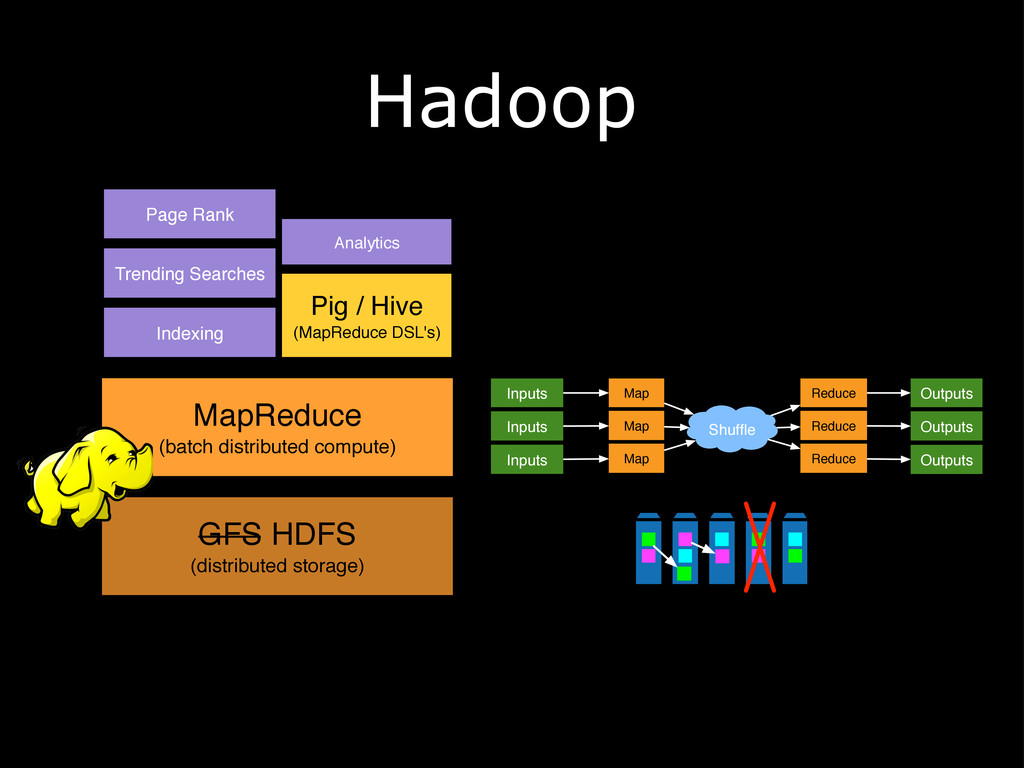
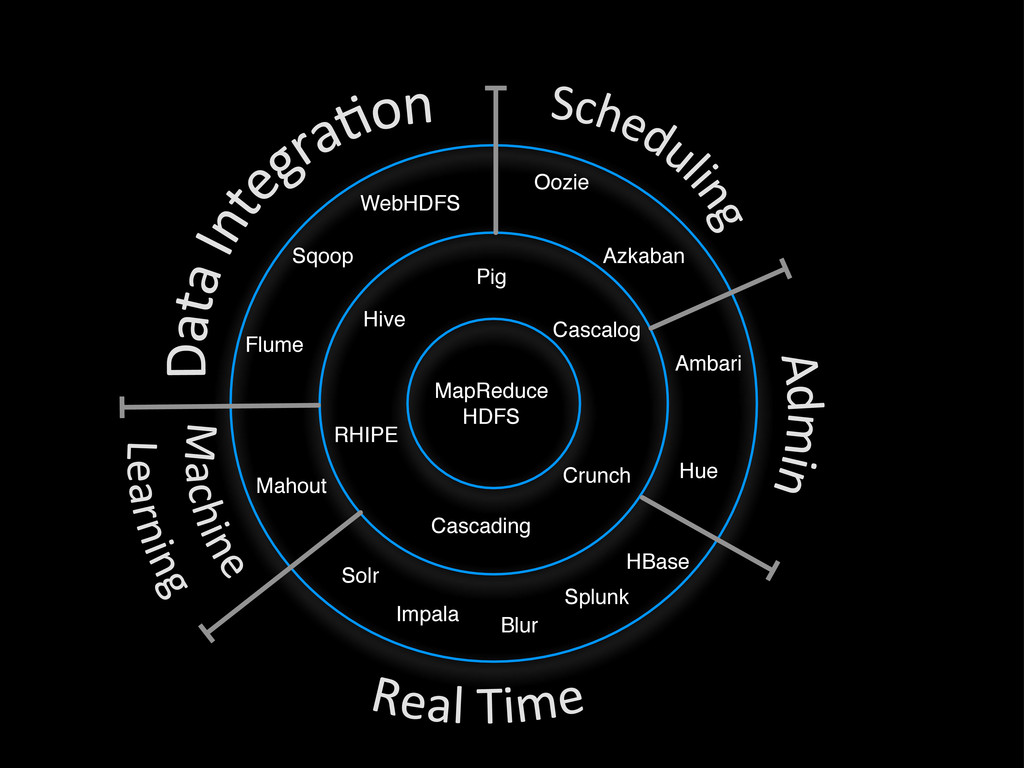
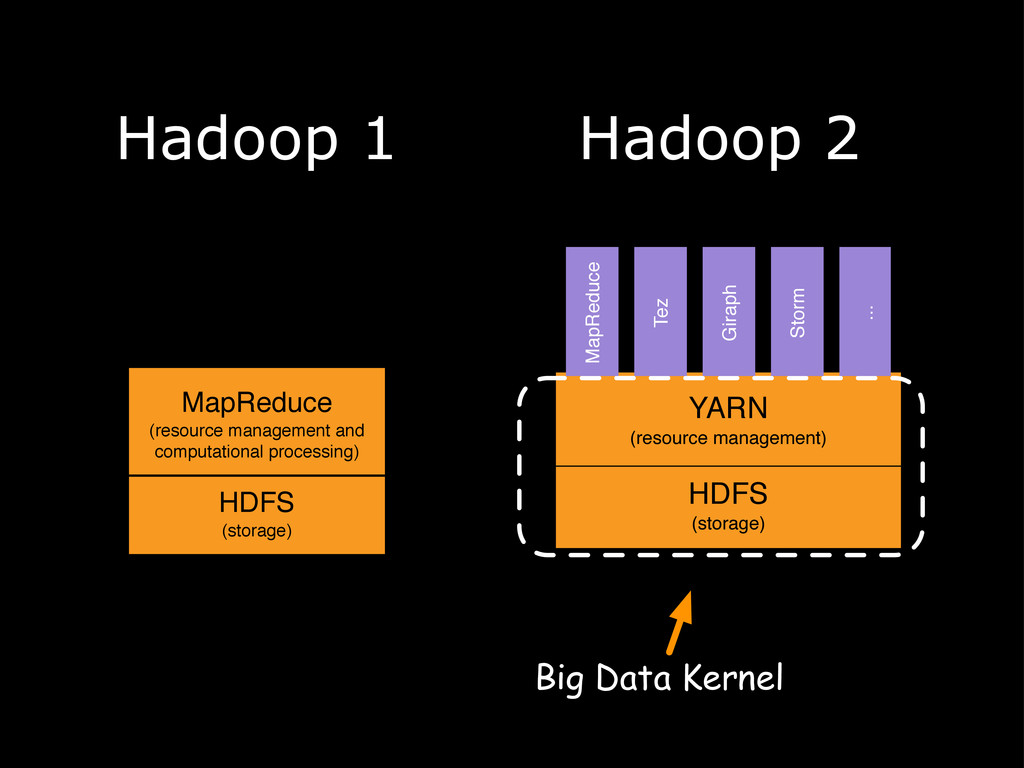
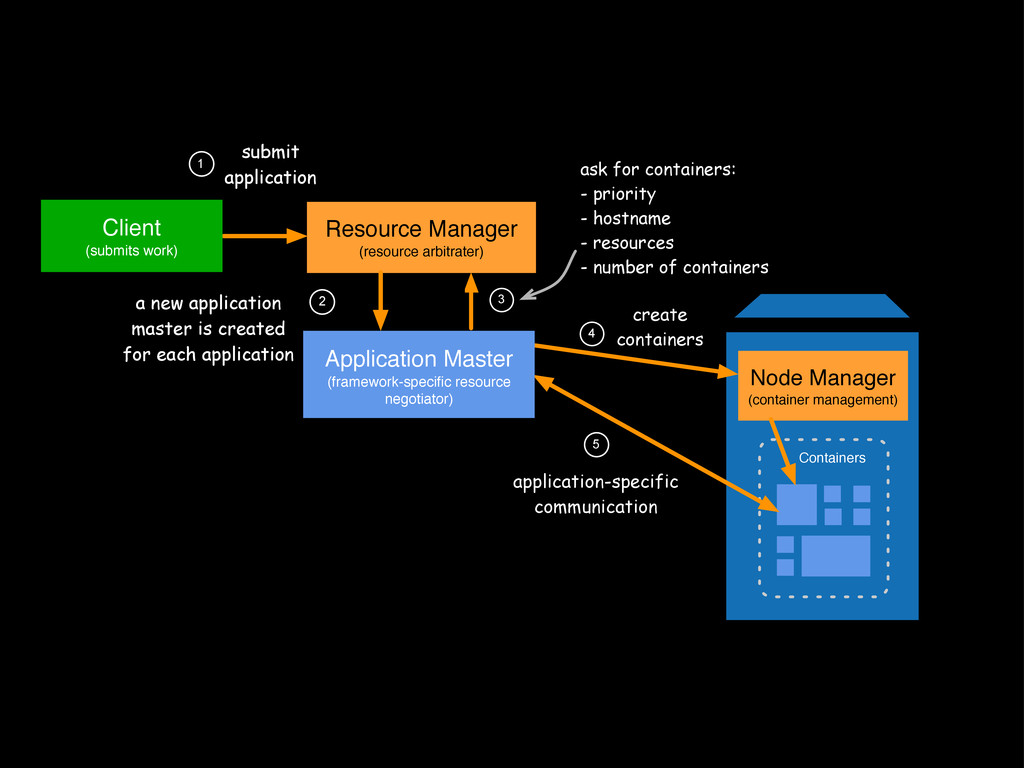
