Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
How Postgres Could Index Itself
Search
Andrew Kane
September 08, 2017
Programming
3.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
How Postgres Could Index Itself
Andrew Kane
September 08, 2017
Other Decks in Programming
See All in Programming
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
Lean は証明の正しさを確認するためだけのツールって思ってませんか?
inoueasei
1
100
フィードバックで育てるAI開発
kotaminato
1
120
トークンをケチるな、設計しろ:GitHub Copilotを賢く使うコンテキスト戦略
ochtum
0
330
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
190
The Past, Present, and Future of Enterprise Java
ivargrimstad
0
360
symfony/aiとlaravel/boost
77web
0
140
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
180
Laravel Boostに学ぶ、AIにPHPを書かせる技術 〜OSSの実装から蒸留するエージェント制御の王道〜
kentaroutakeda
3
520
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
2.9k
【やさしく解説 設計編 #1】「ドメイン駆動」と「実装駆動」ってなに? 〜設計の考え方を、たとえ話で学ぼう〜
panda728
PRO
1
120
Apache Hive: そしてCloud Native Lakehouseへ
okumin
1
160
Featured
See All Featured
Mobile First: as difficult as doing things right
swwweet
225
10k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.3k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
GitHub's CSS Performance
jonrohan
1033
470k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
270
How to Talk to Developers About Accessibility
jct
2
420
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
380
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
The Curse of the Amulet
leimatthew05
2
13k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Transcript
How Postgres Could Index Itself
None
github.com/ankane
None
Read speed vs Write speed Space
None
v1
Collect queries Analyze queries
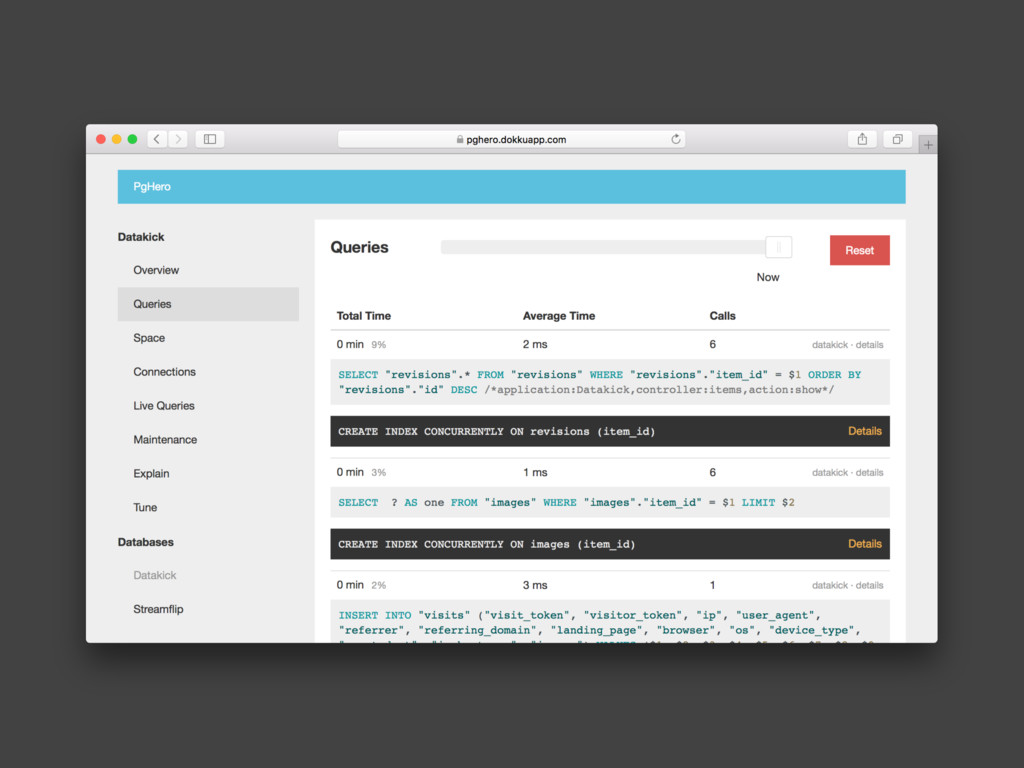
pg_stat_statements Query Total Time (ms) Calls Average Time (ms) SELECT
… 40,000 80,000 0.5 SELECT … 30,000 300 100
SELECT * FROM products WHERE store_id = 1
pg query github.com/lfittl/pg_query _
SELECT * FROM products WHERE store_id = 1
SELECT * FROM products WHERE store_id = 1 AND brand_id
= 2
Stores have many products Brands have a few products
id store_id brand_id 1 1 2 2 4 8 3
