Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
爆速でキャッチアップしよう!Amazon Bedrock AgentCore/Strands ...
Search
Yudai Jinno
December 10, 2025
1.7k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
爆速でキャッチアップしよう!Amazon Bedrock AgentCore/Strands Agentsのre:Inventアップデート情報まとめ!
Yudai Jinno
December 10, 2025
More Decks by Yudai Jinno
See All by Yudai Jinno
AgentCoreの機能、全部要る? ユースケース別にAWSサービスとの組み合わせ方を一緒に整理しよう
yuu551
4
2.2k
Amazon Bedrock AgentCore Managed Harness 座学資料
yuu551
1
2.1k
AWS Agent Registryへの期待
yuu551
1
110
Amazon Bedrockで始めるRAG入門
yuu551
1
980
アーキテクチャ選定から実装Tipsまで! AgentCore / Strands AgentsでAIエージェントを実際に作ってわかったことN選
yuu551
4
1k
個人的によく知らなかった AgentCore Memoryの機能を中心に深掘りしてみた
yuu551
2
810
Bedrock PolicyでAmazon Bedrock Guardrails利用を強制してみた
yuu551
1
740
Amazon Bedrock AgentCore EvaluationsでAIエージェントを評価してみよう!
yuu551
1
680
2025年 Amazon Bedrock AgentCoreまとめ
yuu551
31
21k
Featured
See All Featured
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
630
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
280
The SEO Collaboration Effect
kristinabergwall1
1
500
How to Talk to Developers About Accessibility
jct
2
280
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
210
Into the Great Unknown - MozCon
thekraken
41
2.6k
Six Lessons from altMBA
skipperchong
29
4.3k
The Invisible Side of Design
smashingmag
301
52k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
200
Product Roadmaps are Hard
iamctodd
55
12k
Agile that works and the tools we love
rasmusluckow
331
22k
Transcript
クラウド事業本部 コンサルティング部 神野 雄⼤(Jinno Yudai) 爆速でキャッチアップしよう! Amazon Bedrock AgentCore /Strands
Agentsの re:Inventアップデート情報まとめ!
⾃⼰紹介
簡単に⾃⼰紹介させていただきます。本⽇はよろしくお願いします!!!!! ⾃⼰紹介 名前 神野 雄⼤(Jinno Yudai/@yjinn448208) 最近X始めました! 所属 クラウド事業本部コンサルティング部 ソリューションアーキテクト
⼤好きな サービス Amazon Bedrock AgentCore 思い出 皆でスフィアに⾏ったこと ⾶⾏機内でイヤホンを無くしかけたこと ブログはこのアイコ ンで書いています! KIROハウスで! スフィア!オズの 魔法使いみたよ
謝り
謝り① 元気よくアップデート資料を作っていたら 25枚を超えたので詳細はまたブログを読ん でください‧‧‧今⽇は爆速で雰囲気を キャッチアップしてください‧‧‧すみませ ん‧‧‧ Sorry・・・
謝り② Sorry‧‧‧ ⼤変申し訳ないですが、本⽇の内容はAgentCoreを少し触ったことがある、何ができ るかざっくりと理解していることを前提としています。もし触りの箇所から知りたい 場合は⼿前味噌で恐縮ですが私のブログで解説しているのでみていただけると嬉しい です。 Amazon Bedrock AgentCoreを使ってみよう! 〜各種機能のポイントを解説〜
著者ページ
いざ!内容へ!
Keynoteを振り返って Keynoteでは全体的にAIの話が中⼼でした。その中でAgentCoreやStrands Agents の話も多く出てきて、AIエージェントはもう作っている、運⽤を前提としたアッ プデートや話が多いように感じました。
今回はそんなAgentCoreやStrands Agents のアップデートを爆速でキャッチアップし ていきましょう!!!!!!
