NoSQL, distributed database built for modern, mission-critical online applications. Written in Java and is a hybrid of Amazon Dynamo and Google BigTable Masterless with no single point of failure Distributed and topology aware 100% uptime Predictable scaling Low latency High throughput 4 DataStax Confidential. Do not distribute without consent. 3 Dynamo BigTable BigTable: http://research.google.com/archive/bigtable-osdi06.pdf Dynamo: http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pd CASSANDRA"
University Distributed large-scale data processing engine Real-time Streaming Distributed Processing GraphX, MLLib Ease of Use No storage engine of its own 10x – 100x speed of MapReduce
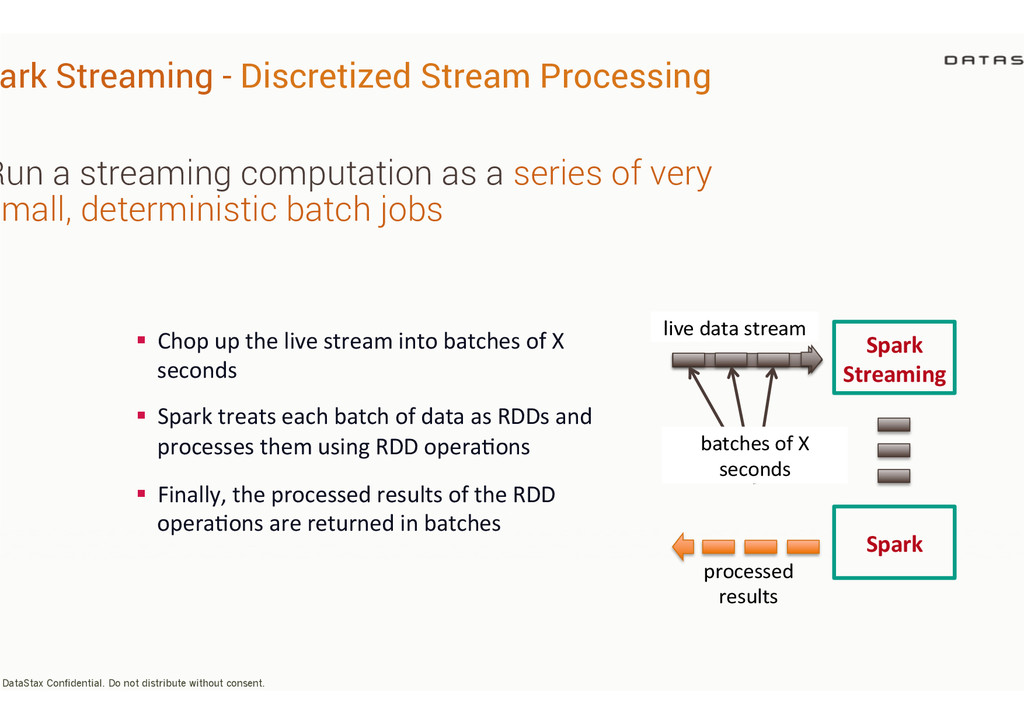
distribute without consent. Run a streaming computation as a series of very small, deterministic batch jobs Spark Spark Streaming batches