by hyperparameters • Unlike model parameters whose values are learned from the training data, hyperparameter values are prede f i ned before the training process begins. • Choosing appropriate values of the hyperparameters is important because they a f f ect model performance and even training speed. 3
i nd the hyperparameter combinations in the hyperparameter space that maximises some performance function on a holdout dataset. • Some example performance functions for binary classi f i cation problems are Accuracy, ROC AUC, precision, recall etc. x⋆ X f(x) 4 x⋆ = arg max x∈X f(x)
1 Step 2 Step 3 Step 1 Select hyperparameter combination from a grid or through a random process x Step 2 Train a model using the hyperparameter combination selected M x Step 3 Evaluate the performance of model on validation dataset using performance metric M f(x)
commonly used approaches… 6 • Simple and easy to implement • Because they treat the evaluation of every hyperparameter combination independently, they are easy to parallelise. • They work really well in not-so-complex situations (when it is cheap to evaluate the performance function)
f f ers from the curse of dimensionality • They don’t use past evaluation of the performance function to intelligently select the next hyperparameter combinations to try. • We could end up wasting huge amounts of resources when training complex models like neural networks. f(x)
hyperparameter optimisation actually looks like this 8 Step 1 Step 2 Step 3 Step 1 Select hyperparameter combination from a grid or through a random process x Step 2 Train a model using the hyperparameter combination selected M x Step 3 Evaluate the performance of model on validation dataset using performance metric M f(x) } There is no connection between Steps 3 and 1. Step 3 does not guide step 1
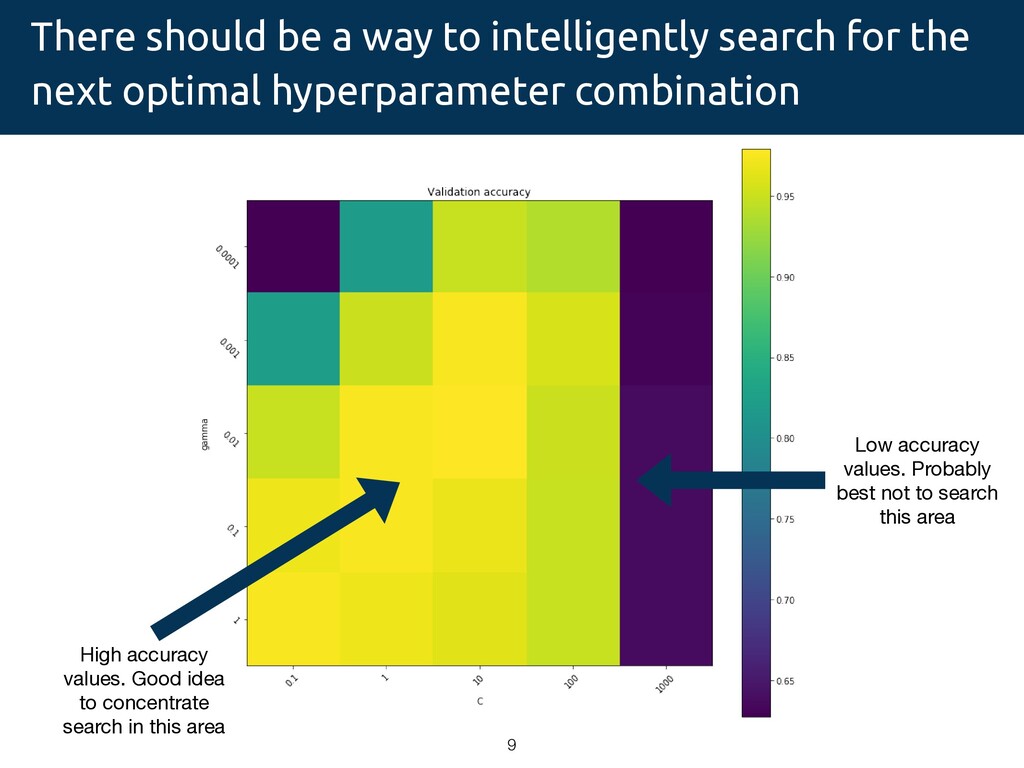
next optimal hyperparameter combination 9 High accuracy values. Good idea to concentrate search in this area Low accuracy values. Probably best not to search this area
evaluation result which it uses to build a surrogate probability model of the objective function. • The surrogate is much easier to optimise than the objective function, so Bayesian optimisation works by f i nding the next set of hyperparameters to evaluate on the actual objective function by selecting the hyperparameters that perform best on the surrogation model.
the true objective function. • Find the hyperparameters that perform best on the surrogate function. • Apply these hyperparameters to the true objective function. • Update the surrogate model by using the new results. • Repeat the above steps until maximum iterations or convergence.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}