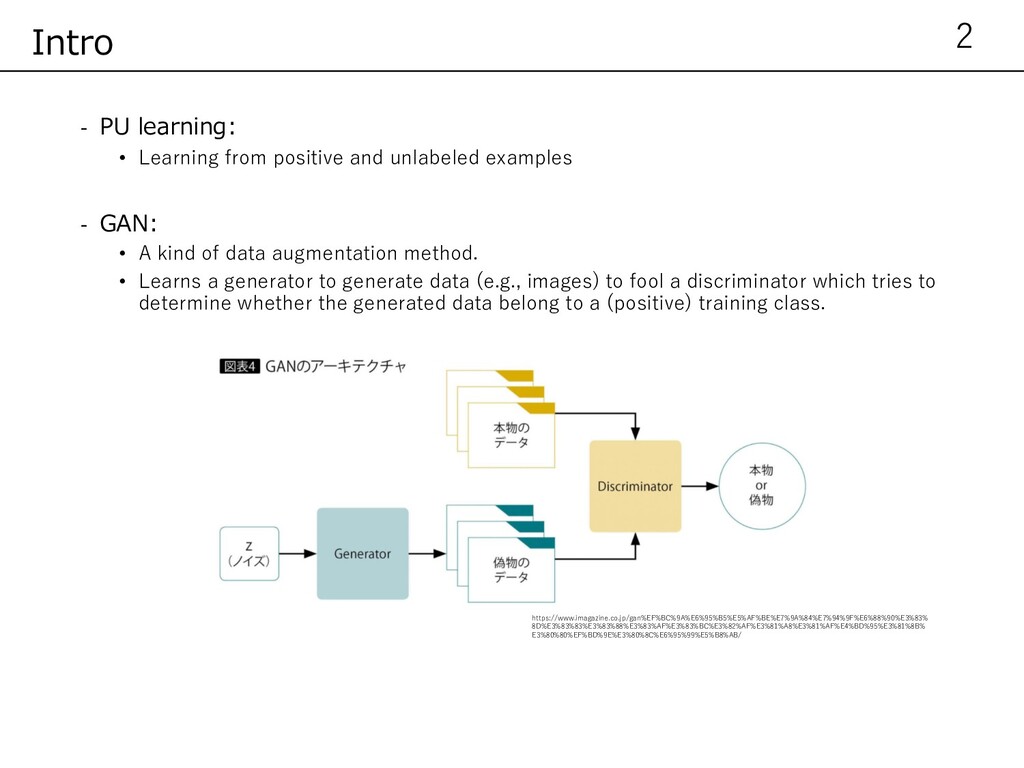
- GAN: • A kind of data augmentation method. • Learns a generator to generate data (e.g., images) to fool a discriminator which tries to determine whether the generated data belong to a (positive) training class. 2 Intro https://www.imagazine.co.jp/gan%EF%BC%9A%E6%95%B5%E5%AF%BE%E7%9A%84%E7%94%9F%E6%88%90%E3%83% 8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AF%E3%81%A8%E3%81%AF%E4%BD%95%E3%81%8B% E3%80%80%EF%BD%9E%E3%80%8C%E6%95%99%E5%B8%AB/
applying GAN is problematic because GAN focuses on only the positive data. • The resulting PU learning method will have high precision but low recall. - We propose a new objective function based on KL-divergence. (PAN) - Advantage of PAN • A major advantage of PAN is that it does not need the input of class prior probability, which many state-of-the-art systems need. • when the class prior probability estimate is off, the existing methods can perform quite poorly • PAN can be applied to any data as it has no generator. 3 Intro
