Presentation given at Web Directions Engineering AI Sydney
Agenda included elaborating my colorful headlines:
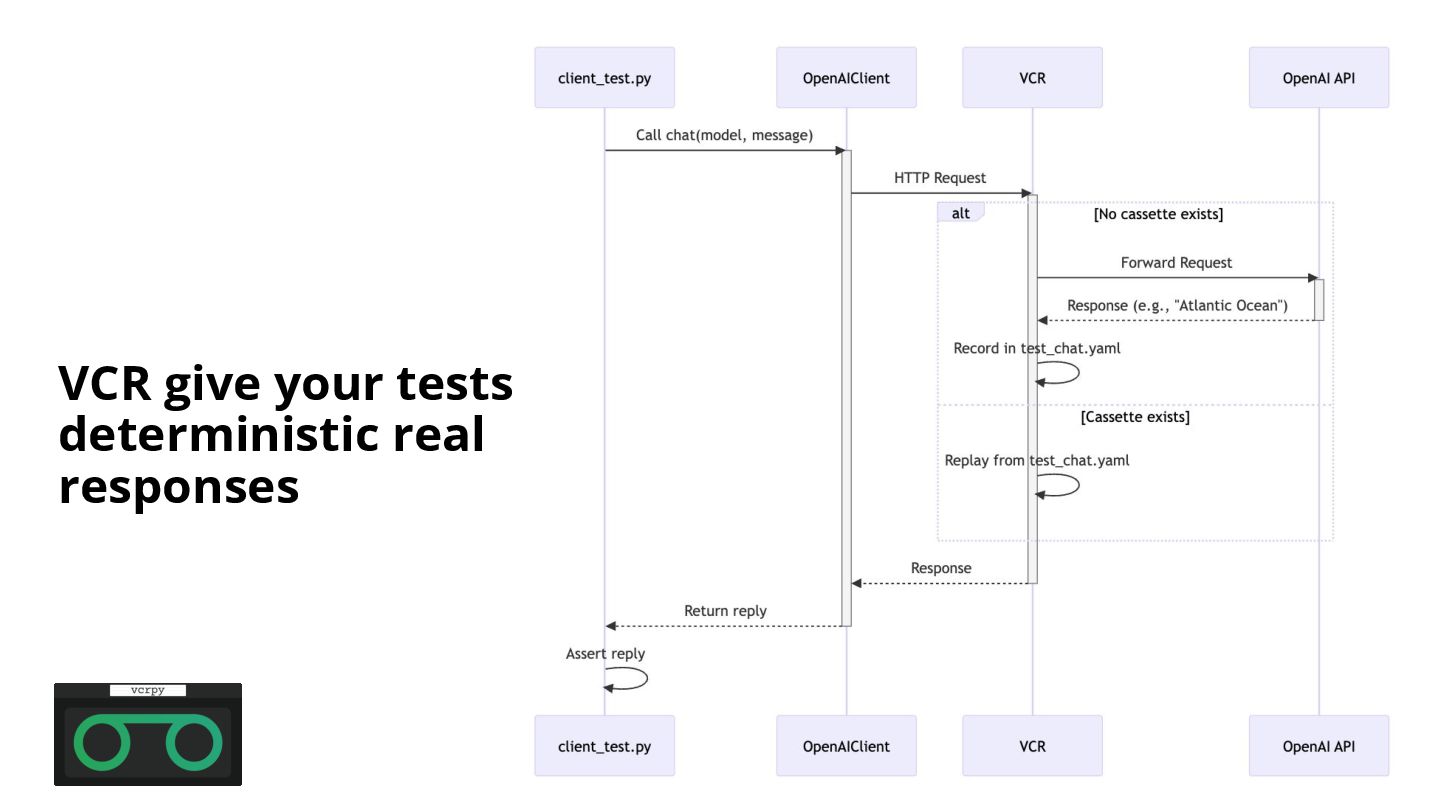
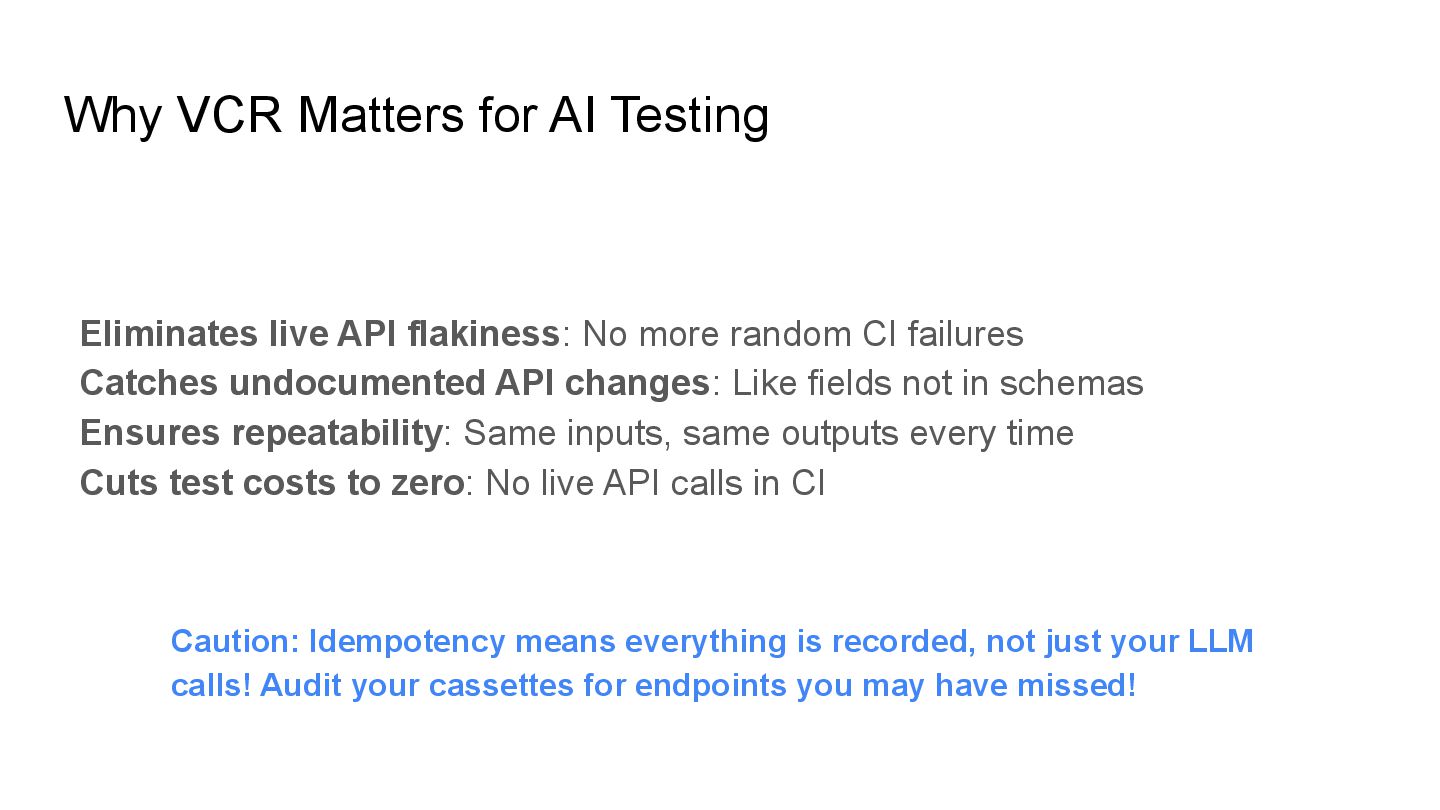
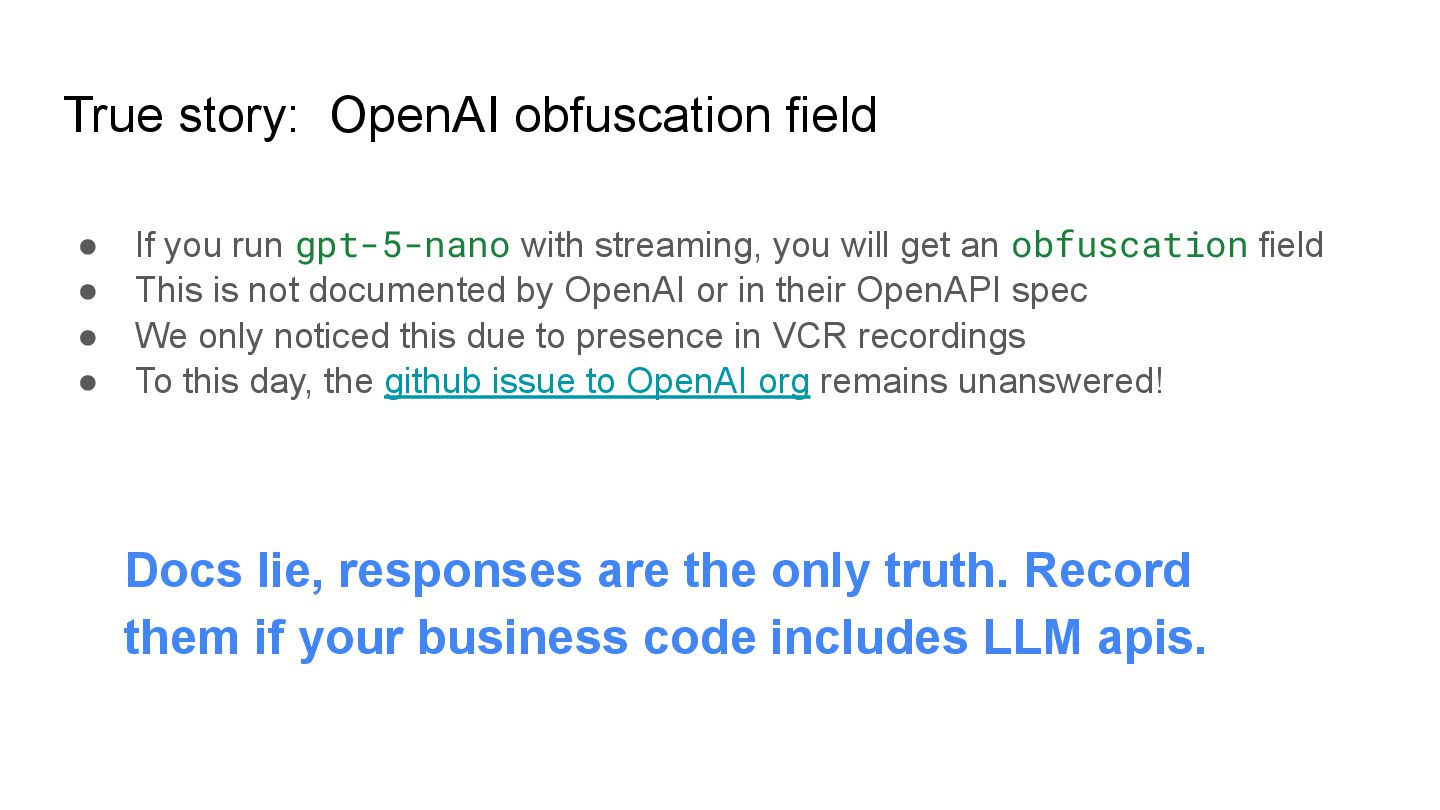
