Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Generative Spoken Dialogue Language Modeling [対...
Search
Sloth
December 14, 2023
Research
470
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Generative Spoken Dialogue Language Modeling [対話論文読み会@電通大]
TACL'23でMeta AI Researchから発表された"Generative Spoken Dialogue Language Modeling"の輪読資料です.
Sloth
December 14, 2023
More Decks by Sloth
See All by Sloth
AVSRの世界と日本語特化モデル開発の裏側.pdf
yuta0306
1
590
Core Audio tapを使ったリアルタイム音声処理のお話
yuta0306
0
410
Other Decks in Research
See All in Research
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
4.4k
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
430
2026 東京科学大 情報通信系 研究室紹介 (すずかけ台)
icttitech
0
4.1k
SLAMはどこまで解決されたのか?
tomonom
0
840
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
290
[CV勉強会@関東 CVPR2026] PSDesigner: Automated Graphic Design with a Human-Like Creative Workflow / kantocv 67th CVPR 2026
shunk031
0
170
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
610
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
310
論文紹介:HalluCitation Matters
wasyro
0
130
Cross-Media Information Spaces and Architectures
signer
PRO
0
320
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
130
Featured
See All Featured
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
WCS-LA-2024
lcolladotor
0
740
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
510
Abbi's Birthday
coloredviolet
3
8.7k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
What's in a price? How to price your products and services
michaelherold
247
13k
Transcript