to generate data instances (e.g., images) similar to those in the real/training data. • It has two networks, a generator G() and a discriminator D(). • G() tries to generate new data instances that can approximate the real data to fool the discriminator. • D() tries to discriminate the generated data from the real data 4 Background: GAN Discriminator: RealデータをPositiveにGeneratorが作ったデータをNegativeに Generator: DiscriminatorがPositiveと識別するように
PU learning, called a-GAN • The goal of C() is to identify likely positives in the unlabeled set U to give to the discriminator for it to decide whether these are real positive data. 5 Direct Adaptation of GAN for PU Learning
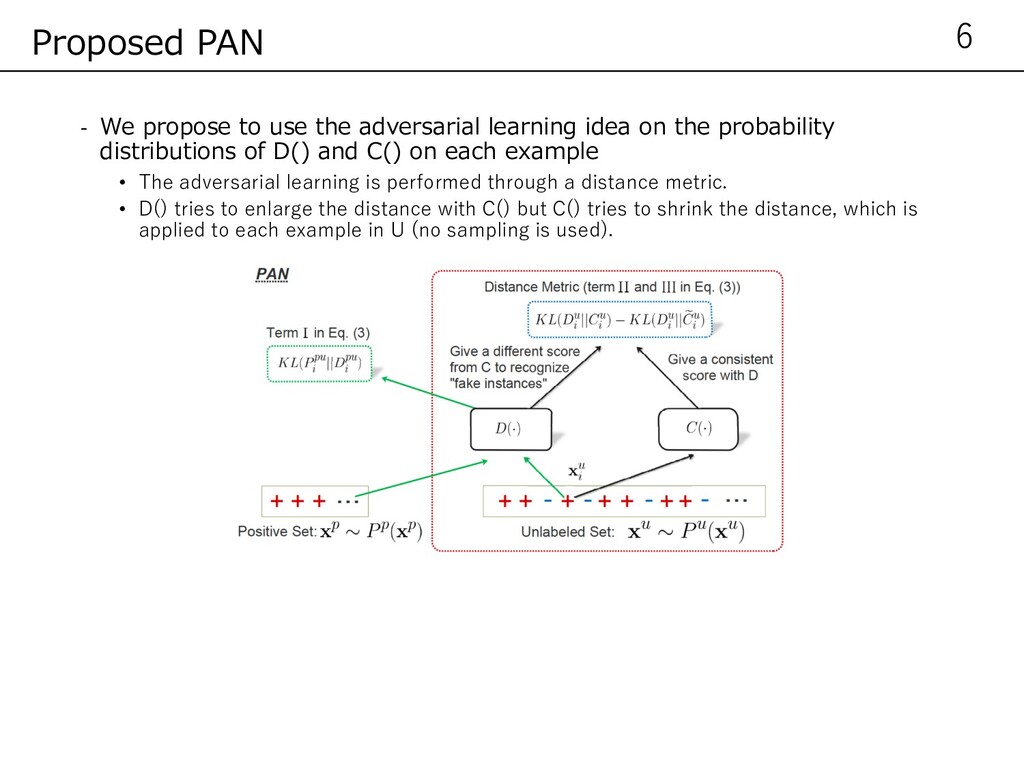
the probability distributions of D() and C() on each example • The adversarial learning is performed through a distance metric. • D() tries to enlarge the distance with C() but C() tries to shrink the distance, which is applied to each example in U (no sampling is used). 6 Proposed PAN