Hadoop is rapidly becoming the kernel for distributed computing. Hadoop is known as the de facto tool for anything related to batch processing, but the little-known secret is that in recent years, it has become much more than batch. The introduction of tools and technologies such as HBase, Impala, and the next-generation MapReduce architecture have brought real-time capabilities to Hadoop, and it now offers a complete ecosystem that can be used to address any challenge. This presentation explores several real-world big data problems and identifies key parts of Hadoop that can be used to solve these challenges. It also examines how real-time and batch processing can be fused to play to their strengths.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
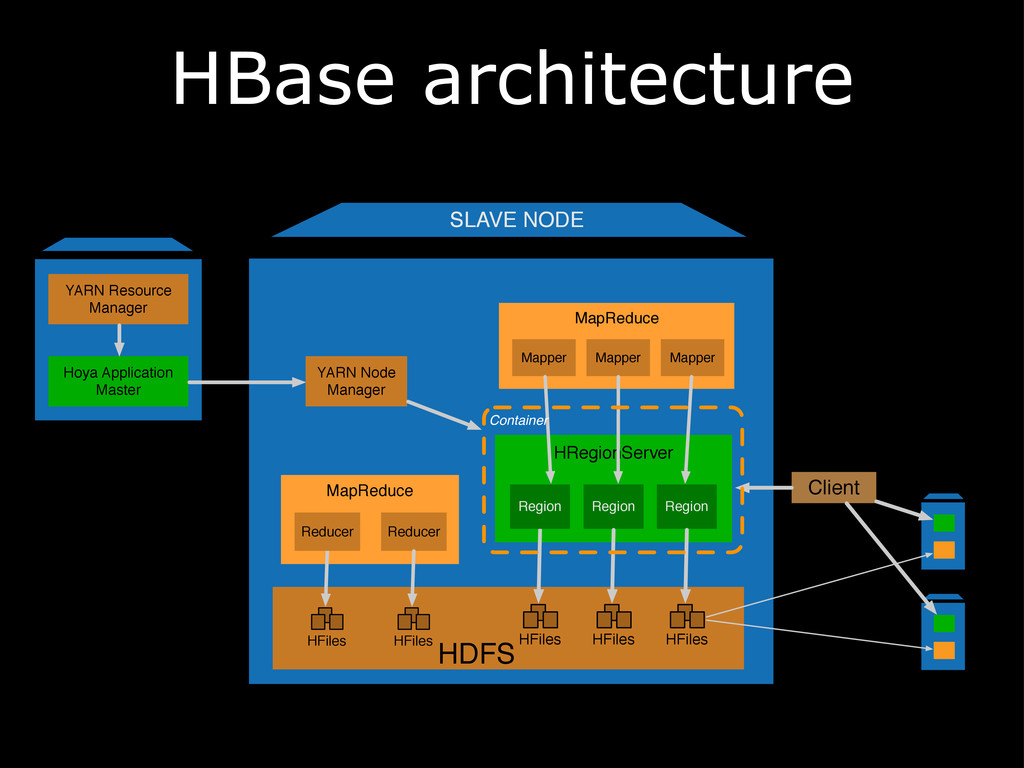{kind=link}
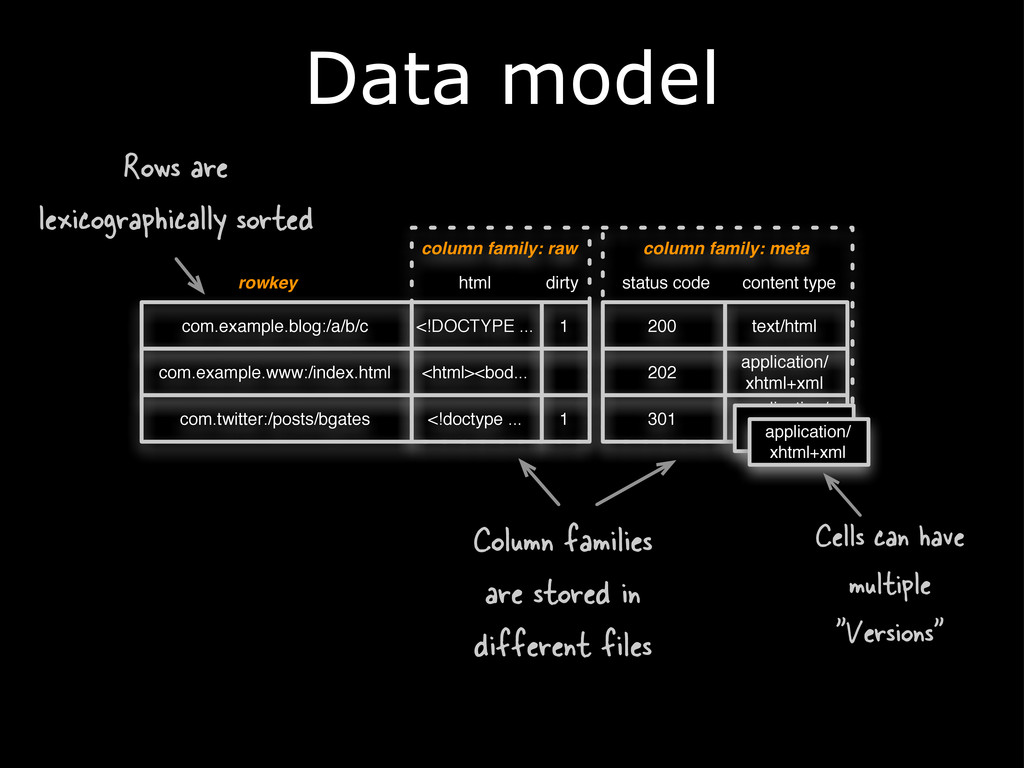{kind=link}
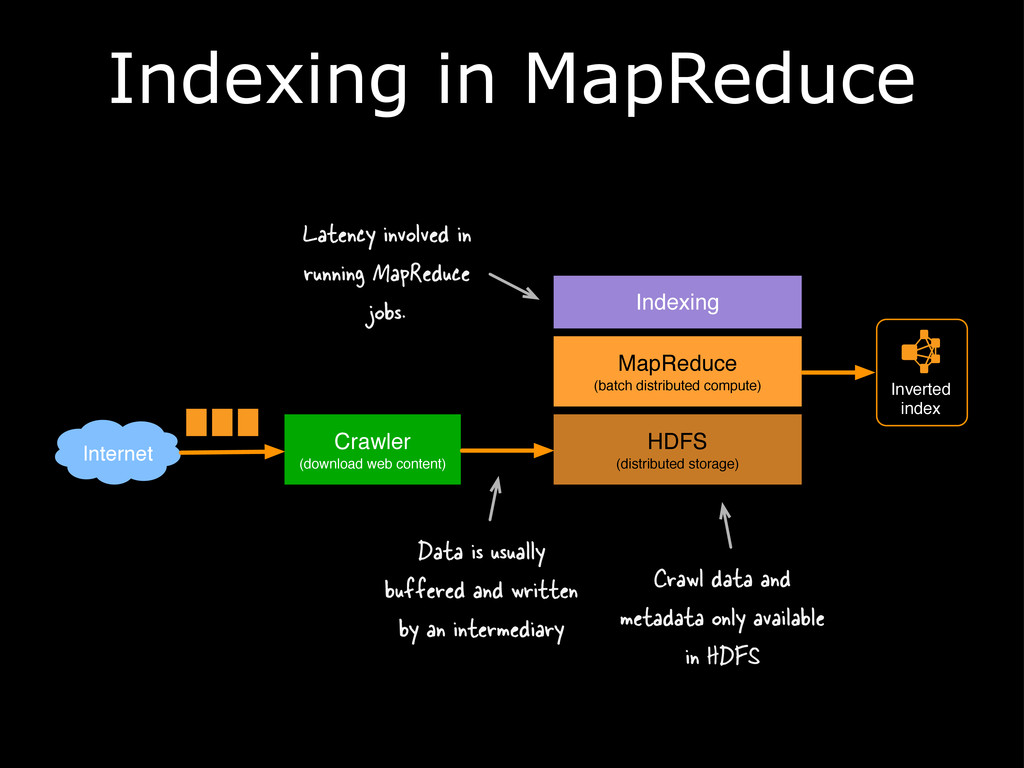{kind=link}
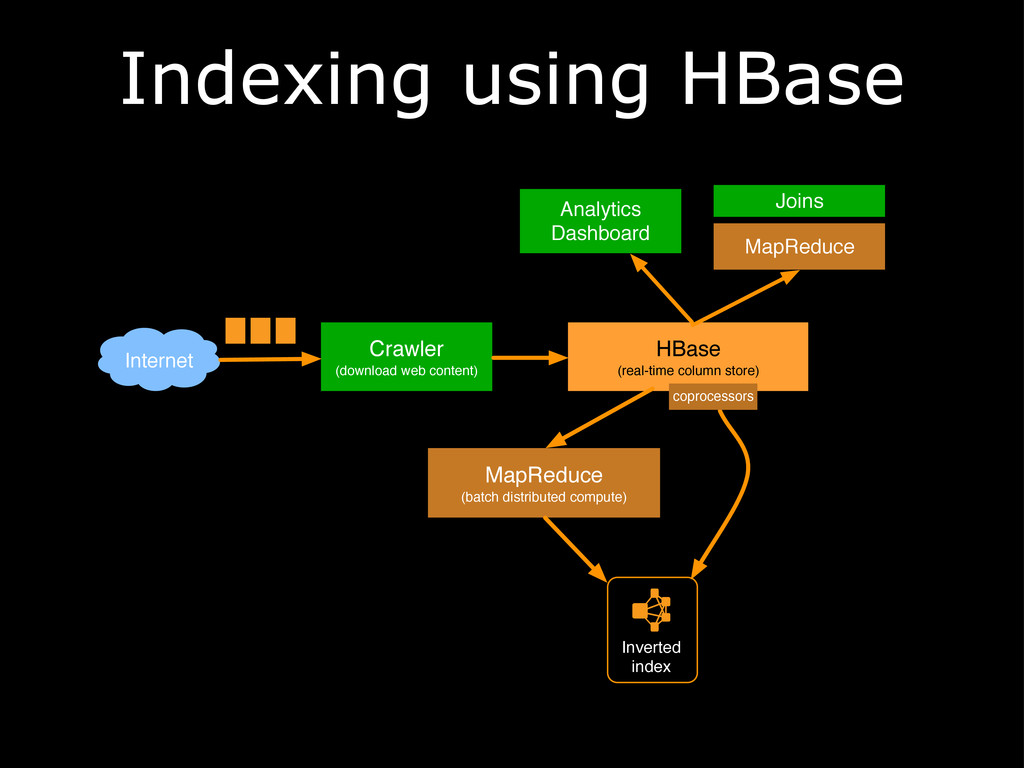{