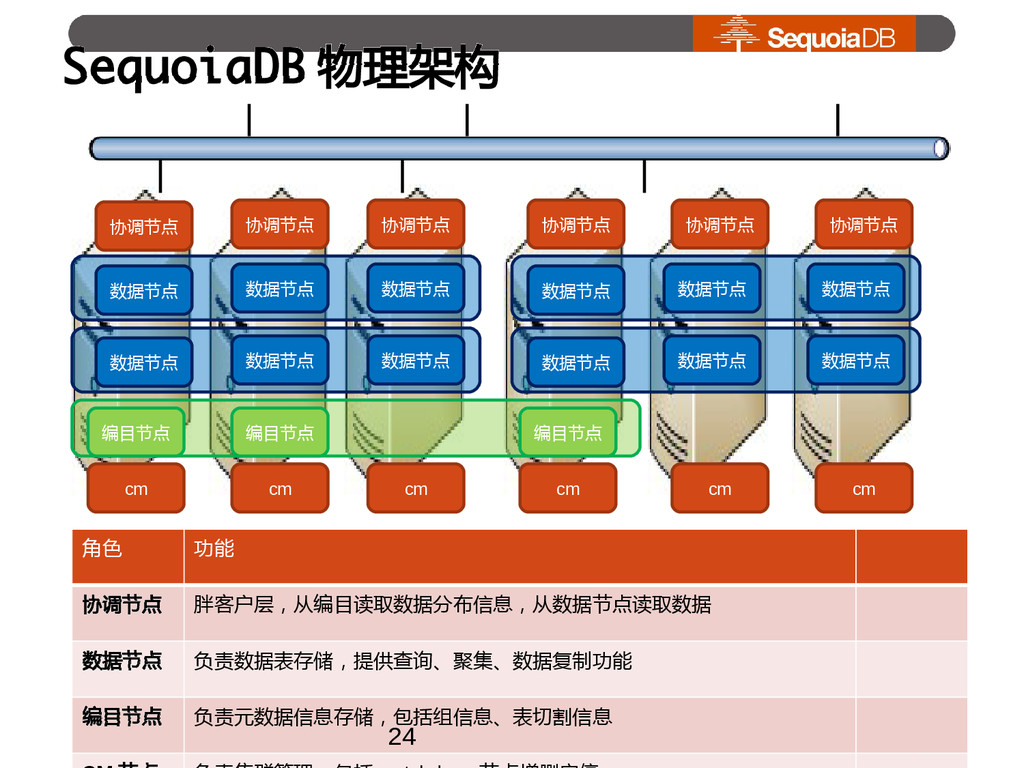
协调节点 数据节点 数据节点 数据节点 数据节点 数据节点 数据节点 数据节点 数据节点 数据节点 编目节点 编目节点 编目节点 角色 功能 协调节点 胖客户层,从编目读取数据分布信息,从数据节点读取数据 数据节点 负责数据表存储,提供查询、聚集、数据复制功能 编目节点 负责元数据信息存储,包括组信息、表切割信息 cm cm cm cm cm cm 24
