Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Python Idiomático
Search
Alejandro Gómez
October 20, 2013
Programming
160
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Python Idiomático
Alejandro Gómez
October 20, 2013
Other Decks in Programming
See All in Programming
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
540
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
1
240
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
2
600
PHP初心者セッション2026 〜生成AIでは見えない裏側を知る:今だからLAMPを通して仕組みを学ぶ〜
kashioka
0
620
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
120
ビデオ通話が繋がる0.2秒で何が起きているのか
supurazako
2
150
Foundation Models frameworkで画像分析
ryodeveloper
1
130
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
6.7k
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
530
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
820
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
990
生成AI導入の「期待外れ」を乗り越える ー 開発フロー改革が目指す、真の組織変革
starfish719
0
1.5k
Featured
See All Featured
WENDY [Excerpt]
tessaabrams
11
38k
What's in a price? How to price your products and services
michaelherold
247
13k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
How to build a perfect <img>
jonoalderson
1
5.8k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.3k
Crafting Experiences
bethany
1
230
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
270
From π to Pie charts
rasagy
0
240
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Utilizing Notion as your number one productivity tool
mfonobong
4
440
Fireside Chat
paigeccino
42
4k
Transcript
@dialelo | github.com/alejandrogomez Python Idiomático
Idiomático Perteneciente o conforme al modo de expresión de un
lenguaje (de programación).
import this
from __future__ import print_function
Unpacking
☹ favorite_color = [0xBA, 0xDA, 0x55] red = favorite_color[0] green
= favorite_color[1] blue = favorite_color[2]
☺ favorite_color = [0xBA, 0xDA, 0x55] red, green, blue =
favorite_color
3 head, *body, tail = range(5) # head == 0
# body == [1, 2, 3] # tail == 4
Slices
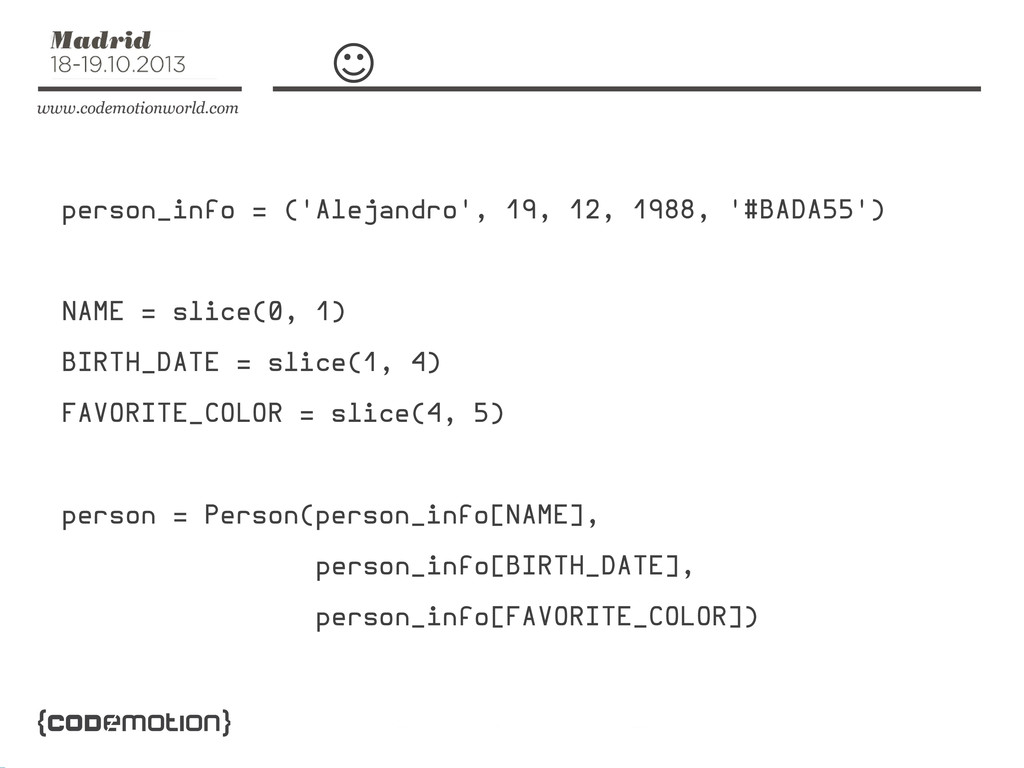
☹ person_info = ('Alejandro', 19, 12, 1988, '#BADA55') person =
