In this talk, I introduce the concepts that make search engines are fast, and discuss the underpinnings of the open-source projects (Apache Lucene) that modern-day search engines are made of.
Cloud (bonsai.io, hosted Elasticsearch, and websolr.com - hosted Solr). We’re the first “search in the cloud” hosting company - local to Austin and self-funded. This talk covers how search works on a fundamental level.
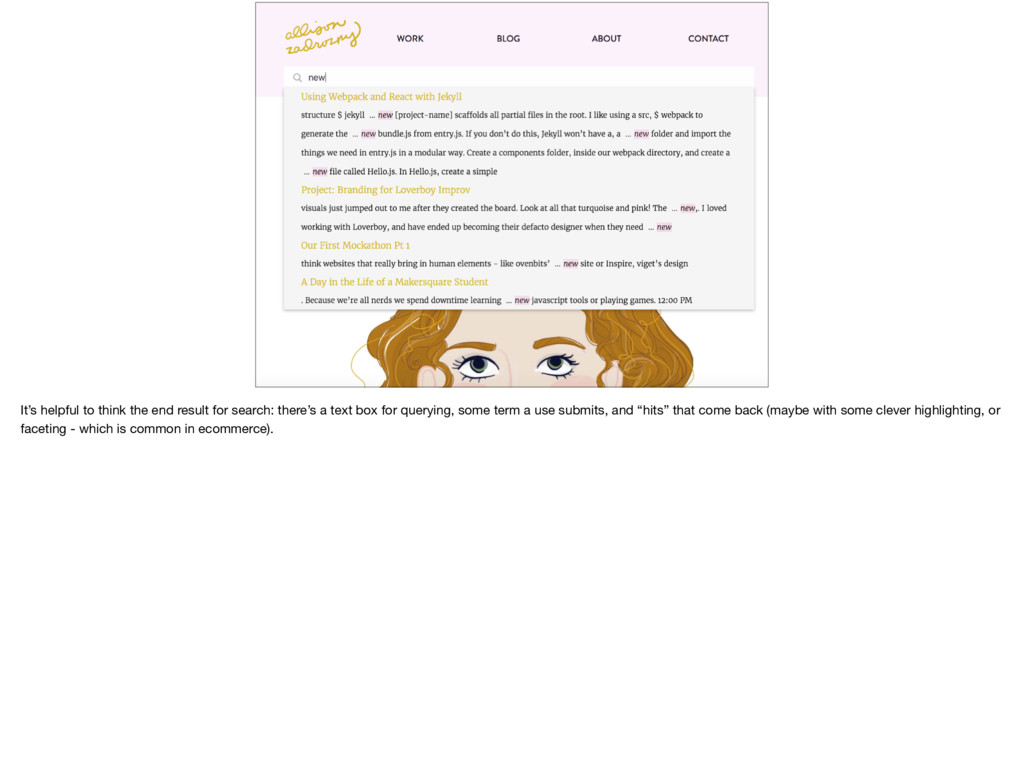
a text box for querying, some term a use submits, and “hits” that come back (maybe with some clever highlighting, or faceting - which is common in ecommerce).
of giants • The search libraries we still use today have been around since 1999 • Apache Lucene! ❤ • There are two major open-source search engines • Solr • Elasticsearch • Plus, a bunch of proprietary options…because, capitalism Powerful search has been building for a long time. Most of what you use today is built on top of a Java search library that’s open-source, called Apache Lucene. This is important to note: because Lucene is still being hacked on today its changes coincide with changes to popular engines out there - Sold and Elasticsearch.
Solr • Java • XML • New releases (v6 out) • 2004: Compass • Java • Transition project that informed the build of Elasticsearch • 2010: Elasticsearch • Java • JSON • New releases (v7 coming soon) where it came from There’s a longish history here, and many open-source solutions that are available today came out of many iterations of the same ideas of Lucene. The basics: there’s Solr, which is an older iteration and XML-based, and Elasticsearch, which is relatively newer and has gained a lot of popularity over the last few years.