1 Generative Spoken Dialogue Language Modeling @TACLʼ23 佐々⽊裕多 東京⼯業⼤学 M1
Tu Anh Nguyen et al. from Meta AI Research 🔗https://aclanthology.org/2023.tacl-1.15/ https://github.com/facebookresearch/fairseq/tree/main/examples/textless_nlp/dgslm 🗣https://speechbot.github.io/dgslm
2 概要 Ø ⾳声⼊⼒から⾳声⽣成を⾏う`textless`対話モデル dGSLMを提案 Ø Cross-attentionを採⽤した Dual-tower Transformerアーキテクチャ Ø
テキストやその他ラベルを⽤いずに2000h⽣⾳声で学習 Ø 笑いや相槌のような⾮⾔語な語彙を⽣成 Ø ポーズやオーバラップのようなターンテイキングの ⽣成が可能 Ø 分布も評価データセットと⾼い相関 Ø テキストベースの対話モデルと⽐べ、発話内容には 課題あり
3 対話システムの現状 Ø 会話は流れるようなターンの連続 ❌ 多すぎるオーバラップ ❌ ⻑い沈黙 Ø オーバラップや沈黙は起きるが、重要な情報を伝える
Ø Content-neutralな⾔語情報 Ø E.g., “hmm”, “yeah” Ø ⾮⾔語な語彙 Ø E.g., 笑い Ø 聞き⼿の態度 Ø E.g., 相槌 テキストベースのインターフェースでの対話研究が多いため、 ターンテイキングの調整に難しさ
4 本研究の⽴ち位置 Ø テキストやASRを介さず、⽣⾳声から⾳声対話モデルを学習す る実現可能性を検証 Ø ASRを通すとユーザからの⼊⼒を待つ必要性 Ø ⾃⼰教師あり学習やtextlessな⾳声処理が発展中 Ø
