to share their experience and have created a Speakers Program full of benefits! If you are interested please contact us for details. Need help, or want to contribute? Email [email protected]
power of the Merkle tree" Joined Credit Suisse as a software engineer two years ago after graduating from computer science. Have developed an interest in big data problems and have been working on the banks leading big data team for just over 6 months.
an extra level of indirection solve? • Copy whole database and do reporting / analytics off that. • Give up on consistency as a whole. • Start using /dev/null databases (!) • Build strange things solve specific performance issues. • CQRS, Event Sourcing… but all those viewmodels…need a fast store for them.
model for queries. • Modelling for queries gets you back analysing use cases. • Constraints as guides. • Relentless denormalisation… no use clutching onto one true schema to rule them all. • Gears towards service orientation.
well ☺ • Tools and libraries – nowhere near SQL, but getting there…fast. • Query language – CQL. • If you’re in .NET, the DataStax driver has EF like contexts that you can use…nice and familiar to start with. • Dead easy to pick up from app dev perspective. Progressive learning. • A little modelling goes a long way. Fast. • Easy install. Free, open source. Commercial version + support from DataStax.
DataStax Enterprise. • Spark connector is awesome…open up access to Spark ML, Spark SQL and all other loveliness built on top of spark. • Import / Export via csv.
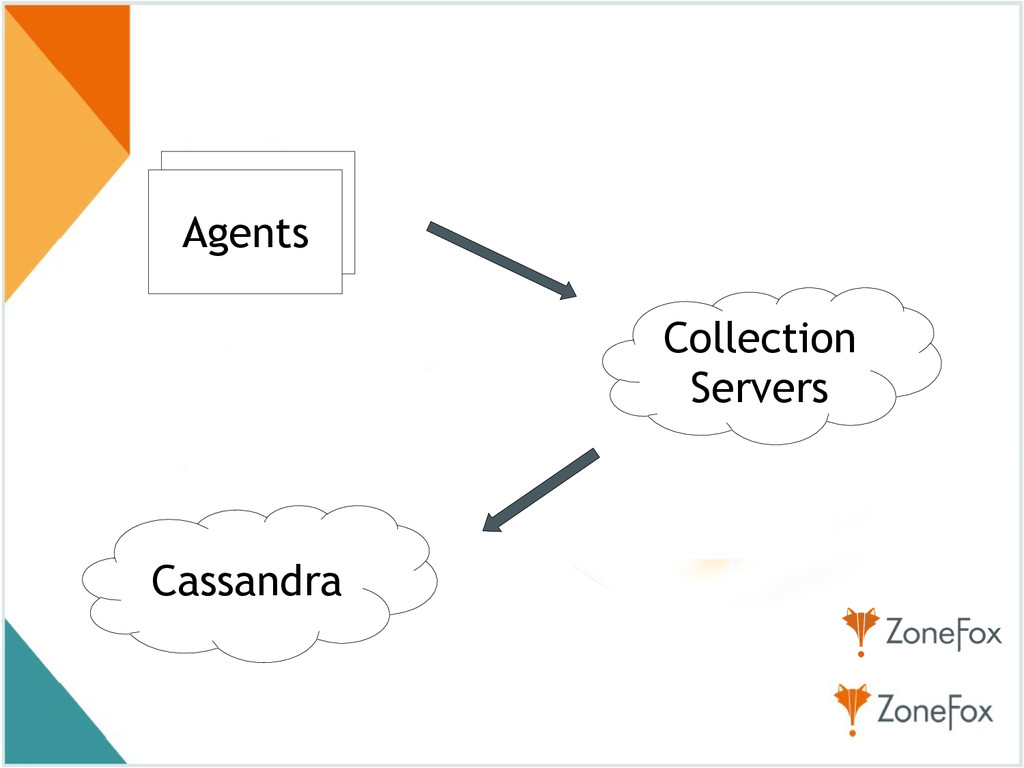
! 19:55 - Oleksii Mandrychenko “Using Cassandra to create write-heavy real-time security application” I am a senior software engineer at ZoneFox. I have been involved in IT for the last 10 years, where I was doing coding, hacking, configuring, deploying, and testing. My area of expertise is real-time forensic and behavioural analysis. I am responsible for architecting scalable, high performance, analytical system to detect insider thread attacks. I hold MSc in computer science and currently writing up a PhD thesis on a stack of computer science and health.