• Discriminator: Classifierのopposite distributionと近くなるように - II can cause unbalanced training between positive and negative examples and lead to high precision and low recall. To this end, we propose the term marked III which can eliminate the concern 7 Proposed PAN
D() is: - In Term (a) and Term (b), asymmetric for positive and negative data as positive data exist in the unlabeled set. That causes the positive being over optimized toward negative. - Also occurs in the gradient for C() 8 Asymmetry of KL(D||C) for Positive and Negative Data
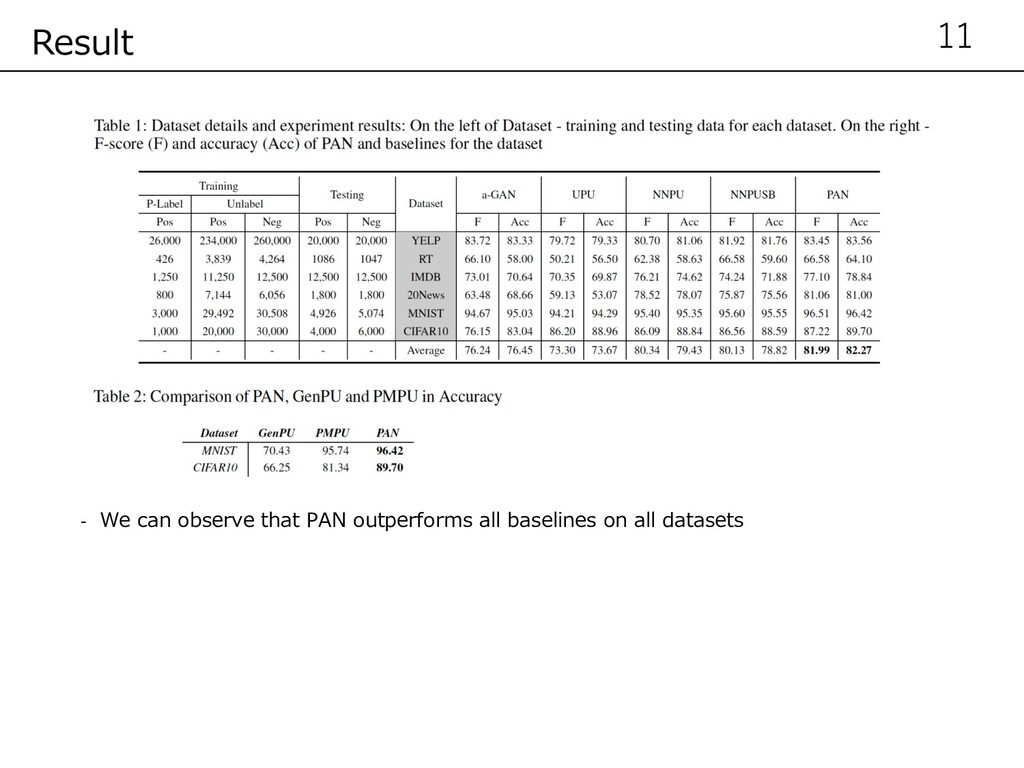
PU More robust PU Note that both UPU and NNPU need the input of the class prior probability, which is often not available in practice. In our experiments, we give them the correct class priors.
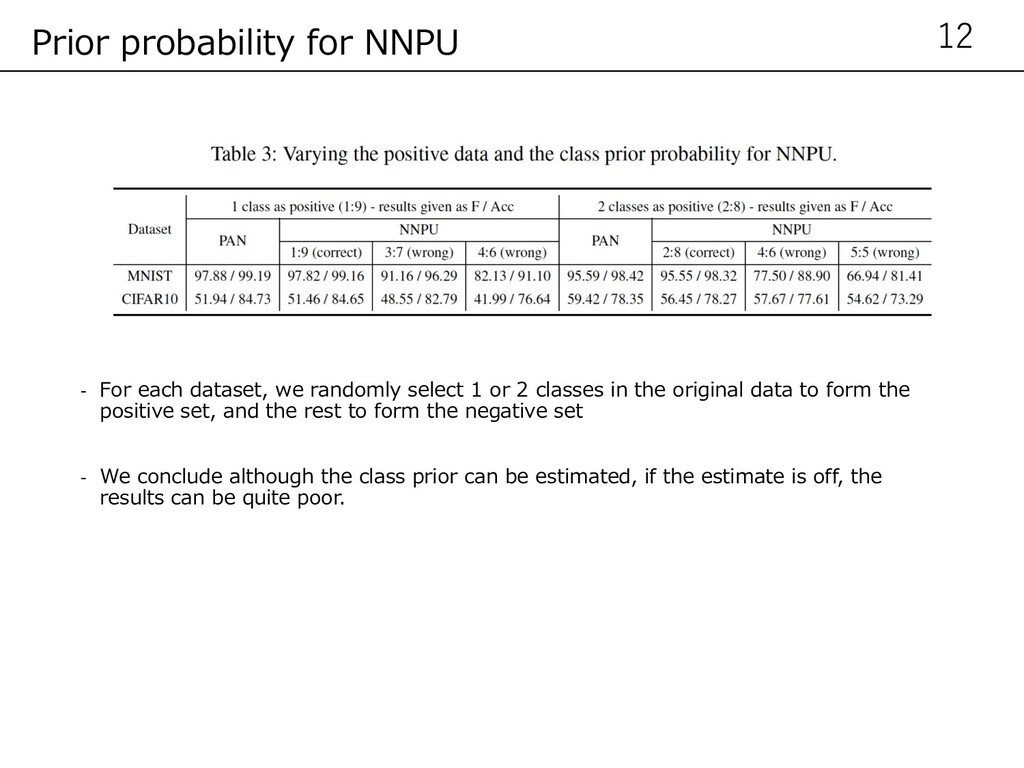
classes in the original data to form the positive set, and the rest to form the negative set - We conclude although the class prior can be estimated, if the estimate is off, the results can be quite poor. 12 Prior probability for NNPU
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}