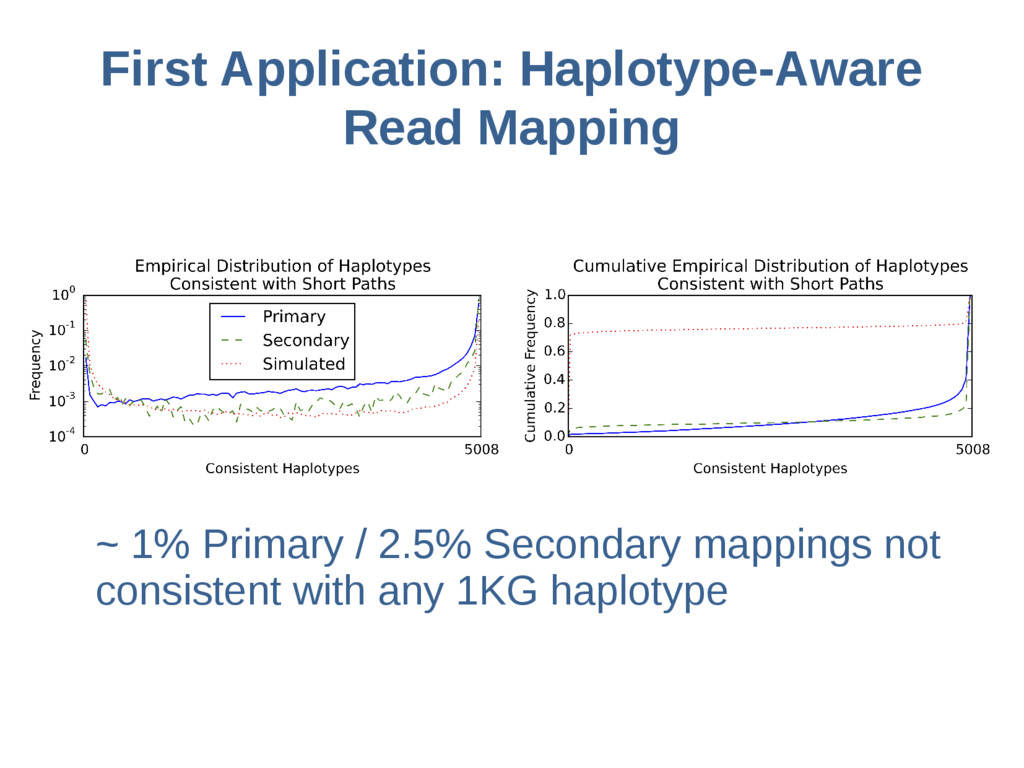
sample, per chromosome: 115k threads in 1000 Genomes Each thread visits ~1.3 million nodes on average Impractical to scan ~150 billion visits for queries
