Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIエージェントの設計で注意するべきポイント6選
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Har1101
December 20, 2025
Programming
4.6k
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AIエージェントの設計で注意するべきポイント6選
JAWS-UG Presents AI Builders Dayでの登壇資料です
Har1101
December 20, 2025
More Decks by Har1101
See All by Har1101
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
500
Even G2とAWSで推しのエージェントを召喚しよう!
har1101
1
170
エージェンティックRAGにAWSで入門しよう!
har1101
9
2k
TypeScriptだけでAIエージェントを作る フロント・エージェント・インフラのフルスタック実践
har1101
7
1.7k
AgentCore Registry入門 ~マルチアカウントでどう使うの~
har1101
1
110
AgentCore×VPCでの設計パターンn選と勘所
har1101
4
560
AgentCore RuntimeからS3 Filesをマウントしてみる
har1101
4
720
AgentCore Session Storageで激安RAG作るためのあれやこれや
har1101
4
420
(技術的には)社内システムもOKなブラウザエージェントを作ってみた!
har1101
2
600
Other Decks in Programming
See All in Programming
技術記事、 専門家としてのプログラマ、 言語化
mizchi
14
7.5k
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
140
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
790
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
200
【SRE NEXT 2026 Lunch Session】一人目専任SREの立ち上げを加速する ― AIと進めたオンボーディングで2分を0.04秒にした話
pkshadeck
PRO
0
2.8k
yield再入門 #phpcon
