What is the current state of speech technology? Is automatic speech recognition (ASR) sufficient for closed captioning or live captioning? Do we still need humans to achieve accuracy standards for accessibility?
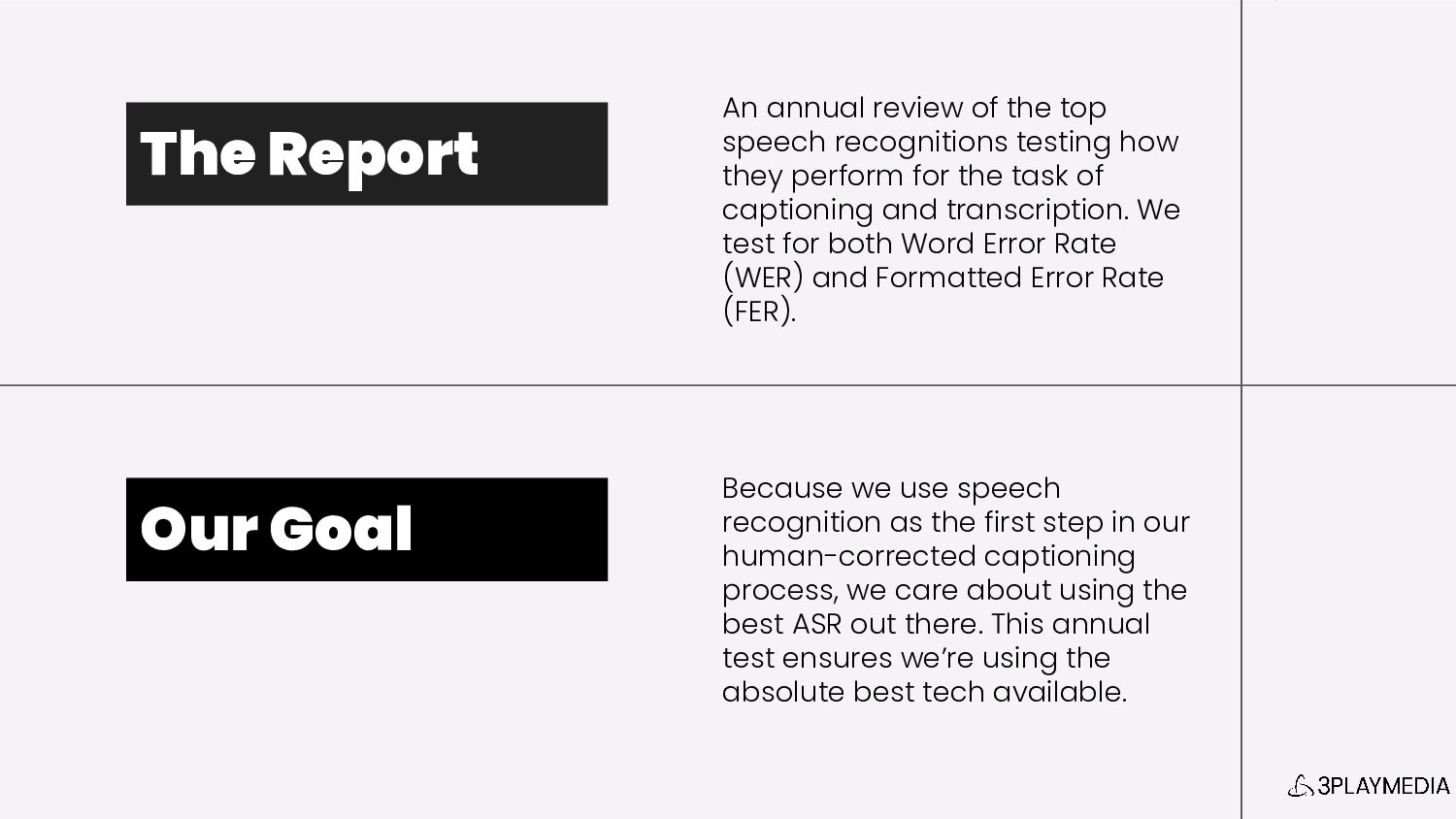
Speech recognition is widely used to streamline the process of creating closed captions, audio descriptions, and other media accessibility accommodations. This session will discuss the findings from a 2024 research study of leading ASR engines to understand how speech AI measures up to the task of captioning and transcription without the intervention of a human editor.
This is the only report of its kind focused on the application of speech recognition technology for captioning vs. for other technologies.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}