loops, asynchronous IO ▸ concurrent.futures ▸ high level abstractions: ThreadPoolExecutor and ProcessPoolExcutor ▸ threading ▸ low level constructs: build your own solution based on thread, semaphores and locks ▸ multiprocessing ▸ similar to threading, but for processes
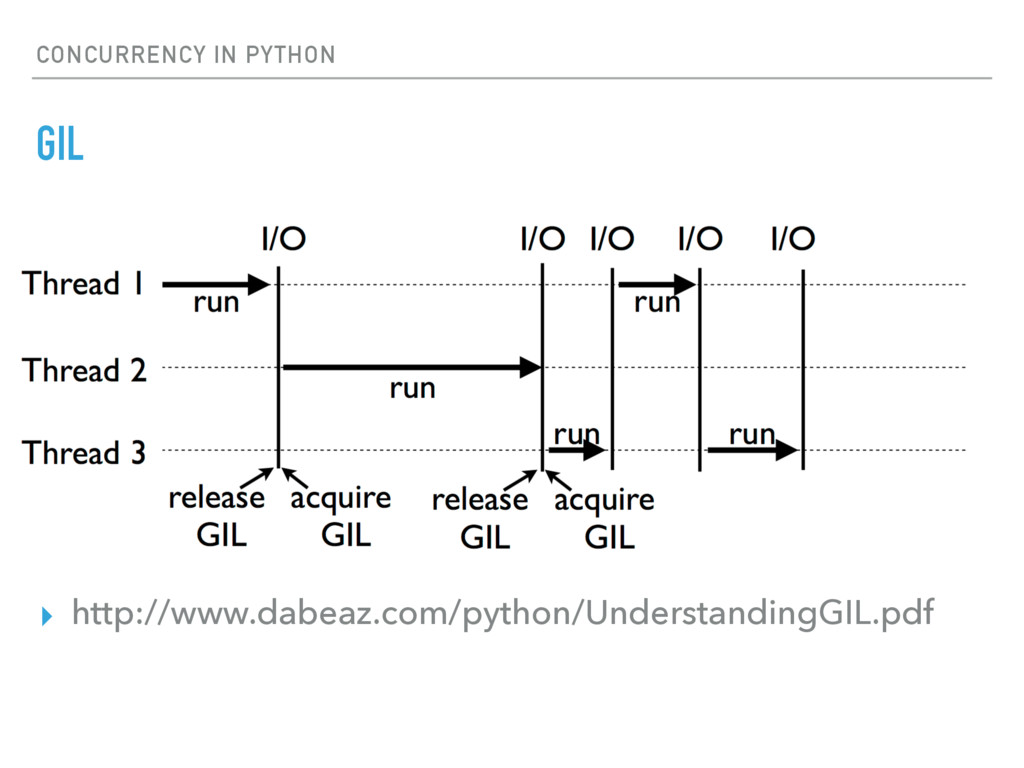
▸ Multiple Python processes across CPUs ▸ Good for CPU intensive tasks ▸ ThreadPoolExecutor ▸ Threads run inside a single Python interpreter. ▸ Only one thread can run at a time, because of the GIL (Global Interpreter Lock) ▸ Good for I/O. When a thread is blocked on IO, it releases the GIL, which gets acquired by another thread.
