service, completes text, image, audio • MCP: Primarily a client+server protocol for tools, though it does a bit more • Agent: LLM loop that auto-completes actions (with tools) not just text, etc. LLM MCP
Mesh, Google Cloud Service Mesh, Azure Service Fabric • Istio data plane (world's most popular service mesh) Built for observability and performance • C++ proxy handling millions of requests/second • Observability-first design with rich metrics and tracing But here's the problem... • Envoy sees AI calls as just HTTP requests • No understanding of tokens, models, or AI costs
wasn’t enterprise ready! • First stab at LLM proxy was using FastAPI (Python) • 100s of tenants = 100s of configs - configuration explosion Ok.. Envoy is everywhere, but when we tried to use it for AI… • "Let's use Envoy directly" - all AI developers failed at setup • Even experienced Envoy users struggled with DIY AI config Dan brought this to problem to the Envoy community and worked with Tetrate on a solution. Dan Sun: Bloomberg Cloud Native Compute Services & AI Inference and KServe Co-Founder
proxy that manages traffic from AI Agents in a multi-tenant deployment • Connect a routing API (typically OpenAI’s) to LLM or MCP providers • Throttle usage based on different tenant categories or cost models • Centralize authentication and authorization across different backends • Observability in terms of the above categories
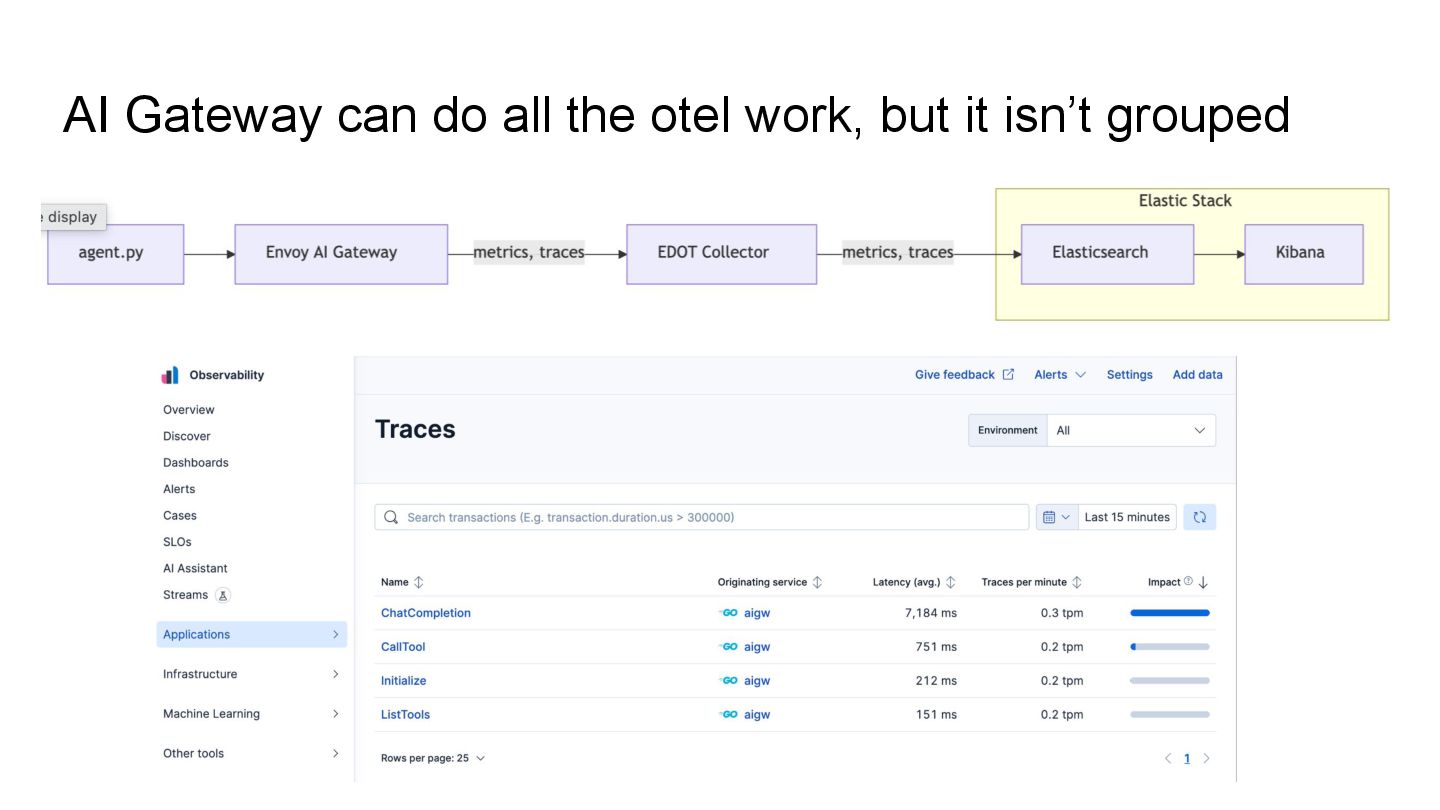
otel compatible metrics system including Prometheus-compatible dashboards for real-time monitoring Traces: OpenInference-enriched spans enabling LLM, Embedding and MCP evaluation Logs, Metrics and Traces for AI
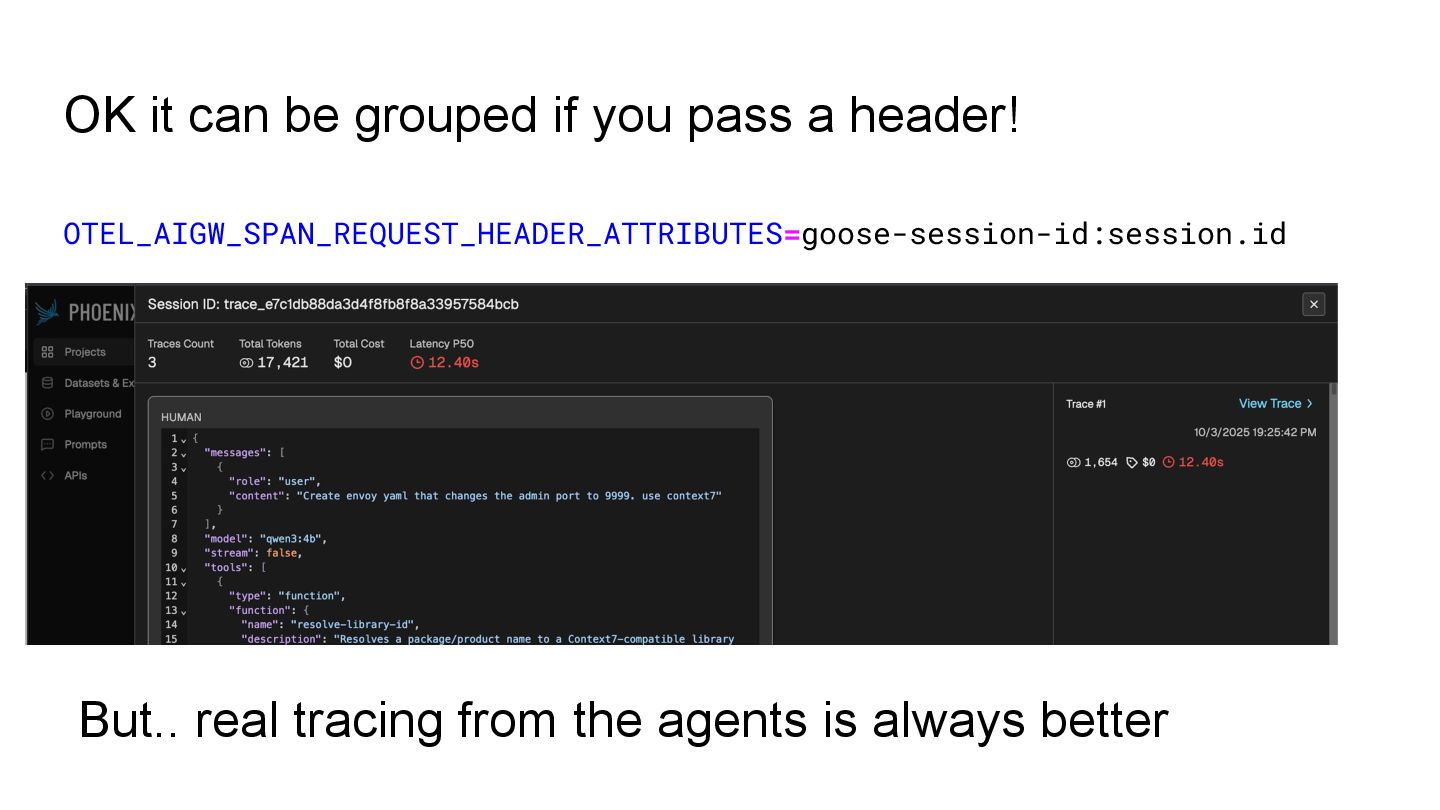
may think it is OpenAI when it is Bedrock: tracks the backend in dynamic metadata used in rate limiting and metrics. The original model may not be what’s used: tracks the original model from the proxy, the request sent to the backend vs and response model LLM Evals needs full request/response data: OpenInference format includes full LLM, MCP and Embedding inputs and outputs, with recording controls. Clients might not be instrumented: Customizable session.id capture from headers, which provide grouping for those not using OpenTelemetry on the clients.