o0h
PRO
0
540
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
2.7k
1年で人数1.5倍、PR数5.5倍増。 品質とアウトカムはどうなったか、 何が効いたか
ike002jp
0
140
5分で問診!Composer セキュリティ健康診断
codmoninc
0
340
LaravelLive Japan の裏方のすべて — 第188回 PHP勉強会@東京 (2026-06-24)
suguruooki
2
150
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
590
Featured
See All Featured
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
The Pragmatic Product Professional
lauravandoore
37
7.4k
Leo the Paperboy
mayatellez
8
1.9k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
320
Designing for Timeless Needs
cassininazir
1
370
Transcript
AIエージェントの設計で 注意するべきポイント6選 2025/12/20 (土) JAWS-UG Presents AI Builders Day 福地開
Who am I ? 福地 開 (ふくち はるき) @har1101mony 所属:JAWS-UG東京/NECソリューションイノベータ
年次:3年目 業務:LLM Engineer 選出:AWS Community Builders (AI Engineering) 2025 Japan AWS Jr.Champions 2025 Japan All AWS Certifications Engineers
今日話すこと ◆LLM組み込みシステム・AIエージェントシステムの設計について • 私が作っているAIエージェント • Architecture • Build • Context
• Domain • Evaluation • Fail-safe ※資料中で「AI」と記載しているものは「生成AI」とりわけ「LLM」のことを指します ※以降、LLM組み込みシステムを「AIエージェント」に含めます ※所属組織とは一切関係ない、私個人の意見・考えとなります
今日話すこと ◆LLM組み込みシステム・AIエージェントシステムの設計について • 私が作っているAIエージェント • Architecture・Context • Build・Evaluation・Fail-safe • Domain
