Presentation to the Data Engineering Melbourne meetup: https://www.meetup.com/fr-FR/Data-Engineering-Melbourne/events/277038718/
In this talk, Andy Petrella will do 50% live coding (scala, python) and 50% highlights on best practices to help data teams keep calm and let AI go to production.
Andy is an entrepreneur with a Mathematics and Distributed Data background focused on unleashing unexploited business potentials leveraging new technologies in machine learning, artificial intelligence, and cognitive systems.
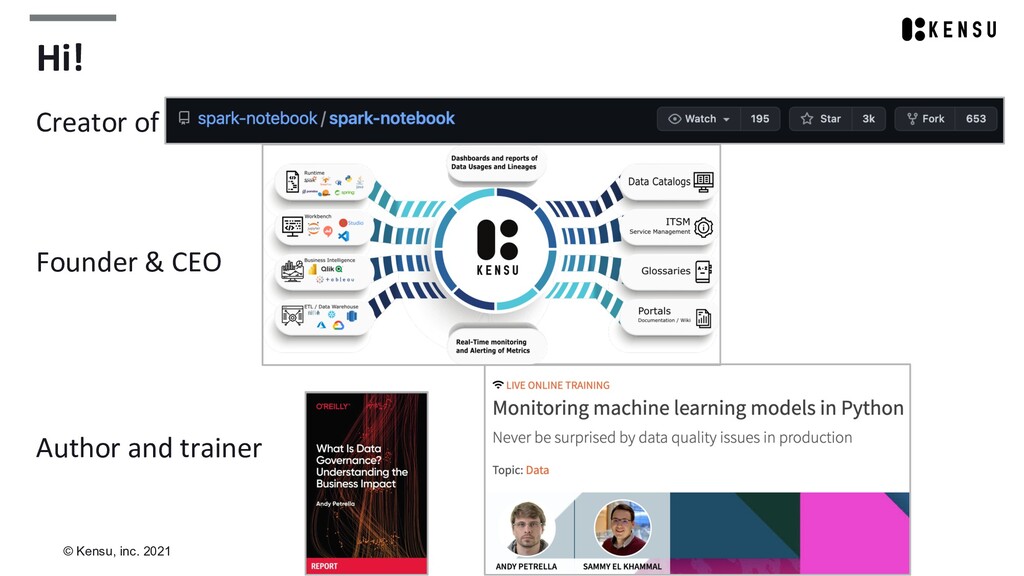
In the data community, Andy is known as an early evangelist of Apache Spark (2011-), the Spark Notebook creator (2013-), a public speaker at various events (Spark Summit, Strata, Big Data Spain), and an O'Reilly author (Distributed Data Science, Data Lineage Essentials, Data Governance, and Machine Learning Model Monitoring).