limiting and other features You can place this alongside your other logging properties to see it in context of single requests Access Logging in Envoy AI Gateway
`gen_ai.server.request.duration` - Total request time - `gen_ai.server.time_to_first_token` - Time to first token (streaming) - `gen_ai.server.time_per_output_token` - Inter-token latency (streaming) Exports metrics to OTEL or scrape Prometheus on the `/metrics` endpoint Adds performance data to dynamic metadata for downstream use: - `token_latency_ttft` - Time to first token in milliseconds (streaming) - `token_latency_itl` - Inter-token latency in milliseconds (streaming) Metrics in Envoy AI Gateway
Gateway, or a standalone binary OpenTelemetry traces add context to web service calls, applied carefully at message layer for MCP! OpenInference is a trace schema built for evaluation of LLM, embedding and tool calls, by Arize (the dominant AI evaluation player) Tracing in Envoy AI Gateway
package: pip install elastic-opentelemetry Run edot-bootstrap which analyzes the code to install any relevant instrumentation available: edot-bootstrap —-action=install Add OpenTelemetry environment variables OTEL_EXPORTER_OTLP_ENDPOINT OTEL_EXPORTER_OTLP_HEADERS Prefix python with opentelemetry-instrument or use auto_instrumentation.initialize() github.com/elastic/elastic-otel-python
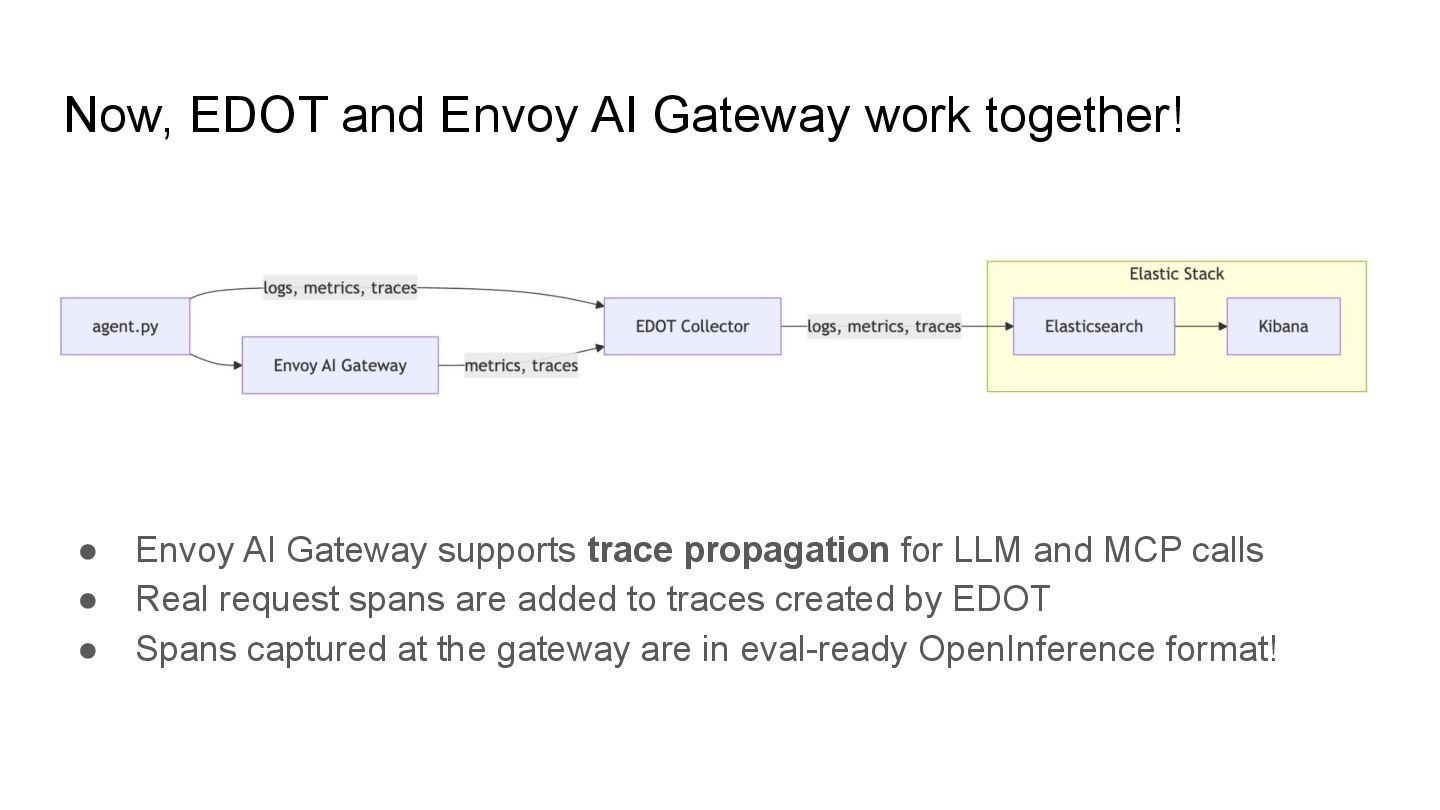
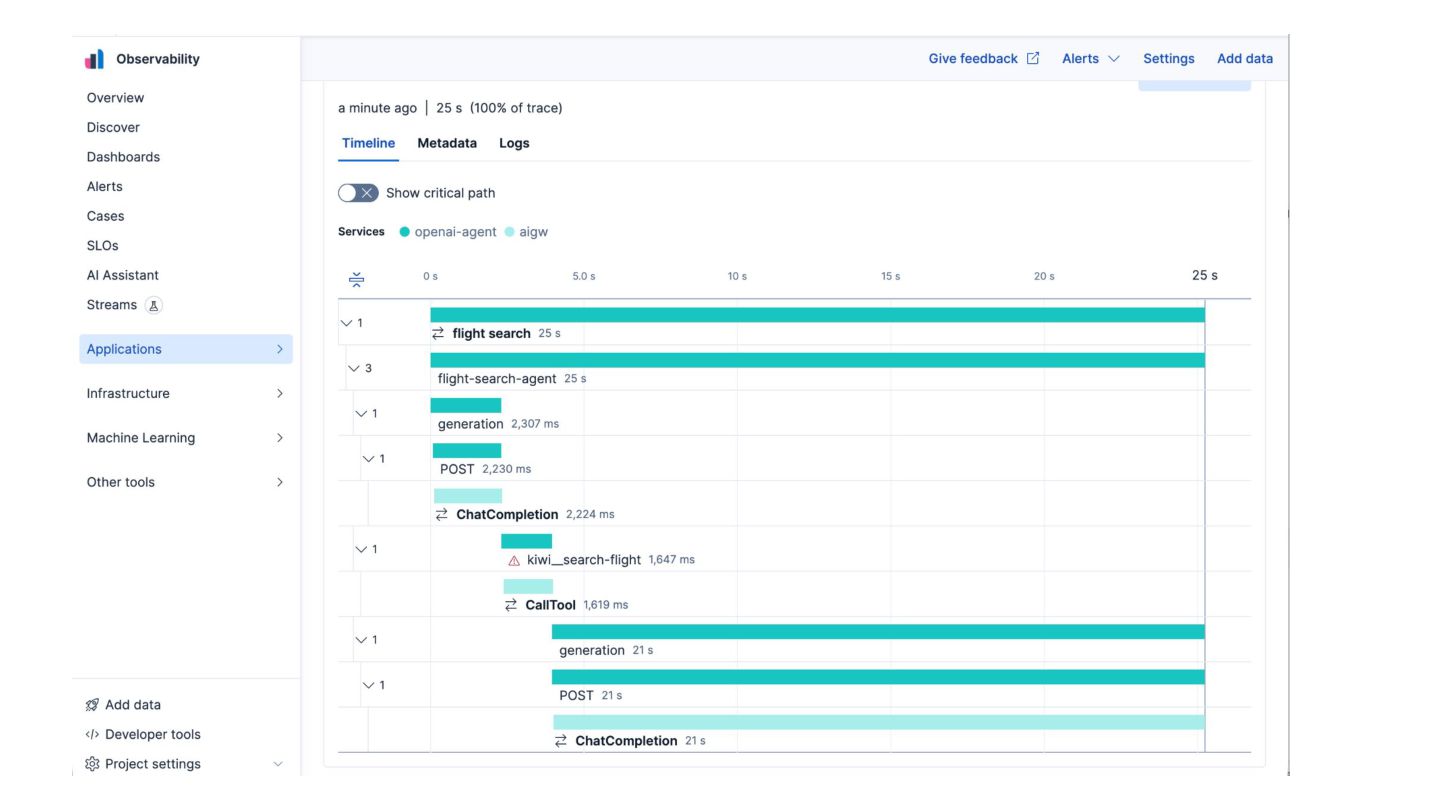
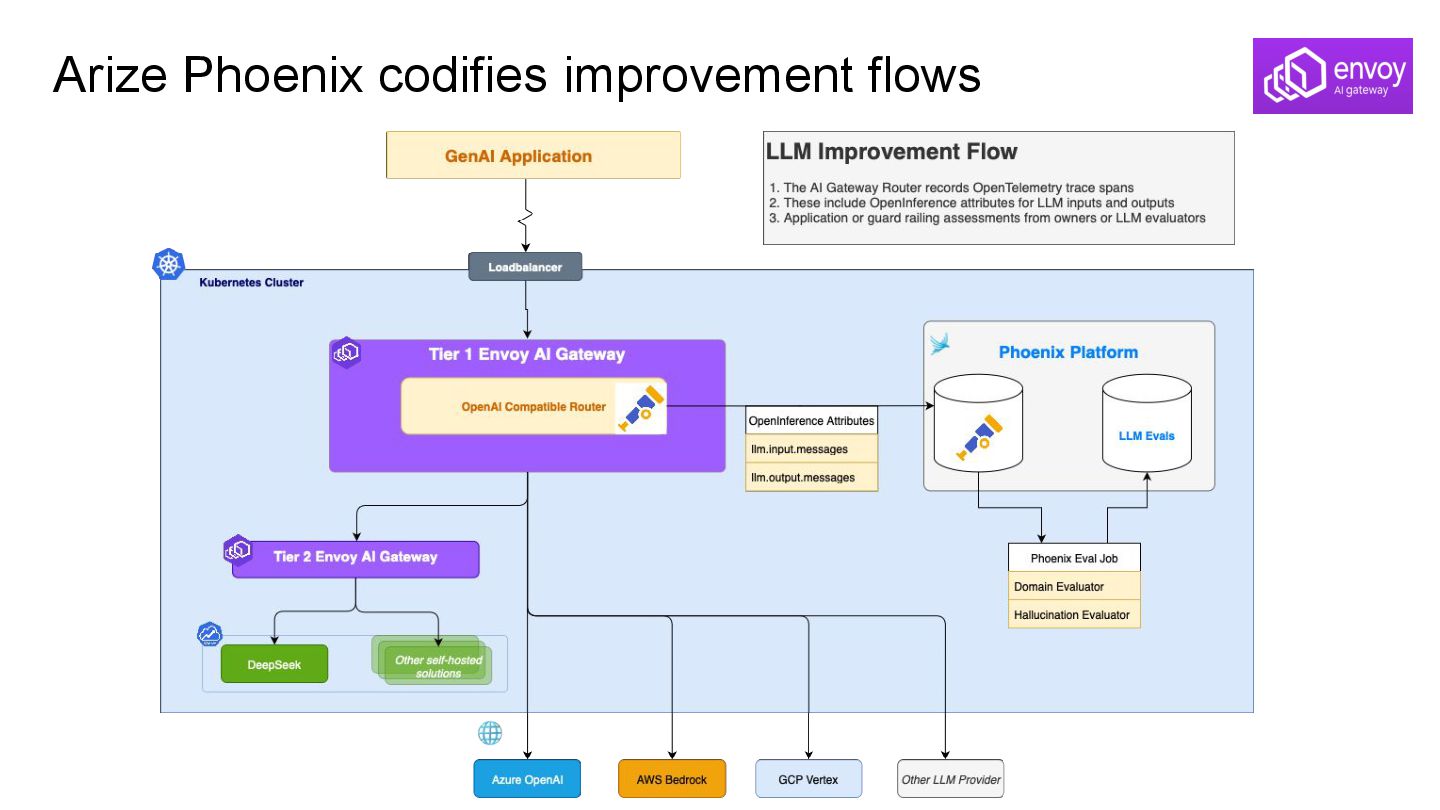
AI Gateway supports trace propagation for LLM and MCP calls • Real request spans are added to traces created by EDOT • Spans captured at the gateway are in eval-ready OpenInference format!
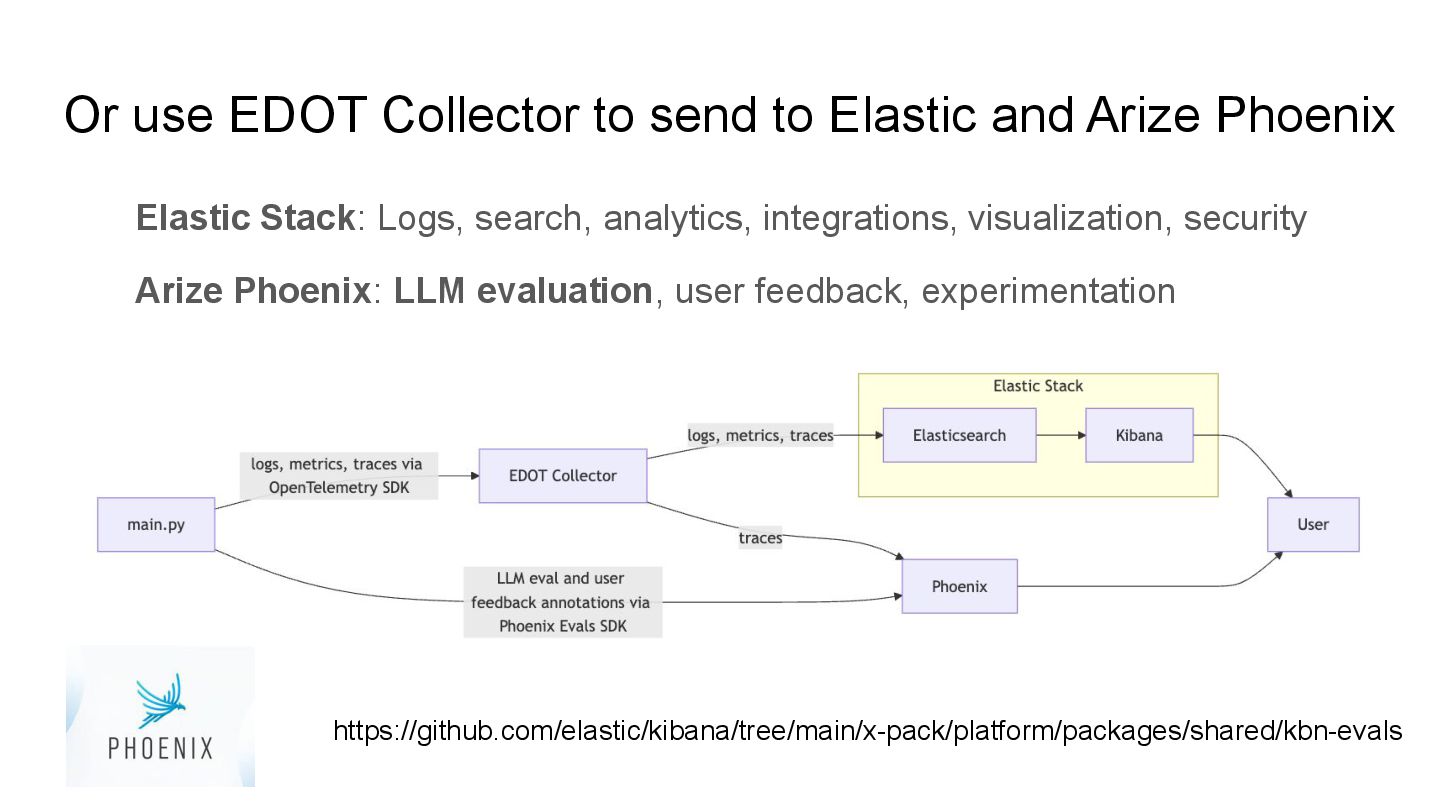
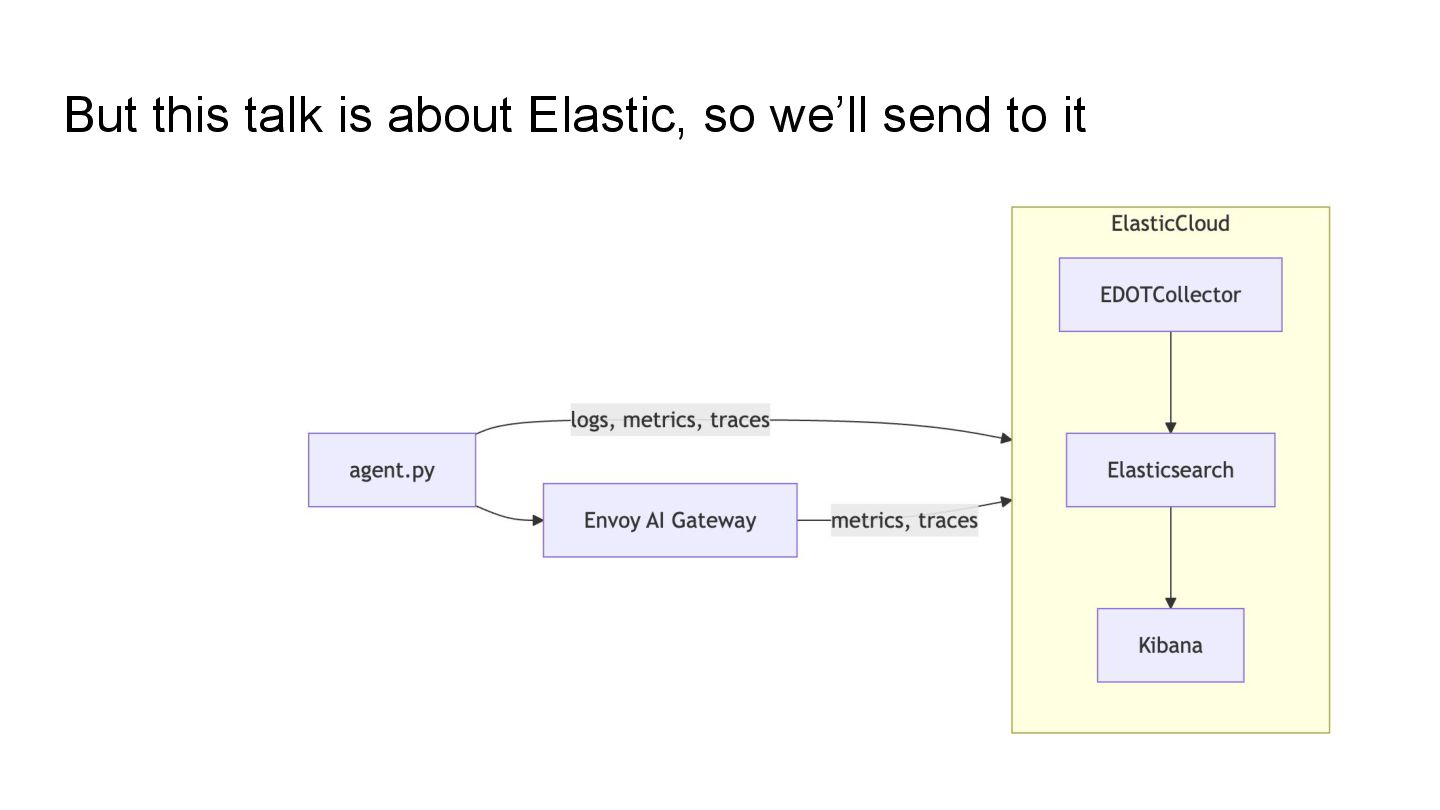