対話モデルを⾮⾔語的な特徴でも評価 Ø 提案モデルdGSLMが、会話の表⾯上の特徴であるターンテイキ ングや相槌を⾼精度で模倣できていることを⽰す Ø テキストベースのカスケードな対話モデルのような意味的な情報を明⽰ 的には学習しないが…
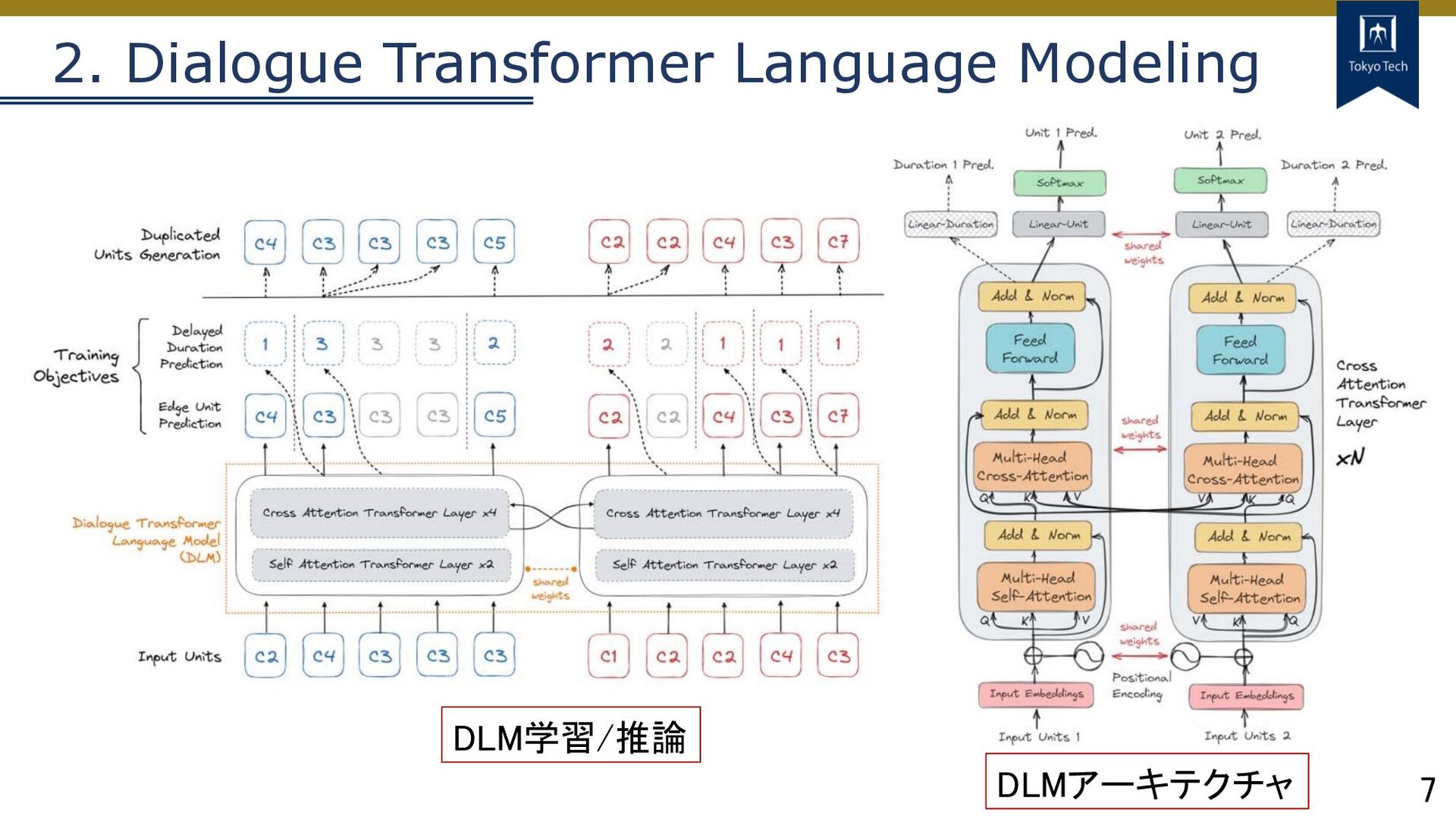
5 提案⼿法 2. Dialogue Transformer Language Modeling (DLM) Dual-tower Transformerで2チャンネル⼊出⼒
1. Discrete Phonetic Representation HuBERT + kmeansで⽣⾳声から⾳韻表現を抽出 3. Waveform Generation ⼩データでも⾼品質な⾳声合成が可能な 離散的unit-baseのHiFi-GANボコーダ
6 1. Discrete Phonetic Representation HuBERT: Self-Supervised Speech Representation Learning
by Masked Prediction of Hidden Units Ø 会話には “hmm”のようなカジュアル表現や 笑いのような⾮⾔語⾳声含まれる Ø ドメインに適切な⾳韻表現を獲得するため HuBERTを採⽤ Ø HuBERTの出⼒をkmeansでクラスタリング Ø 離散的な⾳韻unitを獲得 Ø 最終的な離散的⾳韻unitのコードブックは500 Ø 様々な⾳韻クラスをモデル化 ※HuBERTの⾃⼰教師あり学習は⾯⽩いので 興味があれば論⽂を参照してください
7 2. Dialogue Transformer Language Modeling DLMアーキテクチャ DLM学習/推論
