This talk was given at 41st International Conference on Very Large Databases, Kohala Coast, Hawai'i, 2015.
Abstract:
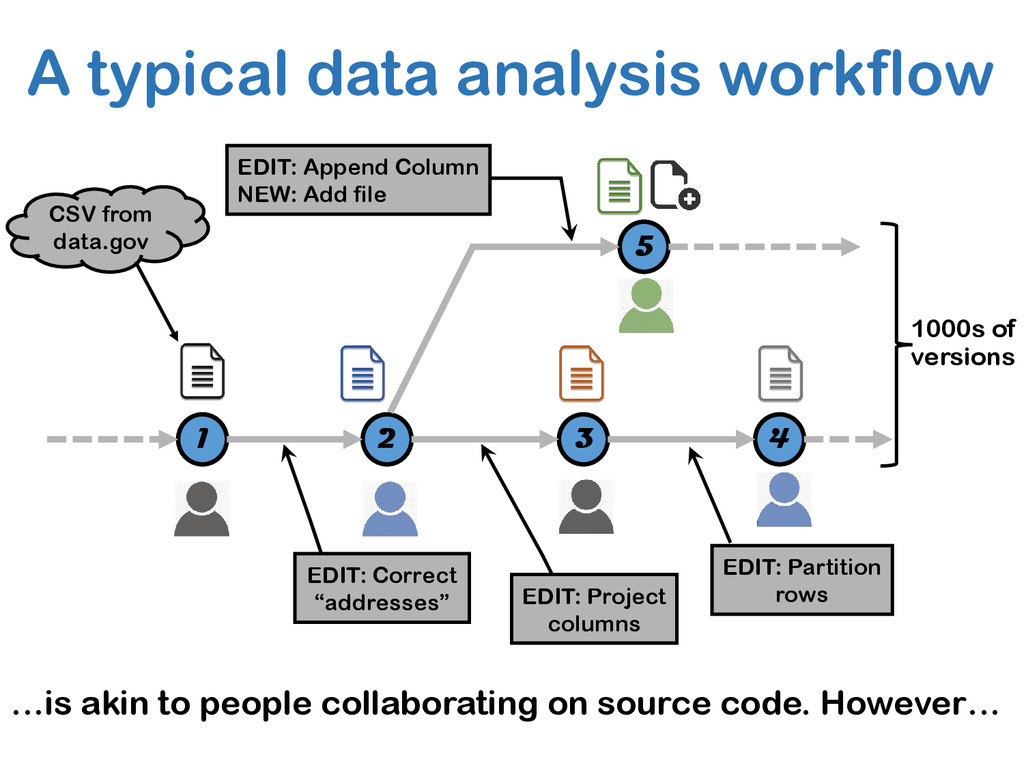
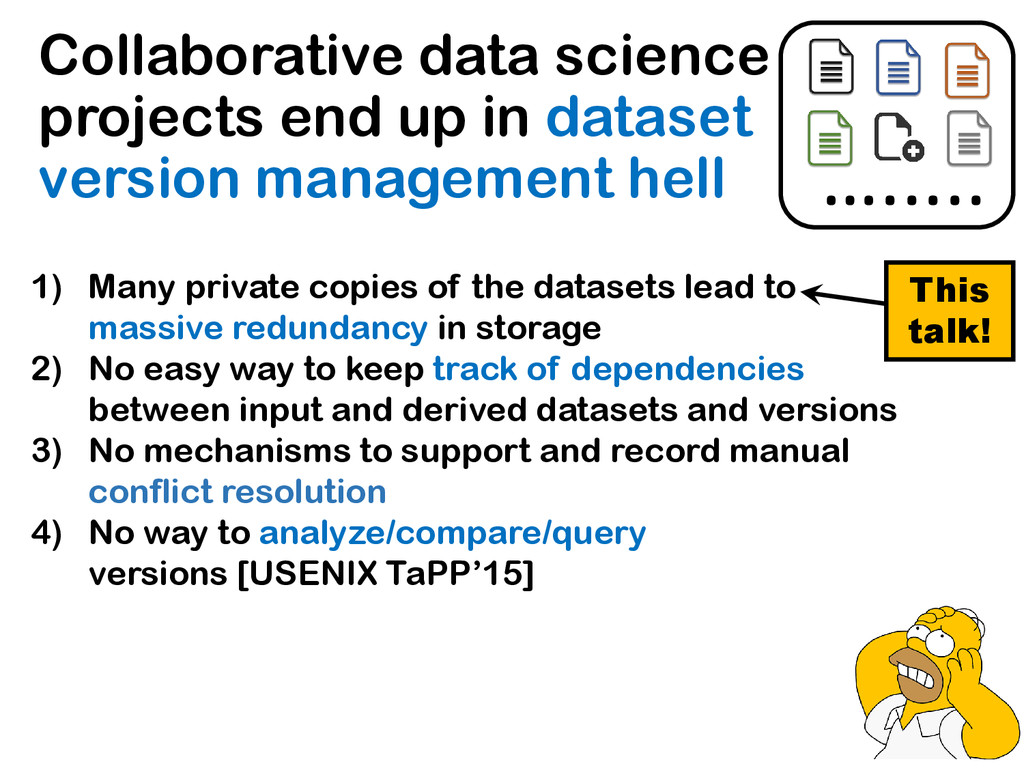
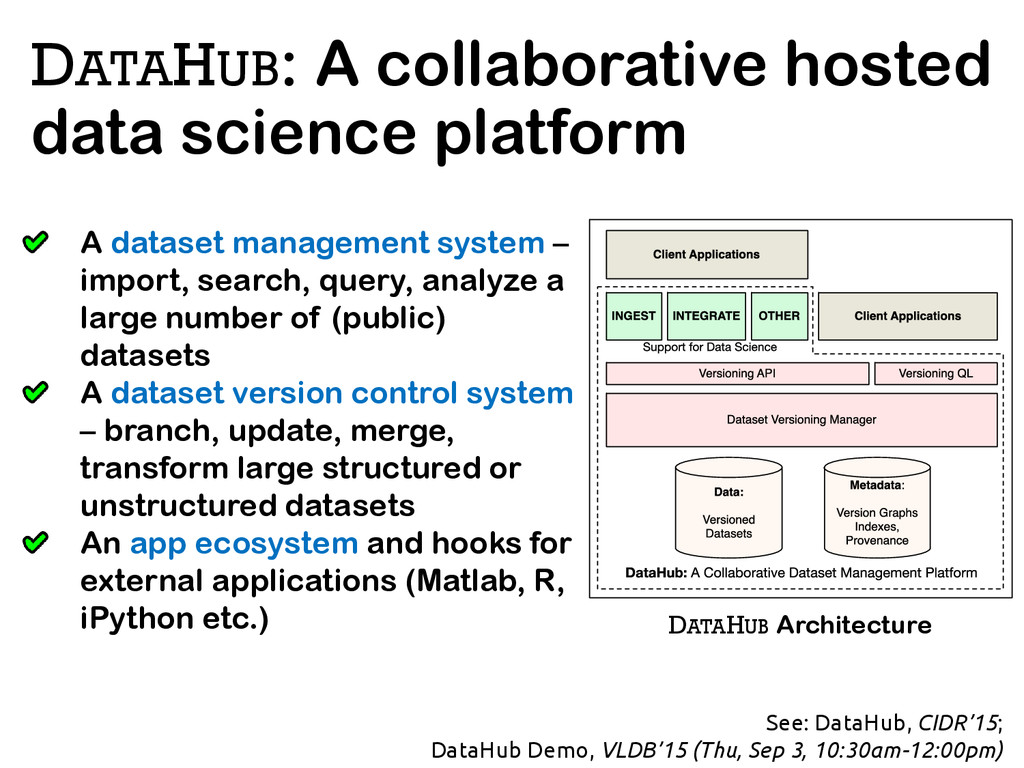
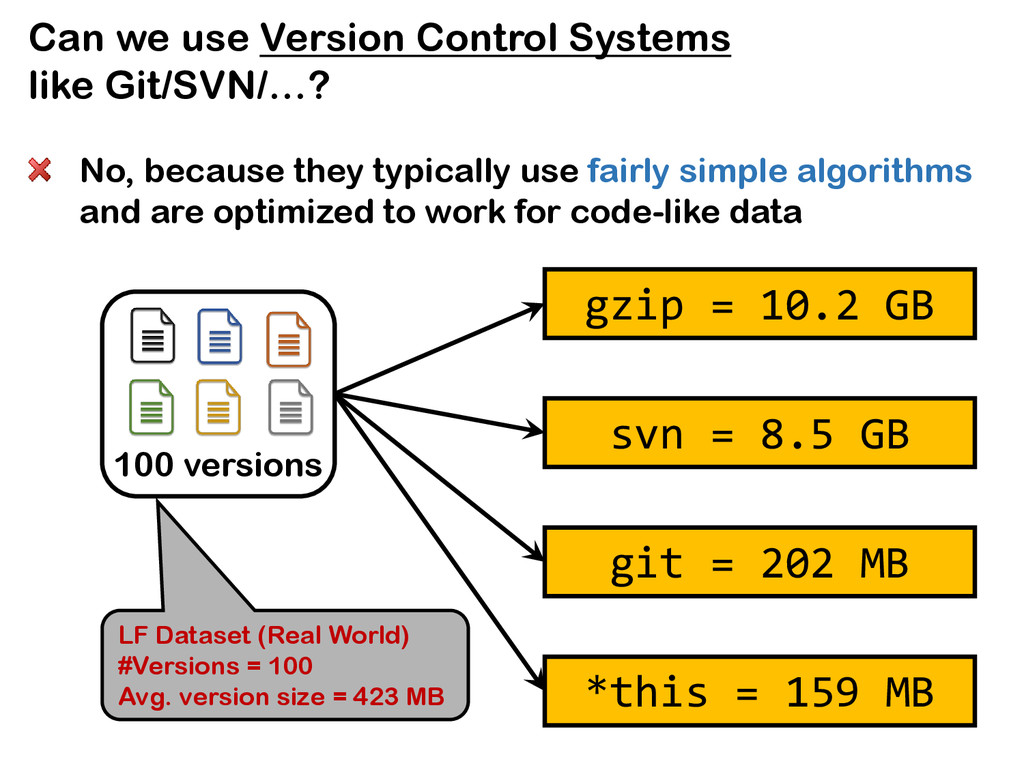
