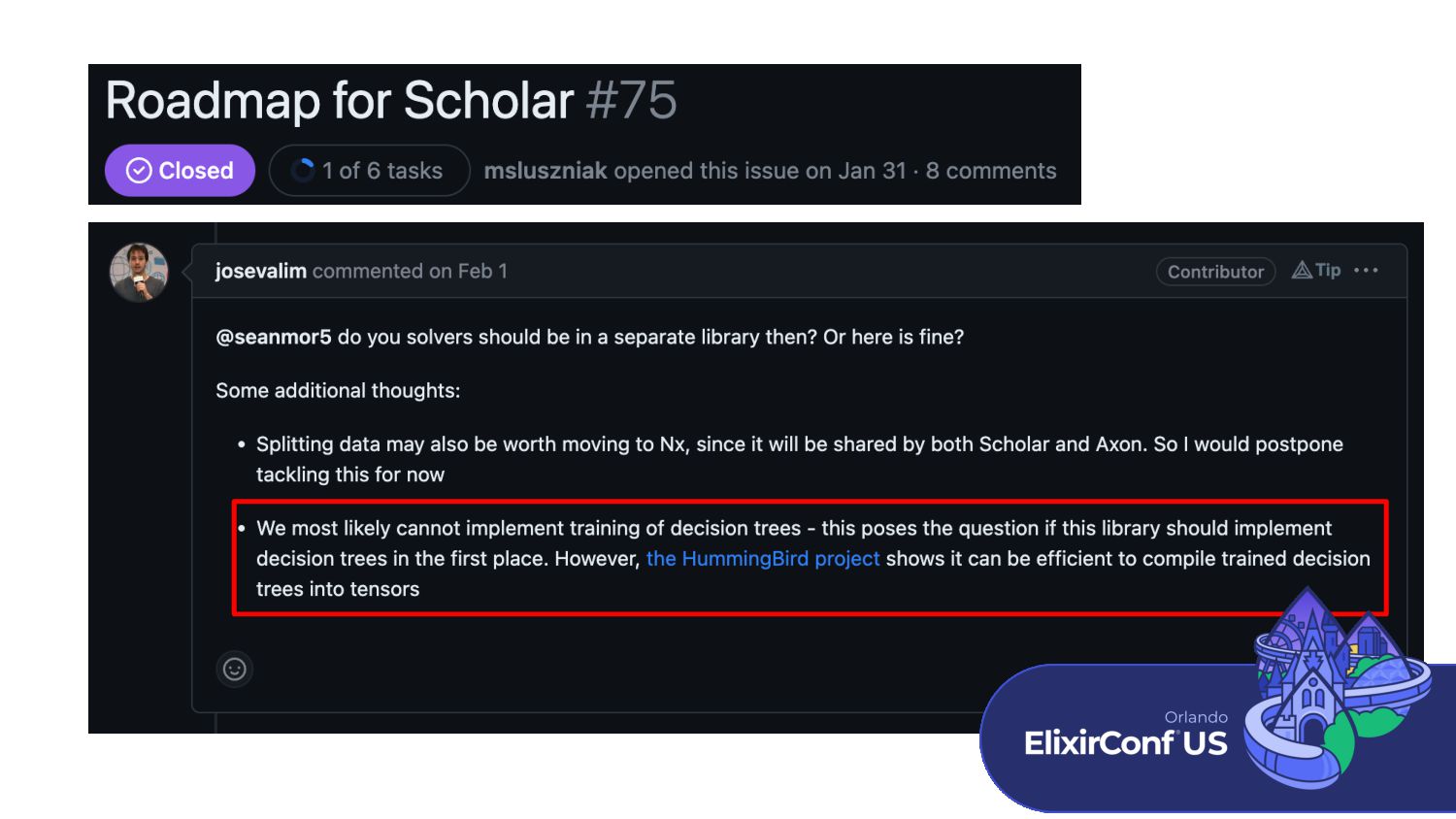
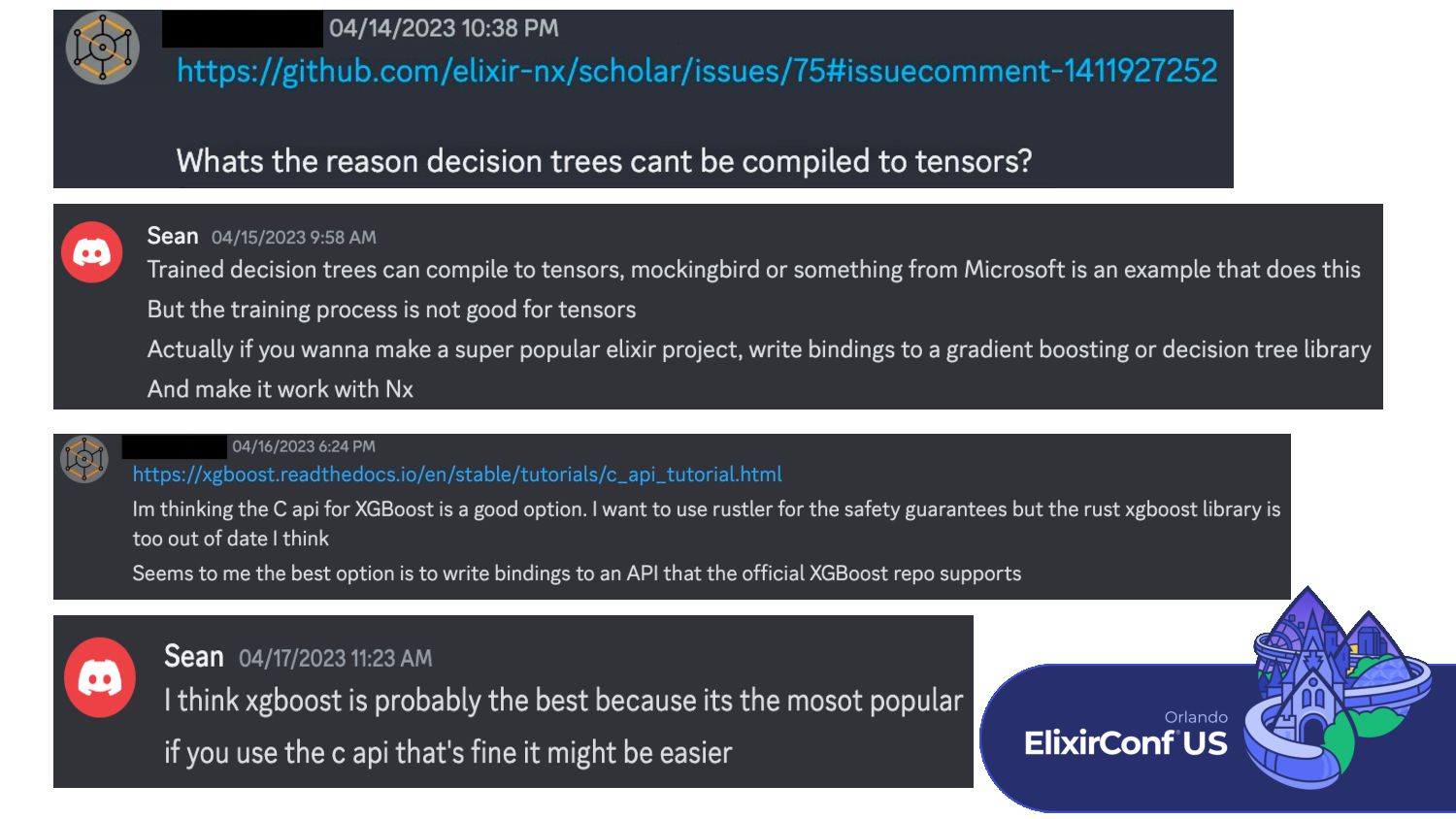
Decision Trees are an extremely popular class of supervised Machine Learning techniques that are beginner-friendly due to their intuitive and digestible design. However, they have also stood the test of time as one of the preeminent techniques for learning structured tabular data. This type of data, common among spreadsheets and relational databases, is still the gold standard used in business and enterprise environments and has now made its way to Elixir.
