Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AVSRの世界と日本語特化モデル開発の裏側.pdf
Search
Sloth
January 15, 2026
590
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AVSRの世界と日本語特化モデル開発の裏側.pdf
Sloth
January 15, 2026
More Decks by Sloth
See All by Sloth
Core Audio tapを使ったリアルタイム音声処理のお話
yuta0306
0
410
Generative Spoken Dialogue Language Modeling [対話論文読み会@電通大]
yuta0306
1
470
Featured
See All Featured
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Balancing Empowerment & Direction
lara
6
1.2k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Test your architecture with Archunit
thirion
1
2.3k
Transcript
None
自己紹介 佐々木 裕多 2019.4 ~ 2023.3 岩手大学 ユーモア認識研究、この辺りから音声処理を触り始める 2023.4 ~ 東京科学大 休学中(来年度戻らないと在籍期間超過😇) 2023.7
~ Reazon Human Interaction Lab Audio-Visual Speech Recognitionの日本語モデル開発 Speech SSLの日本語モデル開発 2024.3 ~ Kotoba Technologies フロント, バックエンド, モデル推論, インフラ, モバイル... @Sloth65557166
Reazon Human Interaction Labについて https://hilab.jp/ AI Robotics Speech & NLP
なぜAVSR (Audio-Visual Speech Recognition)? サービスロボットがデプロイ される環境の多くは... • 複数人の声が混在する カクテルパーティ環境下 •
話者とマイクの距離が離れ ている場合も多い
なぜAVSR (Audio-Visual Speech Recognition)? サービスロボットがデプロイ される環境の多くは... • 複数人の声が混在する カクテルパーティ環境下 •
話者とマイクの距離が離れ ている場合も多い → ASR単体では実用性が制 限
なぜAVSR (Audio-Visual Speech Recognition)? サービスロボットがデプロイ される環境の多くは... • 複数人の声が混在する カクテルパーティ環境下 •
話者とマイクの距離が離れ ている場合も多い → 視覚情報を統合し、 頑健性向上すればいい!
AVista を本日1/15リリース https://huggingface.co/collections/enactic/avista SSLの中間モデルも含め全公開 16個のモデルをリリース
1. データセット構築 2. モデル選定&実装 3. モデル学習 4. モデル評価 5. データスケールアップ
6. リリース AVista 開発での取り組み
データセット構築
AVSR研究でよく見るデータセット https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox2.html https://mmai.io/datasets/lip_reading/ LRS3-TED, T. Afouras et al., 2018 VoxCeleb2,
J. S. Chung et al., 2018 2,400時間 400時間
大規模な日本語 AVSRデータセットは ... ない!! 最初から予想はしていたけど
データが全然集まらない 😇
まずは既存の資産を活用してみる ReazonSpeechの資産を使ってみた • 地上波主要チャンネルは全部ある ◦ 当時で2年ちょいくらいはあった • ワンセグ録画のため、豊富な動画がある • メタデータから番組やカテゴリはわかる
まずは既存の資産を活用してみる ReazonSpeechの資産を使ってみた • 地上波主要チャンネルは全部ある ◦ 当時で2年ちょいくらいはあった • ワンセグ録画のため、豊富な動画がある • メタデータから番組やカテゴリはわかる
→ 全然大規模なデータセットを構築できず...
ワンセグ録画全体の解析の何が悪手だった? • 大前提、動画解析はかなり時間がかかる • ワンセグは、顔を抽出するには小さすぎる ◦ 解像度は320×180ピクセル ◦ 「アメトーク」のようなひな壇トーク番組は、顔取り出すのがハード •
一人だけが長時間映る番組を絞るのがハード
データセットのソース要件をまとめる マスト要件 1. 長時間人が映っていること 2. なるべくノイズがなく、映る人が話者であること ノイズは後から足せる 3. ライセンスがクリーンであること (YouTubeライセンスなどは避ける)
オプショナル要件 1. できる限り一人が映ること ただし、人の映る位置が変わらないのならば許容
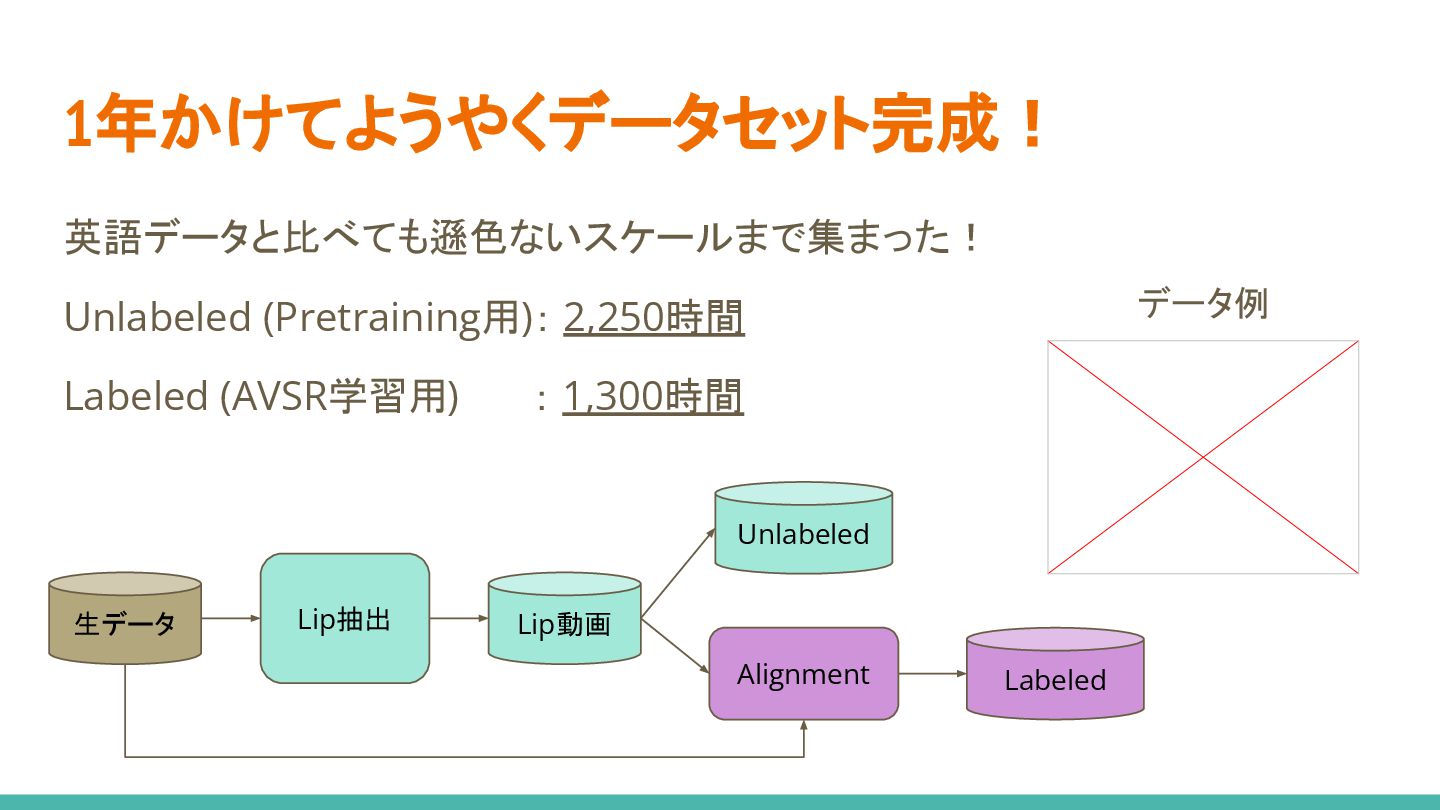
英語データと比べても遜色ないスケールまで集まった! Unlabeled (Pretraining用): 2,250時間 Labeled (AVSR学習用) : 1,300時間 1年かけてようやくデータセット完成! データ例
生データ Lip抽出 Lip動画 Unlabeled Alignment Labeled
モデル選定&実装
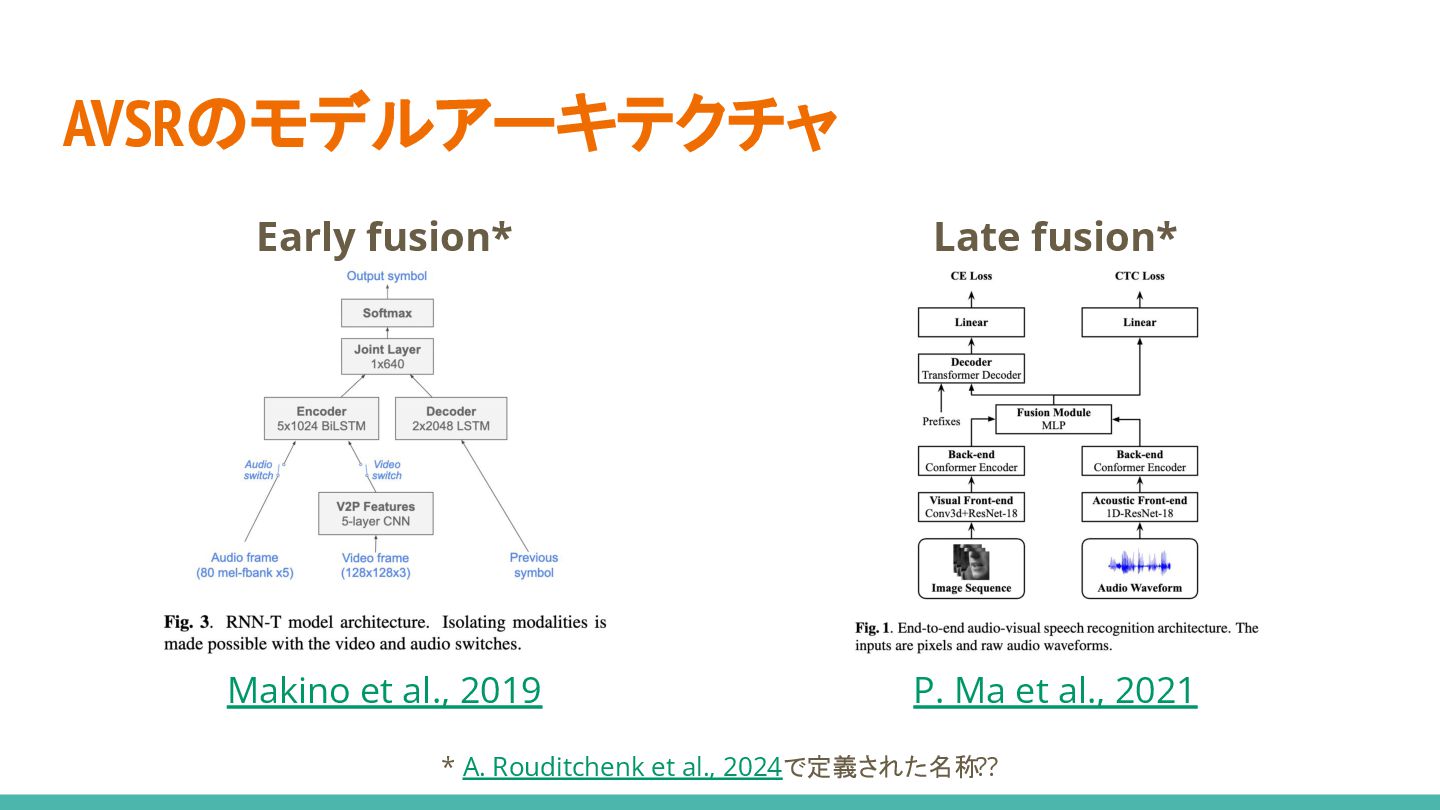
AVSRのモデルアーキテクチャ Early fusion* Late fusion* Makino et al., 2019 P.