LLM evaluation, user feedback, experimentation Or use EDOT Collector to send to Elastic and Arize Phoenix https://github.com/elastic/kibana/tree/main/x-pack/platform/packages/shared/kbn-evals
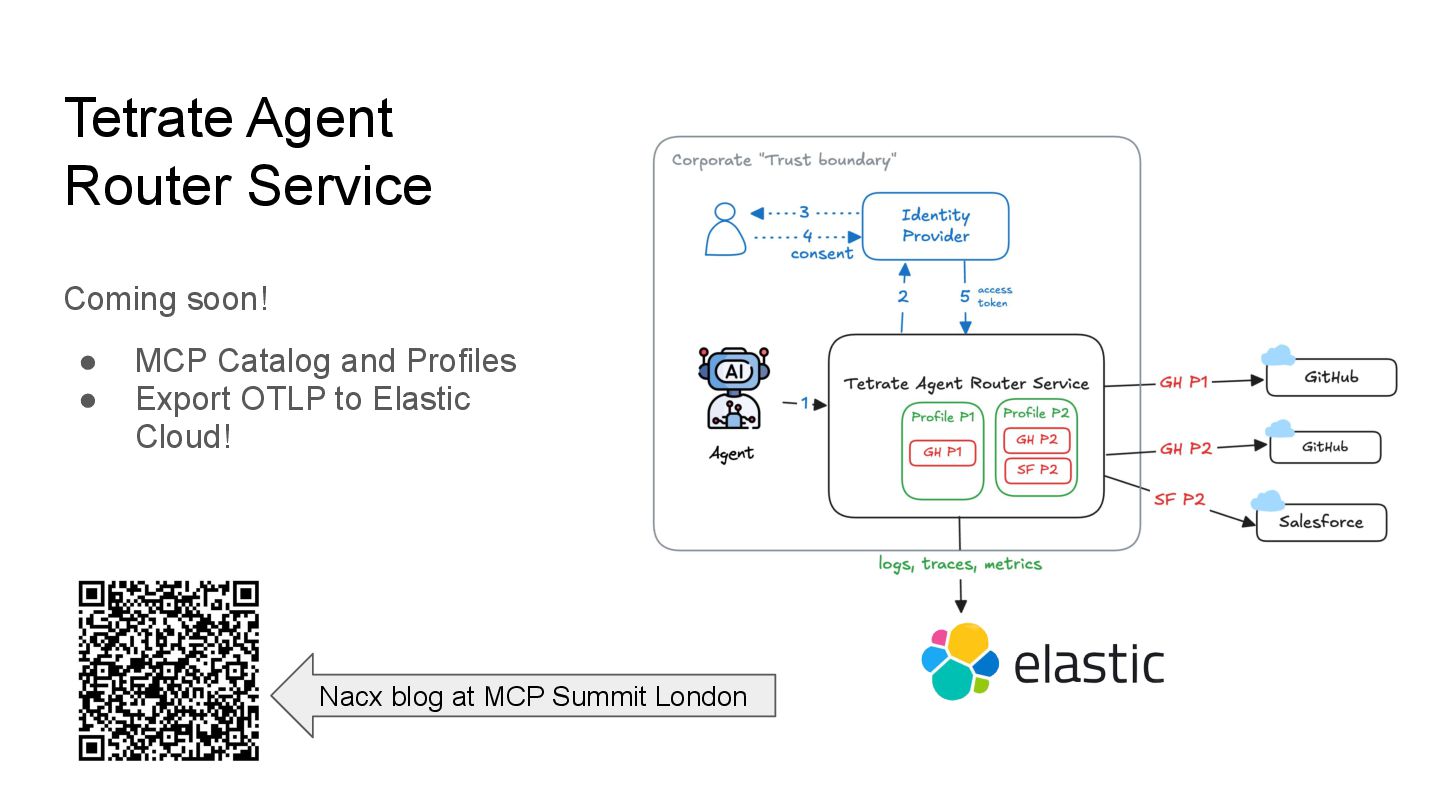
your on-machine AI agent, capable of automating complex development tasks from start to finish. More than just code suggestions, goose can build entire projects from scratch, write and execute code, debug failures, orchestrate workflows, and interact with external APIs - autonomously. Blog on Tetrate Agent Router Service+Goose with free $10
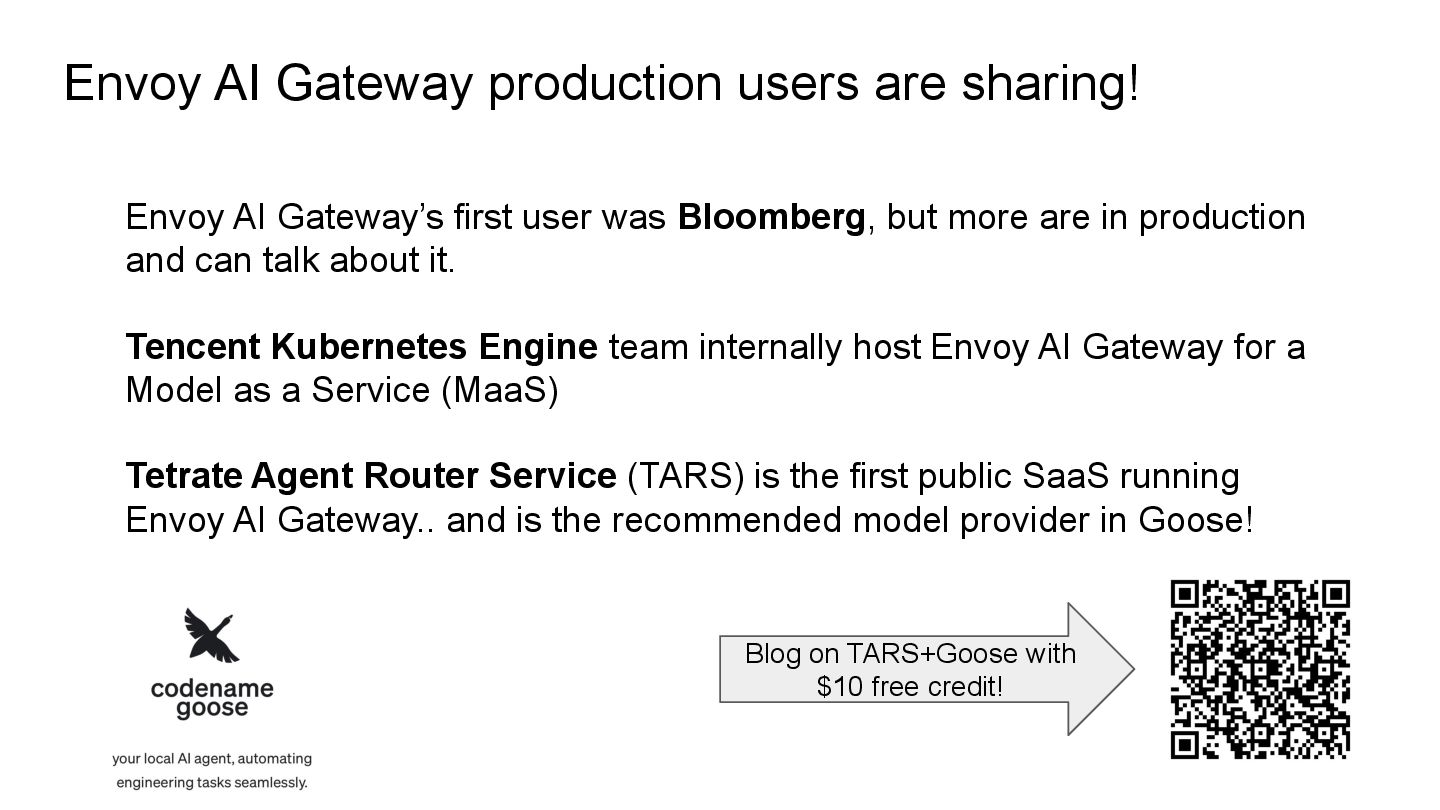
in production and can talk about it. Tencent Kubernetes Engine team internally host Envoy AI Gateway for a Model as a Service (MaaS) Tetrate Agent Router Service (TARS) is the first public SaaS running Envoy AI Gateway.. and is the recommended model provider in Goose! Blog on TARS+Goose with $10 free credit! Envoy AI Gateway production users are sharing!
Log export to OTLP hasn’t complete • Tracing needs to move to the upstream filter (capture actual LLM reqs) AI Gateway has some features TODO, regardless of Otel! • MCP is very new so will change quickly • OpenAI “Responses (stateful)” API used in new Agent tools • Should it do other specs like A2A and ACP (LF)?
origin, with OpenTelemetry native features that work well with EDOT. Elastic Distribution of OpenTelemetry (EDOT) makes it easier for clients to send the entire workflow, connecting traces together when routed through a gateway. OpenInference is the GenAI-tuned OpenTelemetry trace schema for evals, used by many frameworks and even Kibana! Agent apps go beyond LLM and into tools and workflows. This is changing what it means to be an AI gateway! Key Takeaways & Next Steps linkedin.com/in/adrianfcole Blog on TARS+Goose with $10 free credit!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}