Flaky CI & YOLO Clouds: Stabilize your tests with VCR (Envoy AI Gateway)
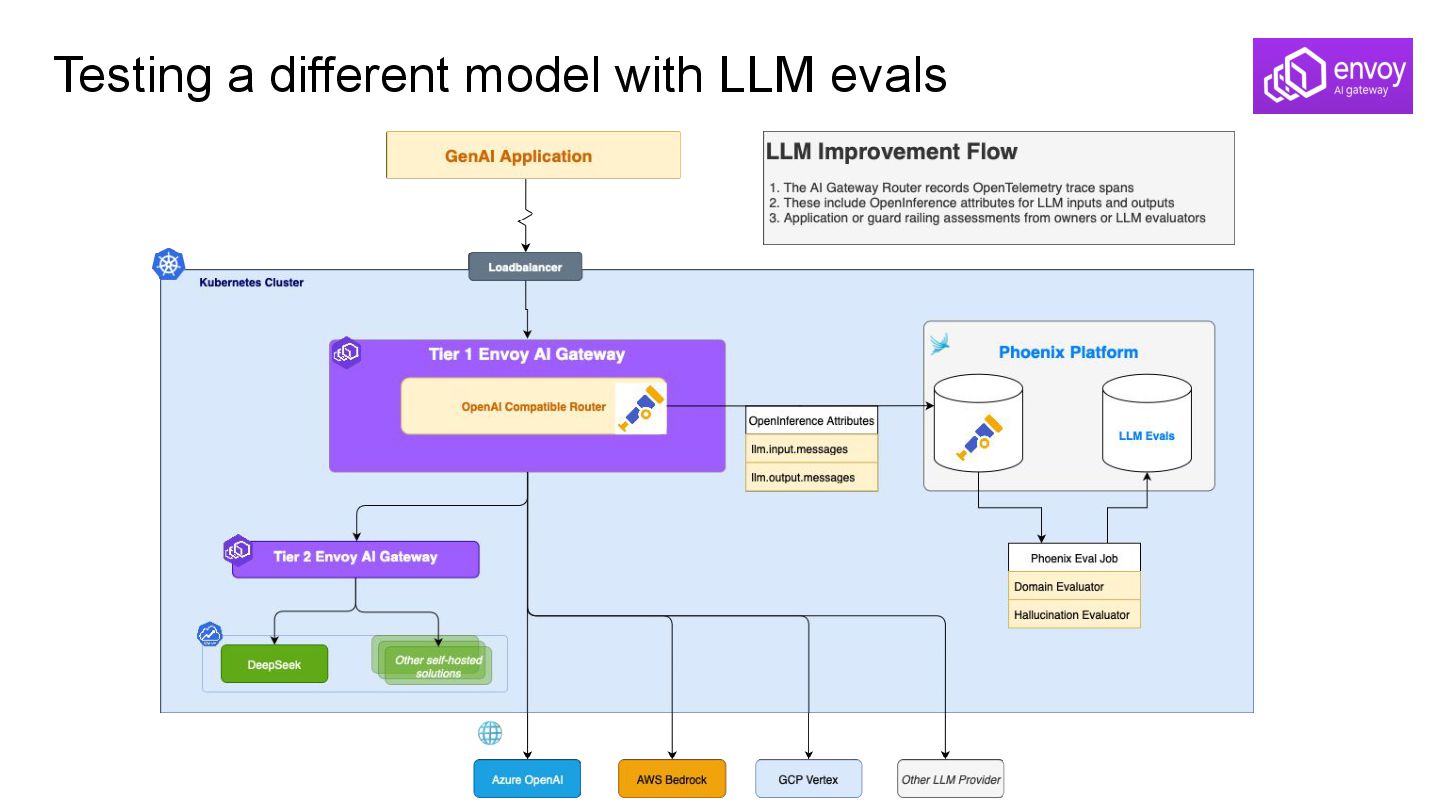