Ma et al., 2021 * A. Rouditchenk et al., 2024で定義された名称??
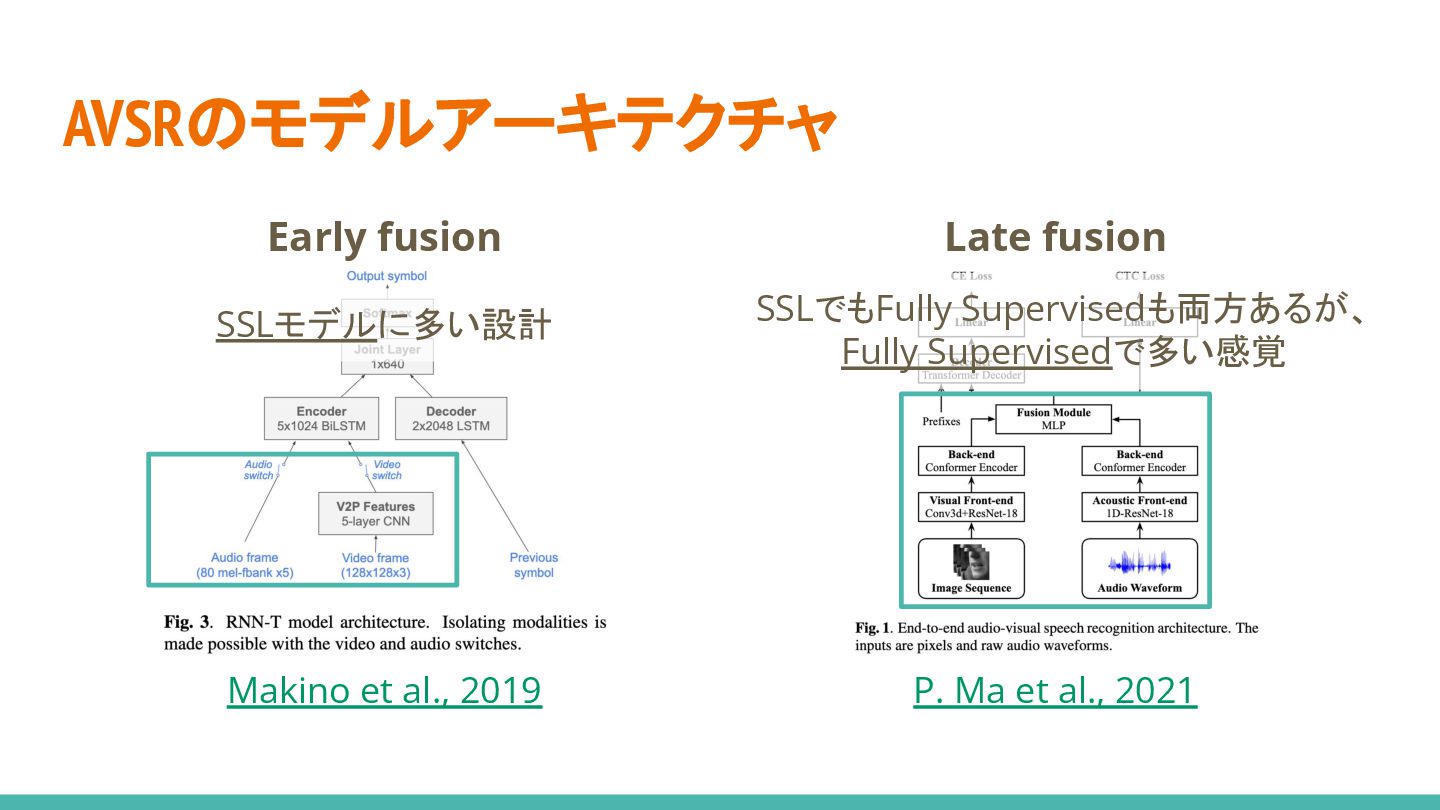
AVSRのモデルアーキテクチャ Early fusion Late fusion Makino et al., 2019 P.
Ma et al., 2021 各モダリティ軽量モジュールで処理 → Encoderへ 各モダリティをガッツリ処理 → Decoderへ
AVSRのモデルアーキテクチャ Early fusion Late fusion Makino et al., 2019 P.
Ma et al., 2021 SSLモデルに多い設計 SSLでもFully Supervisedも両方あるが、 Fully Supervisedで多い感覚
AVSRの学習方法 Fully Supervised Learning • 音声/動画を入力として、書き起こしテキストの予測を学習 • RNN-T、Conformer、Transformerなど様々 Self-Supervised Learning
• 音声/動画を入力として、エンコーダの表現を学習 ◦ 音声/動画/音声+動画の入力に対し、 同じ埋め込みにマッピングするのがキモ! • ダウンストリームタスクとして、書き起こしテキストの予測を学習 • Transformerベースが主流
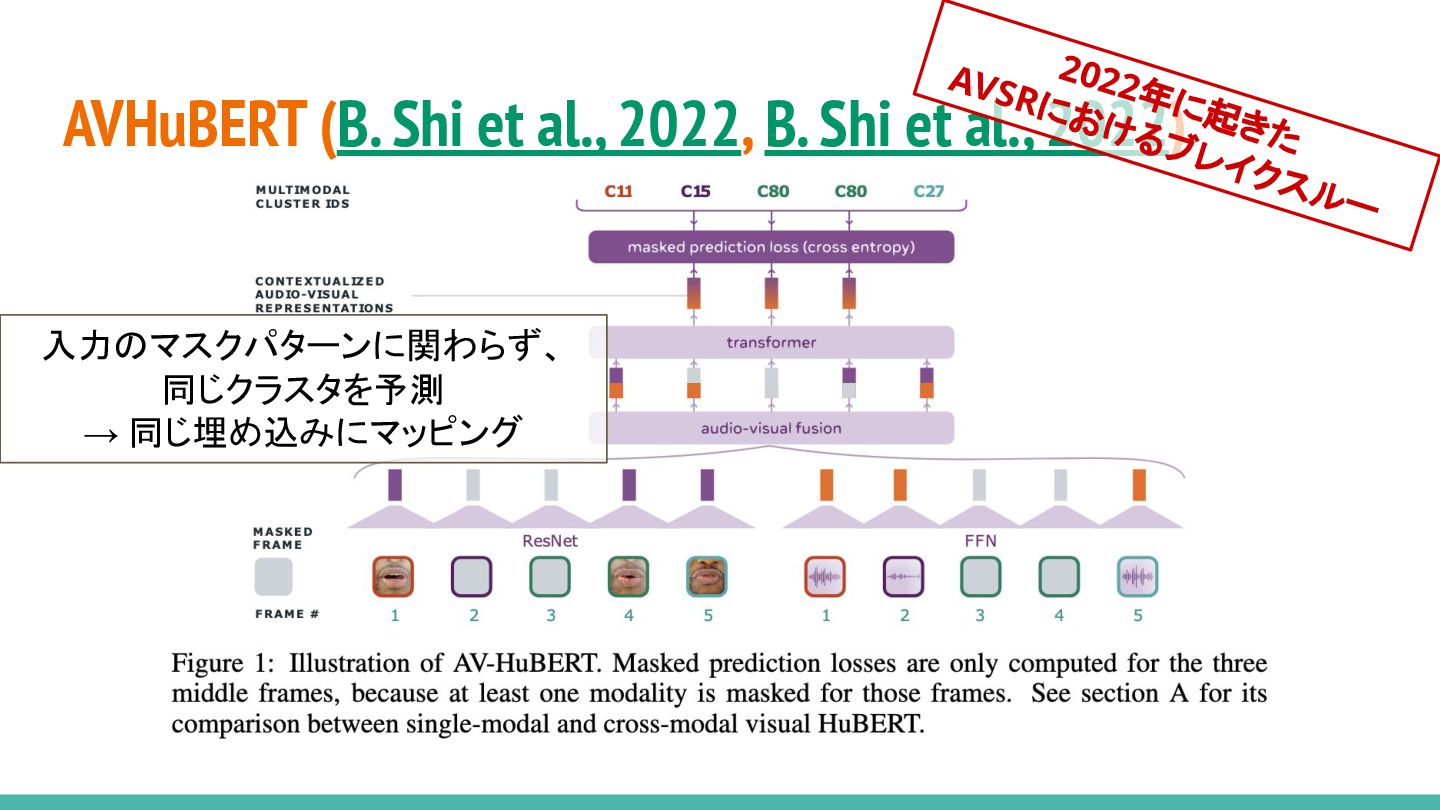
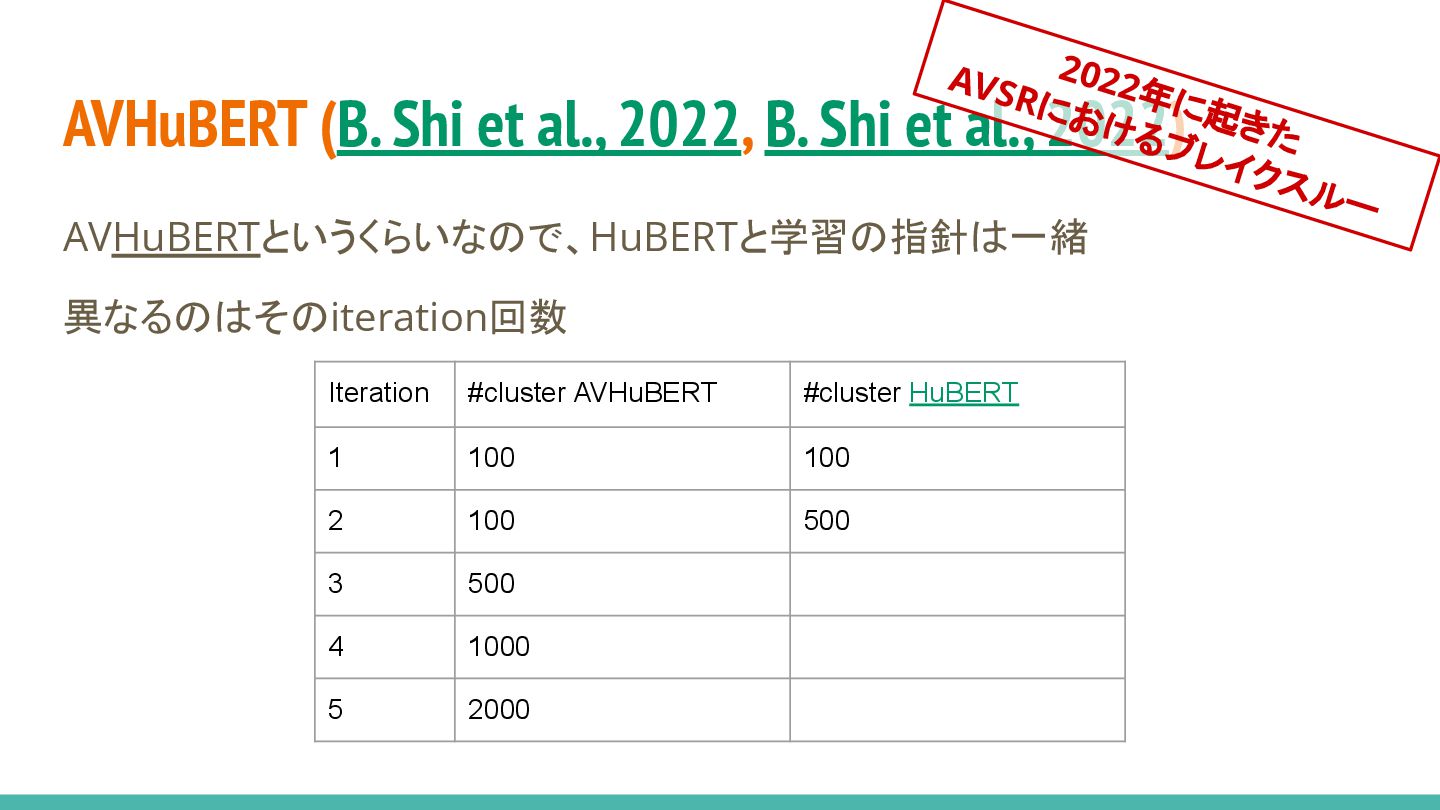
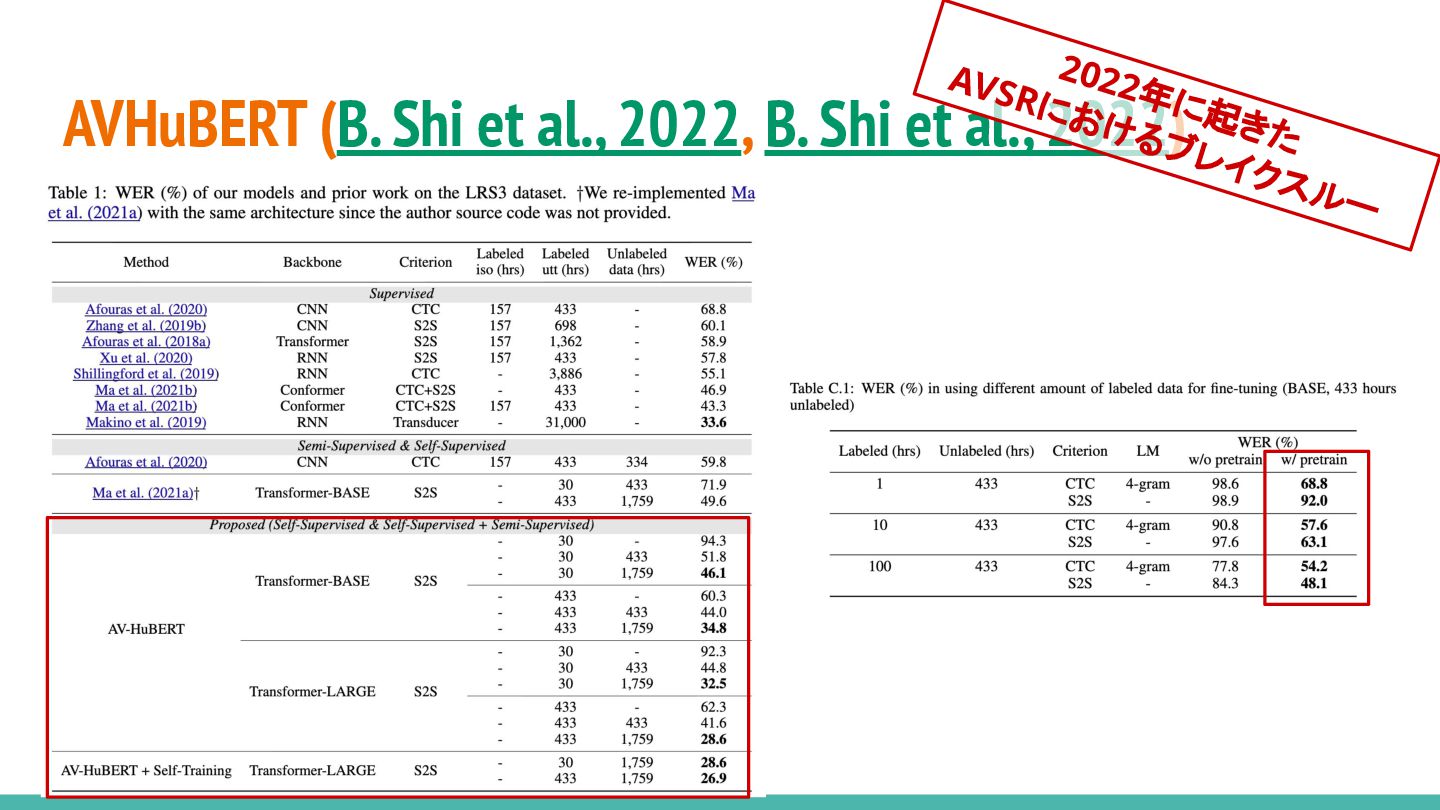
AVHuBERT (B. Shi et al., 2022, B. Shi et al.,
2022) 2022年に起きた AVSRにおけるブレイクスルー 入力のマスクパターンに関わらず、 同じクラスタを予測 → 同じ埋め込みにマッピング