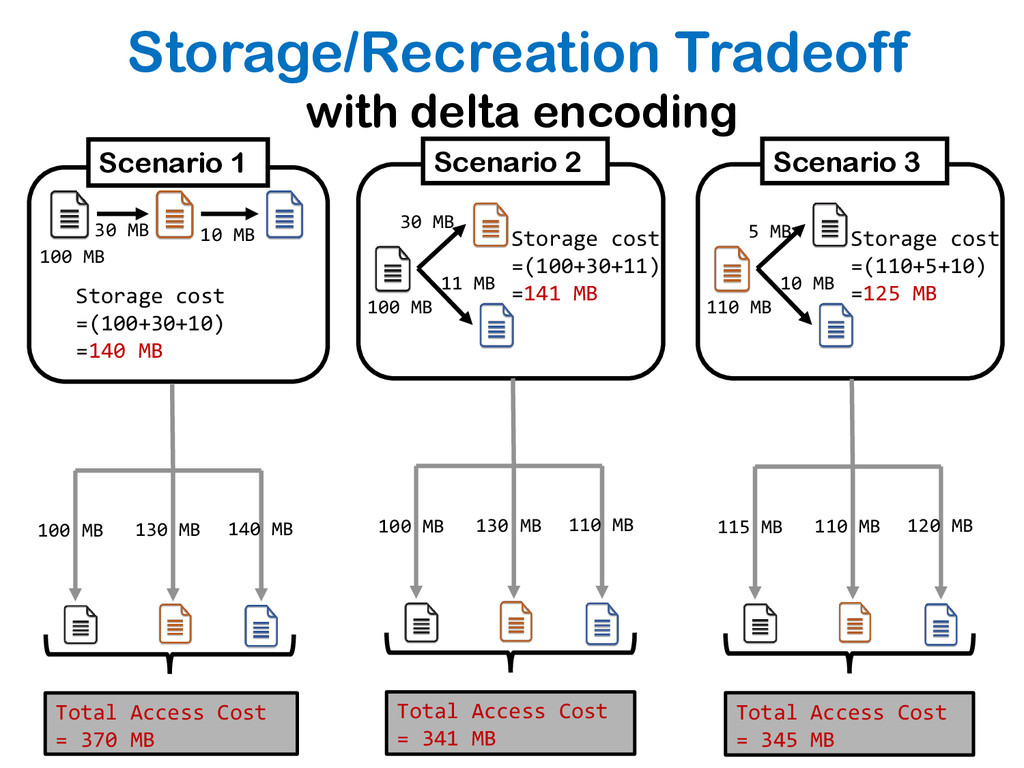
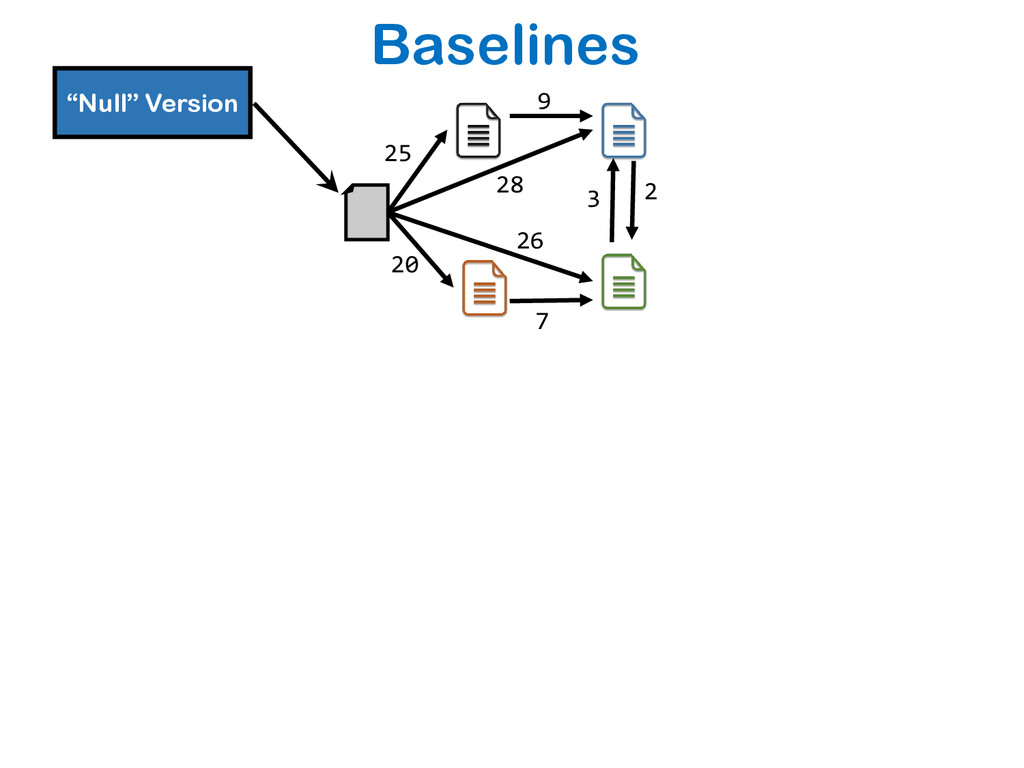
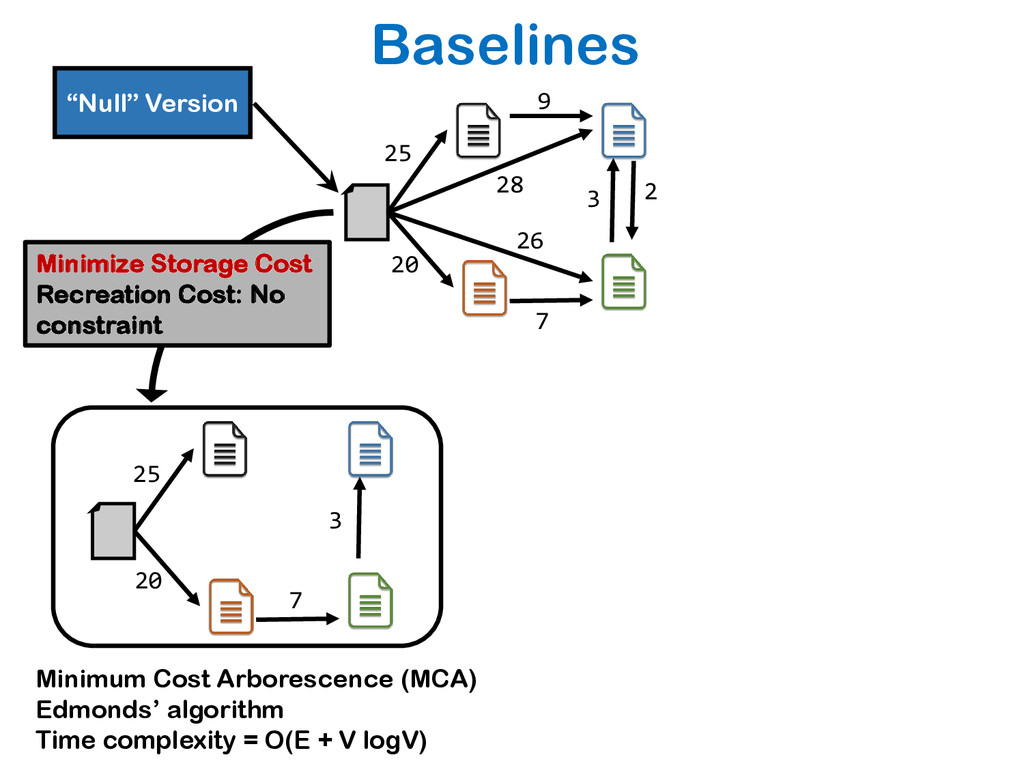
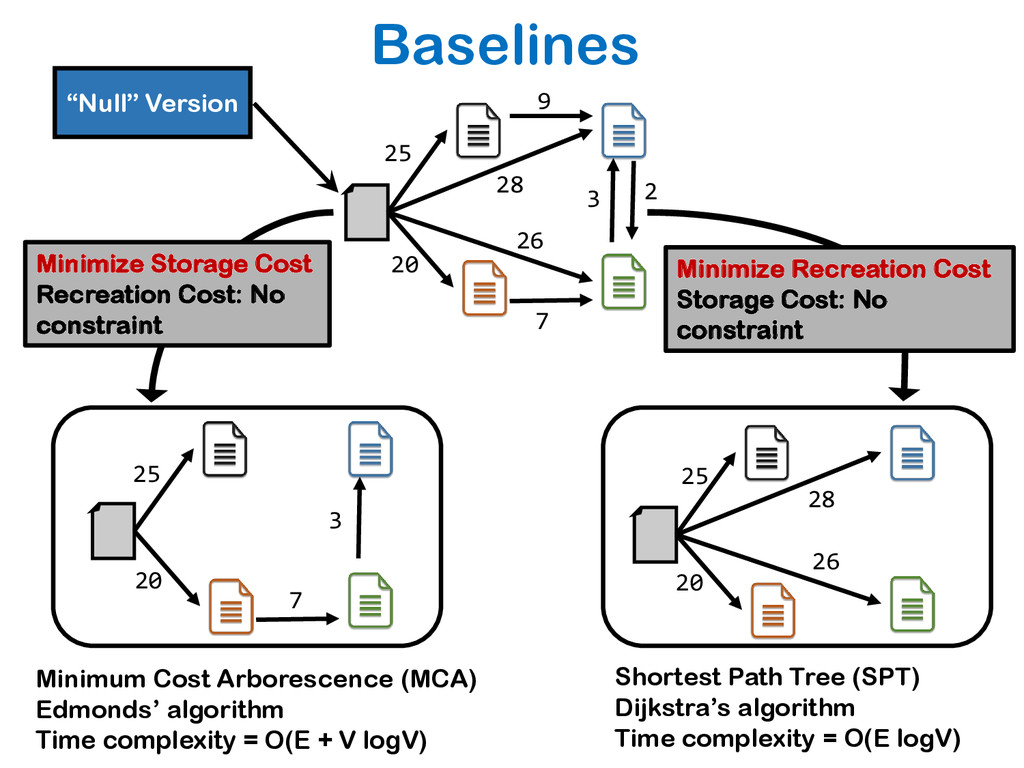
The relative ease of collaborative data science and analysis has led to a proliferation of many thousands