※資料中で「AI」と記載しているものは「生成AI」とりわけ「LLM」のことを指します ※以降、LLM組み込みシステムを「AIエージェント」に含めます ※所属組織とは一切関係ない、私個人の意見・考えとなります
対象とレベル感 ◆本セッションの対象 • これからAIエージェントを構築していく(いきたい)方 • AI Builder入門者 ◆レベル感 • AWSのセッションレベルだと200-300の間くらい
※資料中で「AI」と記載しているものは「生成AI」とりわけ「LLM」のことを指します ※以降、LLM組み込みシステムを「AIエージェント」に含めます ※所属組織とは一切関係ない、私個人の意見・考えとなります
私が作っているAIエージェント • 私が作っているAIエージェント • Architecture・Context • Build・Evaluation・Fail-safe • Domain
私が作っているAIエージェント ◆レポート生成エージェント ◆セキュリティレビューエージェント ◆アウトプット集約エージェント ◆英会話練習エージェント(草案のみ) ※当然すべてAWS環境上で動いて(動かそうとして)います
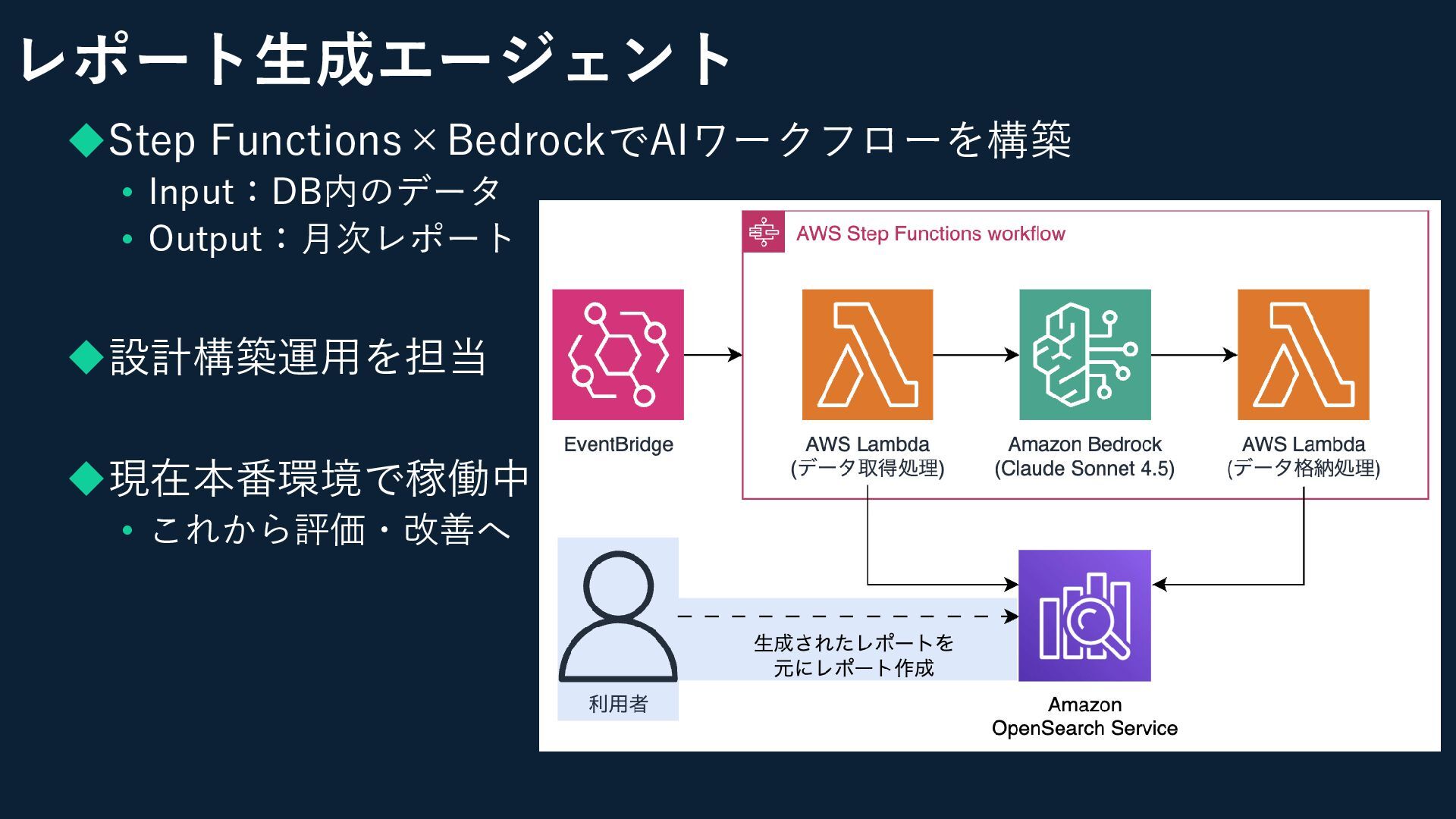
レポート生成エージェント ◆Step Functions×BedrockでAIワークフローを構築 • Input:DB内のデータ • Output:月次レポート ◆設計構築運用を担当 ◆現在本番環境で稼働中 •
これから評価・改善へ
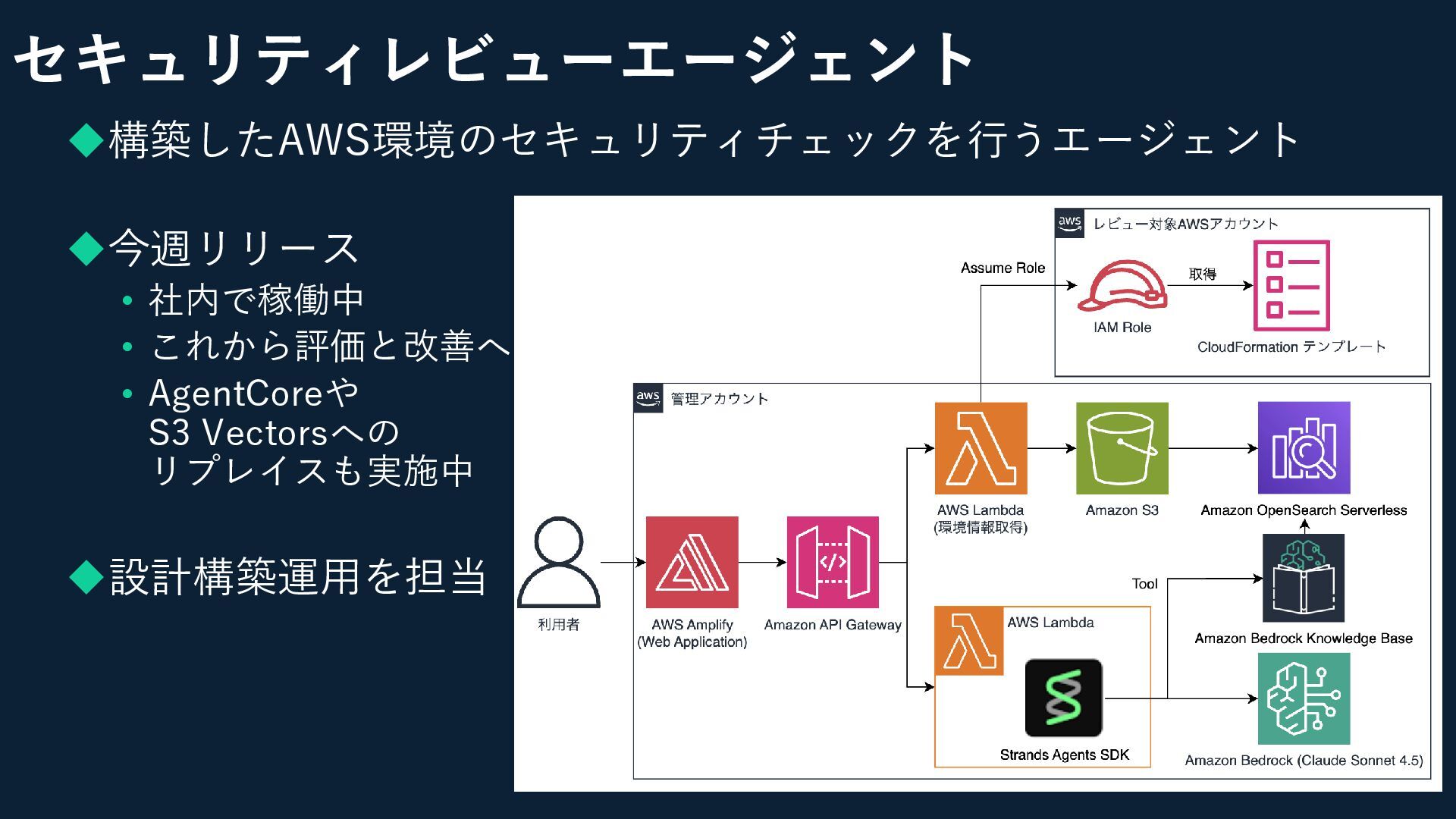
セキュリティレビューエージェント ◆構築したAWS環境のセキュリティチェックを行うエージェント ◆今週リリース • 社内で稼働中 • これから評価と改善へ • AgentCoreや S3
Vectorsへの リプレイスも実施中 ◆設計構築運用を担当
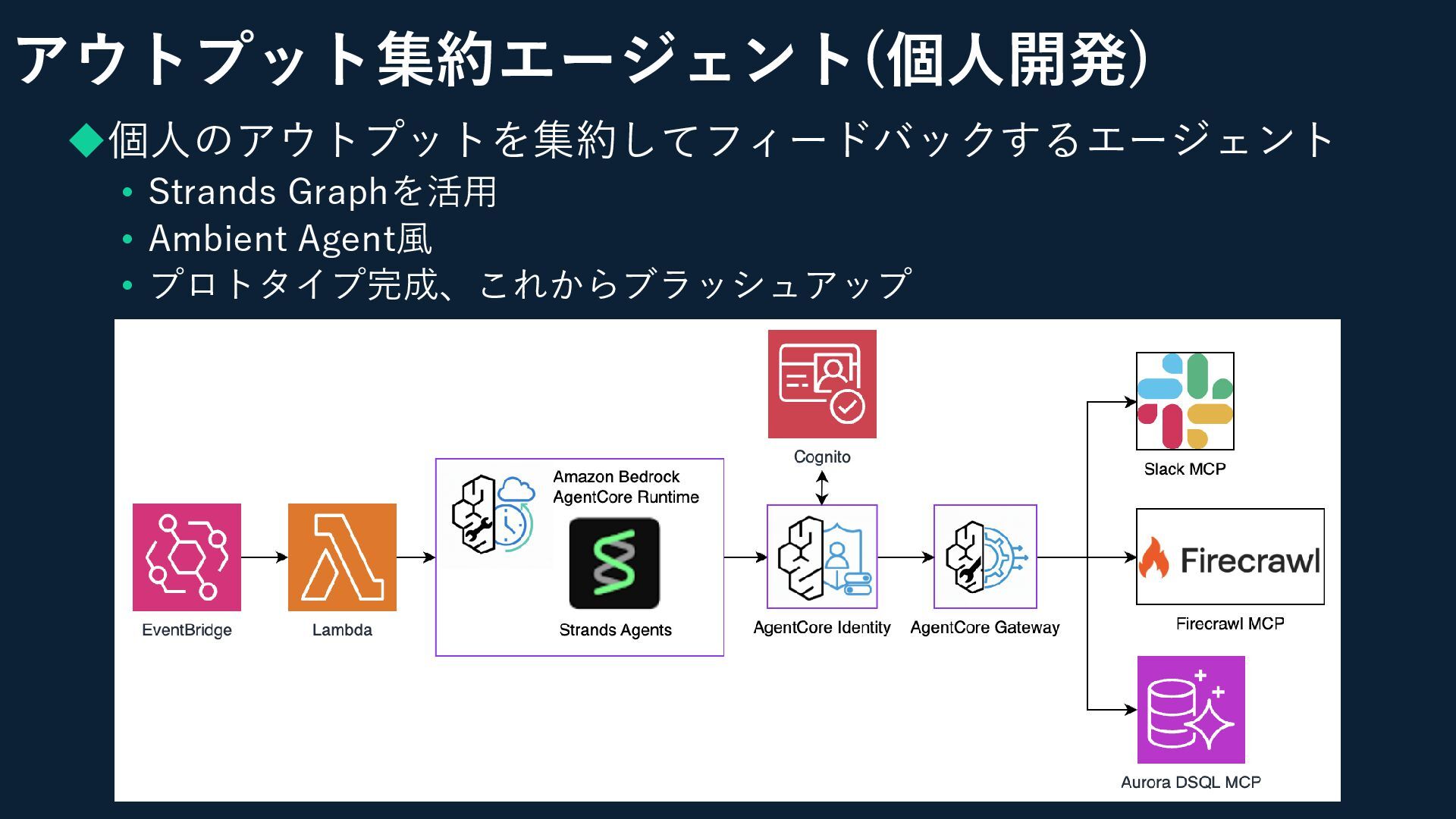
アウトプット集約エージェント(個人開発) ◆個人のアウトプットを集約してフィードバックするエージェント • Strands Graphを活用 • Ambient Agent風 • プロトタイプ完成、これからブラッシュアップ
私が作っているAIエージェント ◆レポート生成エージェント ◆セキュリティレビューエージェント ◆アウトプット集約エージェント ◆英会話練習エージェント(草案のみ) ※当然すべてAWS環境上で動いて(動かそうとして)います ◆ちょこちょこエージェントを作ってきた中での知見・学びなどを 共有させていただきます!