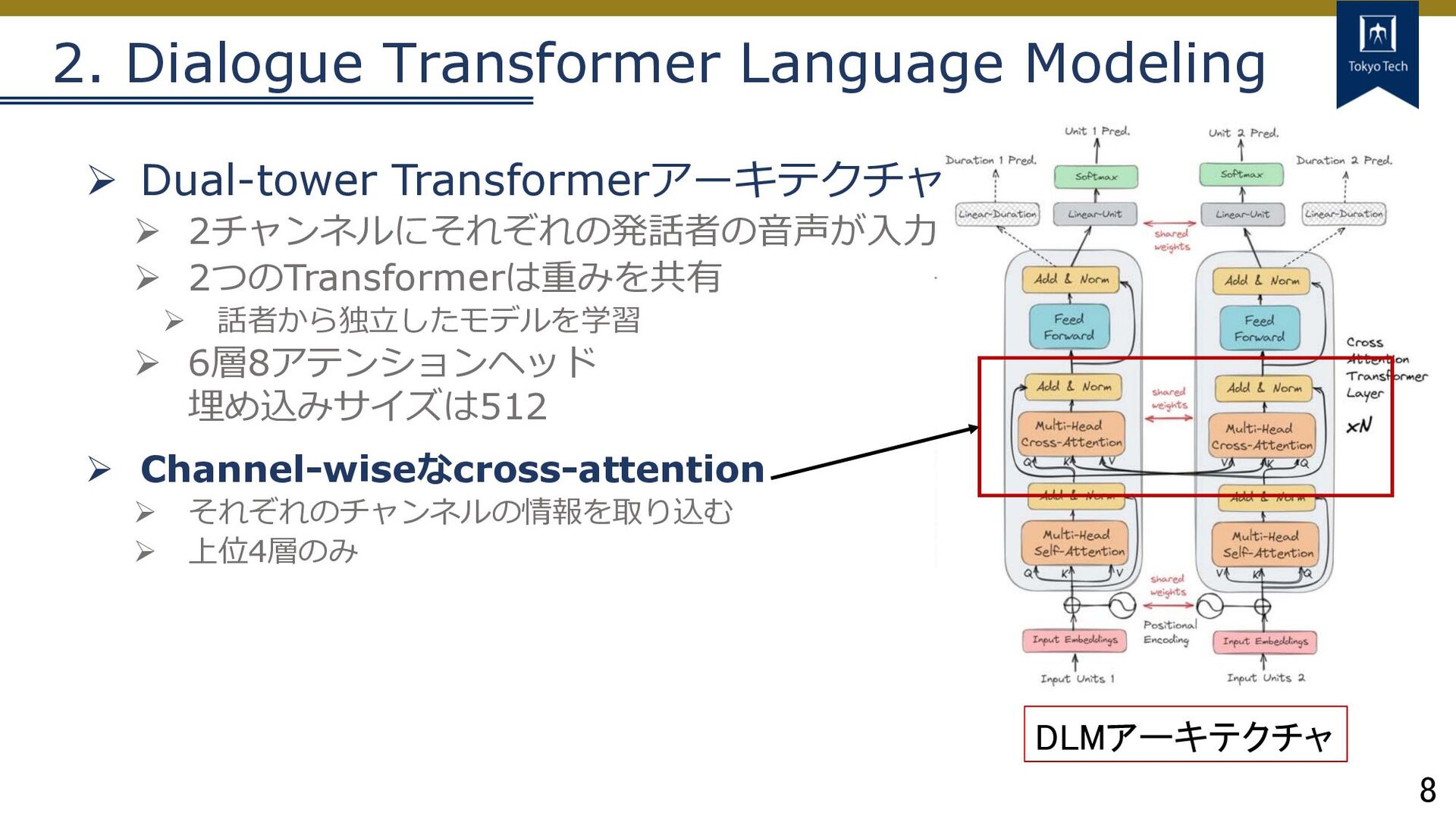
8 2. Dialogue Transformer Language Modeling DLMアーキテクチャ Ø Dual-tower Transformerアーキテクチャ
Ø 2チャンネルにそれぞれの発話者の⾳声が⼊⼒ Ø 2つのTransformerは重みを共有 Ø 話者から独⽴したモデルを学習 Ø 6層8アテンションヘッド 埋め込みサイズは512 Ø Channel-wiseなcross-attention Ø それぞれのチャンネルの情報を取り込む Ø 上位4層のみ
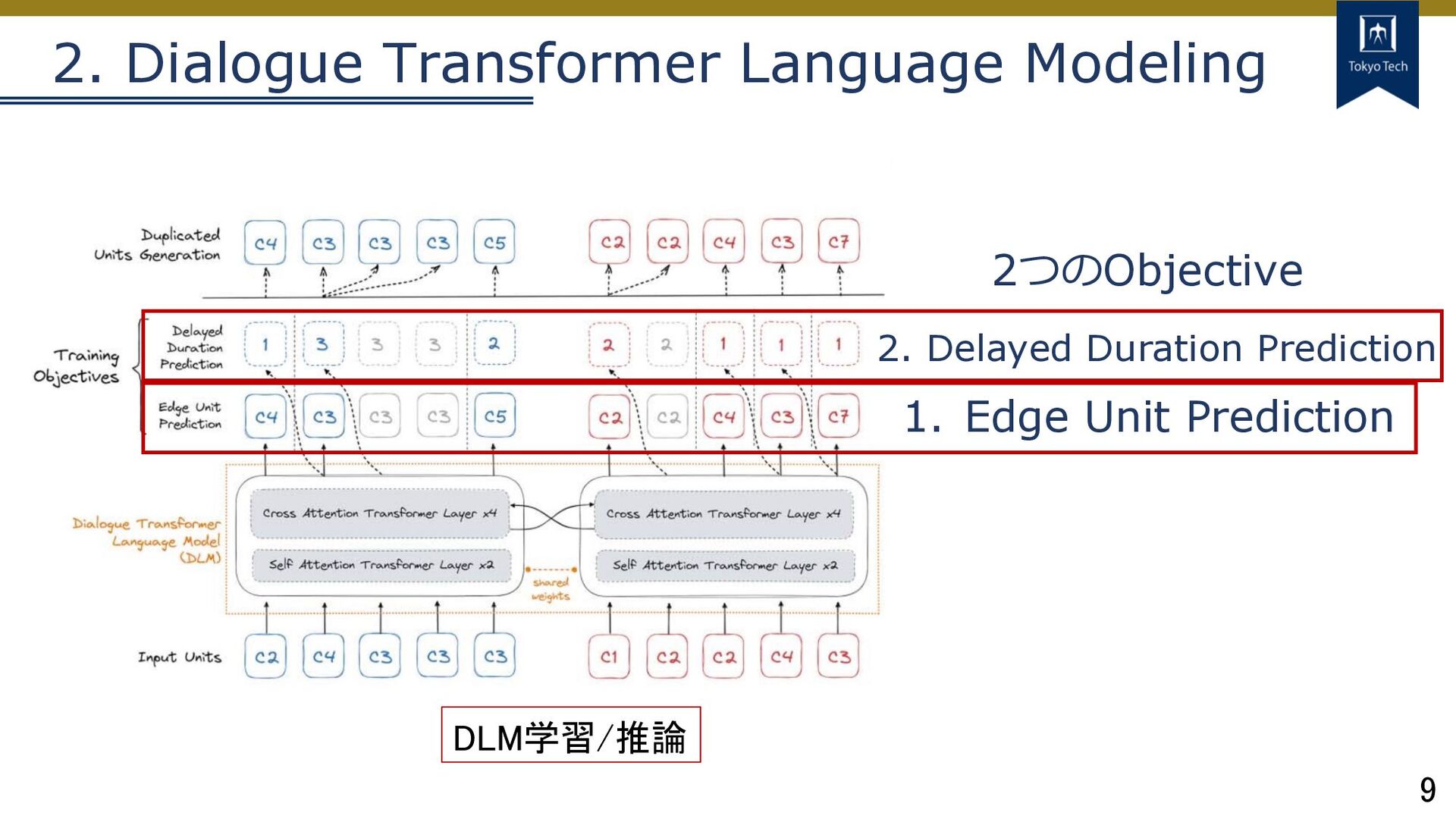
9 2. Dialogue Transformer Language Modeling DLM学習/推論 1. Edge Unit
Prediction 2. Delayed Duration Prediction 2つのObjective
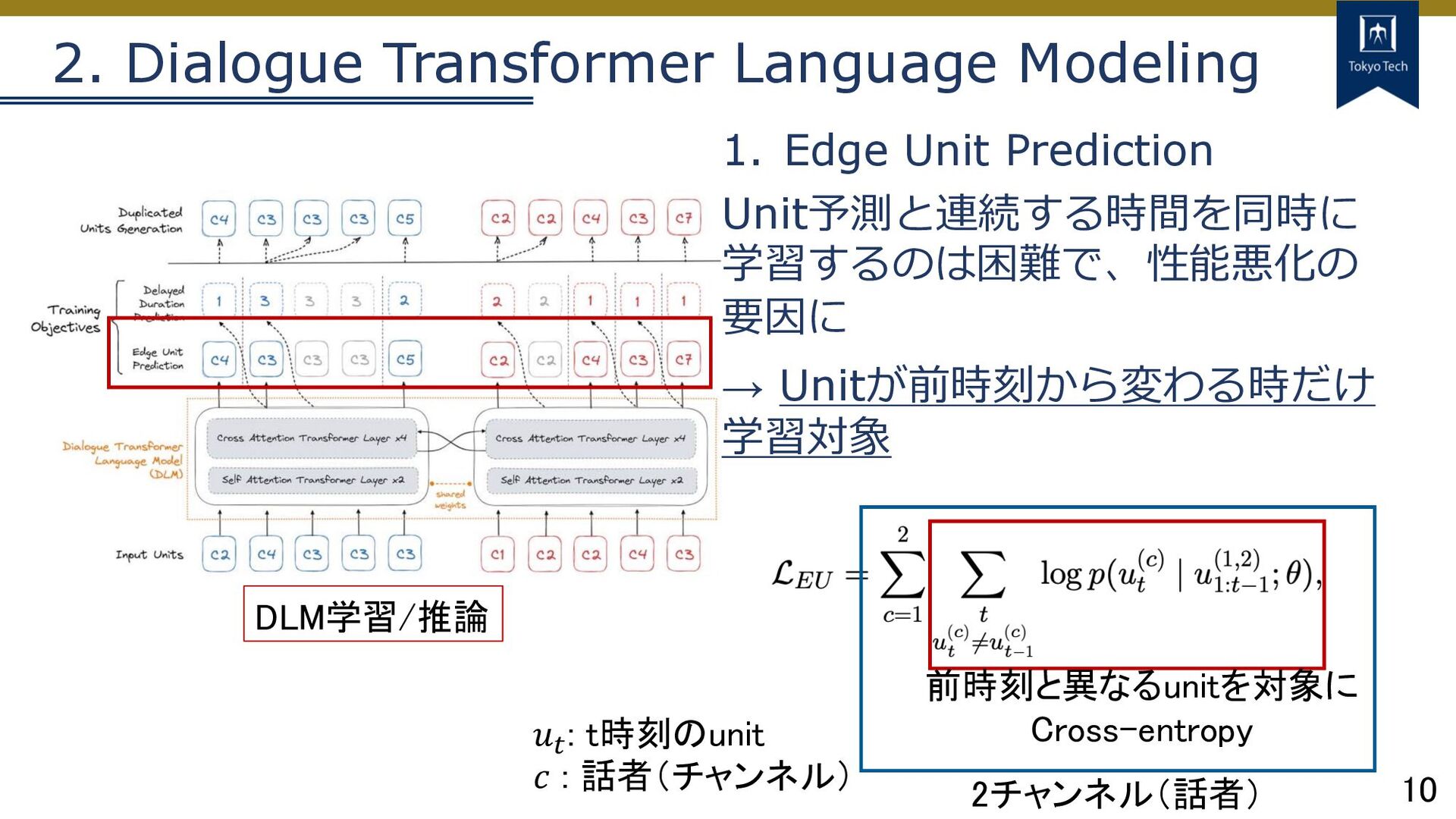
10 2. Dialogue Transformer Language Modeling DLM学習/推論 1. Edge Unit
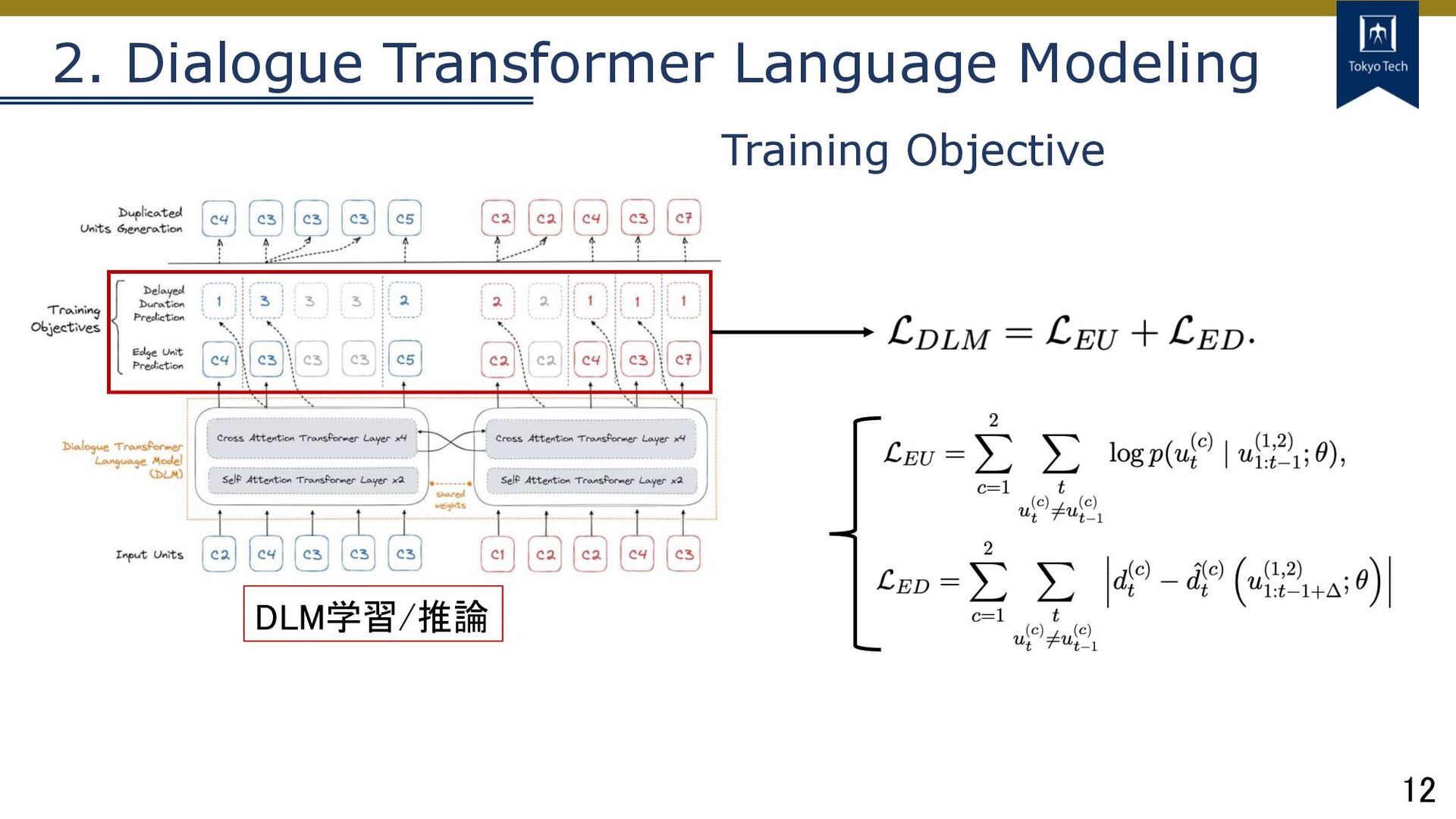
Prediction Unit予測と連続する時間を同時に 学習するのは困難で、性能悪化の 要因に → Unitが前時刻から変わる時だけ 学習対象 前時刻と異なるunitを対象に Cross-entropy 2チャンネル(話者) 𝑢! : t時刻のunit 𝑐 : 話者(チャンネル)
