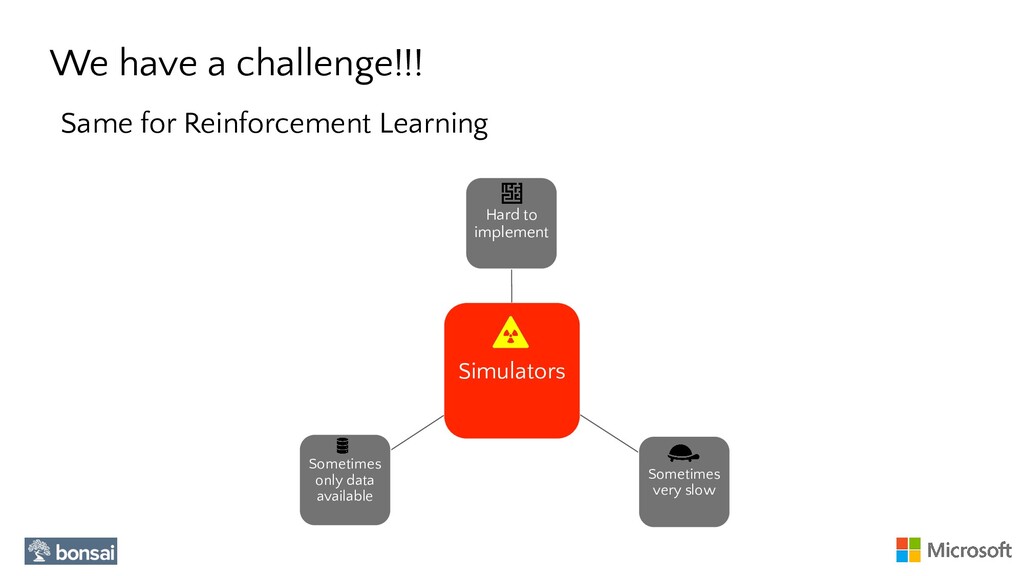
Reinforcement Learning is a fast growing field that is starting to make an impact across different engineering areas. However, Reinforcement Learning is typically framed as an Online Learning approach where an Environment (simulated or real) is required during the learning process. The need of an environment is typically a constrain that prevents the application of RL techniques in fields where having a simulator is very hard or unfeasible (e.g., Health, NLP, etc.).