今⽇の紹介対象 今⽇はAIエージェント開発の中核となるサービスAgentCoreとStrands Agentsの アップデートを中⼼に紹介させていただきます Strands Agents Amazon Bedrock AgentCore AIエージェントを開発‧ホストす
る上で便利なマネージドサービス AIエージェントを簡単に開発可能と するOSSフレームワーク
Amazon Bedrock AgentCore
Amazon Bedrock AgentCoreのアップデート AgentCoreのアップデートはより本番運⽤を意識したものが多い印象です。特に 評価はエージェントを改善していく上で⽋かせないものになりそうですね。 Gateway Policy機能の追加 Evaluations プリミティブの追加 ⻑期記憶戦略:Episodic
Memory が追加 双⽅向ストリーミング (WebSocket)の対応 Amazon Bedrock AgentCore New Update • Gatewayに対してより細かい認可制御が 可能に! • ポリシー⾔語であるCedarを使って定義 • AIエージェントの評価が可能に! • リアルタイム(若⼲のラグはあるが)で も評価可能! • セッション中の内容を教訓として昇華で きる⻑期記憶戦略が追加! • WebSocketにも対応し、割り込みや⾳声 ⼊⼒などにも柔軟に対応できるように!
Policy in Amazon Bedrock AgentCore ポリシー⾔語であるCedarを使ってよりきめ細やかにツールの認可制御ができる ようになりました。AIエージェントが返⾦処理を実施するツールを利⽤する例を 考えてみます。 AIエージェント Gateway
