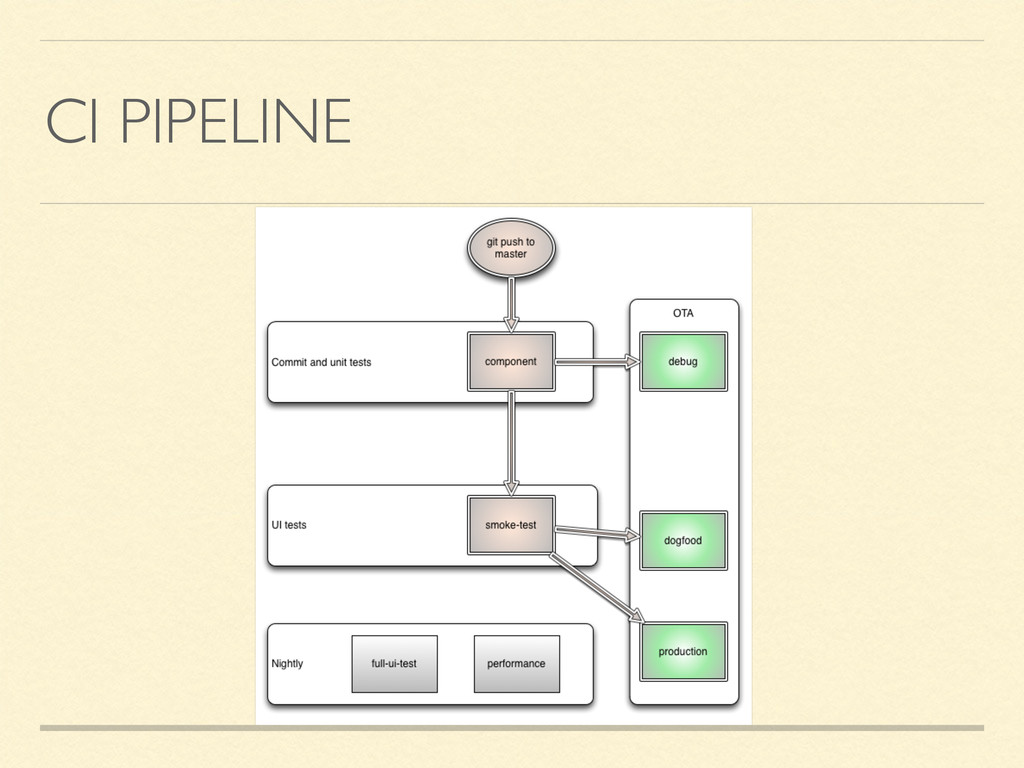
do a pull request to merge Short lived branches, keep PRs brief Master always builds, always shippable All code must be reviewed Compile-time feature toggles “disable” code that is not ready
Slower than plain JUnit tests, but significantly faster than UI tests Very useful as unit tests With architectures such as MVP, can also be acceptance tests
hours to run because of sync issues For sanity checking, a smoke suite will do Relatively fast (10-15min) & simple UI test Ensure app runs and can see all screens
leaks Could be included in automated nightly runs Make sure app activity is restricted Lock monkey in app (e.g. Surelock) Consider removing certain features when monkey runs
the least testing and why?), but should not enforce a coverage target Reasonable to expect acceptance tests with features Enforce testing through code review Tests are code! Refactoring, good architecture, documentation, still apply
one Challenges: All strings needs to be translated Number formatting, currency formatting etc. Support, reviews, release notes Testing load increased — UI issues with some locales only
no lint errors on build Collect all strings early for translation before they block release Have standard release notes saved & translated for emergencies Some test devices permanently on tricky locales
a user to create a team? What are the best triggers for a user to sign in? How often do users share something with friends? Signs of frustration: e.g. repeating identical action
it’s not easy) Don’t reinvent the wheel, use 3rd party tools for this We use Flurry Real challenge: What does user engagement mean? How do you measure it?