AVHuBERT (B. Shi et al., 2022, B. Shi et al.,
2022) AVHuBERTというくらいなので、HuBERTと学習の指針は一緒 異なるのはそのiteration回数 2022年に起きた AVSRにおけるブレイクスルー Iteration #cluster AVHuBERT #cluster HuBERT 1 100 100 2 100 500 3 500 4 1000 5 2000
AVHuBERT (B. Shi et al., 2022, B. Shi et al.,
2022) 2022年に起きた AVSRにおけるブレイクスルー
その後多様な SSL手法が現れる Teacher-student Modeling • RAVEn (A. Haliassos et al.,
2023) • BRAVen (A. Haliassos et al., 2024) • … Self-supervised Learning • XLAVS-R (H. Han et al., 2024) • u-HuBERT (Hsu et al., 2022) • VATLM (Q. Zhu et al., 2024) • ...
モデル何使おう?どう実装しよう?
手法はAVHuBERT一択 なぜ? 1. AVSR学習用のデータが少ない a. 実際フルスクラッチ学習では性能が全く出ず... 2. 日本語AVSRを支える基盤モデルとなりうる a. 多くの論文で、本家AVHuBERTを特徴量抽出に使った実績が豊富
実運用を見据えた実装を 1. Transformersを利用 a. このLLM時代、.from_pretrainedで使える手軽さが大事 b. HuggingFace基盤を活用したい 2. AVSRの前処理で一般に使われるLip抽出をdlibからmediapipeに a.
