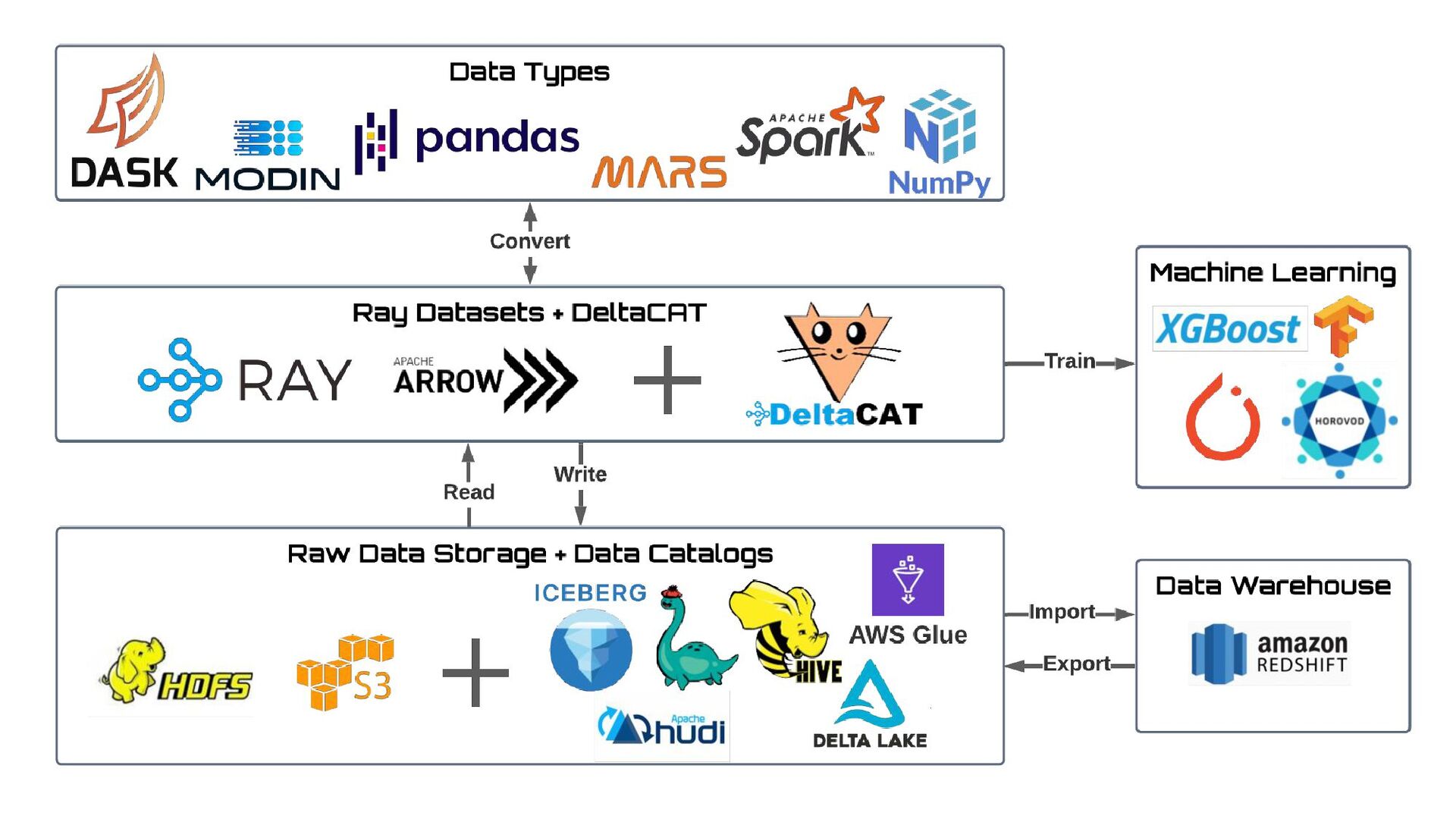
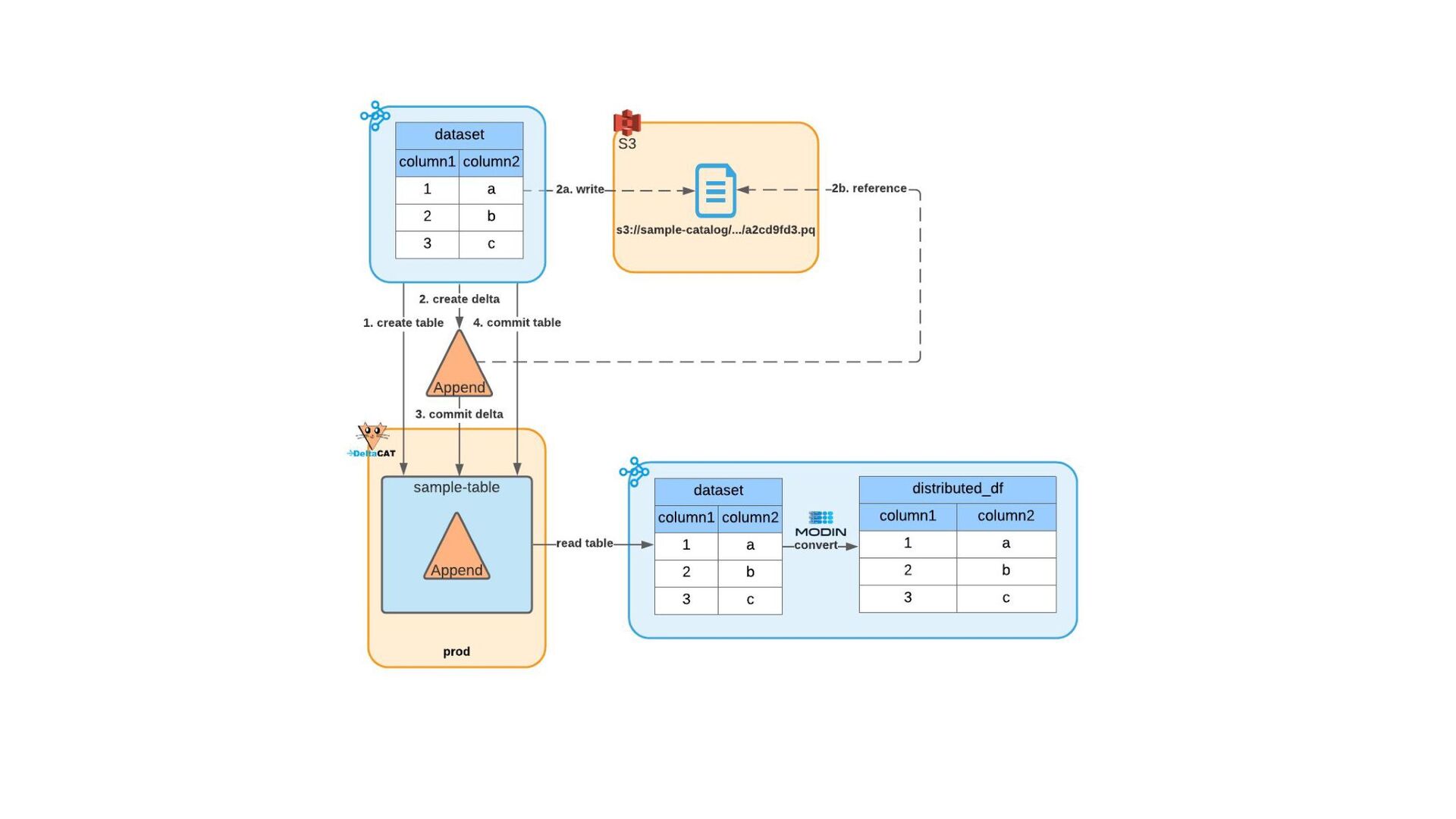
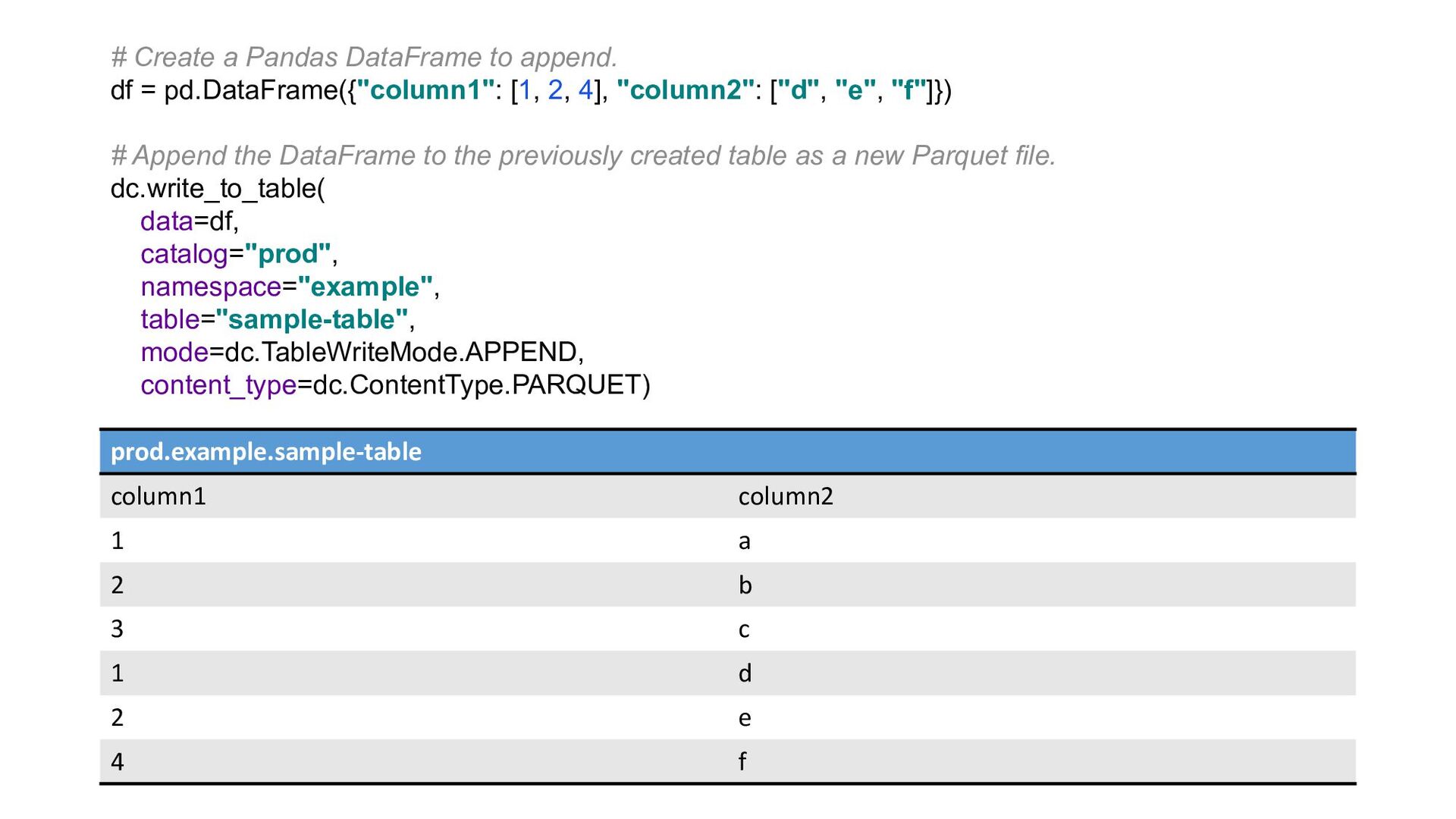
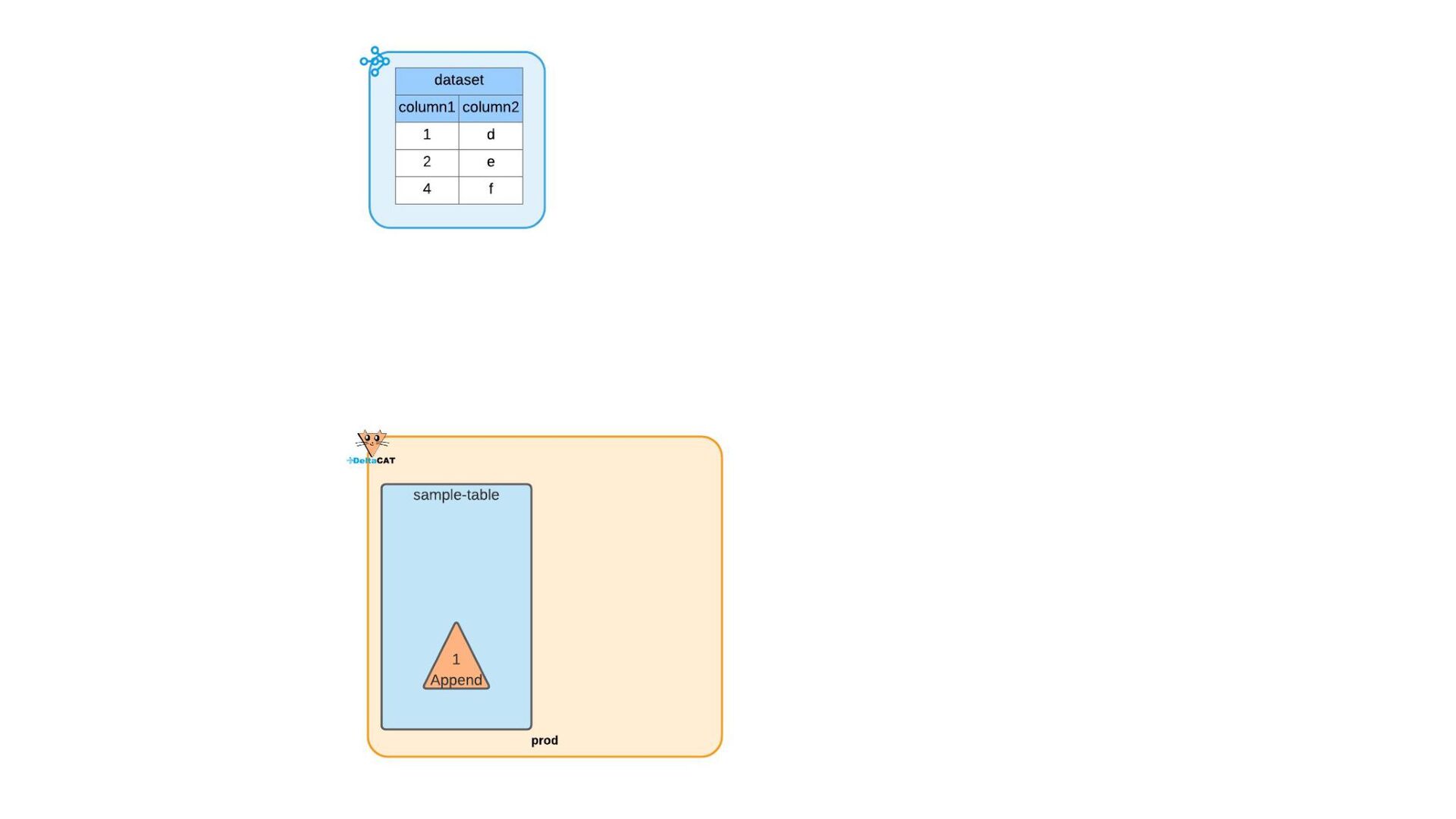
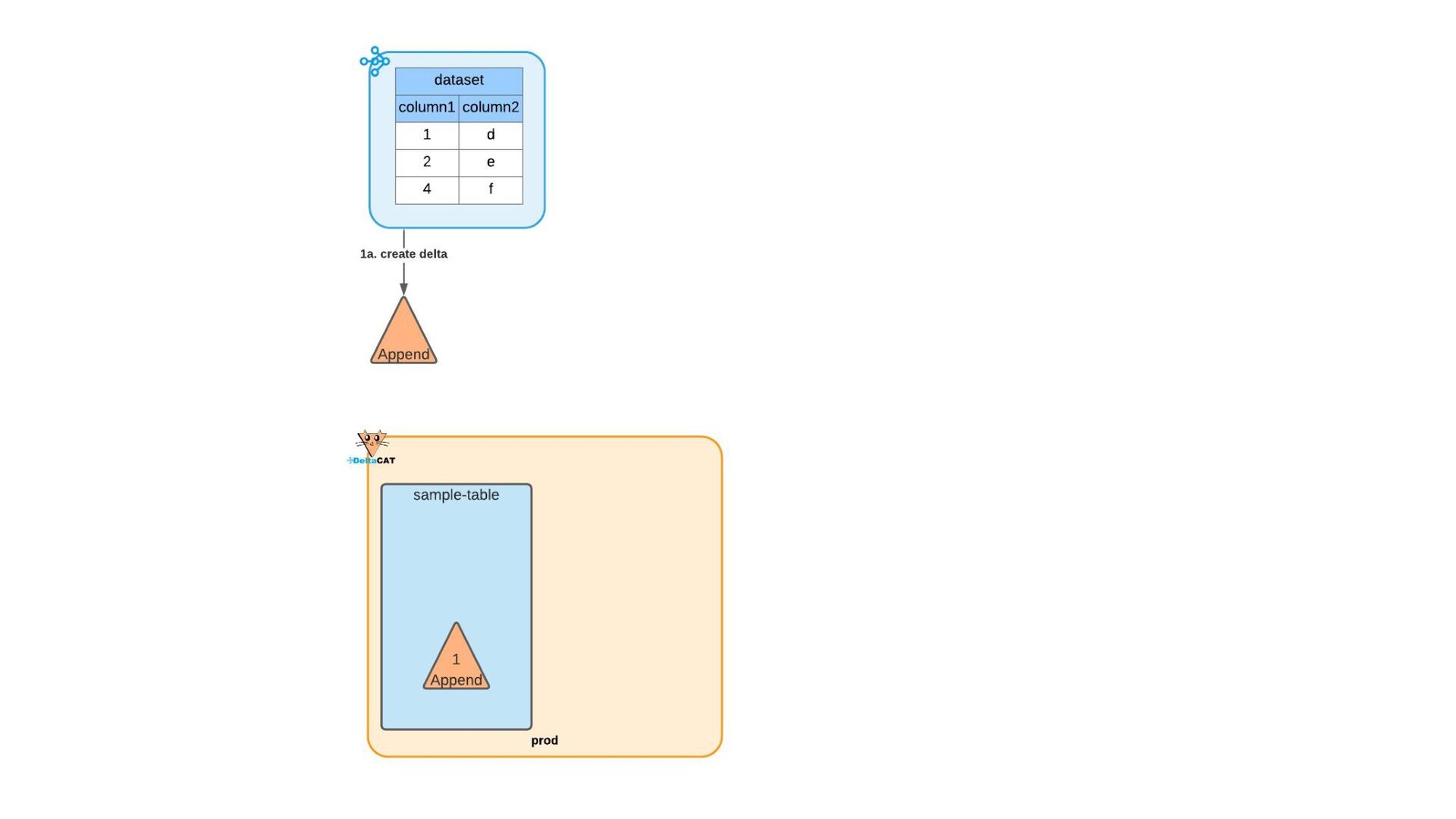
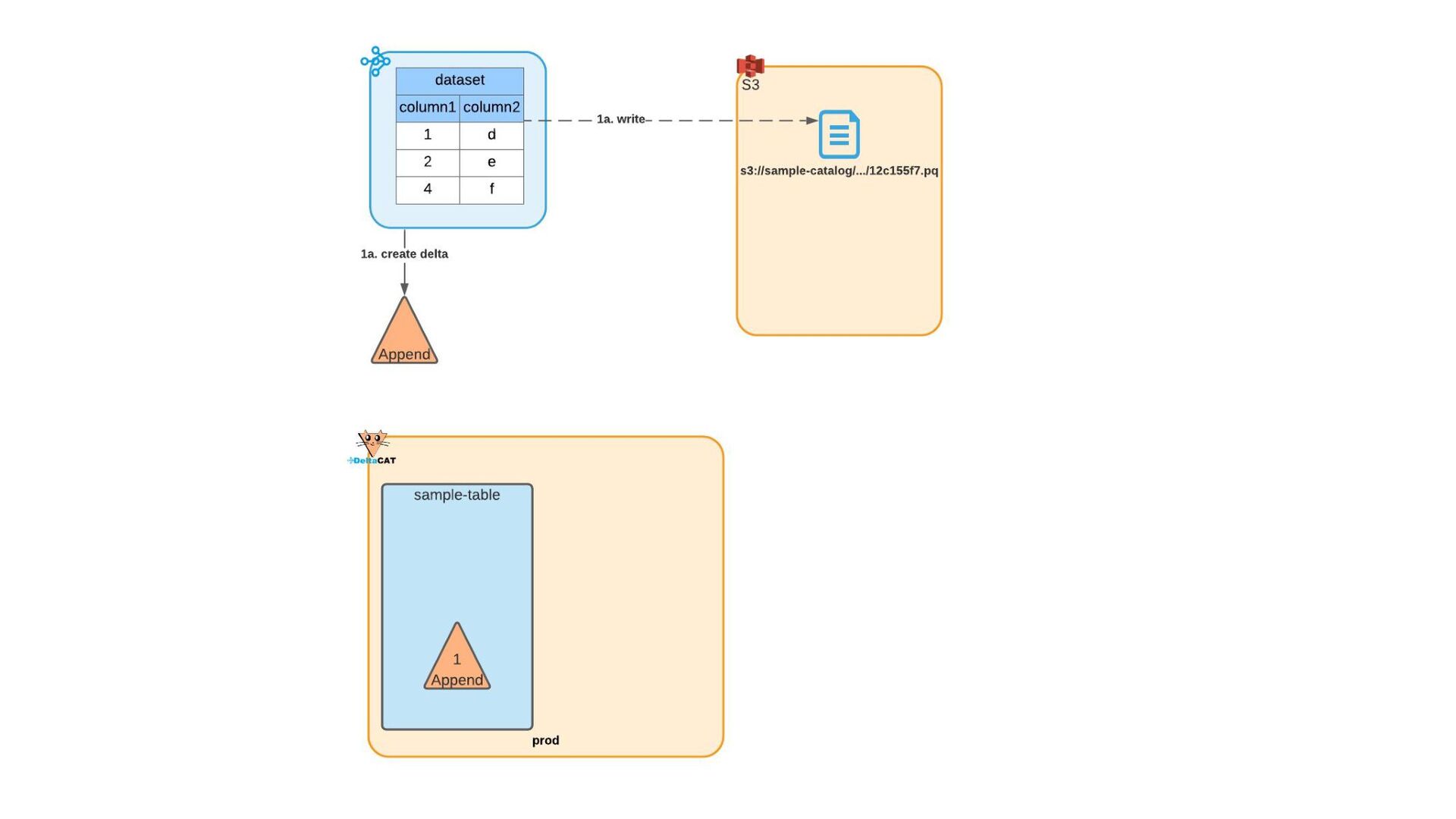