Architecture・Context ✓ 私が作っているAIエージェント • Architecture・Context • Build・Evaluation・Fail-safe • Domain
AIエージェントのアーキテクチャ ◆アーキテクチャは大きく2種類存在 • Anthropic社のブログ「Building Effective Agents」→ ◆エージェントは、LLM が独自のプロセスとツールの使用を 動的に指示し、タスクの達成方法を制御するシステムです。 ◆ワークフローは、LLM
とツールが事前定義されたコードパスを 通じてオーケストレーションされるシステムです。 ◆ここでは少し表現を変えて、以下のように記載 • エージェント→自律型エージェント • ワークフロー→ワークフロー型エージェント
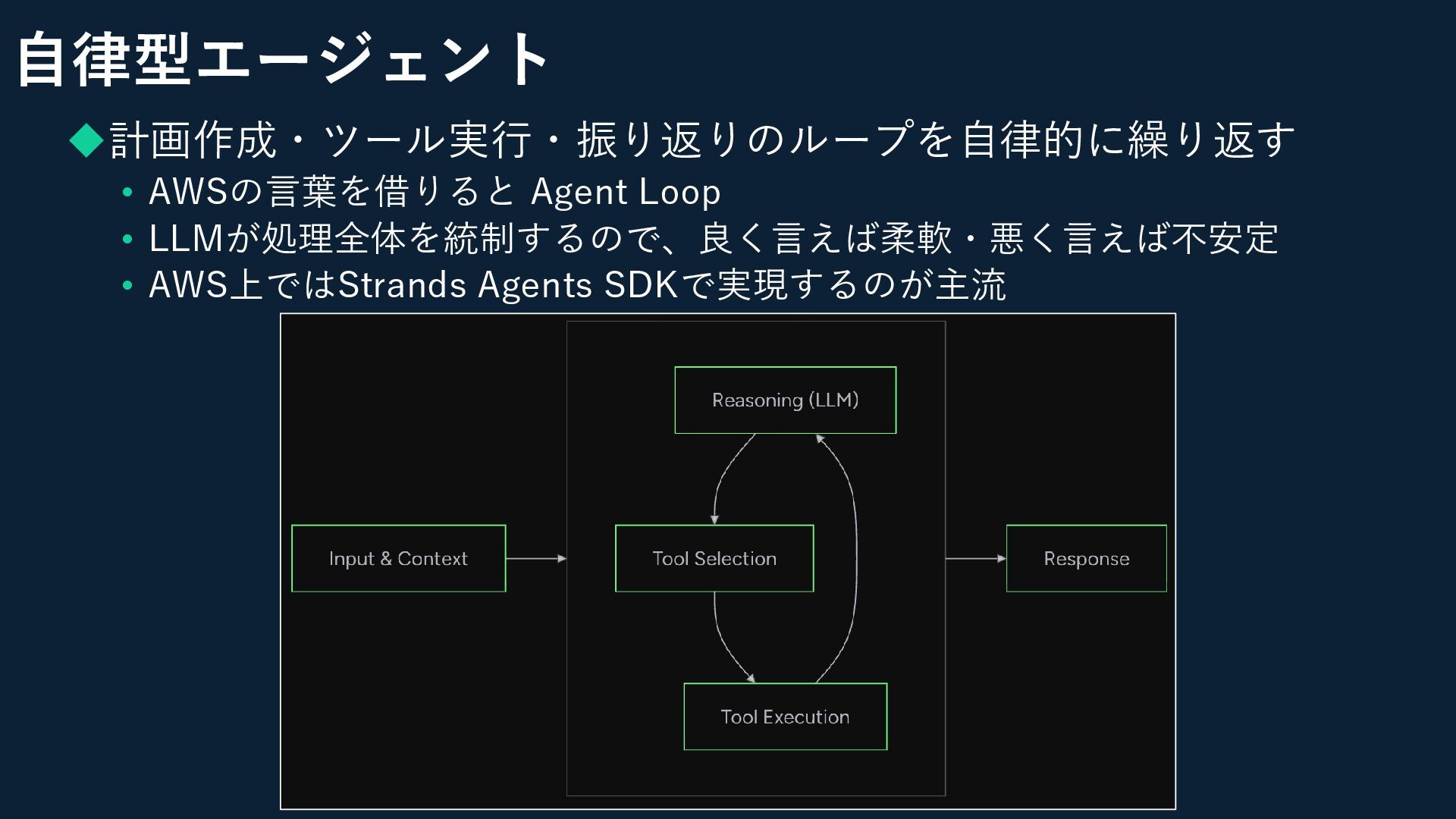
自律型エージェント ◆計画作成・ツール実行・振り返りのループを自律的に繰り返す • AWSの言葉を借りると Agent Loop • LLMが処理全体を統制するので、良く言えば柔軟・悪く言えば不安定 • AWS上ではStrands
Agents SDKで実現するのが主流
ワークフローエージェント ◆事前に定義したとおりに処理を実行し、その中でLLMが動く • 処理のオーケストレーターは事前に定義済み • 良く言えば安定して処理可能、悪く言えば柔軟性がない • AWS上ではStep Functions×Bedrockや、Bedrock Flowで実現可能
• エージェンティックワークフローというのもある
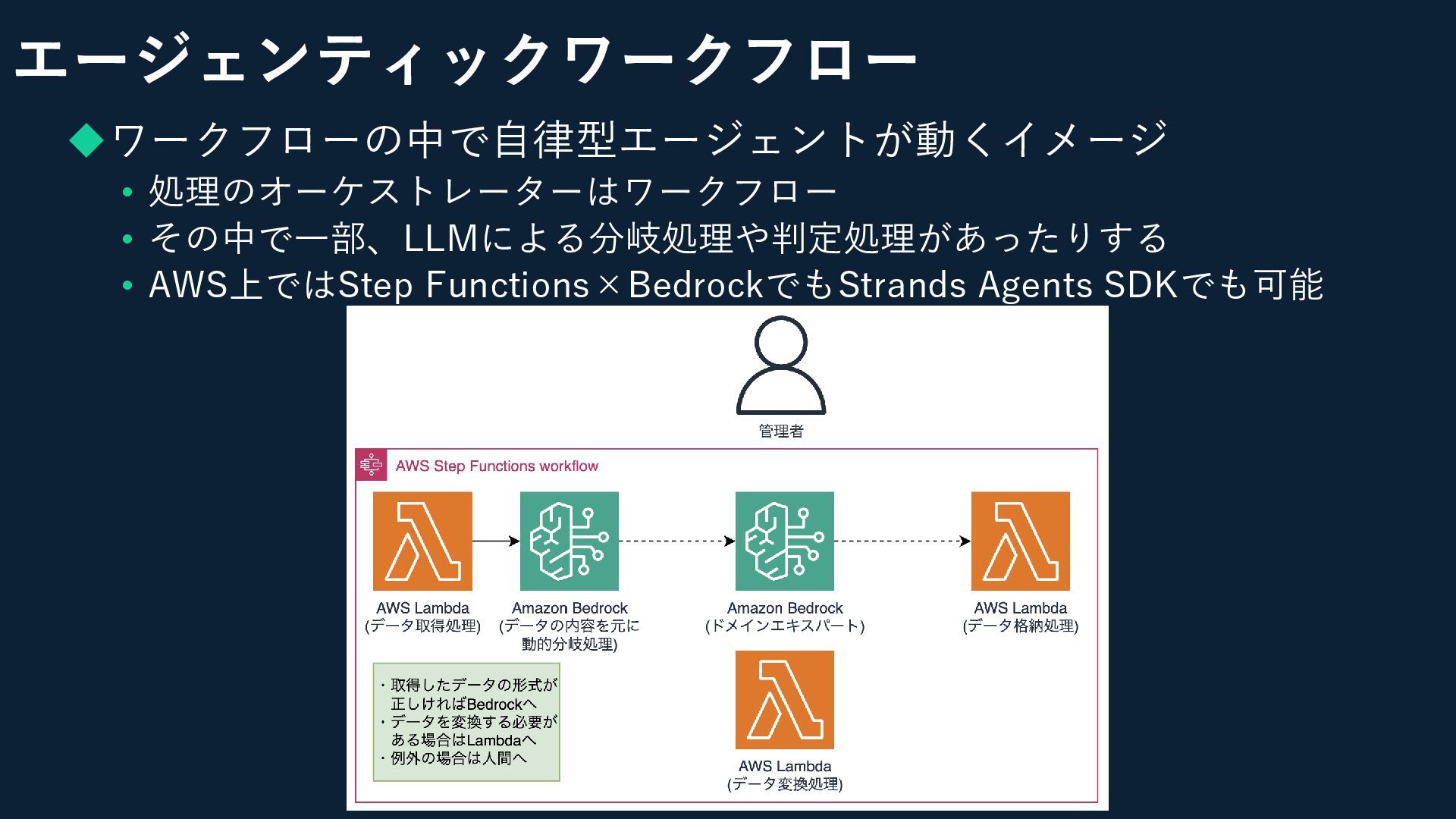
エージェンティックワークフロー ◆ワークフローの中で自律型エージェントが動くイメージ • 処理のオーケストレーターはワークフロー • その中で一部、LLMによる分岐処理や判定処理があったりする • AWS上ではStep Functions×BedrockでもStrands Agents
SDKでも可能
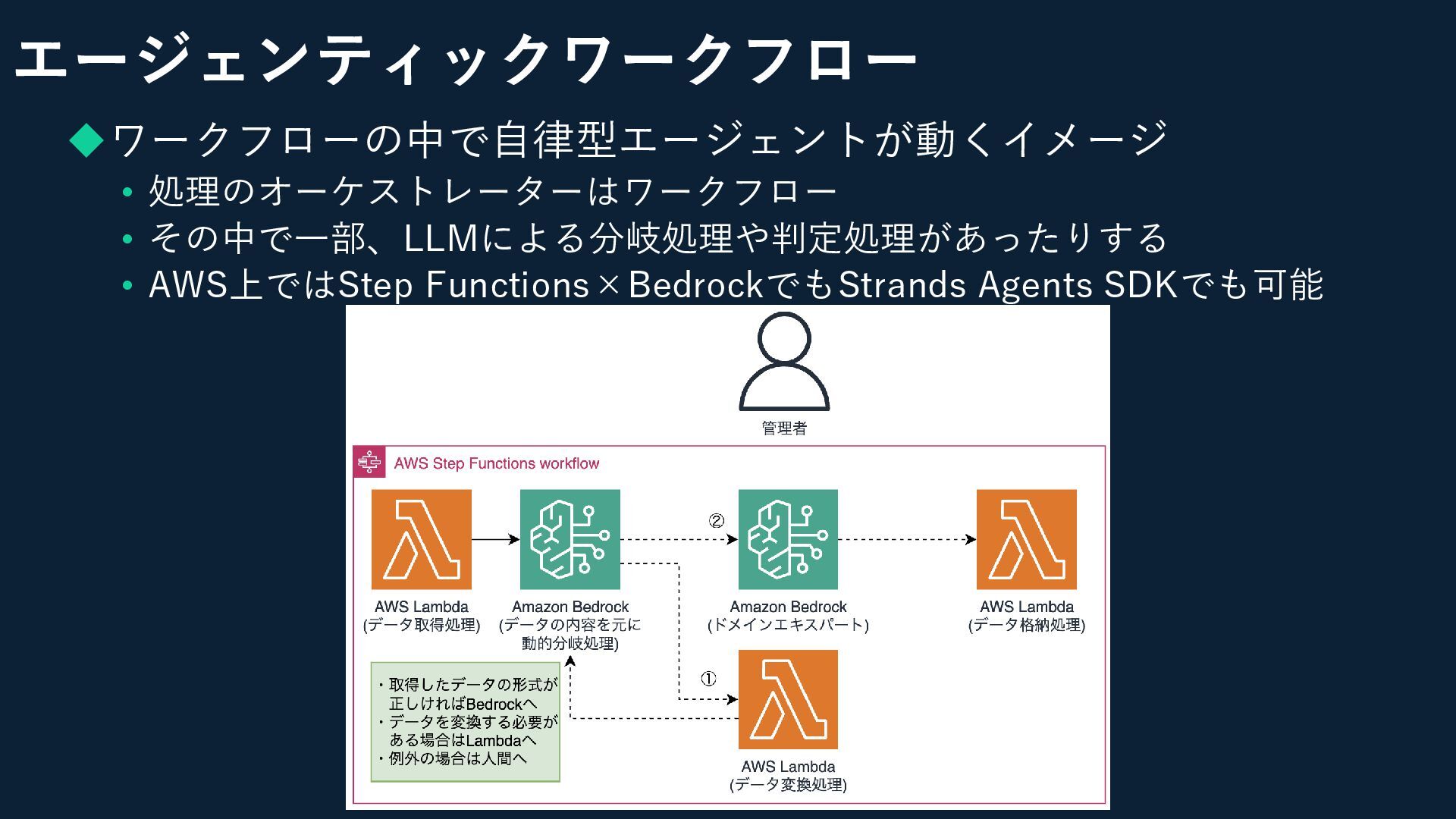
エージェンティックワークフロー ◆ワークフローの中で自律型エージェントが動くイメージ • 処理のオーケストレーターはワークフロー • その中で一部、LLMによる分岐処理や判定処理があったりする • AWS上ではStep Functions×BedrockでもStrands Agents
SDKでも可能
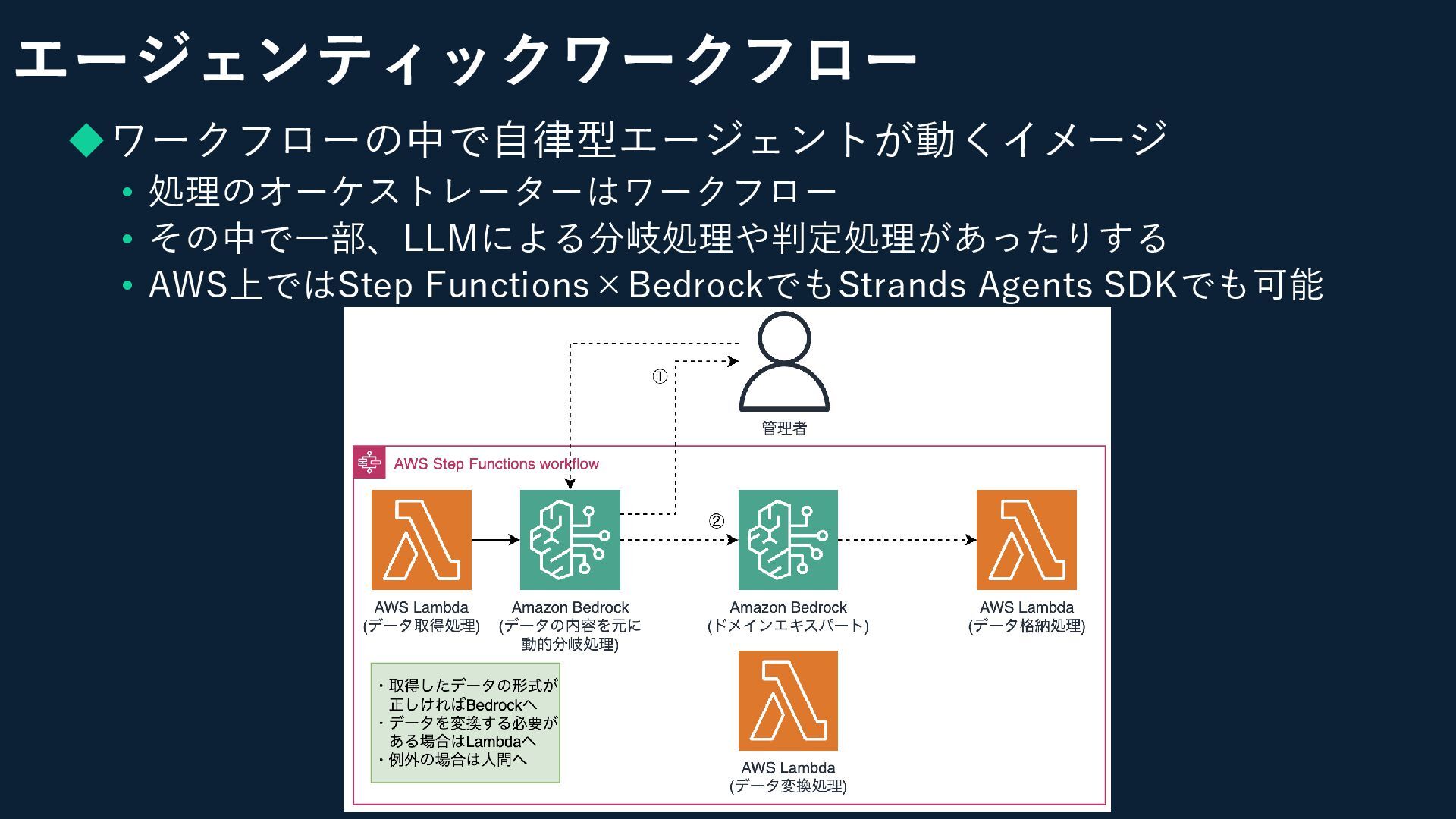