Person(person_info[0], person_info[1:4], person_info[4])
☺ person_info = ('Alejandro', 19, 12, 1988, '#BADA55') NAME =
slice(0, 1) BIRTH_DATE = slice(1, 4) FAVORITE_COLOR = slice(4, 5) person = Person(person_info[NAME], person_info[BIRTH_DATE], person_info[FAVORITE_COLOR])
Strings
☹ family_members = 'Mikel' family_members += ', Ángel' family_members +=
', Isabel'
☺ names = ('Mikel', 'Ángel', 'Isabel') family_members = ', '.join(names)
Iteración Con índice
colors = ['red', 'green', 'blue']
☹ for i in range(len(colors)): print( colors[{}] : {} .format(i,
colors[i])) “ ”
☺ for i, color in enumerate(colors): print( colors[{}] : {}
.format(i, colors)) “ ”
Iteración A la inversa
☹ for color in colors[::-1]: print(color)
☺ for color in reversed(colors): print(color)
Iteración En orden
☺ for color in sorted(colors): print(color)
• ¿Necesitas definir el orden? – Prefiere key a cmp
– key sólo se llama una vez por elemento – cmp compara pares de elementos, no está en Python 3
☺ for color in sorted(colors, key=len): print(color)
from functools import cmp_to_key @cmp_to_key def my_comparison(a, b): # ...
Iteración iter
• iter tiene dos formas – iter(collection) → iterador –
iter(callable, sentinel) → iterador
☹ while True: value = read_value() if value is None:
break else: do_something(value)
☺ for value in iter(read_value, None): do_something(value)
Diccionarios Iterar
d = { 'red': 0xBA, 'green': 0xDA, 'blue': 0x55 }
# `for` itera sobre las claves for k in d: print(k)
☹☹ for k in d: print( {} : {} .format(k,
d[k])) “ ”
☹ for k, v in d.items(): print( {} : {}
.format(k, v)) “ ”
☺ for k, v in d.iteritems(): print( {} : {}
.format(k, v)) “ ”
3 for k, v in d.items(): print( {} : {}
.format(k, v)) “ ”
Diccionarios Construir
colors = ['red', 'green', 'blue'] values = [0xBA, 0xDA, 0x55]
☹ d = dict(zip(colors, values))
☺ from itertools import izip d = dict(izip(colors, values))
☺ from itertools import izip d = {c: v for
(c, v) in izip(colors, values)}
Diccionarios Combinar
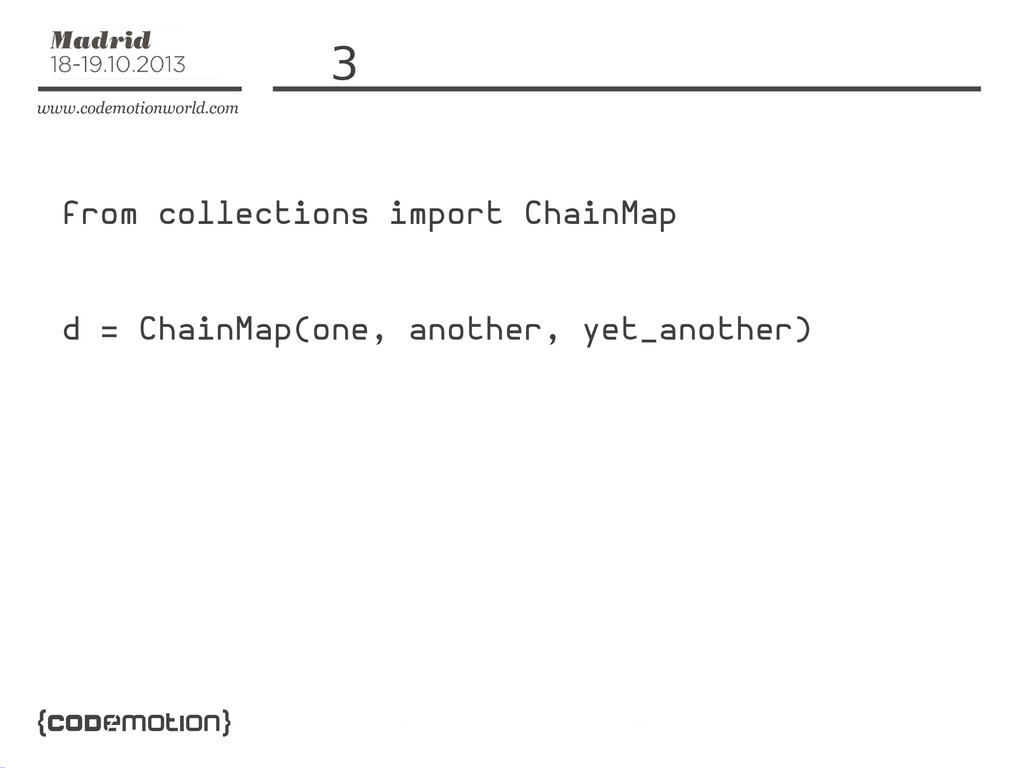
one = { 'foo': 42 } another = { 'bar':
None, 'baz': 8 } yet_another = { 'foo': 1, 'baz': 0 }