20:00 - Alok Dwivedi "Quickly enumerating sub sets of very large C* tables using composite partition keys" I am a Senior developer working for Symantec, with over 14 years of Software development and design experience mainly in RDBMS and various server side technologies using Java/C++/ C#. Since last one year I have been working on NoSQL and Big Data technologies mainly Cassandra.
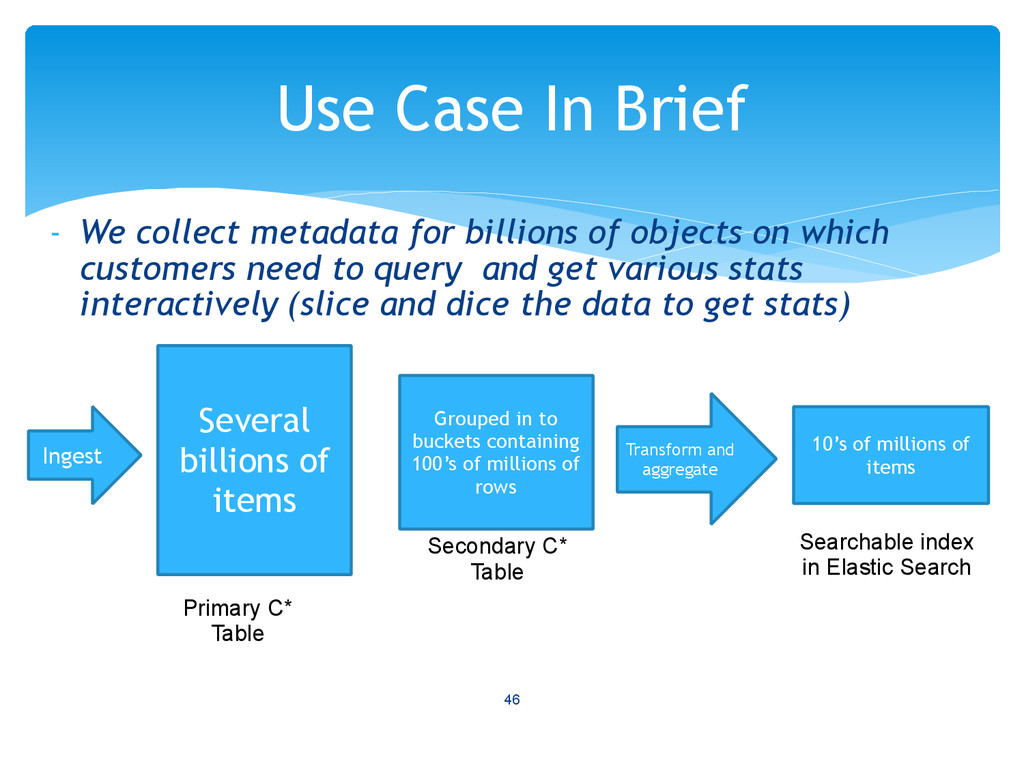
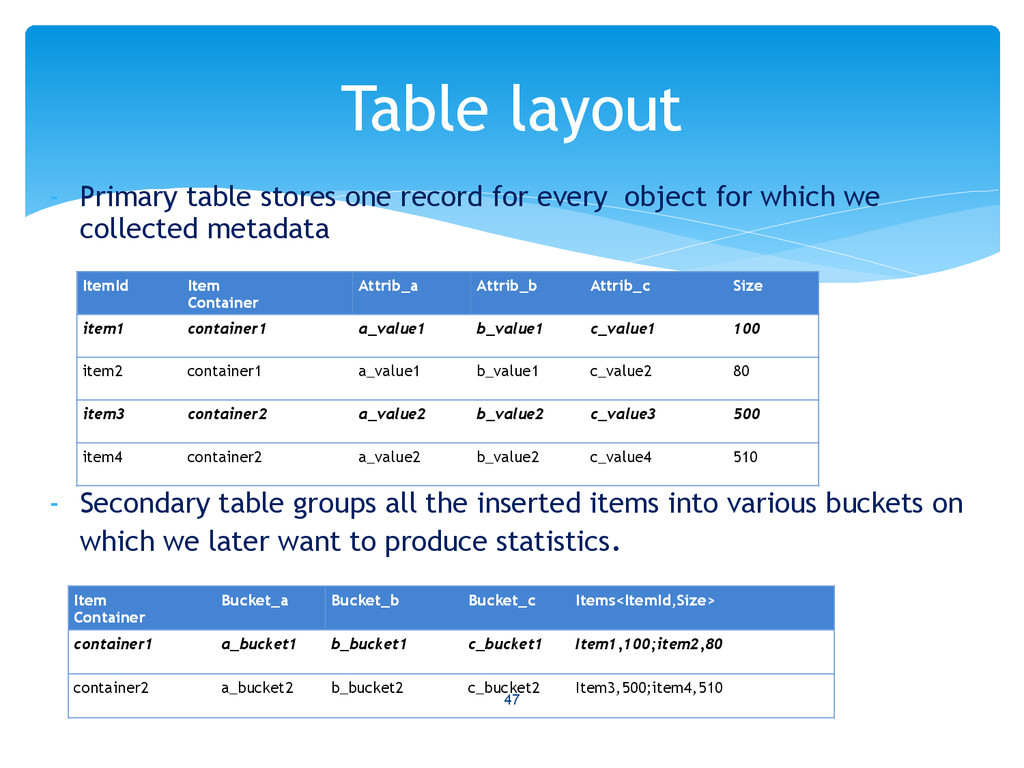
customers need to query and get various stats interactively (slice and dice the data to get stats) 46 Use Case In Brief Several billions of items Ingest Grouped in to buckets containing 100’s of millions of rows Primary C* Table Secondary C* Table Transform and aggregate 10’s of millions of items Searchable index in Elastic Search
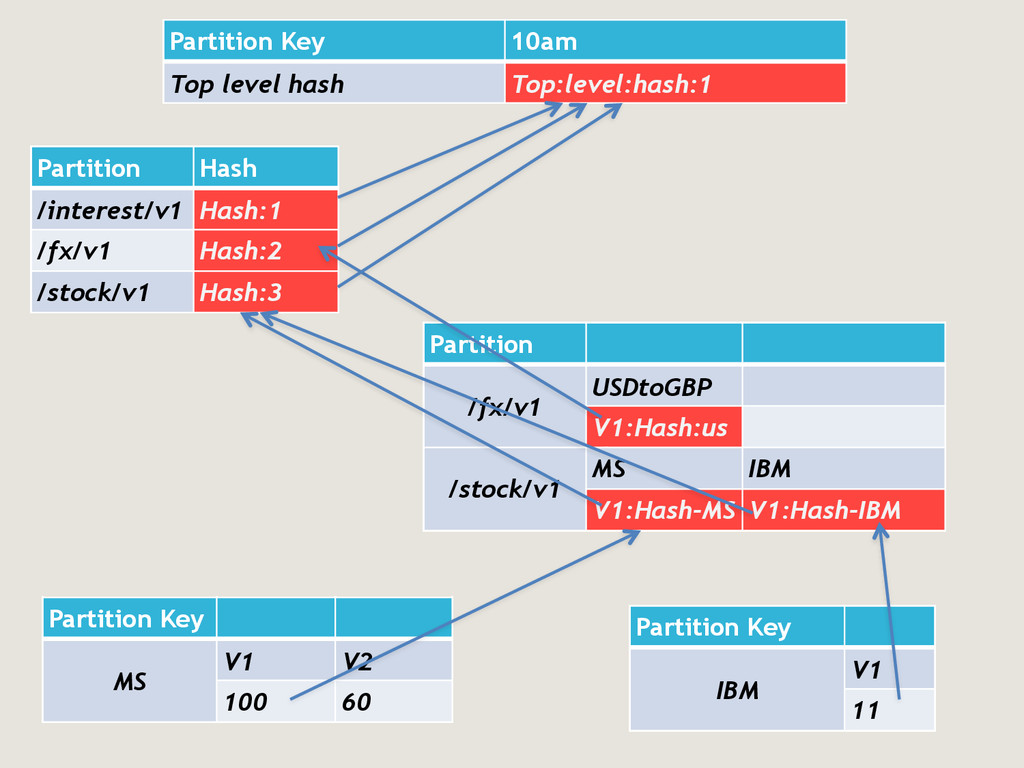
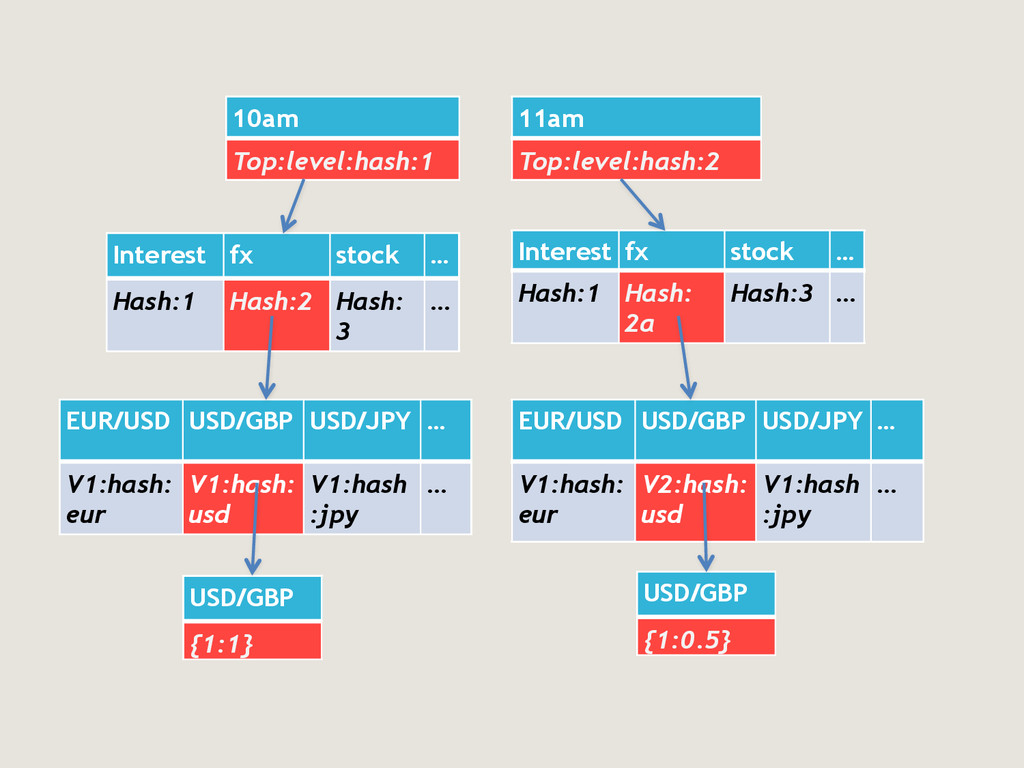
