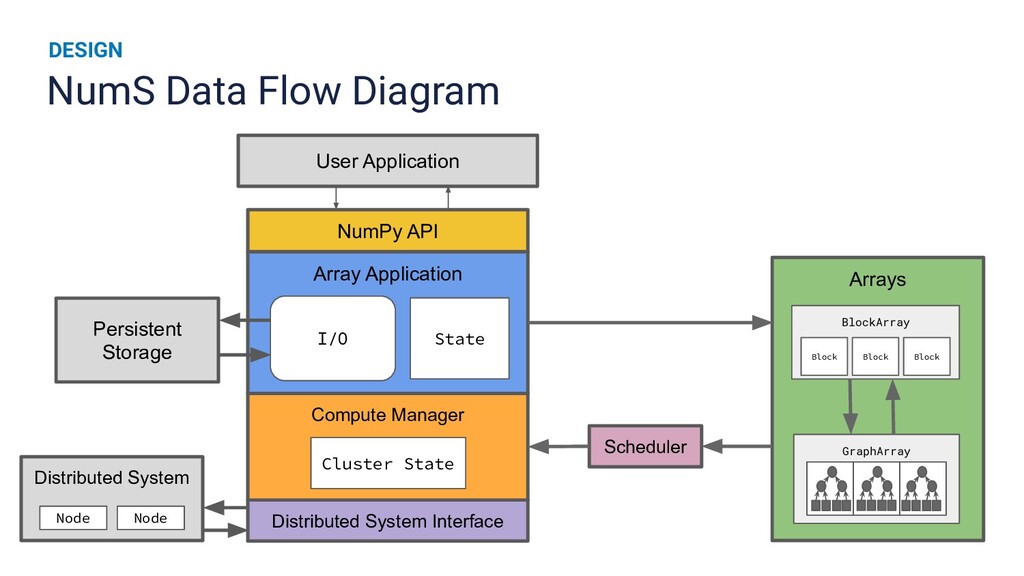
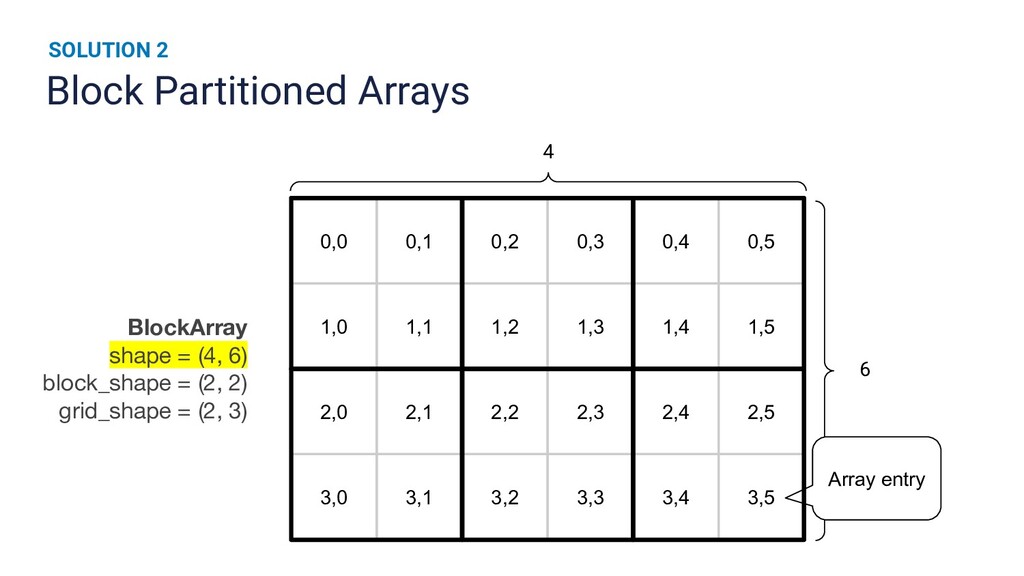
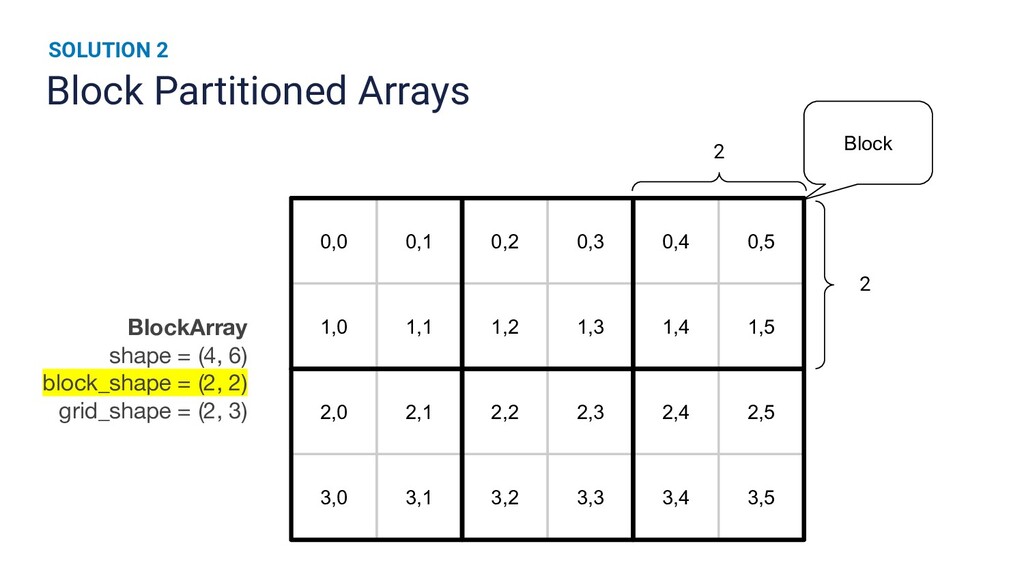
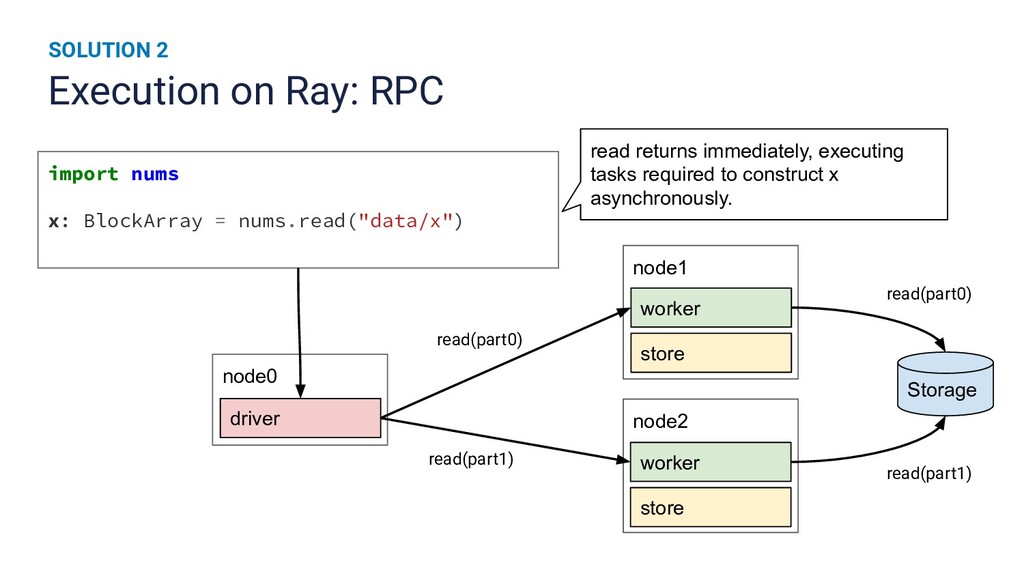
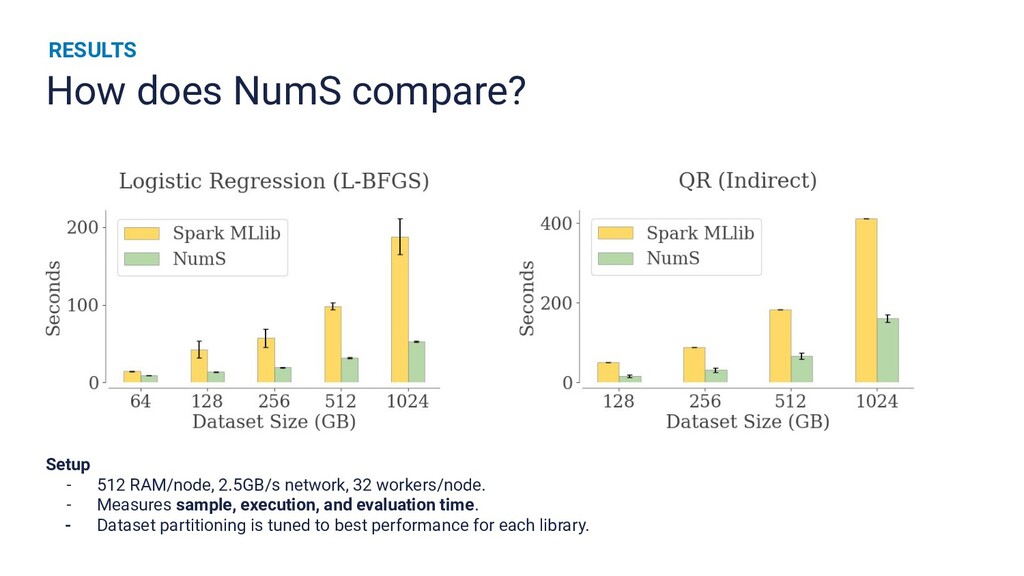
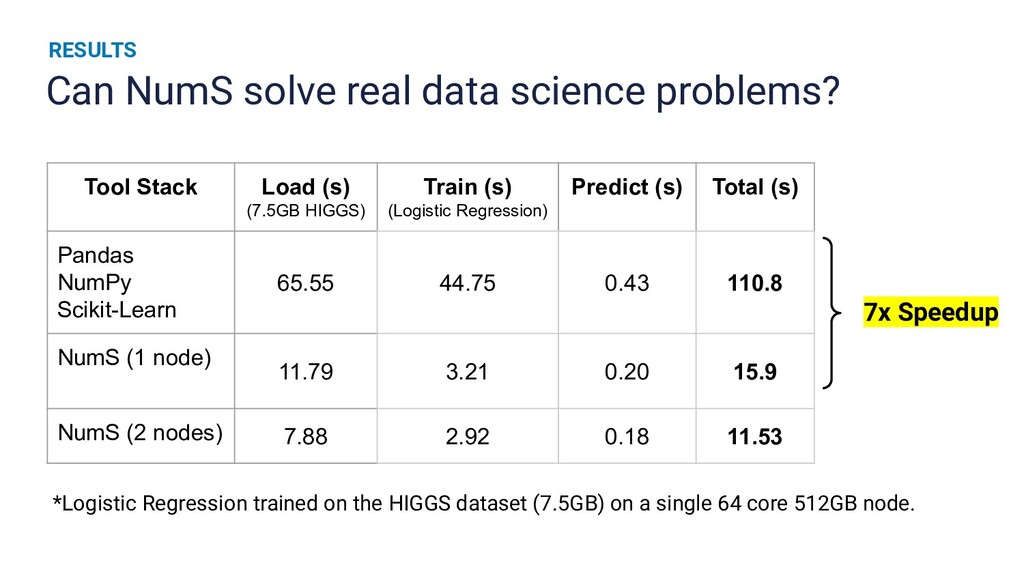