エージェンティックワークフロー ◆ワークフローの中で自律型エージェントが動くイメージ • 処理のオーケストレーターはワークフロー • その中で一部、LLMによる分岐処理や判定処理があったりする • AWS上ではStep Functions×BedrockでもStrands Agents
SDKでも可能
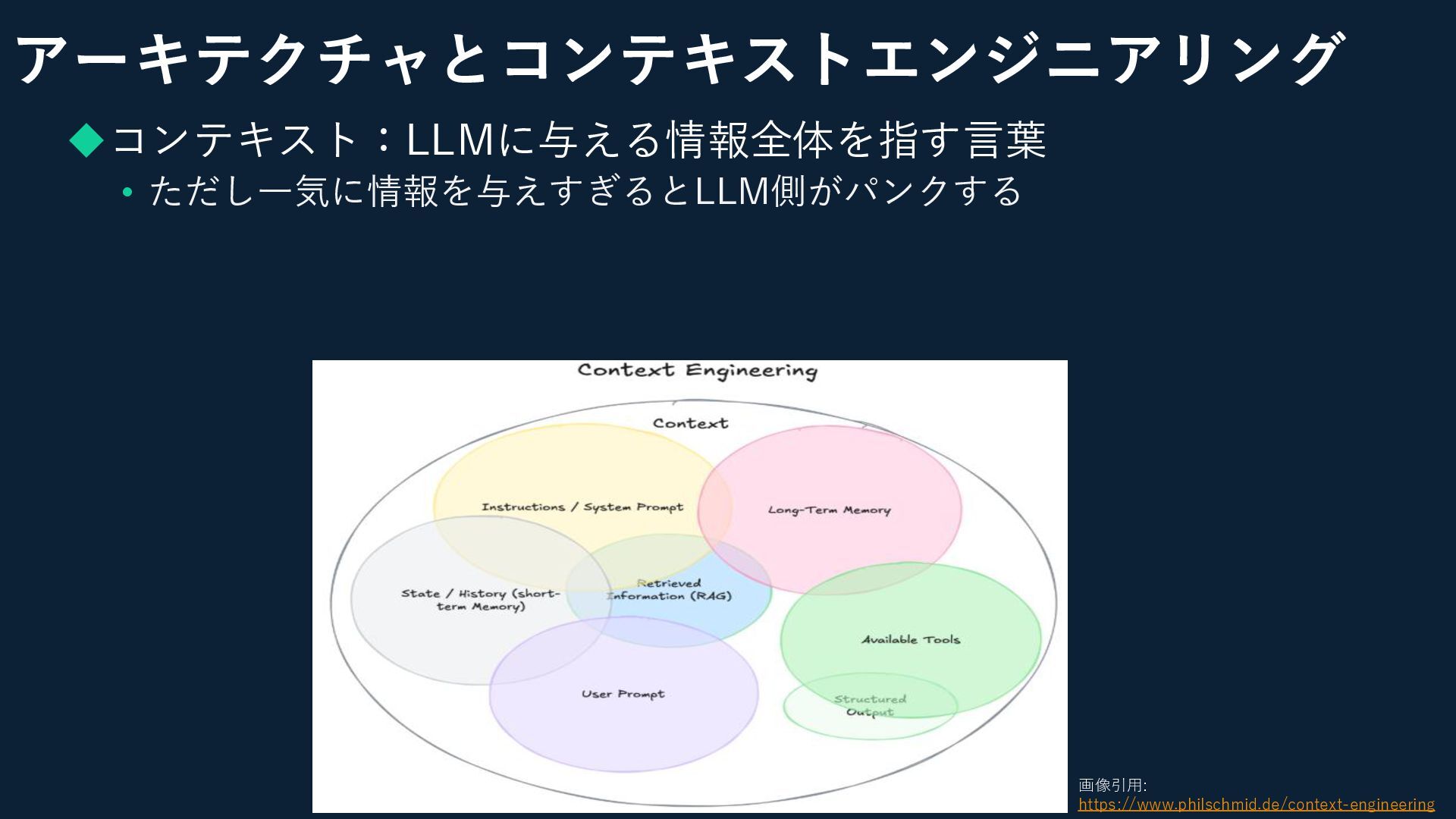
アーキテクチャとコンテキストエンジニアリング ◆コンテキスト:LLMに与える情報全体を指す言葉 • ただし一気に情報を与えすぎるとLLM側がパンクする 画像引用: https://www.philschmid.de/context-engineering
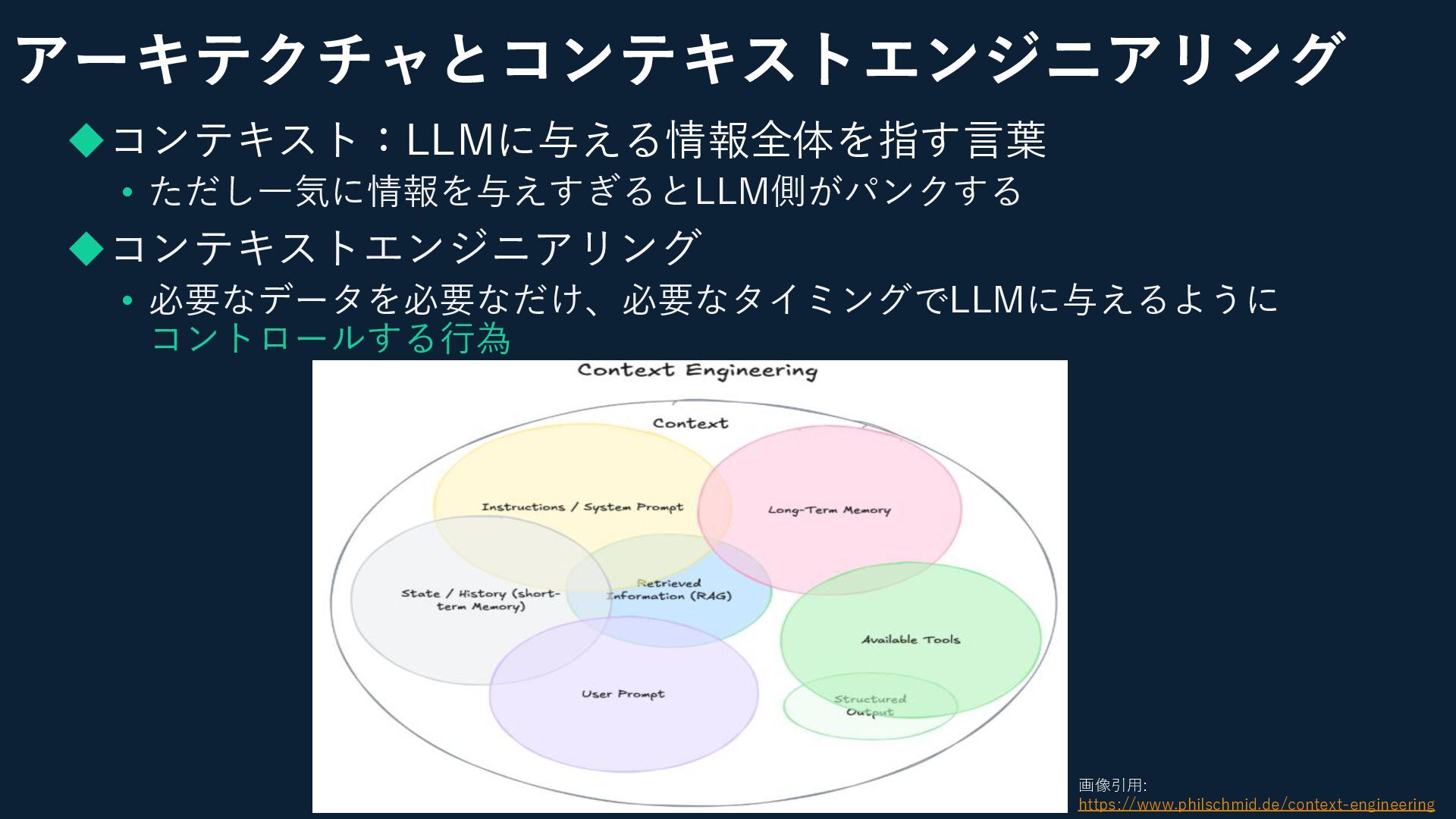
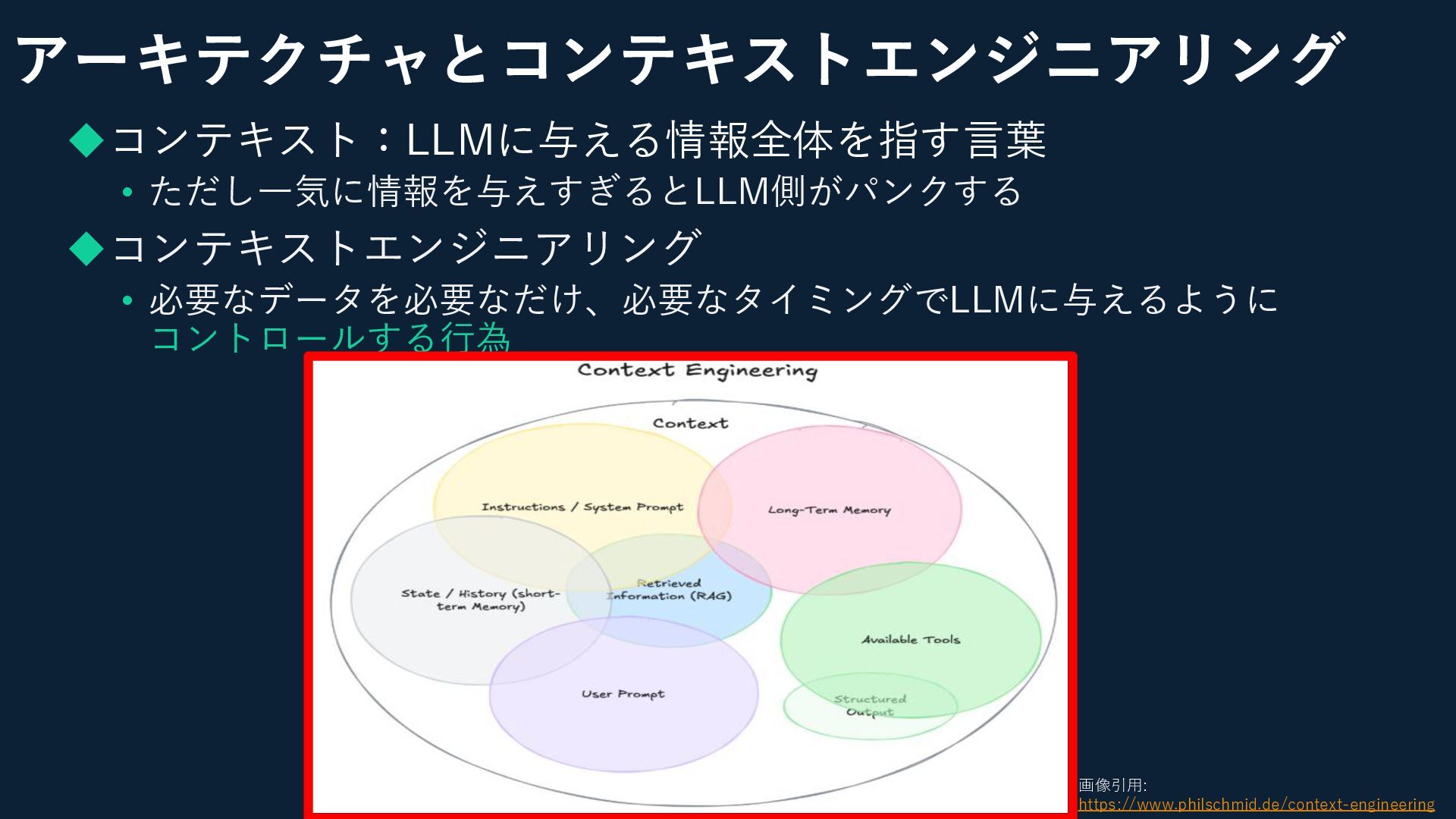
アーキテクチャとコンテキストエンジニアリング ◆コンテキスト:LLMに与える情報全体を指す言葉 • ただし一気に情報を与えすぎるとLLM側がパンクする ◆コンテキストエンジニアリング • 必要なデータを必要なだけ、必要なタイミングでLLMに与えるように コントロールする行為 画像引用: https://www.philschmid.de/context-engineering
アーキテクチャとコンテキストエンジニアリング ◆コンテキスト:LLMに与える情報全体を指す言葉 • ただし一気に情報を与えすぎるとLLM側がパンクする ◆コンテキストエンジニアリング • 必要なデータを必要なだけ、必要なタイミングでLLMに与えるように コントロールする行為 画像引用: https://www.philschmid.de/context-engineering
コンテキストの構成要素 ◆システムプロンプト: 会話中のモデルの動作を定義する最初の一連の指示 ◆ユーザープロンプト: ユーザーからの入力内容 ◆短期記憶: ユーザーとモデルの会話履歴 ◆長期記憶: 過去の会話から収集されたナレッジベース やり取りの内容をコンパクトにして保持する(例:
ユーザーの好み、過去のプロ ジェクトの概要、将来の使用のために記憶するように指示された事柄など) ◆外部情報: 特定の質問に答えるためにドキュメント・データベース・ APIなど から取得した外部の関連情報 ◆ツール: 利用できるすべてのツールの定義(例: current_time、send_email) 特にツールの名前と説明を指す ◆構造化出力: モデルの応答の形式の定義 (例: JSON オブジェクト) 引用: https://www.philschmid.de/context-engineering