実運用では、CPUでリアルタイムにlip抽出するべき b. mediapipeは軽量で高速! i. ありがとう、Google〜〜
モデル学習
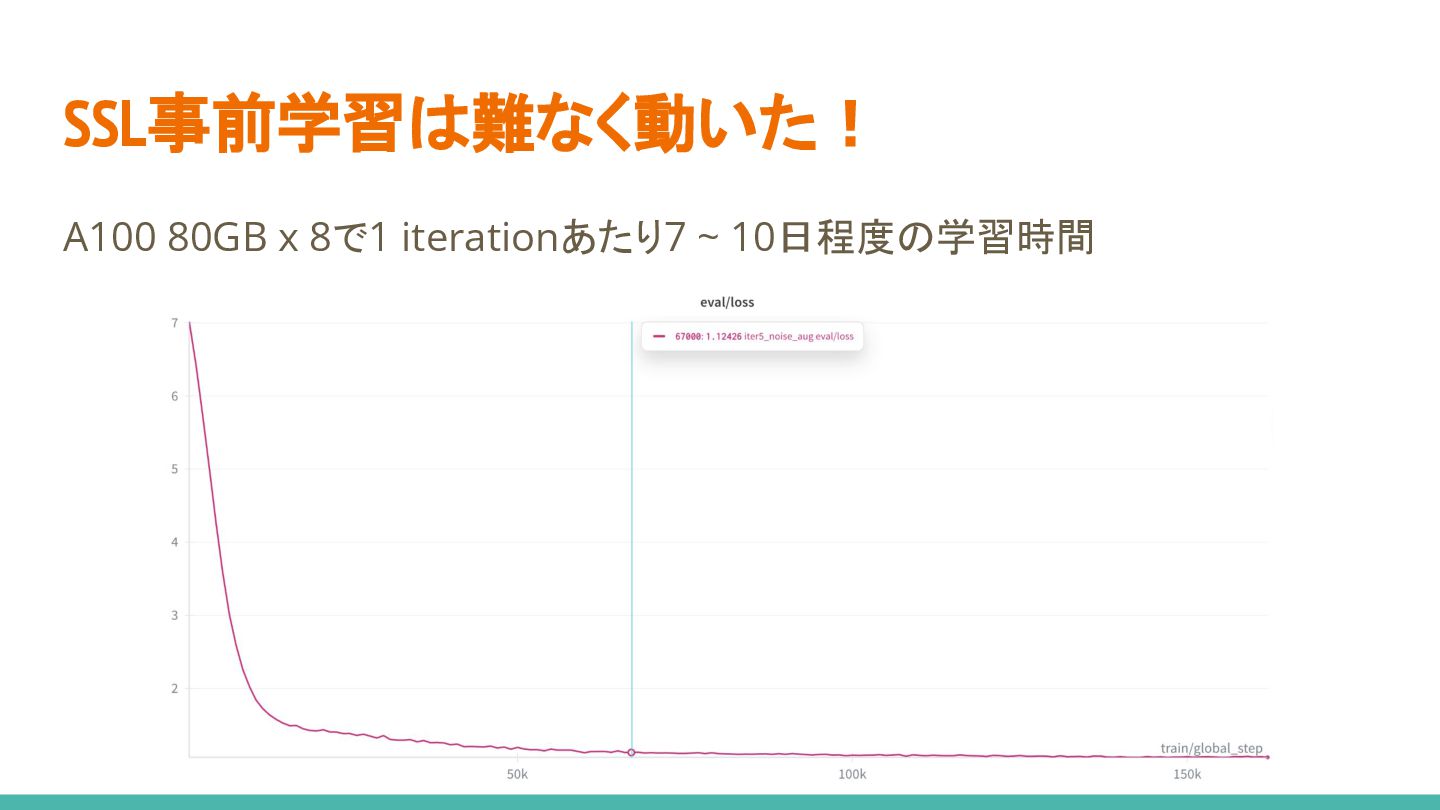
SSL事前学習は難なく動いた! A100 80GB x 8で1 iterationあたり7 ~ 10日程度の学習時間
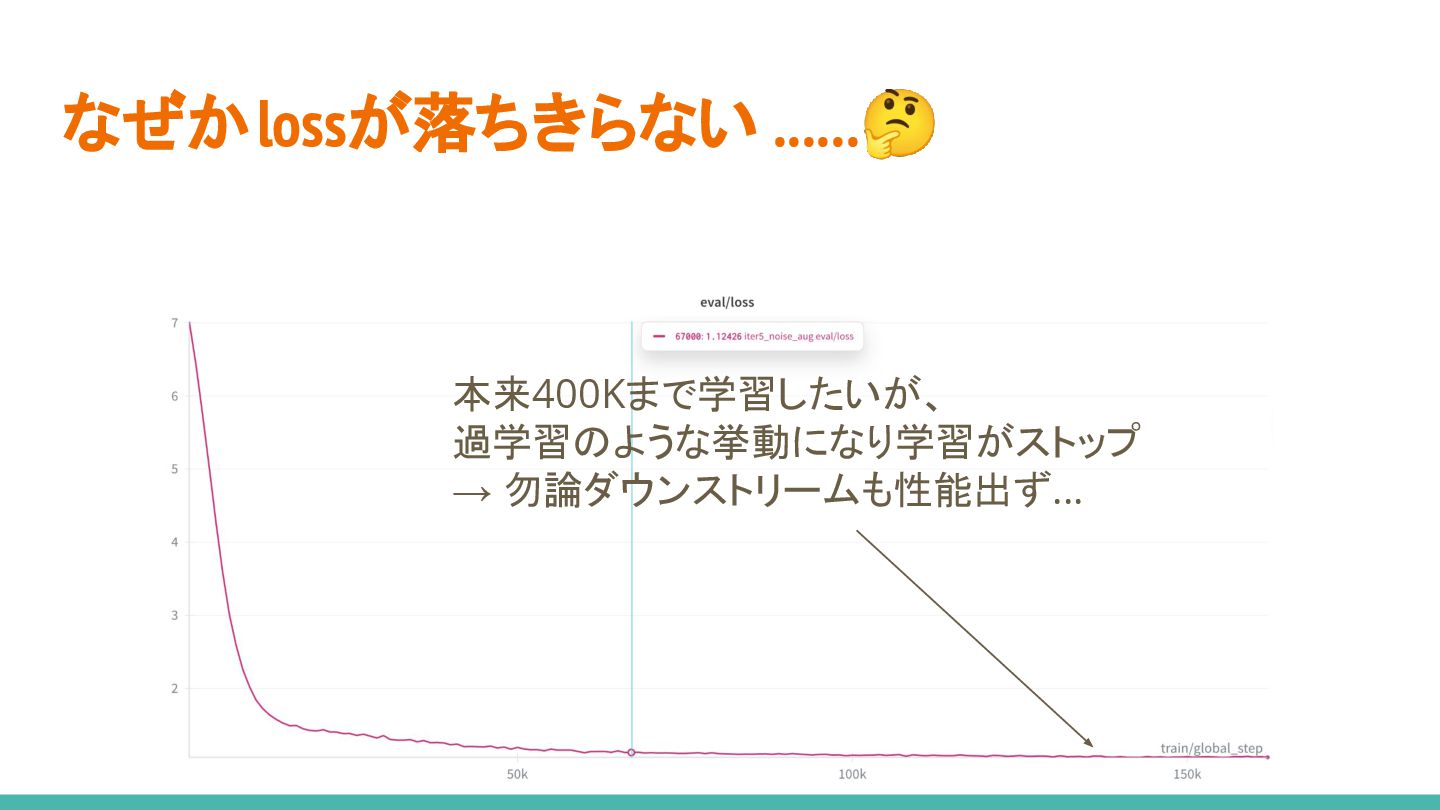
動いたように見えて、 なぜかlossが落ちきらない ......🤔
なぜかlossが落ちきらない ......🤔 本来400Kまで学習したいが、 過学習のような挙動になり学習がストップ → 勿論ダウンストリームも性能出ず...
前処理バグを発見 😱 基本的にAVSRモデルは、入力動画は25FPSを前提 今回集めたデータは30FPS → 動画後半になるほど、音声と動画のアライメントがズレてた... (ちなみに、テレビデータは29.97FPSで配信されるため、ほぼ30FPSとして扱う ことができます)
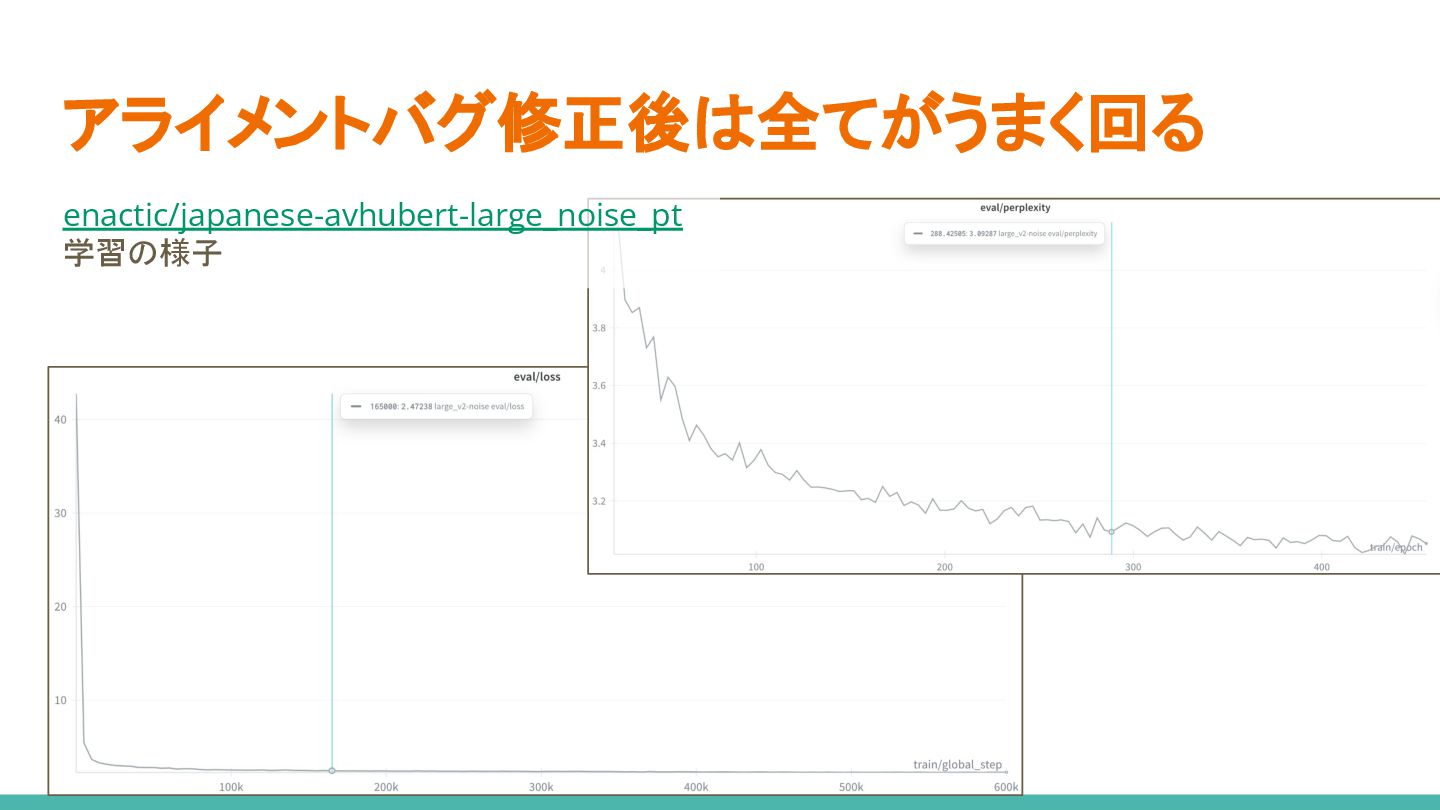
アライメントバグ修正後は全てがうまく回る enactic/japanese-avhubert-large_noise_pt 学習の様子
モデル評価
簡単なデモを作ってみると ... 「こんにちは」すら難しいぞ!? In-domainの評価はすごく高かったのにー
デモしたら全く使い物にならない ... ちゃんと評価データ作るかー
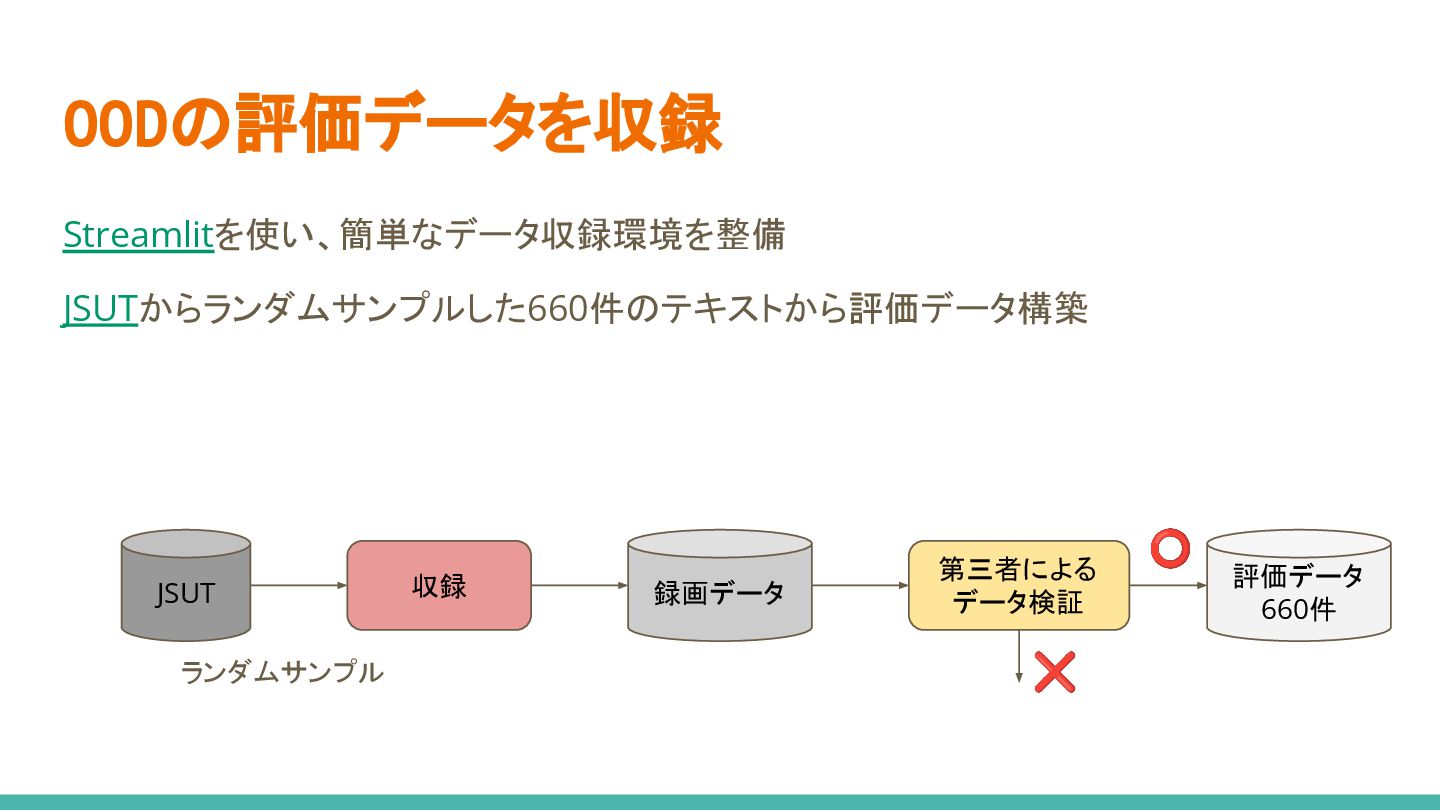
OODの評価データを収録 Streamlitを使い、簡単なデータ収録環境を整備 JSUTからランダムサンプルした660件のテキストから評価データ構築 JSUT 収録 録画データ 第三者による データ検証 評価データ 660件
ランダムサンプル ⭕ ❌
OODの評価データを収録 収録結構辛い... そのためランキングを用意して 少しでもモチベをあげてみる
作ったデータで評価してみると ノイズがなくても、OOD性能はこの有り様... → 評価パイプラインは出来上がったのでよし👍 あとはこの評価データで良い性能を出すだけ → データをスケールさせて強いモデルを作ろう!