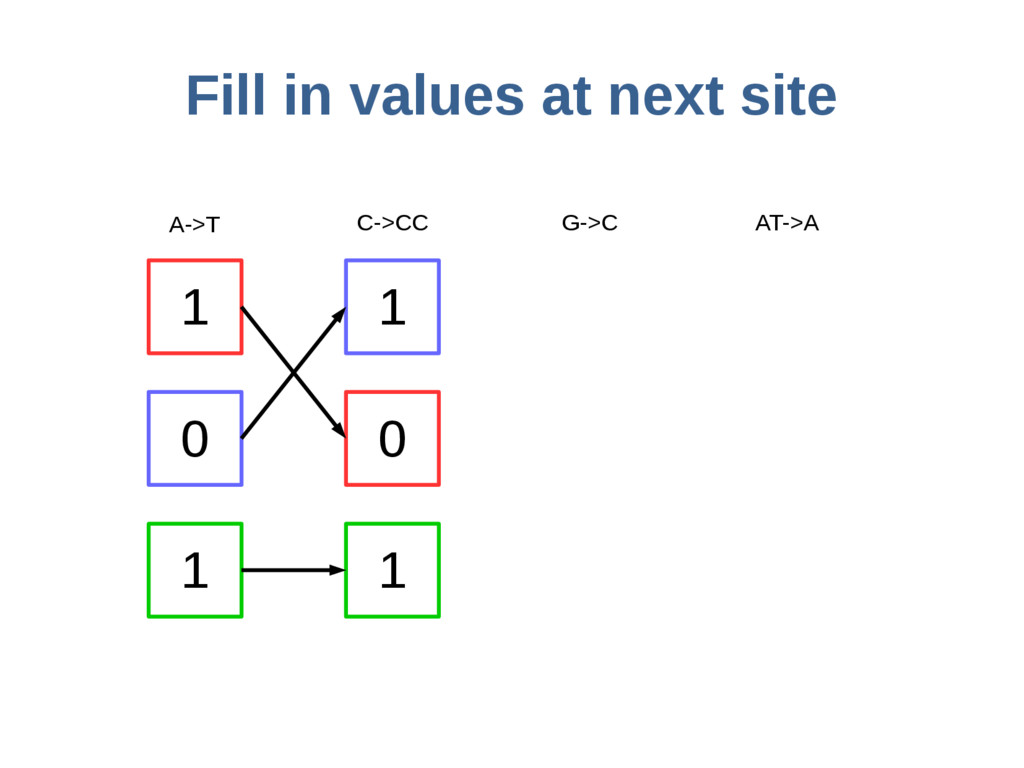
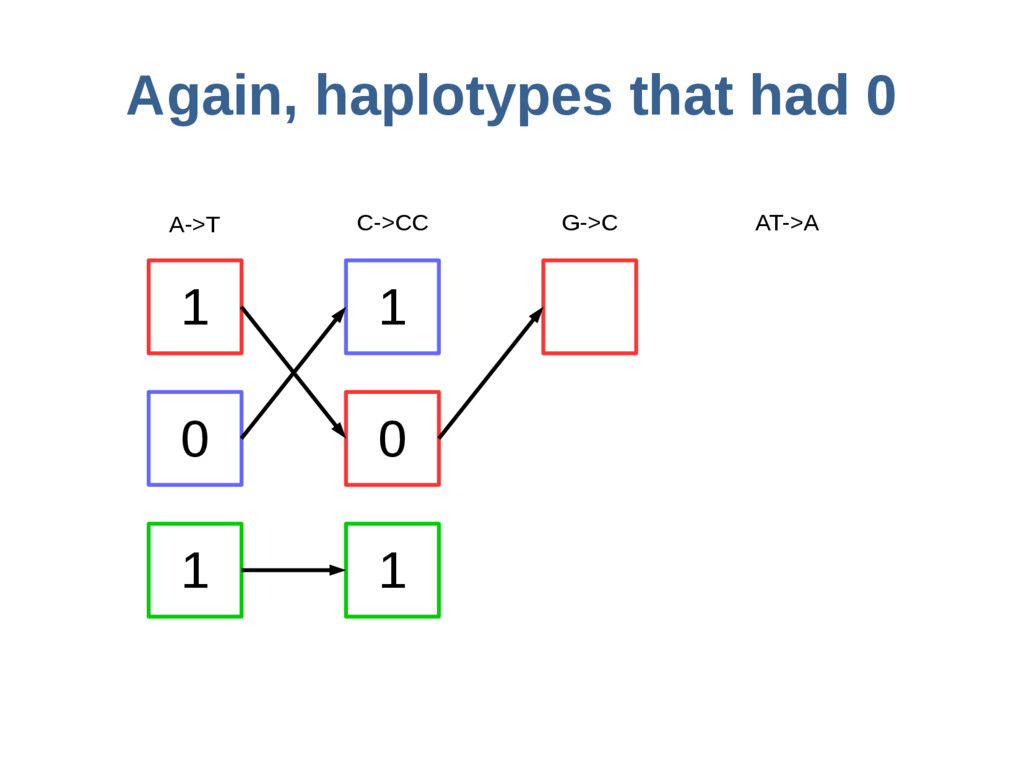
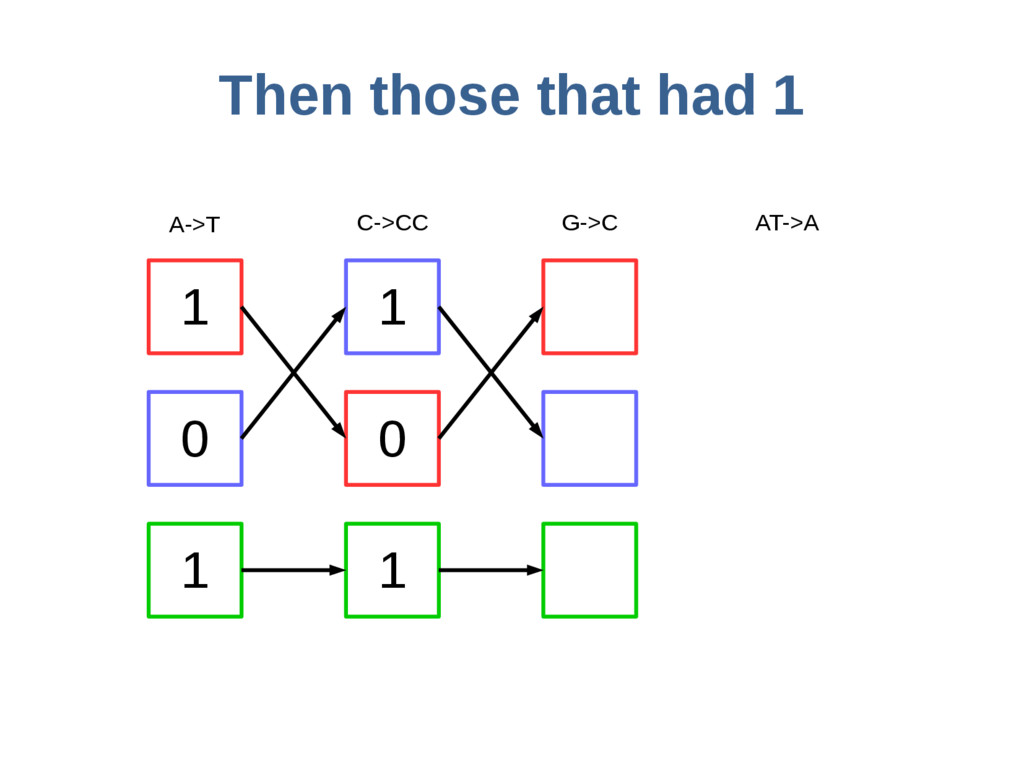
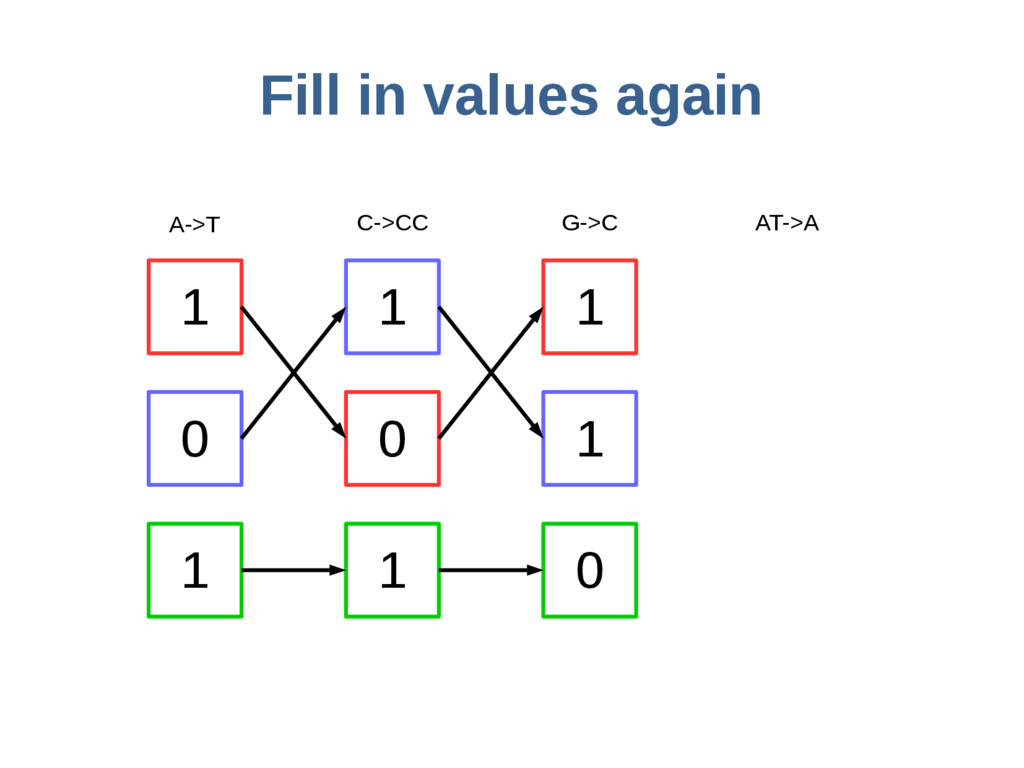
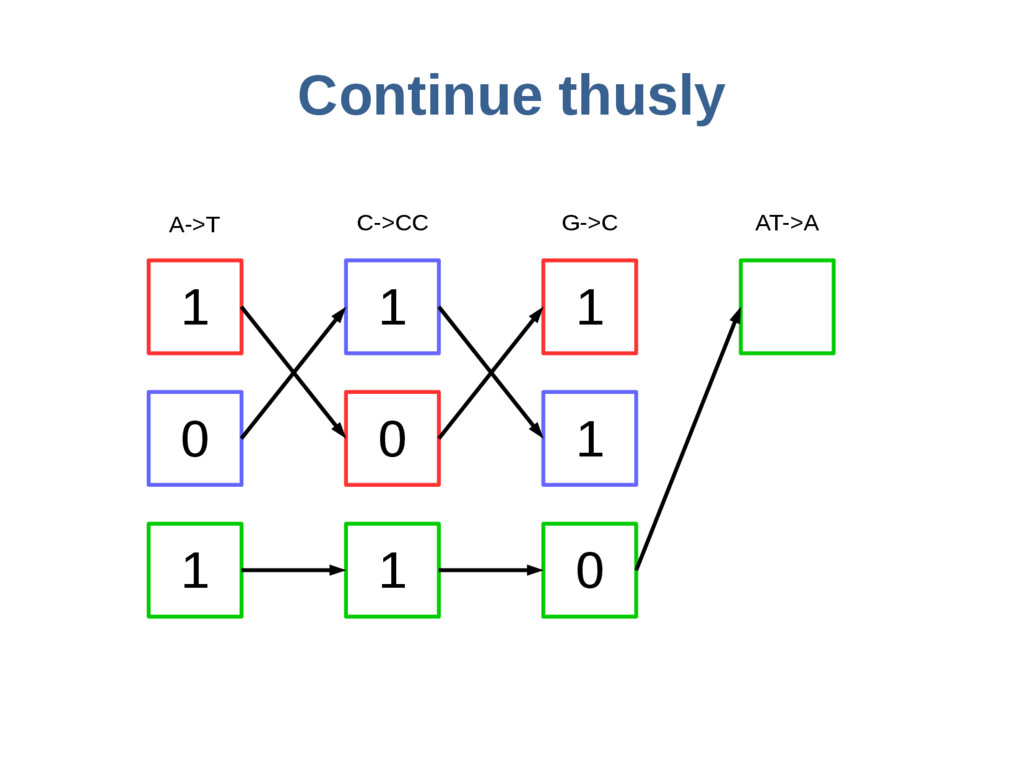