of X seconds live data stream processed results § Chop up the live stream into batches of X seconds § Spark treats each batch of data as RDDs and processes them using RDD opera;ons § Finally, the processed results of the RDD opera;ons are returned in batches
from and write to Cassandra Mapping of C* tables and rows to Scala objects ll Cassandra types supported and converted to Scala types erver side data selection irtual Nodes support cala only driver for now
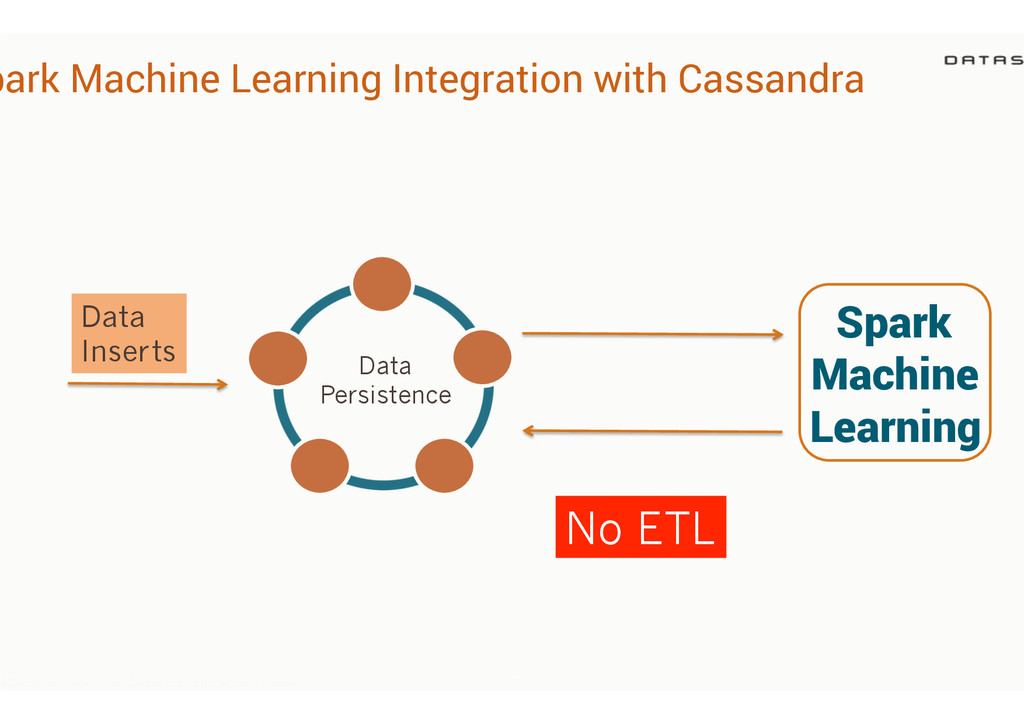
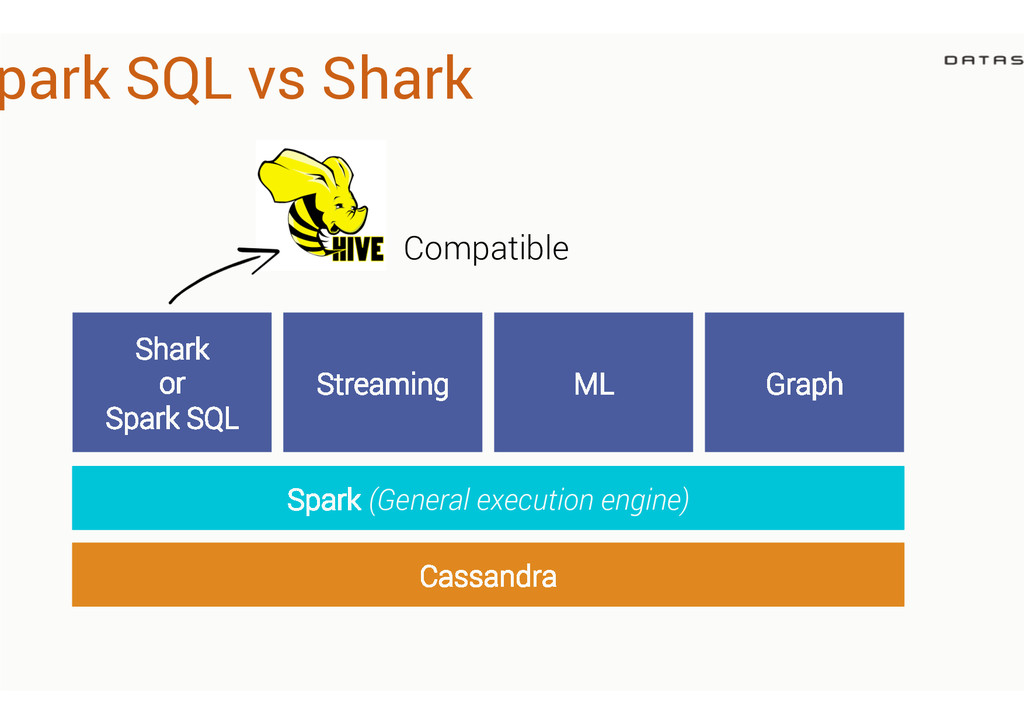
like Joins across multiple Cassandra tables Batch queries Caching Massively faster than Hadoop/Hive queries 4 DataStax Confidential. Do not distribute without consent. 25 CREATE TABLE CachedStocks TBLPROPERTIES ("shark.cache" = "true") ! AS SELECT * from PortfolioDemo.Stocks WHERE value > 95.0;! ! SELECT * FROM CachedStocks;!