似たような議論は行われており ... Do VSR Models Generalize Beyond LRS3? (Djilali et
al., 2023) • LRS3のテストデータは0.9hのみ • In-the-wildなテストデータを作ると VSRの性能がかなり落ちたよーとの レポート
データスケールアップ
他言語のデータセットはどう集めてる? • ViCocktail (Nguyen et al., 2025):ベトナム語 a. YouTubeから収集、ラベルはASRモデルで •
CI-AVSR (Dai et al., 2022):広東語 a. In-Carコマンド(〜まで案内して。など)に特化 b. 読み上げテキストのテンプレートを作成し、 [LOCATION]のようなプ レースホルダーを様々入れる • OLKAVS (Park et al., 2024):韓国語 a. 1,107の被験者を集め、1,150時間も収録。すごい、、、 b. GoProを使い、様々な角度から同時に収録 • などなど
改めてテレビ動画を解析 流石に数千時間規模を人手収集するのはコストが高い フルセグ収録を開始しており、改めて本気で解析を開始! (収録は他のスーパーエンジニアが対応してくれましたが、 トラブルが多くとっっっっっても大変そうでした...)
データスケール、想像以上に難しすぎる ...🤯
結局テレビ動画解析は何が難しい? • 話者が映り続くことが少なすぎる ◦ ナレーションやVTRが結構多い ◦ ニュース番組もVTRが多い • カメラワークがとても上手 ◦
バラエティやドラマは字幕もあり、良い資源に見える ◦ しかし、リアクションする側が一時的に映るなど、 話者を常にとらえるカットが意外と見当たらない ▪ 視聴者としては観てて面白いんですがー (笑) • 特定の顔を追従するのが難しい ◦ シーン中に映る位置や人数が変わる場合、 自動で同じ人を追従するのは難しい
Auto-AVSR (Ma et al., 2023) UnlabeledデータにASRモデルで擬似ラベルを 付与してスケール
Auto-AVSR (Ma et al., 2023) UnlabeledデータにASRモデルで擬似ラベルを 付与してスケール 今回はそもそもAVデータ量のスケールが難しい状況のため この手の手法は向かず...
Interleaved Training Protocol (Li et al., 2024) これは本当に革命的 1. 大規模な音声データセットと