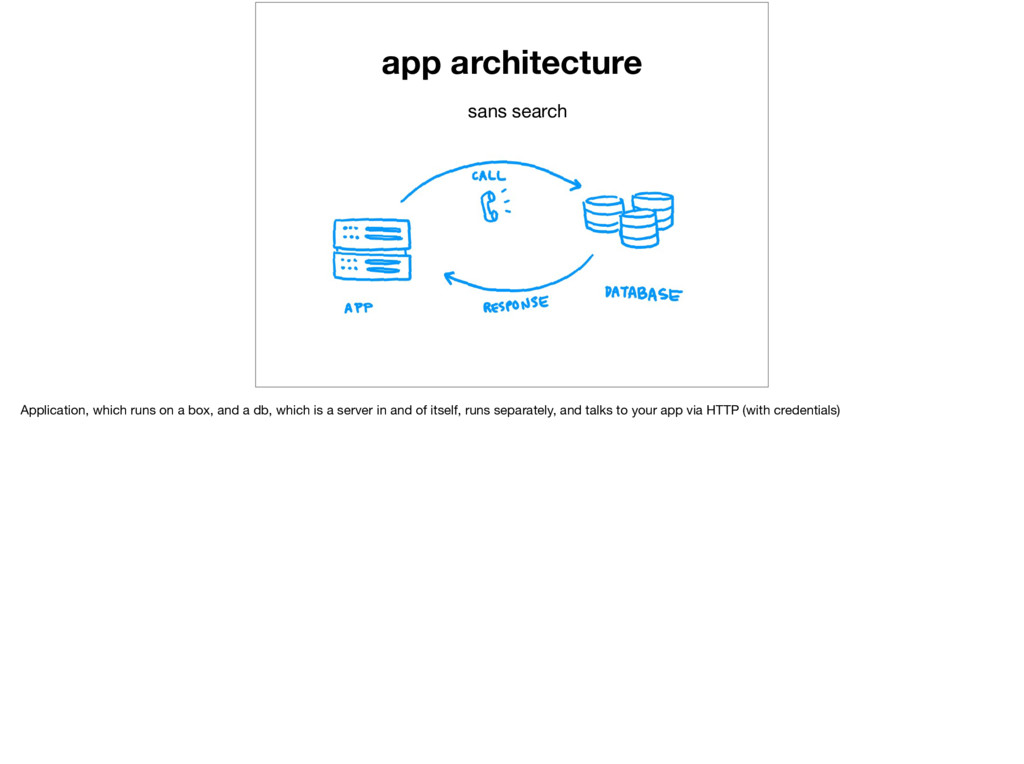
2. Full-text search engines that speak HTTP • Open-source • Elasticsearch • Solr • Proprietary Sure, you _could_ build a search engine on the client-side if you have small data sets, but the bigger you go, the bigger your power needs to be. Kind of like static sites vs. server-backed applications. Serving a simple site with plain old html and css files, maybe some javascript? Stick to S3. Need to hook it up to a database and add in lots of records, plus do it with redundancy? You need more firepower.
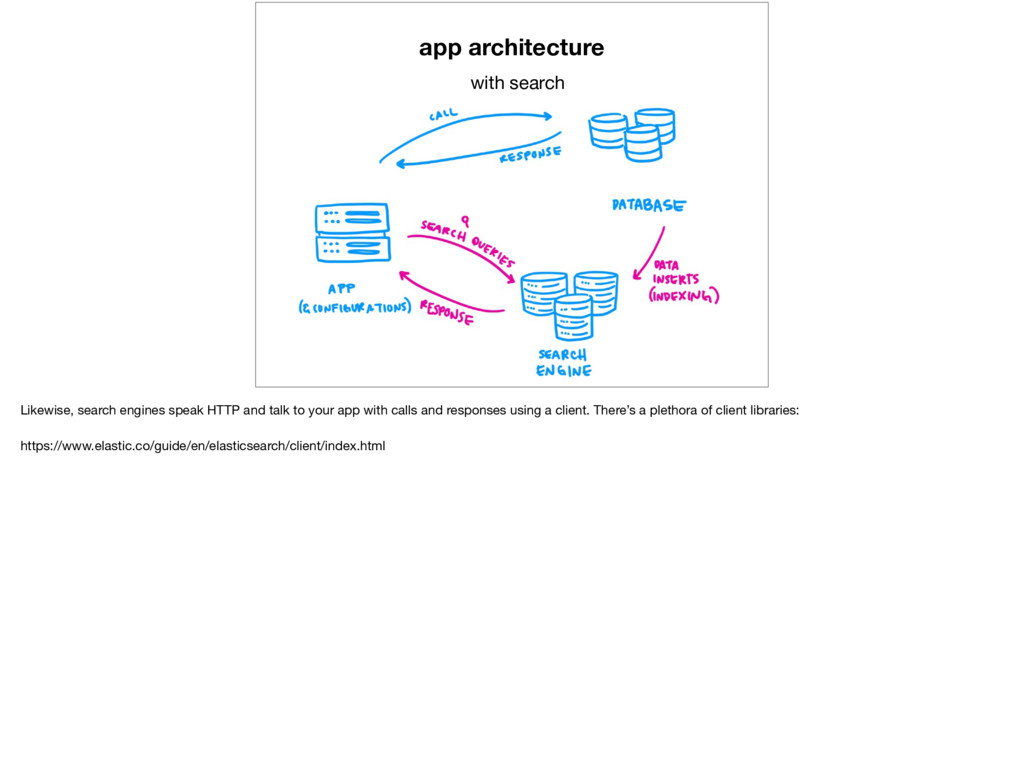
talk to your app with calls and responses using a client. There’s a plethora of client libraries: https://www.elastic.co/guide/en/elasticsearch/client/index.html
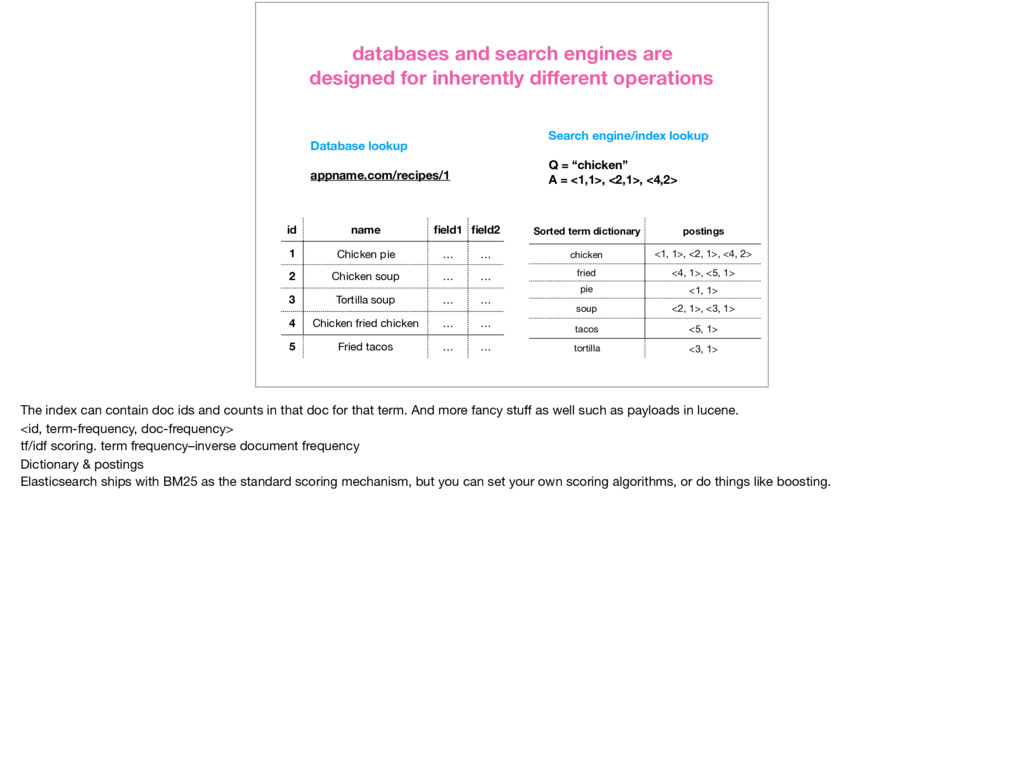
database, but it’s kind of like one. • On a basic level, search engines work the same way as a book index. • A sorted, inverted index is used to look up terms via binary search.
inherently different operations Search engine/index lookup Q = “chicken” A = <1,1>, <2,1>, <4,2> id name field1 field2 1 Chicken pie … … 2 Chicken soup … … 3 Tortilla soup … … 4 Chicken fried chicken … … 5 Fried tacos … … Sorted term dictionary postings chicken <1, 1>, <2, 1>, <4, 2> fried <4, 1>, <5, 1> pie <1, 1> soup <2, 1>, <3, 1> tacos <5, 1> tortilla <3, 1> The index can contain doc ids and counts in that doc for that term. And more fancy stuff as well such as payloads in lucene. <id, term-frequency, doc-frequency> tf/idf scoring. term frequency–inverse document frequency Dictionary & postings Elasticsearch ships with BM25 as the standard scoring mechanism, but you can set your own scoring algorithms, or do things like boosting.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![bonsai.io websolr.com storyofsearch.com @allizad [email protected]](https://files.speakerdeck.com/presentations/d49f9d6c1199401ba6acdb4988c2ee06/slide_27.jpg){kind=link}