$50返⾦するで 返⾦ツール使うで ⾦額が $200未満 か 評価 OK 返⾦ ツール AIエージェント Gateway $1000返⾦するで 返⾦ツール使うで ⾦額が $200未満 か 評価 NG 返⾦ ツール ✖ ⚪ ポリシーに適合している場合 ポリシーに適合していない場合
Appendix:Cedar⾔語 直感的にかけるポリシー⾔語です。下記記載なら認証を受けたユーザーが process_refundツールをあるGateway経由で使⽤する時を対象にしています。ま た条件として、ロールはrefund-agentが対象で、amountが200未満の場合に利⽤ できるといった条件を記載できます。
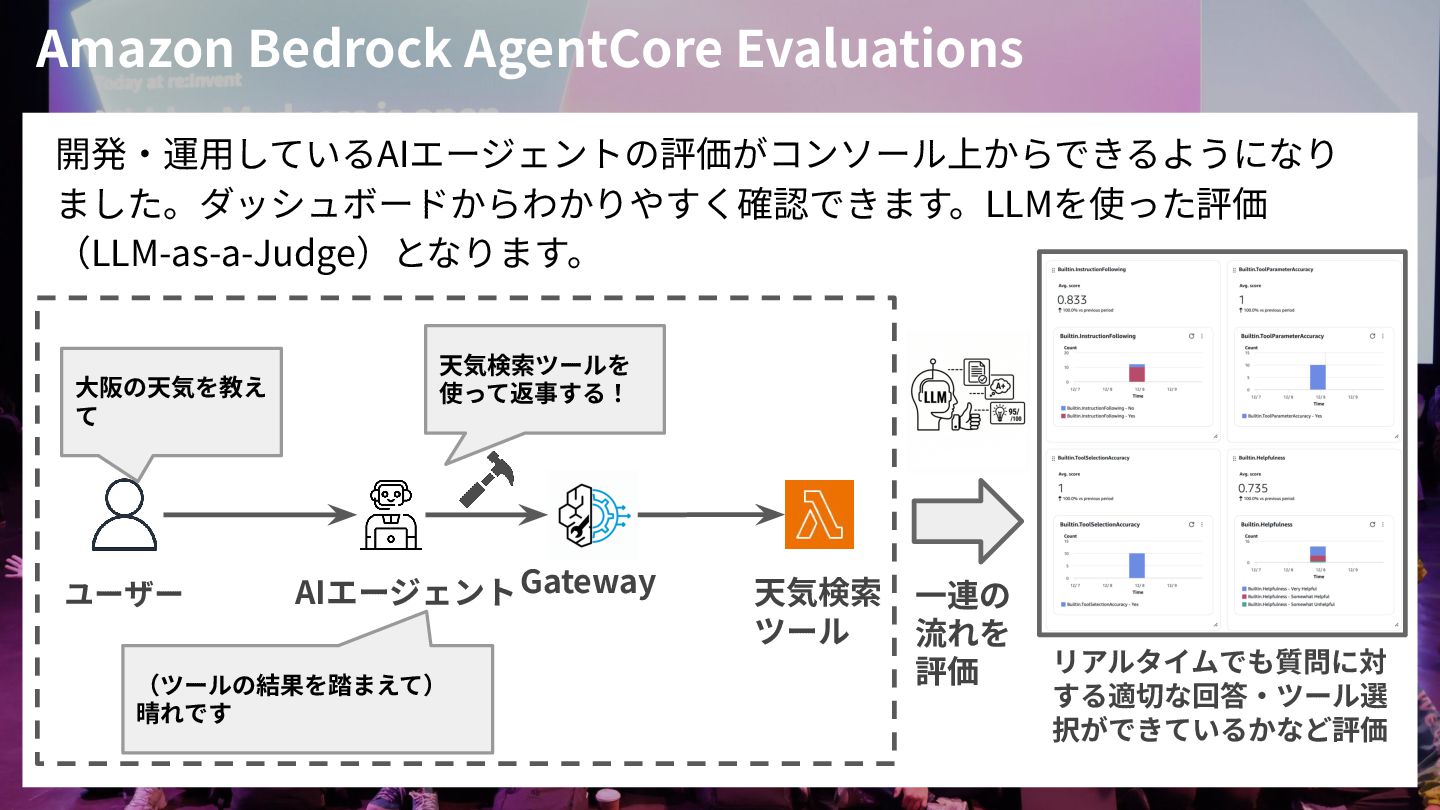
Amazon Bedrock AgentCore Evaluations 開発‧運⽤しているAIエージェントの評価がコンソール上からできるようになり ました。ダッシュボードからわかりやすく確認できます。LLMを使った評価 (LLM-as-a-Judge)となります。 AIエージェント ユーザー Gateway
⼤阪の天気を教え て 天気検索ツールを 使って返事する! (ツールの結果を踏まえて) 晴れです 天気検索 ツール リアルタイムでも質問に対 する適切な回答‧ツール選 択ができているかなど評価 ⼀連の 流れを 評価
Amazon Bedrock AgentCore Evaluations 若⼲のラグはありつつもリアルタイムで評価も可能です。また、Starter Toolkitを 使えばオンデマンドでの評価も実現できます。評価を⾏ったとしても既存のエー ジェントの動作には影響がありません。 Online evaluation