低資源なAVデータセットを両方使う 2. ミニバッチ作成時、Audio/AVのどちらか一方 のプールからデータをサンプリング 3. ノイズ耐性は多少犠牲にしつつ、 基本性能を底上げ
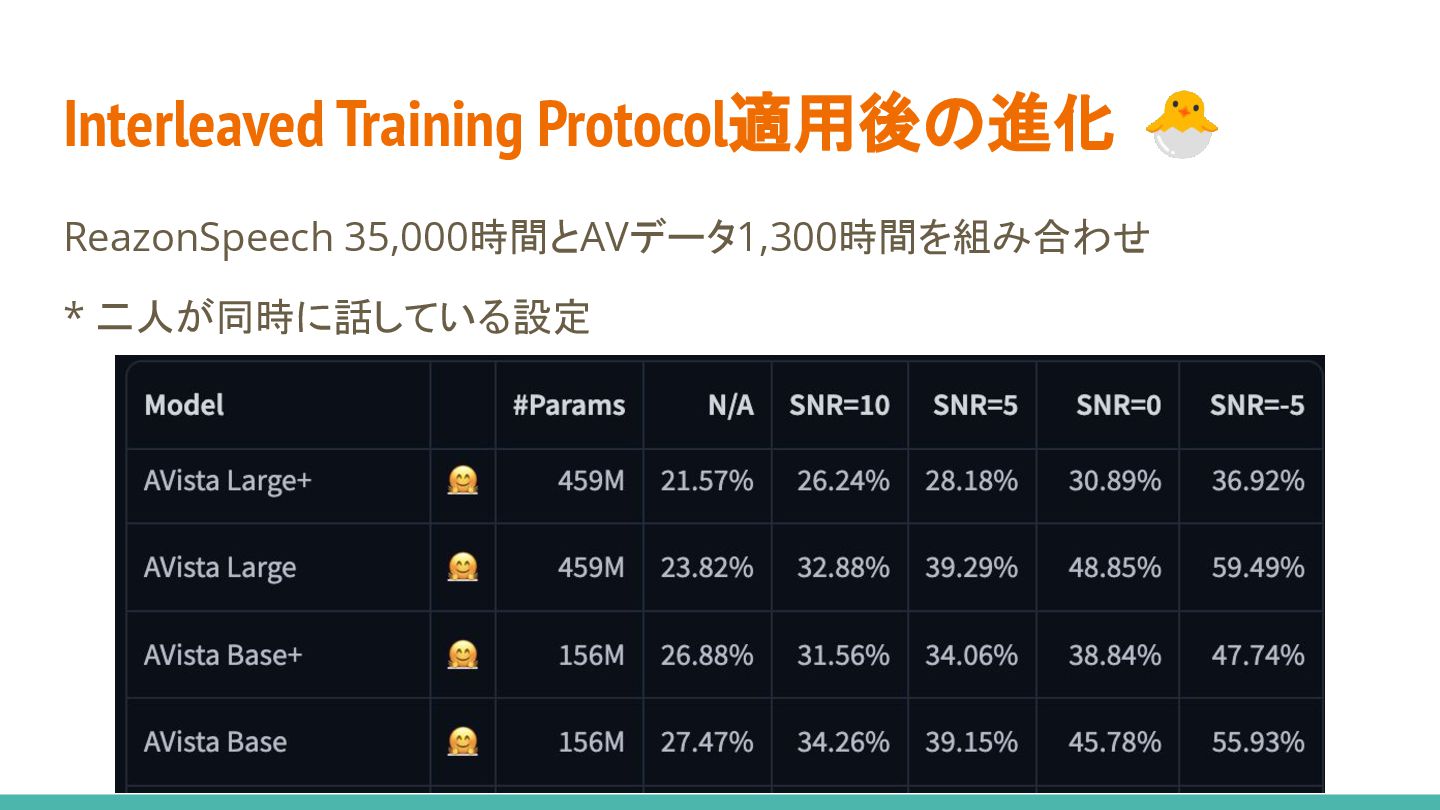
Interleaved Training Protocol適用後の進化 🐣 ReazonSpeech 35,000時間とAVデータ1,300時間を組み合わせ * 二人が同時に話している設定
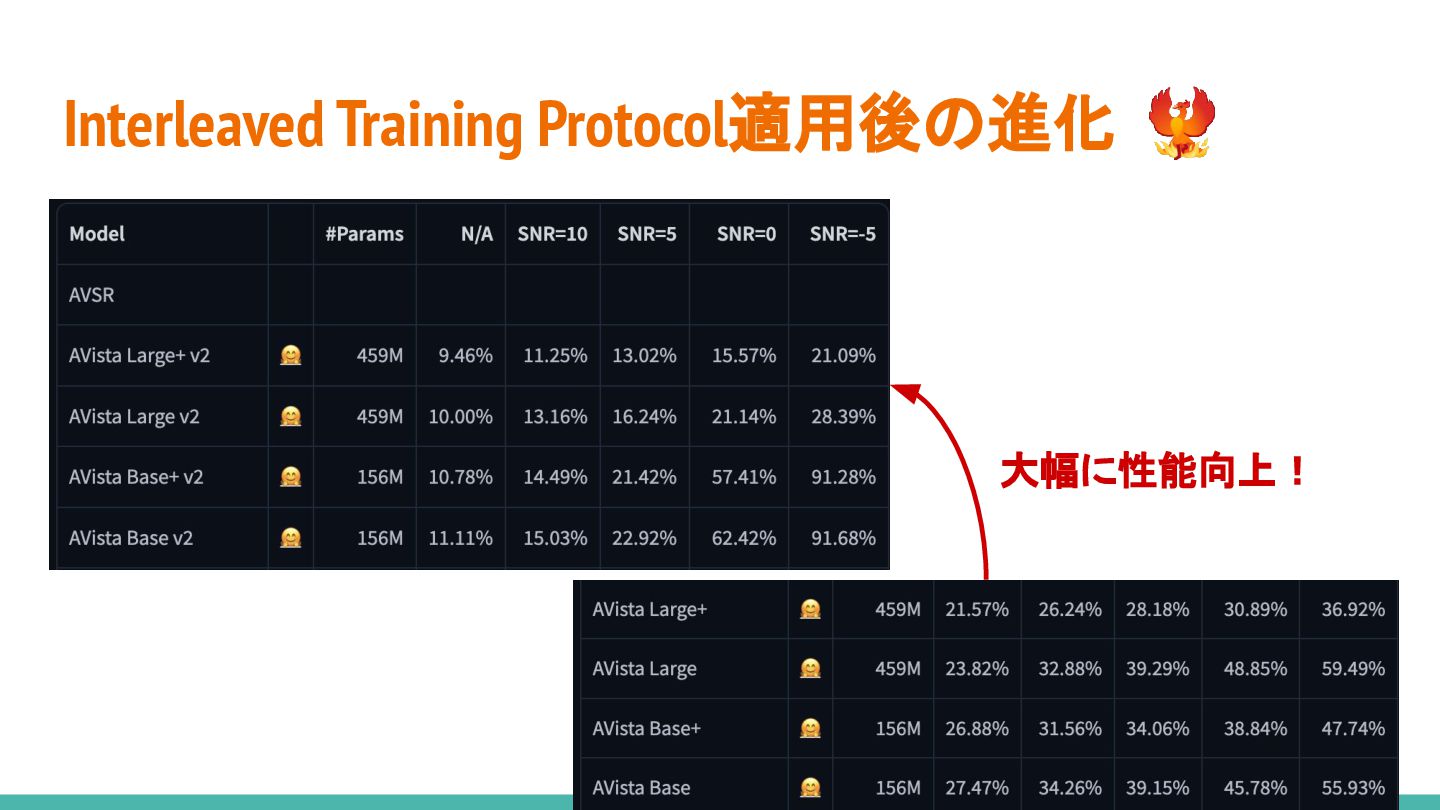
Interleaved Training Protocol適用後の進化 大幅に性能向上!
リリース
モデル実装時の判断が功を奏し お手軽リリースに成功
Transfomersから簡単に使えるので試してね〜 from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor processor = AutoProcessor.from_pretrained("enactic/avista-large-v2", trust_remote_code=True)
model = AutoModelForSpeechSeq2Seq.from_pretrained("enactic/avista-large-v2", trust_remote_code=True) inputs = processor(raw_audio="path/to/audio", raw_video="path/to/video", extract_mouth=True) outputs = model.generate(**inputs, num_beams=5, max_new_tokens=256) transcription = processor.decode(outputs[0], skip_special_tokens=True)
AVSR周辺の最近の動向
事前学習済みモデルを活用したタスク応用 主に以下が多い印象 • AVSE (Audio-Visual Speech Enhancement) • AVSS (Audio-Visual
Speech Separation) タスク内容: 音声と動画を入力として、ターゲット話者の音声を抽出
