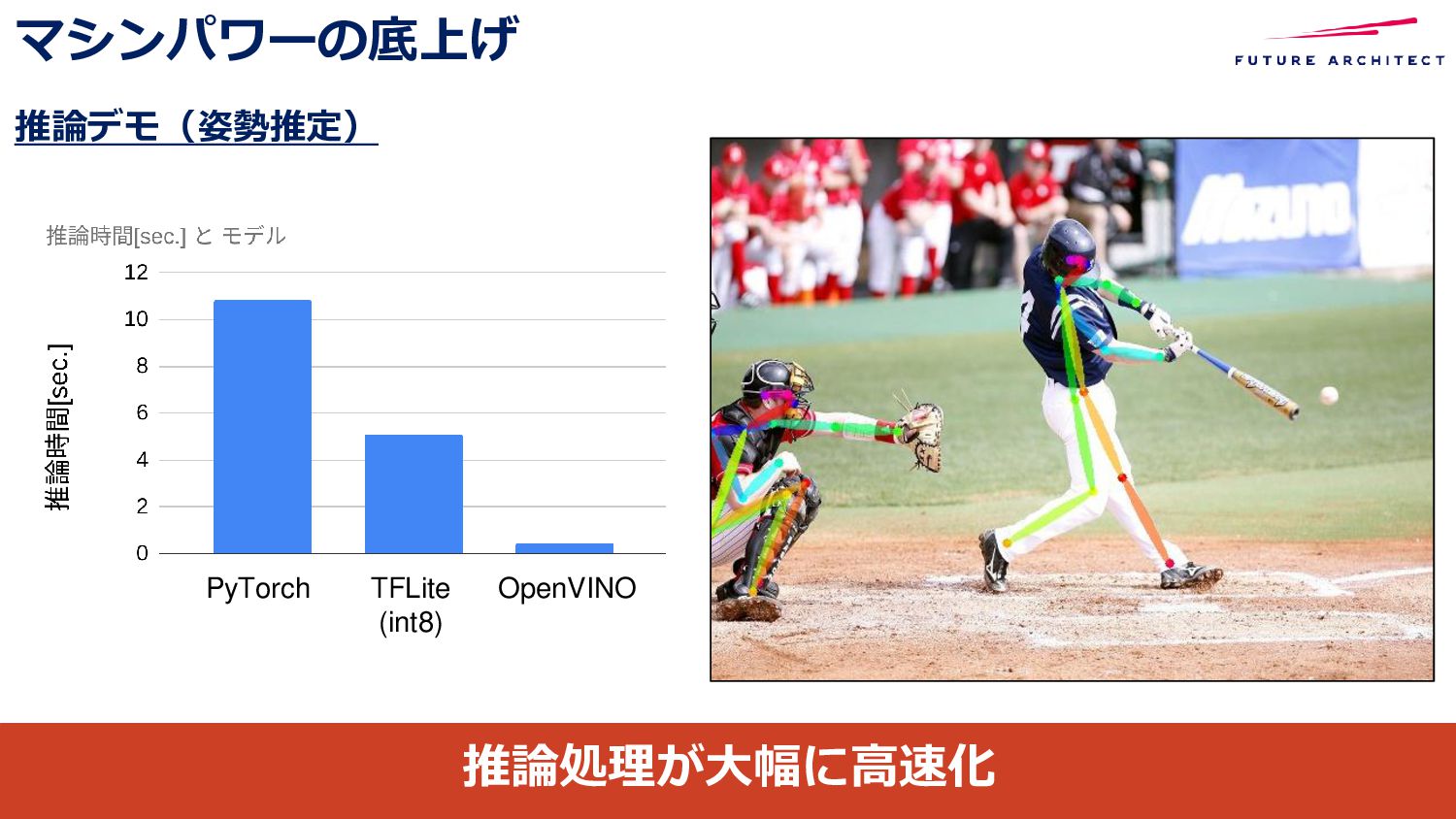{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}