コンテキストの構成要素 ◆システムプロンプト: 会話中のモデルの動作を定義する最初の一連の指示 ◆ユーザープロンプト: ユーザーからの入力内容 ◆短期記憶: ユーザーとモデルの会話履歴 ◆長期記憶: 過去の会話から収集されたナレッジベース やり取りの内容をコンパクトにして保持する(例:
ユーザーの好み、過去のプロ ジェクトの概要、将来の使用のために記憶するように指示された事柄など) ◆外部情報: 特定の質問に答えるためにドキュメント・データベース・ APIなどか ら取得した外部の関連情報 ◆ツール: 利用できるすべてのツールの定義(例: current_time、send_email) 特にツールの名前と説明を指す ◆構造化出力: モデルの応答の形式の定義 (例: JSON オブジェクト) ◆外部情報のコンテキスト取得方法を考える(他は後述) 引用: https://www.philschmid.de/context-engineering
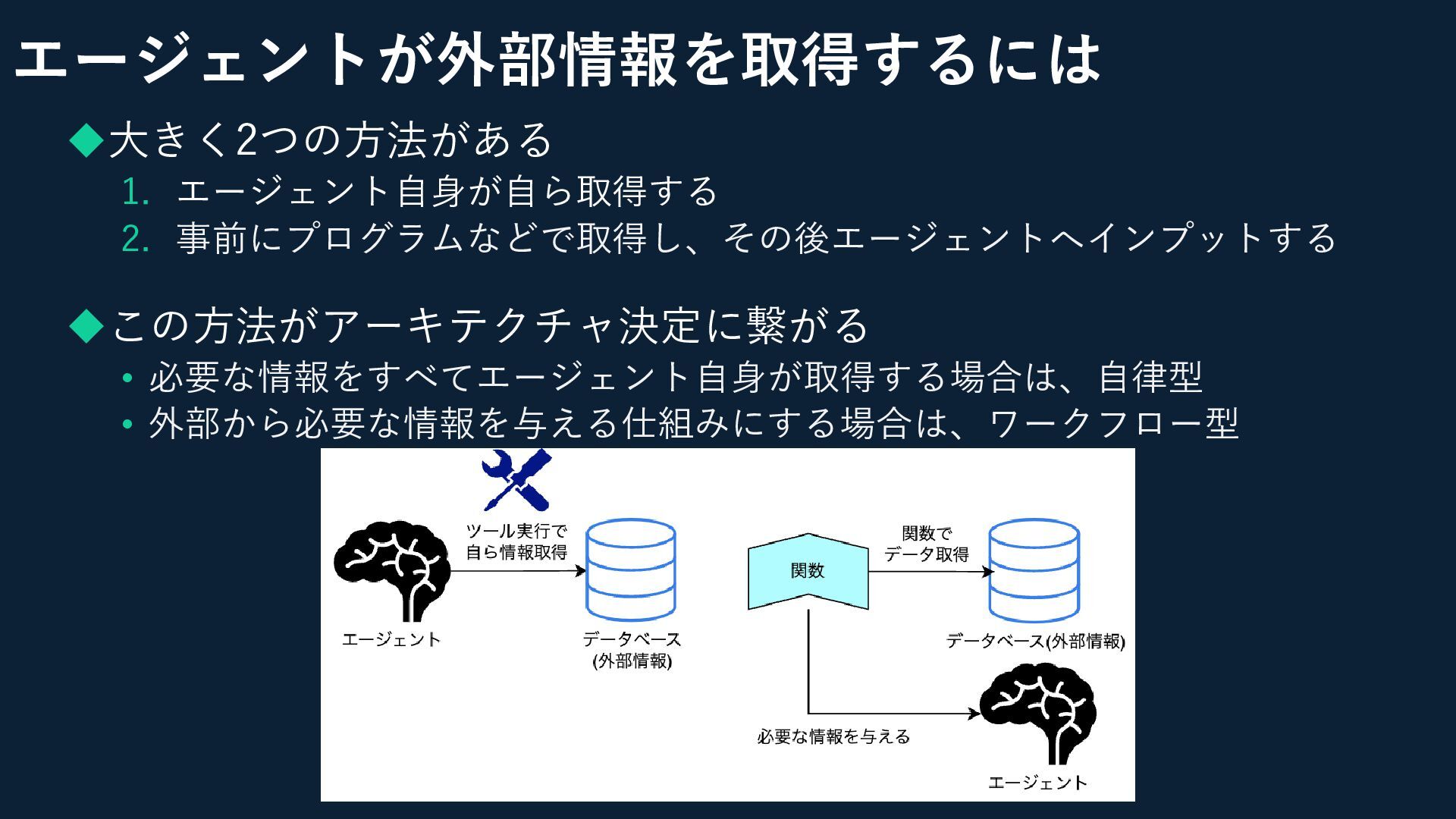
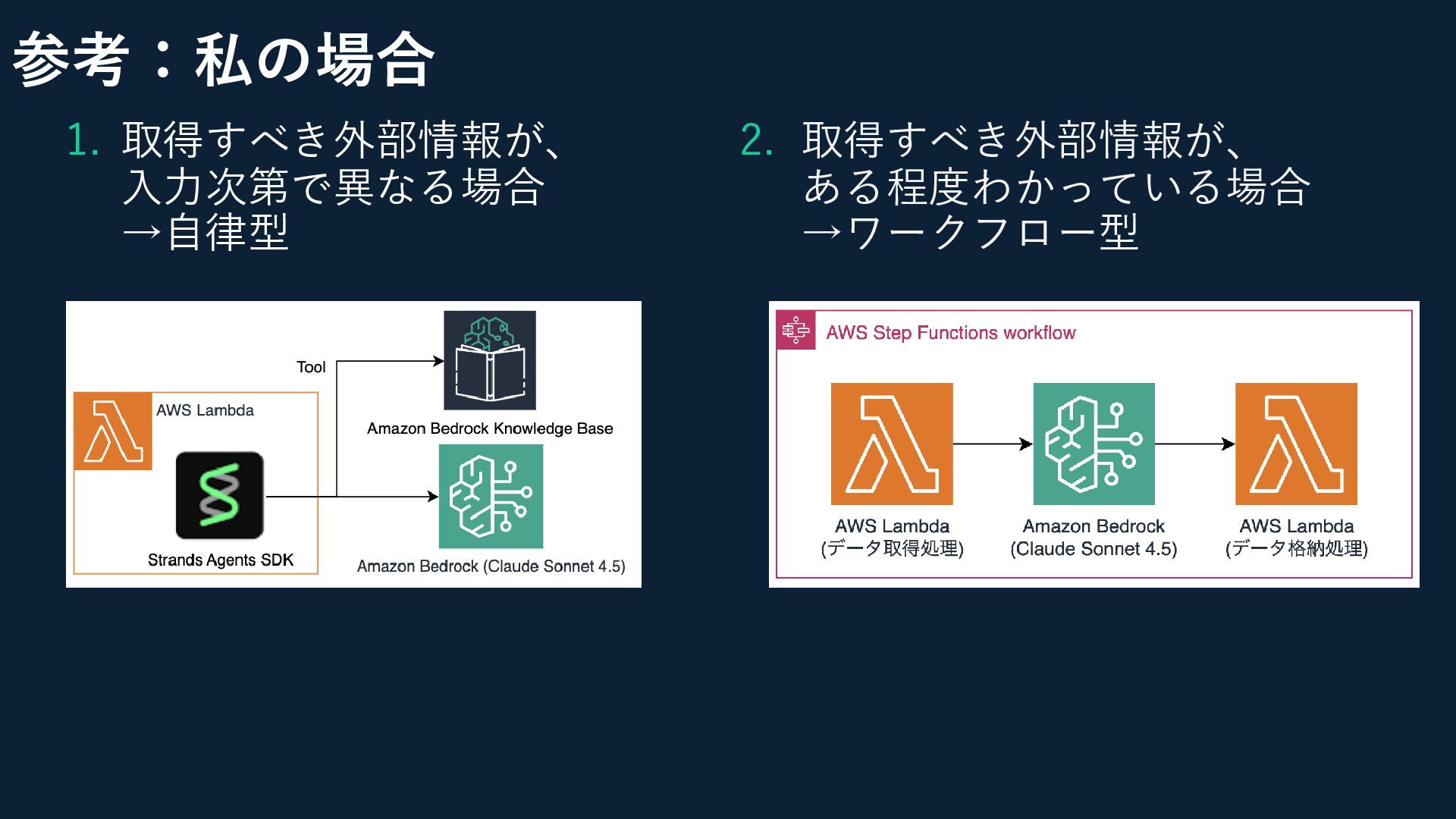
エージェントが外部情報を取得するには ◆大きく2つの方法がある 1. エージェント自身が自ら取得する 2. 事前にプログラムなどで取得し、その後エージェントへインプットする
エージェントが外部情報を取得するには ◆大きく2つの方法がある 1. エージェント自身が自ら取得する 2. 事前にプログラムなどで取得し、その後エージェントへインプットする ◆この方法がアーキテクチャ決定に繋がる • 必要な情報をすべてエージェント自身が取得する場合は、自律型 •
外部から必要な情報を与える仕組みにする場合は、ワークフロー型
余談:その他のコンテキスト構成要素 ◆外部情報以外のコンテキスト構成要素は、エージェント自身は取得できない ◆システムプロンプト: 開発者がエージェントに設定する ◆ユーザープロンプト: ユーザーの入力をエージェントにインプットする ◆短期/長期記憶: 開発者がエージェントのメモリー用DBを設定する ◆ツール: 開発者がエージェントに設定する
◆構造化出力: 開発者がエージェントに設定する 引用: https://www.philschmid.de/context-engineering
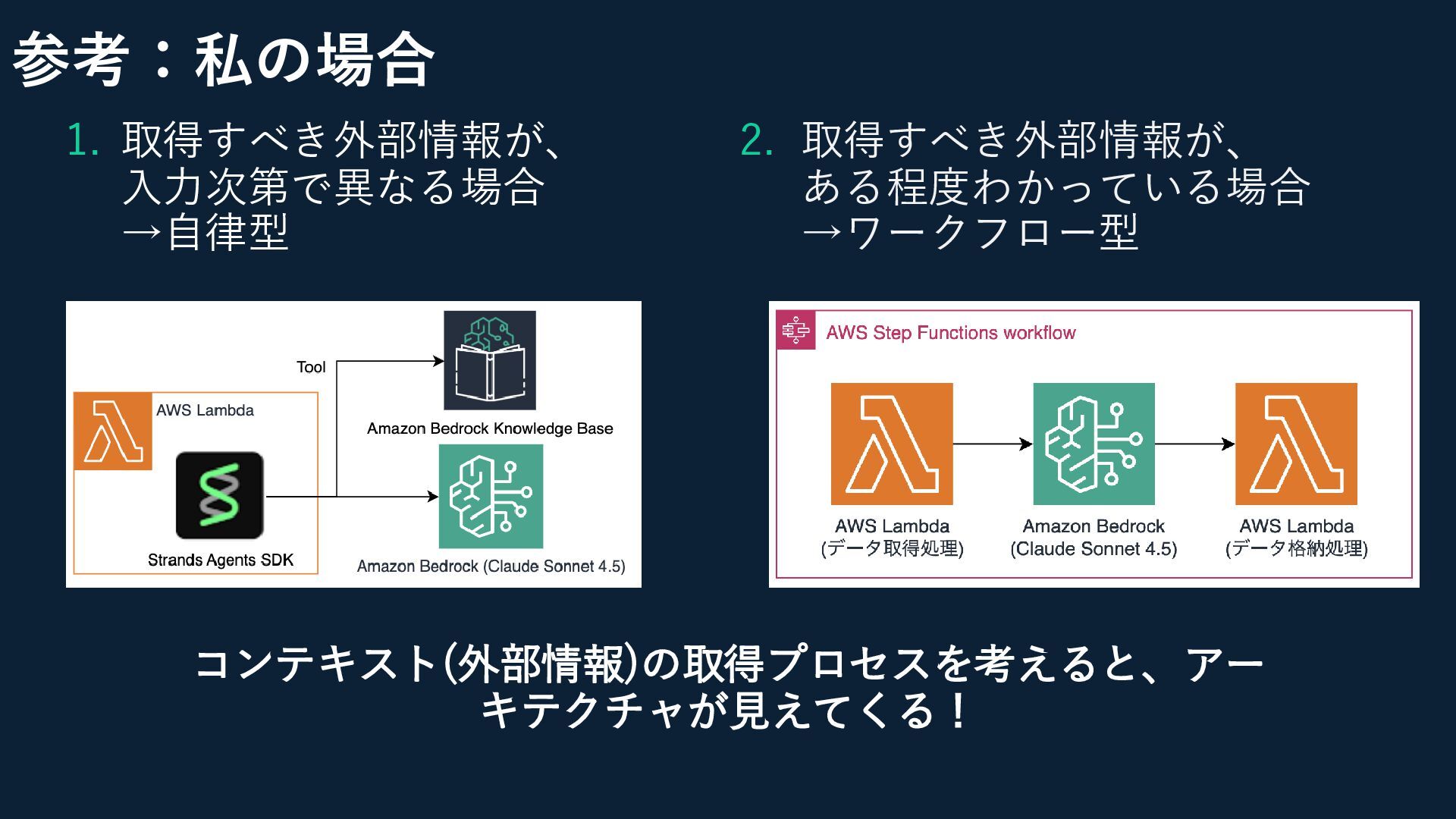
参考:私の場合 1. 取得すべき外部情報が、 入力次第で異なる場合 →自律型 2. 取得すべき外部情報が、 ある程度わかっている場合 →ワークフロー型
参考:私の場合 1. 取得すべき外部情報が、 入力次第で異なる場合 →自律型 2. 取得すべき外部情報が、 ある程度わかっている場合 →ワークフロー型 コンテキスト(外部情報)の取得プロセスを考えると、アー
キテクチャが見えてくる!
