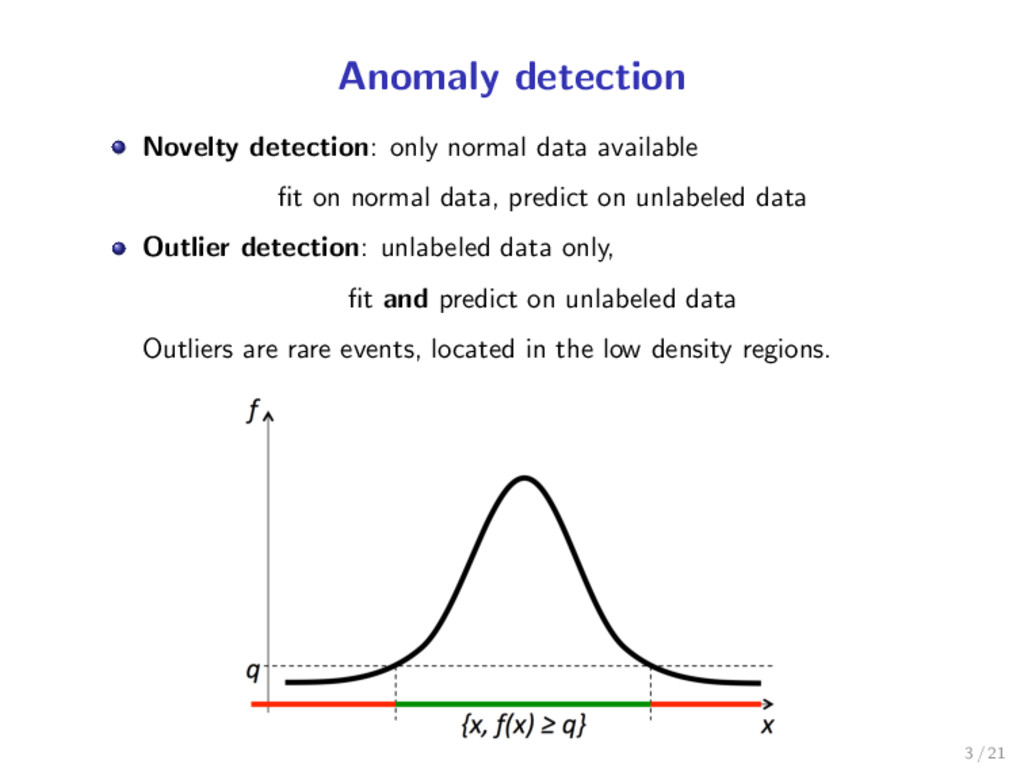
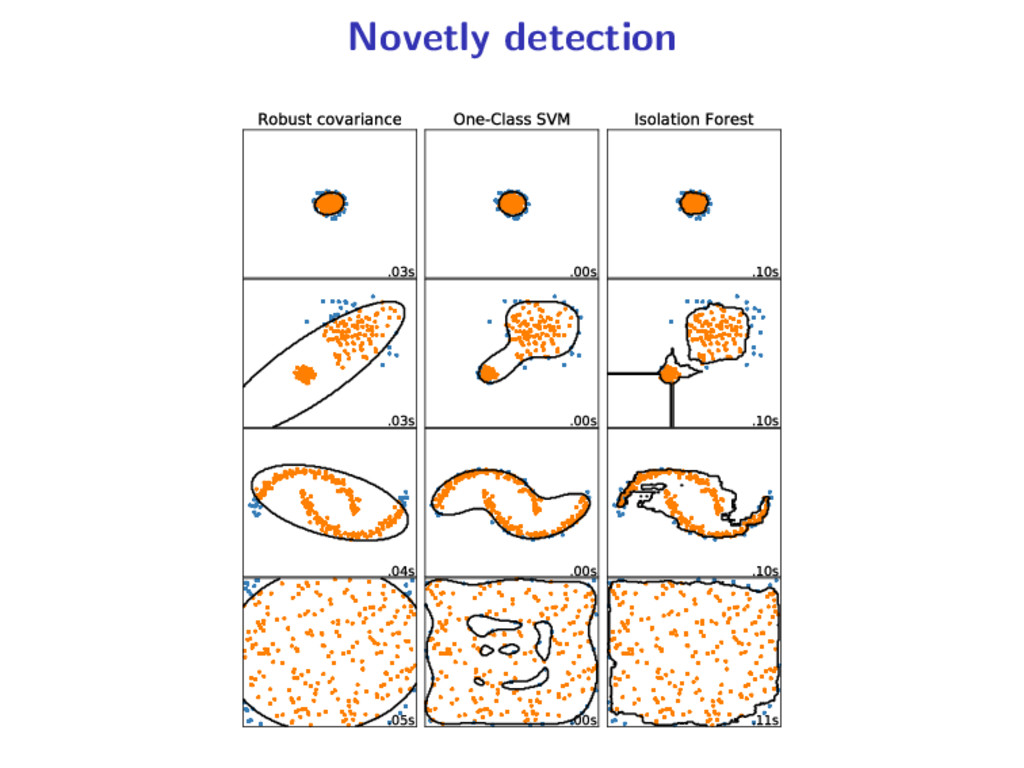
detection: only normal data available fit on normal data, predict on unlabeled data Outlier detection: unlabeled data only, fit and predict on unlabeled data Outliers are rare events, located in the low density regions. 2 / 21
normal data, predict on unlabeled data Outlier detection: unlabeled data only, fit and predict on unlabeled data Outliers are rare events, located in the low density regions. 3 / 21