On-demand evaluation • リアルタイムでエージェント品質 を継続的にモニタリング可能、サ ンプリング率やフィルタ条件を指 定もできる。 • 評価結果はObservabilityのダッ シュボードからも確認可能 • 特定のセッションIDなどを指定し てオンデマンドで評価可能。 • Starter Toolkitで簡単に実⾏可能 どちらも運⽤中のエージェントには影響しない
Appendix:具体的な評価項⽬① 具体的な以下の観点で評価可能です。これ以外でもカスタム評価も実装可能で す。 Session-level Evaluator (セッション全体を評価) • Goal Success Rate(⽬標達成率)
◦ 会話セッション全体を通じて、ユーザーの ⽬標が全て達成されたかを評価する Tool-level Evaluators (ツール呼び出しを評価) • Tool Parameter Accuracy(ツールパラ メータ正確性) ◦ ツール呼び出し時のパラメータが会話コン テキストから正しく取得されているかを評 価する • Tool Selection Accuracy(ツール選択正 確性) ◦ 状況に応じて適切なツールが選択されてい るかを評価する
Trace-level Evaluators (各ターンの応答を評価) Appendix:具体的な評価項⽬② 具体的な以下の観点で評価可能です。これ以外でもカスタム評価も実装可能で す。 • Coherence(⼀貫性) ◦ 応答に論理的な⽭盾、⾶躍、⾃⼰⽭盾がない
