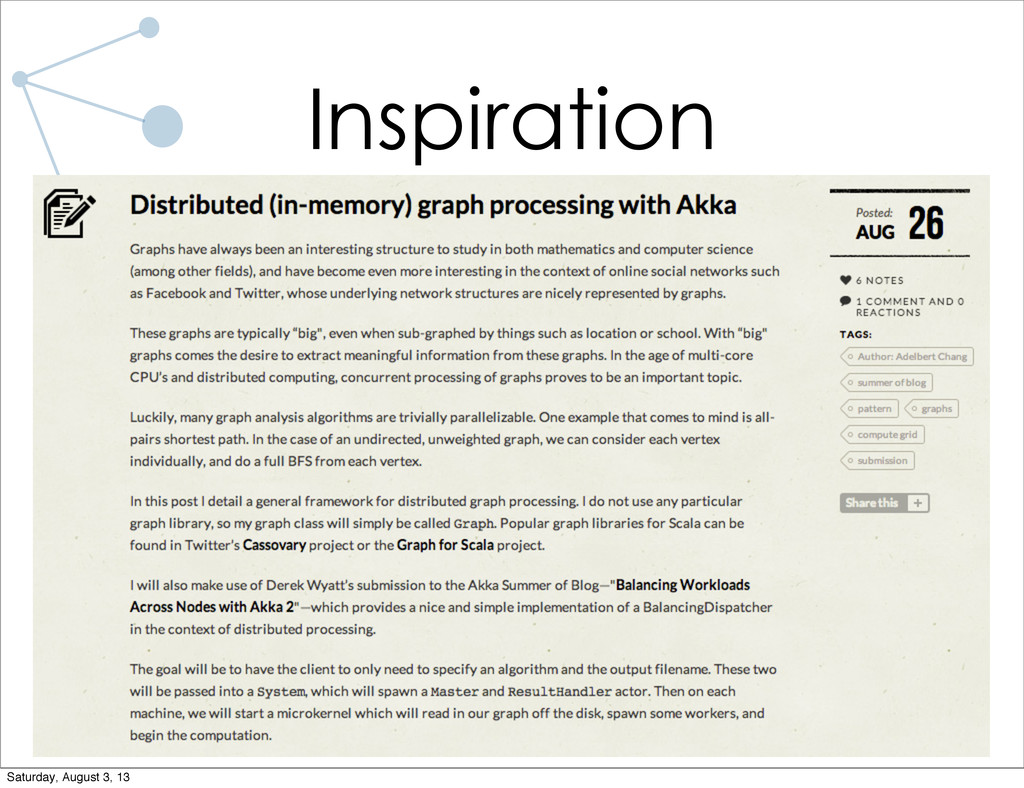
In recent years, the boom of online social networks such as Facebook and Twitter have presented several interesting problems, especially in regards to their massive underlying graph structures. With such a large and rich dataset, it is clearly beneficial to leverage these graphs to power features like friendship recommendation. However, dealing with so much data in a scalable manner is difficult, and considerable amounts of engineering and research efforts have gone into solving this problem, manifesting into systems such as Pregel and graph databases (e.g. Neo4J).