☹ merged = {} for d in (one, another, yet_another):
merged.update(d)
3 from collections import ChainMap d = ChainMap(one, another, yet_another)
Django from django.utils.datastructures import MergeDict # funciona al revés que
`collections.ChainMap` ☹ d = MergeDict(yet_another, another, one)
☺ from itertools import izip d = {c: v for
(c, v) in izip(colors, values)}
Funciones λ
people = [{ 'name': 'Zoe' }, { 'name': 'Bob' },
{ 'name': 'Alice' }]
☹ for p in sorted(people, key=lambda p: p['name']): print(p)
☺ from operators import itemgetter for p in sorted(people, key=itemgetter('name')):
print(p)
Funciones Argumentos
results = search('#codemotion', 10) # ¿qué es 10? results =
search('#codemotion', min_retweets=10) results = search('#codemotion', limit=10)
• Argumentos con nombre – ☺ Código más legible –
☺ Parámetros documentados – ☹ Coste en rendimiento
Funciones Valores de retorno
def run_tests(): # … return (passed, failed, skipped)
☹ passed, failed, skipped = run_tests()
from collections import namedtuple TestResults = namedtuple('TestResults', [ 'passed', 'failed',
'skipped']) def run_tests(): # … return TestResults(passed, failed, skipped)
☺ results = run_tests() # results.passed # results.failed # results.skipped
Context Managers
• Setup y teardown – Operaciones de entrada/salida – Locks
– Contexto
☹ f = open('readme.md') try: content = f.read() finally: f.close()
☺ with open('readme.md') as f: content = f.read()
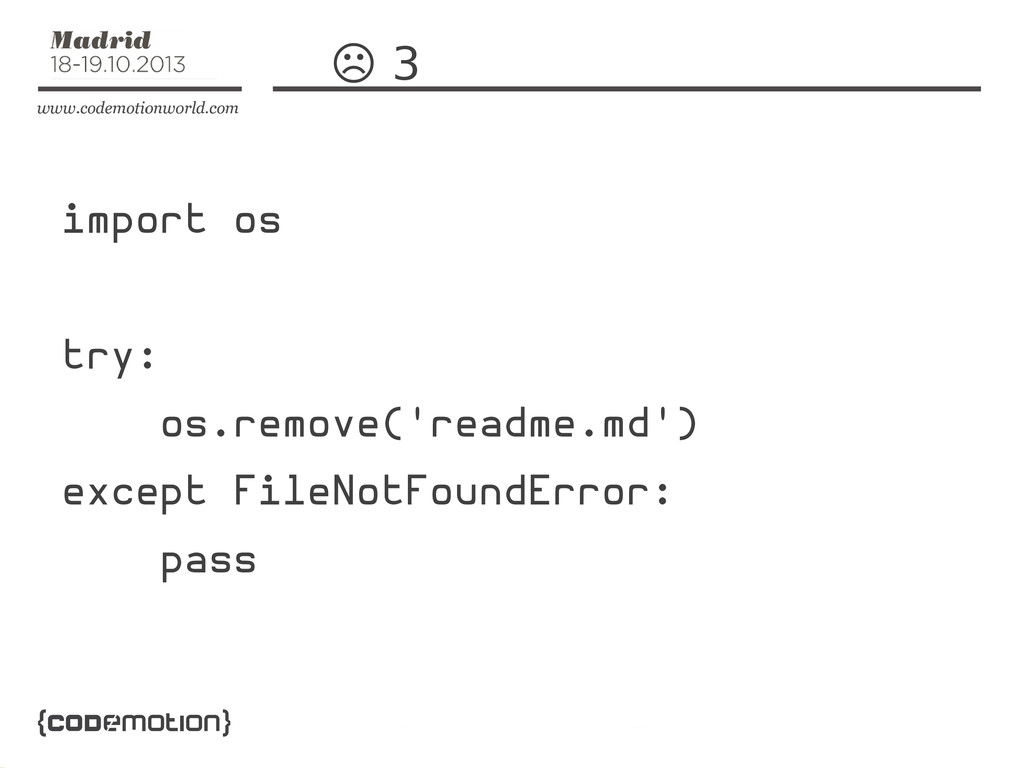
Excepciones
☹☹ import os try: os.remove('readme.md') except: pass
☹ import os try: os.remove('readme.md') except OSError: pass
☹ 3 import os try: os.remove('readme.md') except FileNotFoundError: pass
☺ >= 3.4 from contextlib import ignored with ignored(FileNotFoundError): os.remove('readme.md')
☺ < 3.4 from contextlib import contextmanager @contextmanager def ignored(*exceptions):
try: yield except exceptions: pass
Generator expressions
• Equivalentes a las comprensiones de listas pero perezosas –
Manipulación de secuencias en múltiples pasos – Secuencias como resultados intermedios