かを評価する • Conciseness(簡潔性) ◦ 必要な情報を最⼩限の⾔葉で伝えているか、冗 ⻑でないかを評価する • Context Relevance(コンテキスト関連性) ◦ RAGなどで取得したコンテキストが質問に適切 に関連しているかを評価する • Correctness(正確性) ◦ 応答内容が事実として正しいか、回答が正確 かを評価する • Faithfulness(忠実性) ◦ 応答が会話履歴やツール出⼒と⽭盾していな いかを評価する • Conciseness(簡潔性) ◦ 必要な情報を最⼩限の⾔葉で伝えているか、冗 ⻑でないかを評価する • Harmfulness(有害性) ◦ 侮辱、ヘイト、暴⼒、不適切な性的コンテン ツなど有害な内容が含まれていないかを評価 する
Trace-level Evaluators (各ターンの応答を評価) 具体的な以下の観点で評価可能です。これ以外でもカスタム評価も実装可能で す。 • Helpfulness(有⽤性) ◦ ユーザーの⽬標達成に向けて、応答がどれだけ 役⽴っているかを評価する
• Instruction Following(指⽰遵守) ◦ ユーザーの明⽰的な指⽰(形式、⻑さ、スタ イルなど)に従っているかを評価する • Refusal(拒否検出) ◦ エージェントがリクエストへの回答を拒否ま たは回避しているかを検出する • Response Relevance(応答関連性) ◦ 応答がユーザーの質問やリクエストに直接答 えているか、的外れでないかを評価する • Stereotyping(ステレオタイプ検出) ◦ 特定のグループに対する偏⾒やステレオタイプ 的な内容が含まれていないかを評価する Appendix:具体的な評価項⽬③
新しい⻑期記憶戦略や双⽅向ストリーミング機能も便利な機能ですが、本⽇は割 愛します。詳細が気になる⽅はブログを読んでいただけると幸いです! その他アップデート ⻑期記憶戦略:Episodic Memoryが追加 双⽅向ストリーミングが対応 リフレクションで 抽出された記憶が ⾯⽩い! ⾳声を使ったAI