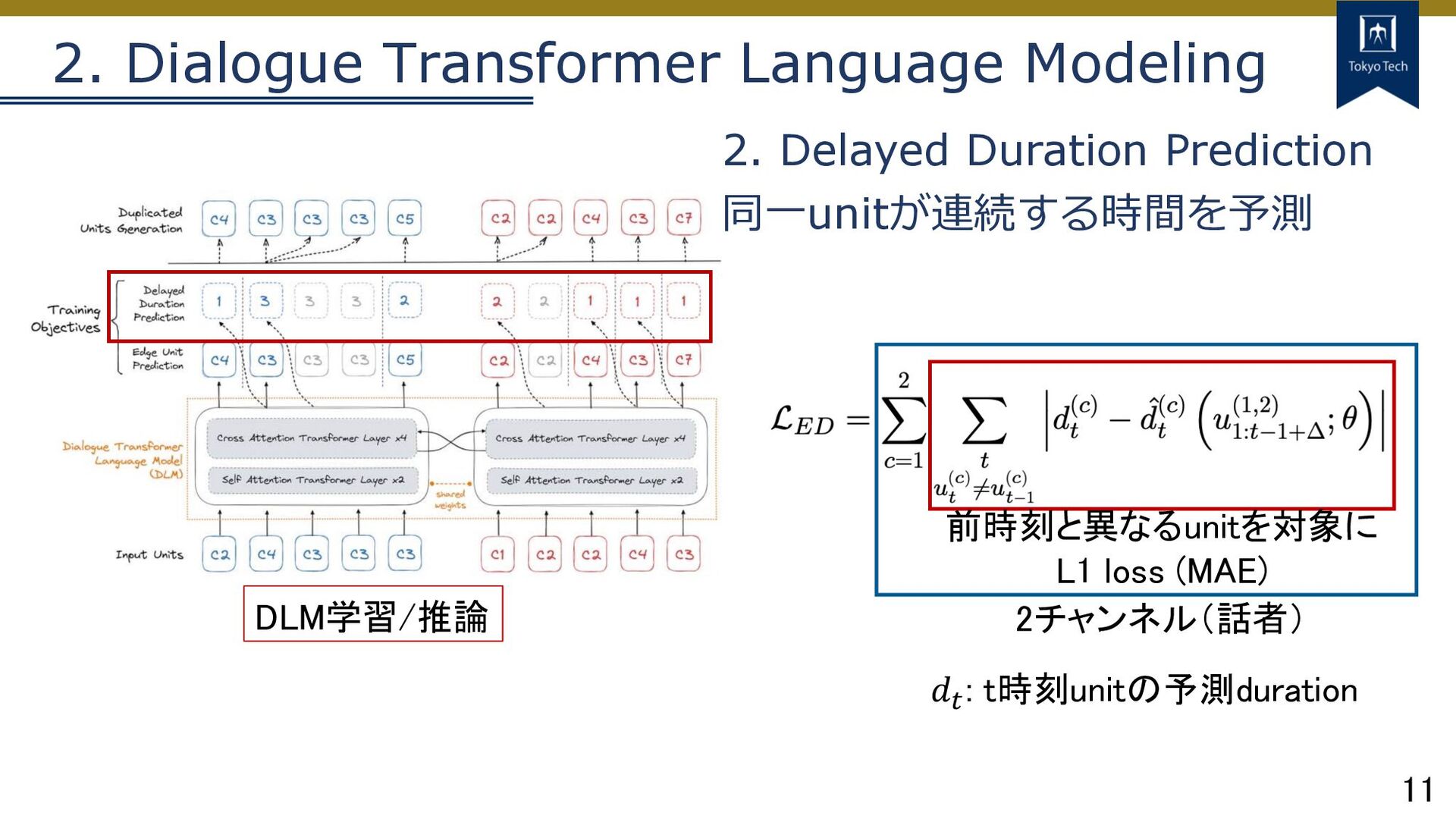
11 2. Dialogue Transformer Language Modeling DLM学習/推論 2. Delayed Duration
Prediction 同⼀unitが連続する時間を予測 前時刻と異なるunitを対象に L1 loss (MAE) 2チャンネル(話者) 𝑑! : t時刻unitの予測duration
12 2. Dialogue Transformer Language Modeling DLM学習/推論 Training Objective
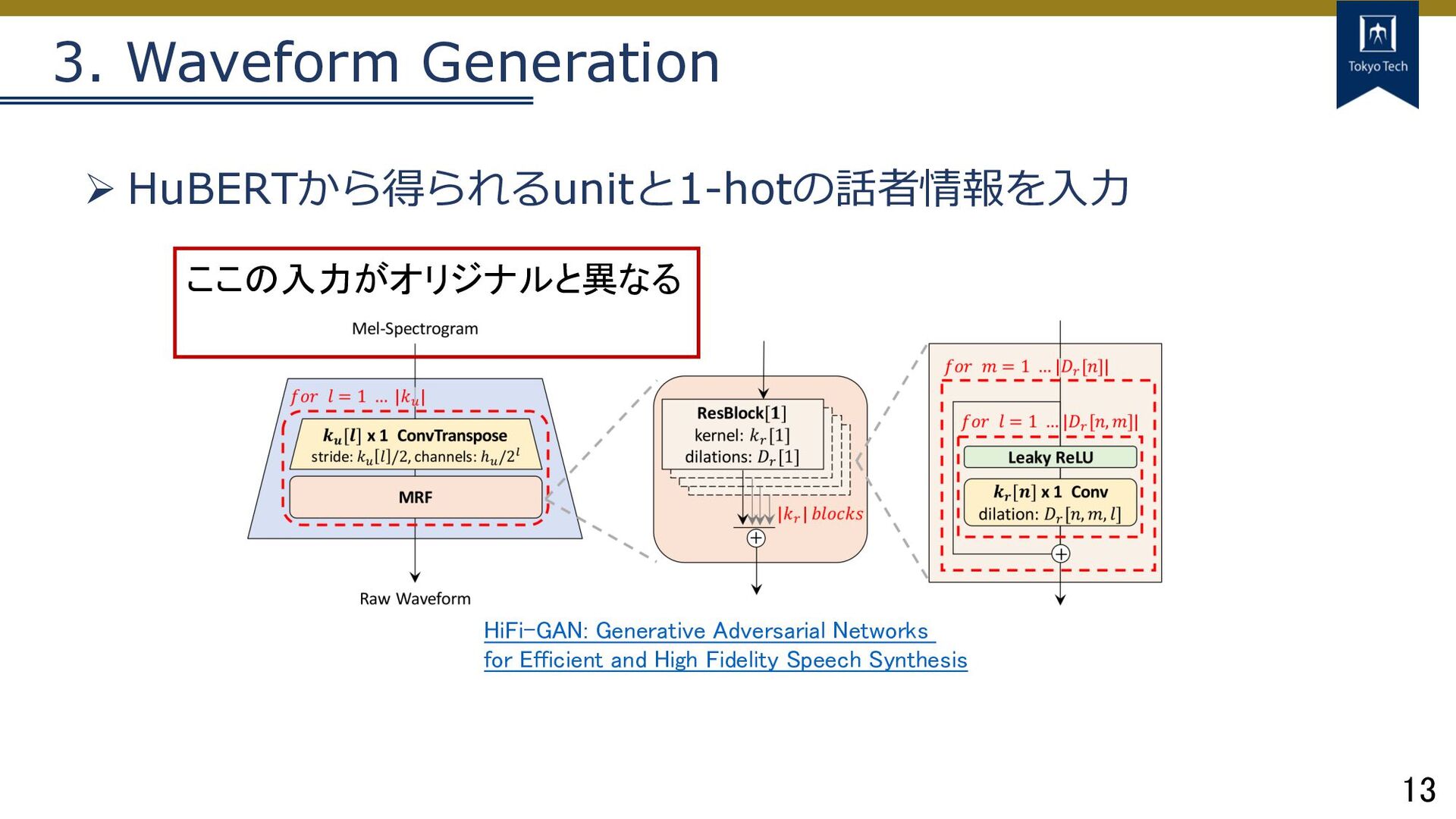
13 3. Waveform Generation Ø HuBERTから得られるunitと1-hotの話者情報を⼊⼒ HiFi-GAN: Generative Adversarial Networks
for Efficient and High Fidelity Speech Synthesis ここの入力がオリジナルと異なる
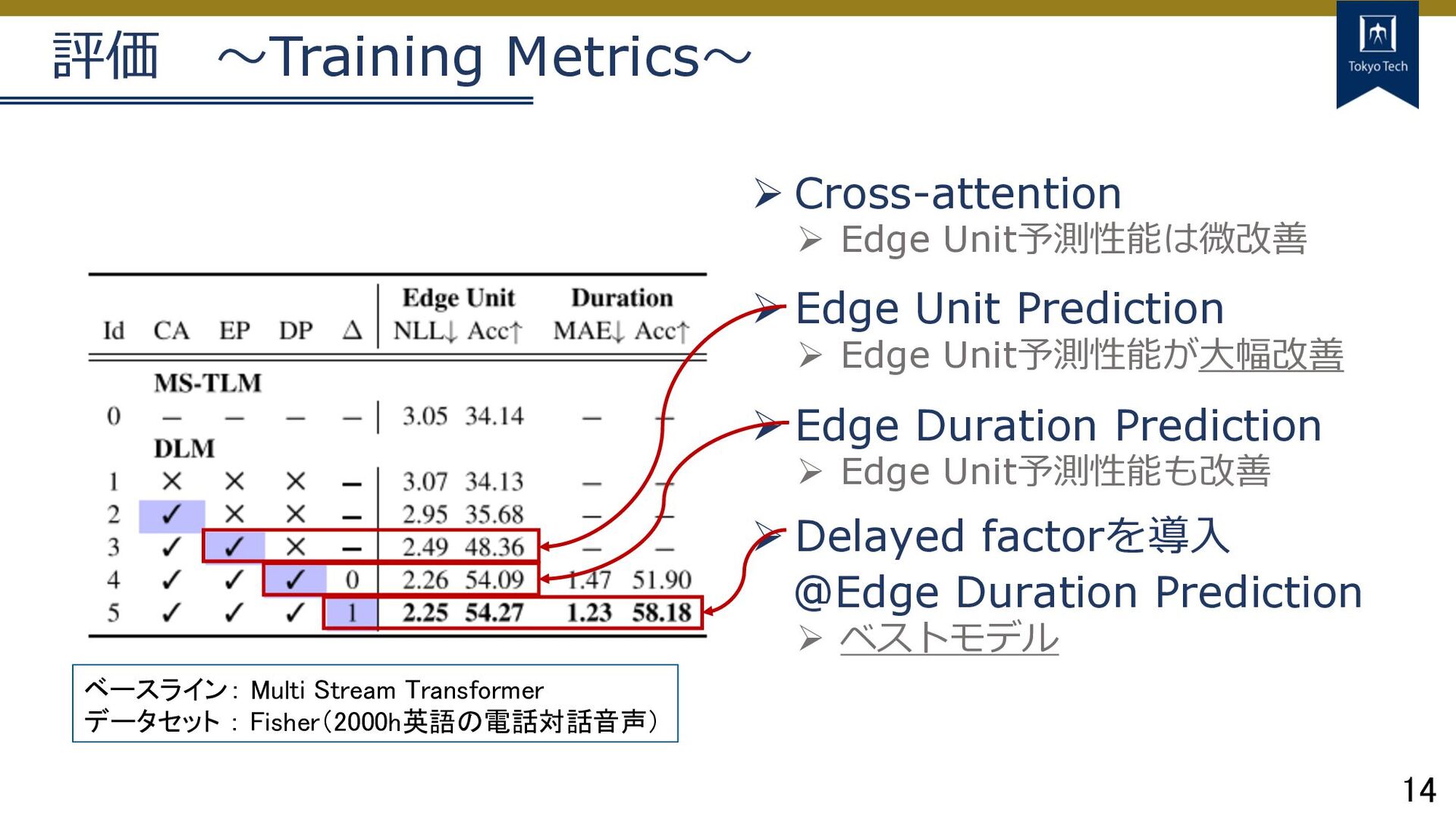
14 評価 〜Training Metrics〜 Ø Cross-attention Ø Edge Unit予測性能は微改善 Ø
Edge Unit Prediction Ø Edge Unit予測性能が⼤幅改善 Ø Edge Duration Prediction Ø Edge Unit予測性能も改善 Ø Delayed factorを導⼊ @Edge Duration Prediction Ø ベストモデル ベースライン: Multi Stream Transformer データセット : Fisher(2000h英語の電話対話音声)