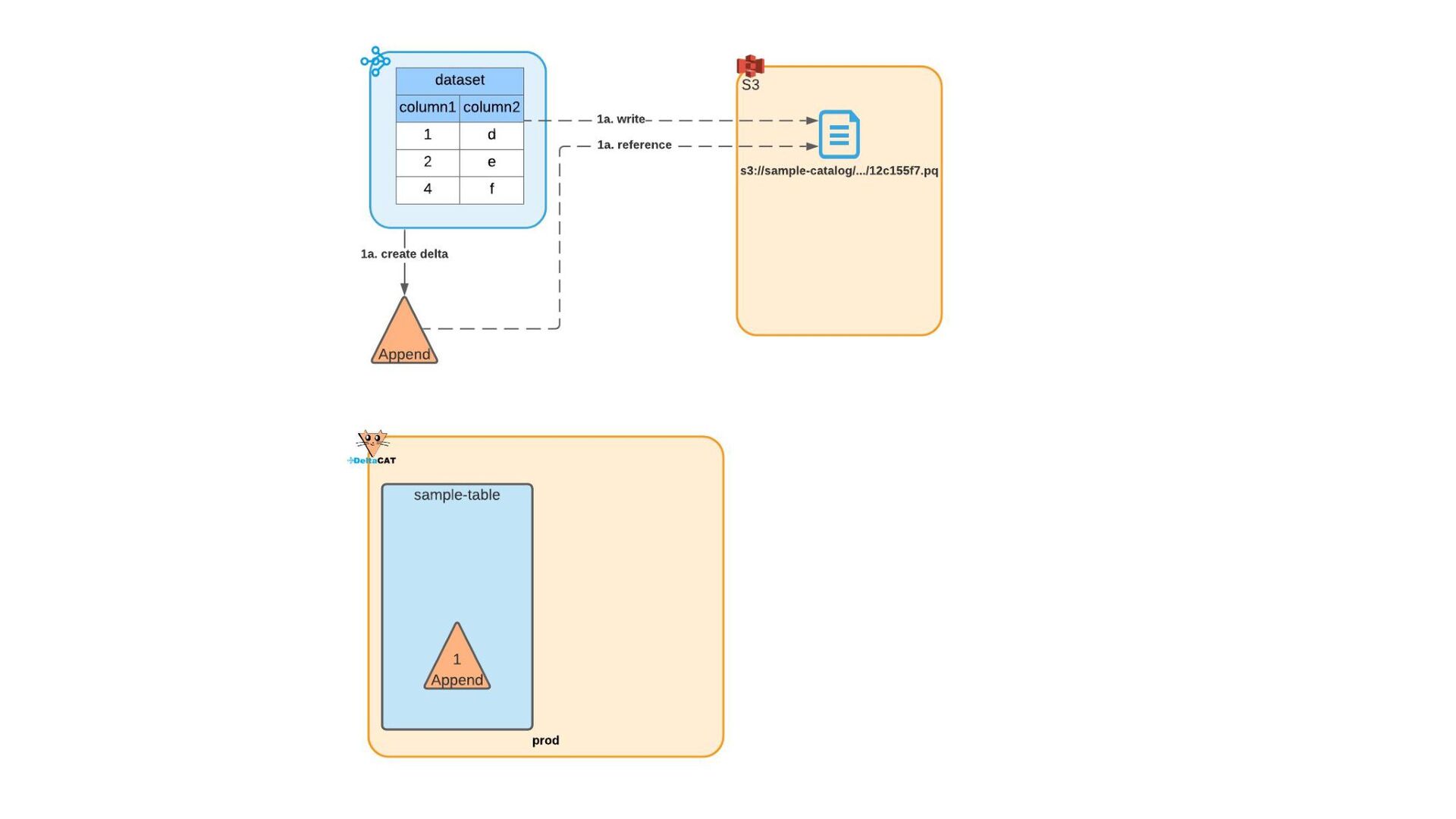
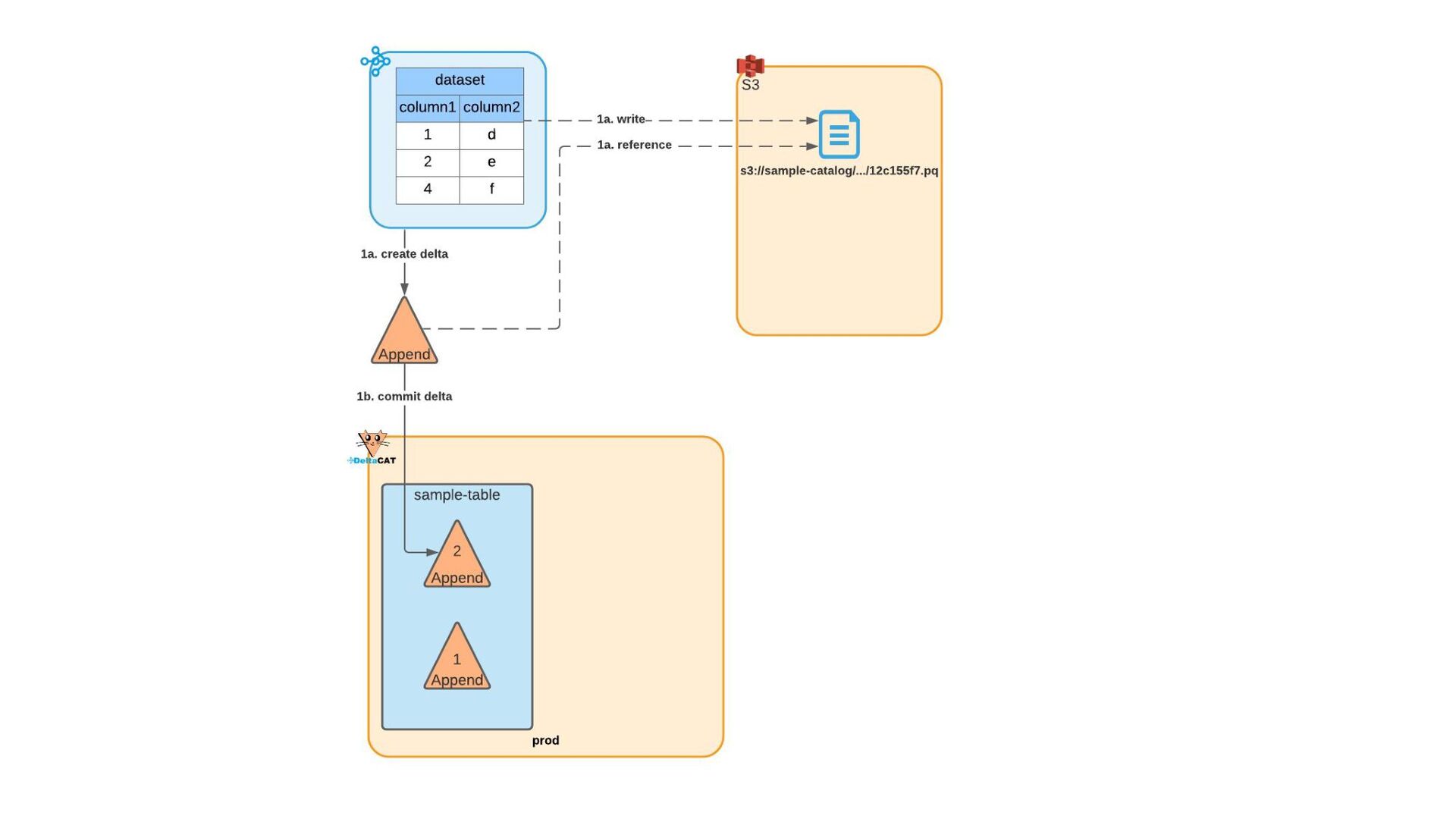
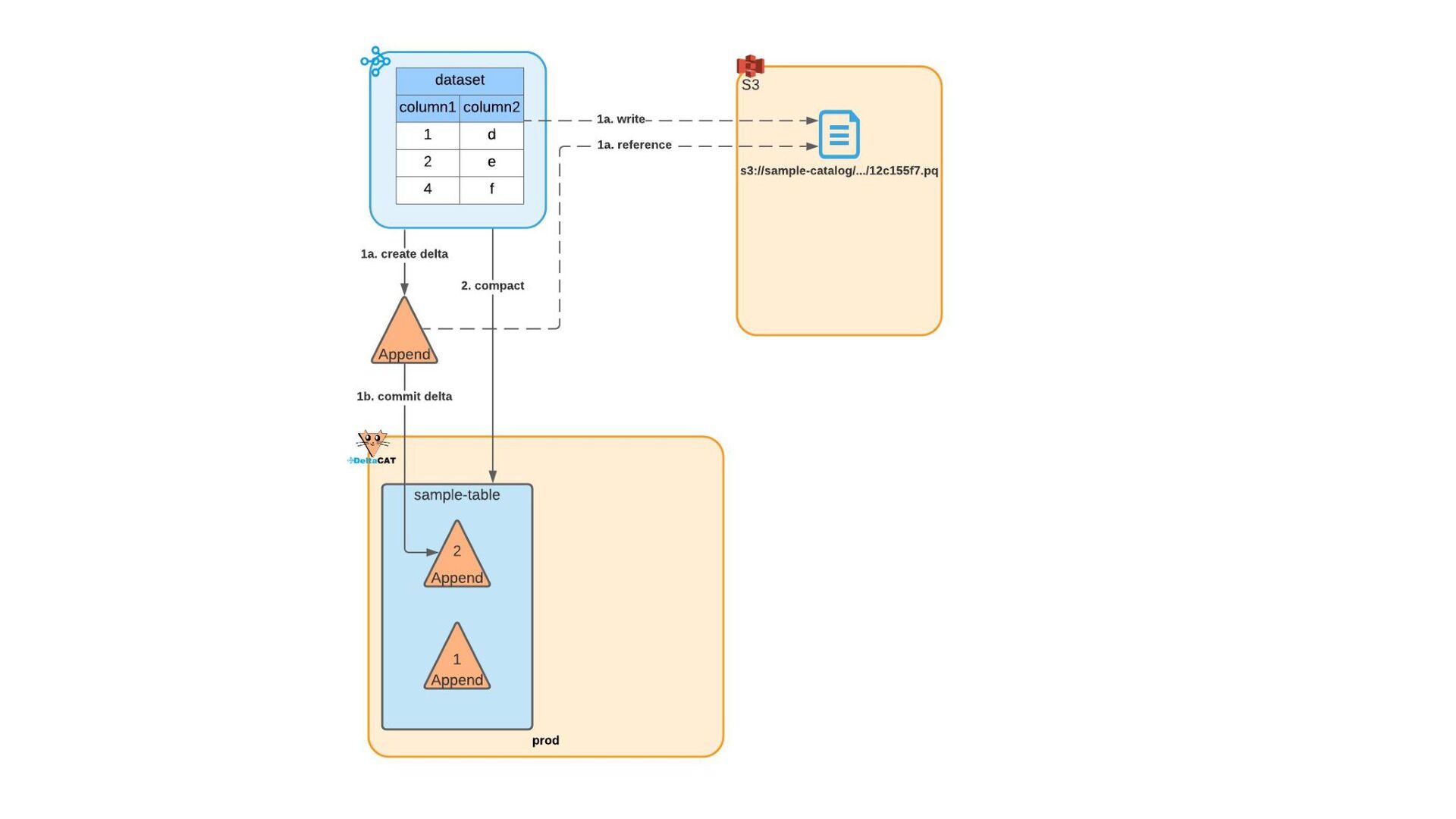
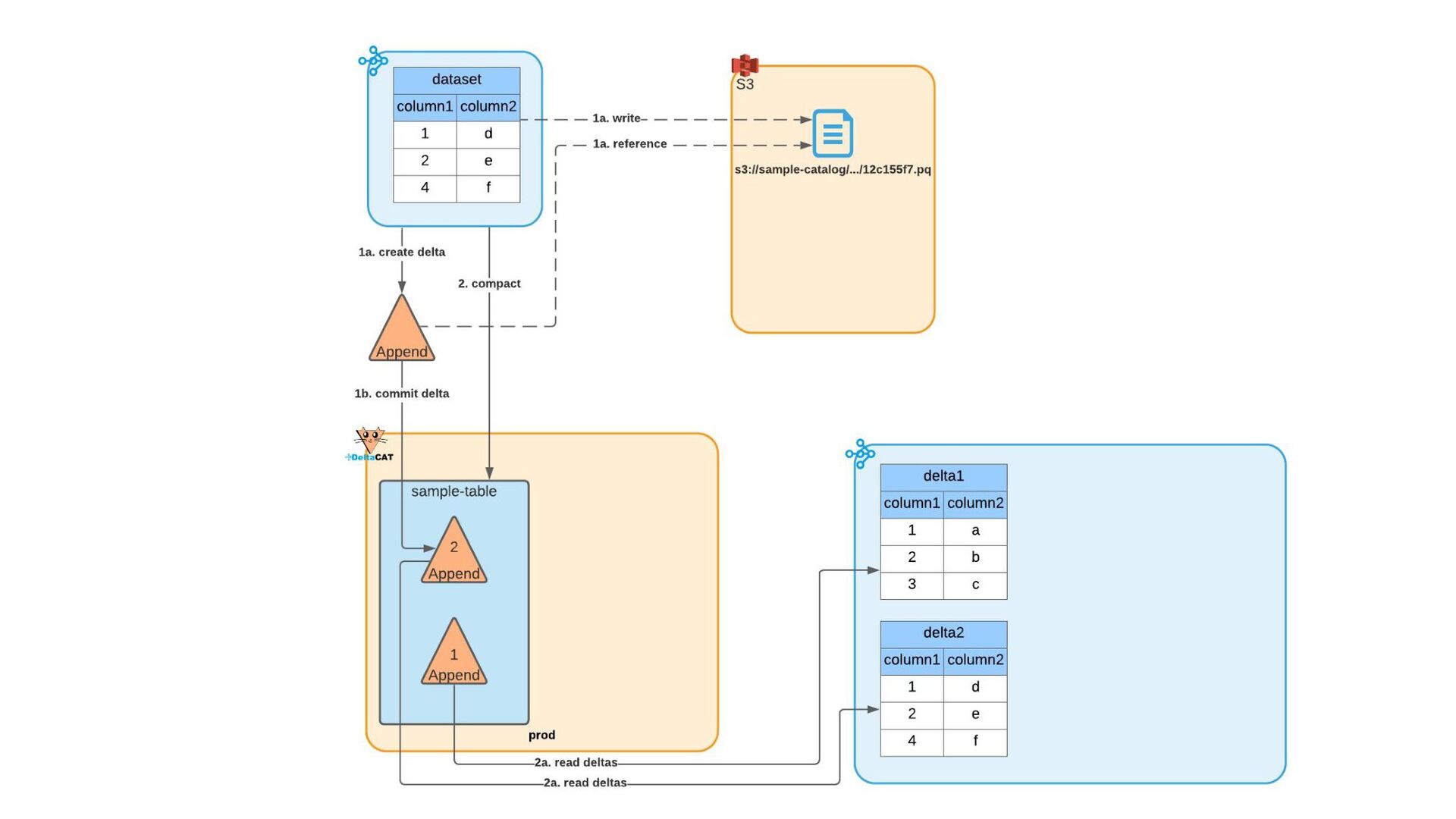
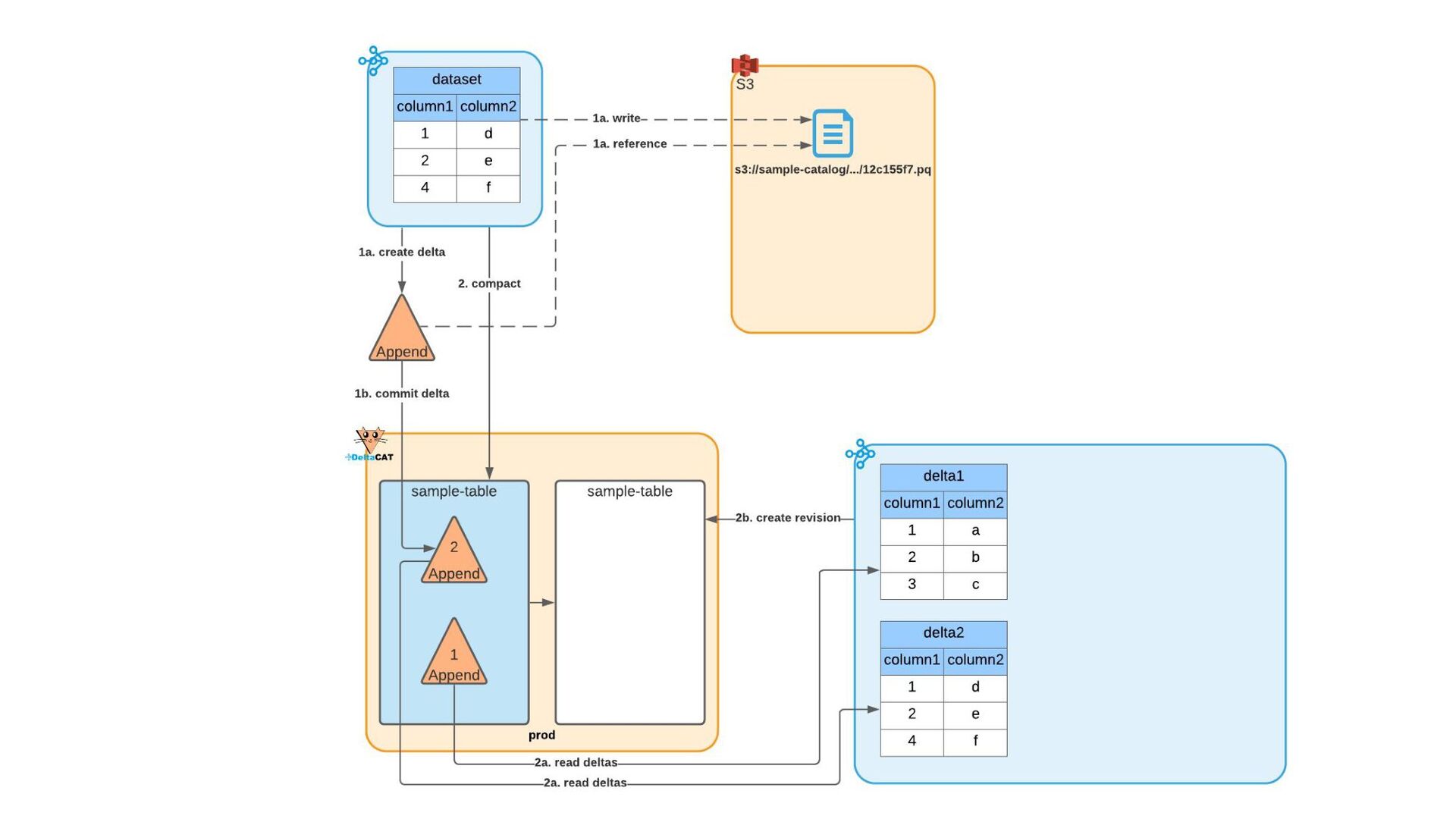
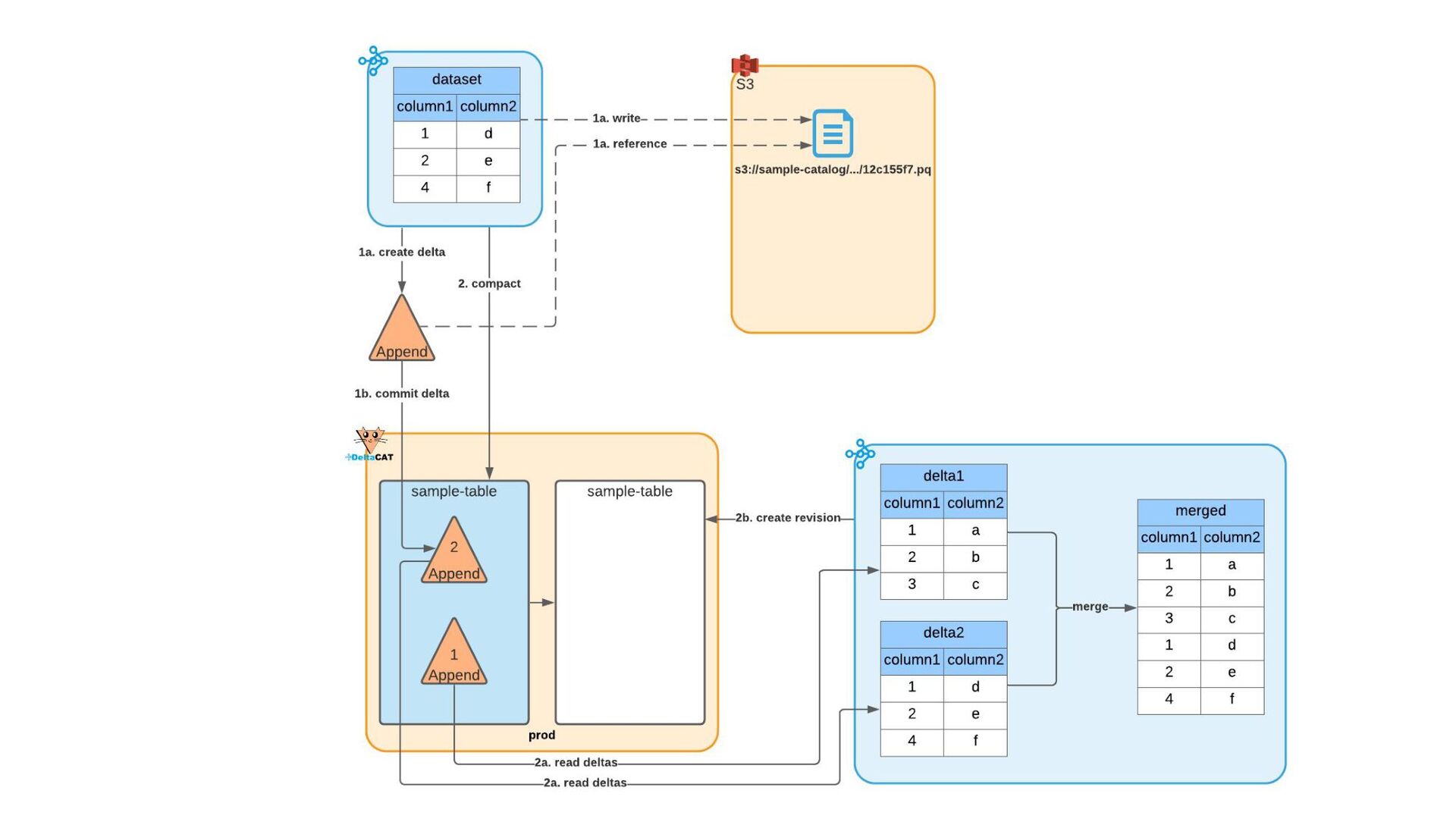
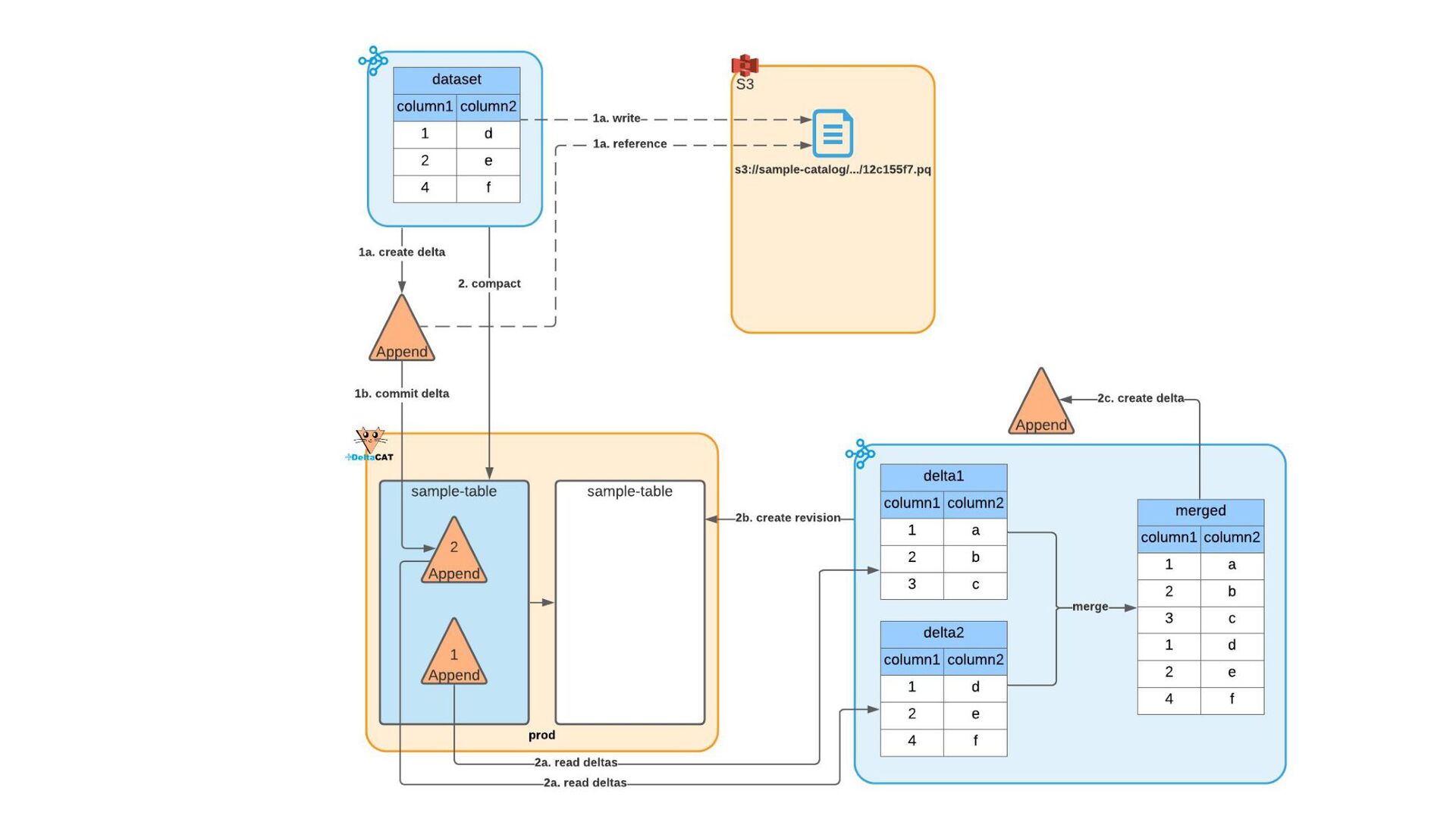