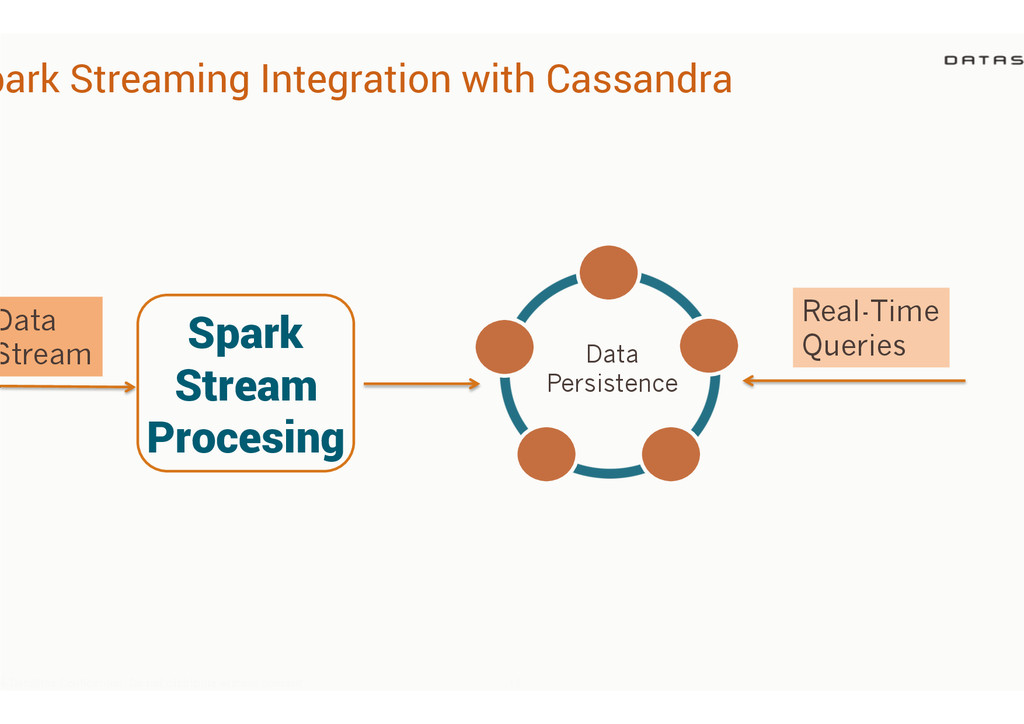
Streaming • Real-Time event processing • Data enrichment • Cassandra as the persistence layer 4 DataStax Confidential. Do not