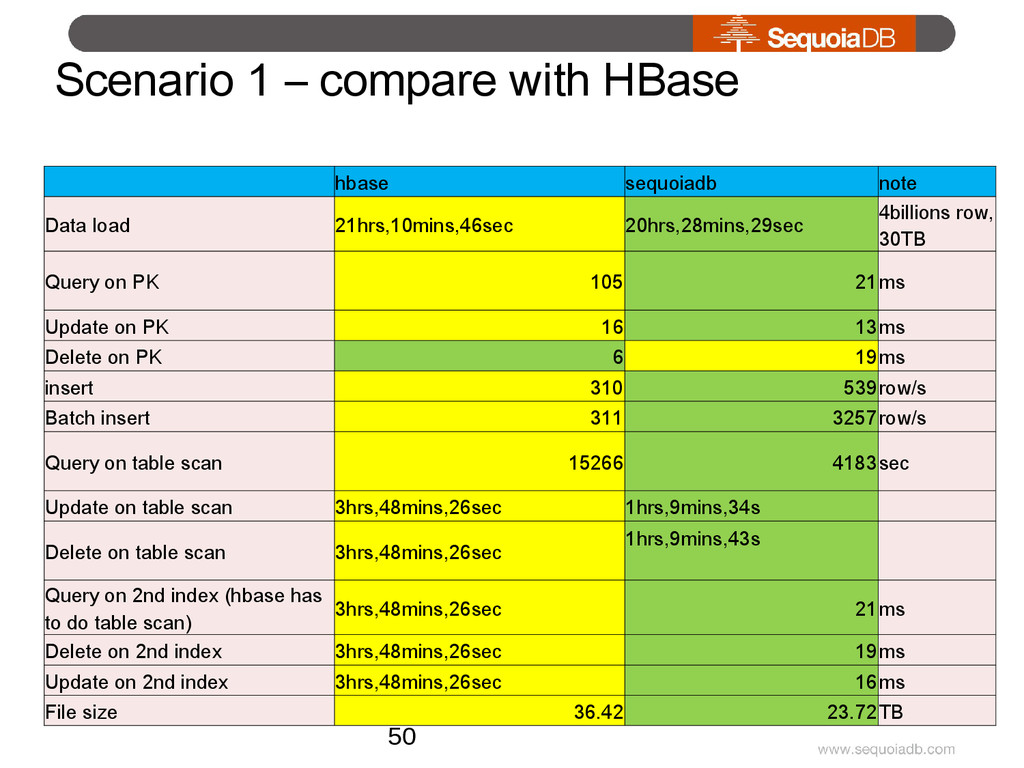
Data load 21hrs,10mins,46sec 20hrs,28mins,29sec 4billions row, 30TB Query on PK 105 21ms Update on PK 16 13ms Delete on PK 6 19ms insert 310 539row/s Batch insert 311 3257row/s Query on