acceptable or not? • Metrics • Perceived quality from the end-users perspective • Common SLI's: Availability, Throughput, Latency, etc SLI - SERVICE LEVEL INDICATOR
for maintenance for about 53 minutes over the course of the last year, we could claim that the service had 99.99% availability for the same period. • Availability Table: https://landing.google.com/sre/sre-book/chapters/availability-table/ SLI EXAMPLE: AVAILABILITY
target • How well I'm doing against it? • Generally consists of 3 parts: - Description of the thing that we are measuring (SLI) - Expected service level expressed as a percentage - Period where the measurement takes place SLO - SERVICE LEVEL OBJECTIVE
a single month must be at least 99% • The response time for 95% of service requests to X, when measured in a period of a year, must not exceed 100ms • The cpu utilisation for the database, when measured in a period of a day, must be in the range [40%-70%] SLO EXAMPLE
service consumers. • Willing to do (refund money for example) if you are failing to meet the objectives. • The SLA outlines a set of SLOs that have to be met and the consequences for both meeting and failing to meet them SLA - SERVICE LEVEL AGREEMENT
24 hours. But that same SLA doesn’t spell out what happens if the client takes 24 hours to send answers or screenshots to help your team diagnose the problem. Does it mean the team’s 24-hour window been eaten up by client slow-downs or does the clock start and stop based on when clients respond? • PRO-TIP: tech should be involved in the creation of SLAs SLA EXAMPLE
= (Nº of GOOD interactions) - (Nº of TOTAL interactions) POs and SREs define an availability target • Error Budget = (100% reliability) - (SLO) Example: 99.9% of SLO = 43min error budget a month • Developers can manage the risk themselves: decide how to spend their error budget • Developer teams become self-policing • Shared responsibility for system uptime: infrastructure failures eat into the devs error budget ERROR BUDGET
can ship new features to improve the overall quality of the product • Ops engineers can focus more heavily on long-term reliability projects, such as database maintenance and process automation • But when the error budget begins running low, developers will need to slow down or freeze feature work — and work closely with the ops team to restabilize the system before any SLAs or SLOs are violated. • Error budgets act as a quantifiable method for aligning the work and goals of Developers and Ops engineers. ERROR BUDGET
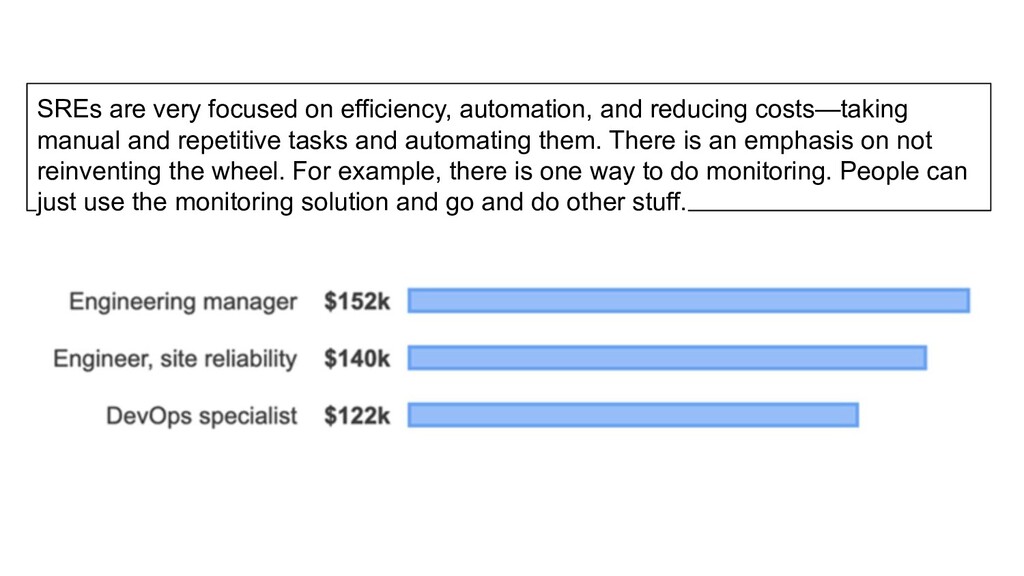
manual and repetitive tasks and automating them. There is an emphasis on not reinventing the wheel. For example, there is one way to do monitoring. People can just use the monitoring solution and go and do other stuff.
scale problems that have a lot of moving parts? 2. Do you like thinking about how to make large systems more reliable? 3. Are you okay with working on software that will likely never be overtly seen by an external user? 4. Do you enjoy looking at a terminal for large amounts of time? 5. Do you enjoy the process of diagnosing and fixing a problem? If yes, what if the diagnosis involves system level problems that you cannot always see? 6. Do you enjoy thinking about system information (e.g. disk space, cpu, os, kernel, etc.) and system level functionality (e.g. ssh, proc, cron, swaps, etc.)? 7. Are you comfortable with the idea of being “on-call” in which you are likely to be in high-stakes scenario where something needs to be fixed? 8. Are you able to stay calm under pressure? 9. Do you approach problems in a logical, process-oriented way? 10. Are you comfortable attempting a problem that has never been solved before? 11. Are you someone who thinks about how you can make things better?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected], @andrealmar_ on Twitter, @andrealmar on Instagram andrealmar.com This presentation](https://files.speakerdeck.com/presentations/c0c30a08d45f420a9235b7b3b9f63acd/slide_22.jpg){kind=link}