distribute without consent. 26
{kind=link}
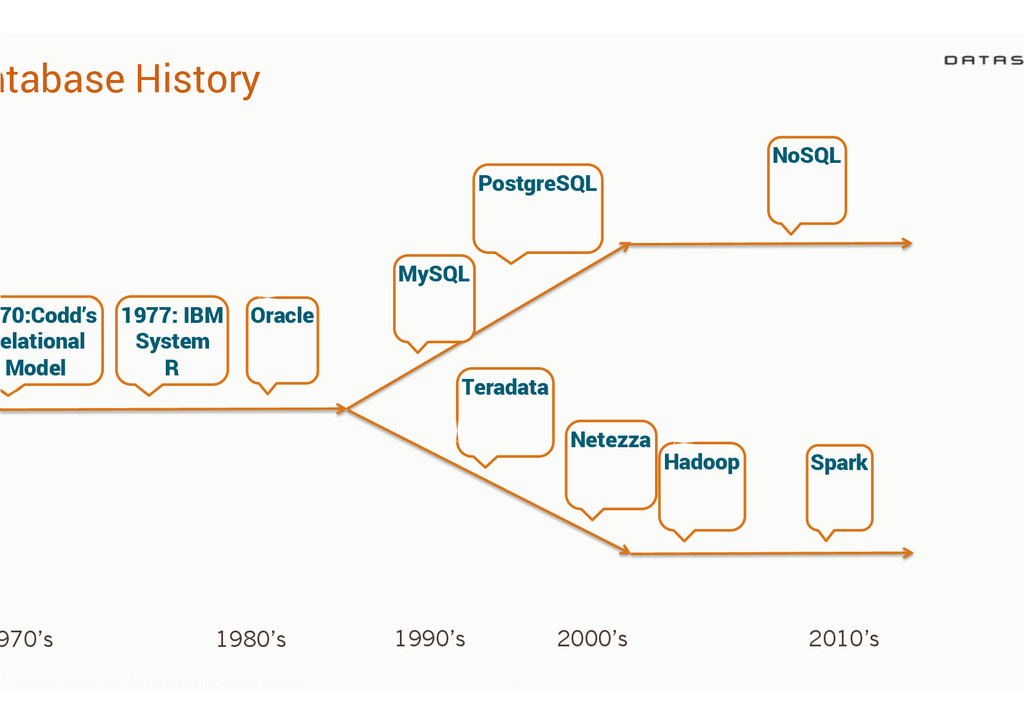{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
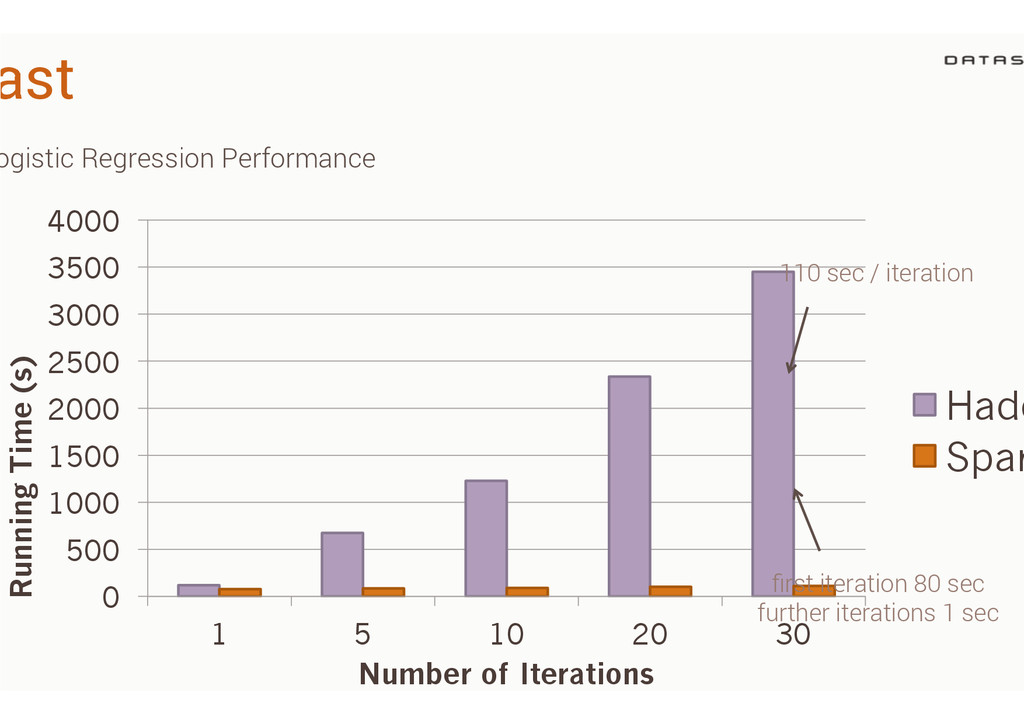{kind=link}