Runtime improvements to multi-dimensional array operations increasingly rely on parallelism, and Python's scientific computing community has a growing need to train on larger datasets. Existing SPMD distributed memory solutions present Python users with an uncommon programming model, and block-partitioned array abstractions that rely on task graph scheduling heuristics are optimized for general workloads instead of array operations. In this work, we present a novel approach to optimizing NumPy programs at runtime while maintaining an array abstraction that is faithful to the NumPy API, providing a Ray library that is both performant and easy to use. We explicitly formulate scheduling as an optimization problem and empirically show that our runtime optimizer achieves near optimal performance. Our library, called NumS, is able to provide a 10-20x speedup on basic linear algebra operations over Dask, and a 3-6x speedup on logistic regression compared to Dask and Spark on terabyte-scale data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![SOLUTION 1 Array Access Dependency Resolution x = A[:, i].T](https://files.speakerdeck.com/presentations/3fa0a2e310244e7ca7b890b91360583f/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
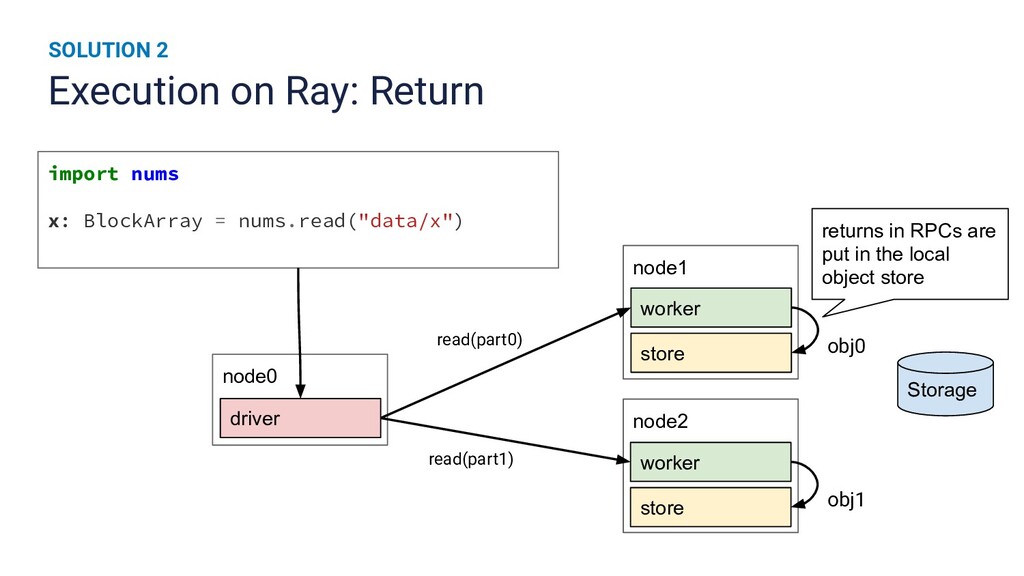{kind=link}
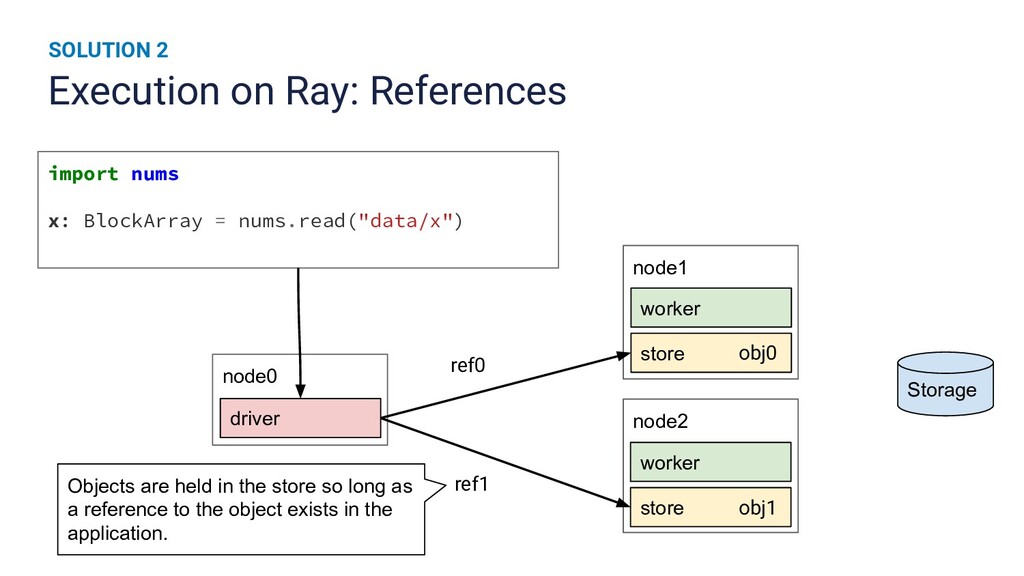{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
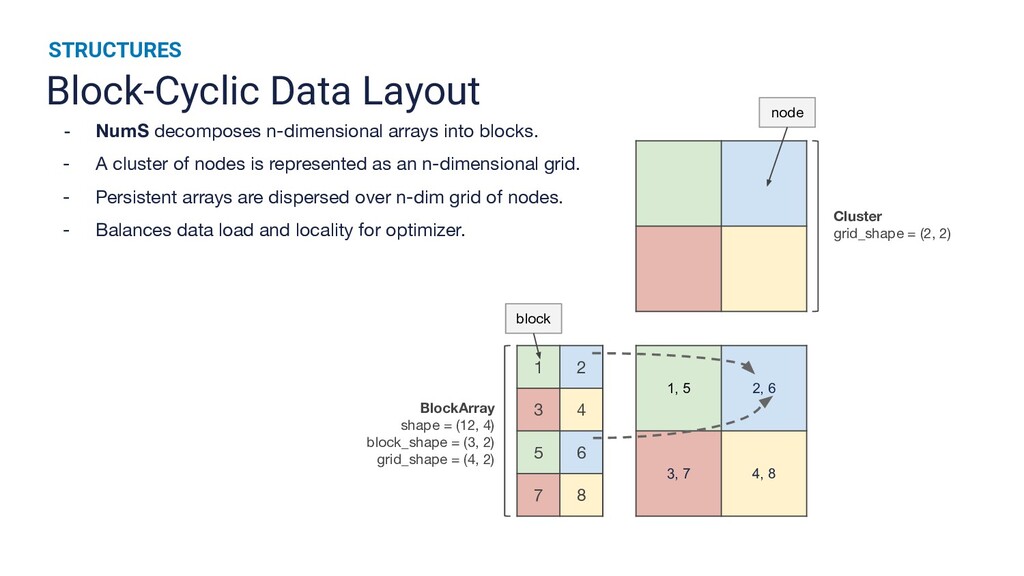{kind=link}
{kind=link}
{kind=link}