アーキテクチャに最適解はない ◆業務で使うならワークフロー or エージェンティックワークフロー派 • ただ、すべてを0から構築し運用・改善していくのは大変! • 後から入力値が増えた際のコード修正も大変 ◆Strandsチームとしてはモデル駆動エージェント •
「全体のオーケストレートに手間を掛けるべきではない、LLMに任せよう」 • とはいえ実業務で不確定要素(=LLMの判断)が増えるのは足踏みしてしまう ◆現状の大方針としては、 • コンテキストベースで考える • エージェントに対して何をインプットし、どんなことをして、 何をアウトプットしてもらいたいかを考え、定義する
Build・Evaluation・Fail-safe ✓ 私が作っているAIエージェント ✓ Architecture・Context • Build・Evaluation・Fail-safe • Domain
LLMOpsまで見据えた構築方法を考える ◆大前提:ユースケースや開発チームのスキルセットを優先 • チャットアプリでストリーミングレスポンスできない構成にするのはダメ
LLMOpsまで見据えた構築方法を考える ◆大前提:ユースケースや開発チームのスキルセットが大事 • チャットアプリでストリーミングレスポンスできない構成にするのはダメ ◆その上で、LLMOps(評価・改善)まで見据えた技術選定が重要 • 普通のアプリケーションの運用とは似て非なる世界 • 私の場合、設計・構築(評価の仕組みづくり含む)は自分の担当だが、 実運用は別チームが実施する、というケースがある
• この時は、運用チームのスキルセットも考慮しておく必要がある
Build: どうやってエージェントを動かす? ◆エージェントの構築方法 • フレームワークを使う(Strands Agents SDK, LangGraph, Mastra…) •
AWS SDKを使う(Converse API) • Bedrock Agentsを使う(最近あまりアップデートされていない…) ◆AWSへのデプロイ方法 • Bedrock AgentCore Runtime • Lambda • ECS/EKS • Step Functions/Lambda Durable Function ◆自分たちのチーム事情・要件に合わせて選ぶ • 判断するためにも、好奇心を持って触ってみることが重要
Evaluation: 評価って何? ◆大前提:AIが生成した回答の正解は1つではない • (例)世界で一番高い山は?という問いに対して…
Evaluation: 評価って何? ◆大前提:AIが生成した回答の正解は1つではない • (例)世界で一番高い山は?という問いに対して… AI「エベレストです」→正解 AI「ヒマラヤ山脈にあるエベレストです。その標高は8848mで〜」→正解 AI「1位はエベレスト、2位はK2、3位はカンチェンジュンガです」→正解
Evaluation: 評価って何? ◆大前提:AIが生成した回答の正解は1つではない • (例)世界で一番高い山は?という問いに対して… AI「エベレストです」→正解 AI「ヒマラヤ山脈にあるエベレストです。その標高は8848mで〜」→正解 AI「1位はエベレスト、2位はK2、3位はカンチェンジュンガです」→正解 • だが、どの回答を求めているかは利用者による
Evaluation: 評価って何? ◆大前提:AIが生成した回答の正解は1つではない • (例)世界で一番高い山は?という問いに対して… AI「エベレストです」→正解 AI「ヒマラヤ山脈にあるエベレストです。その標高は8848mで〜」→正解 AI「1位はエベレスト、2位はK2、3位はカンチェンジュンガです」→正解 • だが、どの回答を求めているかは利用者による
◆評価:AIの回答において「何を正解とするか」を定める行為 • 人間側で「正解」を設定し、そこからどのくらい差が生じているかを 定性的・定量的に判断する必要がある • 回答に有害な内容やハルシネーションが含まれていないかをチェックする (責任あるAI)
Evaluation: 評価って何? ◆大前提:AIが生成した回答の正解は1つではない • (例)世界で一番高い山は?という問いに対して… AI「エベレストです」→正解 AI「ヒマラヤ山脈にあるエベレストです。その標高は8848mで〜」→正解 AI「1位はエベレスト、2位はK2、3位はカンチェンジュンガです」→正解 • だが、どの回答を求めているかは利用者による
◆評価:AIの回答において「何を正解とするか」を定める行為 • 人間側で「正解」を設定し、そこからどのくらい差が生じているかを 定性的・定量的に判断する必要がある • 回答に有害な内容やハルシネーションが含まれていないかをチェックする (責任あるAI) • 「評価は継続的な道のりである(Evals is a continuous journey)」
自律型エージェントの評価は更に大変!? ◆シンプルなワークフローであれば、回答を評価するだけでOK
自律型エージェントの評価は更に大変!? ◆シンプルなワークフローであれば、回答を評価するだけでOK ◆自律型エージェントでは、エージェントの振る舞いも評価しよう • ツールを使うタイミングや回数は適切か? • プラン作成や思考は正しく行えていたか? • 検索クエリは適切だったか? •
最終的に生成した回答は適切だったか? etc…
自律型エージェントの評価は更に大変!? ◆シンプルなワークフローであれば、回答を評価するだけでOK ◆自律型エージェントでは、エージェントの振る舞いも評価しよう • ツールを使うタイミングや回数は適切か? • プラン作成や思考は正しく行えていたか? • 検索クエリは適切だったか? •
最終的に生成した回答は適切だったか? etc… ◆自律的に動く部分が多いほど、評価が難しい • 全部エージェント自身で考えて動くため、性能を上げたければ 細かくチェックする必要がある(マルチエージェントの場合は…もっと大変!?)
2種類の評価方法 ◆オフライン評価 • 用意した模範解答と、AIが出力した回答を照らし合わせる • プロンプト・モデル・パラメータなどを変更する前後で比較する • LLM as a