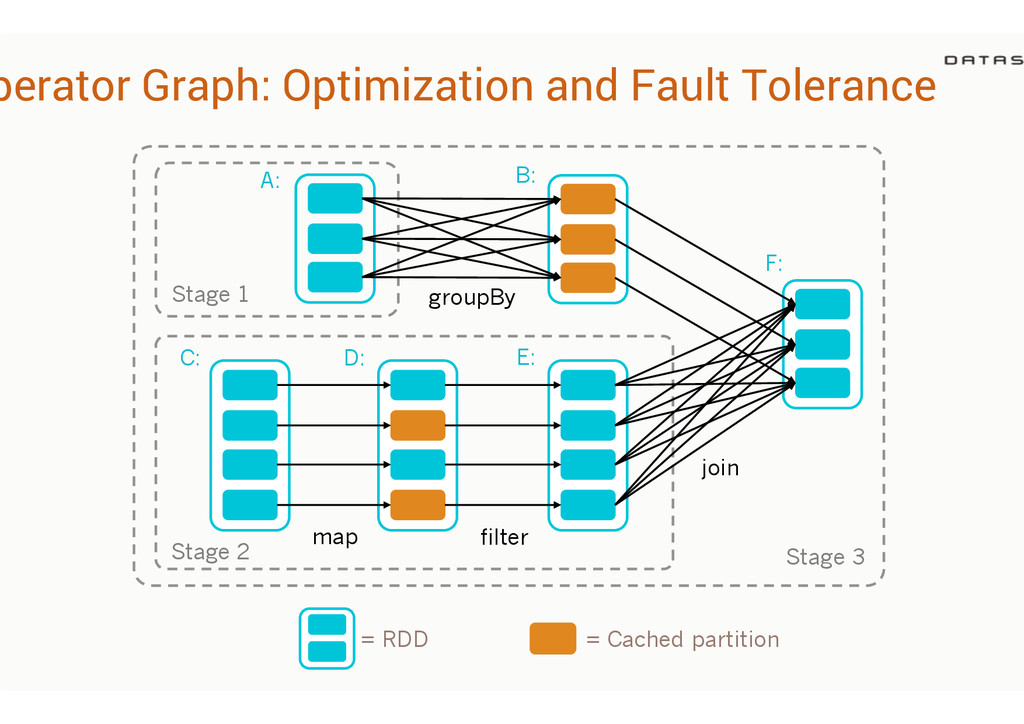{kind=link}
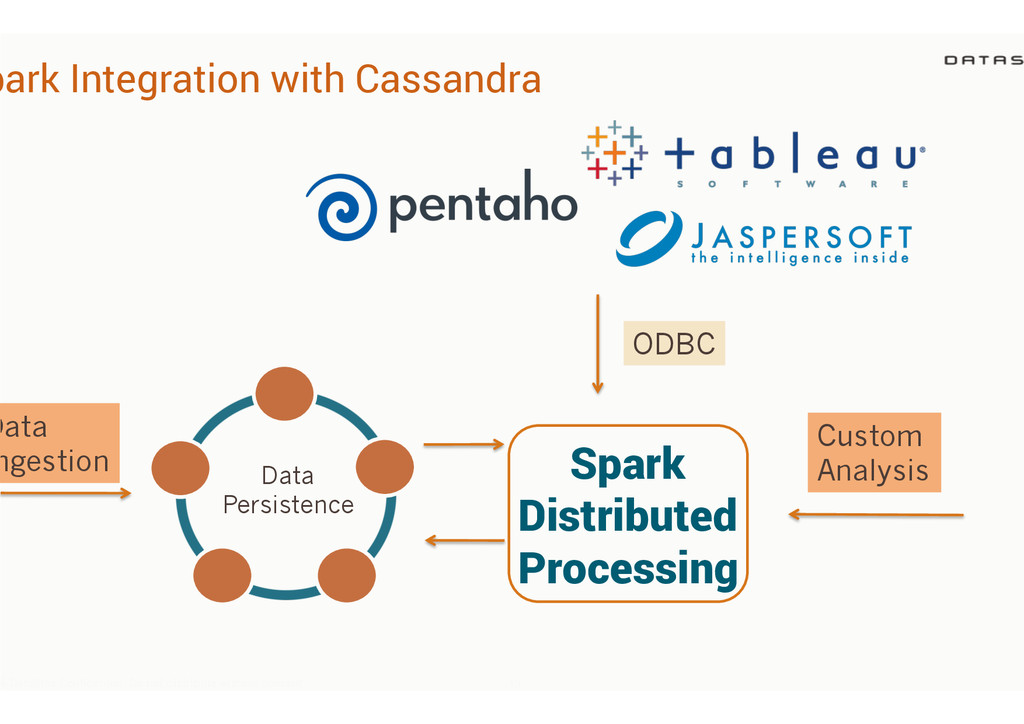{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}