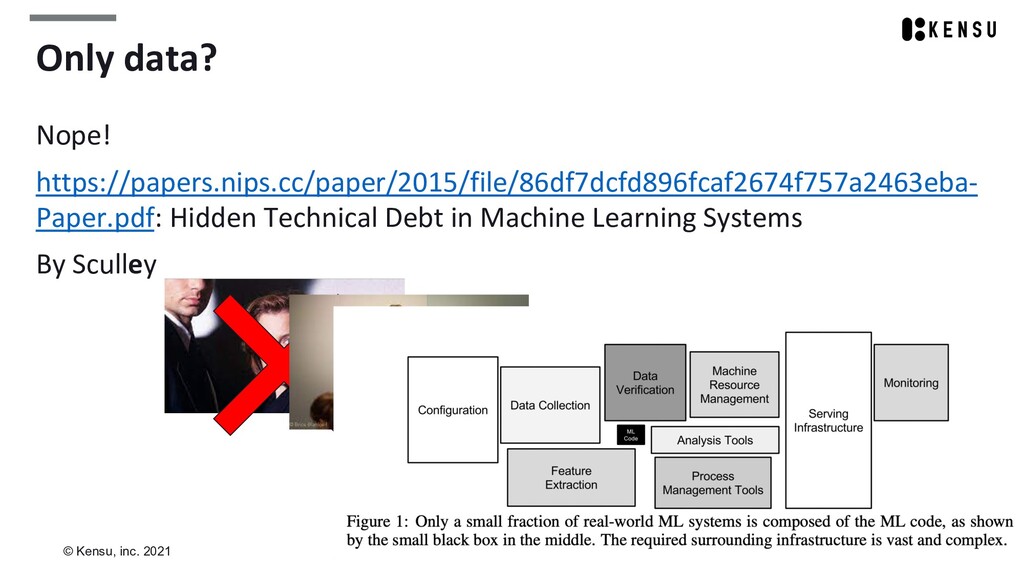
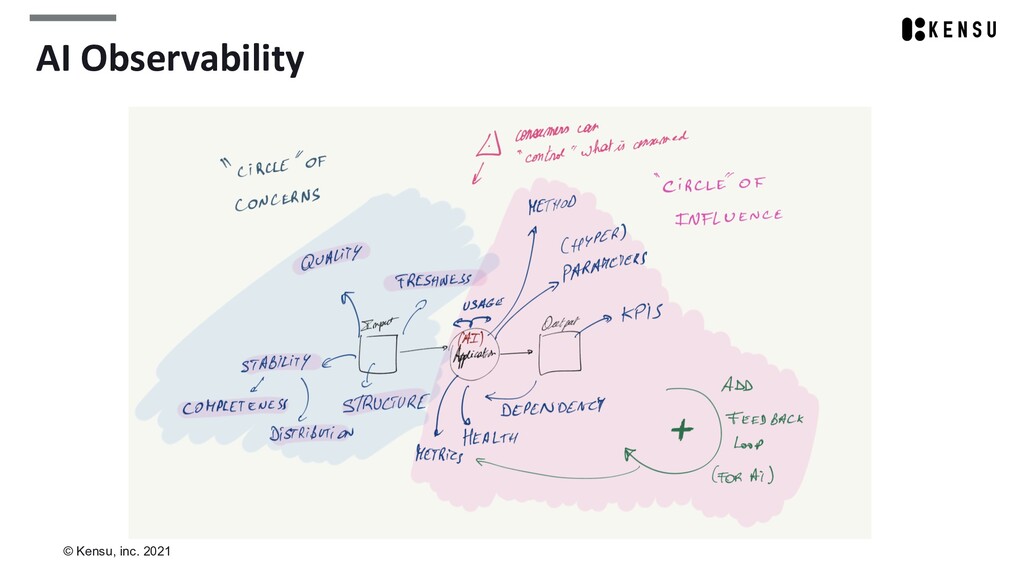
Andy is the CEO of Kensu, bringing the Data Intelligence Management (DIM) Platform for data-driven companies to leverage AI sustainably, combining AI Observability with Data Usage Catalog.
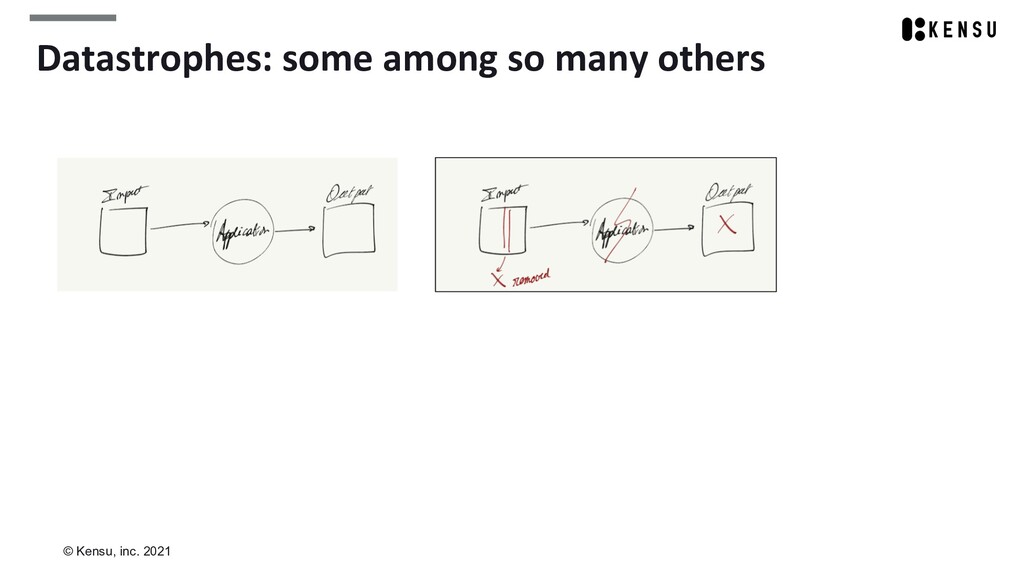
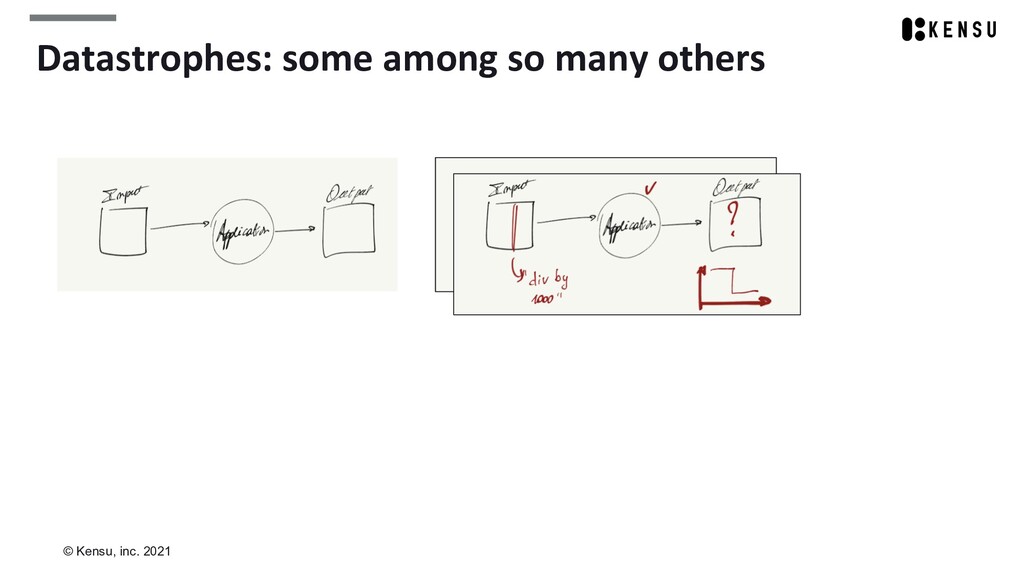