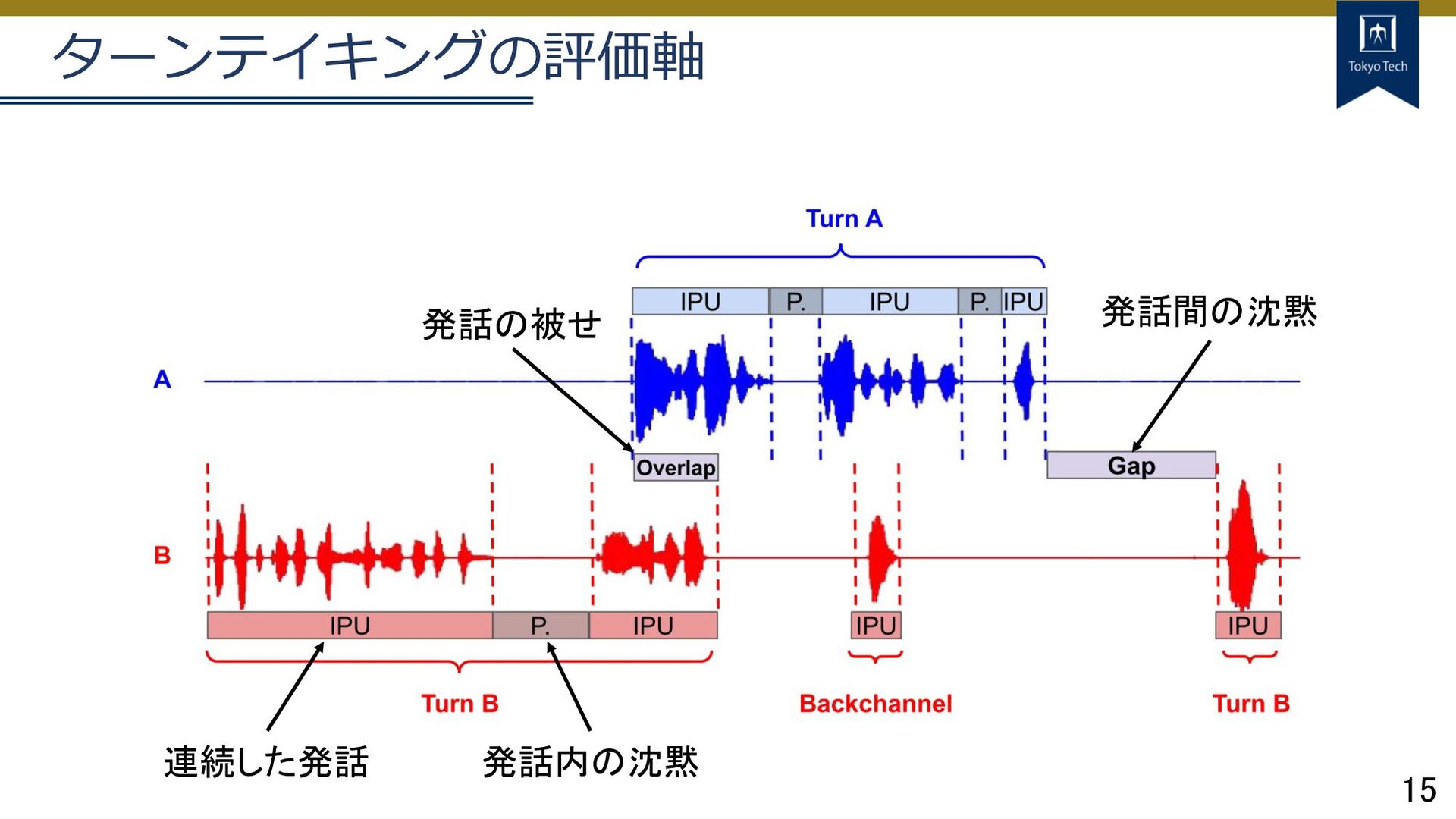
15 ターンテイキングの評価軸 連続した発話 発話内の沈黙 発話の被せ 発話間の沈黙
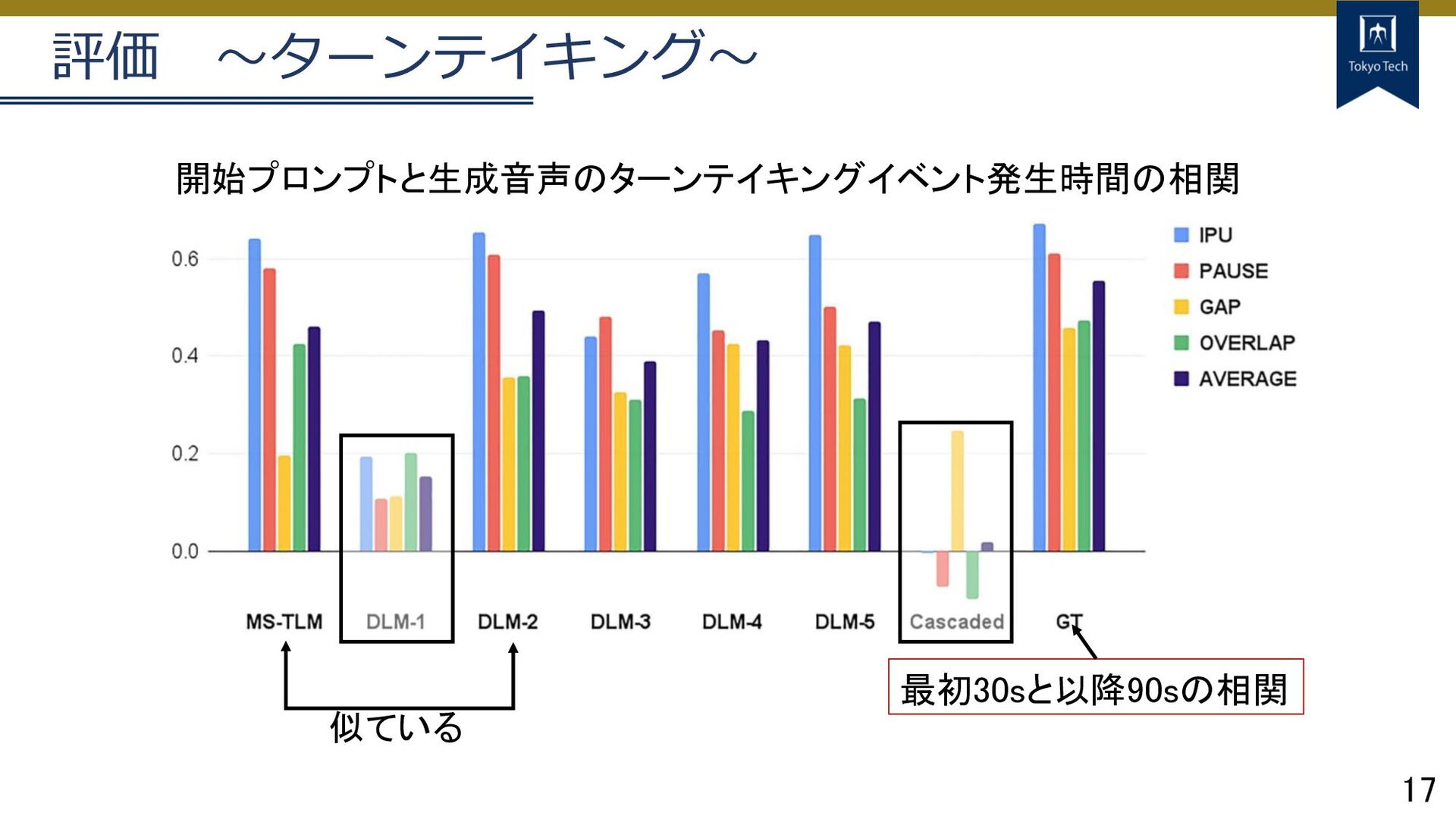
16 評価 〜ターンテイキング〜 DLM-1は IPU以外長い DLM-2はオーバーラップ短め ポーズ/ギャップ長め DLM-3-5はオーバーラップ長め ポーズ/ギャップ短め
17 評価 〜ターンテイキング〜 最初30sと以降90sの相関 開始プロンプトと生成音声のターンテイキングイベント発生時間の相関 似ている
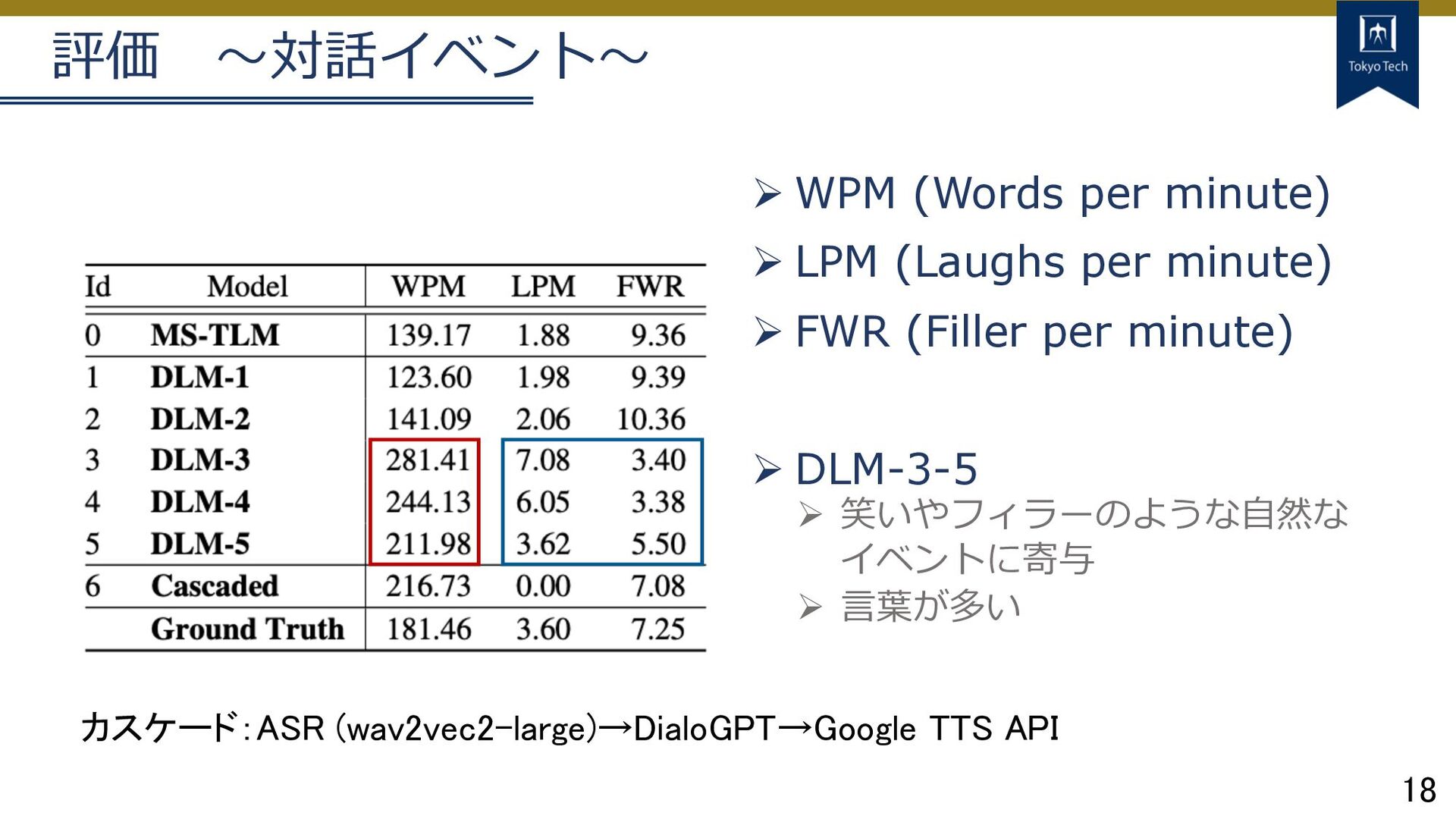
18 評価 〜対話イベント〜 Ø WPM (Words per minute) Ø LPM
(Laughs per minute) Ø FWR (Filler per minute) Ø DLM-3-5 Ø 笑いやフィラーのような⾃然な イベントに寄与 Ø ⾔葉が多い カスケード:ASR (wav2vec2-large)→DialoGPT→Google TTS API
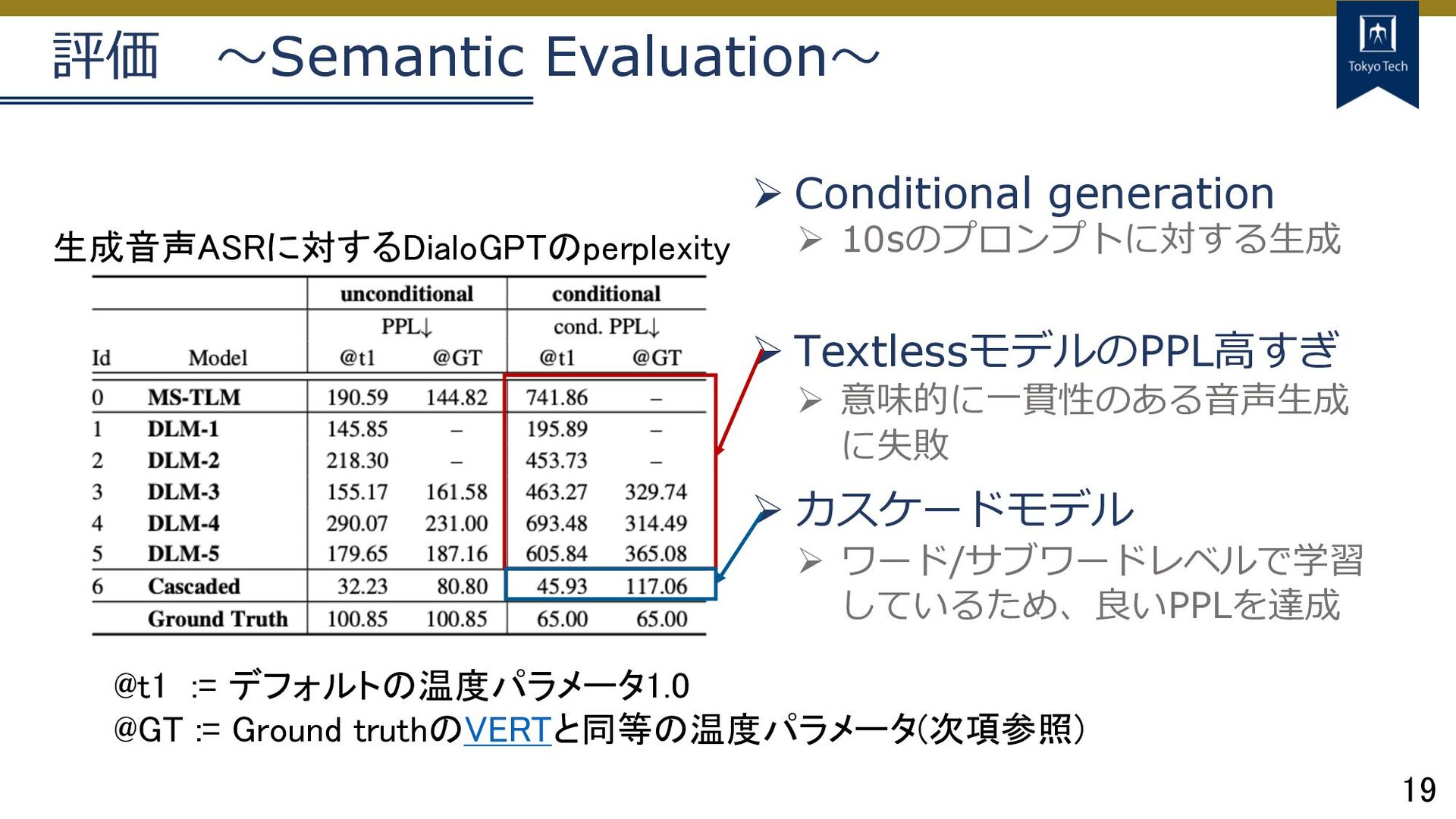
19 評価 〜Semantic Evaluation〜 Ø Conditional generation Ø 10sのプロンプトに対する⽣成 Ø
TextlessモデルのPPL⾼すぎ Ø 意味的に⼀貫性のある⾳声⽣成 に失敗 Ø カスケードモデル Ø ワード/サブワードレベルで学習 しているため、良いPPLを達成 生成音声ASRに対するDialoGPTのperplexity @t1 := デフォルトの温度パラメータ1.0 @GT := Ground truthのVERTと同等の温度パラメータ(次項参照)