partition key and all columns except map of items as PK i.e. - PRIMARY KEY(ContainerId,Bucket-a,Bucket_b,Bucket_c) - This doesn’t works as it will create wide rows which means all the data for a Container is stored in one physical C* row. Initial solutions ContainerId1 Bucket_a1|Bucket_b1| bucket_c1 {itemId1,size1; itemid2,size2; …} Bucket_a1|Bucket_b2| bucket_c1 {itemId3,size3; itemid4,size4; …} Bucket_a1|Bucket_b1| bucket_c2 {itemId1,size1; itemid2,size2; …} All other combinations for ContainerId1 ContainerId2 Bucket_a2|Bucket_b1| bucket_c1 {itemId11,size11; itemid12,size2; …} Bucket_a2|Bucket_b2| bucket_c1 {itemId13,size13; itemid14,size14; …} Bucket_a2|Bucket_b1| bucket_c2 {itemId14,size21; itemid15,size22; …} All other combinations for ContainerId2
- During transformation phase when processing a container we could pick up relevant table for that container and iterate through it without need for any filtering - Disadvantage - Number of tables can grow very large (may be 20K per keyspace). - We gave it a try and found - Issues related to Table Schema not being propagated to all nodes quickly - Performance was never at par with what we got with one table Initial solutions