Rage/FOMO Choices: Model agility via LLM evals (Arize Phoenix)
Complex Agentic Scenarios: Goose recipes & terminal-bench
Takeaways: What you can do with all this
https://webdirections.org/eng-ai/schedule.php
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
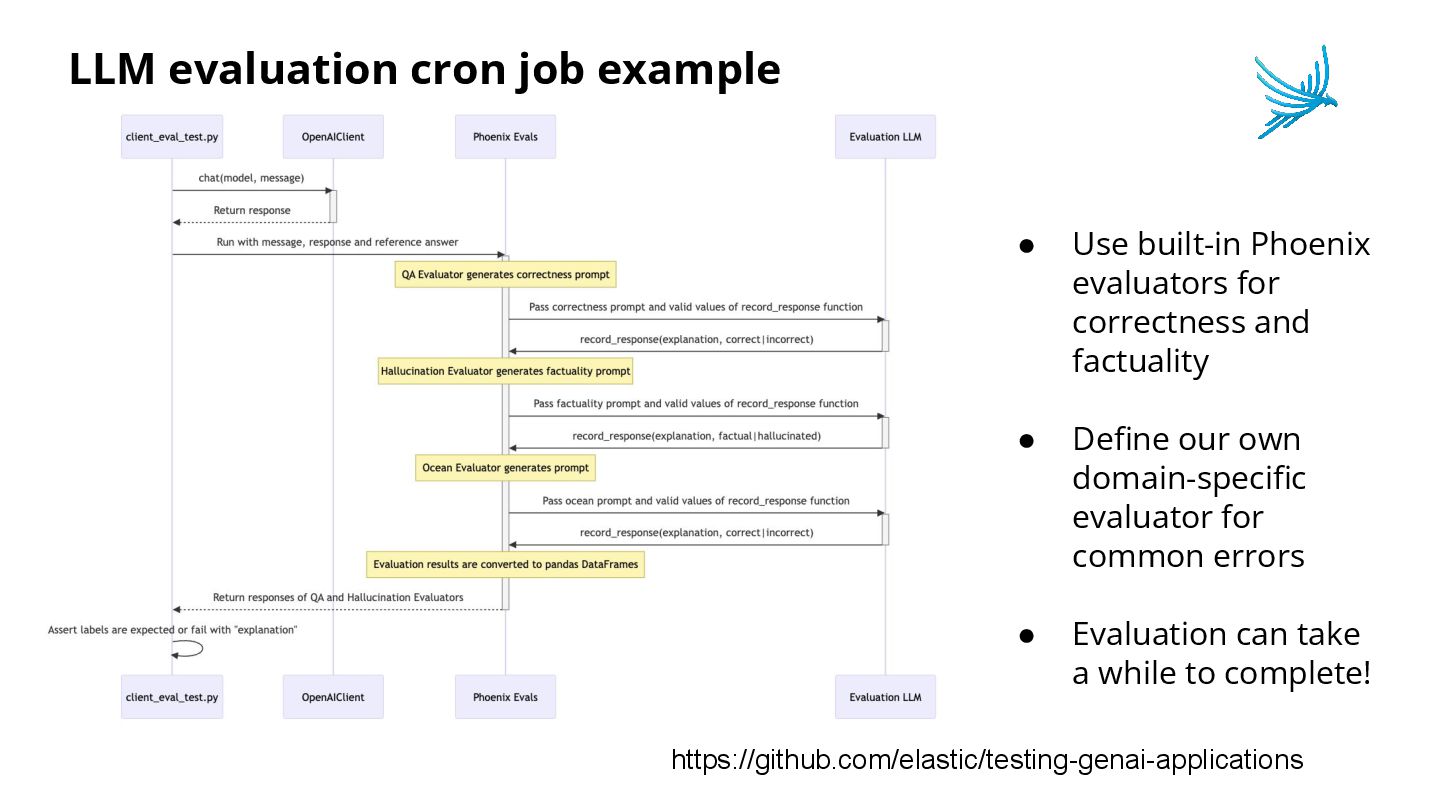{kind=link}
{kind=link}
{kind=link}
