• Alienvault's Authorized Training Center (ATC) for Spain and LATAM • Team of more than 25 Security Experts • Own developments and tool integrations • Advanced Health Check Monitoring • Web: www.a3sec.com, Twitter: @a3sec
Manager • Really believes in Open Source model • Programming since he was 9 years old • Ossim developer at its early stage • Agent core engine (full regex) and first plugins • Python lover :-) • Debian package maintainer (a long, long time ago) • Sci-Fi books reader and mountain bike rider
expressions are almost never the right answer ◦ Difficult to debug and maintain ◦ Performance reasons, slower for simple matching ◦ Learning curve • Python string functions are small C loops: super fast! ◦ beginswith(), endswith(), split(), etc.
expressions are almost never the right answer ◦ Difficult to debug and maintain ◦ Performance reasons, slower for simple matching ◦ Learning curve • Python string functions are small C loops: super fast! ◦ beginswith(), endswith(), split(), etc. • Use standard parsing libraries! Formats: JSON, HTML, XML, CSV, etc.
are a lot of reasons to use regex: • powerful • portable • fast (with performance in mind) • useful for complex patterns • save development time • short code • fun :-) • beautiful?
vs non-greedy (lazy) >>> re.findall('A+', 'AAAA') ['AAAA'] >>> re.findall('A+?', 'AAAA') ['A', 'A', 'A', 'A'] • An overall match takes precedence over and overall non-match >>> re.findall('<.*>.*</.*>', '<B>i am bold</B>') >>> re.findall('<(.*)>.*</(.*)>', '<B>i am bold</B>')
+ string.lowercase regexp = r'^[%s]+$' % CHARS if re.search(regexp, word) return "YES" else "NOP" timeit.timeit(s, 'is_a_word(%s)' %(w)) 1.49650502205 YES len=4 word 1.65614509583 YES len=25 wordlongerthanpreviousone.. 1.92520785332 YES len=60 wordlongerthanpreviosoneplusan.. 2.38850092888 YES len=120 wordlongerthanpreviosoneplusan.. 1.55924701691 NOP len=10 not a word 1.7087020874 NOP len=25 not a word, just a phrase.. 1.92521882057 NOP len=50 not a word, just a phrase bigg.. 2.39075493813 NOP len=102 not a word, just a phrase bigg..
+ string.lowercase regexp = r'^[%s]+$' % CHARS if re.search(regexp, word) return "YES" else "NOP" timeit.timeit(s, 'is_a_word(%s)' %(w)) 1.49650502205 YES len=4 word 1.65614509583 YES len=25 wordlongerthanpreviousone.. 1.92520785332 YES len=60 wordlongerthanpreviosoneplusan.. 2.38850092888 YES len=120 wordlongerthanpreviosoneplusan.. 1.55924701691 NOP len=10 not a word 1.7087020874 NOP len=25 not a word, just a phrase.. 1.92521882057 NOP len=50 not a word, just a phrase bigg.. 2.39075493813 NOP len=102 not a word, just a phrase bigg.. If the target string is longer, the regex matching is slower. No matter if success or fail.
word: if not char in (CHARS): return "NOP" return "YES" timeit.timeit(s, 'is_a_word(%s)' %(w)) 0.687522172928 YES len=4 word 1.0725839138 YES len=25 wordlongerthanpreviousone.. 2.34717106819 YES len=60 wordlongerthanpreviosoneplusan.. 4.31543898582 YES len=120 wordlongerthanpreviosoneplusan.. 0.54797577858 NOP len=10 not a word 0.547253847122 NOP len=25 not a word, just a phrase.. 0.546499967575 NOP len=50 not a word, just a phrase bigg.. 0.553755998611 NOP len=102 not a word, just a phrase bigg..
word: if not char in (CHARS): return "NOP" return "YES" timeit.timeit(s, 'is_a_word(%s)' %(w)) 0.687522172928 YES len=4 word 1.0725839138 YES len=25 wordlongerthanpreviousone.. 2.34717106819 YES len=60 wordlongerthanpreviosoneplusan.. 4.31543898582 YES len=120 wordlongerthanpreviosoneplusan.. 0.54797577858 NOP len=10 not a word 0.547253847122 NOP len=25 not a word, just a phrase.. 0.546499967575 NOP len=50 not a word, just a phrase bigg.. 0.553755998611 NOP len=102 not a word, just a phrase bigg.. 2 python nested loops if success (slow) But fails at the same point&time (first space)
word.isalpha() else "NOP" timeit.timeit(s, 'is_a_word(%s)' %(w)) 0.146447896957 YES len=4 word 0.212563037872 YES len=25 wordlongerthanpreviousone.. 0.318686008453 YES len=60 wordlongerthanpreviosoneplusan.. 0.493942975998 YES len=120 wordlongerthanpreviosoneplusan.. 0.14647102356 NOP len=10 not a word 0.146160840988 NOP len=25 not a word, just a phrase.. 0.147103071213 NOP len=50 not a word, just a phrase bigg.. 0.146239995956 NOP len=102 not a word, just a phrase bigg..
