но есть много/достаточно данных. • автоматическое создание программы из данных. • другие формулировки: открытие закона природы, создание мат. модели, оптимизация функции… 2
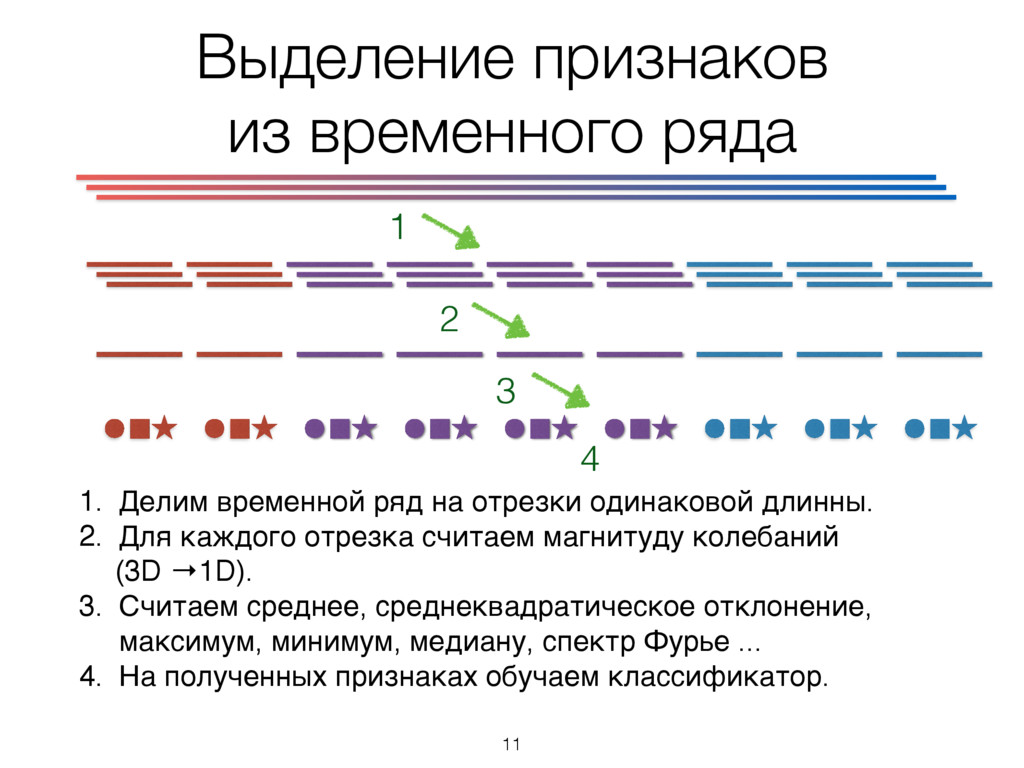
с привязкой ко времени. Вход алгоритма: Два трехмерных временных ряда фиксированной длинны. Выход алгоритма: Тип активности в каждый из этих отрезков времени. 10