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
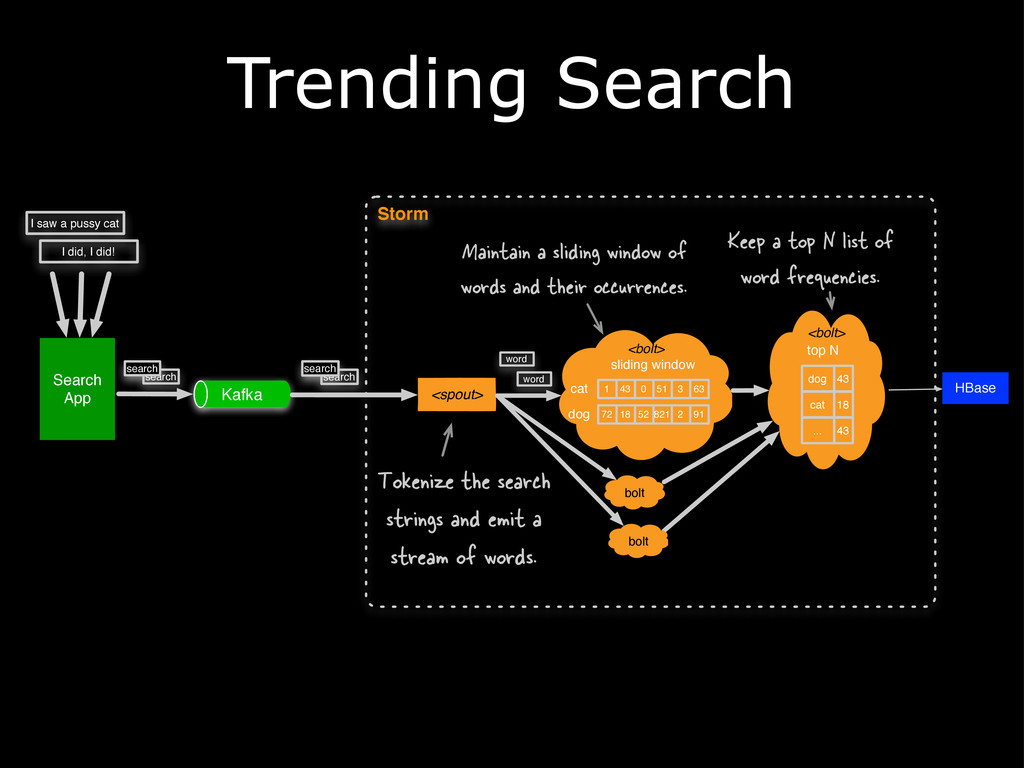{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
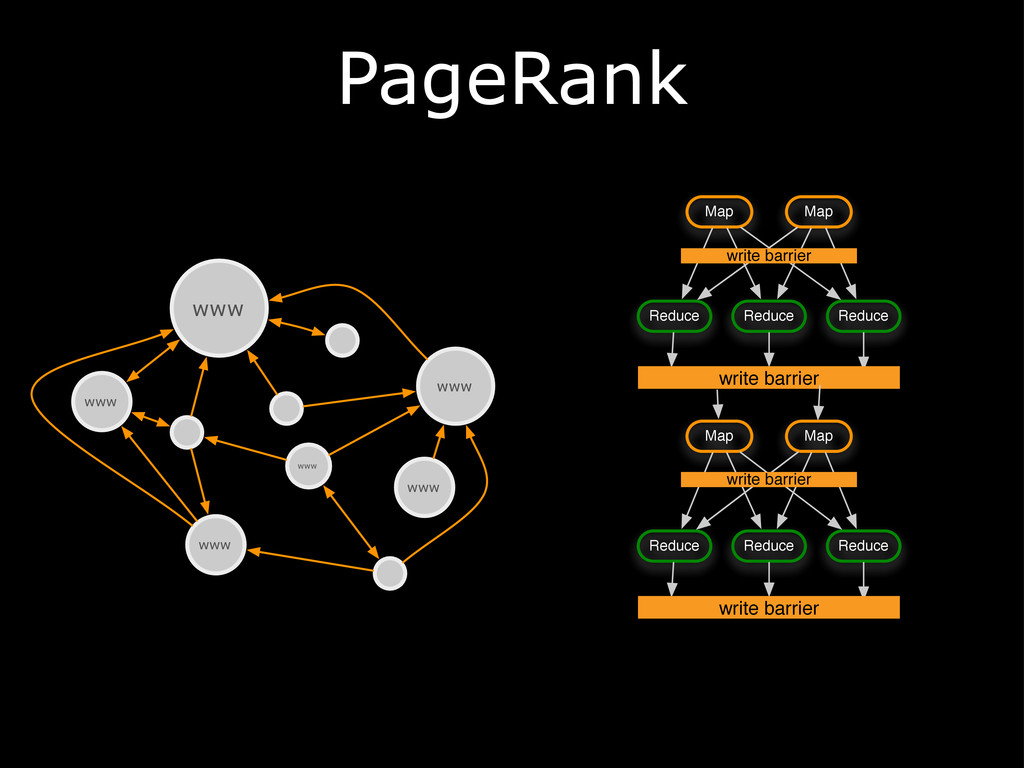{kind=link}