table scan 15266 4183sec Update on table scan 3hrs,48mins,26sec 1hrs,9mins,34s Delete on table scan 3hrs,48mins,26sec 1hrs,9mins,43s Query on 2nd index (hbase has to do table scan) 3hrs,48mins,26sec 21ms Delete on 2nd index 3hrs,48mins,26sec 19ms Update on 2nd index 3hrs,48mins,26sec 16ms File size 36.42 23.72TB 50
{kind=link}
![Who am I? • 许建辉 – [email protected] • SequoiaDB 研发总监](https://files.speakerdeck.com/presentations/58f04910042701322f05622e5395cf7f/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
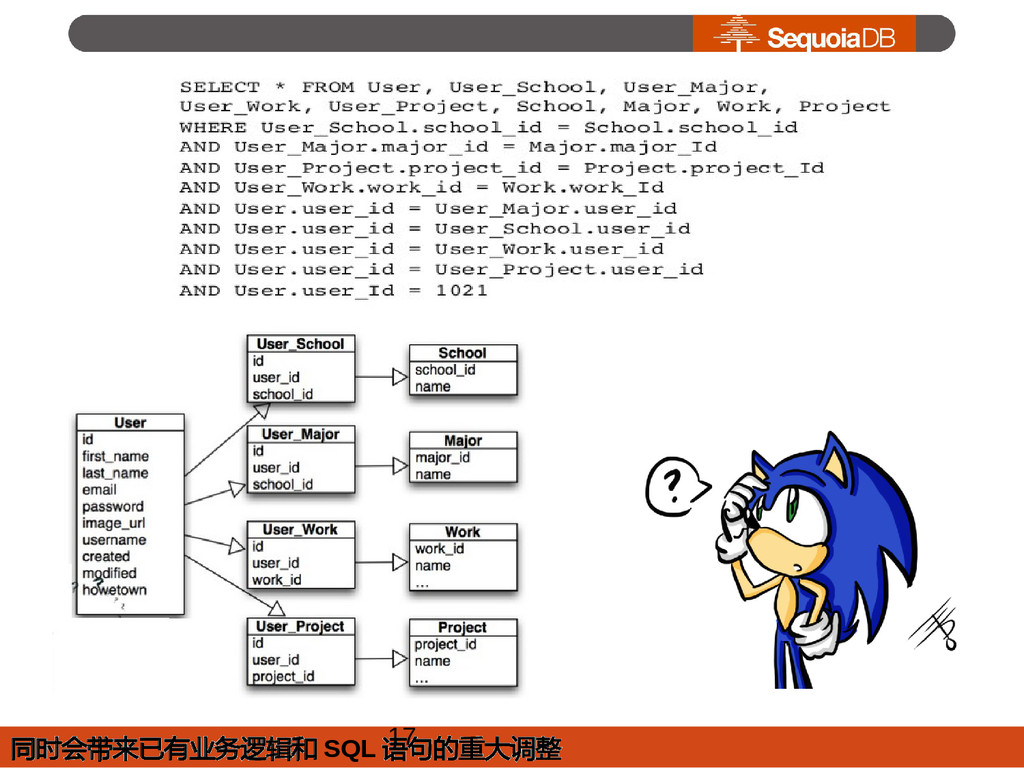{kind=link}
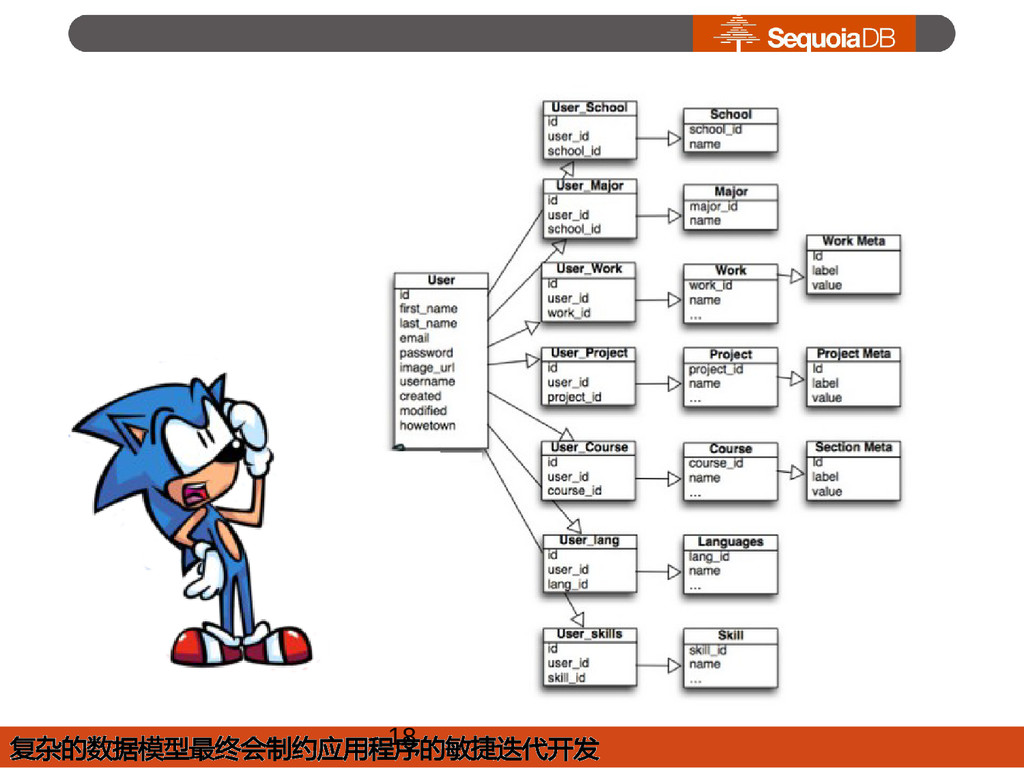{kind=link}
{kind=link}
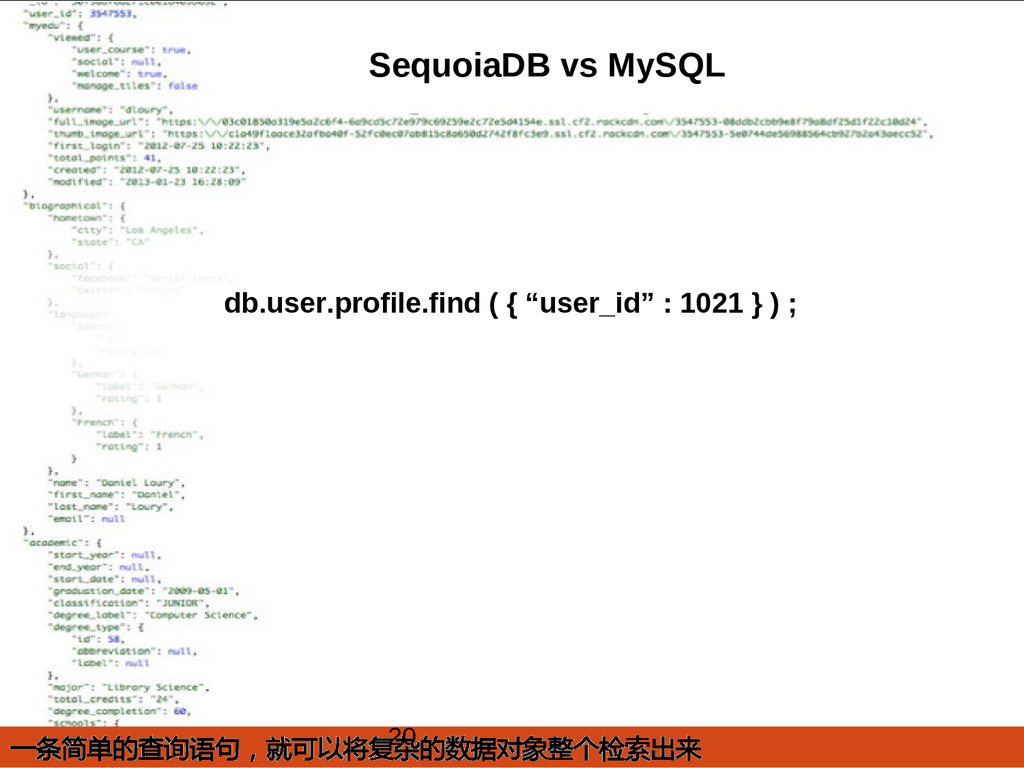{kind=link}