or millions of versions of the same datasets in many scientific and commercial domains, acquired or constructed at various stages of data analysis across many users, and often over long periods of time. Managing, storing, and recreating these dataset versions is a non-trivial task. The fundamental challenge here is the storage-recreation trade-off: the more storage we use, the faster it is to recreate or retrieve versions, while the less storage we use, the slower it is to recreate or retrieve versions. Despite the fundamental nature of this problem, there has been a surprisingly little amount of work on it. In this paper, we study this trade-off in a principled manner: we formulate six problems under various settings, trading off these quantities in various ways, demonstrate that most of the problems are intractable, and propose a suite of inexpensive heuristics drawing from techniques in delay-constrained scheduling, and spanning tree literature, to solve these problems. We have built a prototype version management system, that aims to serve as a foundation to our DataHub system for facilitating collaborative data science. We demonstrate, via extensive experiments, that our proposed heuristics provide efficient solutions in practical dataset versioning scenarios.
Paper:
http://arxiv.org/abs/1505.05211
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
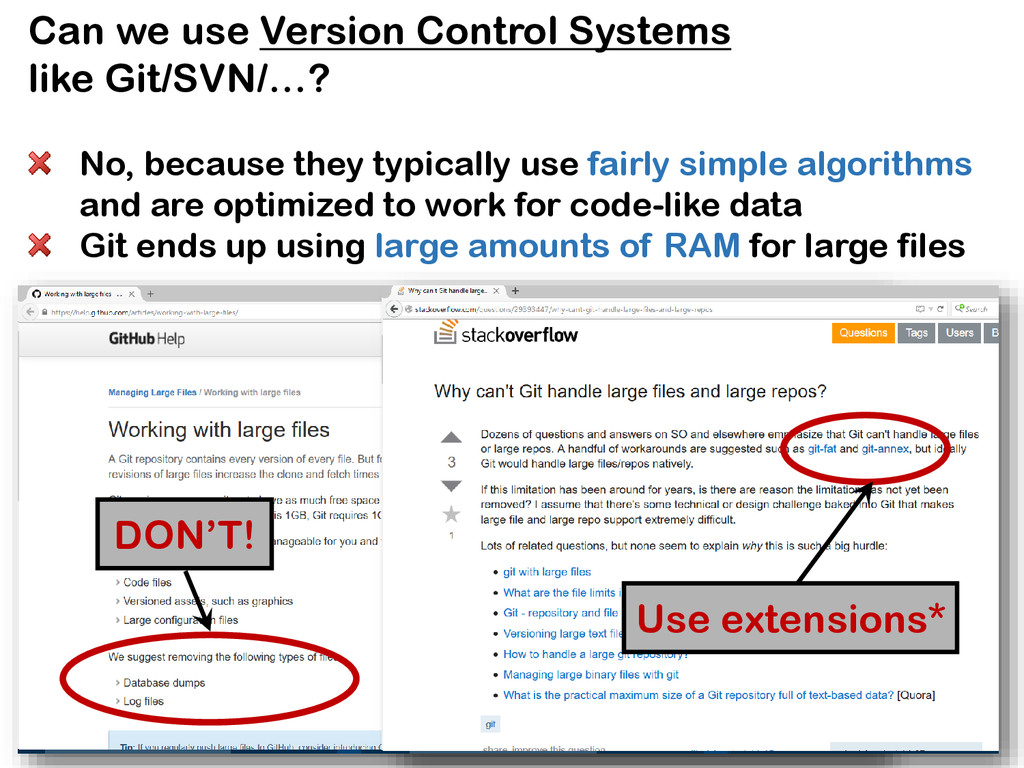{kind=link}
{kind=link}
{kind=link}
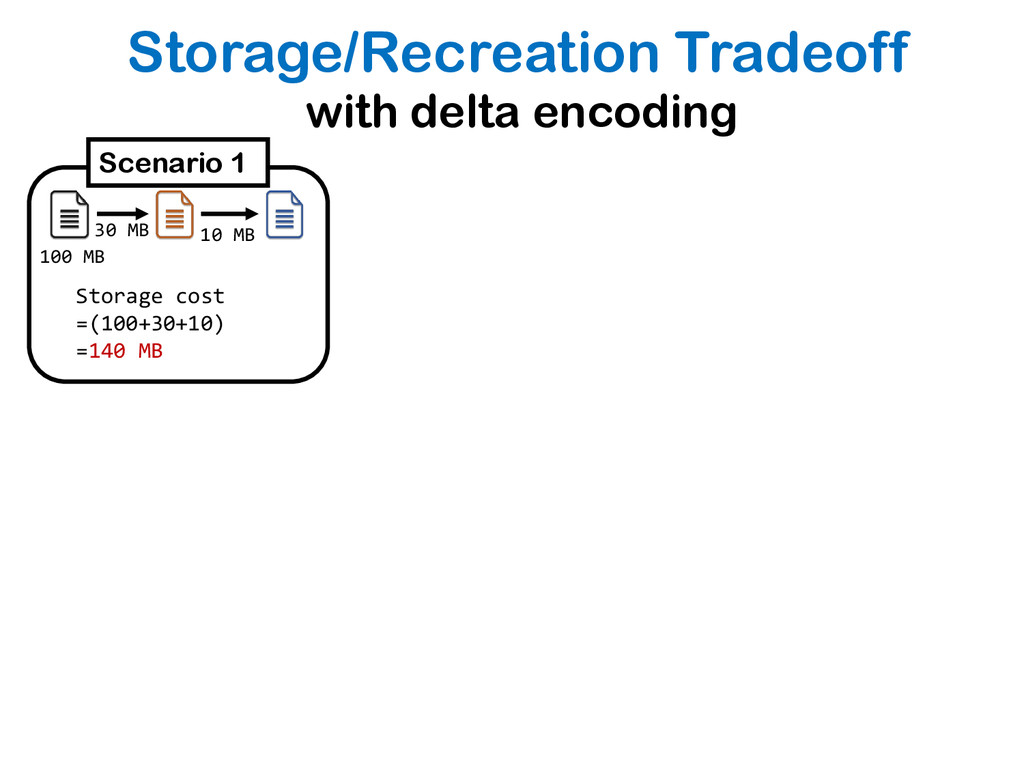{kind=link}
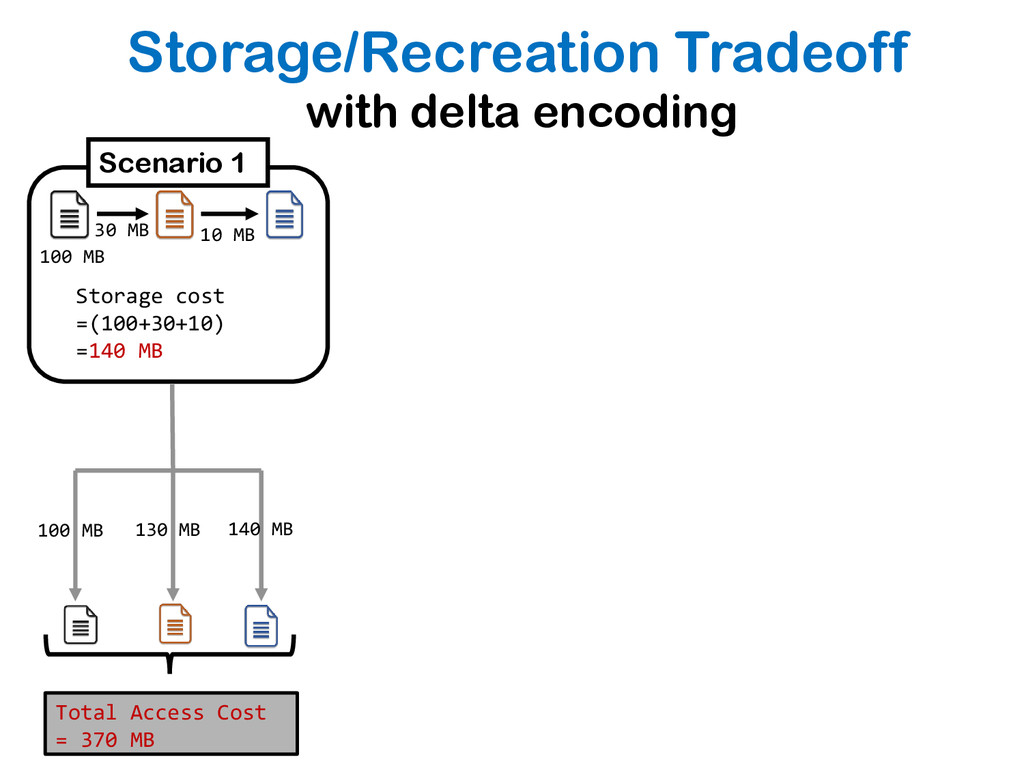{kind=link}
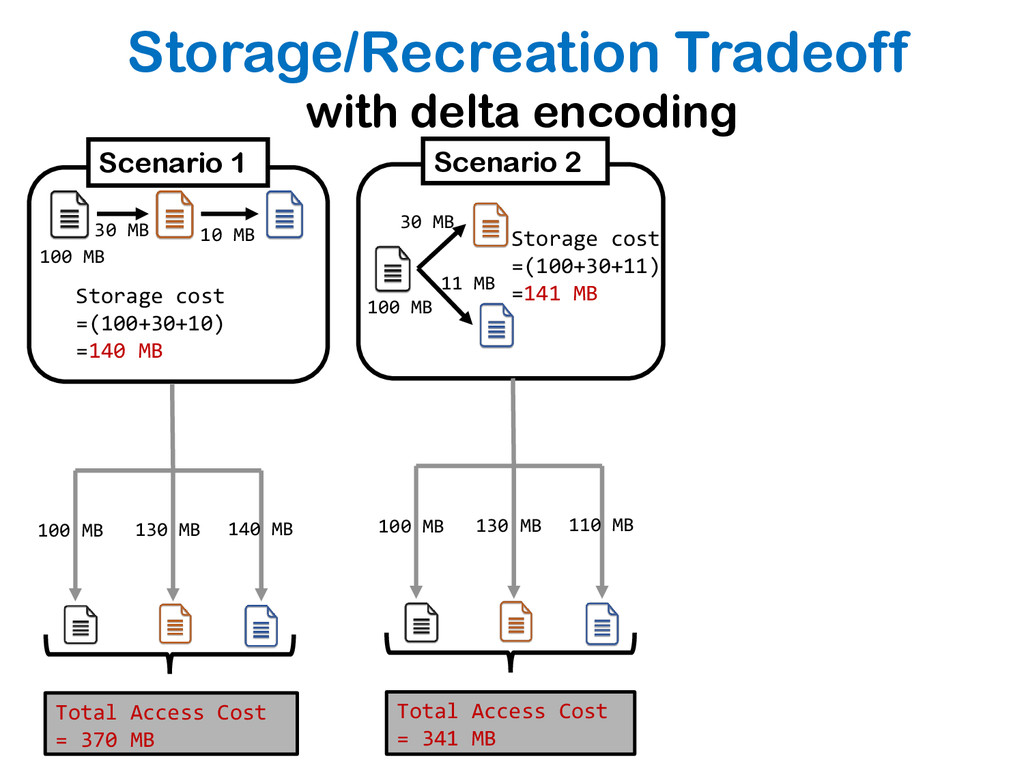{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}