manual analysis: a. Which are the Top 10 largest objects? b. Which are the Top 10 lines of code which allocate the most memory? Usually good at answering: a. Which types are the most common in memory? But that doesn’t provide a lot of value All fail when you use C extensions
you’ll inevitably introduce a dead-lock. Sadly, there’s no automated tool to detect dead-locks (more on this later) Each software has key performance indicators, how fast we parse X, how many Y per second are we sending to the network, what’s the size of the internal Queue holding Z, etc. Need to know!
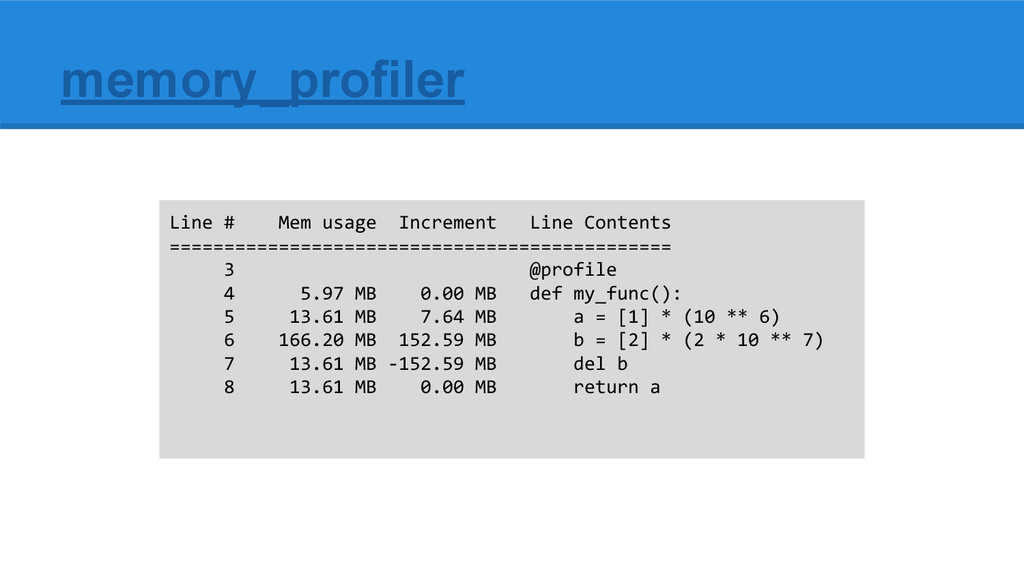
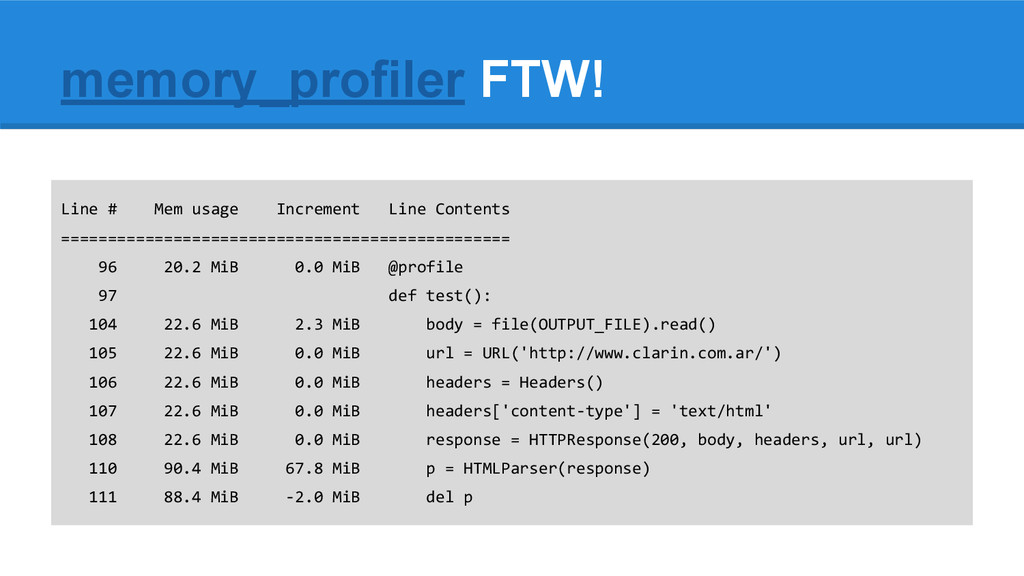
RSS from OS after each line of code, so you can’t decorate “all functions”. You already need to suspect which function is using your memory. 2. Difficult to understand output for loops 3. Information gathering and analysis is done on run time Side note: Understand results: RSS vs. gc referenced data
run time 2. Graphs are difficult to understand for >100 objects. 3. You already need to suspect which object is using a lot of memory >>> objgraph.show_refs([y], filename='sample-graph.png')
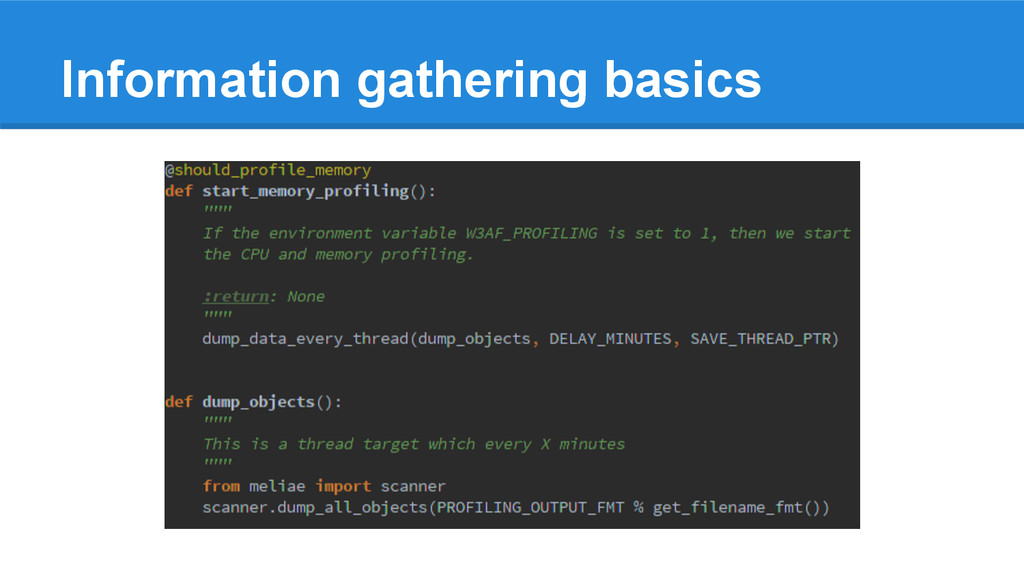