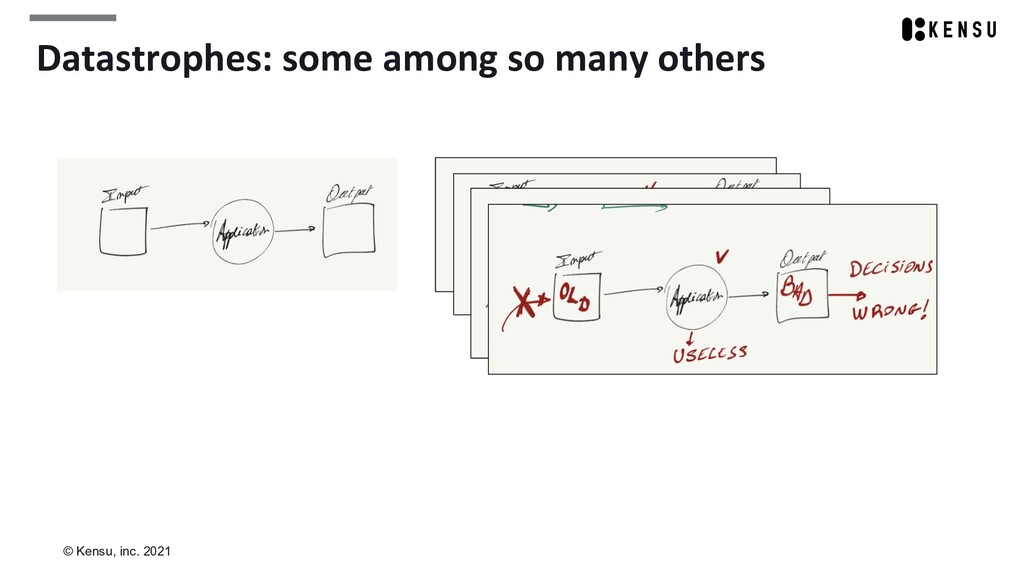
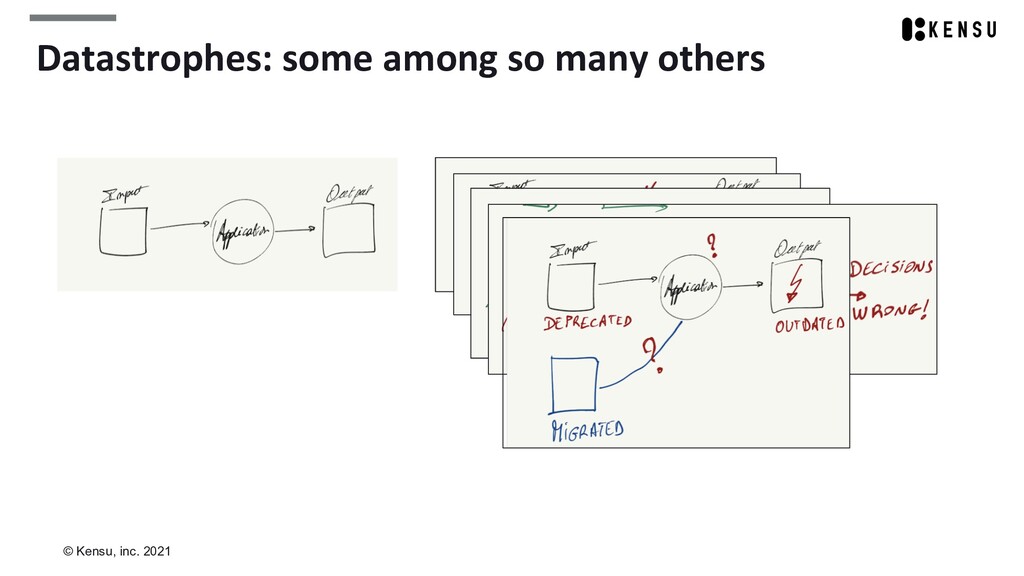
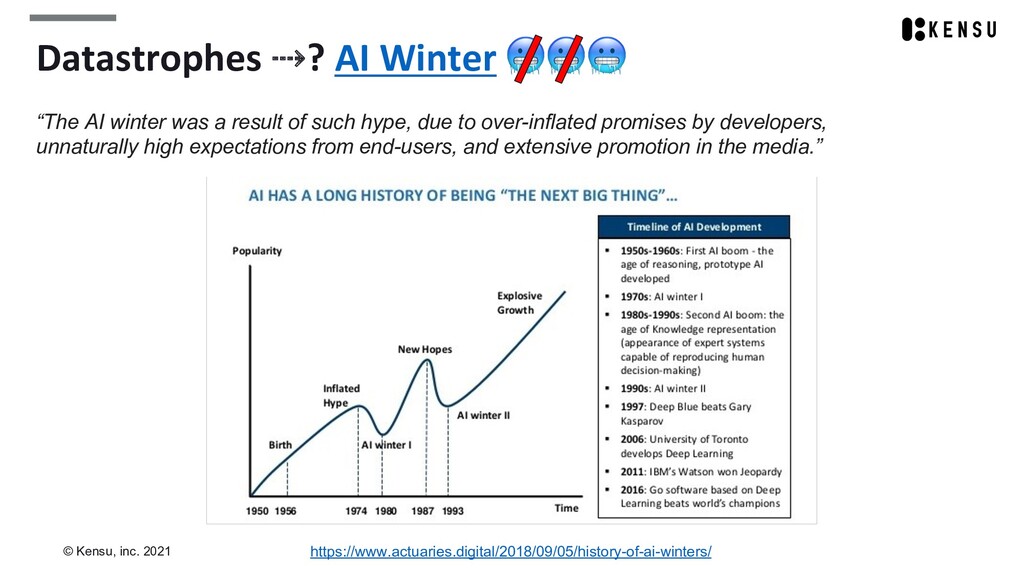
We’ll take the opportunity to introduce concepts like datastrophes, data as a product, and federated governance.
In the end, you’ll have a grasp of the relationship between monitoring data and AI, data mesh, and advanced data discovery.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}