@threads は入れ 子にできる(Julia v1.8 以降) julia> function my_matmul(A::AbstractMatrix, B::AbstractMatrix) T = promote_type(eltype(A), eltype(B)) C = Matrix{T}(undef, (size(A, 1), size(B, 2))) Threads.@threads for x = axes(B, 2) Threads.@threads for y = axes(A, 1) C[y, x] = @view(A[y, :])' * @view(B[:, x]) end end C end my_matmul (generic function with 1 method) julia> let A=[1 2; 3 4; 5 6; 7 8], B=[1 2 3; 4 5 6] C = my_matmul(A, B) @assert C == A * B @show C; end C = [9 12 15; 19 26 33; 29 40 51; 39 54 69]
fetch() は、同期を 取って結果の値を取 得する関数 julia> function threaded_map(fn, array::AbstractArray) tasks = [Threads.@spawn(fn(v)) for v in array] [fetch(task) for task in tasks] end threaded_map (generic function with 1 method) julia> threaded_map(fib, 15:40) == map(fib, 15:40) true julia> using BenchmarkTools julia> @btime map(fib, 15:40); 1.419 s (1 allocation: 272 bytes) julia> @btime threaded_map(fib, 15:40); 652.908 ms (167 allocations: 13.77 KiB)
• ⇒スレッドアンセーフ julia> mutable struct UnsafeCounter count::Int UnsafeCounter() = new(0) end julia> begin counter1 = UnsafeCounter() for n=1:1000 counter1.count += 1 end counter1.count end 1000 julia> begin counter2 = UnsafeCounter() Threads.@threads for n=1:1000 counter2.count += 1 end counter2.count end 650 # 想定より少ない値になってしまう(ことがある)
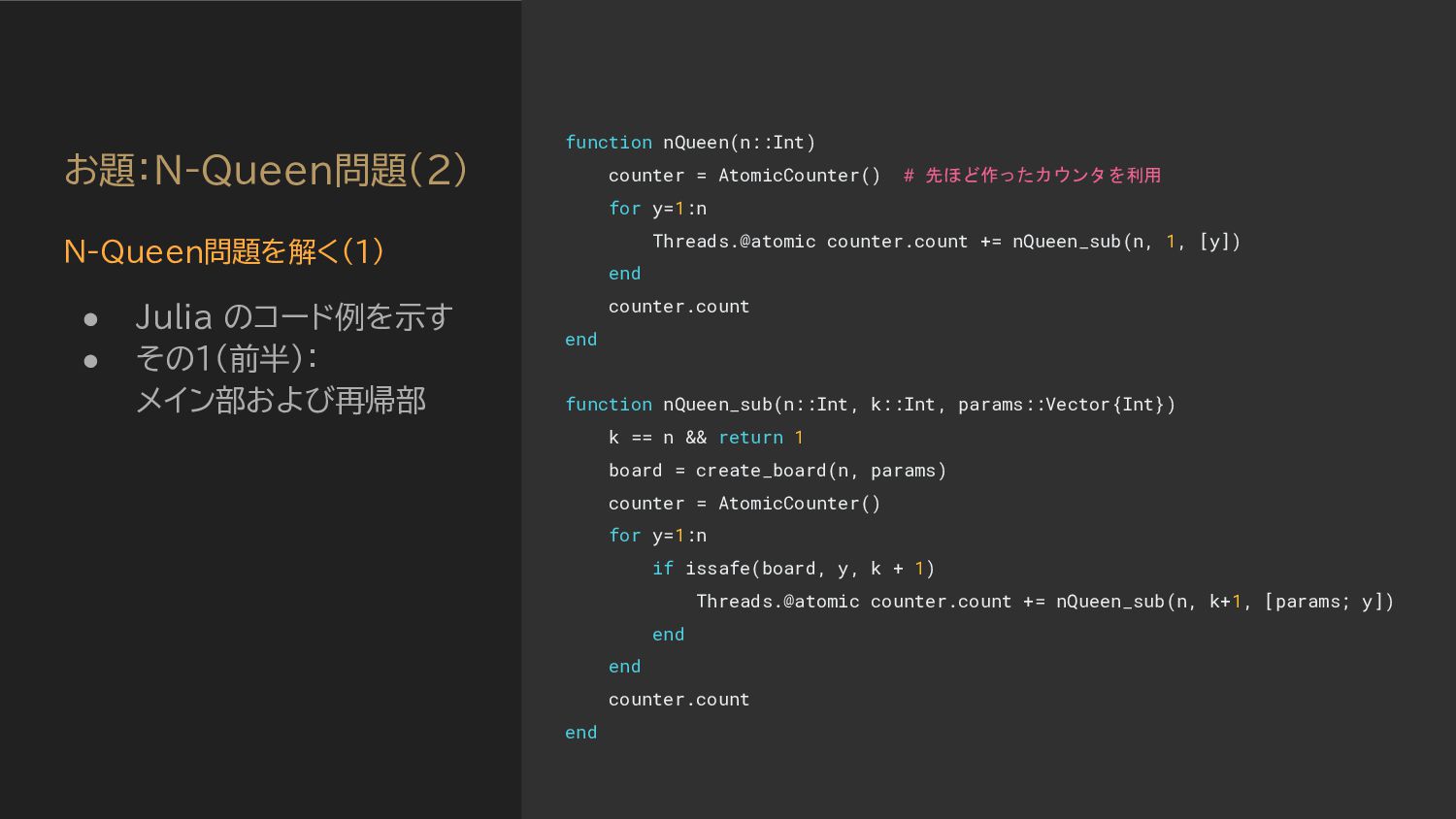
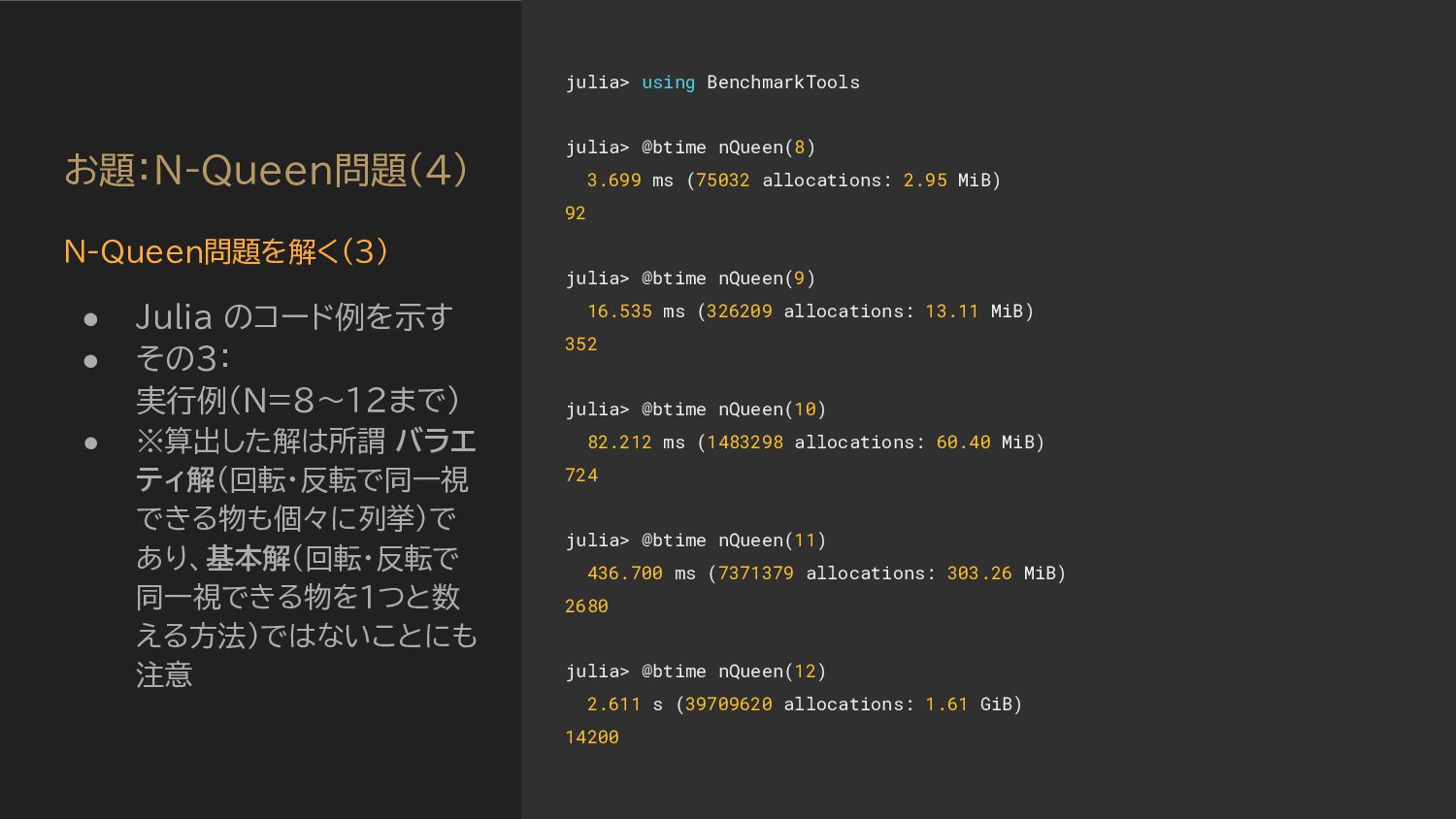
counter = AtomicCounter() # 先ほど作ったカウンタを利用 for y=1:n Threads.@atomic counter.count += nQueen_sub(n, 1, [y]) end counter.count end function nQueen_sub(n::Int, k::Int, params::Vector{Int}) k == n && return 1 board = create_board(n, params) counter = AtomicCounter() for y=1:n if issafe(board, y, k + 1) Threads.@atomic counter.count += nQueen_sub(n, k+1, [params; y]) end end counter.count end
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}