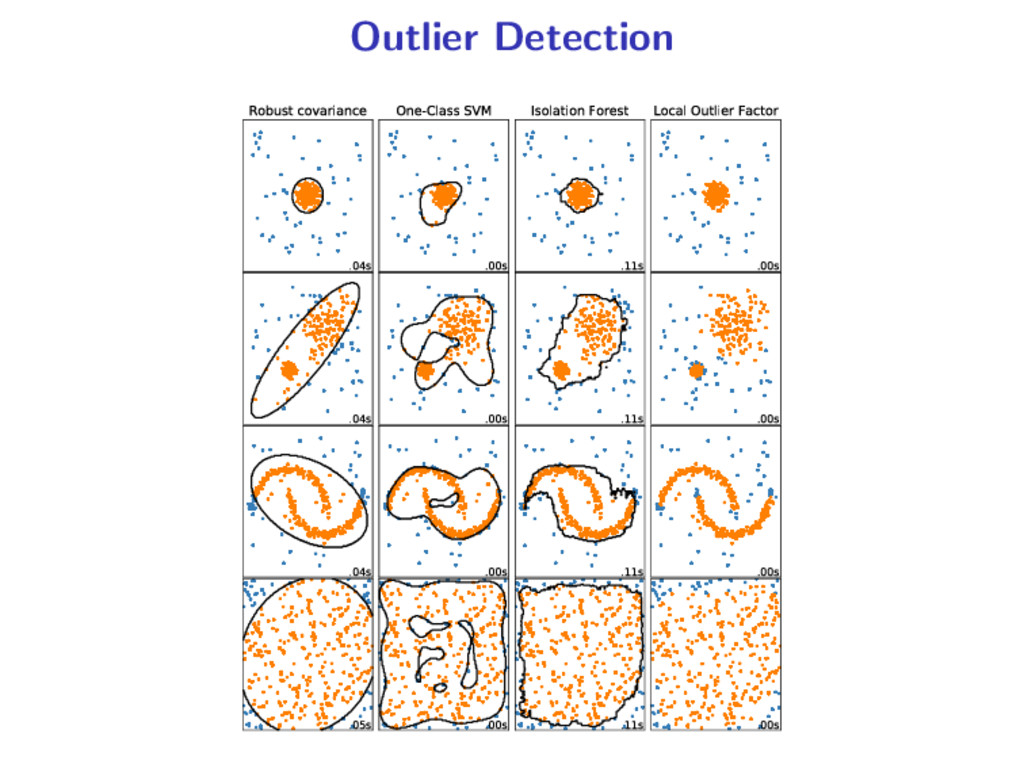
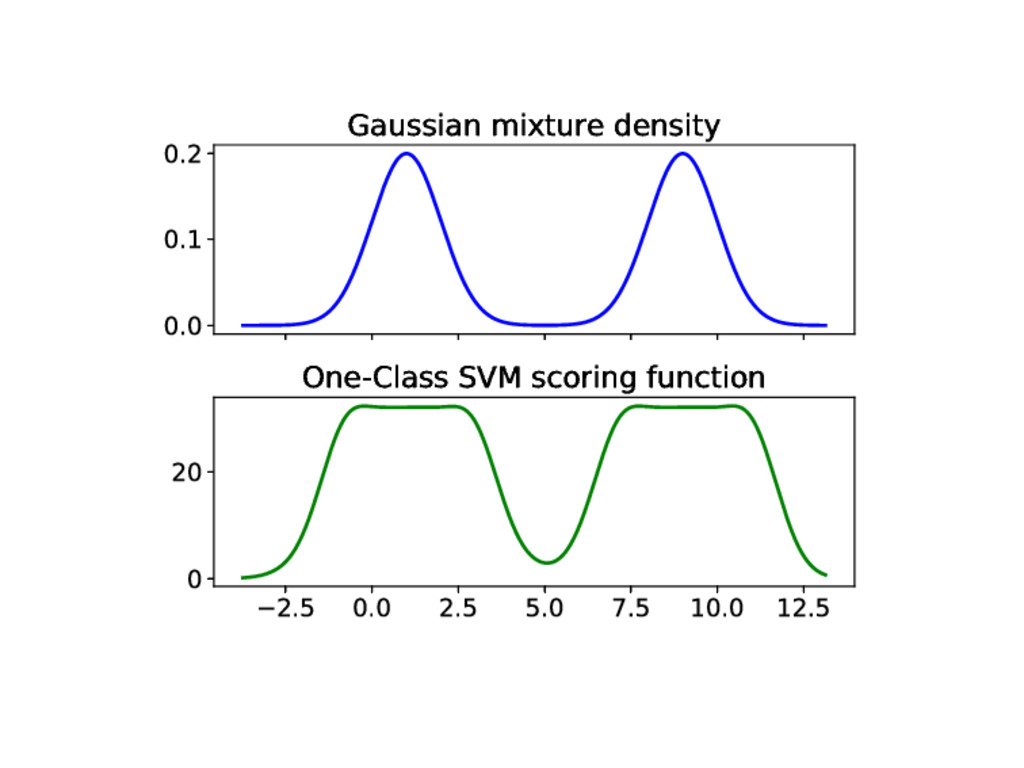
scoring function s such that the smaller spxq the more abnormal is x 2. Threshold s at an offset q: outlier/novelties are such that tx, spxq ă qu q usually depends on a contamination parameter EllipticEnvelope, OneClassSVM IsolationForest (iForest) and LocalOutlierFactor (LOF) 4 / 21