☹ uppercase_lines = [l.upper() for l in open('readme.md')] filtered_lines =
[l for l in uppercase_lines if l.startswith('#')] # ¿qué pasa si readme.md es un fichero ENORME? for l in filtered_lines: print(l)
☺ uppercase_lines = (l.upper() for l in open('readme.md')) filtered_lines =
(l for l in uppercase_lines if l.startswith('#')) # la iteración dirige la evaluación de las genexpressions for l in filtered_lines: print(l)
None
Escribid código bonito
¡Gracias!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![☹ favorite_color = [0xBA, 0xDA, 0x55] red = favorite_color[0] green](https://files.speakerdeck.com/presentations/bbbe94101b9a0131e3b23e3a86e044eb/slide_5.jpg){kind=link}
![☺ favorite_color = [0xBA, 0xDA, 0x55] red, green, blue =](https://files.speakerdeck.com/presentations/bbbe94101b9a0131e3b23e3a86e044eb/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![colors = ['red', 'green', 'blue']](https://files.speakerdeck.com/presentations/bbbe94101b9a0131e3b23e3a86e044eb/slide_15.jpg){kind=link}
![☹ for i in range(len(colors)): print( colors[{}] : {} .format(i,](https://files.speakerdeck.com/presentations/bbbe94101b9a0131e3b23e3a86e044eb/slide_16.jpg){kind=link}
![☺ for i, color in enumerate(colors): print( colors[{}] : {}](https://files.speakerdeck.com/presentations/bbbe94101b9a0131e3b23e3a86e044eb/slide_17.jpg){kind=link}
{kind=link}
![☹ for color in colors[::-1]: print(color)](https://files.speakerdeck.com/presentations/bbbe94101b9a0131e3b23e3a86e044eb/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![colors = ['red', 'green', 'blue'] values = [0xBA, 0xDA, 0x55]](https://files.speakerdeck.com/presentations/bbbe94101b9a0131e3b23e3a86e044eb/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![☹ for p in sorted(people, key=lambda p: p['name']): print(p)](https://files.speakerdeck.com/presentations/bbbe94101b9a0131e3b23e3a86e044eb/slide_49.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![☹ uppercase_lines = [l.upper() for l in open('readme.md')] filtered_lines =](https://files.speakerdeck.com/presentations/bbbe94101b9a0131e3b23e3a86e044eb/slide_71.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}