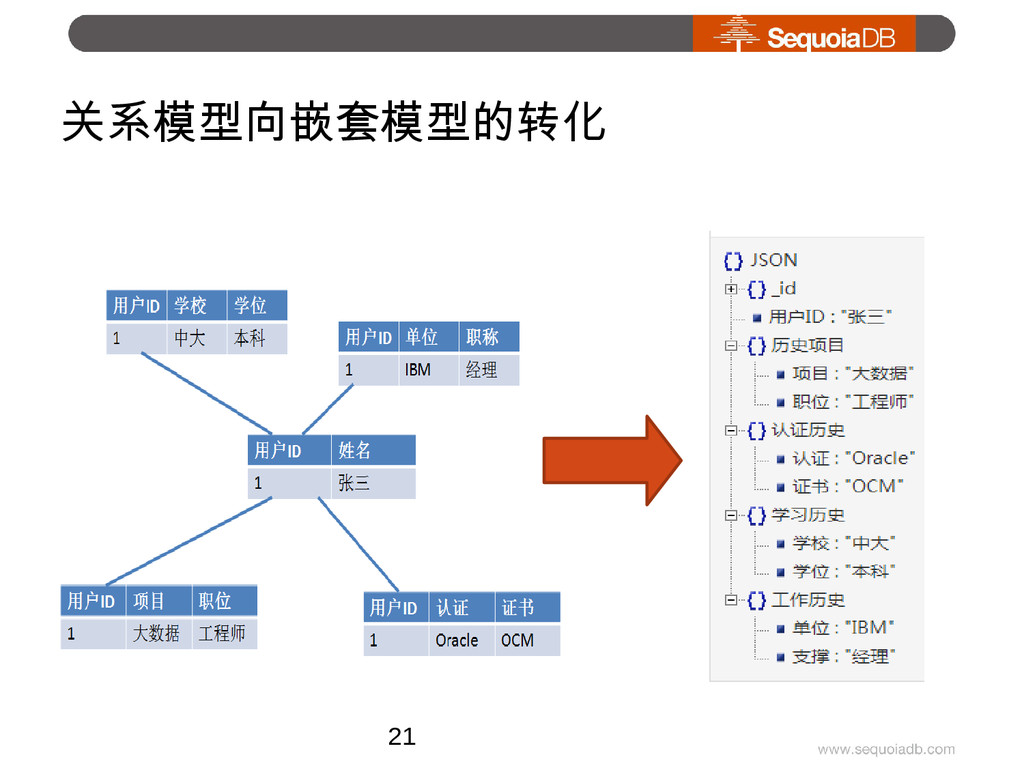{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
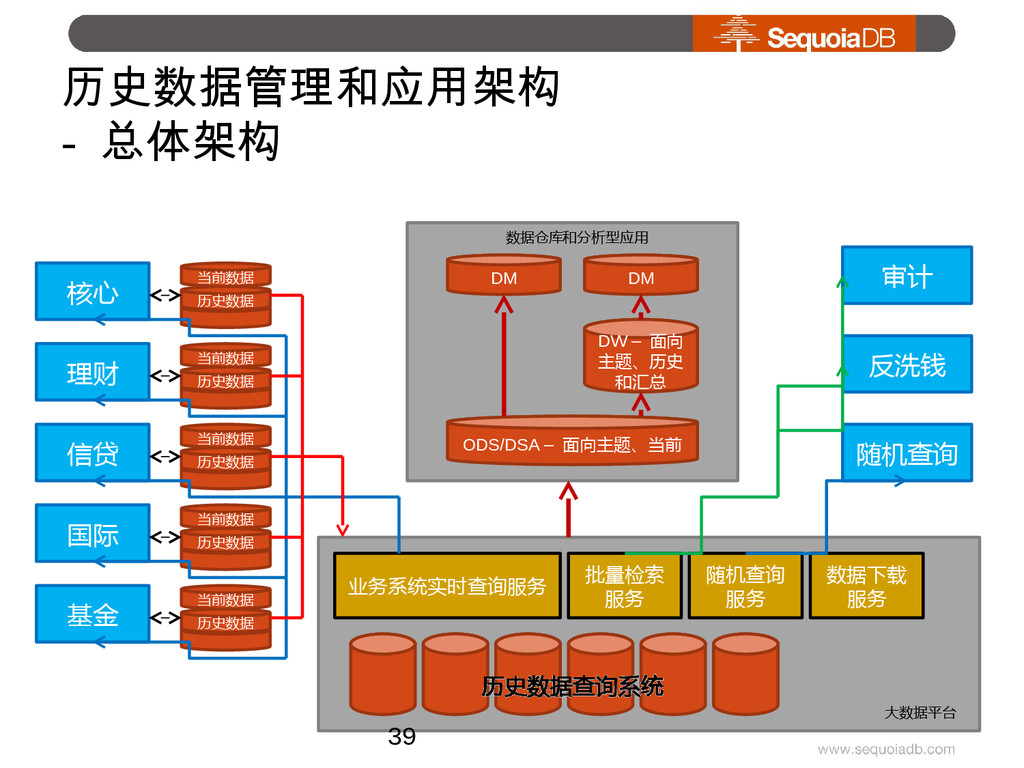{kind=link}
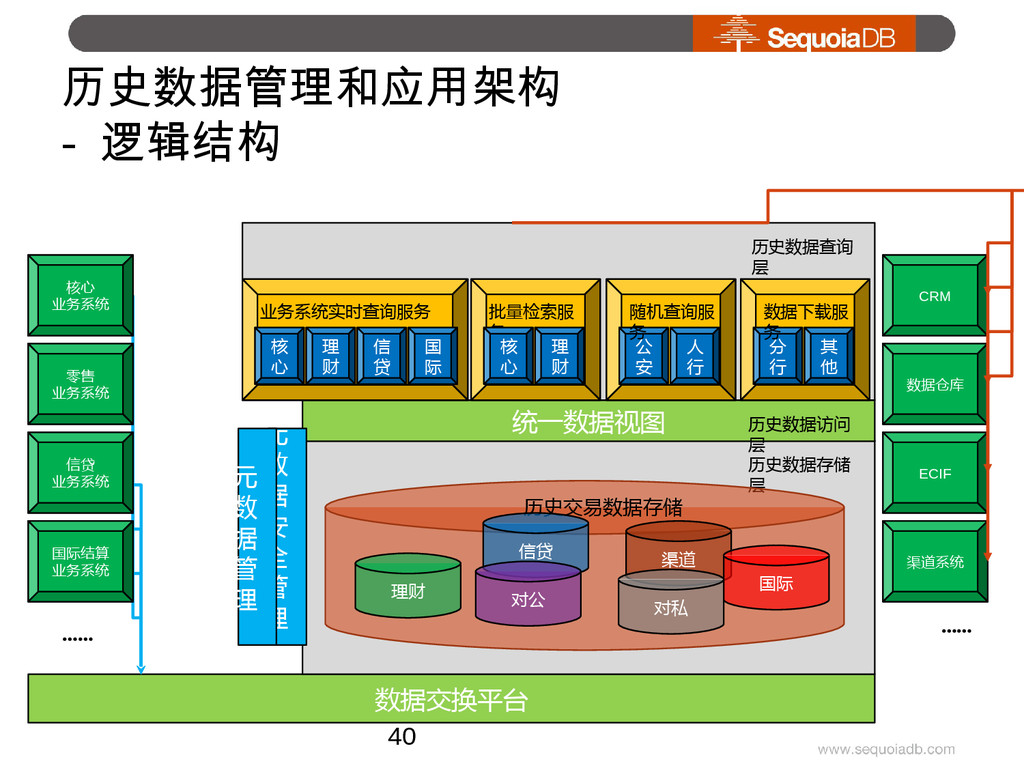{kind=link}