clf = OneClassSVM() clf.fit(X_train) clf.score_samples(X_test): raw score s clf.decision_function(X_test): thresholded score clf.score_samples(X_test) - clf.offset_ #ě 0 for inliers ă 0 for outliers clf.predict(X_test) #`1 for inliers ´1 for outliers Not valid for LOF 10 / 21
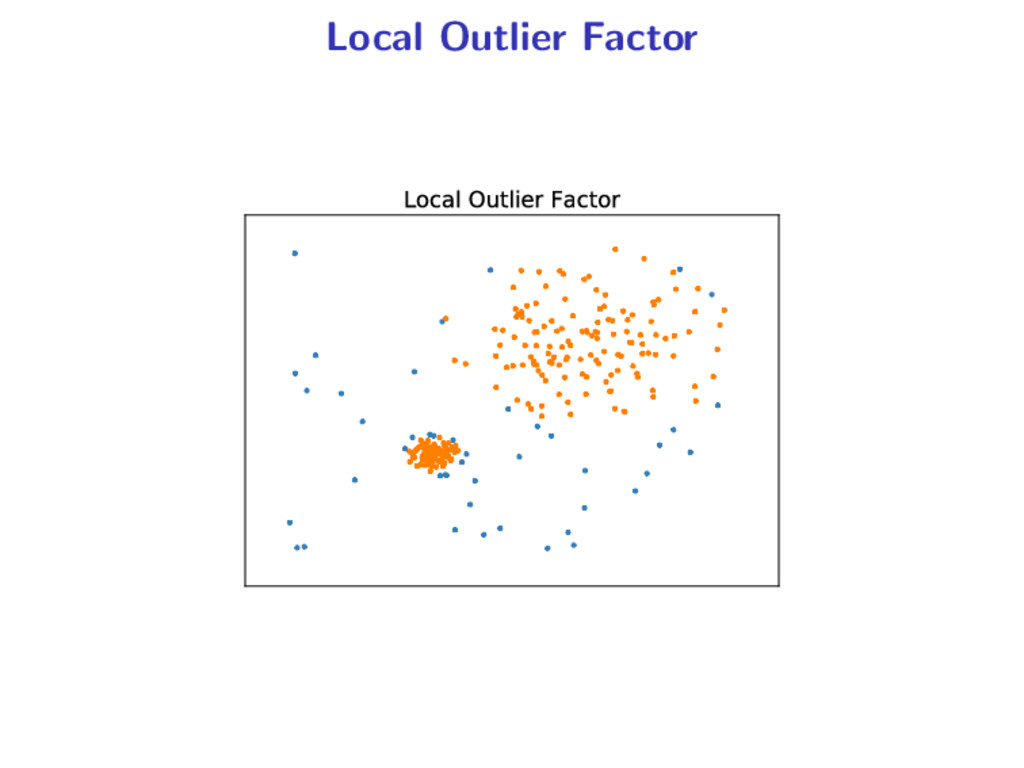
distances predict on x P Xtrain : take the k nearest neighbors of x in Xtrainztxu predict on x R Xtrain : take the k nearest neighbors of x in Xtrain Hard to check whether x P Xtrain or not... 11 / 21