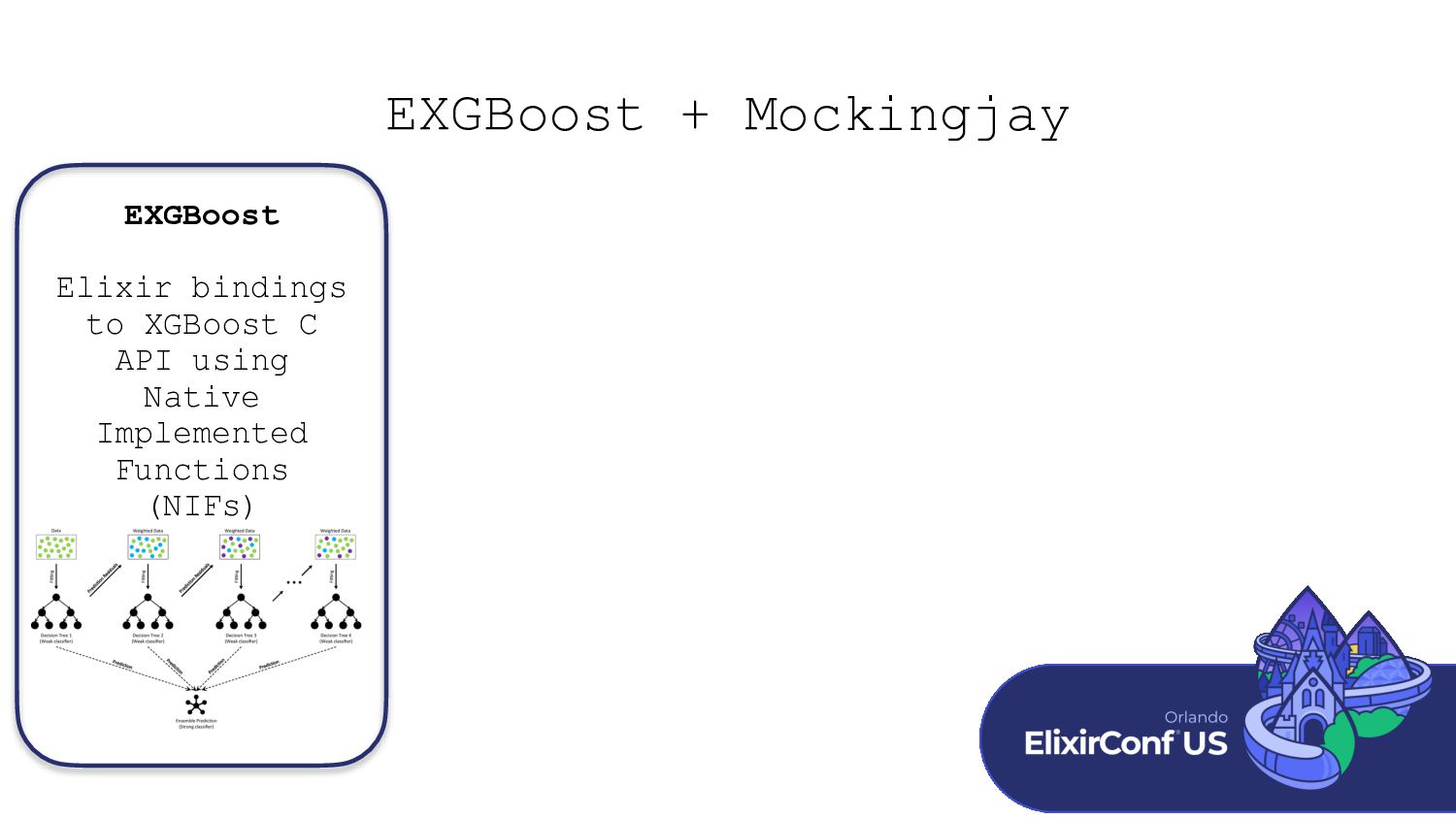
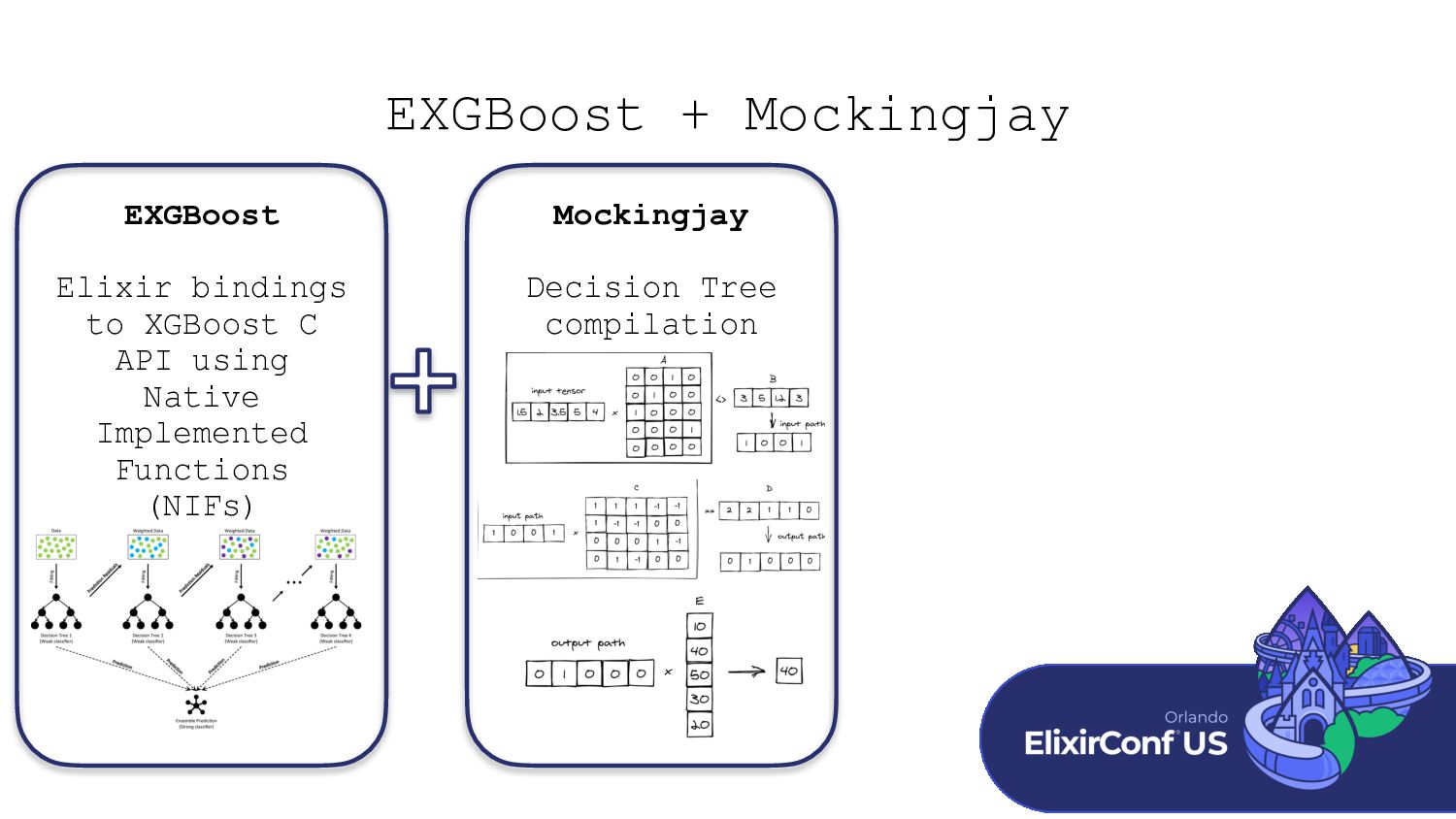
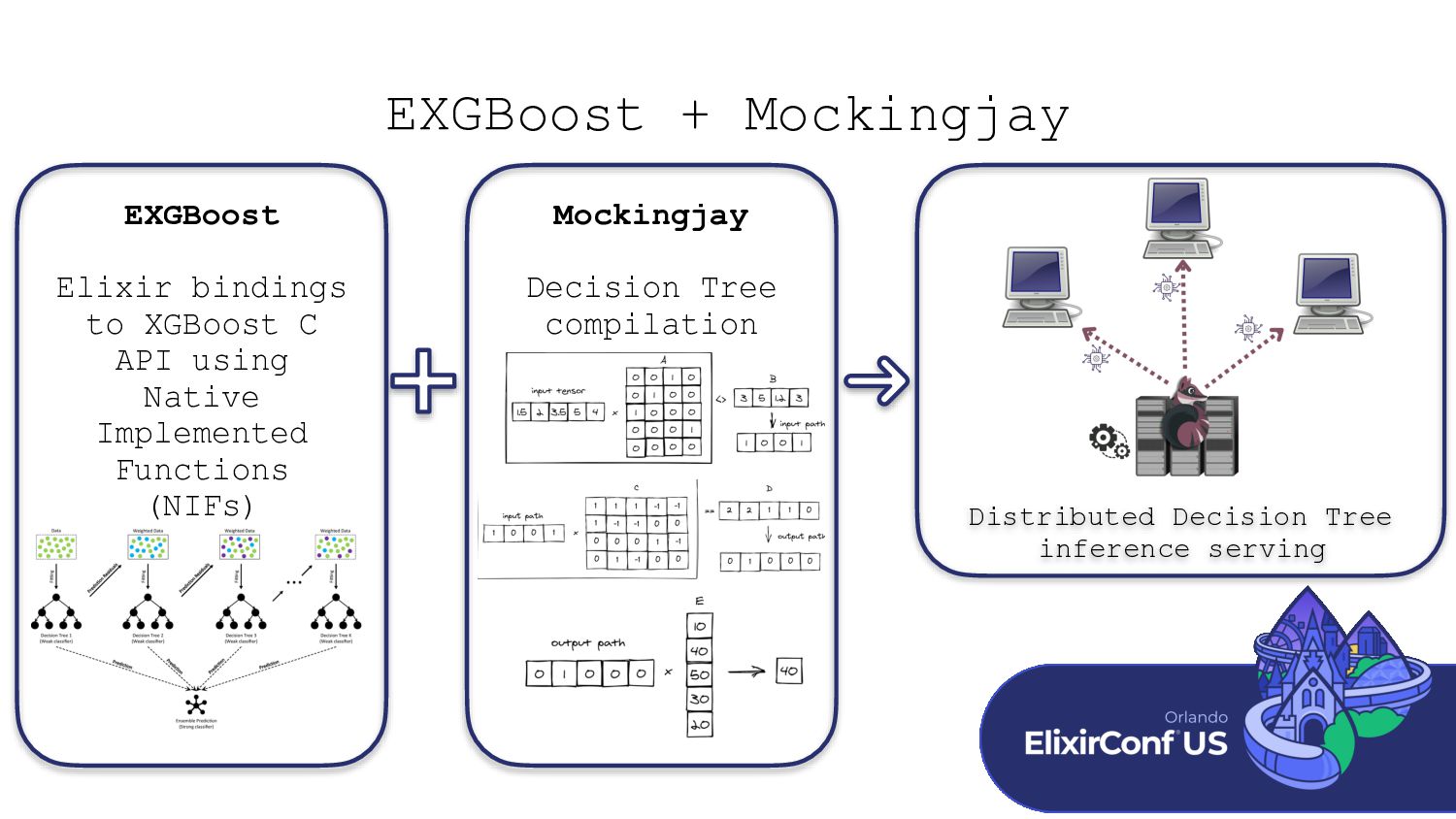
This talk introduces EXGBoost + Mockingjay, a Gradient Boosted Decision Tree library paired with a compilation library that converts trained Decision Trees to Nx tensor operations. We will discuss how both libraries work and work through some examples of using the libraries. Next, we will look at using trained Decision Trees in a scalable production environment using Nx’s Serving capability and a Phoenix web app. Finally, we will look at the future of Machine Learning in Elixir and how bringing this next class of machine learning techniques to the language benefits it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}