Judge など、AI自身に回答を評価させる手法もある • MCP Server as a Judge も選択肢の1つ https://speakerdeck.com/pharma_x_tech/llmapurikesiyonnoping-jia-toji-sok-de-gai-shan https://speakerdeck.com/licux/mcp-server-as-a-judge
2種類の評価方法 ◆オフライン評価 • 用意した模範解答と、AIが出力した回答を照らし合わせる(できれば数値化) • プロンプト・モデル・パラメータなどを変更する前後で比較する • LLM as a
Judge など、AI自身に回答を評価させる手法もある • MCP Server as a Judge も選択肢の1つ ◆オンライン評価 • 人間(特に利用者)が実際に使った上で結果を評価する(Good/Badなど) • AgentCore EvaluationsはLLMでのオンライン評価が可能 • よりリアルなフィードバックを得られるので、可能な限り実施したい →結局、使う人間の感覚次第で良いか悪いかは決まる (コーディングエージェントにおいてベンチマークばかり見るのではなく 自分で試してみろ、と言われていることからも)
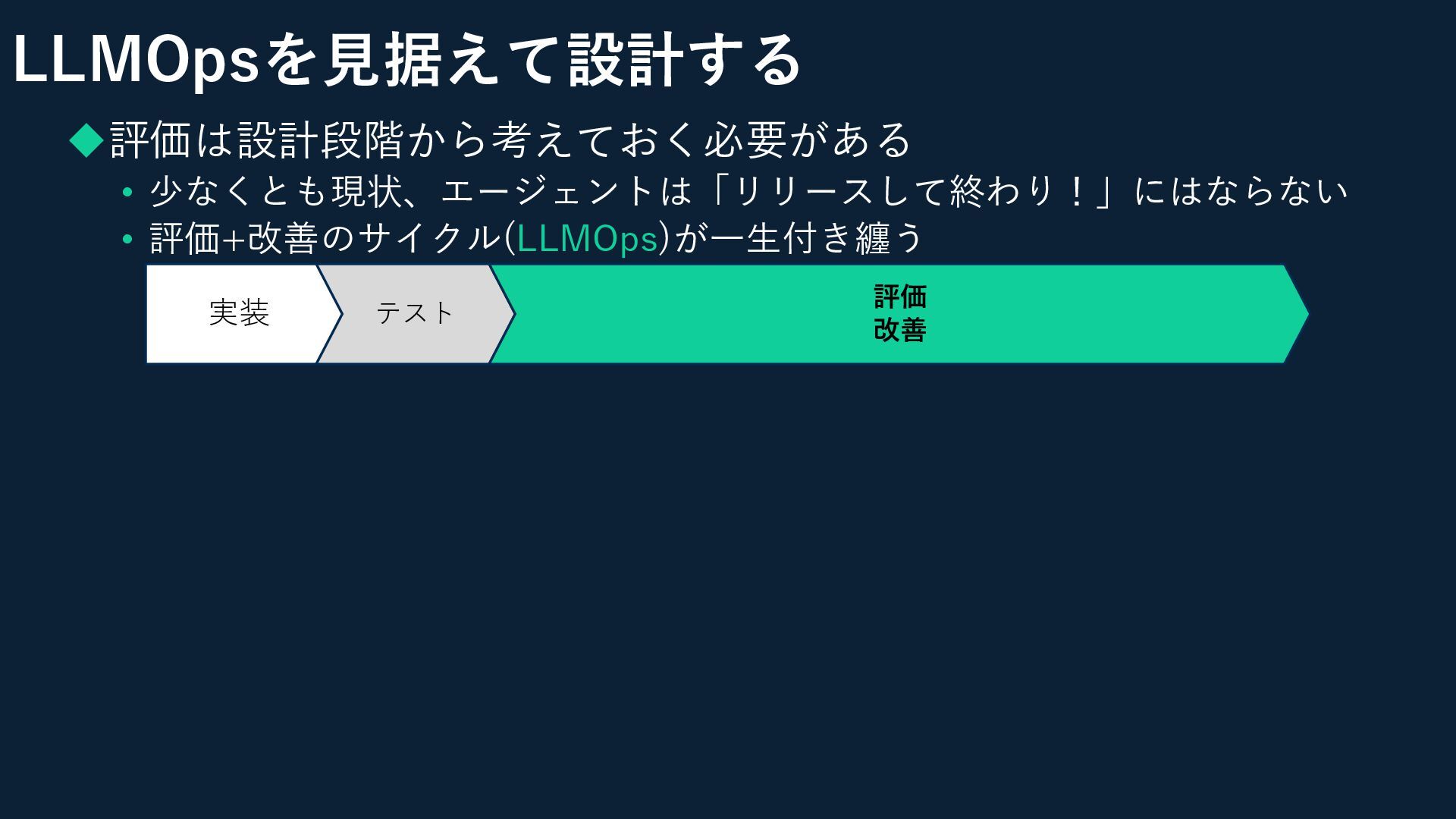
LLMOpsを見据えて設計する ◆評価は設計段階から考えておく必要がある • 少なくとも現状、エージェントは「リリースして終わり!」にはならない • 評価+改善のサイクル(LLMOps)が一生付き纏う 実装 テスト 評価 改善
LLMOpsを見据えて設計する ◆評価は設計段階から考えておく必要がある • 少なくとも現状、エージェントは「リリースして終わり!」にはならない • 評価+改善のサイクル(LLMOps)が一生付き纏う ◆具体的に「どうやって評価を行うか」も考えておく • 何をもって「正解」とするのか? •
2種類ある評価手法をどのくらいの比率で行う? • LLMOps用のツールは何か使う? • お客様環境用のエージェントを作る場合は、 精度向上のためのフィードバック協力を要請しておく 実装 テスト 評価 改善
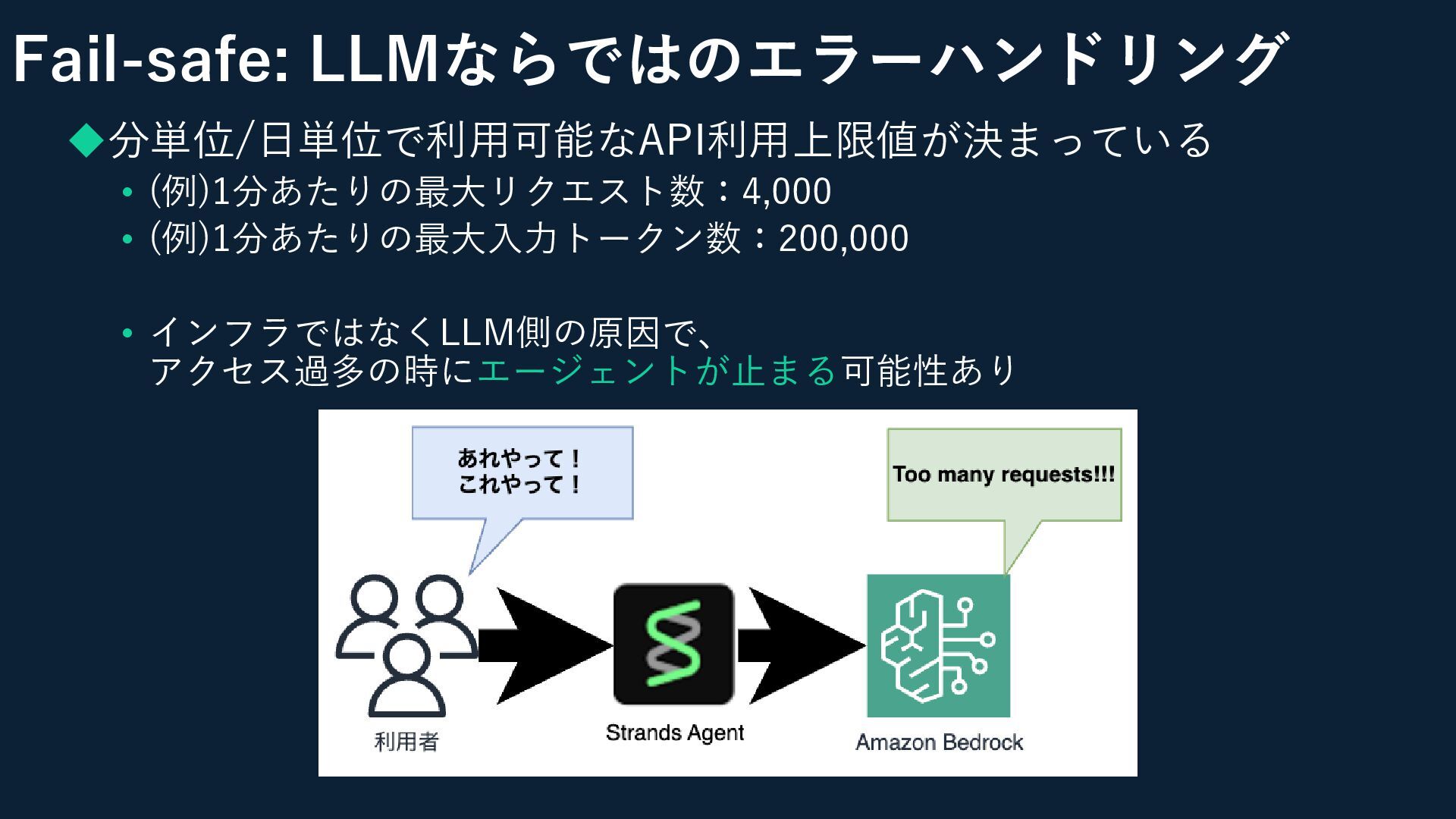
Fail-safe: LLMならではのエラーハンドリング ◆分単位/日単位で利用可能なAPI利用上限値が決まっている • (例)1分あたりの最大リクエスト数:4,000 • (例)1分あたりの最大入力トークン数:200,000 • インフラではなくLLM側の原因で、 アクセス過多の時にエージェントが止まる可能性あり
Fail-safe: LLMならではのエラーハンドリング ◆方針1. リトライ処理を入れておく • Strands Agents SDKはデフォルトで自動リトライ処理が実装されている • 自分で設定する場合は、指数バックオフでのリトライなどを用いる
◆方針2. 複数のモデルを複数の方法で使用できるようにする • Bedrock API、Anthropic API、Vertex AI APIを利用する • フェイルオーバー用セカンダリモデルを用意する(Sonnet 4.5→Haiku 4.5)
エージェント開発ならではのプラクティスがある ◆エージェントはWebアプリケーションだが、 普通のWebアプリケーションのように作るわけではない • 独自のプラクティスが存在する • 未だ発展途上の領域 ◆まずは手を動かしてみることが重要 • フレームワークを使えば簡単にエージェントを作ることができる
• AWS CDKやCLIを用いたデプロイ手順もたくさん用意されている • 試す中で、評価の勘所や考えるべきエラーハンドリングも見えてくる
Domain ✓ 私が作っているAIエージェント ✓ Architecture・Context ✓ Build・Evaluation・Fail-safe • Domain
Domain: 特化・独自エージェントを作るべし ◆エージェントを作る際は以下を自問自答してみる • そのエージェントは、どんな作業を代替してくれるのか? • その役割はChatGPTやClaude Desktopではダメなのか? ◆GPTやClaudeではできないことをやらせよう •
エージェント自身の独自性や、プロダクトとしての独自性を見据えておく • せっかく作っても「それ〇〇でいいじゃん」となると使われない
Domain: 特化・独自エージェントを作るべし ◆エージェントを作る際は以下を自問自答してみる • そのエージェントは、どんな作業を代替してくれるのか? • その役割はChatGPTやClaude Desktopではダメなのか? ◆GPTやClaudeではできないことをやらせよう •
エージェント自身の独自性や、プロダクトとしての独自性を見据えておく • せっかく作っても「それ〇〇でいいじゃん」となると使われない ◆特定の領域やタスクに特化したエージェントを作ろう • 独自データ • 最適なトリガー • 優れたUI-UX
Domain: 特化・独自エージェントを作るべし ◆独自データをコンテキストとして与える • RAGに始まり、現在はToolUse/MCPなどで簡単にデータを活用できる ◆イベント駆動・スケジュール駆動で動かす • Ambient Agent(より環境に溶け込んだエージェント)に本気で取り組む ◆Chat
UIにこだわらない • 利用者が常にPC前にいてタイピングするとは限らない • 音声を用いる方が有用なケースも ◆難しく考えすぎなくてOK! GPT/Claudeとの差別化点を1つ考えよう
◆エージェントの設計について6つの要素を凝縮してお伝えしました • Architecture • Build • Context • Domain •
Evaluation • Fail-safe ◆日々プラクティスが更新される領域だからこそ経験値を貯めていくことが重要 ◆設計で悩みすぎると進めない、ベストプラクティスを待っていると時代に取り 残される ◆Now, go build! まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}