word.isalpha() else "NOP" timeit.timeit(s, 'is_a_word(%s)' %(w)) 0.146447896957 YES len=4 word 0.212563037872 YES len=25 wordlongerthanpreviousone.. 0.318686008453 YES len=60 wordlongerthanpreviosoneplusan.. 0.493942975998 YES len=120 wordlongerthanpreviosoneplusan.. 0.14647102356 NOP len=10 not a word 0.146160840988 NOP len=25 not a word, just a phrase.. 0.147103071213 NOP len=50 not a word, just a phrase bigg.. 0.146239995956 NOP len=102 not a word, just a phrase bigg.. Python string functions (fast and small C loops)
group when no need to capture and save text to a variable (?:abc|def|ghi) instead of (abc|def|ghi) • Pattern most likely to match first (TRAFFIC_ALLOW|TRAFFIC_DROP|TRAFFIC_DENY)
group when no need to capture and save text to a variable (?:abc|def|ghi) instead of (abc|def|ghi) • Pattern most likely to match first (TRAFFIC_ALLOW|TRAFFIC_DROP|TRAFFIC_DENY) TRAFFIC_(ALLOW|DROP|DENY)
group when no need to capture and save text to a variable (?:abc|def|ghi) instead of (abc|def|ghi) • Pattern most likely to match first (TRAFFIC_ALLOW|TRAFFIC_DROP|TRAFFIC_DENY) TRAFFIC_(ALLOW|DROP|DENY) • Use anchors (^ and $) to limit the score re.findall(r'(ab){2}', 'abcabcabc') re.findall(r'^(ab){2}','abcabcabc') #failures occur faster
process is forked for each loaded plugin ◦ Use the plugins that you really need! • A plugin is a set of rules (regexp operations) for matching log lines ◦ If a plugin doesn't match a log entry, it fails in ALL its rules! ◦ Reduce the number of rules, use a [translation] table
for rule matching ◦ Order your rules by priority, pattern most likely to match first • Divide and conquer ◦ A plugin is configured to read from a source file, use dedicated source files per technology ◦ Also, use dedicated plugins for each technology
{kind=link}
{kind=link}
![About Me • David Gil <[email protected]> • Developer, Sysadmin, Project](https://files.speakerdeck.com/presentations/261dc4c0c1360130593816f50ed20d66/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
![Regular Expressions What is a regex? Regular expression: (bb|[^b]{2})](https://files.speakerdeck.com/presentations/261dc4c0c1360130593816f50ed20d66/slide_5.jpg){kind=link}
![Regular Expressions What is a regex? Regular expression: (bb|[^b]{2})\d\d Input](https://files.speakerdeck.com/presentations/261dc4c0c1360130593816f50ed20d66/slide_6.jpg){kind=link}
![Regular Expressions What is a regex? Regular expression: (bb|[^b]{2})\d\d Input](https://files.speakerdeck.com/presentations/261dc4c0c1360130593816f50ed20d66/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Regular Expressions Basics - Groups [...]: Set of characters >>>](https://files.speakerdeck.com/presentations/261dc4c0c1360130593816f50ed20d66/slide_17.jpg){kind=link}
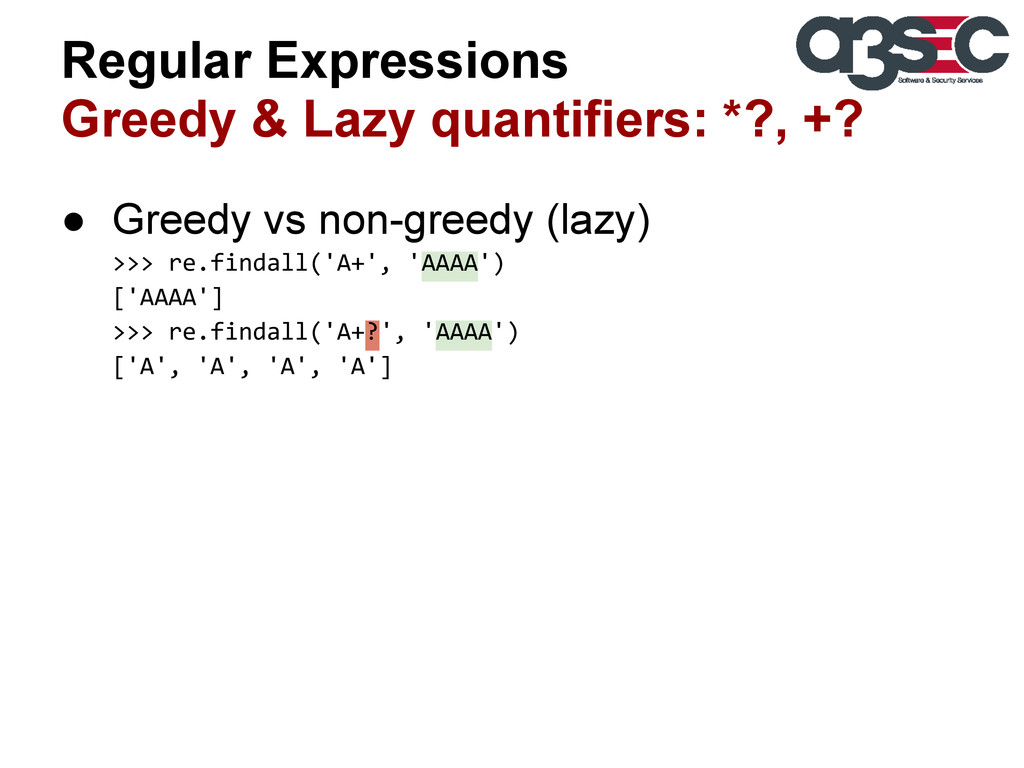{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![A3Sec web: www.a3sec.com email: [email protected] twitter: @a3sec Spain Head Office](https://files.speakerdeck.com/presentations/261dc4c0c1360130593816f50ed20d66/slide_53.jpg){kind=link}