1 9 4 1 3 fetch store_id = 1 id store_id brand_id 1 1 2 2 4 8 3 1 9 4 1 3 filter brand_id = 2 id store_id brand_id 1 1 2 2 4 8 3 1 9 4 1 3 id store_id brand_id 1 1 2 2 4 8 3 1 9 4 1 3 filter store_id = 1 fetch brand_id = 2
pg_stats n_distinct null_frac
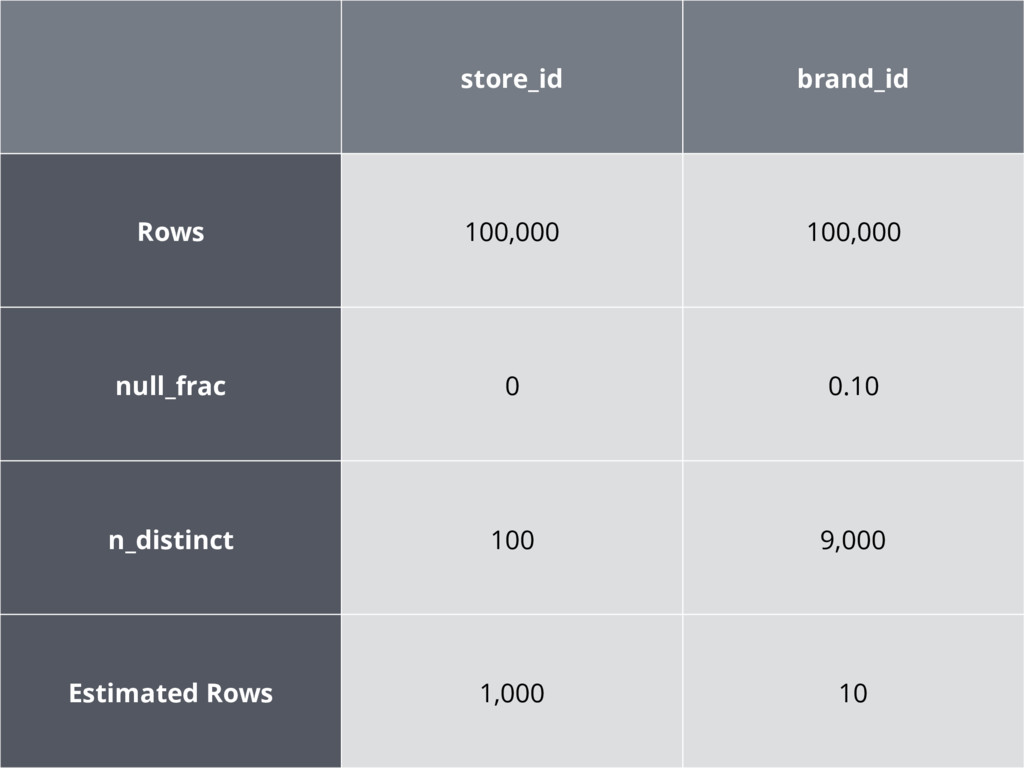
store_id brand_id Rows 100,000 100,000 null_frac 0 0.10 n_distinct 100
9,000 Estimated Rows 1,000 10
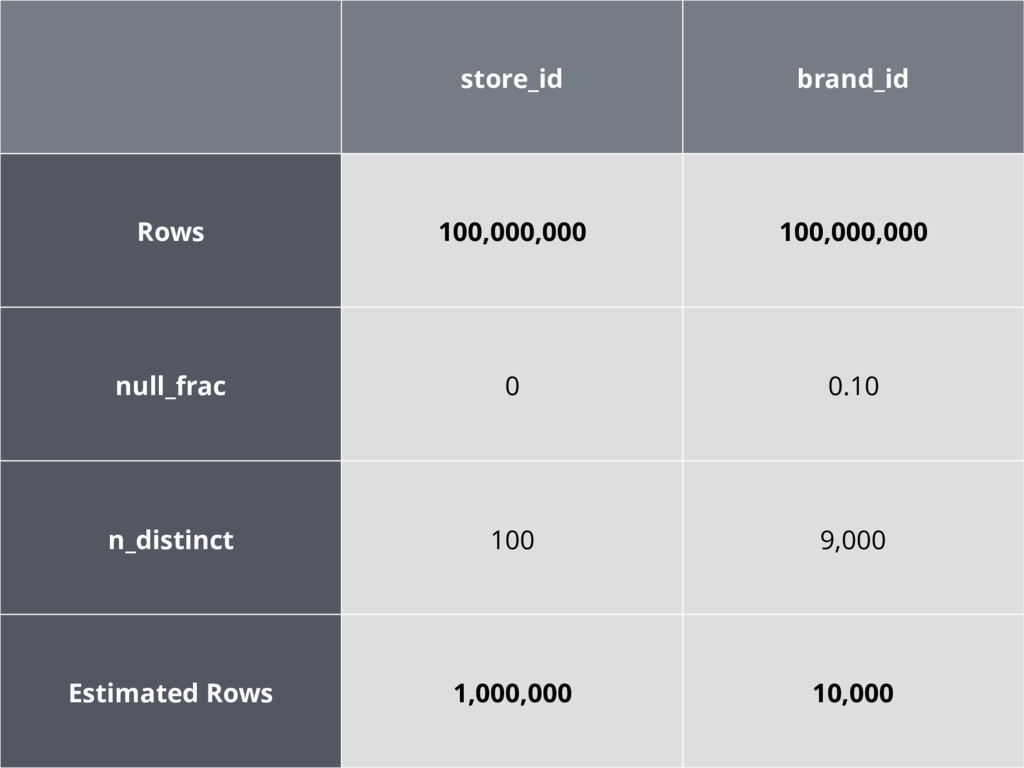
store_id brand_id Rows 100,000,000 100,000,000 null_frac 0 0.10 n_distinct 100
9,000 Estimated Rows 1,000,000 10,000
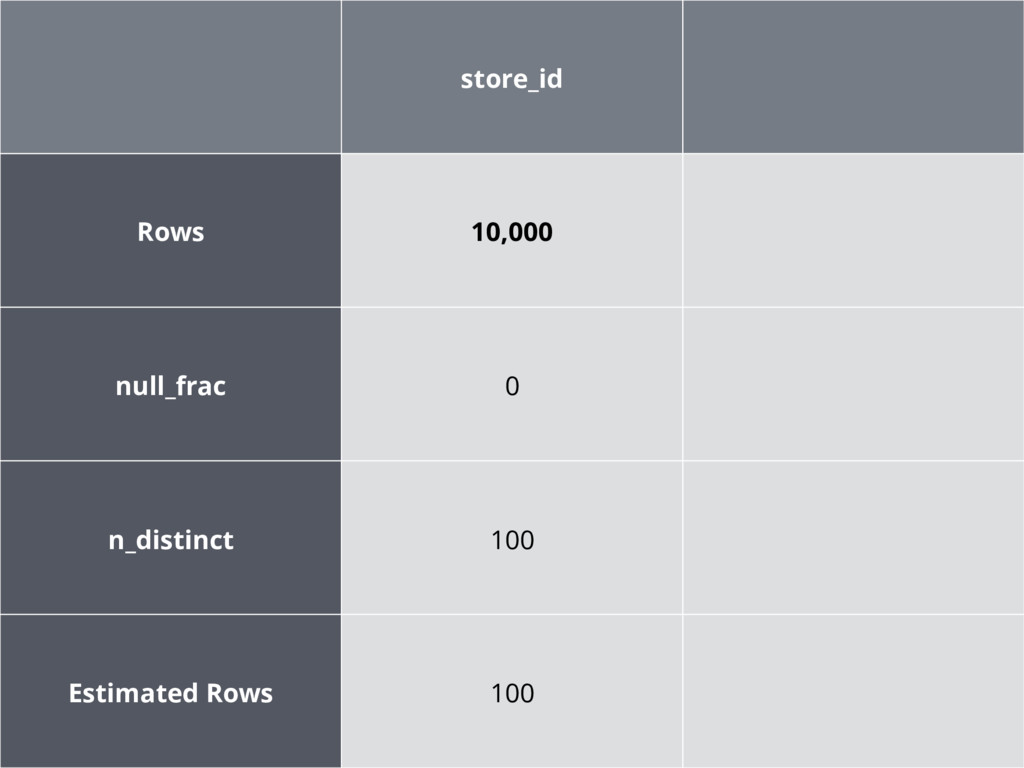
store_id Rows 10,000 null_frac 0 n_distinct 100 Estimated Rows 100
SELECT * FROM products ORDER BY created_at DESC LIMIT 10
SELECT * FROM products WHERE store_id = 1 ORDER BY
created_at DESC LIMIT 10
None
Shortcomings
Single table plus Simple WHERE clause and/or Simple ORDER BY
clause
Duplicating planner logic
pg_stats n_distinct null_frac ✗ most_common_vals ✗ most_common_freqs ✗ histogram_bounds
most_common_vals {2, 5, 1} most_common_freqs {0.9, 0.05, 0.01} store_id =
1 vs store_id = 2
histogram_bounds {0, 9, 25, 60, 99} qty < 5 vs
qty > 5
SELECT * FROM products WHERE store_id = ?