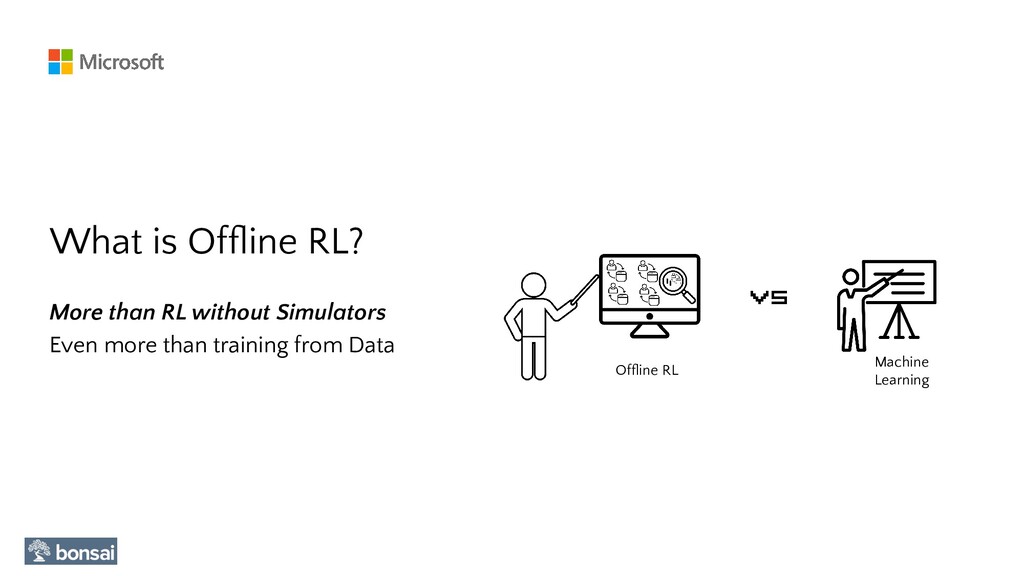
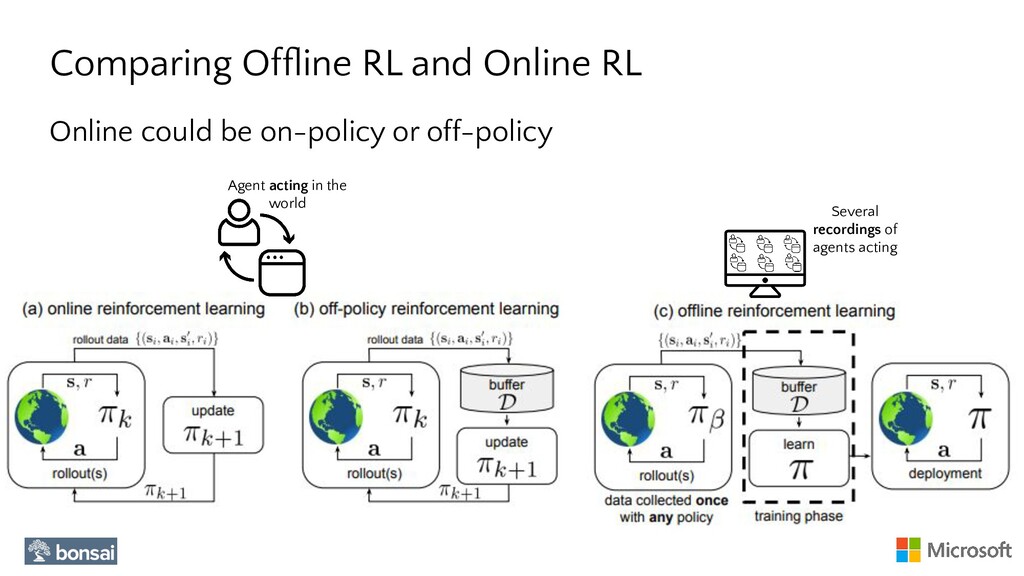
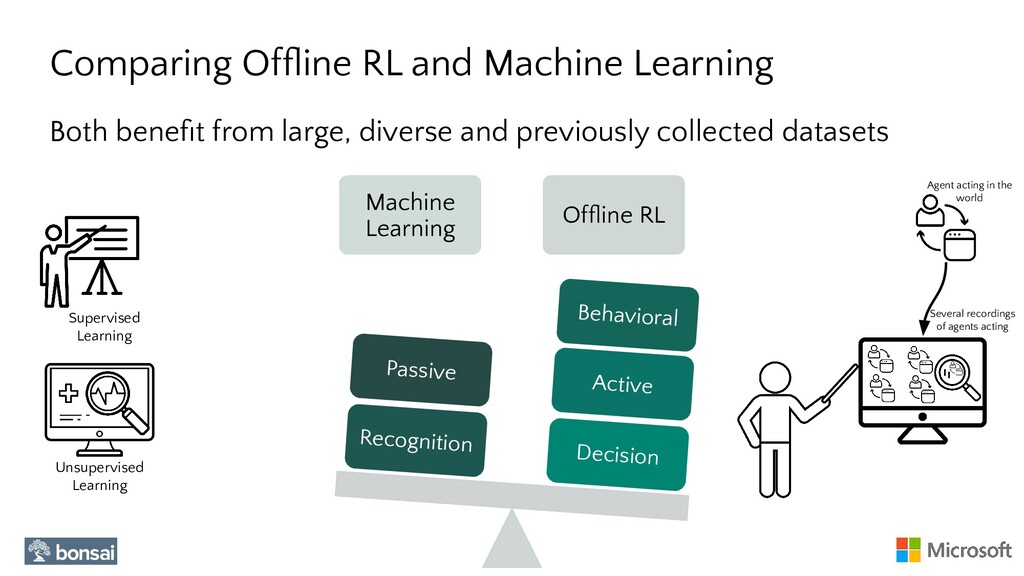
In this talk, we will show how to apply Reinforcement Learning to AI/ML problems where the only available resource is a Dataset, i.e., a recording of interactions of an Agent in an Environment. To this end, we will show how RLlib can be used to train an Agent by only using previously collected Data (Offline Data).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}