result = obj.copy_from(CopySource={'Bucket': bucket, 'Key': key}) return (result['ResponseMetadata']['HTTPStatusCode']) with futures.ThreadPoolExecutor(max_workers=100) as executor: todo = [] for src_object in src_objects: dest_obj = s3.Object(dest_bucket,dest_key) future = executor.submit(copy, dest_obj, src_object.bucket, src_object.key) todo.append(future) results = [] for future in futures.as_completed(todo): res = future.result() results.append(res) print(len(results))
result = obj.copy_from(CopySource={'Bucket': bucket, 'Key': key}) return (result['ResponseMetadata']['HTTPStatusCode']) def task(prefix, src_bucket, src_objects, dest_bucket): with futures.ThreadPoolExecutor(max_workers=100) as executor: for src_object in src_objects: dest_obj = s3.Object(dest_bucket,dest_key) future = executor.submit(copy, dest_obj, src_object.bucket, src_object.key) with futures.ThreadPoolExecutor(max_workers=31) as task_executor: while date != datetime(2016, 6, 31): date = date + relativedelta(days=1) prefix = date.strftime("%Y-%m-%d") future = task_executor.submit(task, prefix, src_bucket, src_objects,dest_bucket) tasks.append(future)
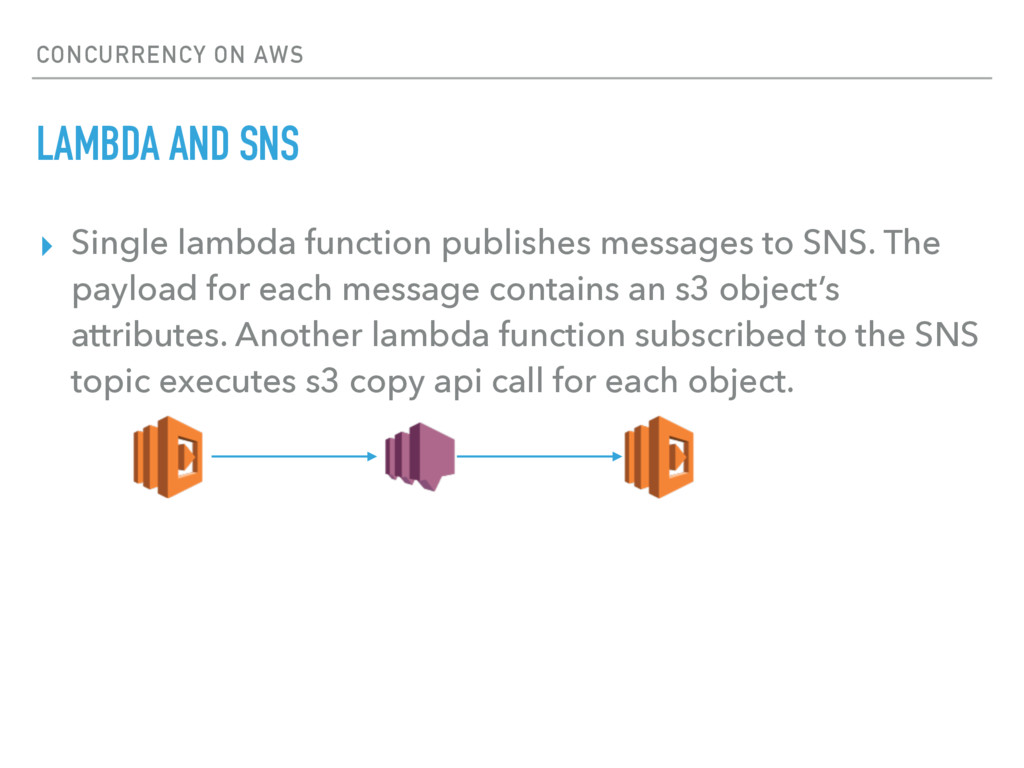
publishes messages to SNS. The payload for each message contains an s3 object’s attributes. Another lambda function subscribed to the SNS topic executes s3 copy api call for each object.
lambda function as the unit of concurrency. ▸ For event sources that are not stream-based: concurrency = events per second * function duration ▸ concurrency = 20 * 30 = 600 ▸ By default, 100 concurrent executions is the safety limit, invocations after that are throttled. Can be increased on request. ▸ Retries on errors
lambda function as the unit of concurrency. ▸ For event sources that are not stream-based: concurrency = events per second * function duration ▸ concurrency = 20 * 30 = 600 ▸ By default, 100 concurrent executions is the safety limit, invocations after that are throttled. Can be increased on request. ▸ Retries on errors LITTLE’S LAW
lambda function as the unit of concurrency. ▸ For event sources that are not stream-based: concurrency = events per second * function duration ▸ concurrency = 20 * 30 = 600 ▸ By default, 100 concurrent executions is the safety limit, invocations after that are throttled. Can be increased on request. ▸ Retries on errors IF YOUR DATA DONT FIT LL, CHANGE YOUR DATA ! - NEIL GUNTHER
if invocations < number of s3 objects to copy ▸ Throttles ▸ Not a problem for simple jobs without a time constraint ▸ Duration ▸ Errors ▸ Also useful for monitoring
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}