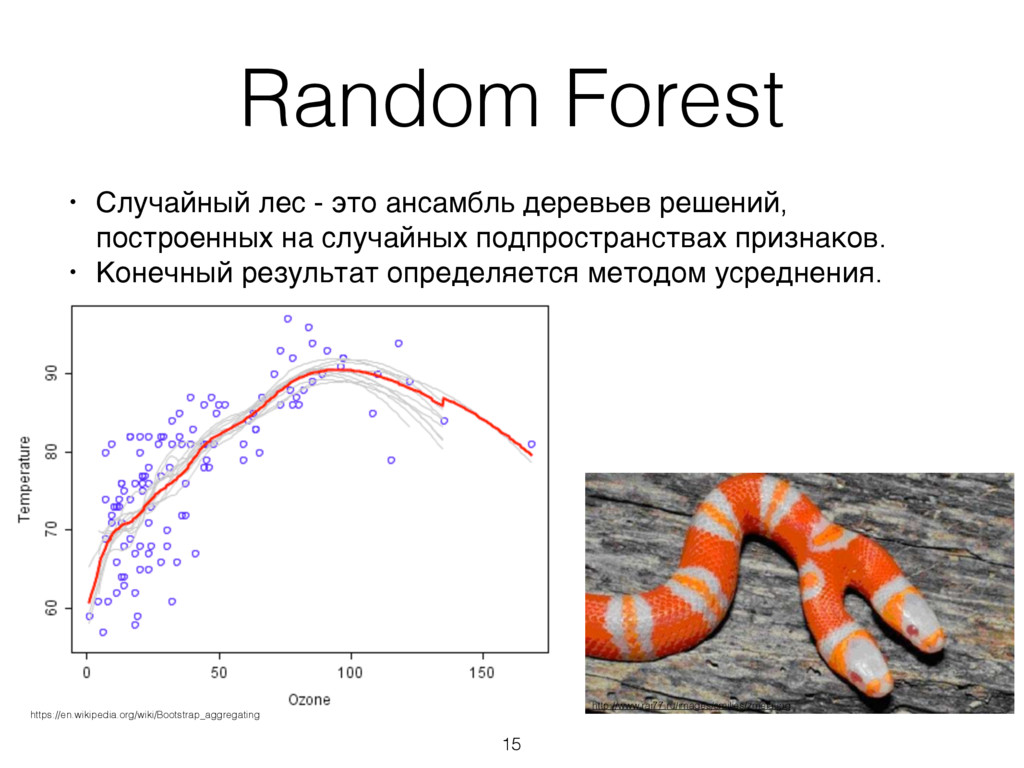
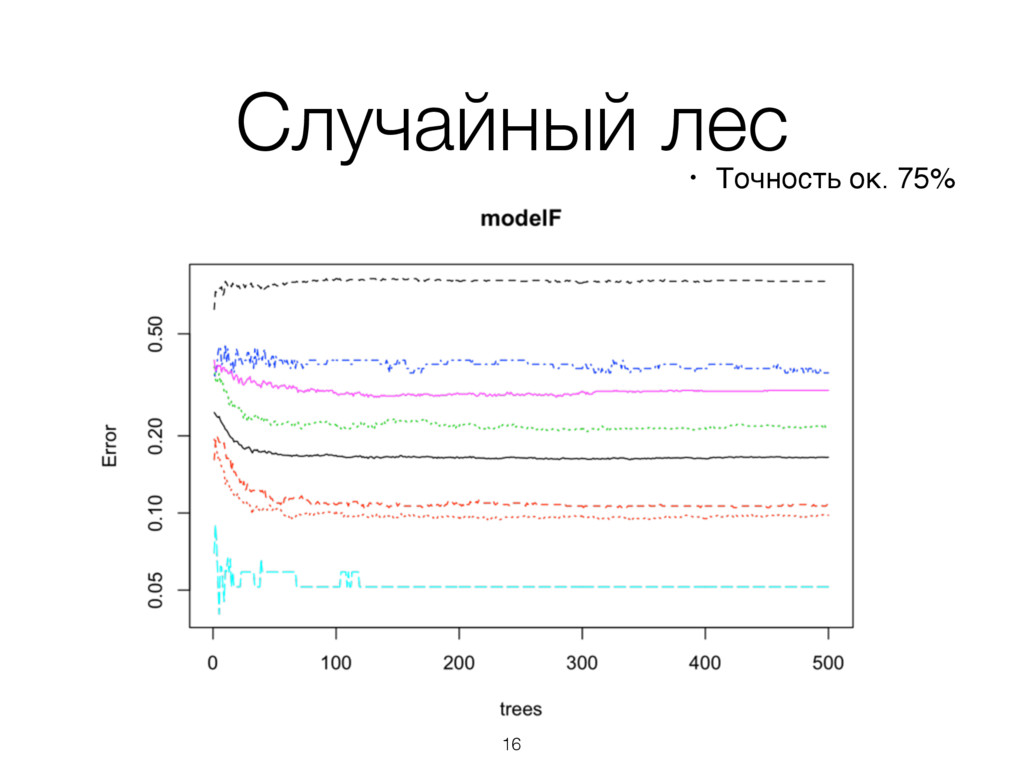
построенных на случайных подпространствах признаков. • Конечный результат определяется методом усреднения. 15 http://www.rai77.ru/images/smilies/zmeia.jpg https://en.wikipedia.org/wiki/Bootstrap_aggregating
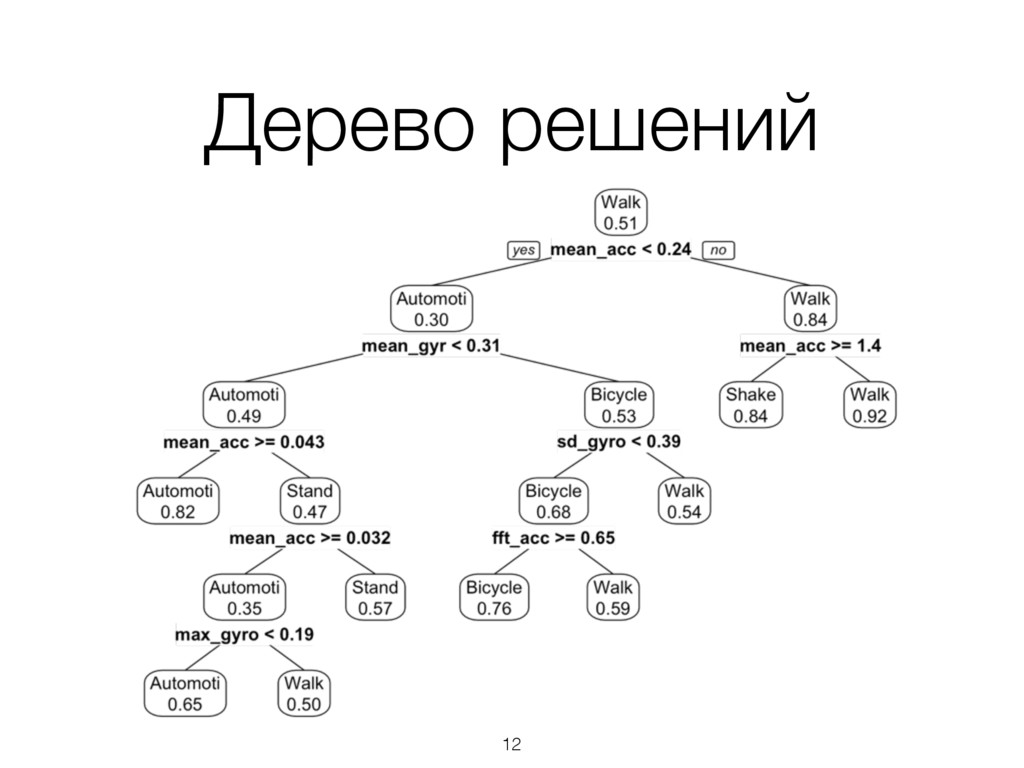
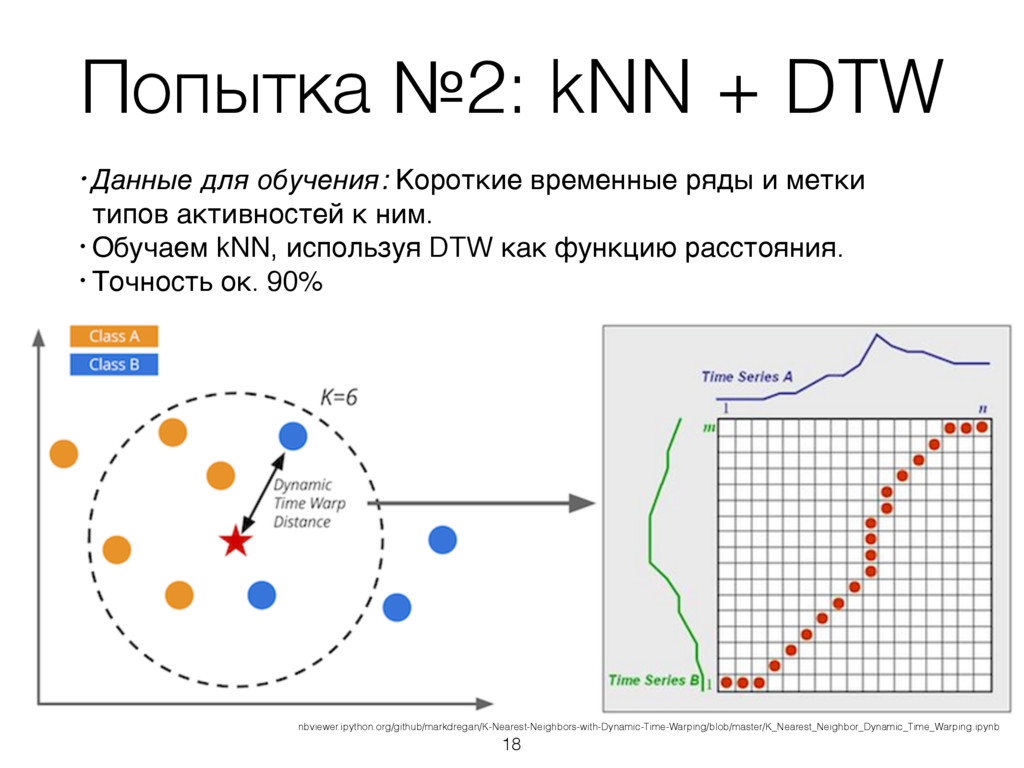
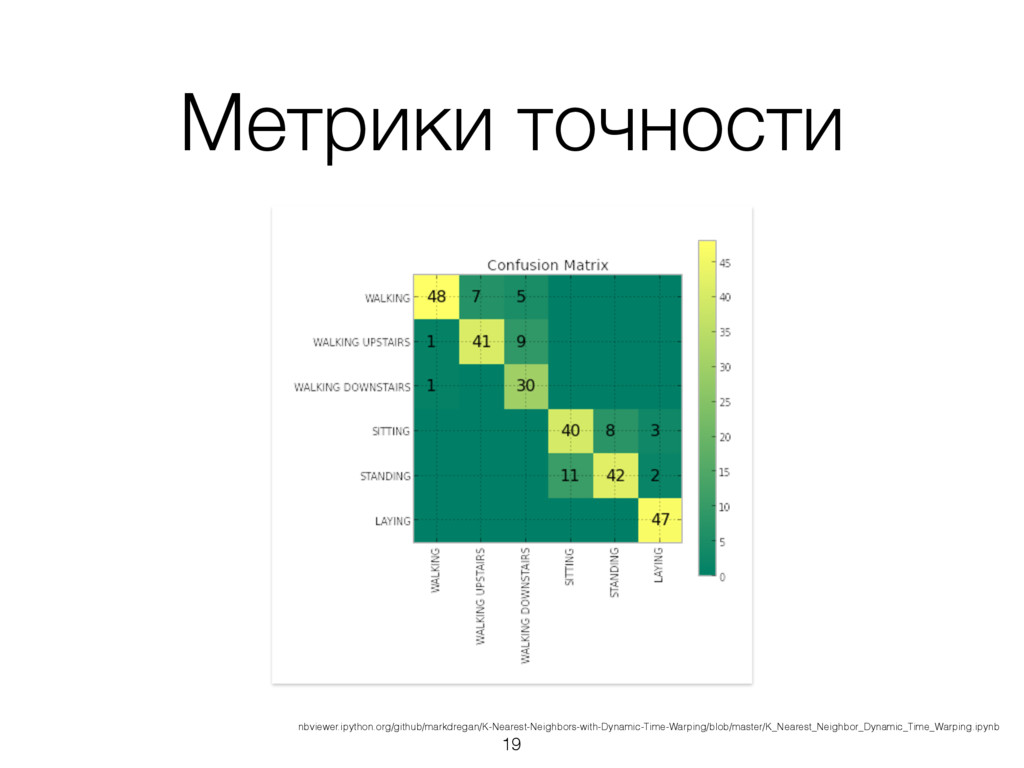