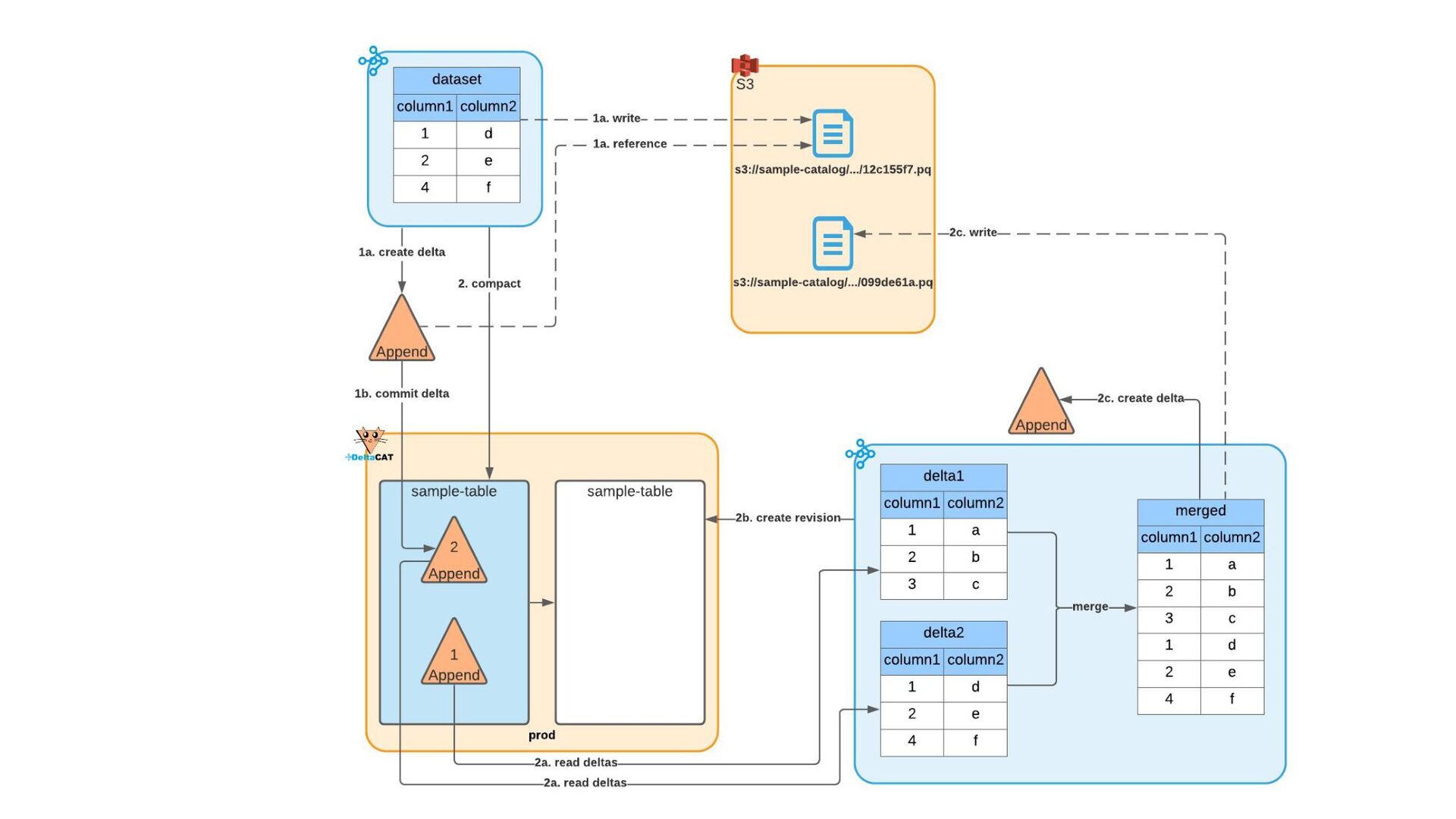
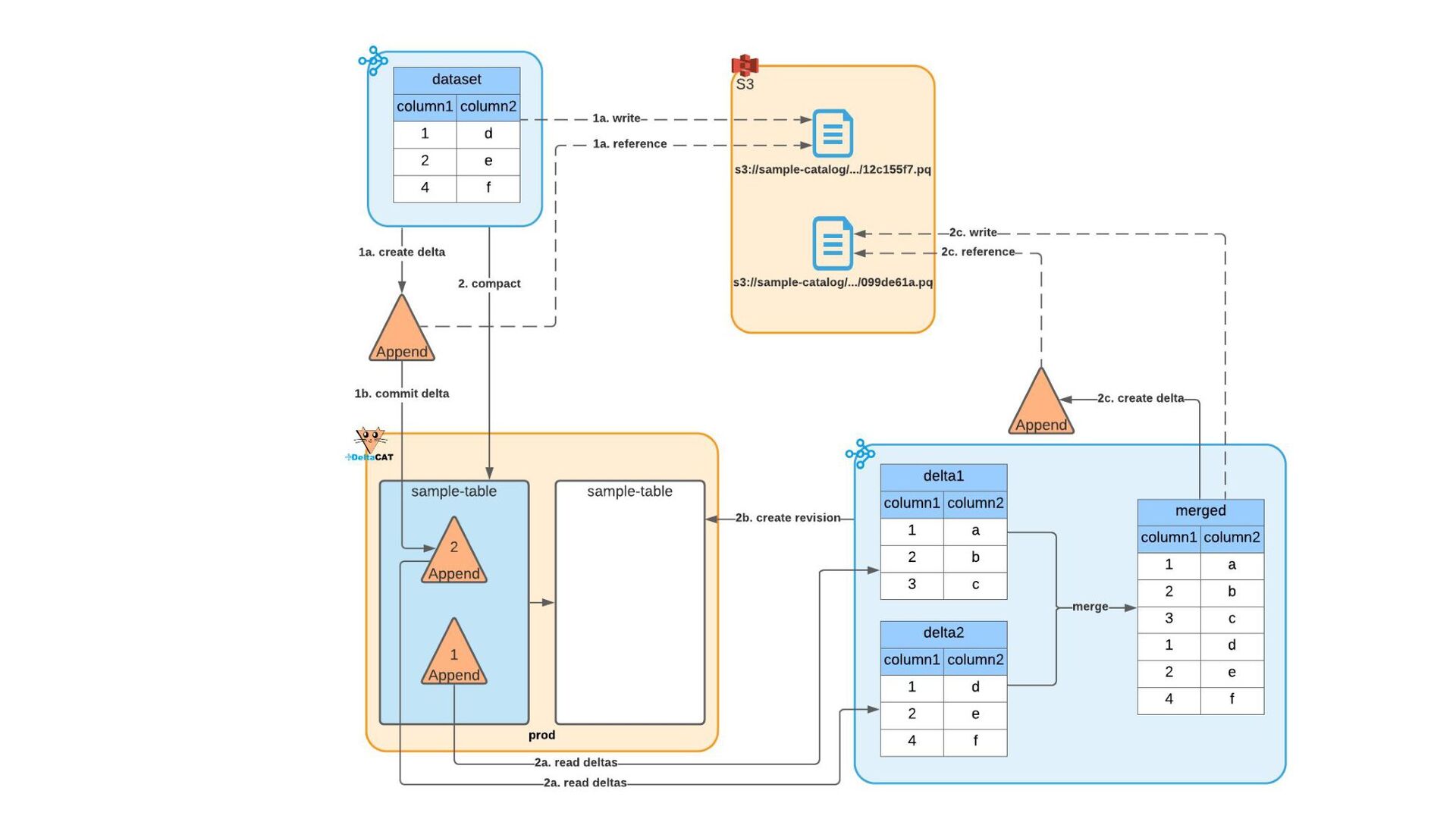
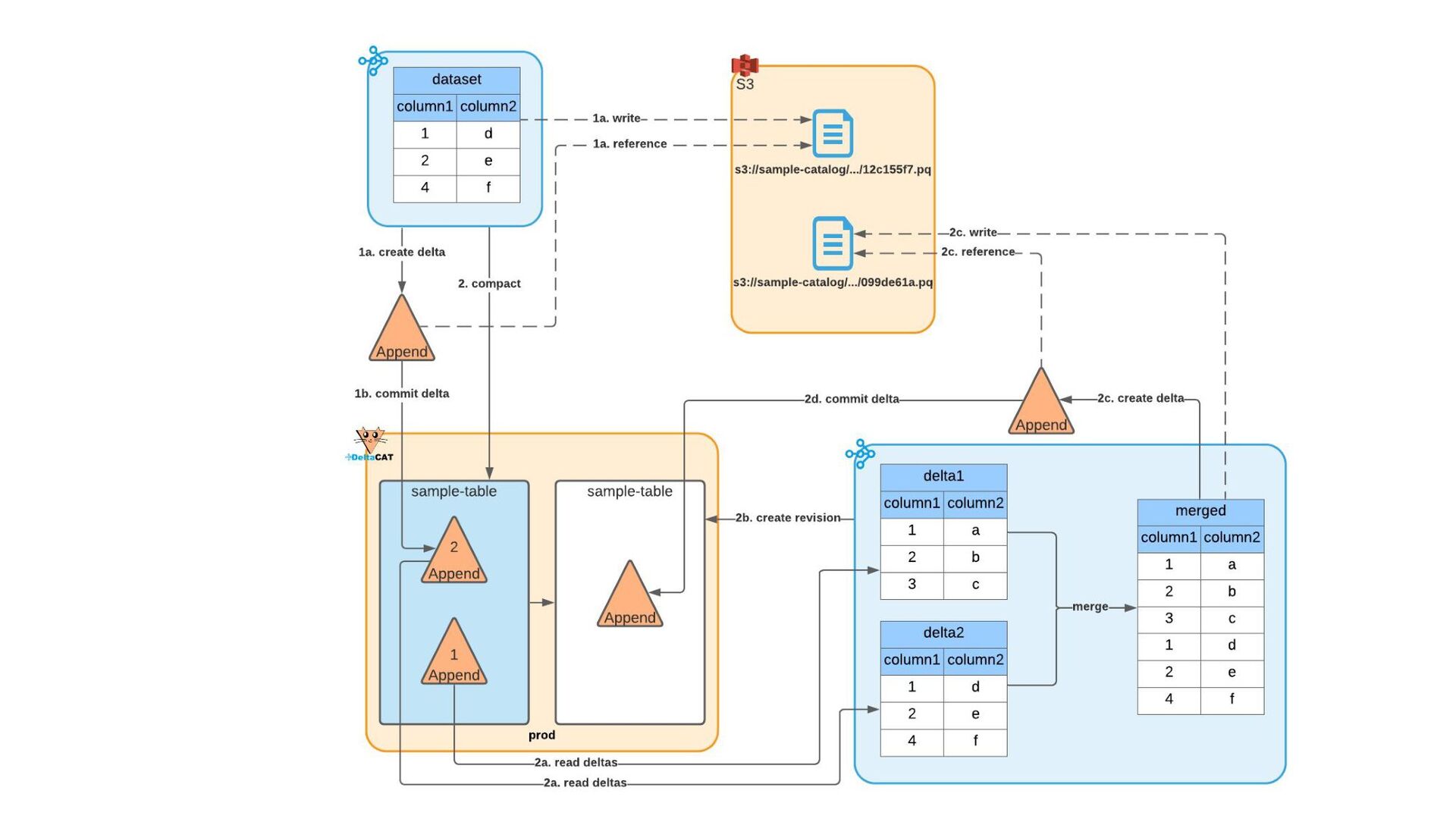
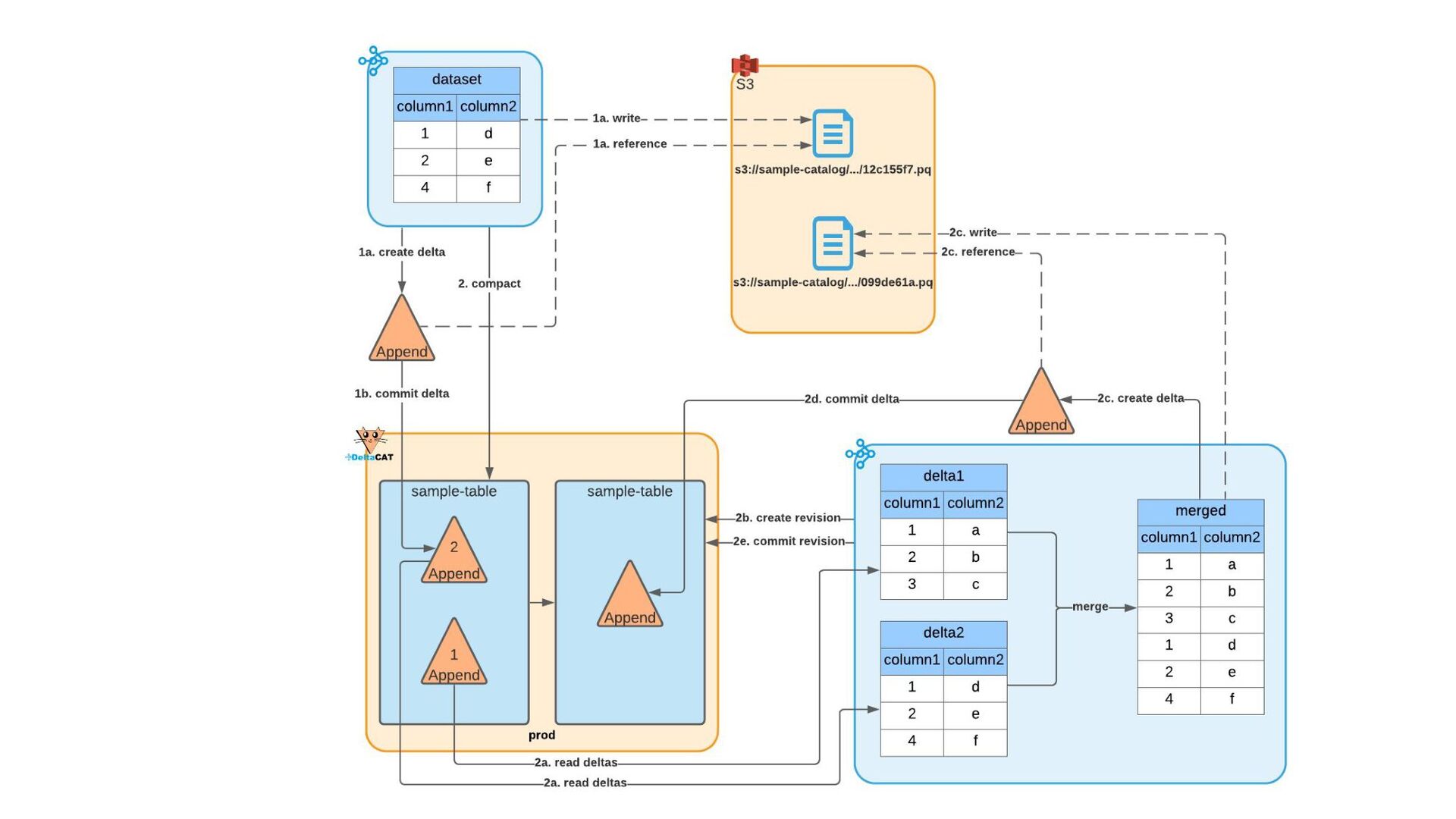
Most of today’s open-source data catalogs and data lakes are written for Java, with Python support either unavailable or tacked on as an afterthought. This can lead to awkward programming models and cross-language integration overhead for Python developers. To better connect Python devs to their data, we introduced the DeltaCAT project to the Ray Project ecosystem.