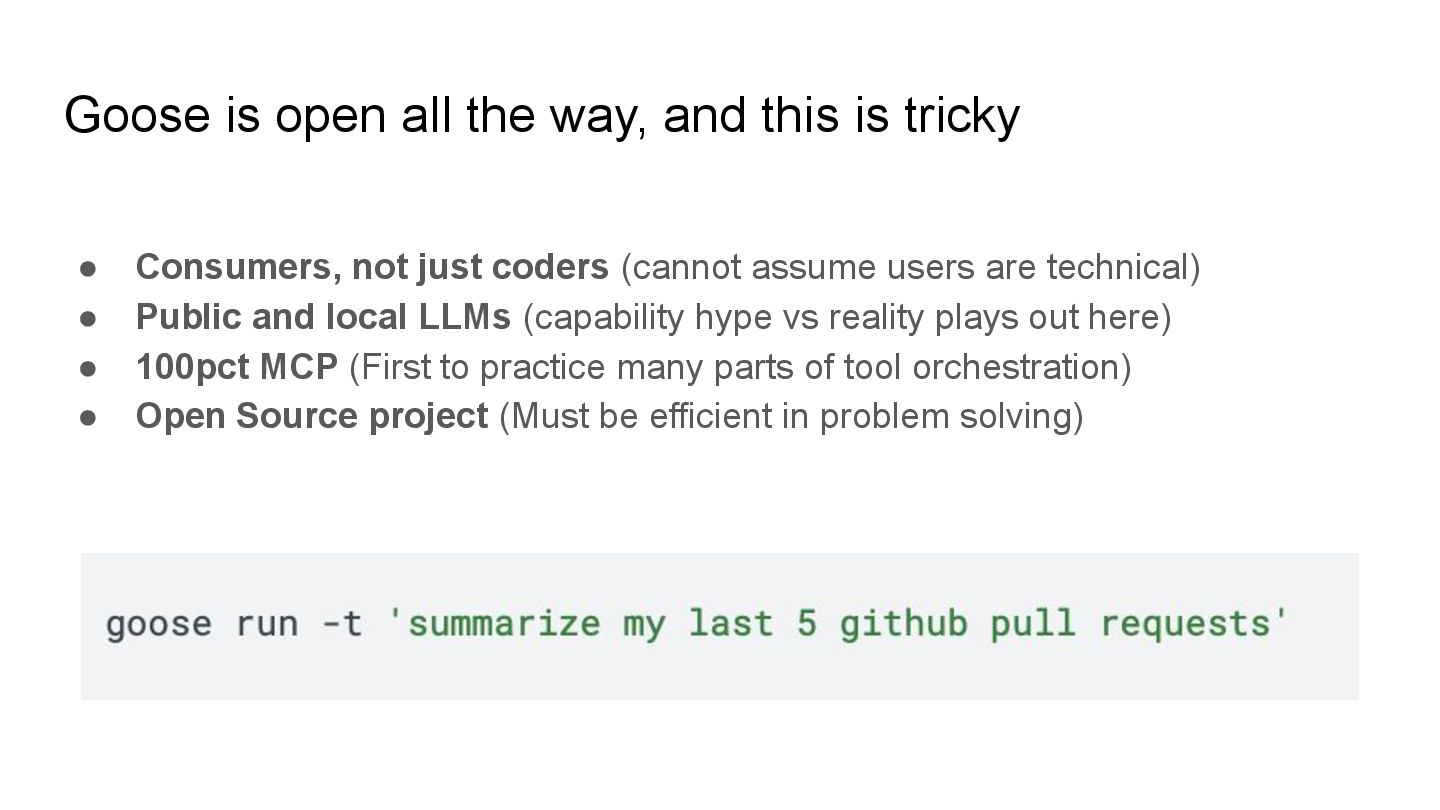{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
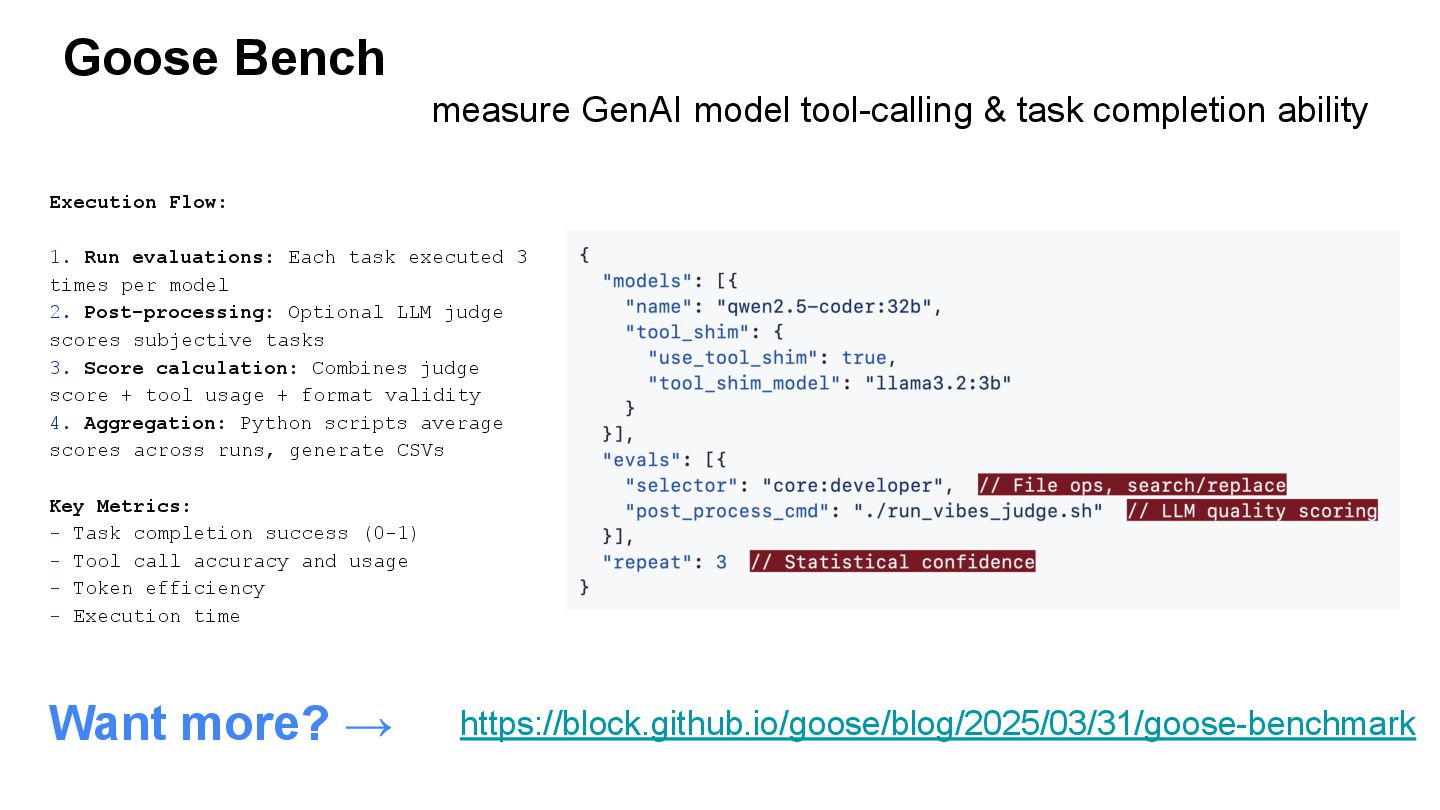