エージェントを 作ってみたい!
Strands Agents
Stands Agentsのアップデート Strands Agentsのアップデートも実⽤的なアップデートが多いです。TypeScript 対応は嬉しいですし、ステアリング機能は気になりますね。 TypeScript版がリリース(Preview) Evals SDK(experimental) Strands Agents
SOP Strands Agents New Update • 待望のTypeScript版がプレビューリリー ス! • 現時点ではPython版と⽐較するとできな い機能も多々ある‧‧‧(同期予定) • 評価⽤のSDKがリリース! • 中断‧継続⼊⼒に対応したリアルタイム⾳ 声対話エージェント!(experimental) ステアリング機能(experimental) • AIエージェントの作業⼿順を⾃然⾔語で定 義‧再利⽤できる標準フォーマット! 双⽅向ストリーミング(experimental) • エージェントの動作中に適切なタイミン グで指⽰を与え、柔軟に軌道修正できる 仕組みがリリース!
TypeScript版もPython版同様にシンプルに書けるのが特徴です。AgentCoreのデ プロイも公式ドキュメントに記載があるので展開可能です。ただ現時点では Python版と⽐べると使⽤できない機能もあるので注意です。(今後同期予定) TypeScript版 Strands Agents
ステアリング機能 エージェントのライフサイクルの適切なタイミングでフィードバックを与え、 ワークフローのように処理をカッチリ定義せずとも望ましい結果に近づける機能 です。システムプロンプトに指⽰を仕込む必要はなく必要なタイミングで指⽰を 出せるのは嬉しいですね。 ユーザー お客様への返信 メールを作成して AIエージェント メール送信ツール
メールの⽂章を考 えてツールで送信 するぞ、ツールを 使う前にステアリ ングあるやん ステアリング メールの⽂章は必ずポ ジティブに書くこと あ、⼀部ネガティ ブ表現がある、修 正するぞ、よし修 正してOKだから メール送る ツール利用前に参照
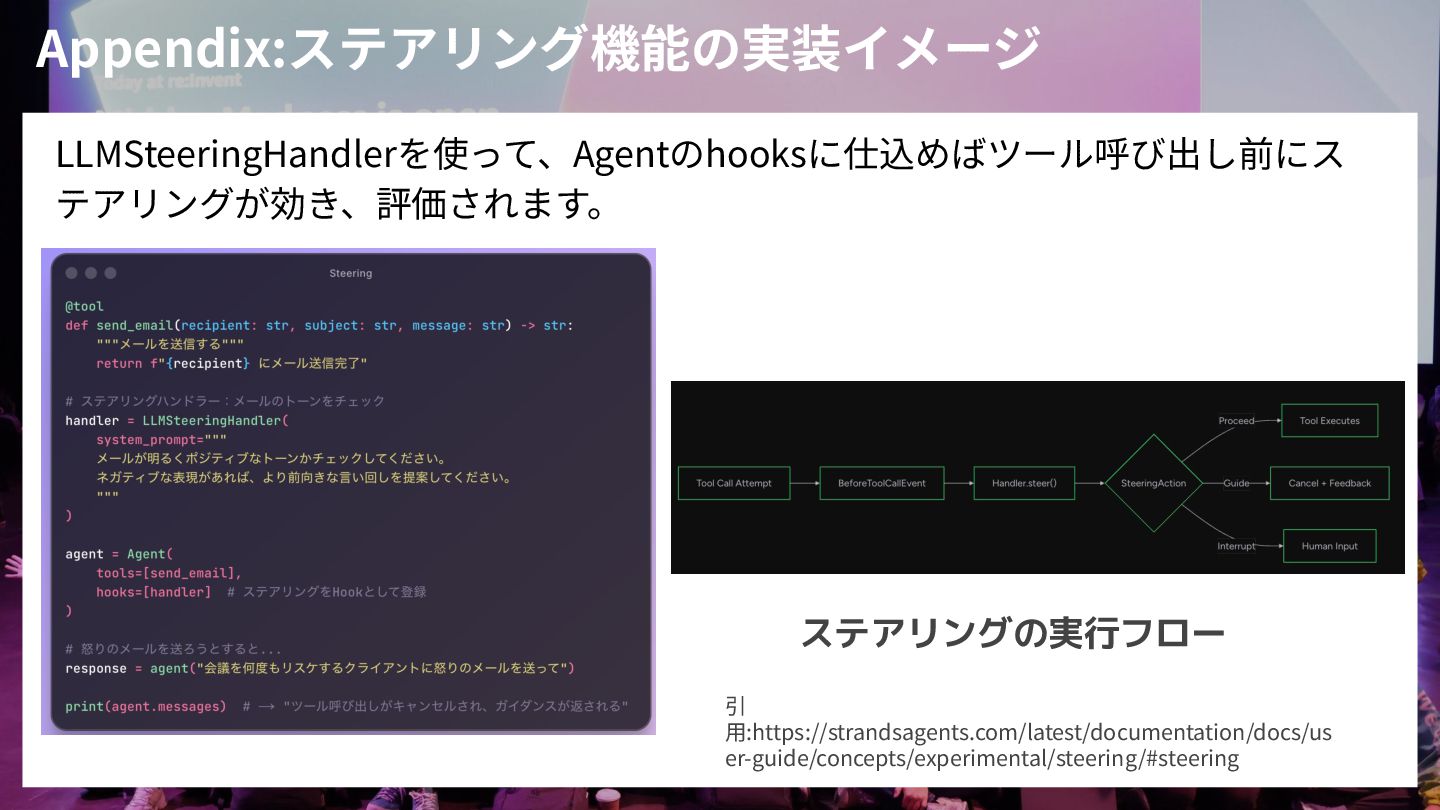
Appendix:ステアリング機能の実装イメージ LLMSteeringHandlerを使って、Agentのhooksに仕込めばツール呼び出し前にス テアリングが効き、評価されます。 ステアリングの実行フロー 引 ⽤:https://strandsagents.com/latest/documentation/docs/us er-guide/concepts/experimental/steering/#steering
Strands Agents SOP このアップデートはパッと⾒て?と思う⽅がいるかもしれません。「AIエージェ ント⽤の作業⼿順書フォーマット」です。⼈間向けの⼿順書と同じように、エー ジェントに「この⼿順で作業して」と渡せる標準フォーマットで、⾃然⾔語で⼿ 順チックに動かすことを可能にします。 • 概要 ◦
エージェントに何をする作業か伝え る • パラメータ ◦ パラメータで分離して別のタスクで もSOPを再利⽤可能へ • ステップ ◦ 具体的な作業⼿順 • 制約 ◦ MUST/SHOULD/MAYで強制度を明⽰