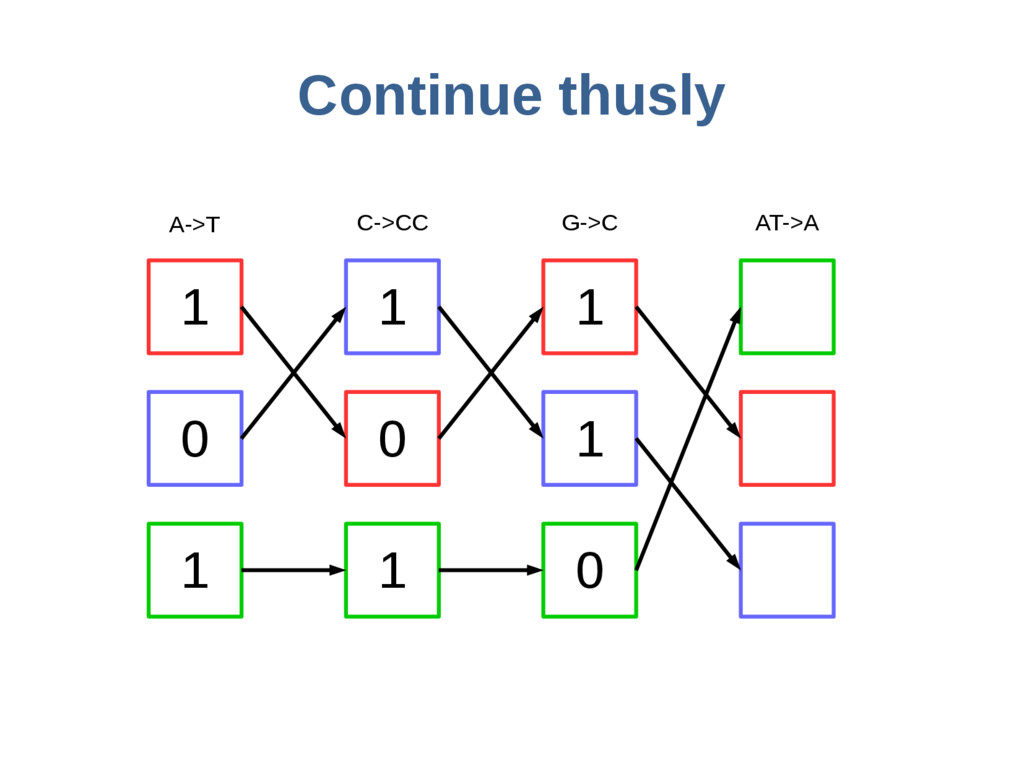
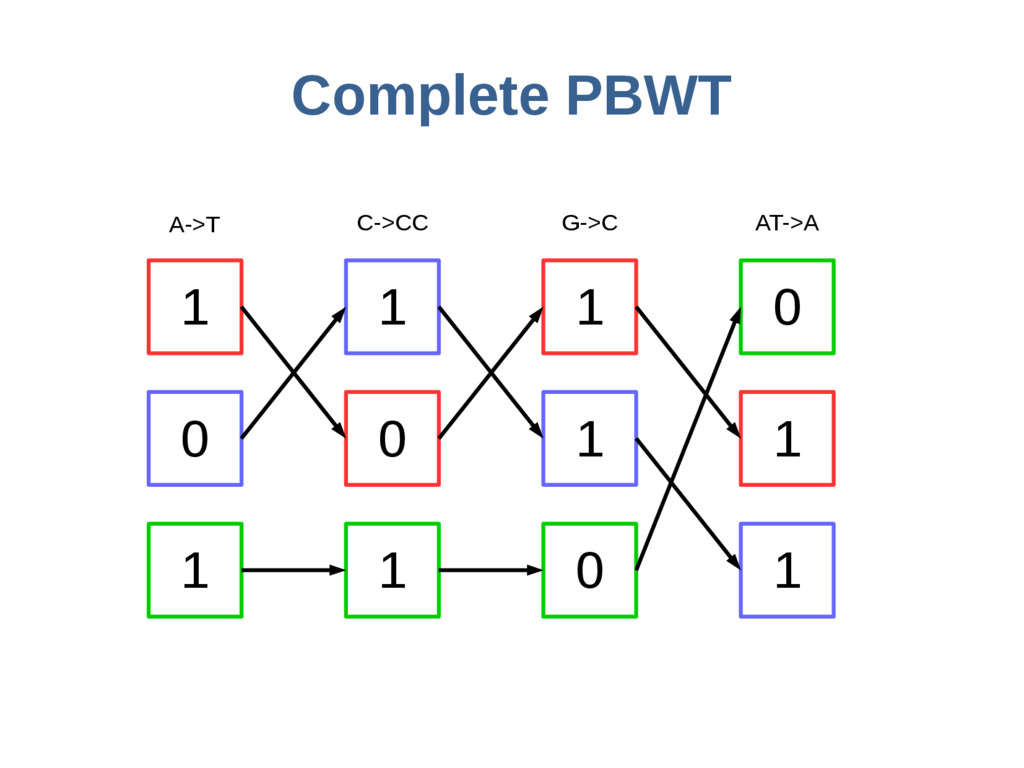
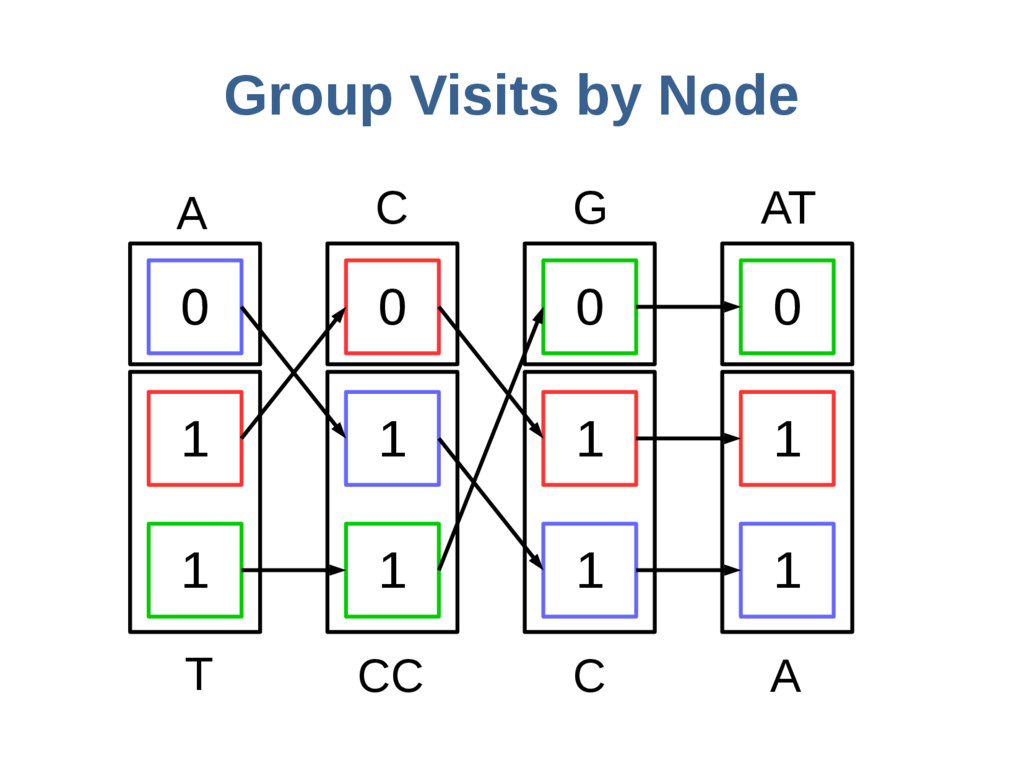
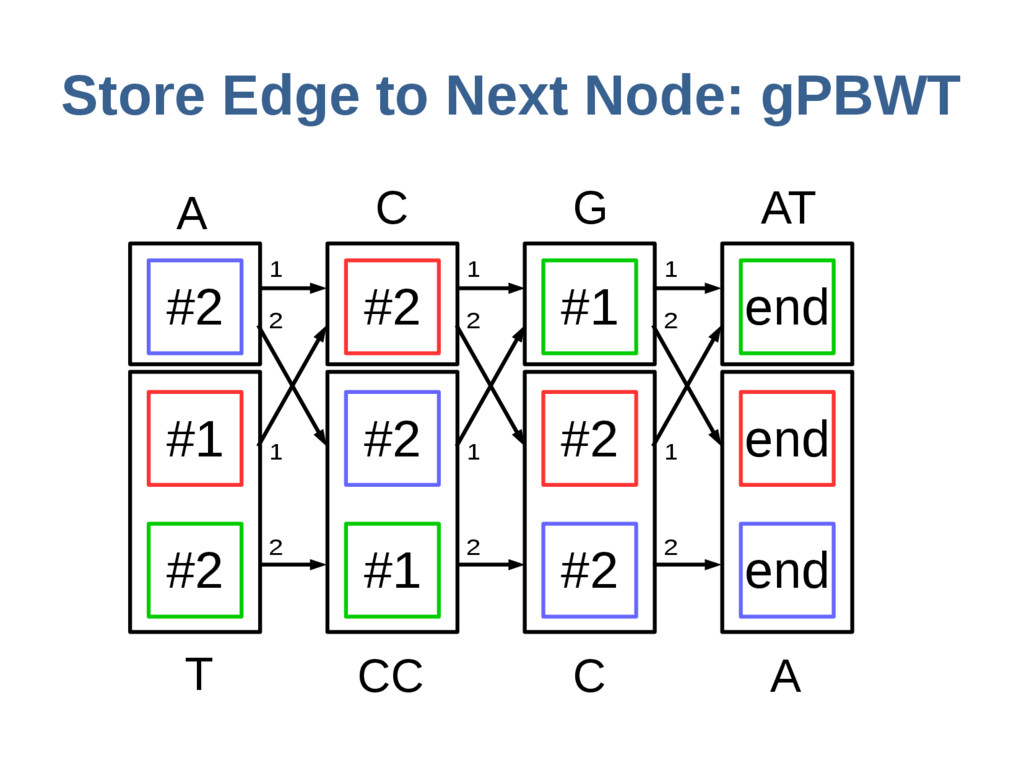
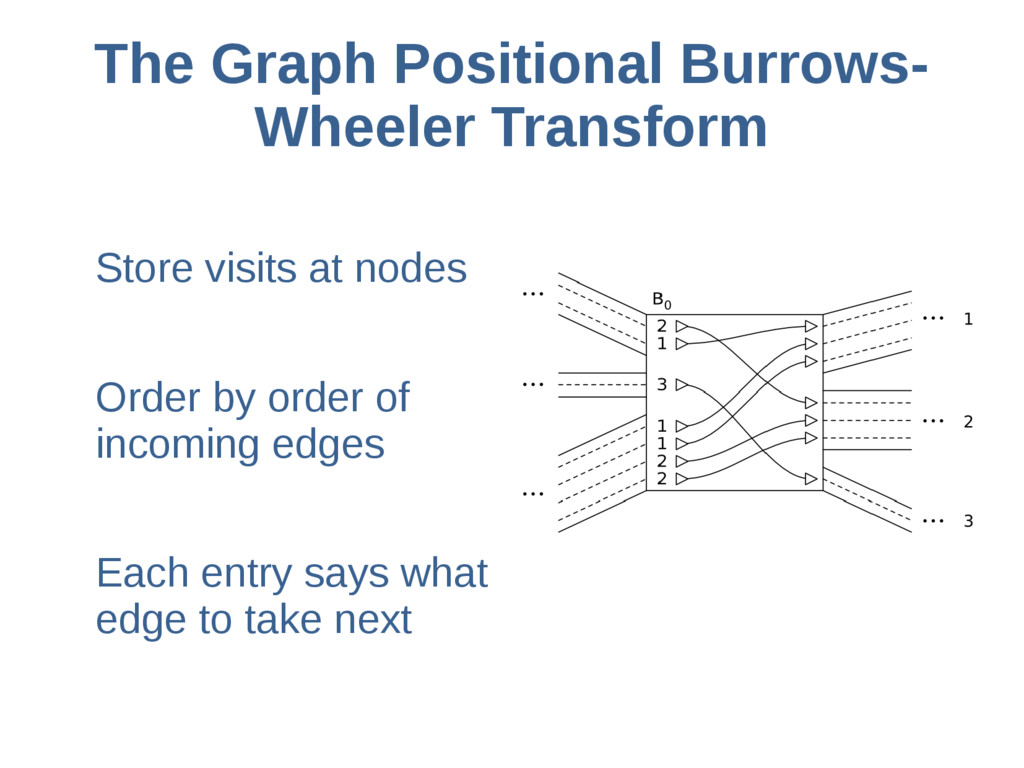