OneClassSVM for outlier detection: proportion of outliers in the data set for novelty detection: type-I error (false positive rate) Used to compute the offset q on the training set tspxq ă qu “ tclf.score_samples(x) < clf.offset_u 14 / 21
and LOF iForest: score of inliers close to 0 and score of outliers close to -1 clf.offset_ = -0.5 LOF: score of inliers « ´1 clf.offset_ = -1.5 15 / 21
Create an OutlierMixin defines a fit_predict for all outlier and novelty detection estimators For all estimators test fit_predict For novelty detection estimators test score_samples, decision_function, offset_ 16 / 21
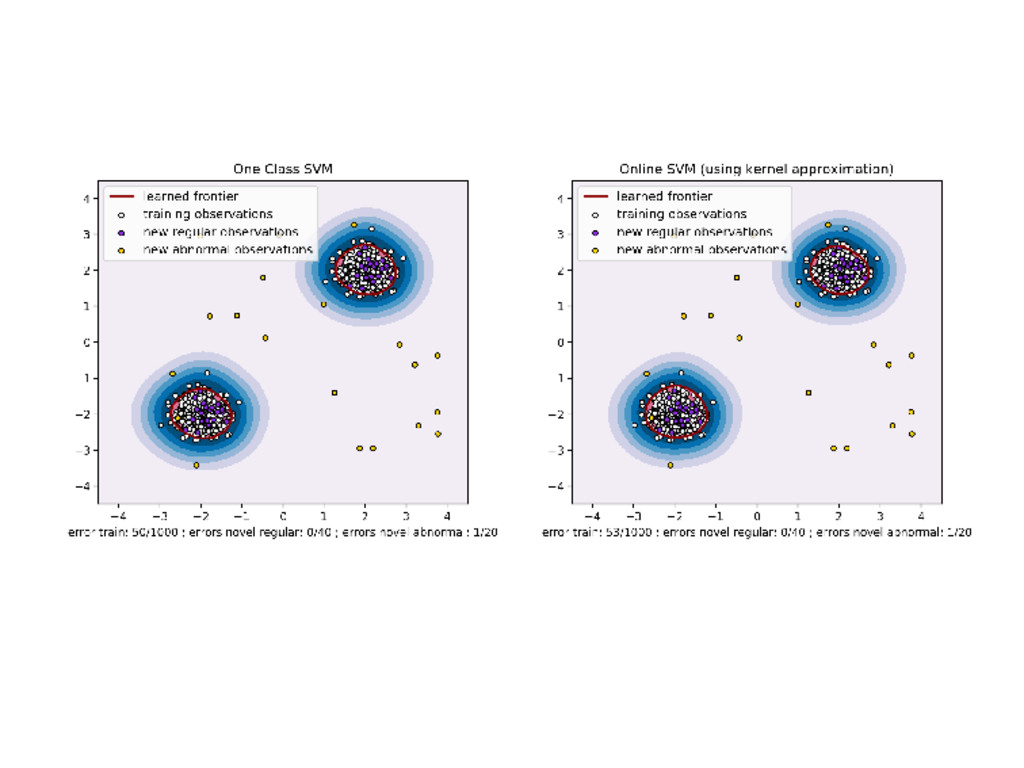
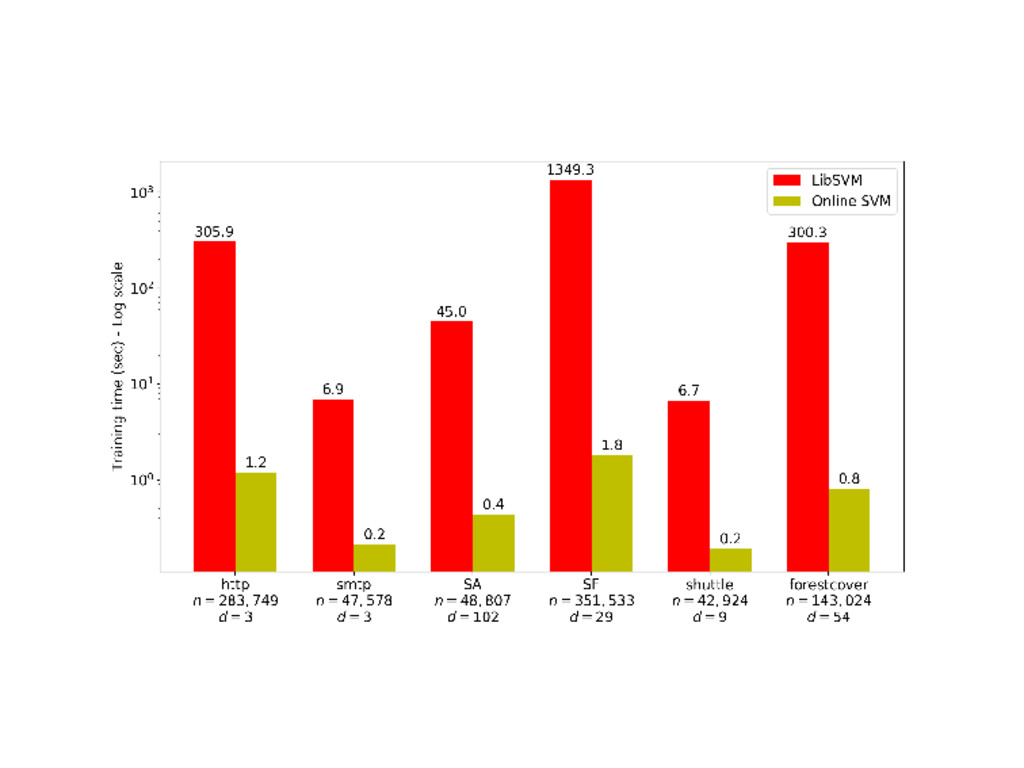
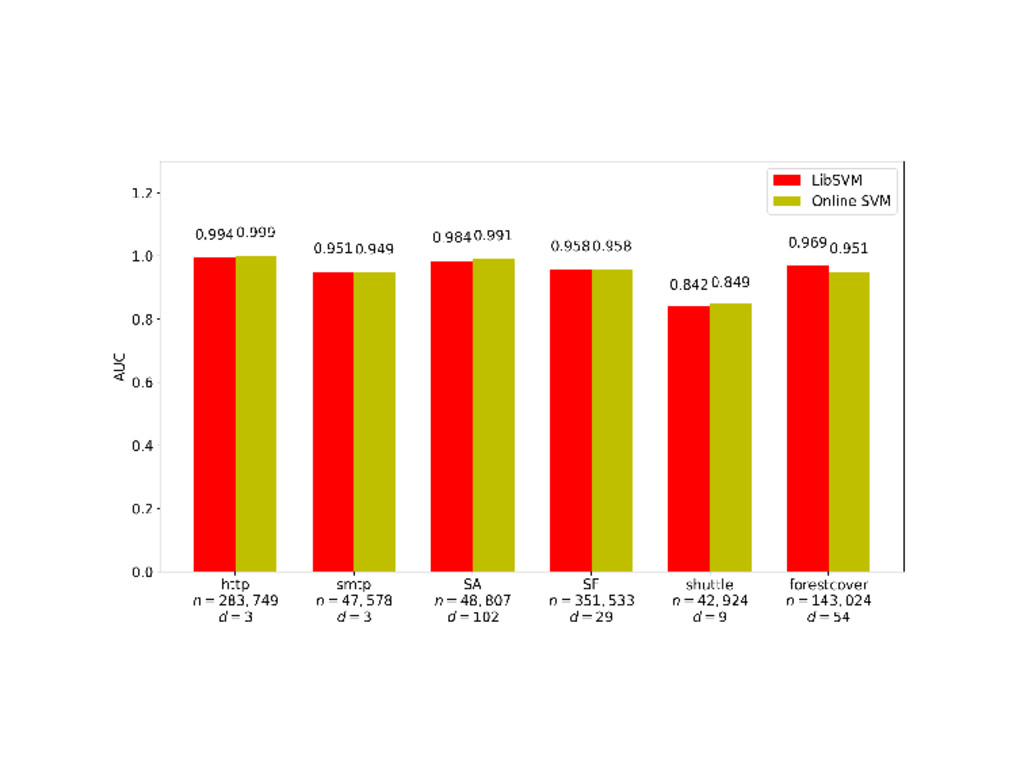
linear version of the OneClassSVM Pipeline with a kernel approximation from sklearn.kernel_approximation import Nystroem from sklearn.linear_model import SGDOneClassSVM nystroem = Nystroem(gamma=gamma) online_ocsvm = SGDOneClassSVM(nu=nu) pipe_online = make_pipeline(nystroem, online_ocsvm) pipe_online.fit(X_train) 17 / 21
script per context (novelty vs outlier detection) convert fast benchmarks into examples New estimators SGDOneClassSVM Local Outlier Probabilities SVDD Online univariate anomaly detection Documentation 20 / 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}