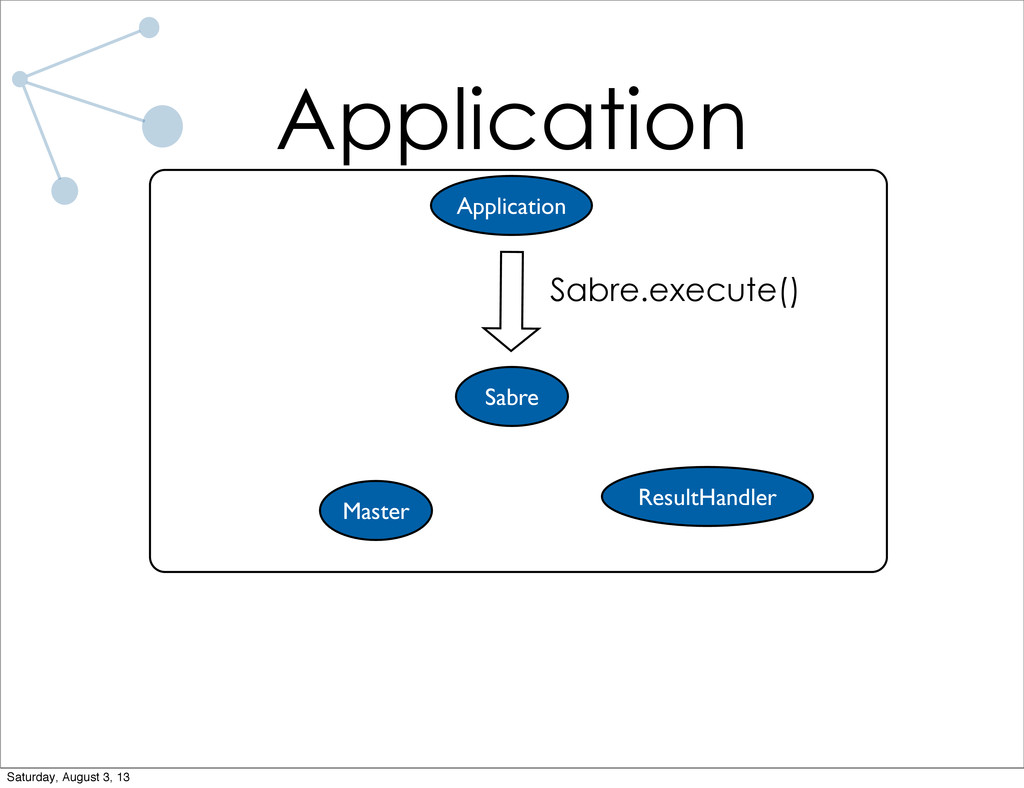
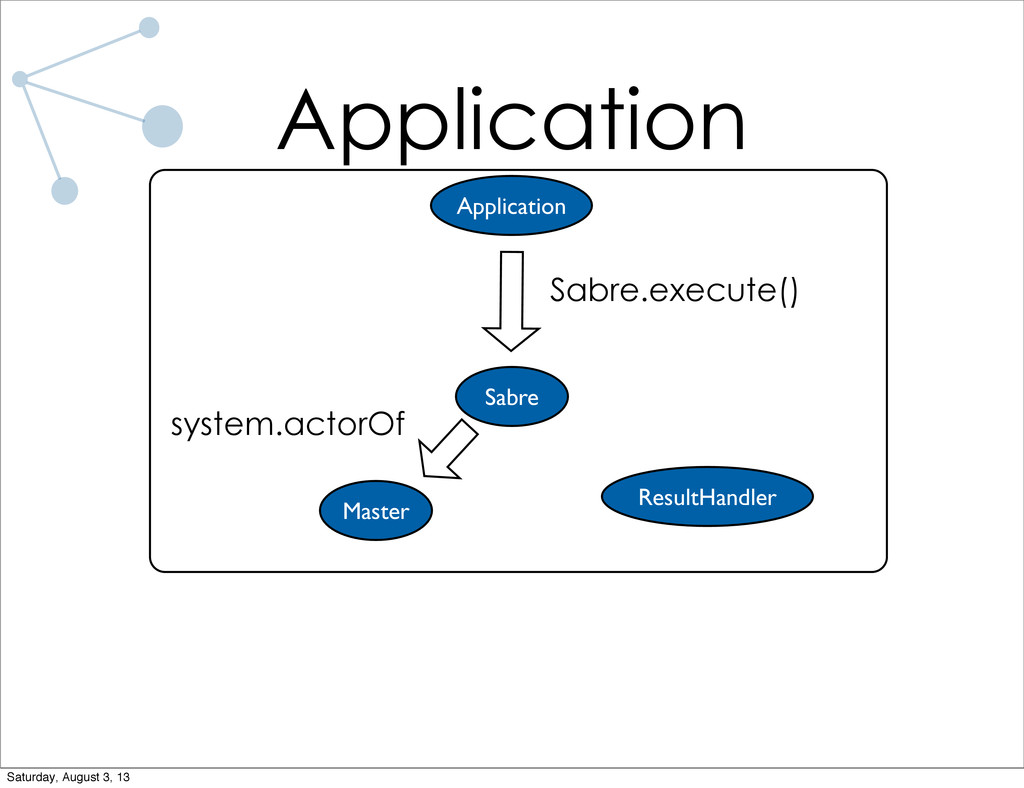
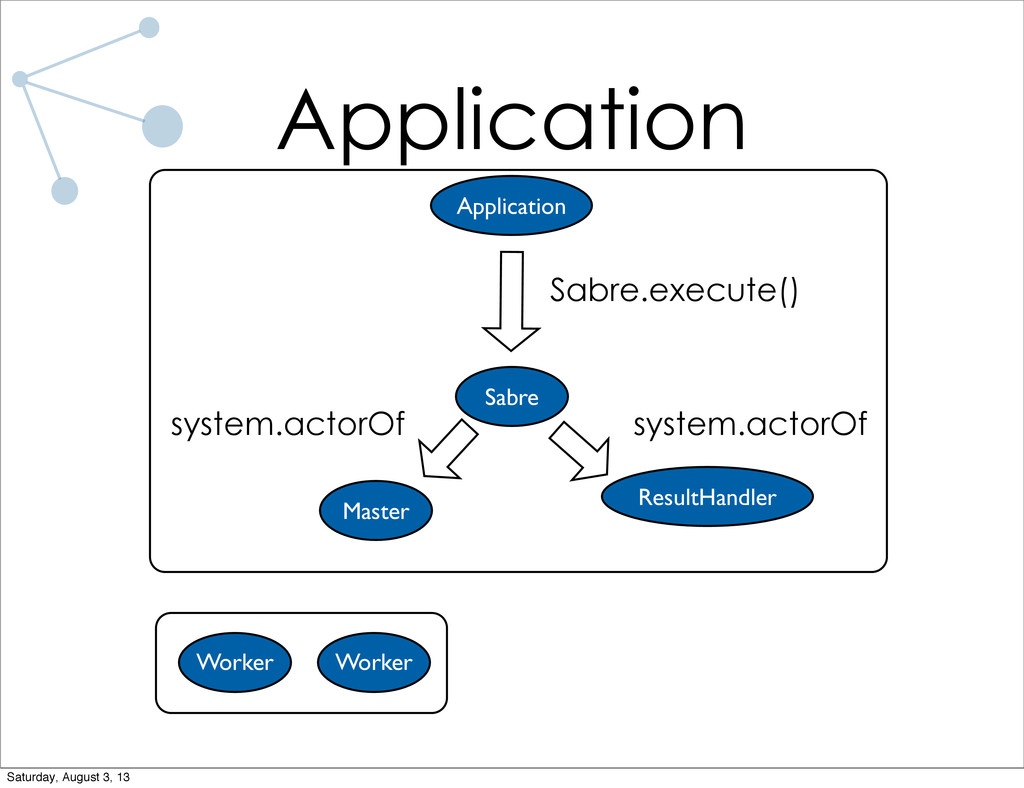
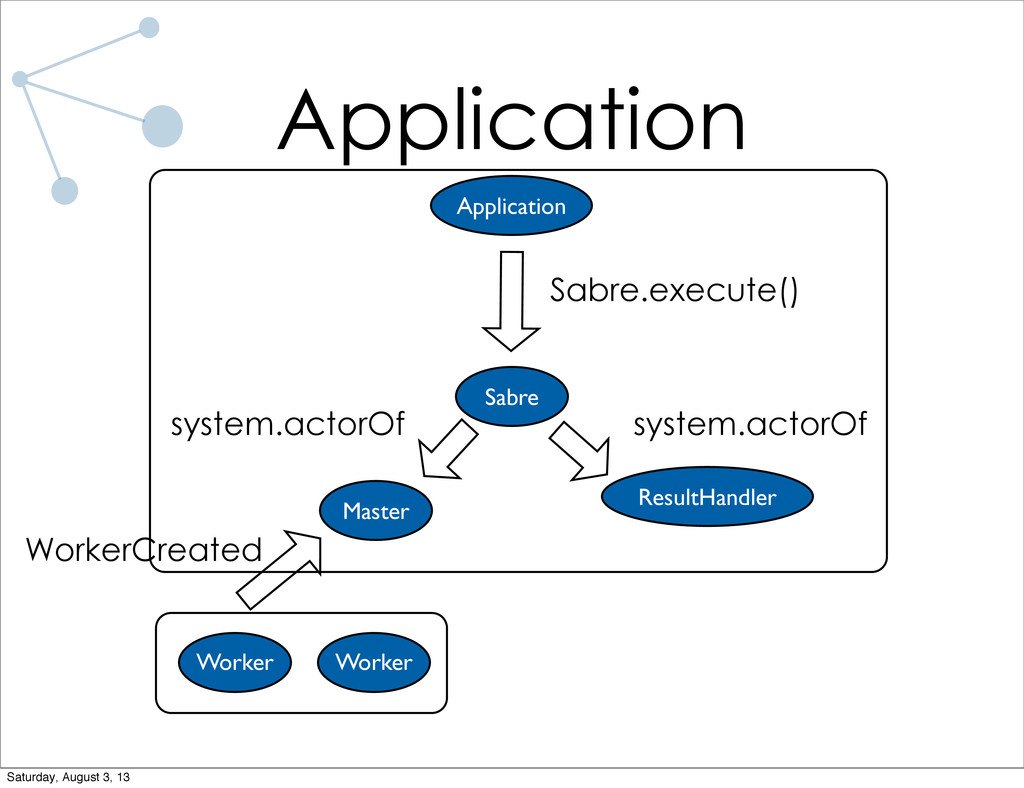
As a research assistant during the school year at UC Santa Barbara, I have implemented a distributed graph processing system for use on the lab cluster. The system is designed specifically for trivially parallelizable graph algorithms (which most algorithms I've run in the lab are). Lots of code will be shown, both of the system and of applications written using the system. I will also talk briefly about what I have planned for future iterations of the system.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![EOF @adelbertchang [email protected] Saturday, August 3, 13](https://files.speakerdeck.com/presentations/72290fd0ded1013071776e2d3649562d/slide_102.jpg){kind=link}
![EOF @adelbertchang [email protected] Questions? Saturday, August 3, 13](https://files.speakerdeck.com/presentations/72290fd0ded1013071776e2d3649562d/slide_103.jpg){kind=link}