Audio-Visual Speech Enhancement and Separation by Utilizing Multi-Modal Self-Supervised Embeddings
(Chern et al., 2023) Speech Enhancement Speech Separation
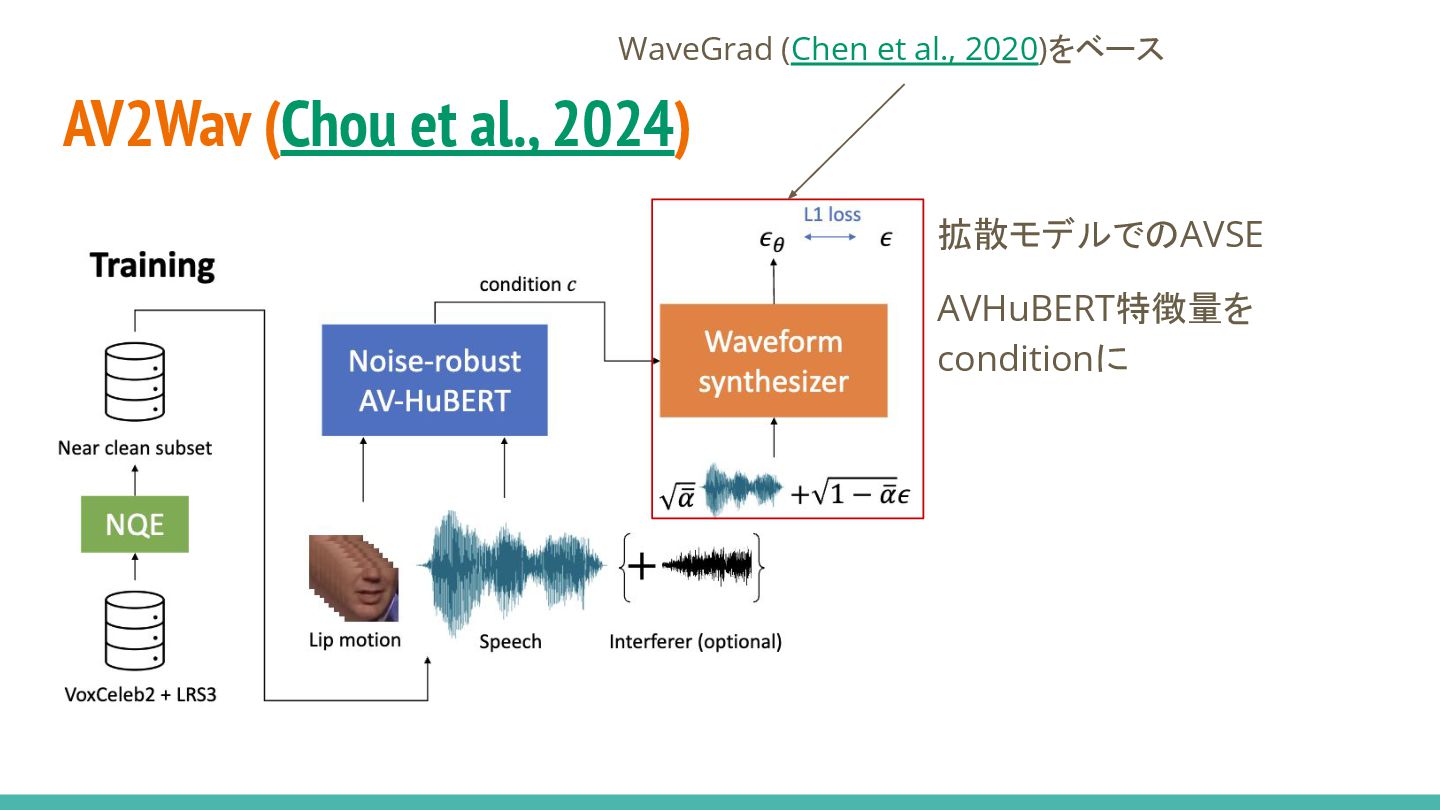
AV2Wav (Chou et al., 2024) 拡散モデルでのAVSE AVHuBERT特徴量を conditionに WaveGrad (Chen
et al., 2020)をベース
AV2Wav (Chou et al., 2024) enactic/japanese-avhubert-large_noise_ptを使って作ってみた! AV2Wav 人口減少という危機に的確に対処していくため、社会 経済の実態を正確に捉える統計の重要性は、
その他Audio-Visual系タスク 今流行りの?Neural Audio Codec (NAC)の研究もある AV入力でNACを作るよさは? • 動画も使うことでよりクリーンな音声を復元できる • 遠隔通信で通信量を相当圧縮できる
Audio-Visual Speech Codecs: Rethinking Audio-Visual Speech Enhancement by Re-Synthesis (Yang
et al., 2022)
新規モデルアーキテクチャの開拓 最近の動向? • 計算効率を向上したい • 各モダリティのアライメント性能をあげたい ◦ → 各モダリティのエンコーダをインタラクションさせる
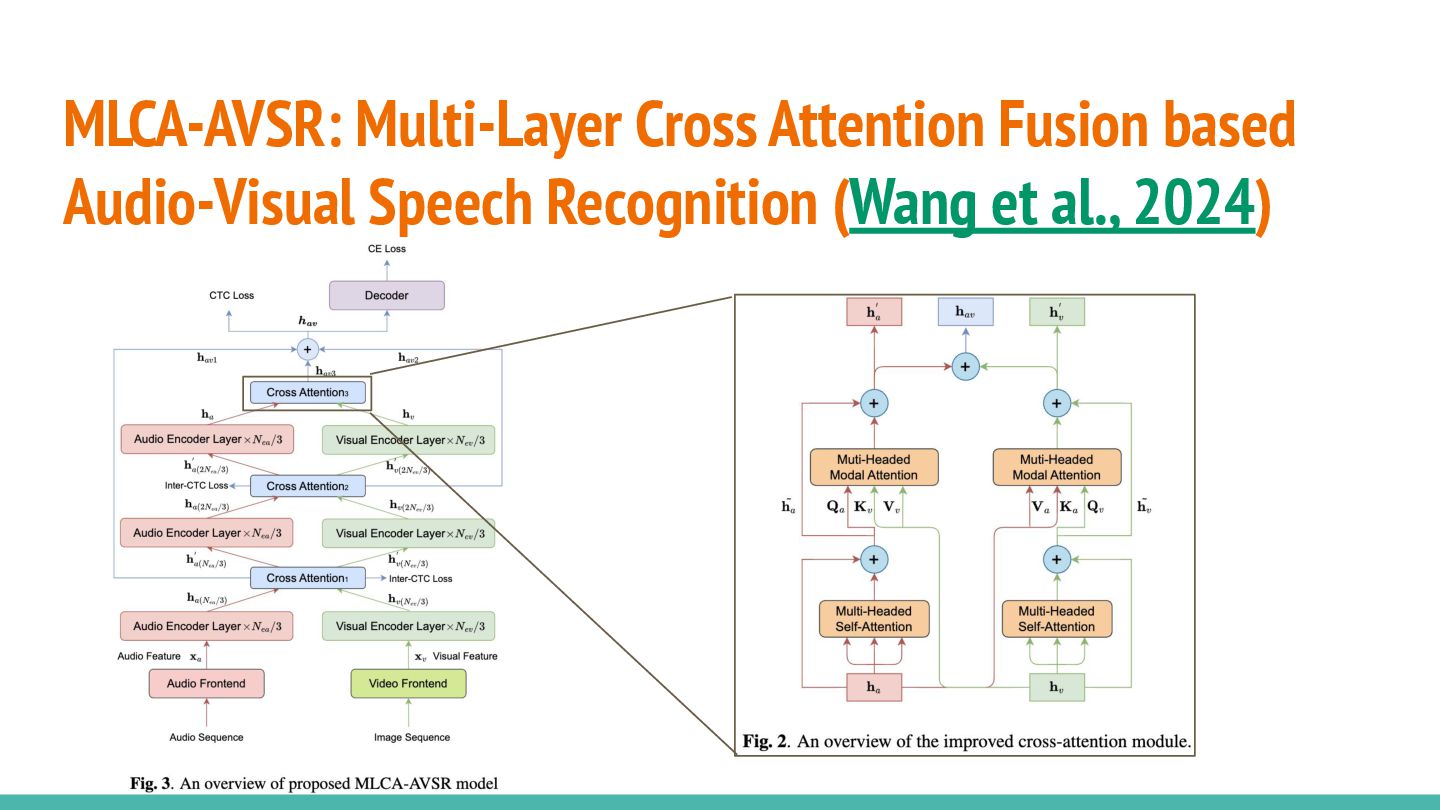
MLCA-AVSR: Multi-Layer Cross Attention Fusion based Audio-Visual Speech Recognition (Wang
et al., 2024)
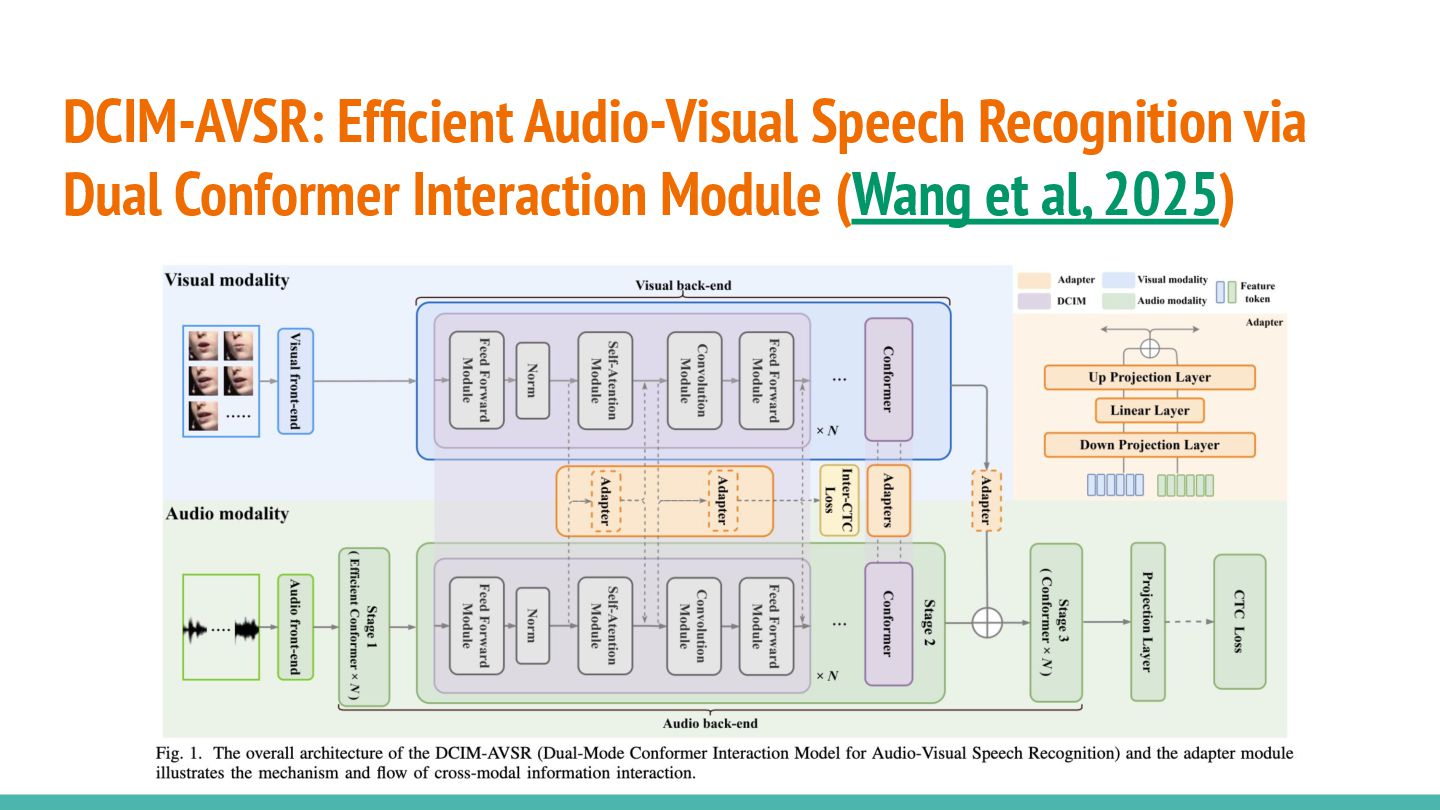
DCIM-AVSR: Efficient Audio-Visual Speech Recognition via Dual Conformer Interaction Module