We’ll discuss how DeltaCAT leverages Ray Datasets to manage petabyte-scale data catalog tables. We’ll also review the goals of the project, how Amazon is using it internally, its current state, and future roadmap.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
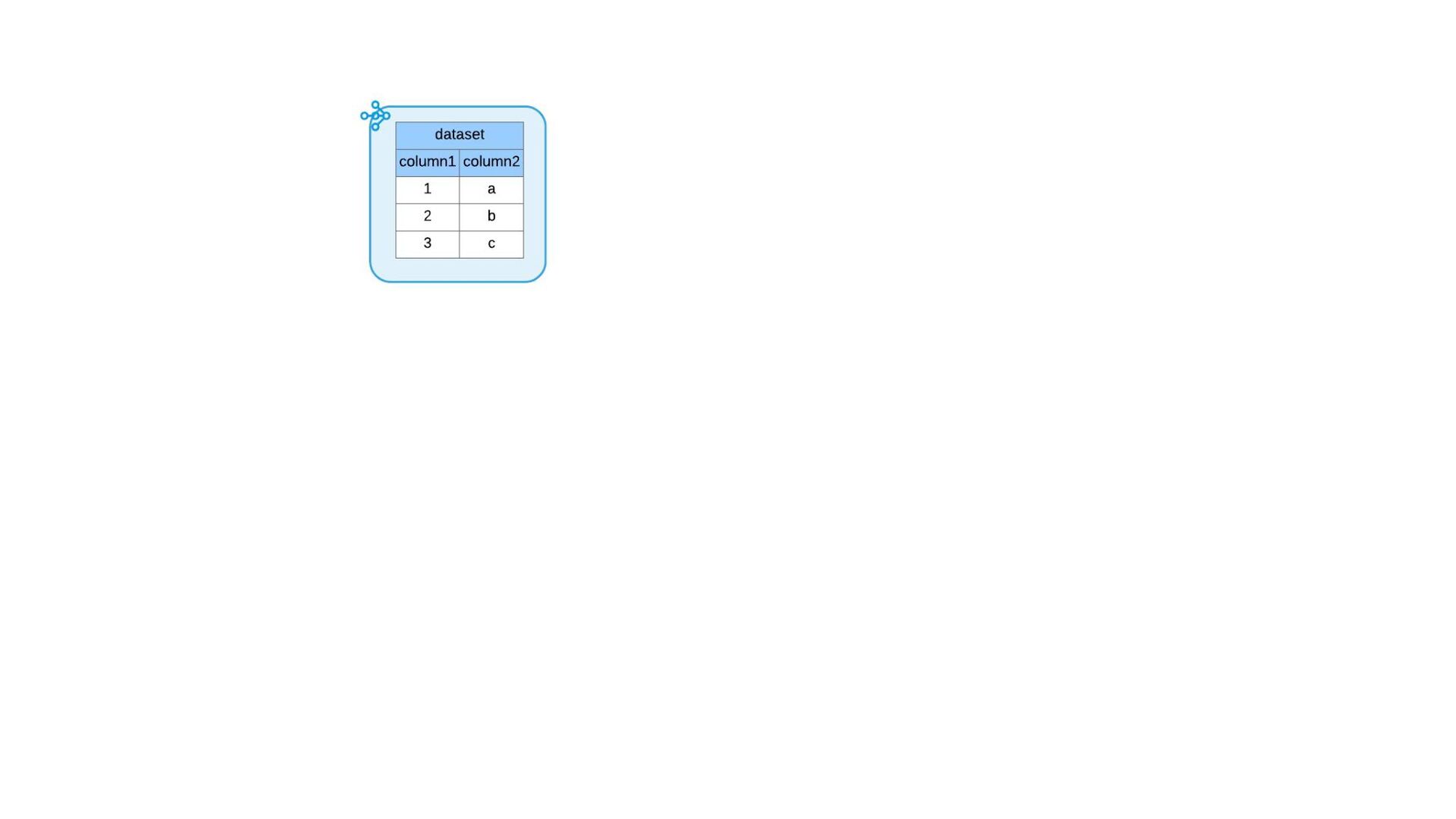{kind=link}