haoplotypes in small numbers of bits Represent haplotypes as sequences of bits, one per site – 0 = ref allele, 1 = alt allele At each site, stably re-order haplotypes by allele at the previous site
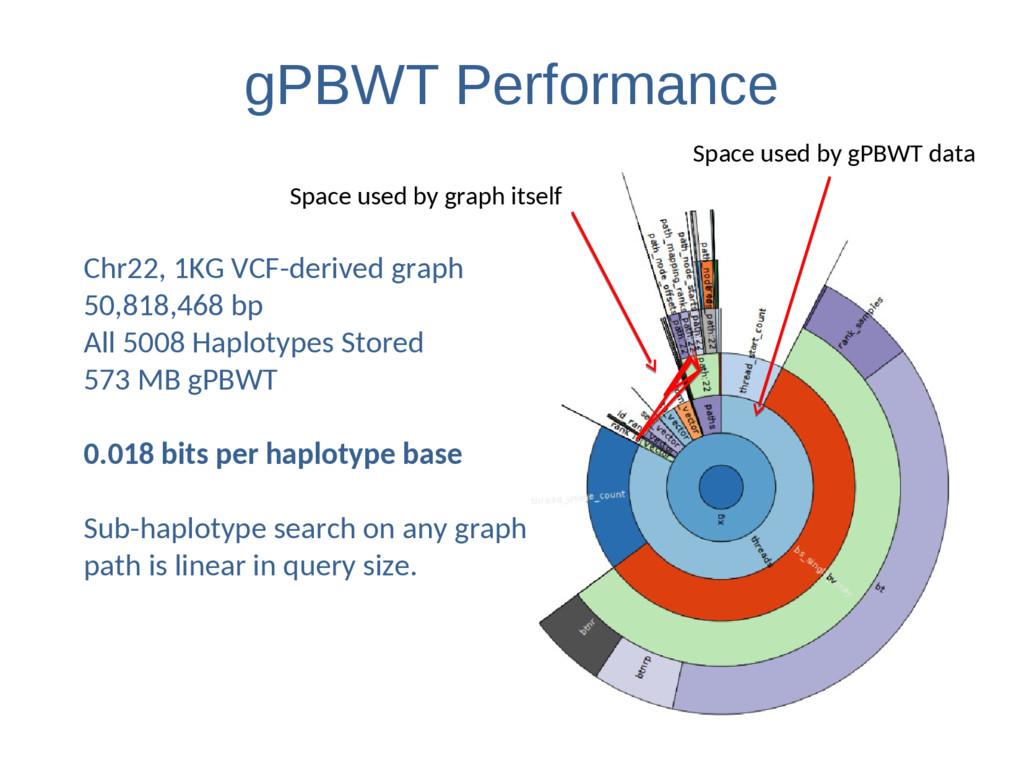
Haplotypes Stored 573 MB gPBWT 0.018 bits per haplotype base Sub-haplotype search on any graph path is linear in query size. Space used by gPBWT data Space used by graph itself
structure in a cyclic graph? How do we actually use haplotype path queries in alignment? How do we attach this to a linked-data framework or RDF interface?