v2
log_min_statement_duration duration: 100 ms statement: SELECT * FROM products WHERE
store_id = 1
Given a query and a set of indexes best indexes
to use
Given a query and all possible indexes best indexes possible
/* Allow a plugin to editorialize on the info we
obtained from the catalogs. Actions might include altering the assumed relation size, removing an index, or adding a hypothetical index to the indexlist. */ get_relation_info_hook 604ffd2
hypopg github.com/dalibo/hypopg
SELECT * FROM products WHERE store_id = 1 AND brand_id
= 2
EXPLAIN Seq Scan on products (cost=0.00..1000.00 rows=100 width=108) Filter: (store_id
= 1 AND brand_id = 2) Final Cost
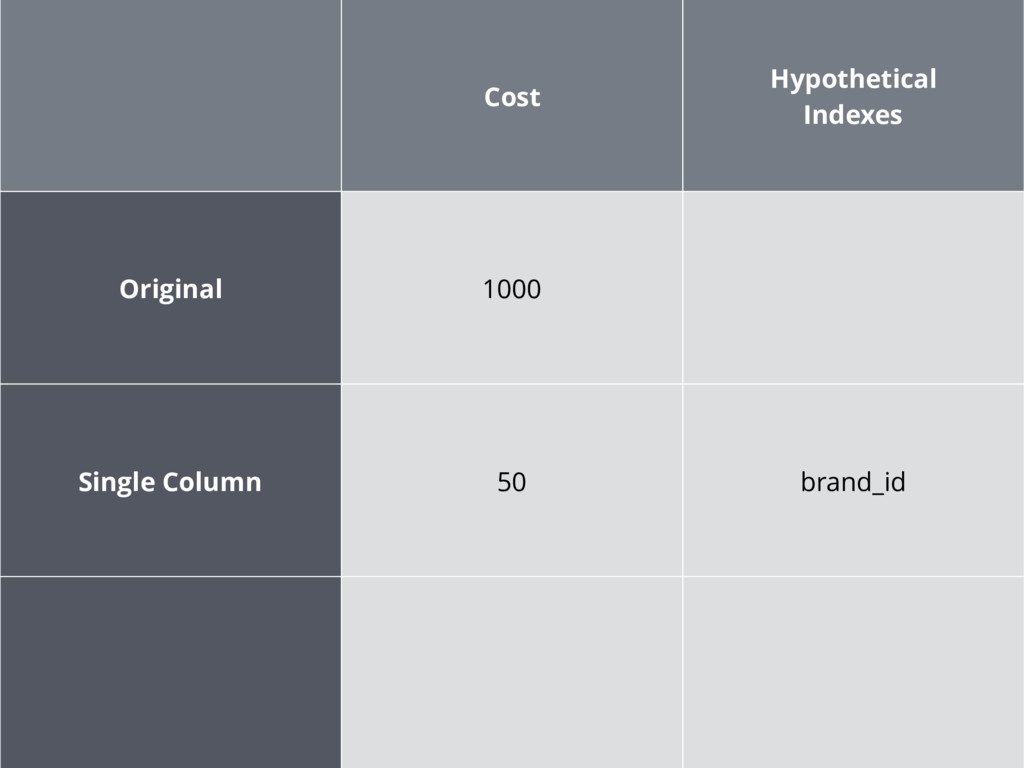
Cost Hypothetical Indexes Original 1000
Add hypothetical indexes store_id brand_id
EXPLAIN Index Scan using <41072>hypo_btree on products (cost=0.28..50.29 rows=1 width=108)
Index Cond: (brand_id = 2) Filter: (store_id = 1) Final Cost Index
Cost Hypothetical Indexes Original 1000 Single Column 50 brand_id
Add hypothetical indexes store_id, brand_id brand_id, store_id (does not try
different sort orders right now)
Cost Hypothetical Indexes Original 1000 Single Column 50 brand_id Multi
Column 45 brand_id, store_id
Dexter github.com/ankane/dexter
tail -F -n +1 <log-file> | dexter <conn-opts>
--create --exclude big_table --min-time 10
Shortcomings
SELECT * FROM products WHERE a = 1 AND b
= 2 SELECT * FROM products WHERE b = 2
B-TREE Only No Expressions No Partial
SELECT * FROM products WHERE qty = 0
DROP INDEX Unused indexes
HypoPG Extension Support
None
pg_query HypoPG
Get Involved github.com/ankane/dexter
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}