20 評価 〜Semantic Evaluation〜 温度パラメータ [0.3, 2.0]に対するDialoGPTのPPLの摂動
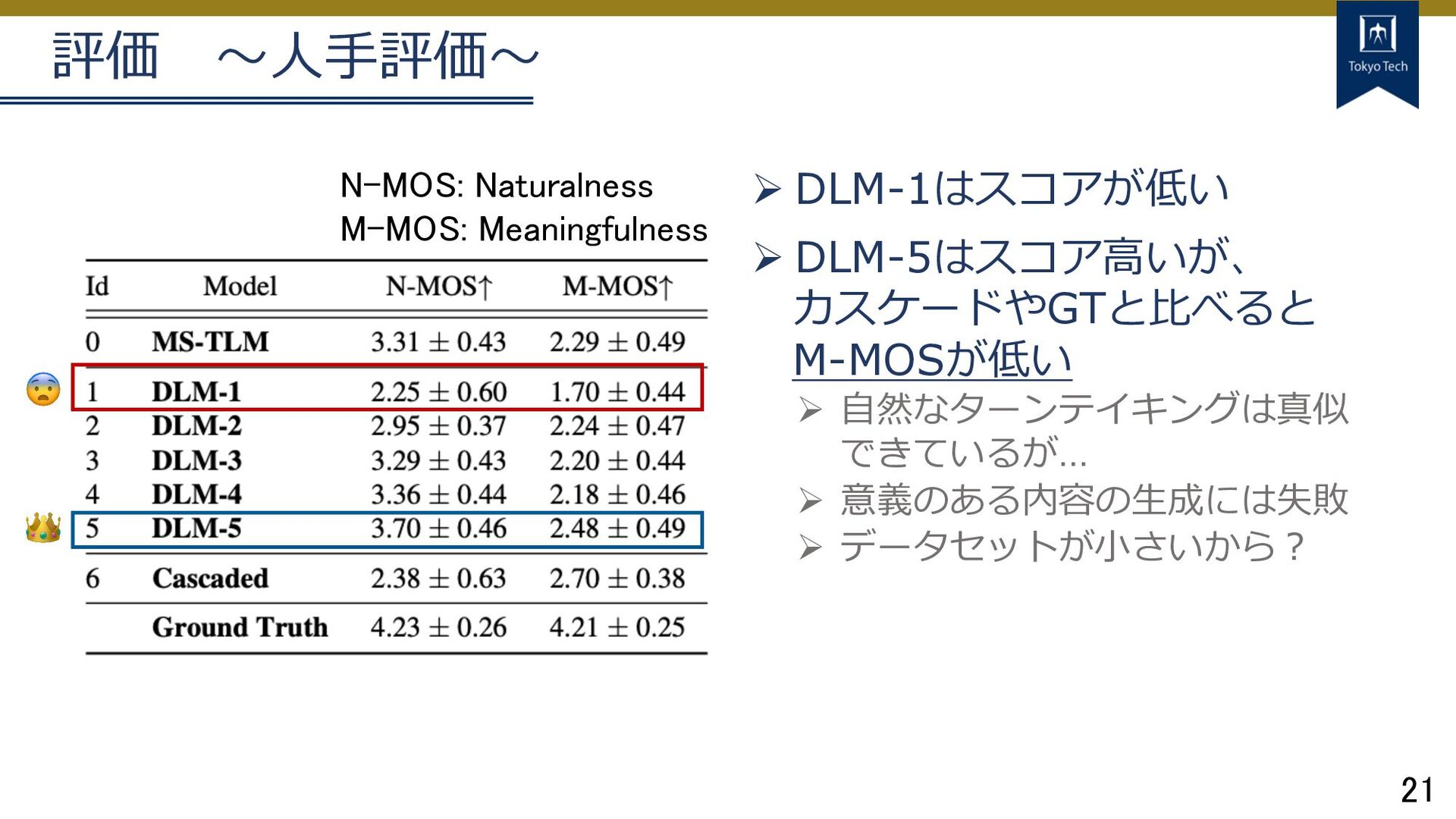
21 評価 〜⼈⼿評価〜 Ø DLM-1はスコアが低い Ø DLM-5はスコア⾼いが、 カスケードやGTと⽐べると M-MOSが低い Ø
⾃然なターンテイキングは真似 できているが… Ø 意義のある内容の⽣成には失敗 Ø データセットが⼩さいから︖ 👑 😨 N-MOS: Naturalness M-MOS: Meaningfulness
22 まとめ Ø ⾳声⼊⼒から⾳声⽣成を⾏う`textless`対話モデル dGSLMを提案 Ø Cross-attentionを採⽤した Dual-tower Transformerアーキテクチャ Ø
テキストやその他ラベルを⽤いずに2000h⽣⾳声で学習 Ø 笑いや相槌のような⾮⾔語な語彙を⽣成 Ø ポーズやオーバラップのようなターンテイキングの ⽣成が可能 Ø 分布も評価データセットと⾼い相関 Ø テキストベースの対話モデルと⽐べ、発話内容には 課題あり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![20 評価 〜Semantic Evaluation〜 温度パラメータ [0.3, 2.0]に対するDialoGPTのPPLの摂動](https://files.speakerdeck.com/presentations/65c3074e5a34431f8e9478e97ab5ebdc/slide_19.jpg){kind=link}
{kind=link}
{kind=link}