временные ряды и метки типов активностей к ним. • Обучаем kNN, используя DTW как функцию расстояния. • Точность ок. 90% 18 nbviewer.ipython.org/github/markdregan/K-Nearest-Neighbors-with-Dynamic-Time-Warping/blob/master/K_Nearest_Neighbor_Dynamic_Time_Warping.ipynb
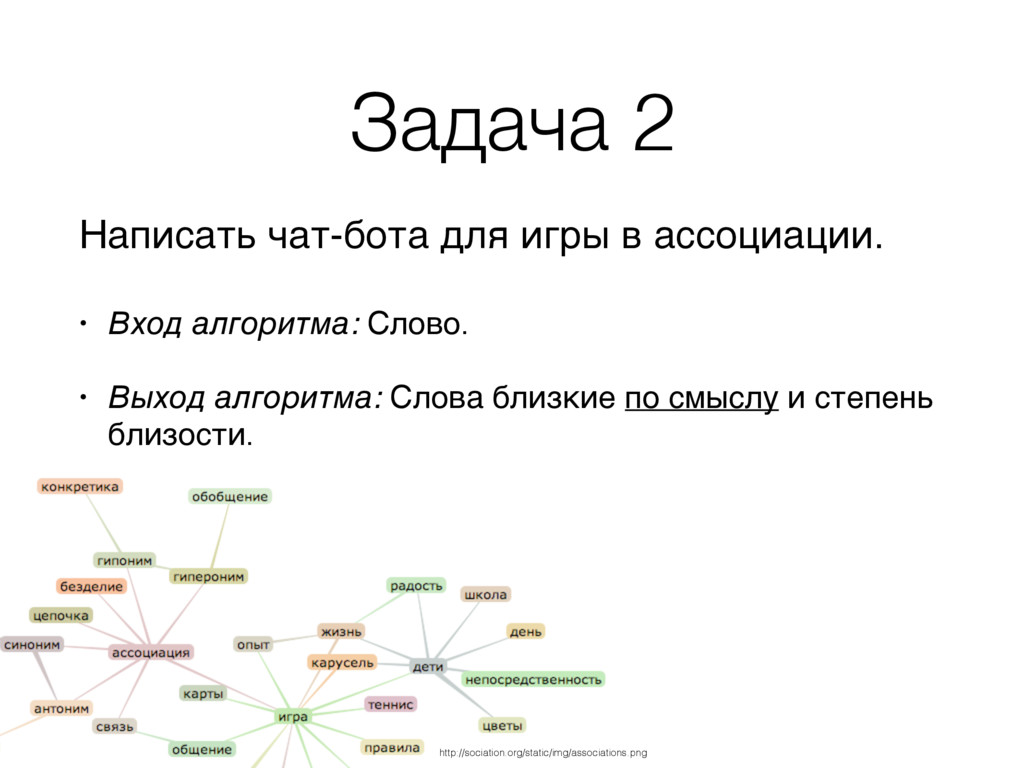
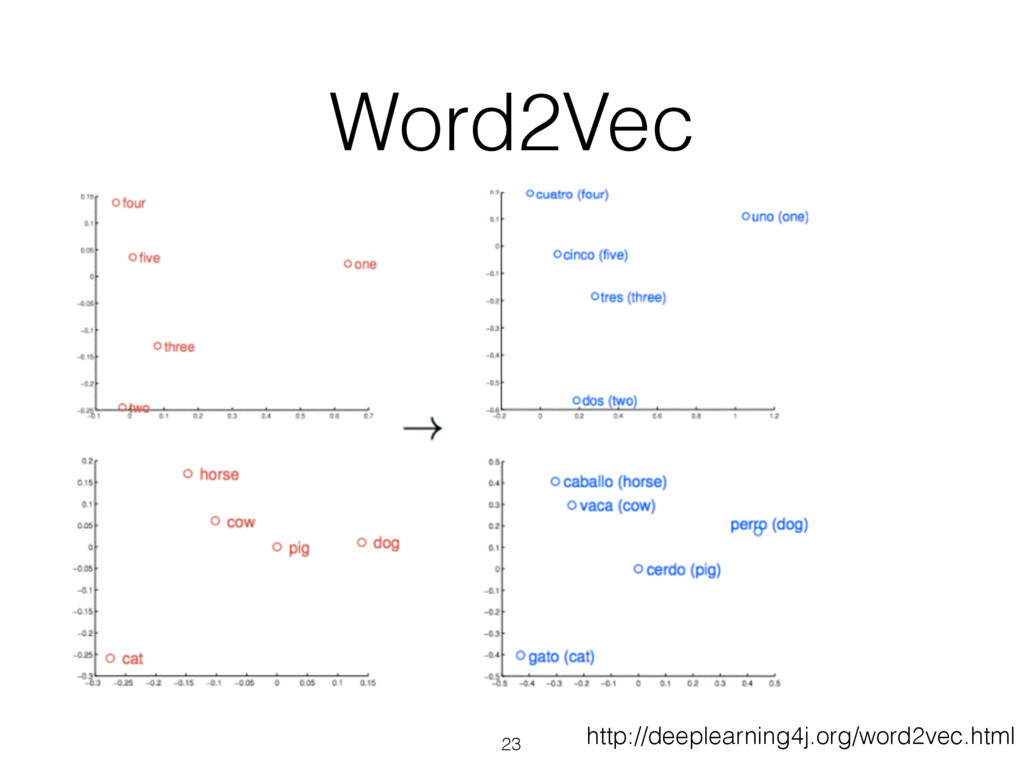