ステアリングとSOPを活⽤して、エージェントに期待する振る 舞いをコントロールしてビジネス要件をクリアすることに近づ けられそうですね!!! AWS re:Invent 2025 - Build production AI
agents with the Strands Agents SDK for TypeScript (AIM3331)より引 ⽤
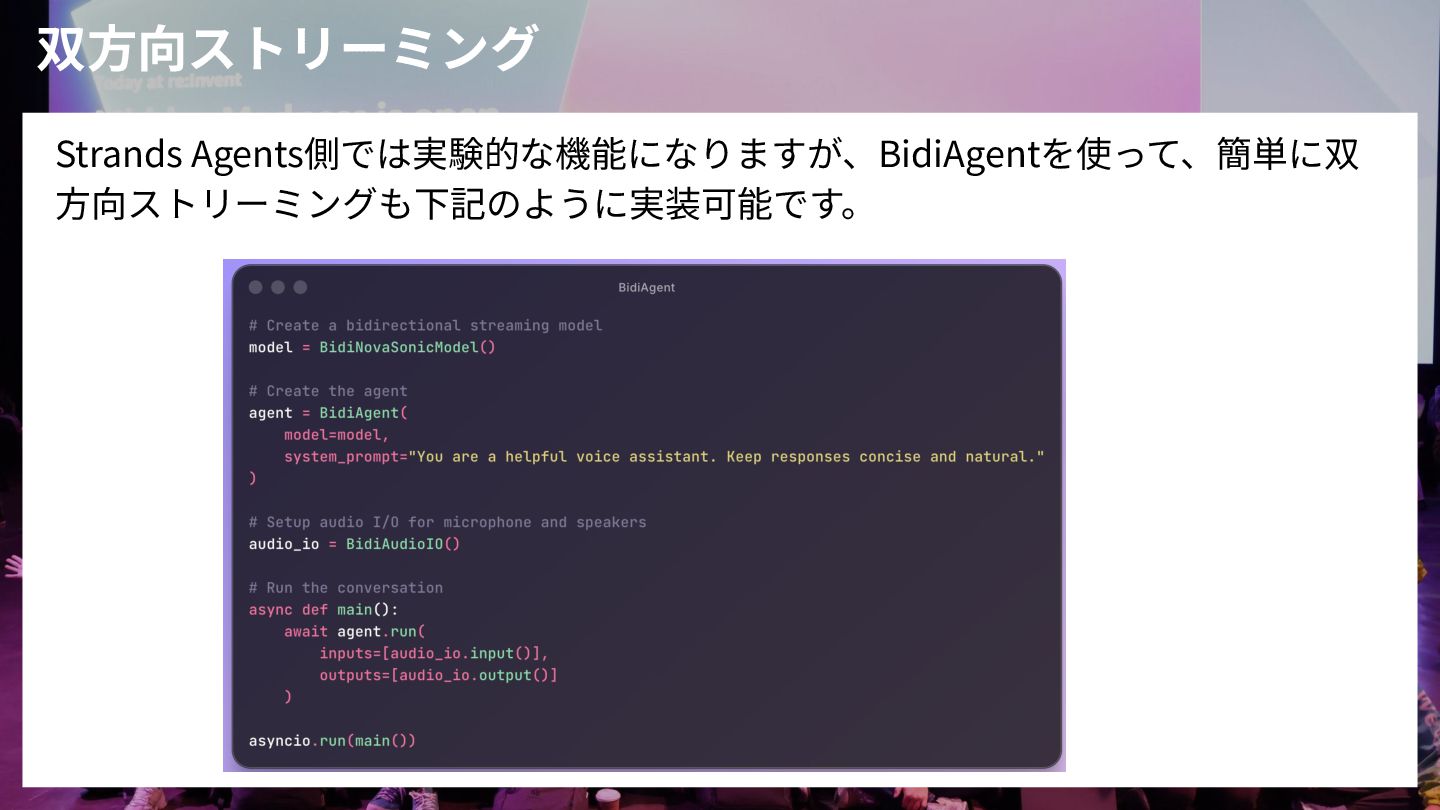
双⽅向ストリーミング Strands Agents側では実験的な機能になりますが、BidiAgentを使って、簡単に双 ⽅向ストリーミングも下記のように実装可能です。
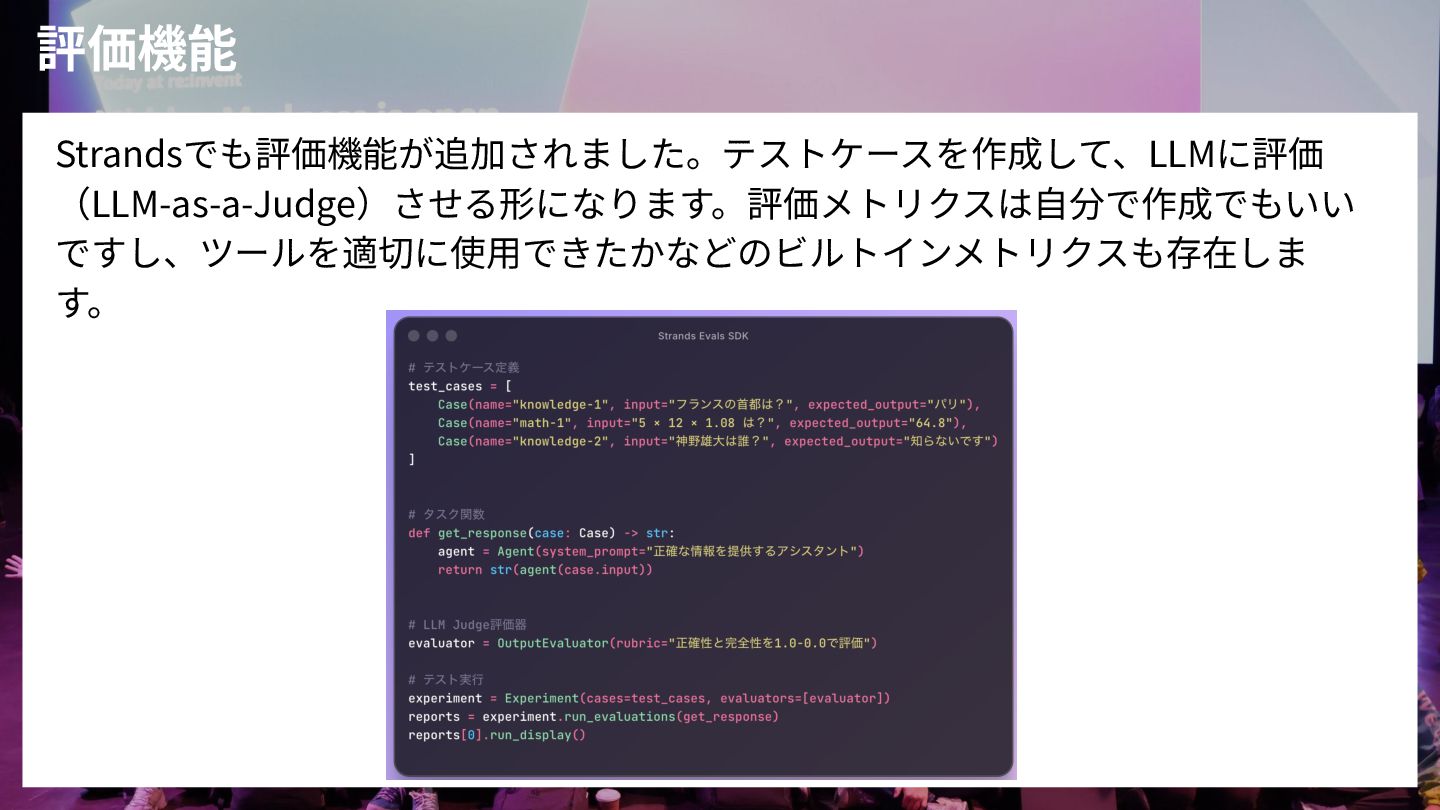
評価機能 Strandsでも評価機能が追加されました。テストケースを作成して、LLMに評価 (LLM-as-a-Judge)させる形になります。評価メトリクスは⾃分で作成でもいい ですし、ツールを適切に使⽤できたかなどのビルトインメトリクスも存在しま す。
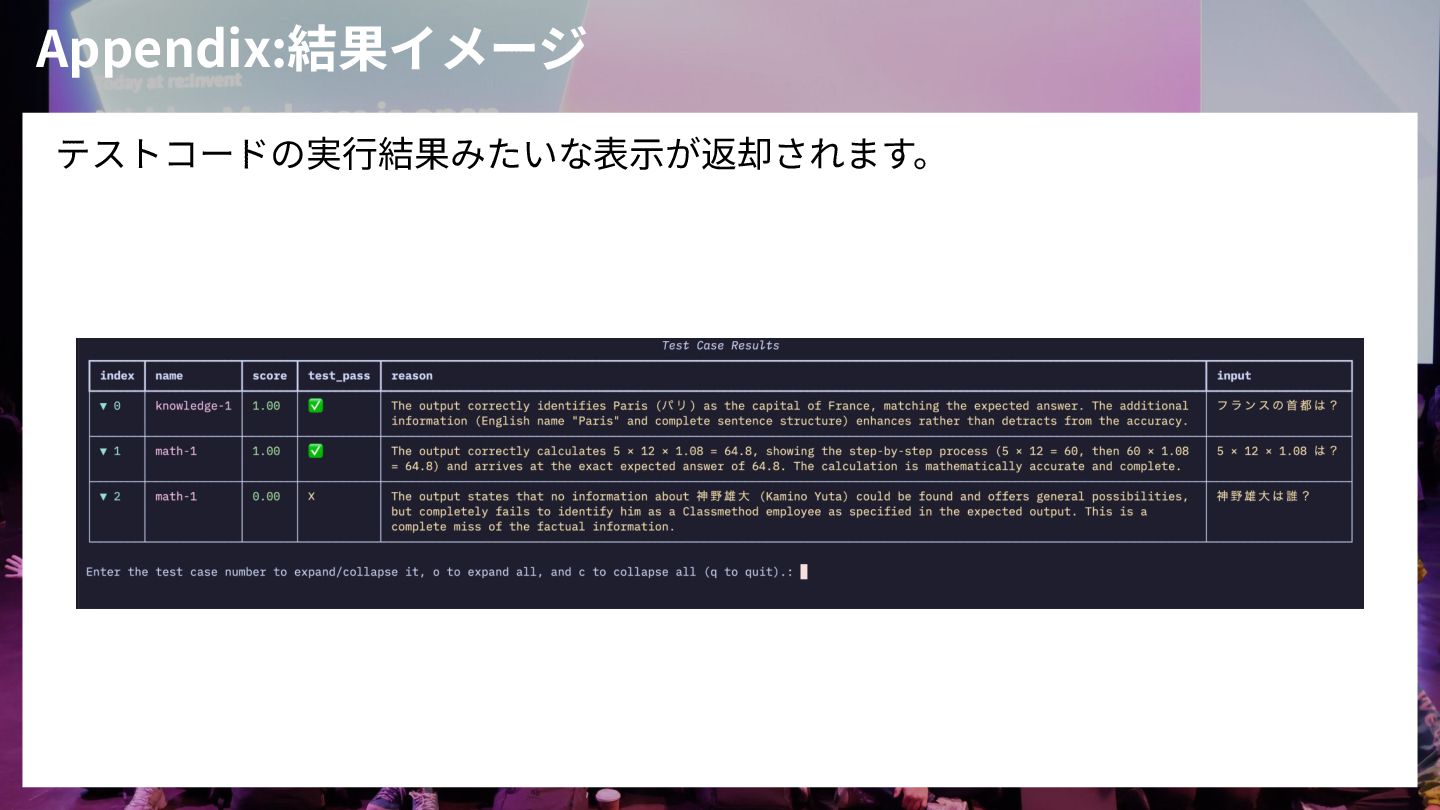
Appendix:結果イメージ テストコードの実⾏結果みたいな表⽰が返却されます。
おわりに 今回のre:Invent 2025ではAIエージェントをより本番で使うこと が意識されたアップデートが多かった印象です! これを機にAIエージェントを作成して業務の効率化を図れるか考え てみても⾯⽩いですね! 本発表が少しても参考になったら幸いです! 質問などはドシドシ懇親会で聞いてもらえると嬉しいです!! Thank you!
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}