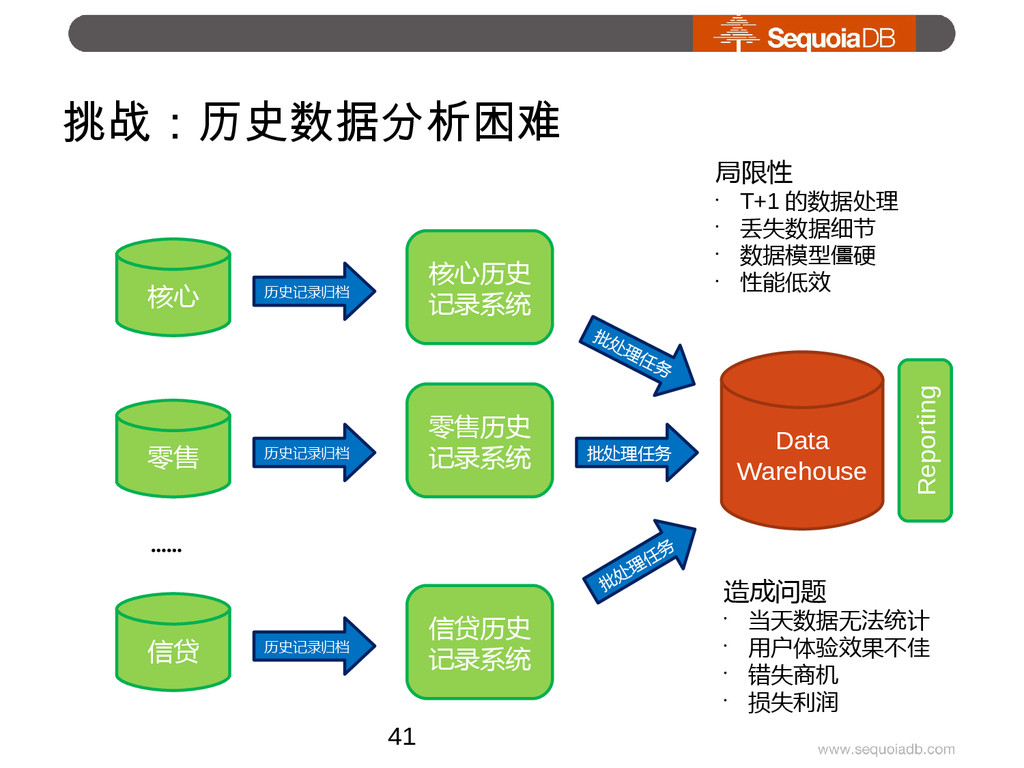{kind=link}
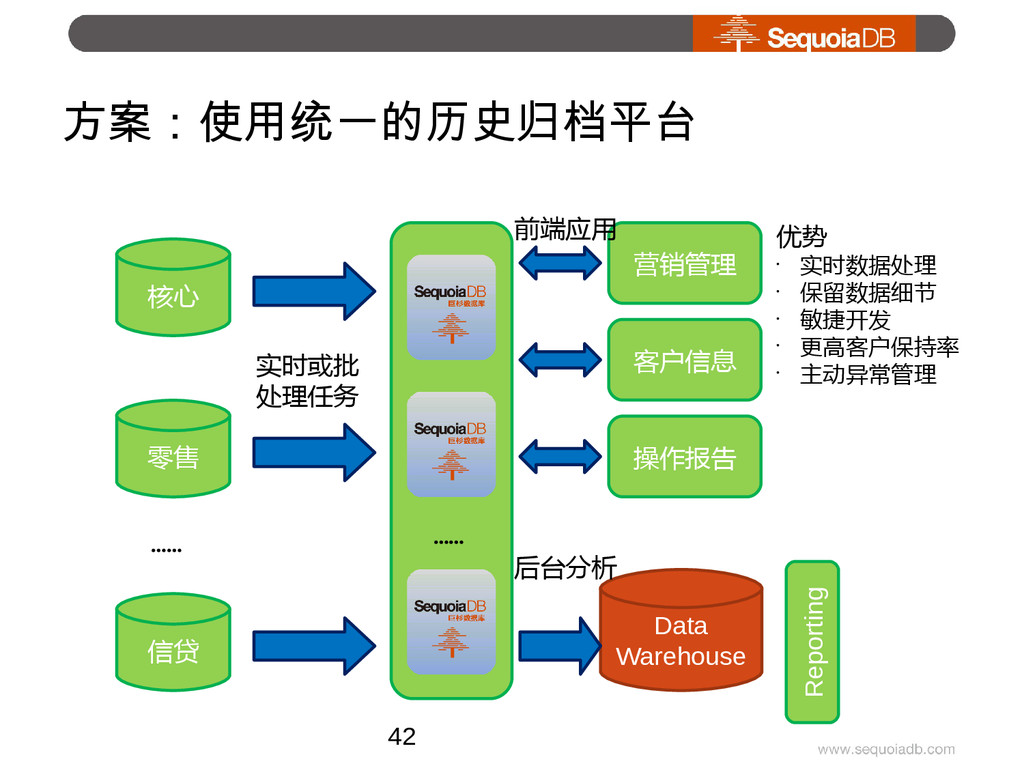{kind=link}
{kind=link}
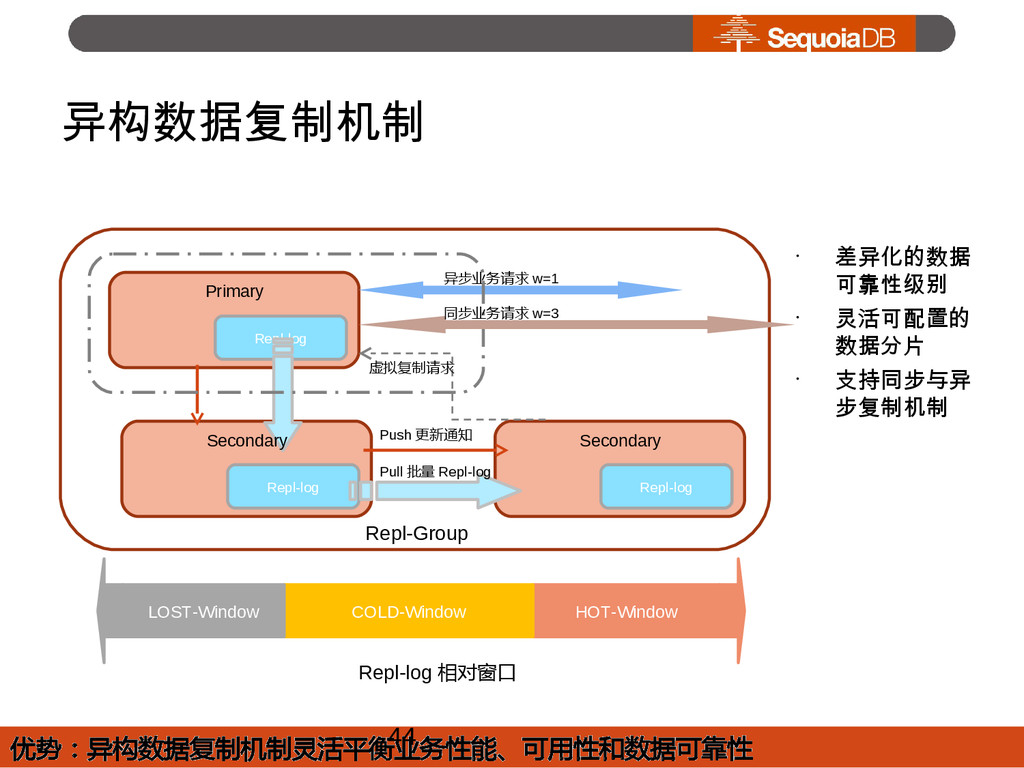{kind=link}
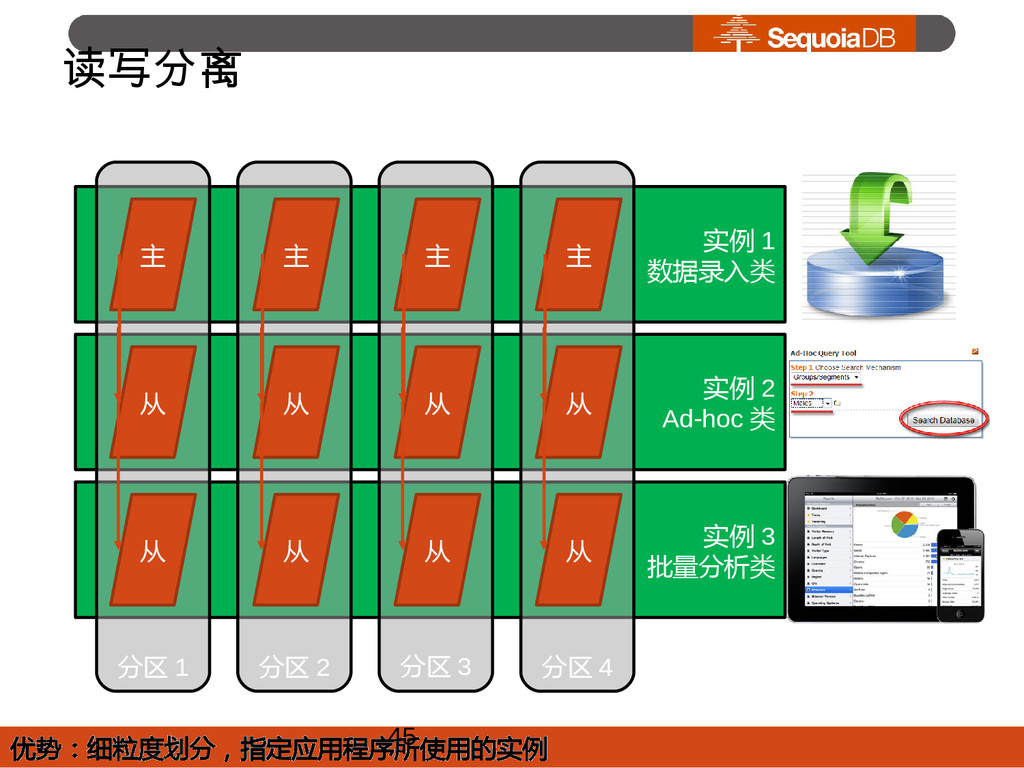{kind=link}