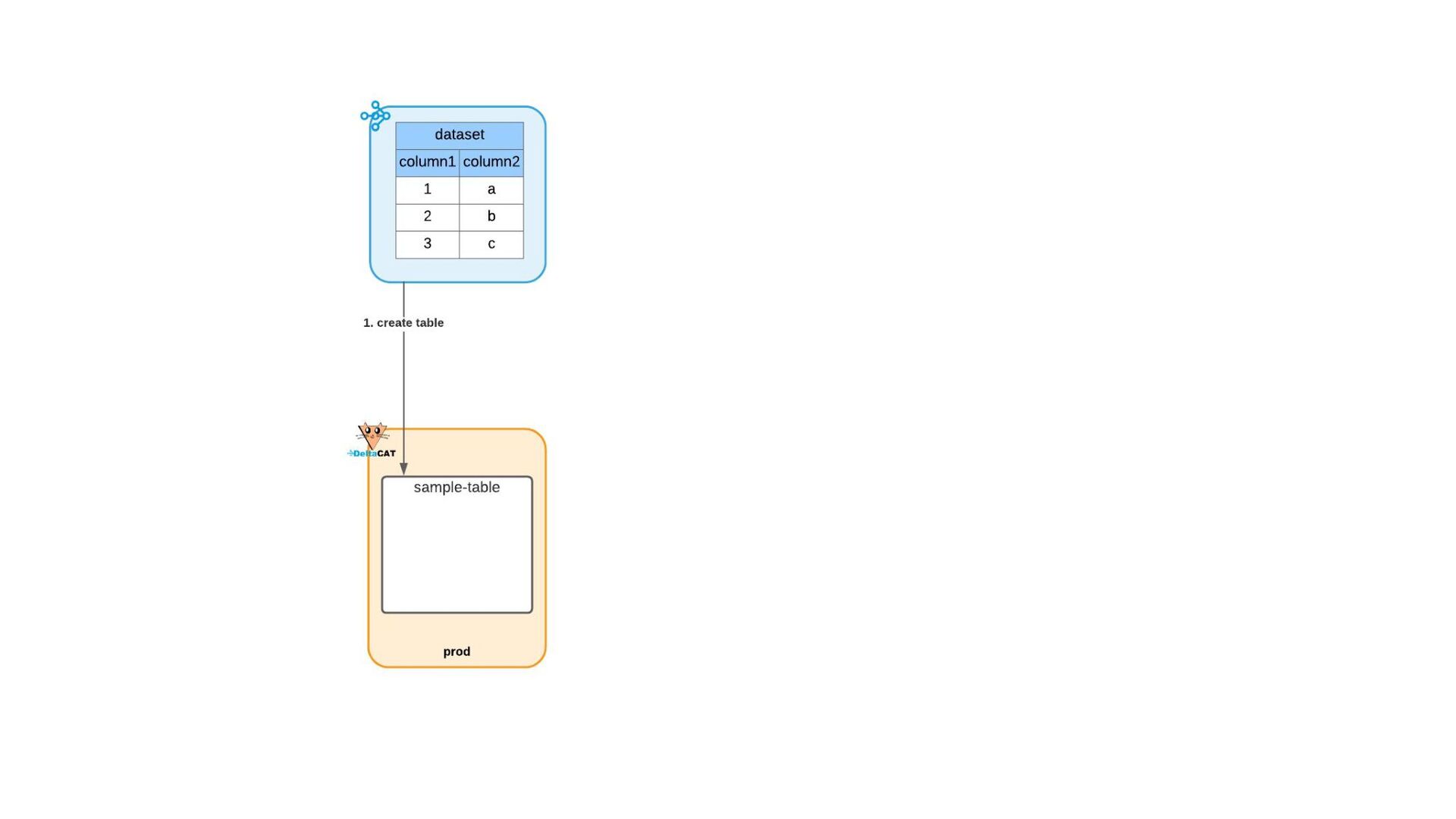{kind=link}
{kind=link}
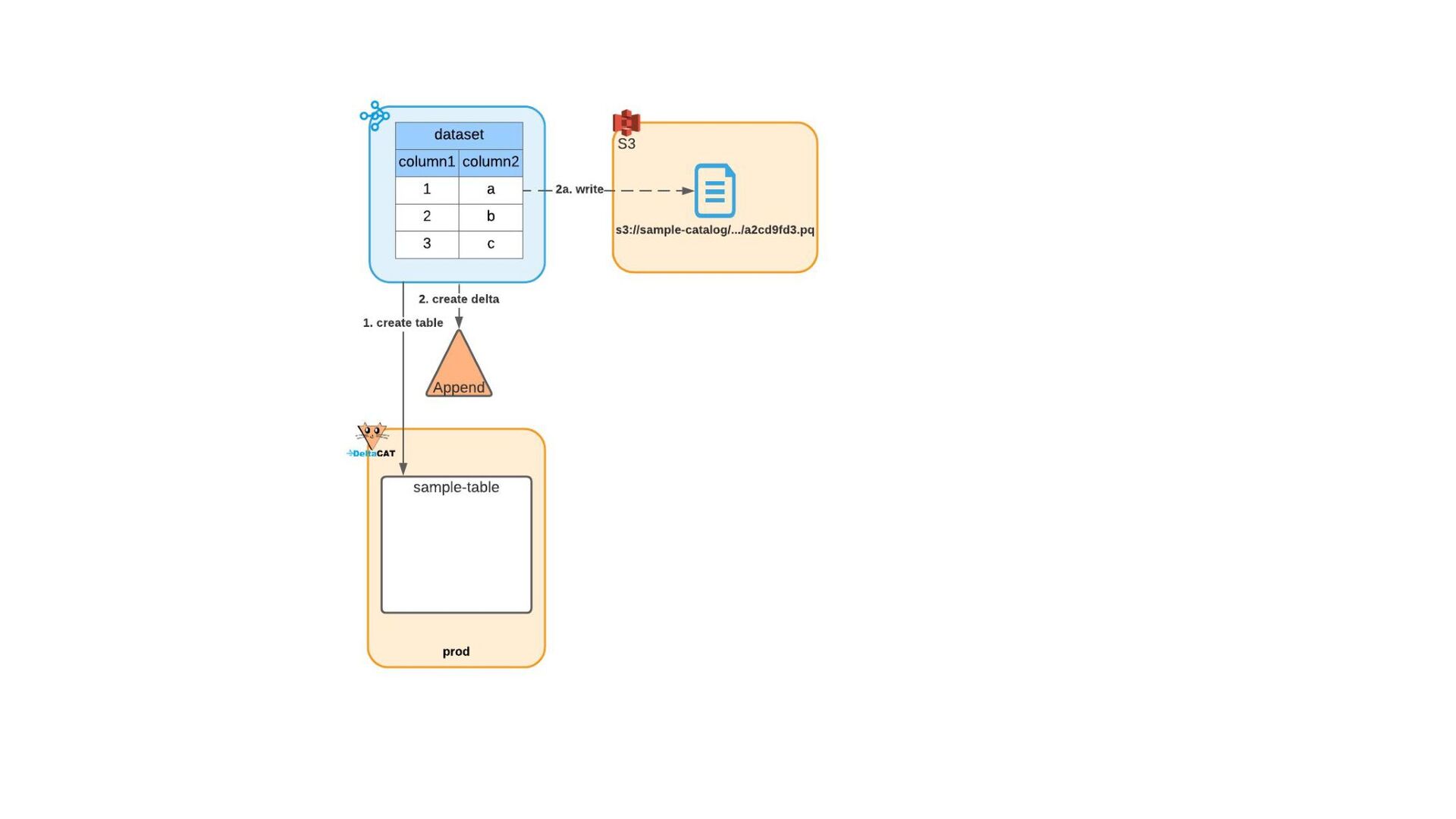{kind=link}
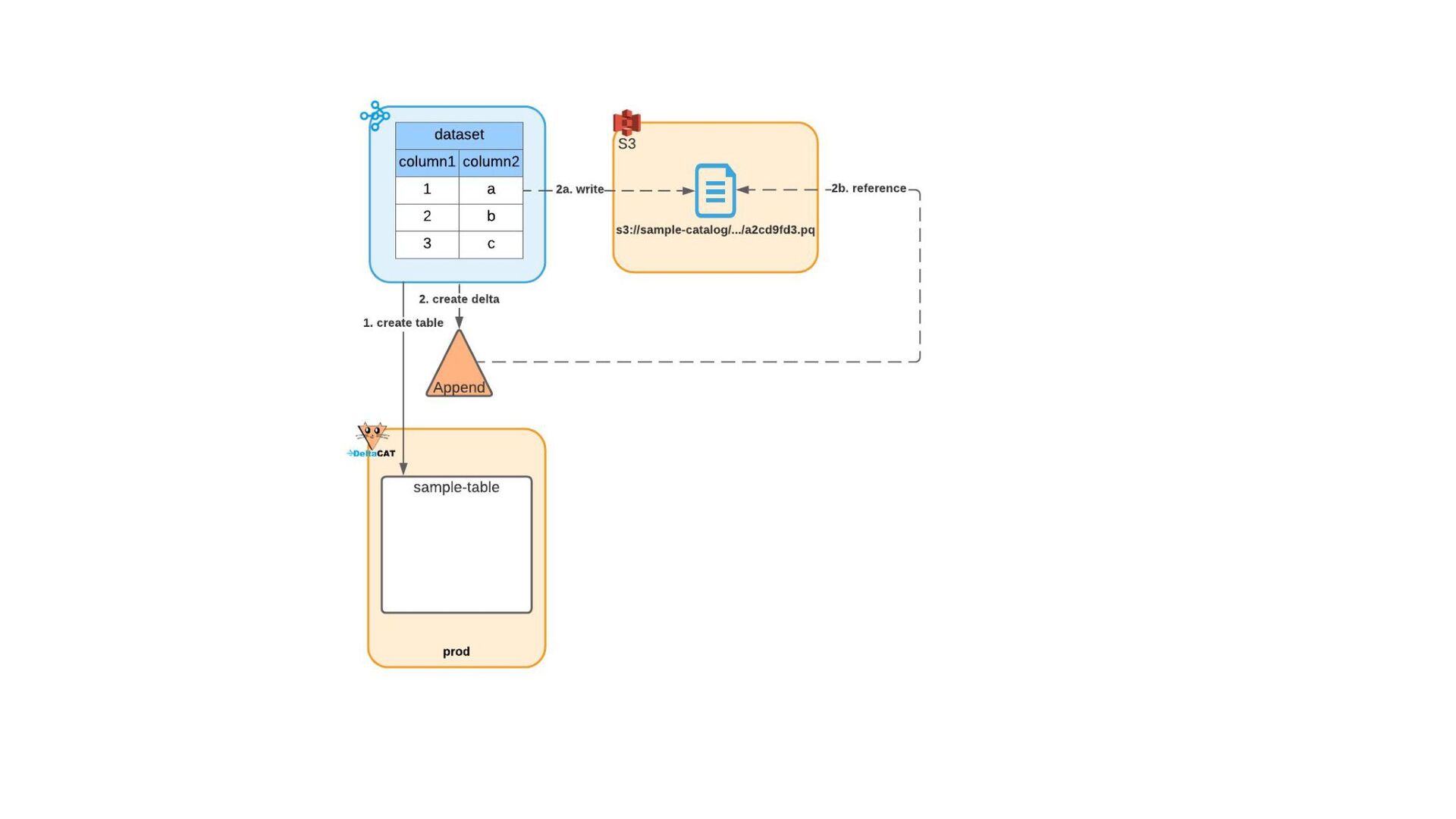{kind=link}
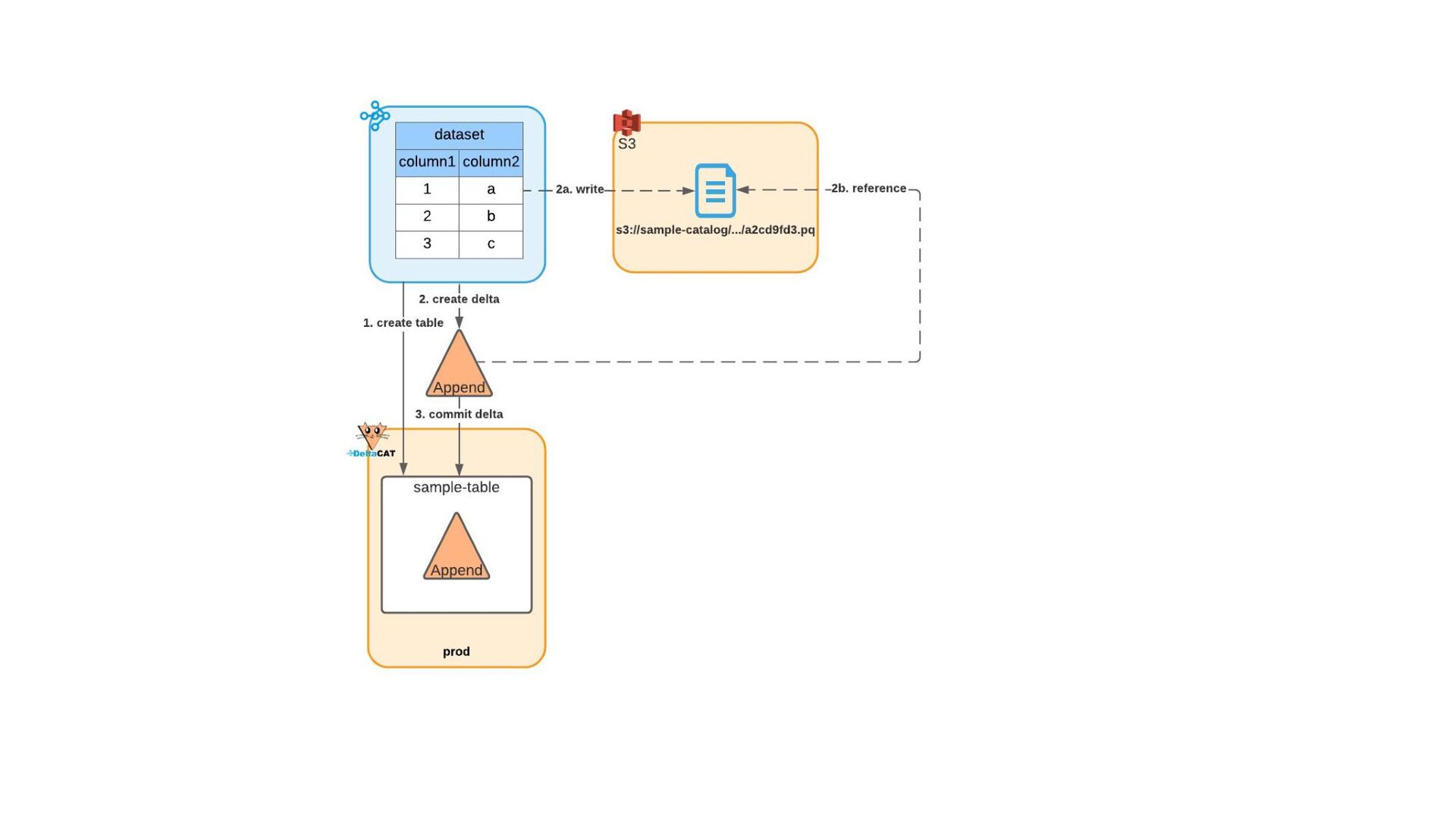{kind=link}
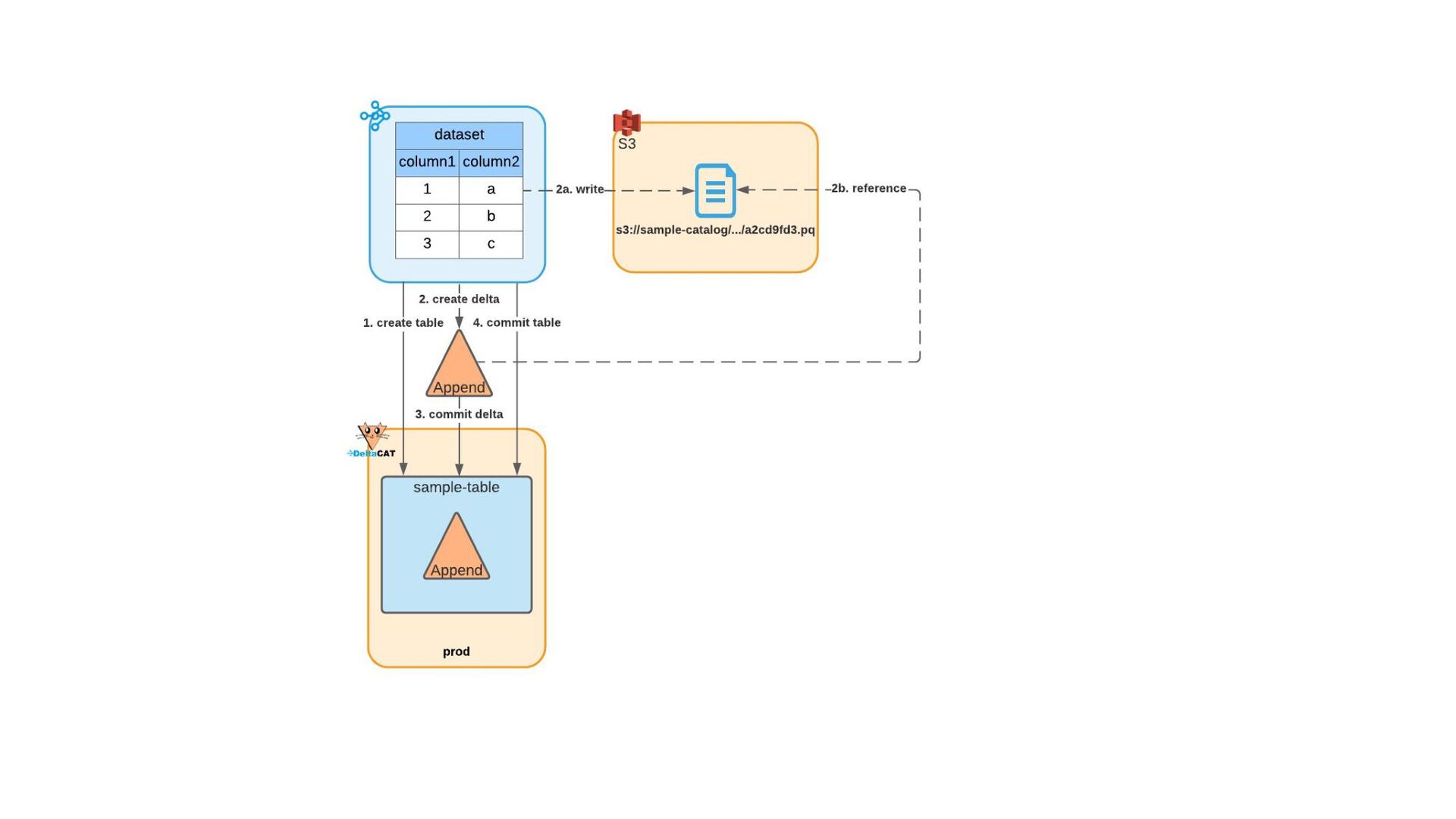{kind=link}