{kind=link}
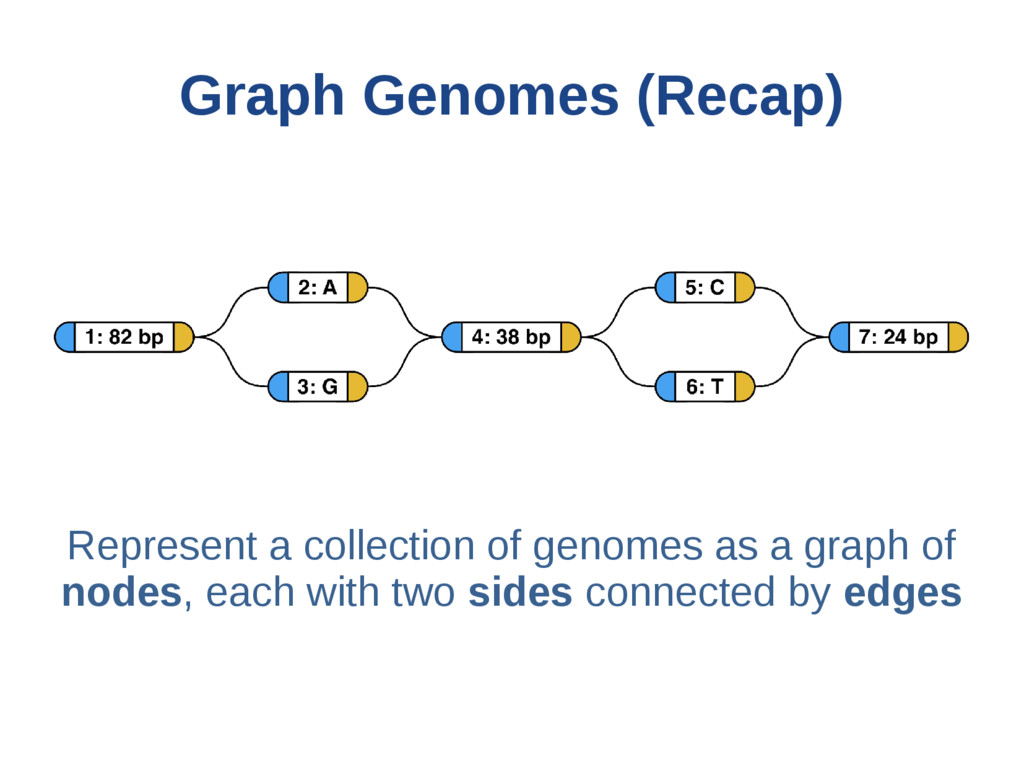{kind=link}
{kind=link}
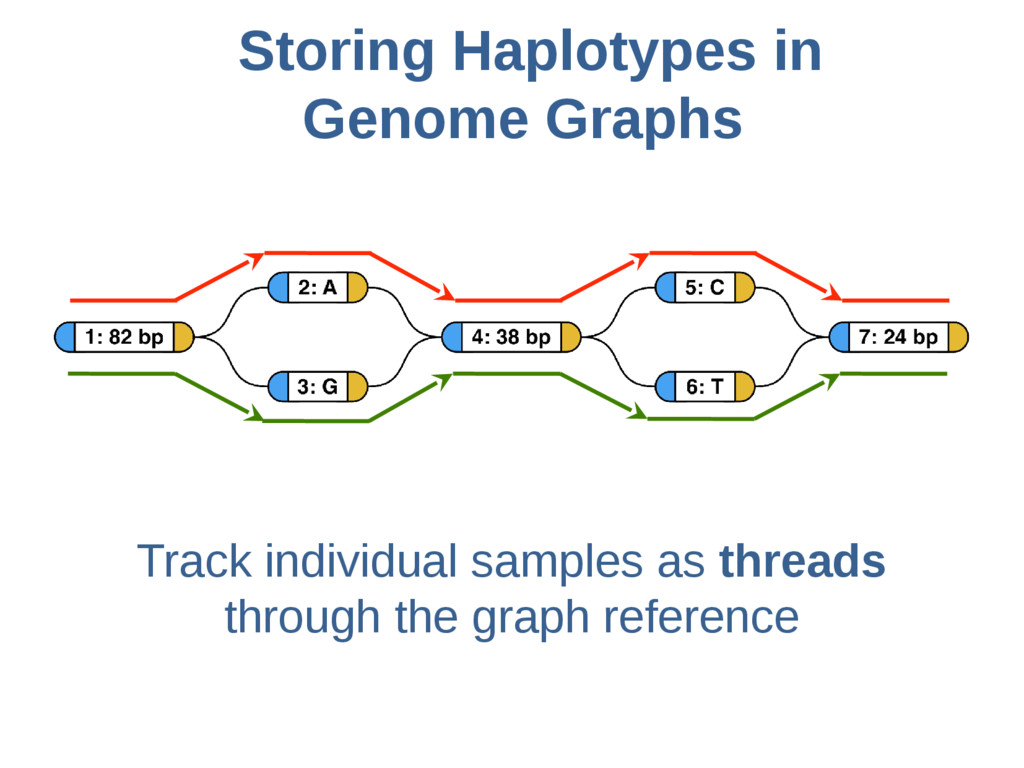{kind=link}
{kind=link}
{kind=link}