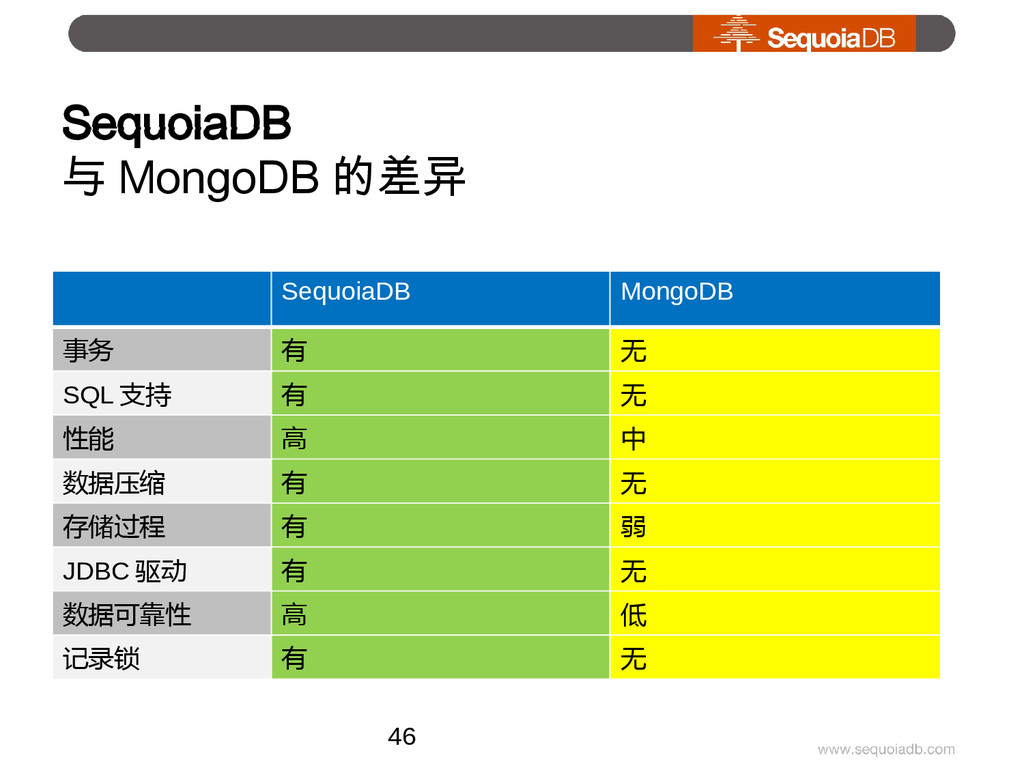{kind=link}
{kind=link}
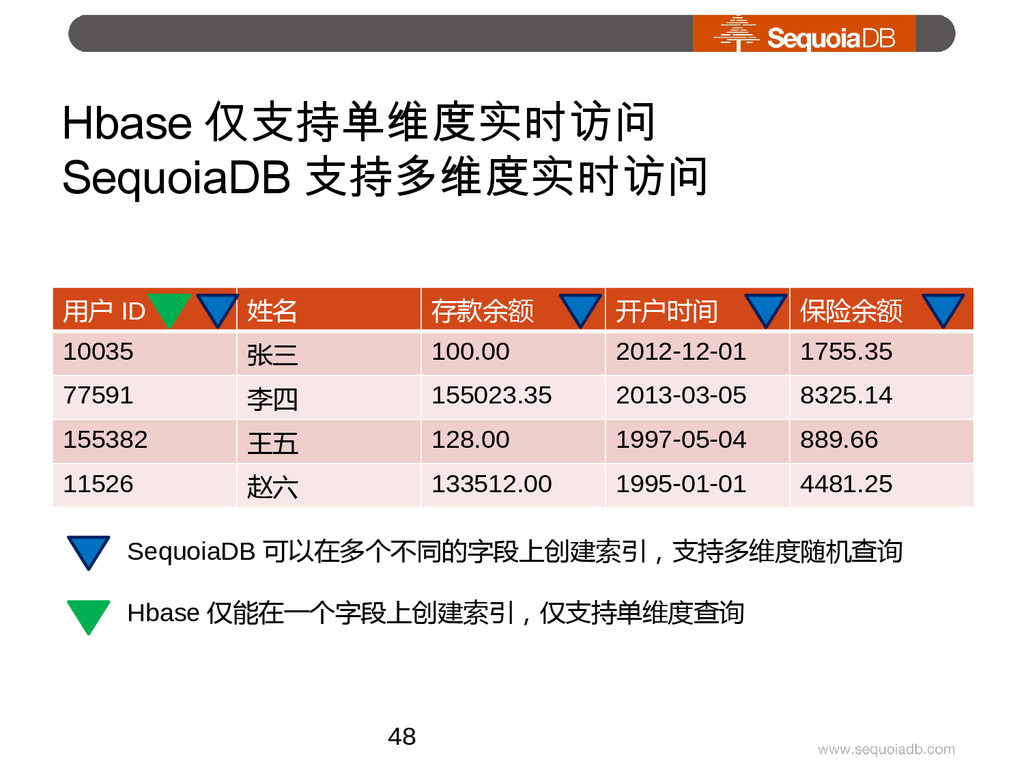{kind=link}
{kind=link}
{kind=link}
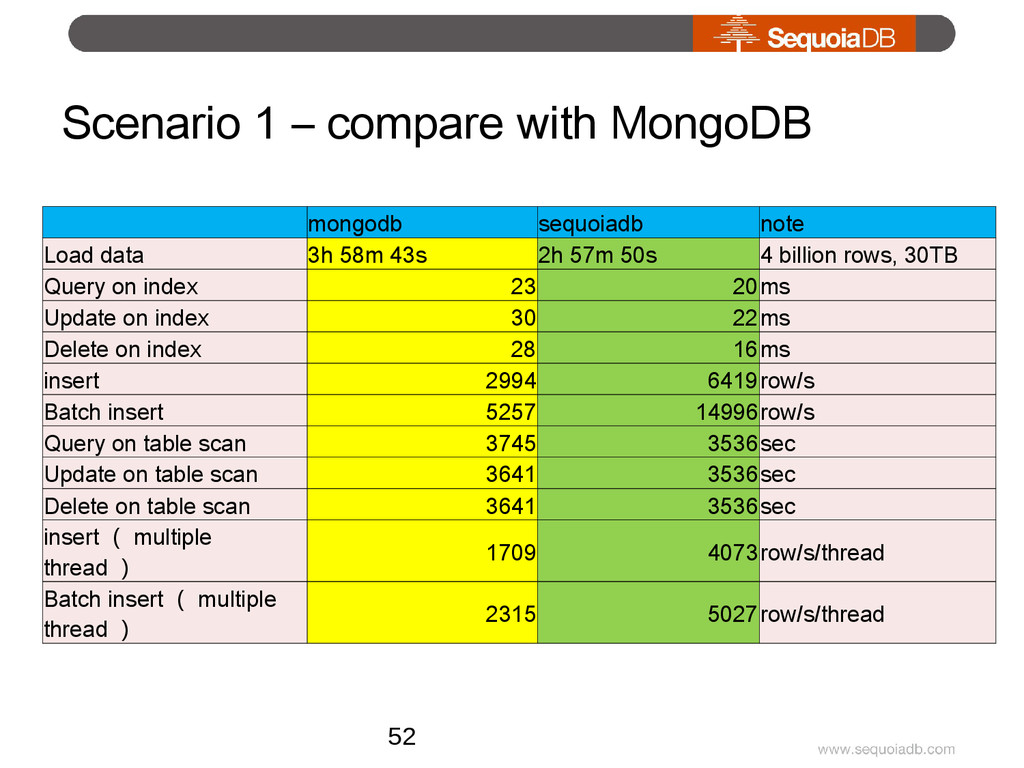
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}