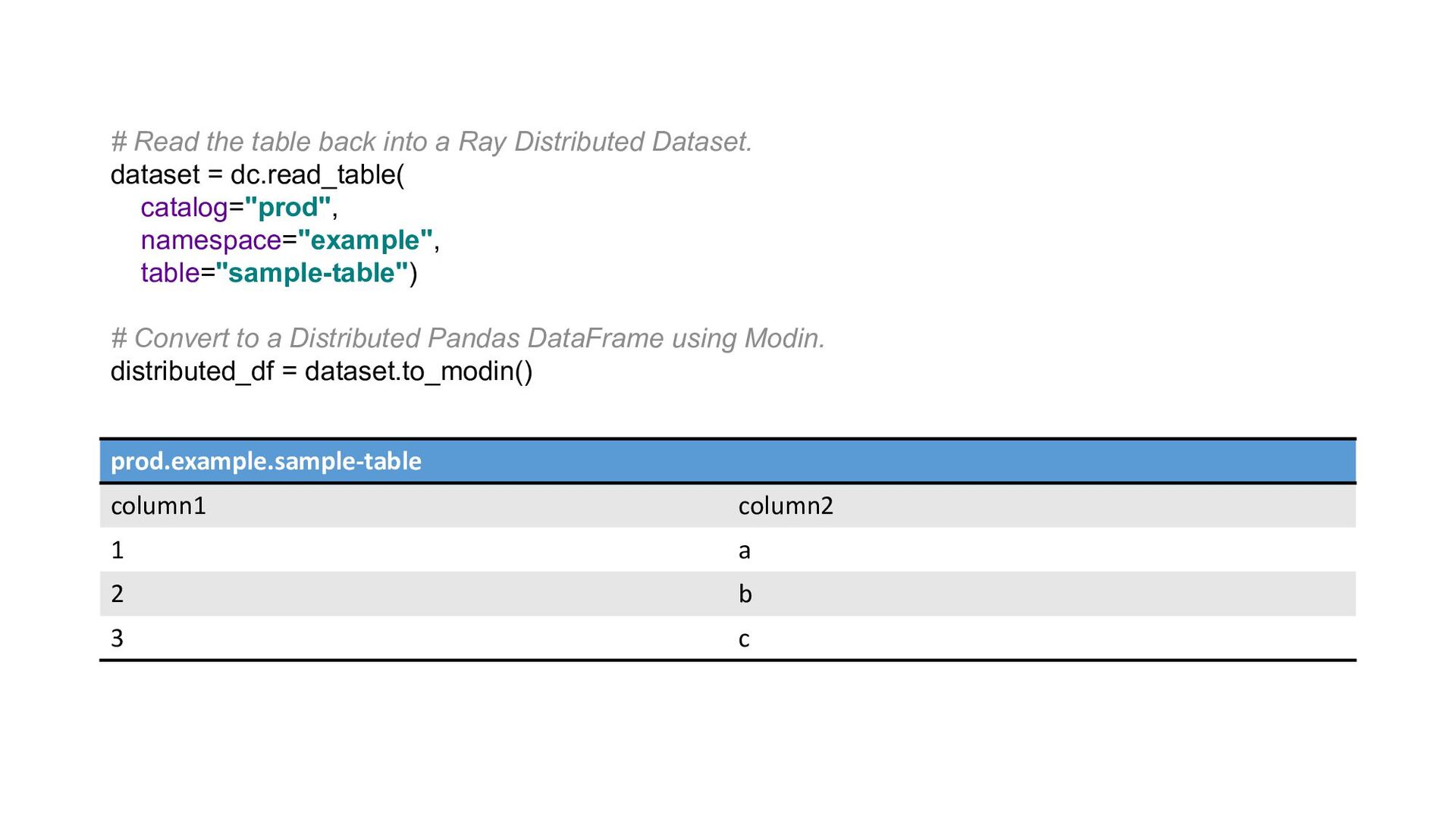{kind=link}
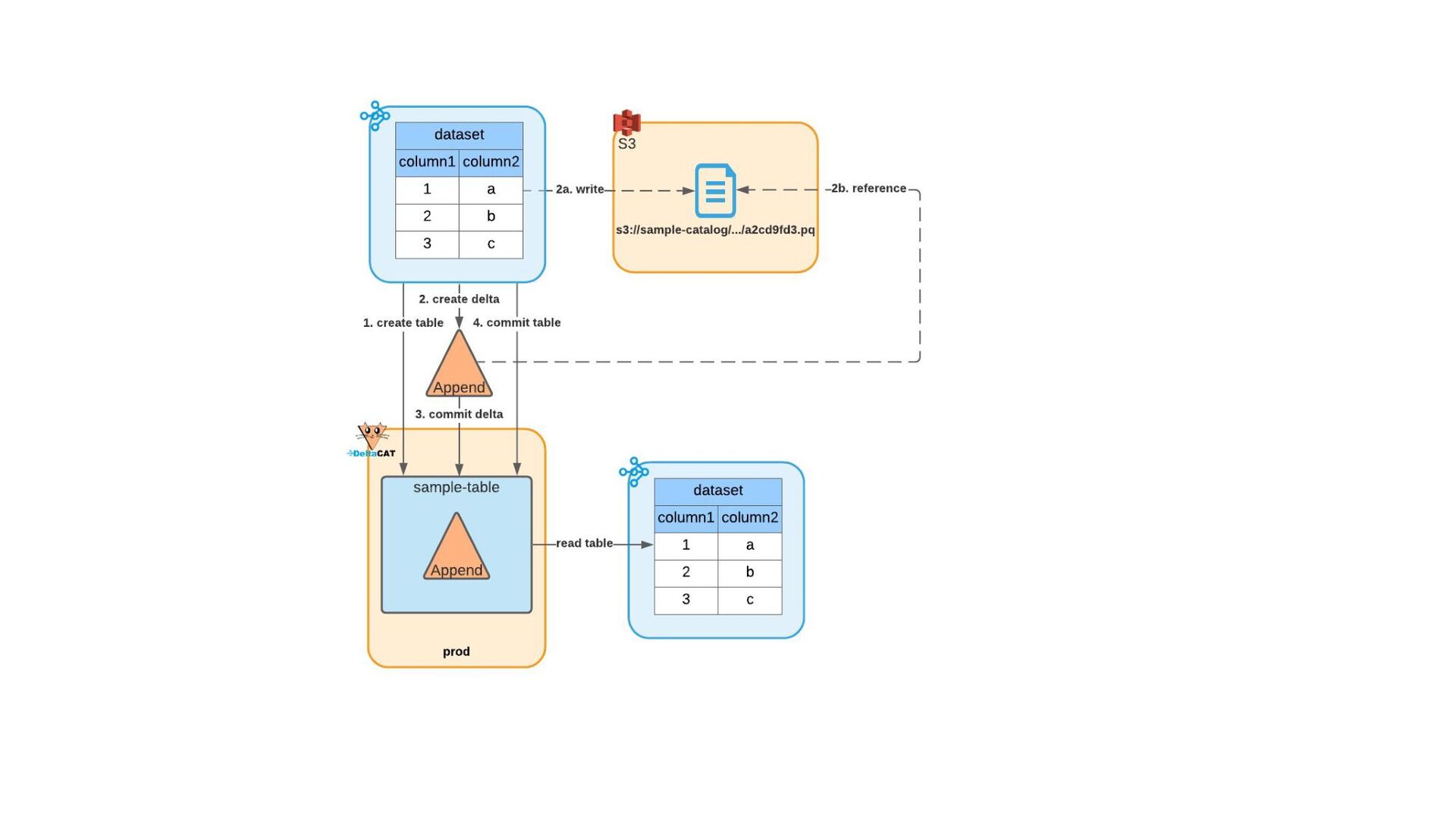{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
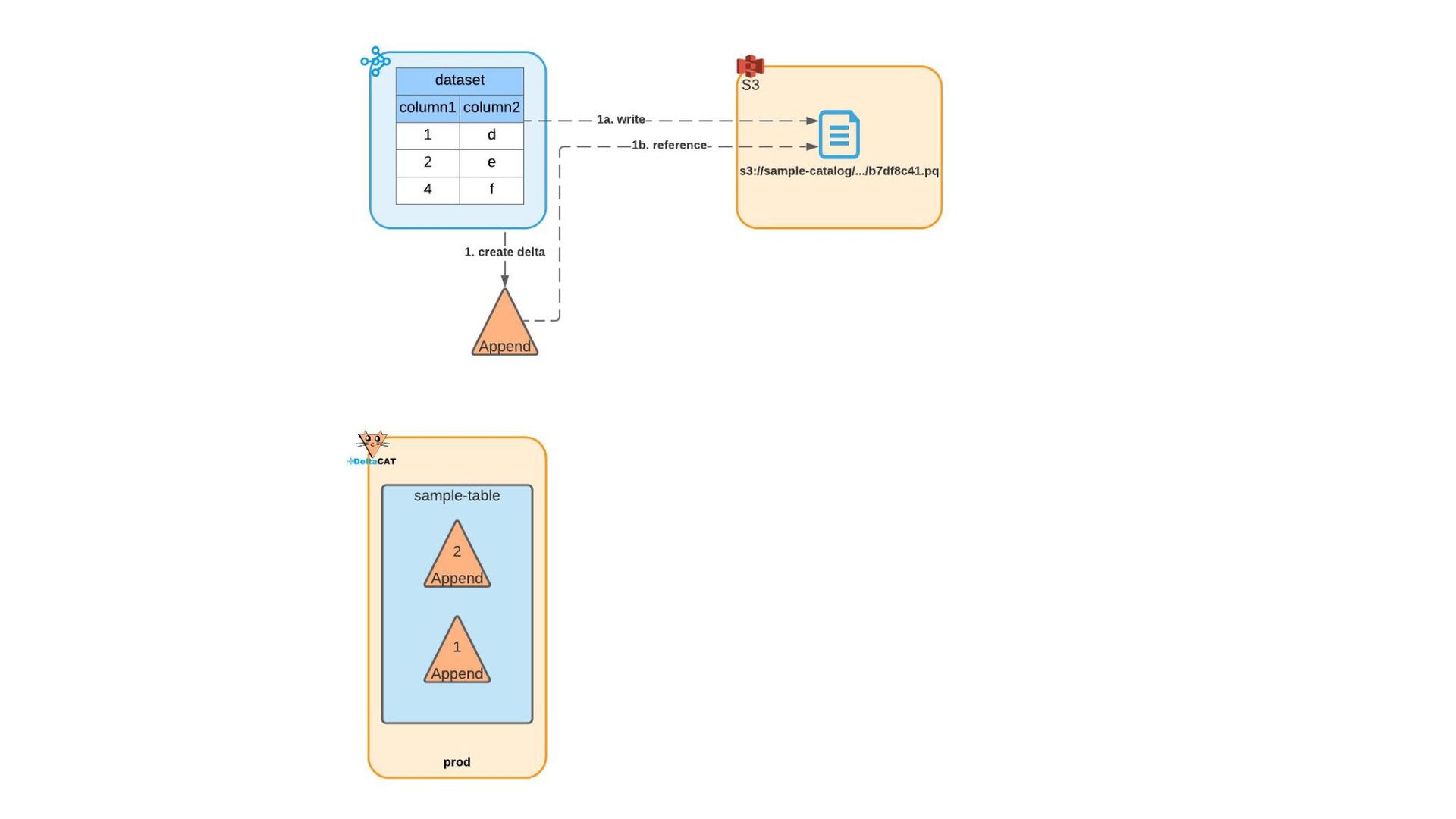{kind=link}
{kind=link}
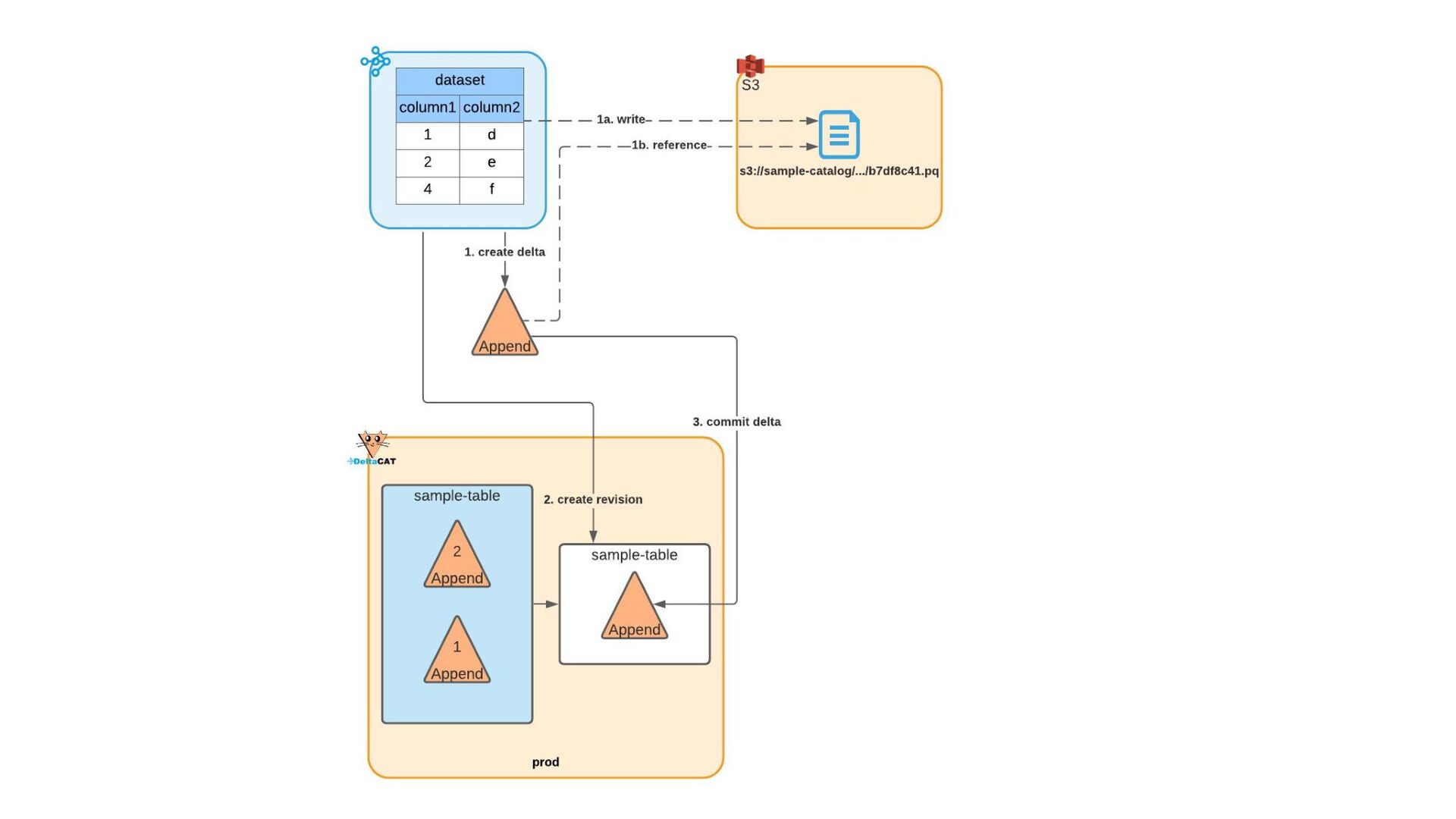{kind=link}
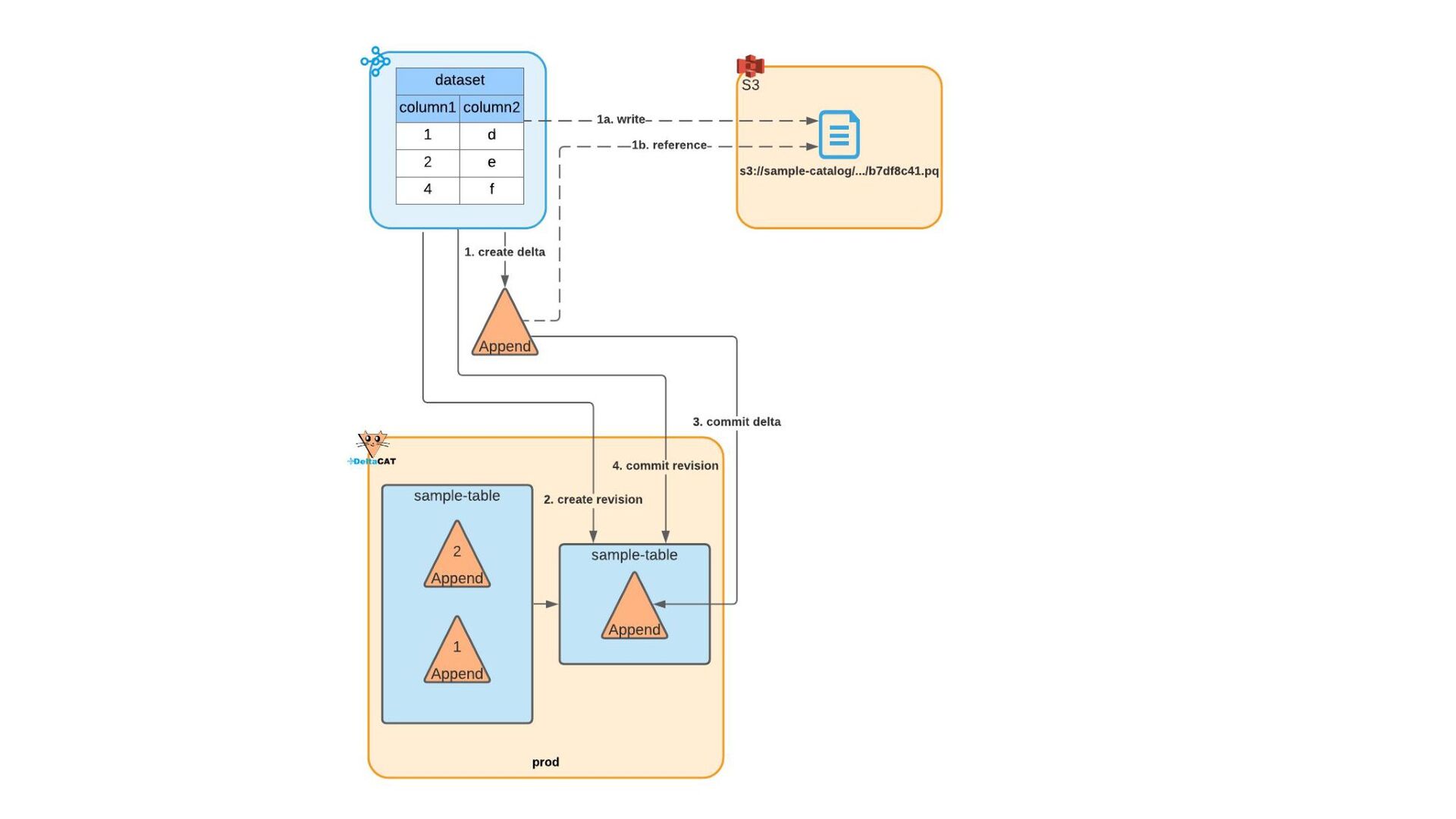{kind=link}