Jordan • Human - Animal = Ethics • President - Power = Prime Minister • Library - Books = Hall • Rome - Italy = Beijing - China • king - queen = man - woman http://deeplearning4j.org/word2vec.html
- не используйте его. 1. Поищите готовое решение, работающее на устройстве. 2. Поищите готовое решение, работающее на сервере. 3. Если 0..2 не устраивают, нужно писать свое решение. 4. Обзор публикаций. 5. Поиск или создание обучающего набора данных. 32
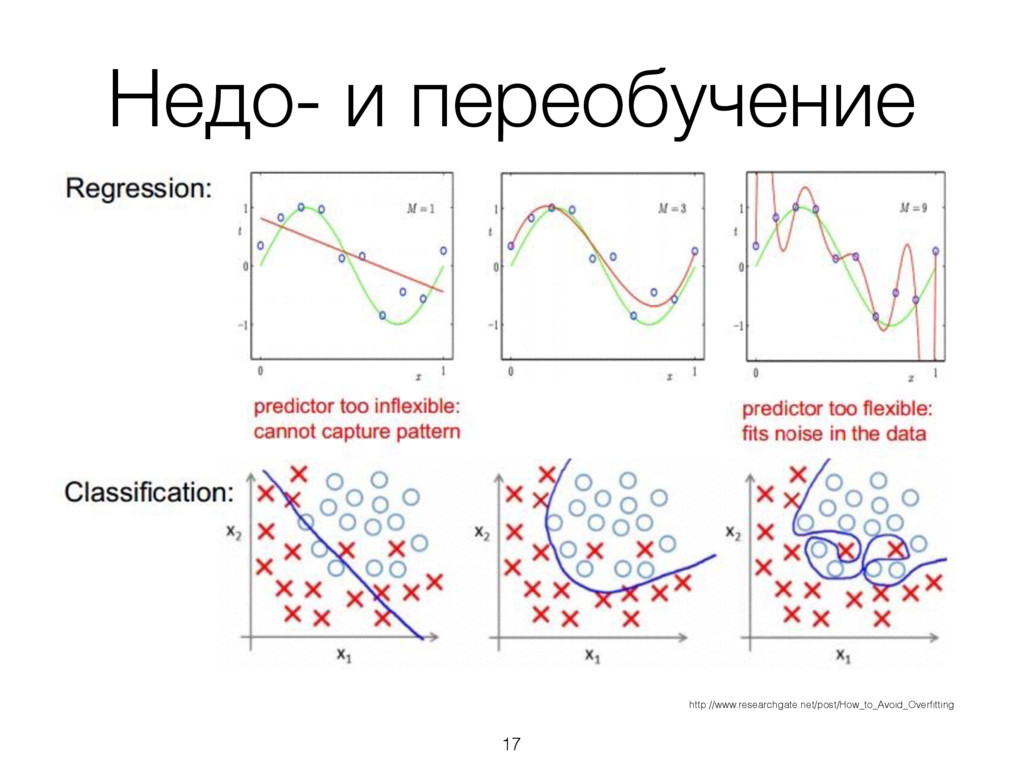
моделей. Часто простые модели работают лучше сложных. 2. Обучающая, тестовая и проверочная выборки. Переобучение. Data augmentation. Метрики. 4. Прототипирование: R, Python (SciPy, scikit-learn), Matlab. 5. Если точность сразу > 90%, вы точно что-то делаете неправильно. 6. Ансамбли моделей могут работать лучше, чем каждая из моделей по-отдельности. Однако, чем сложнее модель, тем она более ресурсоемка. 33
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[4] Visual-Semantic Embeddings 26](https://files.speakerdeck.com/presentations/91e3cc4c332045b598fe6e437c885cc3/slide_25.jpg){kind=link}
![[4]](https://files.speakerdeck.com/presentations/91e3cc4c332045b598fe6e437c885cc3/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}