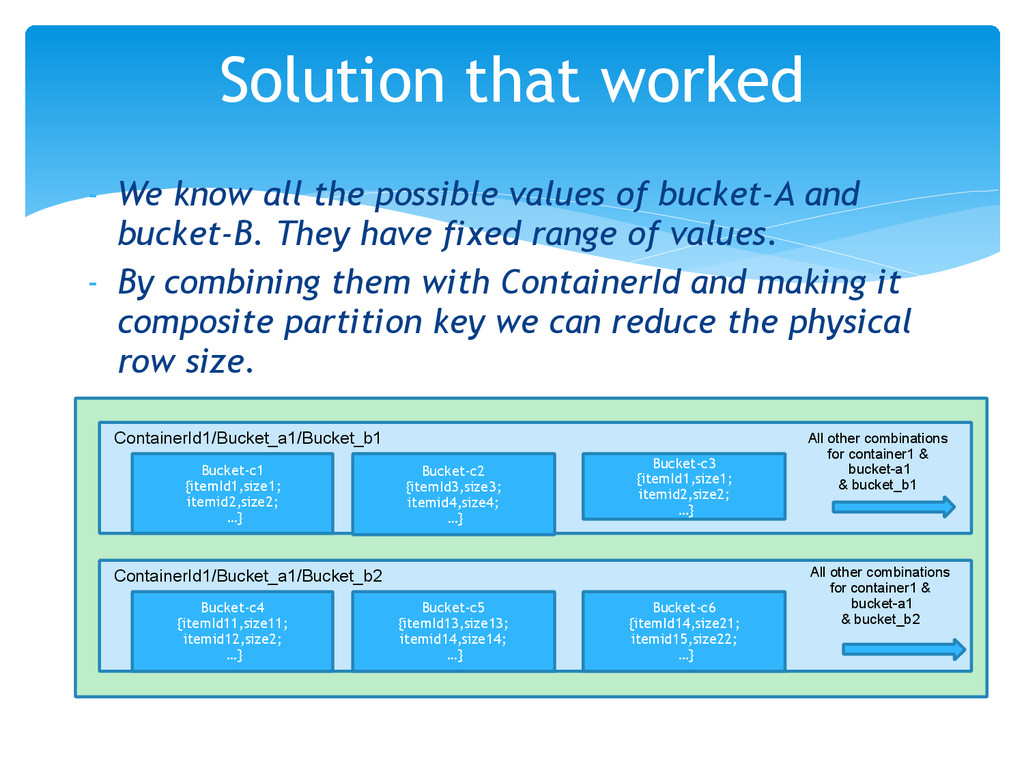
of bucket-A and bucket-B. They have fixed range of values. - By combining them with ContainerId and making it composite partition key we can reduce the physical row size. Solution that worked ContainerId1/Bucket_a1/Bucket_b1 Bucket-c1 {itemId1,size1; itemid2,size2; …} Bucket-c2 {itemId3,size3; itemid4,size4; …} Bucket-c3 {itemId1,size1; itemid2,size2; …} All other combinations for container1 & bucket-a1 & bucket_b1 Bucket-c4 {itemId11,size11; itemid12,size2; …} Bucket-c5 {itemId13,size13; itemid14,size14; …} Bucket-c6 {itemId14,size21; itemid15,size22; …} All other combinations for container1 & bucket-a1 & bucket_b2 ContainerId1/Bucket_a1/Bucket_b2
very wide rows - PRIMARY EY((ContainerId1,Bucket_a,Bucket_b),Bucket_c) - To enumerate all the rows for a container, we make queries using all the know combinations of bucket-A and bucket-B along with that container id. - For e.g. if there are 50 values in bucket A and 10 in bucket-B then we will make 500 queries for that container id one by one. - For container Id1 - For each bucketA - For each size bucketB - Get all rows from secondary table by containerId1, bucket_ValueA1, Bucket_valueB1 - Disadvantage is that some combinations of container and bucket values may not have any record but since these are lookups using partition key so they are extremely quick when no data is present. Solution that worked
the bottom of the cliff!" I am currently a development manager building retail POS and booking software for Neill technologies. I've been working with databases since Oracle v6, and since then, have done training, consultancy, development, analysis and most things in between. I'm currently 3 months into my NOSQL adventure.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![! Oleksii Mandrychenko, Engineer [email protected] Write-heavy security app using Cassandra](https://files.speakerdeck.com/presentations/2885533010f301324de07ae407783e32/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}