{kind=link}
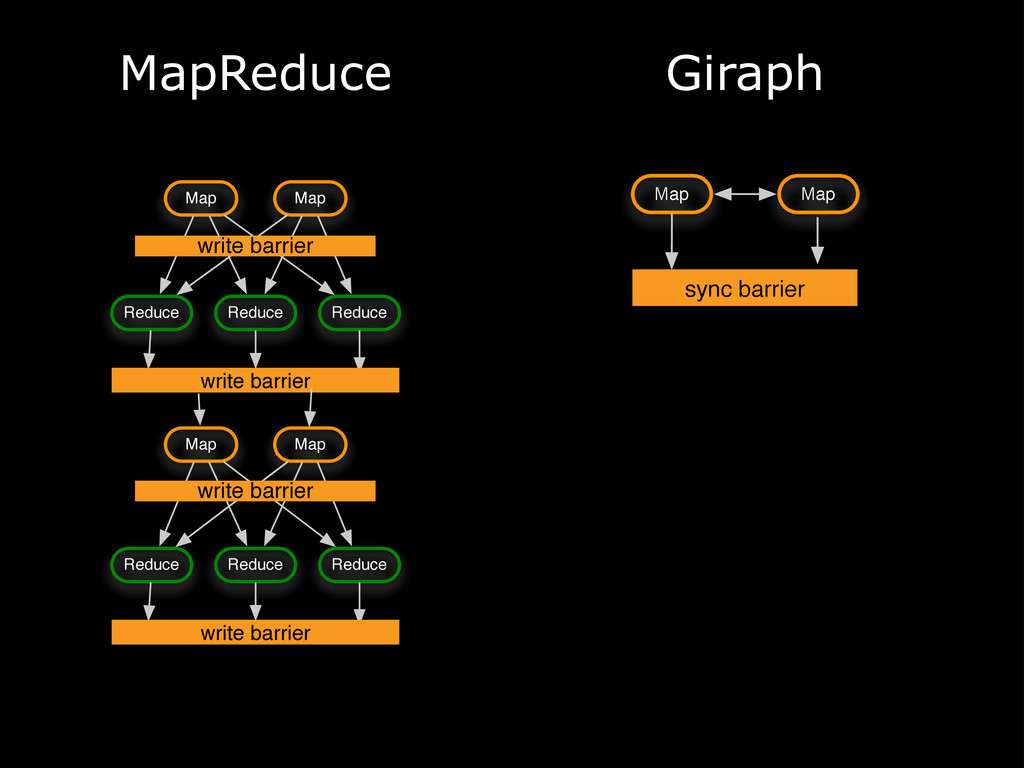{kind=link}
{kind=link}
{kind=link}
{kind=link}
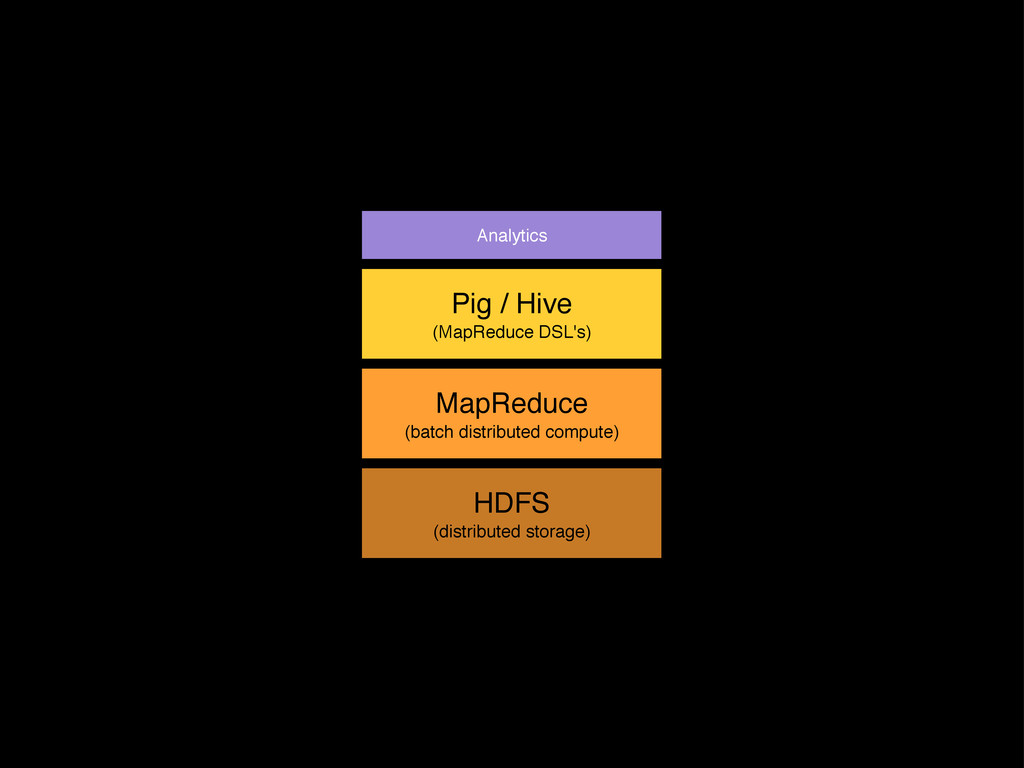{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}