{kind=link}
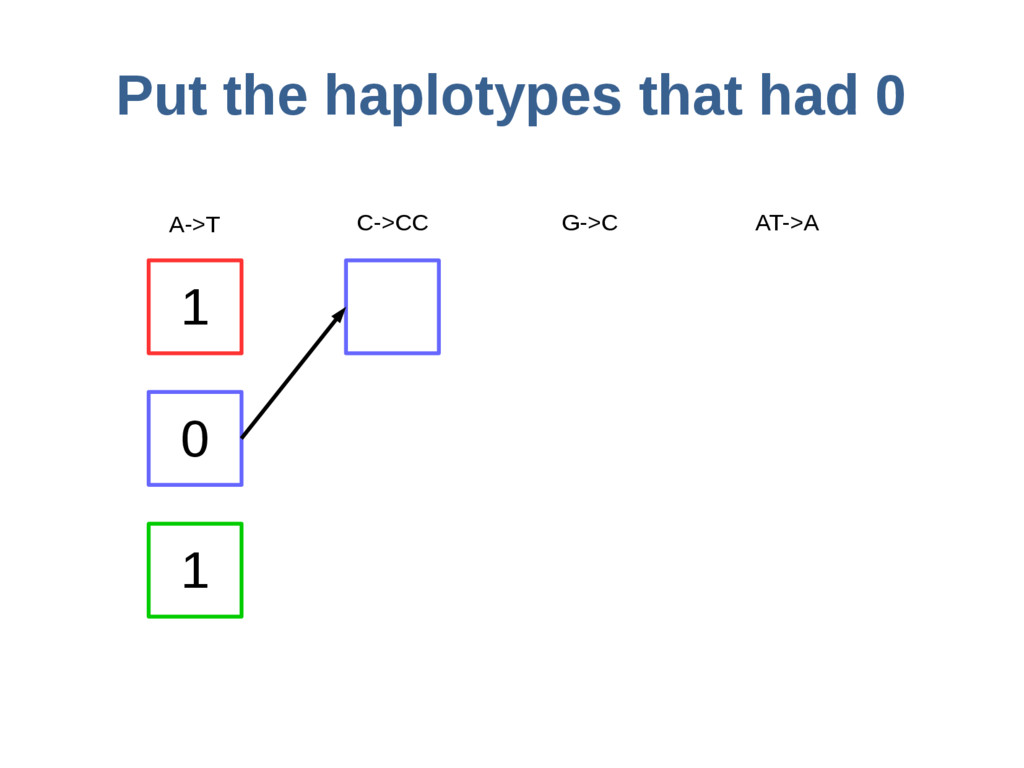{kind=link}
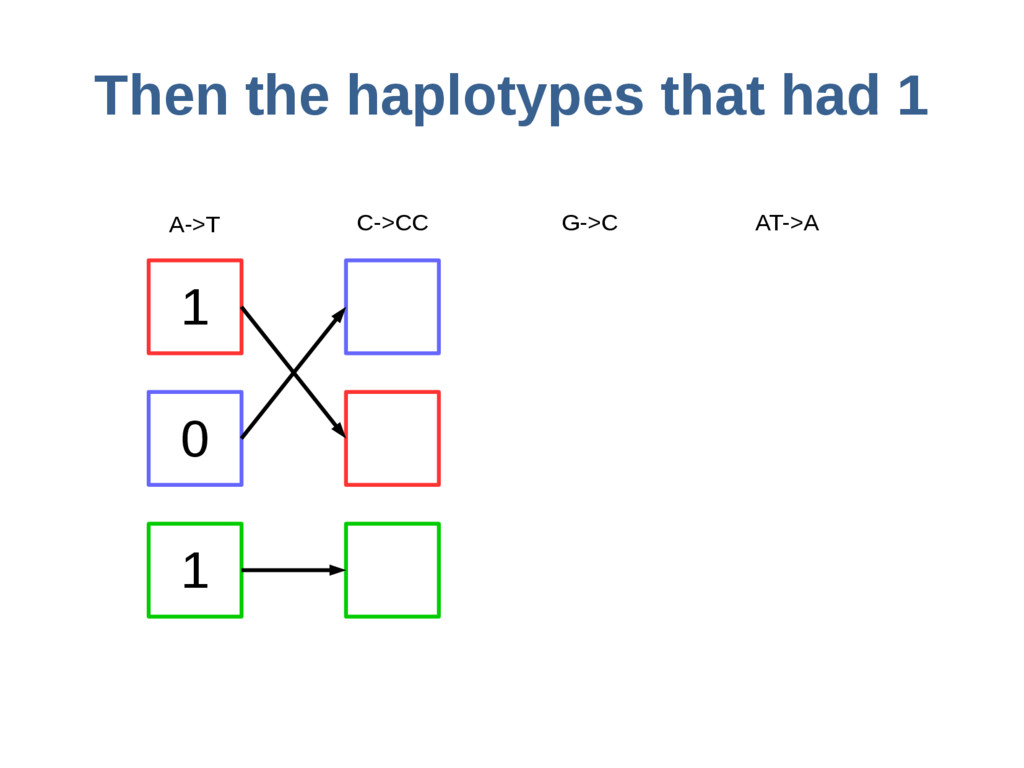{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}