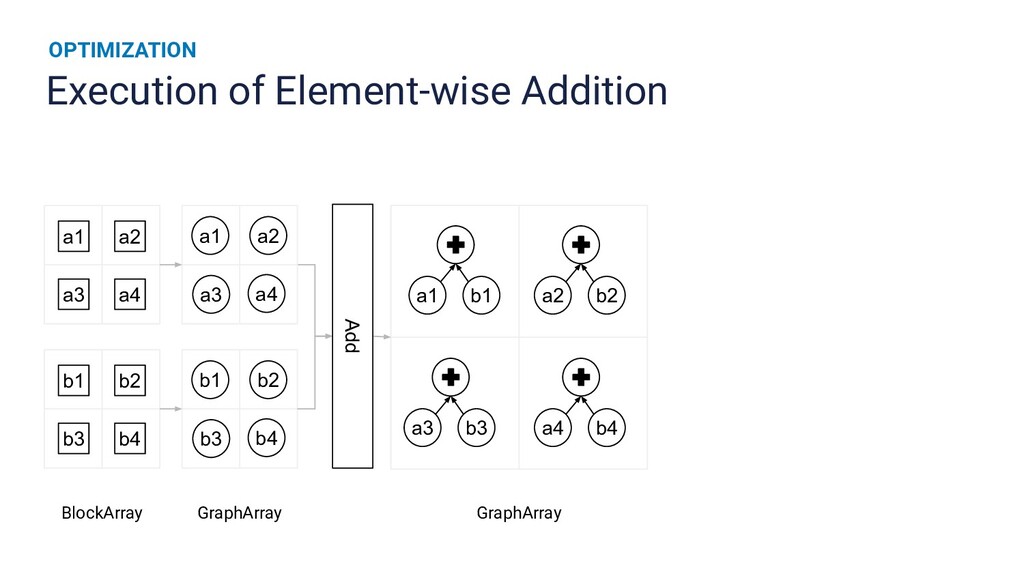{kind=link}
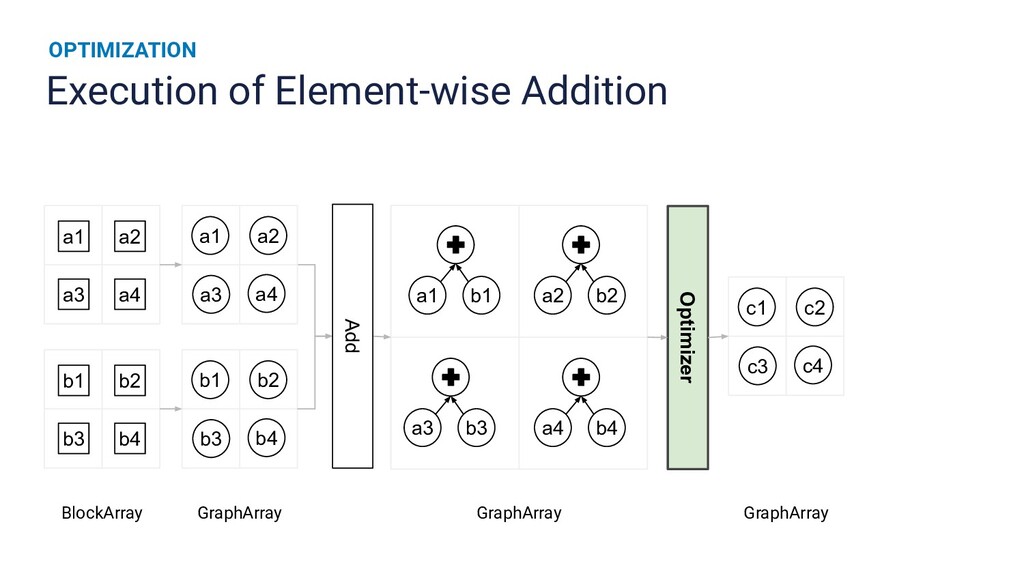{kind=link}
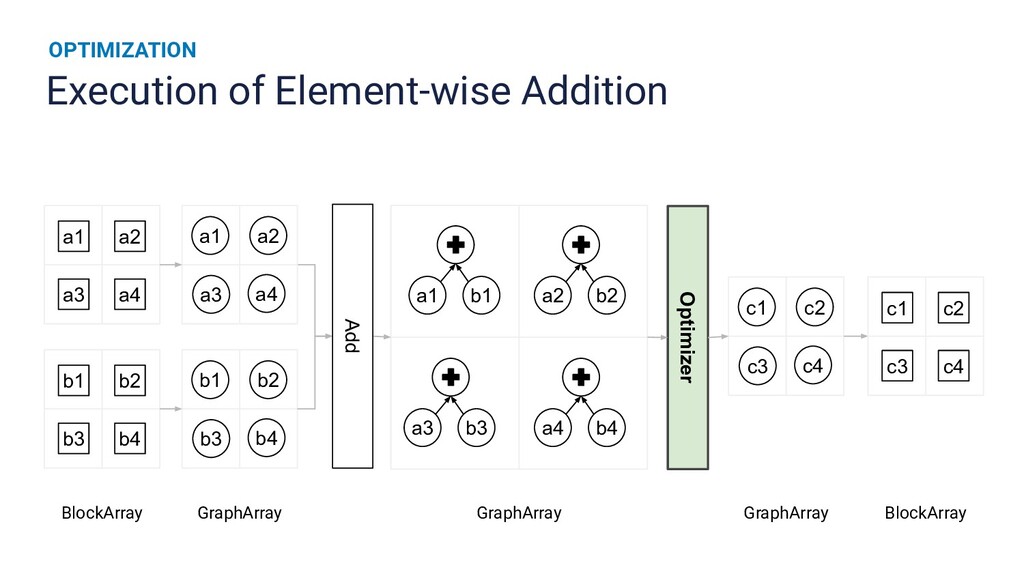{kind=link}
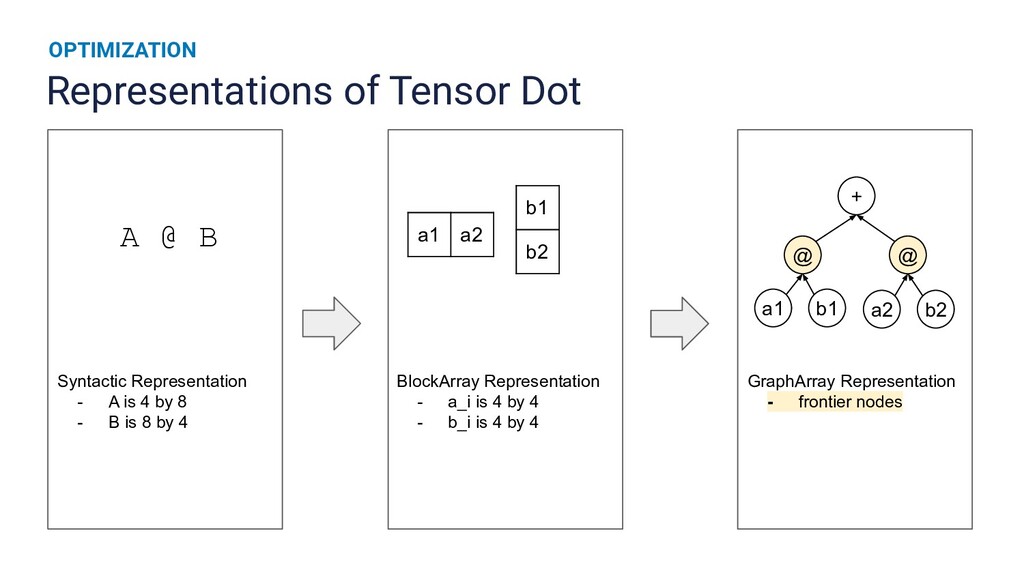{kind=link}
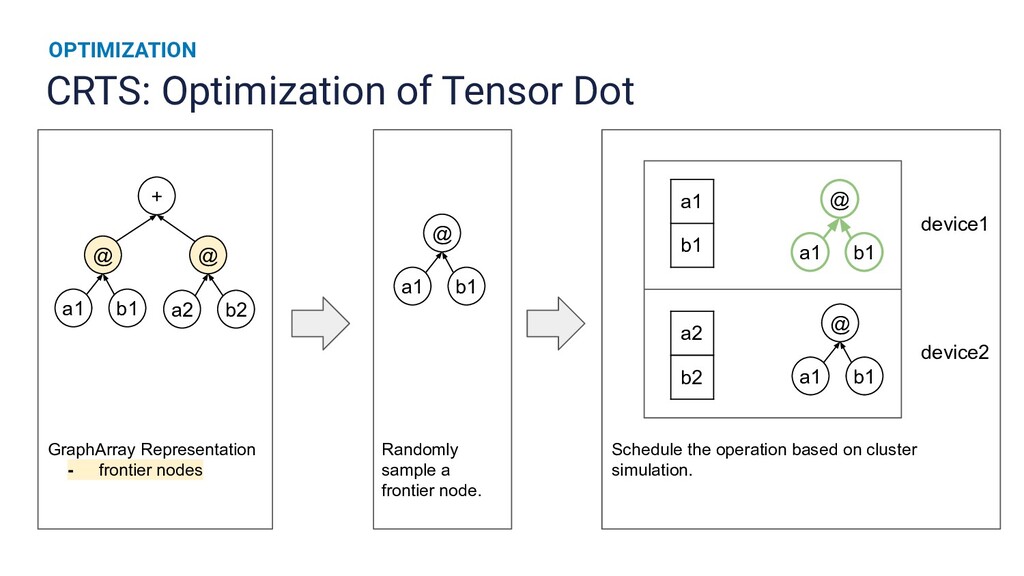{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}