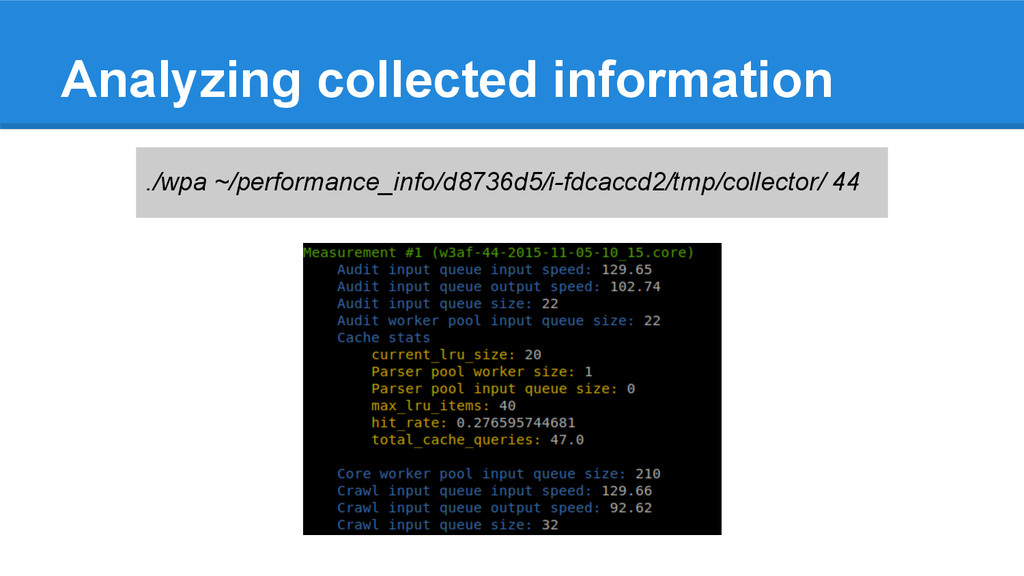
periodically and dump to file (allows “diffs” in analysis phase) 3. Automate information gathering and analysis 4. Store performance information (allows performance “diffs” between different software versions)
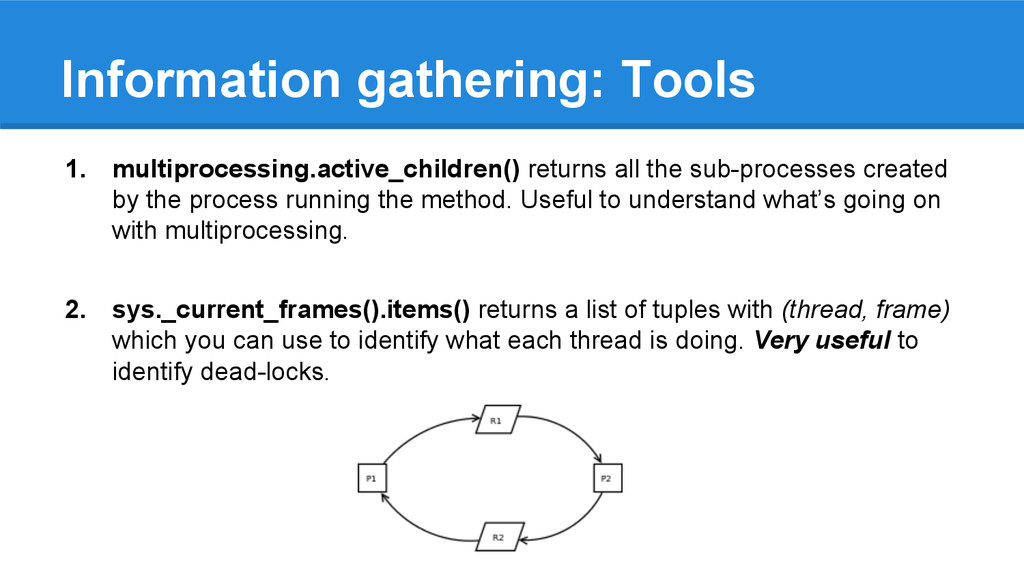
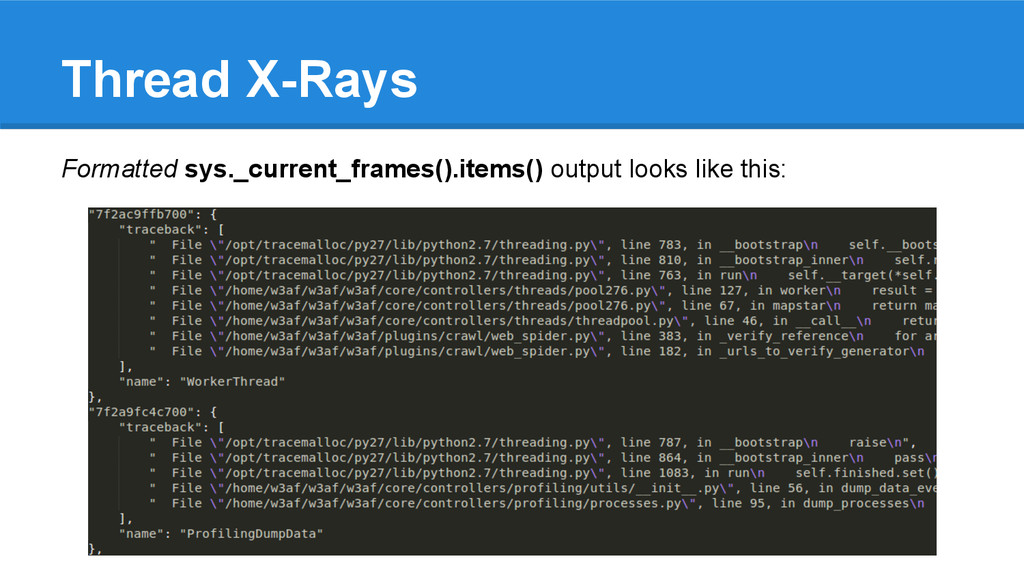
by the process running the method. Useful to understand what’s going on with multiprocessing. 2. sys._current_frames().items() returns a list of tuples with (thread, frame) which you can use to identify what each thread is doing. Very useful to identify dead-locks.