invite or share with friends? What makes users more likely to be engaged? Happy? What features do we add or remove? Is a new feature supporting our high level goals? Goal: maximum user satisfaction and engagement with minimum number of features
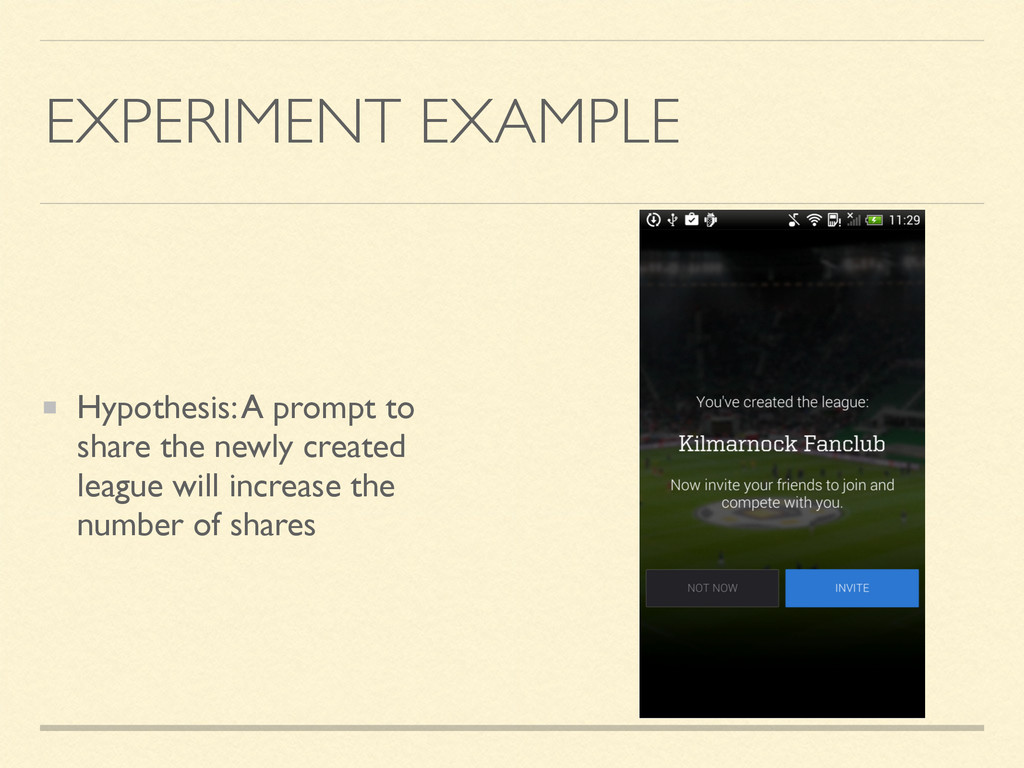
feature in a test bucket (e.g. only for 10% of users) Data is collected for all users, bucket-aware and results are compared across test and control bucket Results can be used to guide product decisions
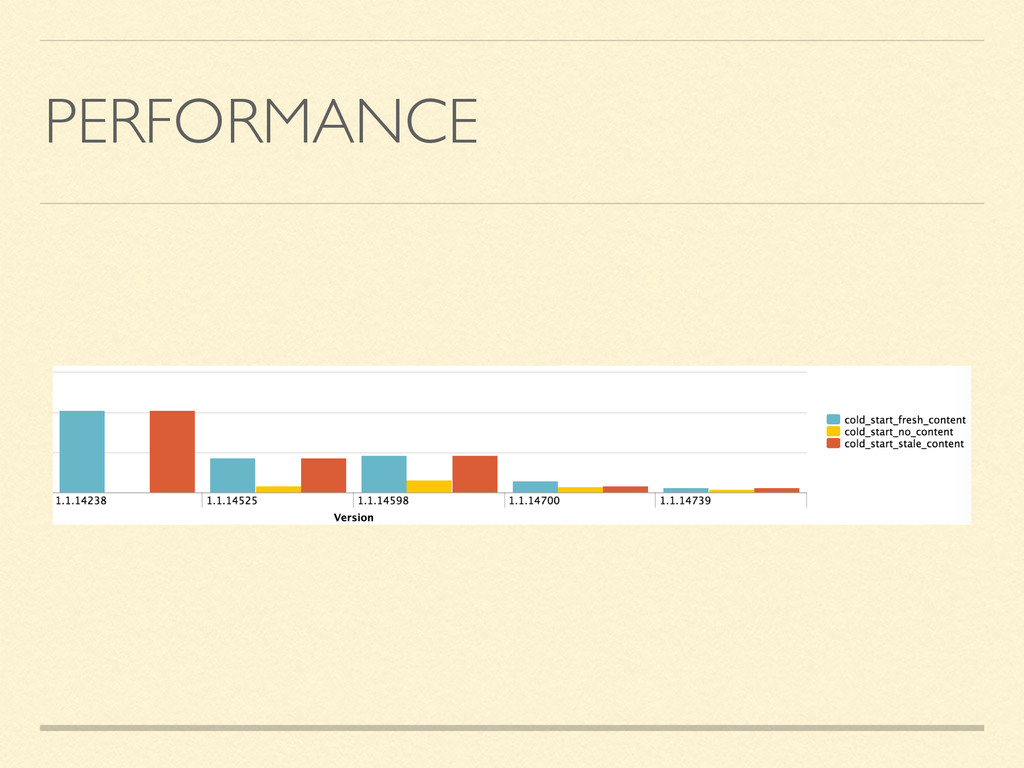
stability Instrument everything, use data to experiment and guide product A/B testing can confirm product hypothesis You should localise your apps, but know what you’re getting into Performance needs prod monitoring and on-going measurement
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}