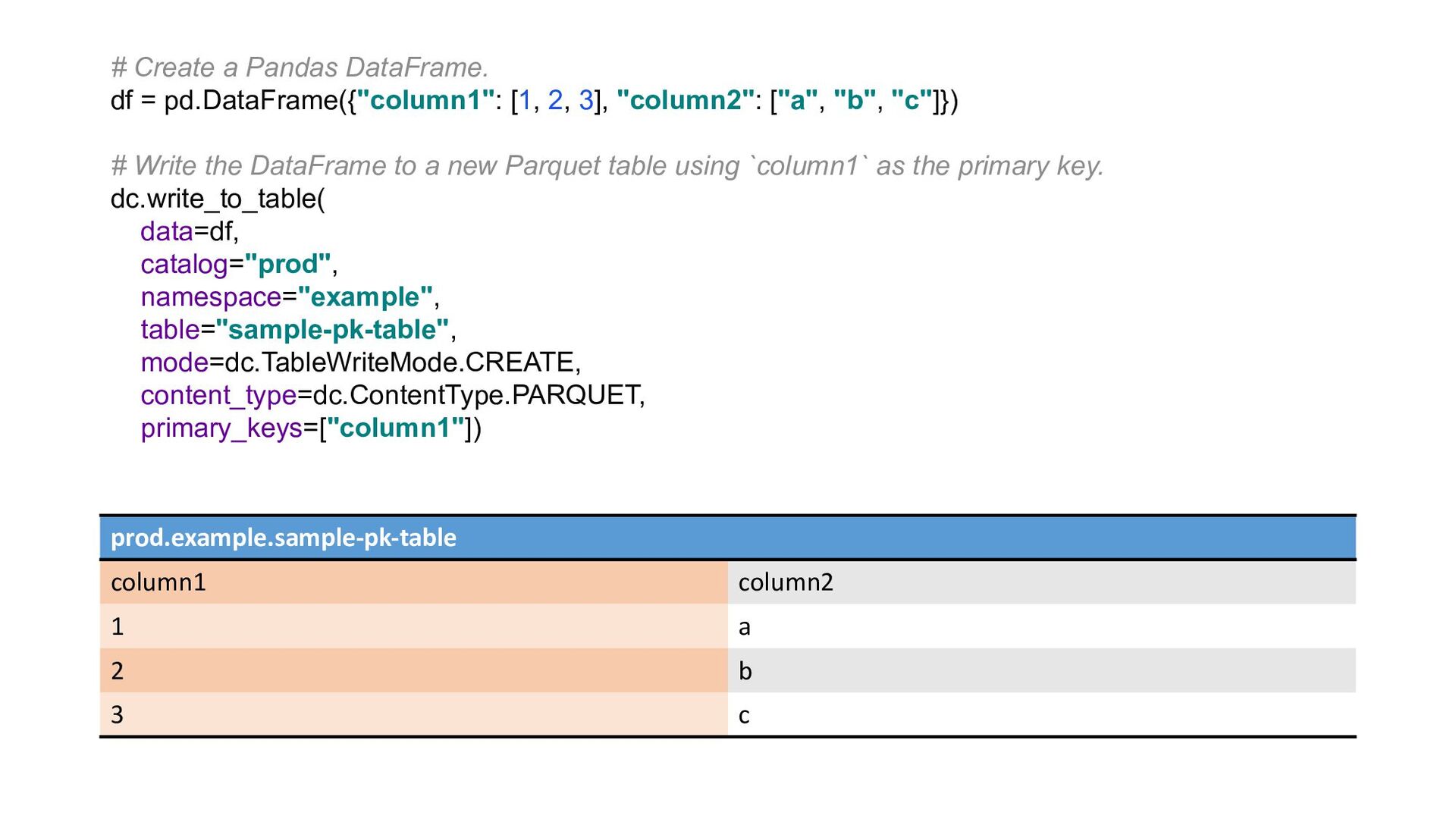{kind=link}
{kind=link}
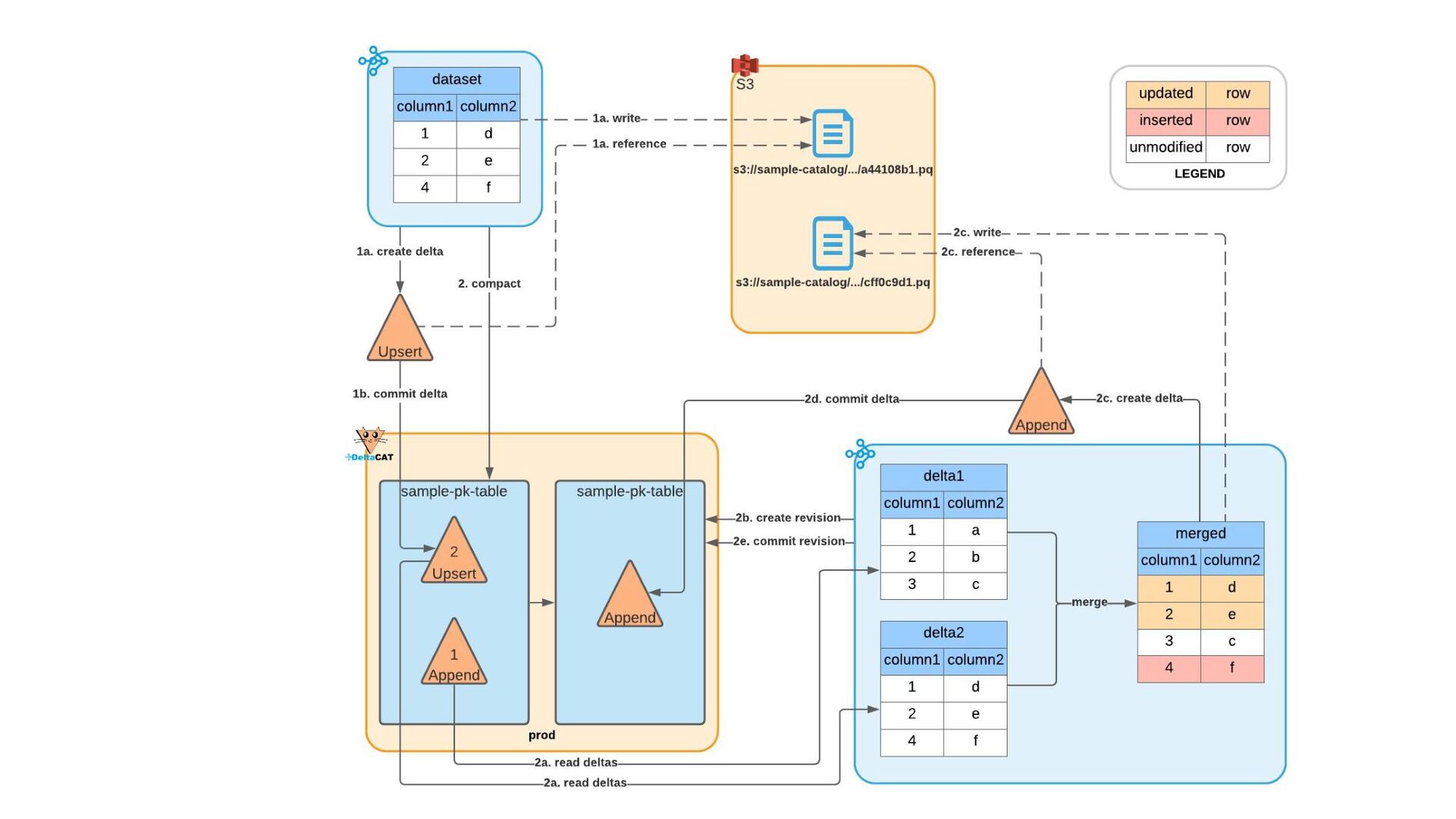{kind=link}
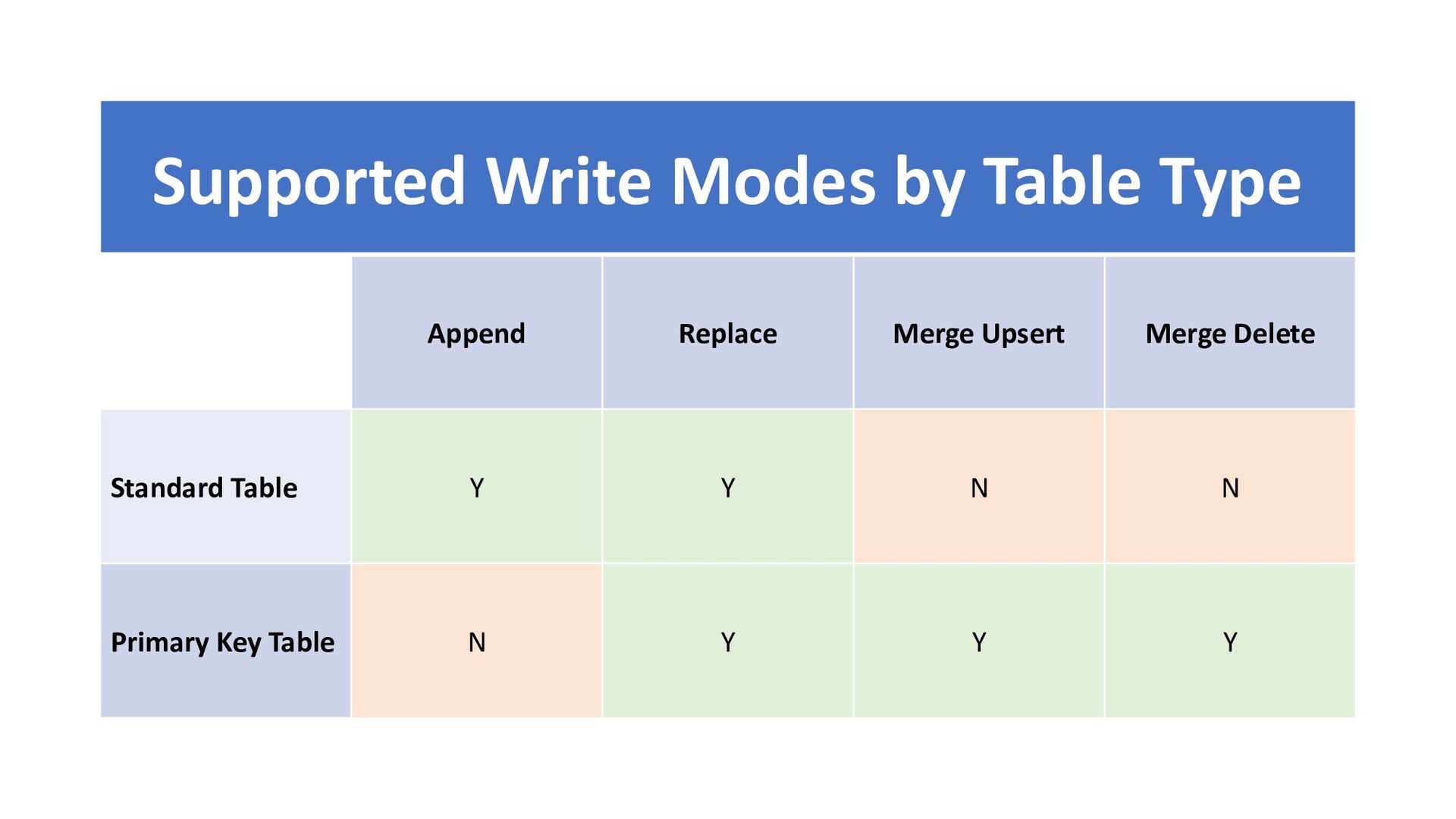{kind=link}
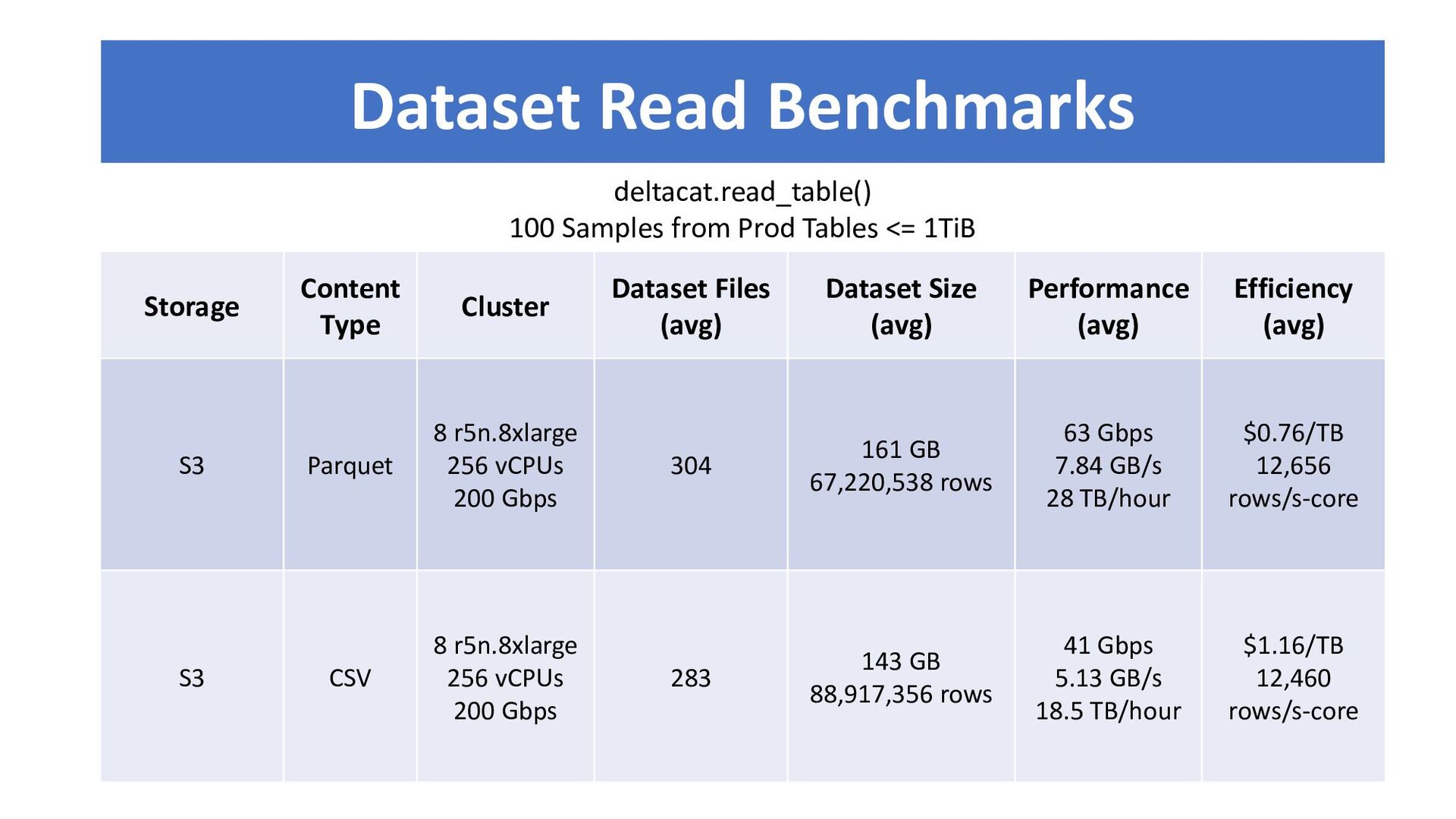{kind=link}
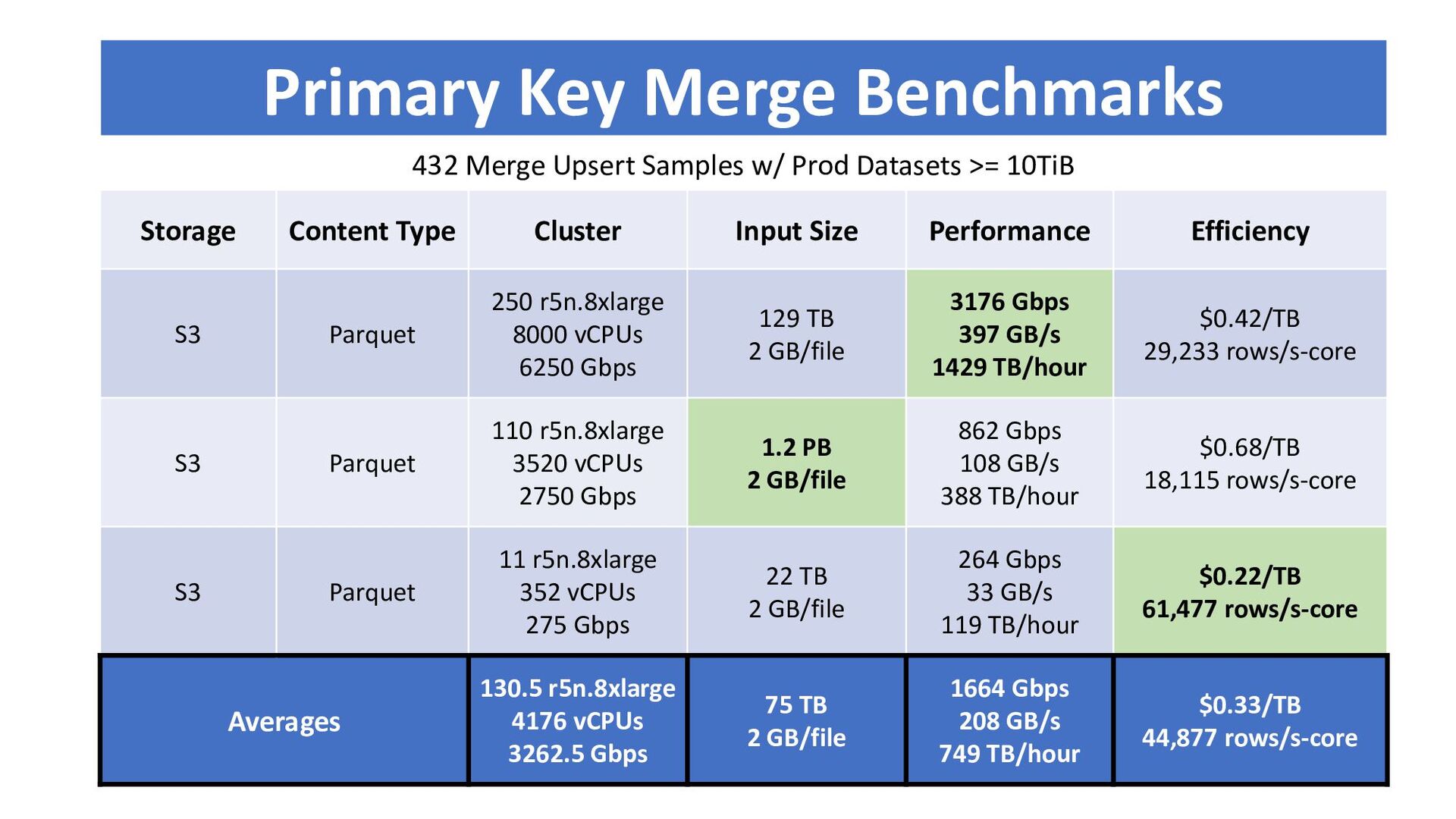{kind=link}
{kind=link}
{kind=link}
{kind=link}