(Wang et al, 2025)
LLM integrationによるモデル強化 これはもうそういう時代 ちょっと面白い点もあって... • AVHuBERTをVideo Encoderとして使い、 ASR Encoder (特にWhisper)をAudio
Encoderとして使うことが多い
Llama-AVSR (Cappellazzo et al., 2025) Whisper AVHuBERT
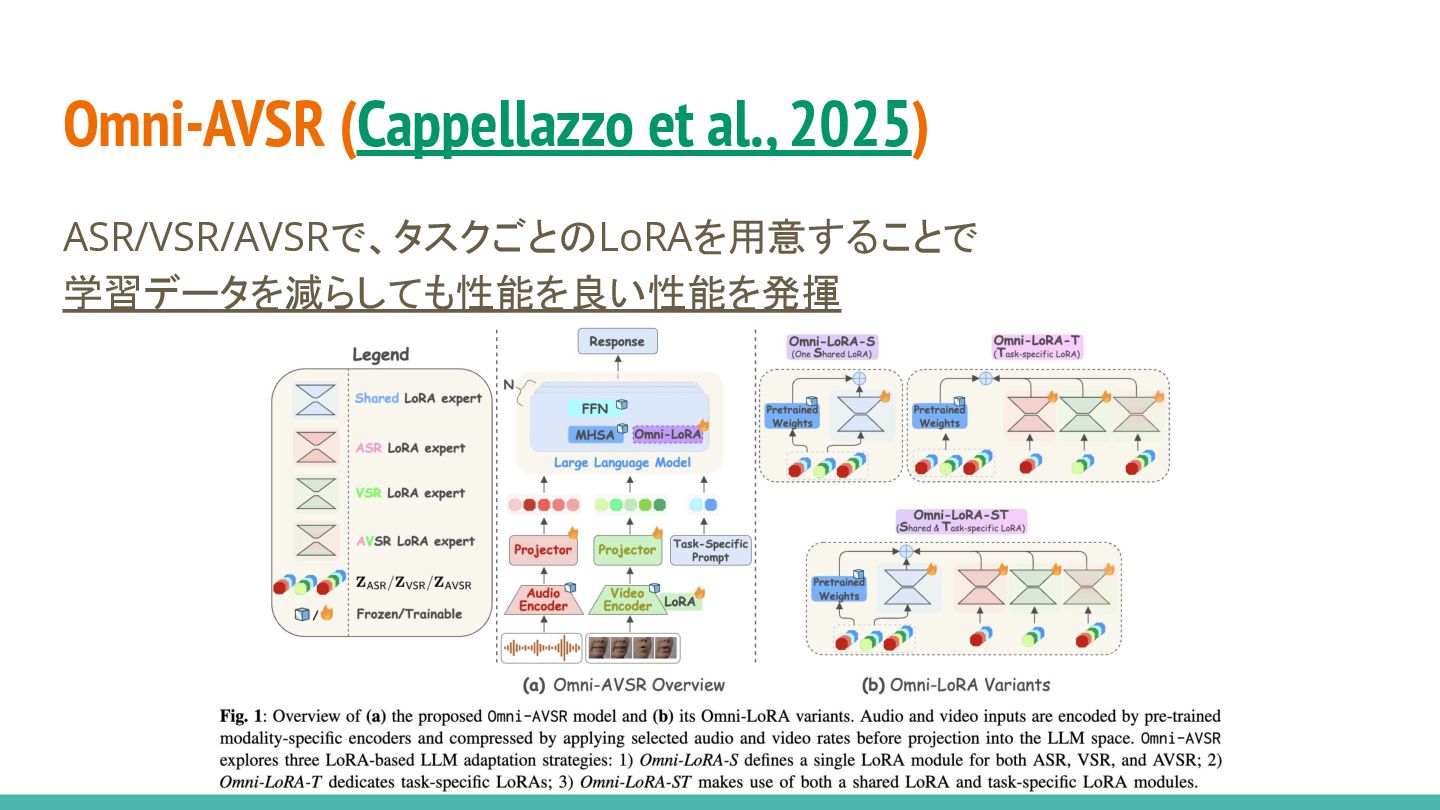
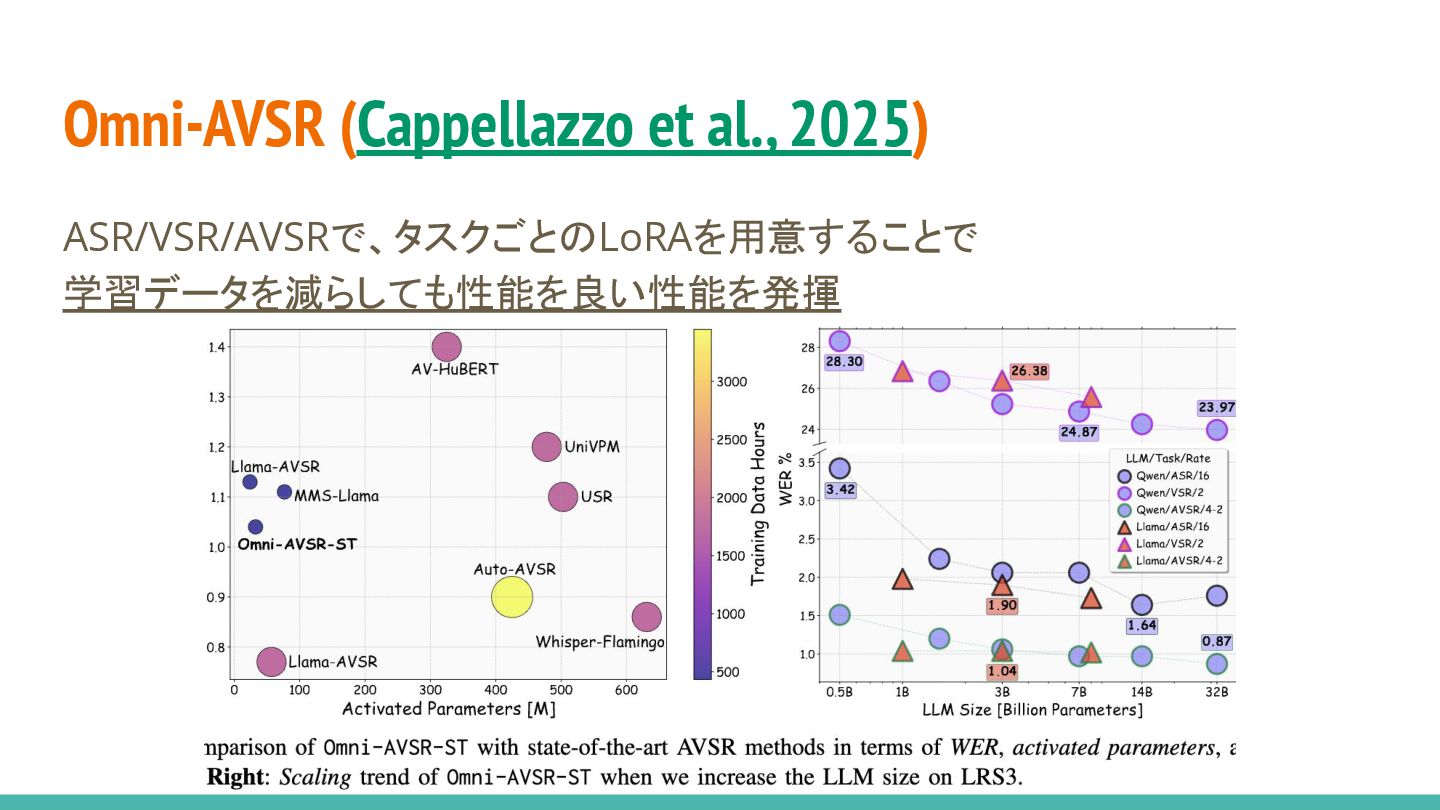
Omni-AVSR (Cappellazzo et al., 2025) ASR/VSR/AVSRで、タスクごとのLoRAを用意することで 学習データを減らしても性能を良い性能を発揮
Omni-AVSR (Cappellazzo et al., 2025) ASR/VSR/AVSRで、タスクごとのLoRAを用意することで 学習データを減らしても性能を良い性能を発揮
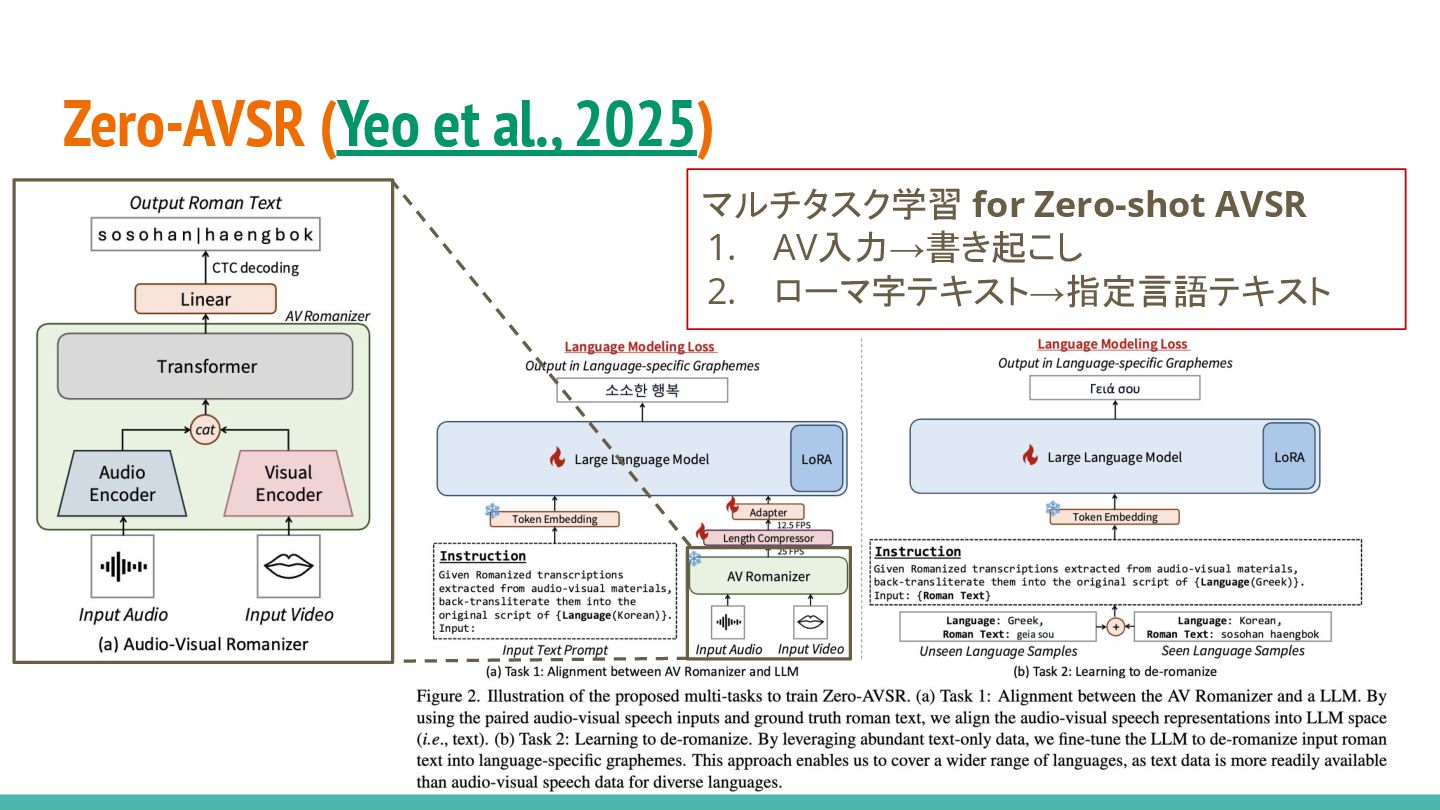
Zero-AVSR (Yeo et al., 2025) マルチタスク学習 for Zero-shot AVSR 1.
AV入力→書き起こし 2. ローマ字テキスト→指定言語テキスト
今日のまとめ
1. データセット構築 2. モデル選定&実装 3. モデル学習 4. モデル評価 5. データスケールアップ
6. リリース AVista 開発での取り組み
AVista 開発での取り組みの裏側 1. データが全然集まらない😇 2. モデル何使おう?どう実装しよう? 3. 動いたように見えて、 なぜかlossが落ちきらない......🤔
4. デモしたら全く使い物にならない... 評価データ作るかー 5. データスケール、 想像以上に難しすぎる...🤯 6. モデル実装時の判断が功を奏し、 お手軽リリースに成功✌ 1. データセット構築 2. モデル選定&実装 3. モデル学習 4. モデル評価 5. データスケールアップ 6. リリース
AVSRは実用的だし面白いぞ みんなで分野を盛り上げよう 🕺
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}