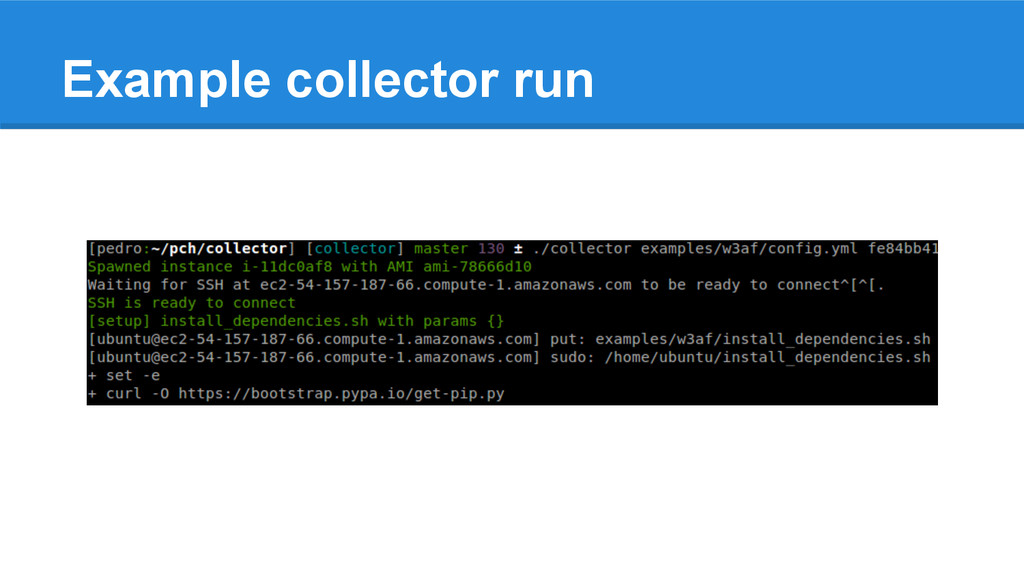
EC2 instance 2. Checkout git revision to test 3. Run the software 4. Download the profiling information to workstation 5. Upload profiling information to S3 Awesome because: 1. Run different commits with the same instance type to compare 2. Run the same software with different instance types to understand if your software runs well with small amount of RAM / only one CPU core ./collector config.yml <git-revision>
instance type to compare them 2. Run the same commit multiple times to make sure the collected information is statistically significant 3. Run the same software with different instance types to understand if your software runs well with small amount of RAM / only one CPU core; or with huge amounts of RAM and multiple cores ./collector config.yml <git-revision>
code takes time if it’s done each time a new instance is started. So I had to use docker: 1. The EC2 instances start from a “saved state” persisted in a custom AMI 2. Then we pull and run the docker image andresriancho/w3af- collector which contains: a. w3af dependencies b. Profiling modules: meliae, yappi, psutil, etc. c. Custom compiled python (with pytracemalloc)
doing and identify dead- locks. The analysis is completely manual, but we could hack a small tool which will identify dead-locks in an automated way during the evening.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![memory_profiler @profile def my_func(): a = [1] * (10 **](https://files.speakerdeck.com/presentations/756cc4e12ad34bb6ae8dfbce9d9654f5/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![objgraph >>> x = [] >>> y = [x, [x],](https://files.speakerdeck.com/presentations/756cc4e12ad34bb6ae8dfbce9d9654f5/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}