{kind=link}
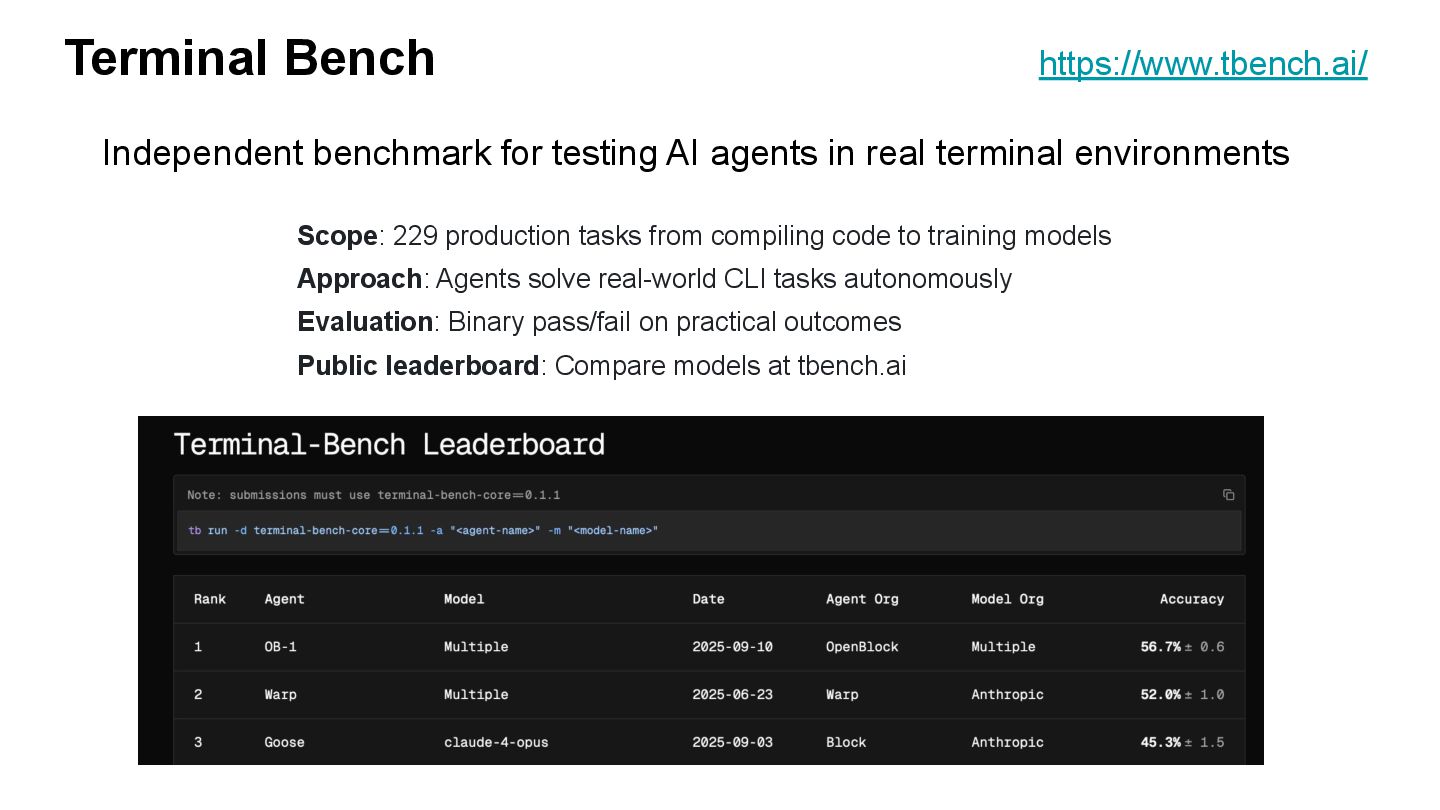{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}