SWIM: Scalable Weakly- Consistent Infection-Style Process Group Membership Protocol
In this talk we introduce SWIM, a membership protocol that makes use of gossip and a randomized failure detector. We also discuss Serf and how it addresses various limitations of SWIM, and it's applicability in Serf and Consul.
for developers and operations, or just DevOps. You may recognize some of our tools, we make Vagrant, Packer, Serf, Consul and Terraform. We will circle back to this later, but SWIM is actually an integral part of both Serf and Consul.
over a network • Packet loss • Partitions • “Who are my live peers?” Before we dive into the paper, it is useful to have background on membership protocols and the problem they are trying to solve. We start by assuming a dynamic group of members or processes communicating over a network. We make no assumptions about the network, and fully expect packet loss and partitions. Membership protocols provide an algorithm so that a program can answer the question “who are my live peers?”
• Network Overlays • Discovery Layer Given that we have a membership protocol giving us a list of live peers, there are a lot of possible use cases. Some common ones are for building P2P networks, network overlays, or as a discovery layer in distributed systems such as Serf and Consul.
Das, Indranil Gupta, Ashish Motivala Now that we have a light intro to the subject, today we are looking at SWIM. The title of the paper is a bit of a mouthful, and out of respect for the authors I won’t butcher their names. Before we dive in, let’s just briefly unpack the title, and set some expectations.
Protocol To set the stage, let’s unpack each of the terms in the name. The “Scalable” is probably the most intuitive part, and we should expect to evaluate this algorithm on hundreds or thousands of machines, not handfuls. Weakly Consistent in this case means all the members may not agree on the state at any given point in time. Infection-Style meaning information is distributed peer-to-peer in a gossip or epidemic style. Lastly, membership protocol is the key, every member should know about every other member.
of traditional heart-beating protocols” • Heartbeating previously state of the art The first word in the title is Scalable, and right in the beginning of the papers abstract, the authors call out the primary motivation behind the work is the scalability limits of the existing work. To really get inside why SWIM is built the way it is, we need to better understand the state of the art, which was heartbeating
If no updates are received from peer P after T*Limit, mark as dead • Membership + Failure Detection At the core of heartbeating, is a very simple idea. On some interval T, nodes tell their peers that they are alive. If a peer isn’t heard from in some Limited number of rounds, then we assume that node has died. Not only does is this simple to understand, but it also naturally gives us membership. When we first hear an “alive” message, we can handle new peers, and if a peer leaves or fails we eventually learn of this at the Limit as well. Let’s look at a few approaches to heartbeating to better understand the limitations.
approach to heartbeating is simple broadcast. Either using broadcast, multicast, or gossip, nodes simply broadcast a liveness message on every broadcast interval to all other nodes. In the case of using IP broadcast or multicast, we are severely limited in what environments this technique works in, as those network layer protocols are generally disabled. However, in all the cases we have a bigger problem, which is that we have O(log(N)*N^2) messages to send on each interval. This may be fine with a handful of nodes, but even with 1000 nodes we would need to send over 10M messages per second for a 100msec gossip interval.
• Accuracy • Impossible to get 100% on asynchronous network • Network Message Load Looking at these this approach, it is clear it has serious limitations. However, we don’t yet have a general rubric for evaluating protocols. The authors provide one, which comes from earlier literature in the space. The four key properties to evaluate are strong completeness, which means do all non-faulty members eventually detect a faulty node. Speed of failure detection which is measure in time from failure until any node detects the failure. Accuracy, which is the rate of false positives. There is a convenient impossibility proof that shows that building a perfect accurate detector over an asynchronous network with strong completeness can’t be done. Lastly, there is the load on the network.
failed. • Speed - Limit * Interval • Accuracy - “High” • Network Load - N^2 Looking back on Heartbeating, we can easily evaluate it against this rubric. Because all nodes receive the “alive” messages, every node can independently detect failures. The speed of failure detection is limited by how many live messages maybe missed. The accuracy depends on a number of factors including packet loss rate, and depends on if broadcast, multicast, or gossip is used. Suffice to say, there is enough work on gossip algorithms to get this reasonably low. Lastly, the network load is a quadratic N^2. This is the show-stopper for this technique.
• Cheaper failure detection? One of the key insights of the authors is that the problem decomposes into two separate parts: failure detection and information dissemination. Using gossip as a peer-to-peer mechanism for disseminating information is robust and low-latency but poorly suited for heartbeating due to the quadratic growth in network usage. By separating these two concerns we can actually remove the N^2 cost.
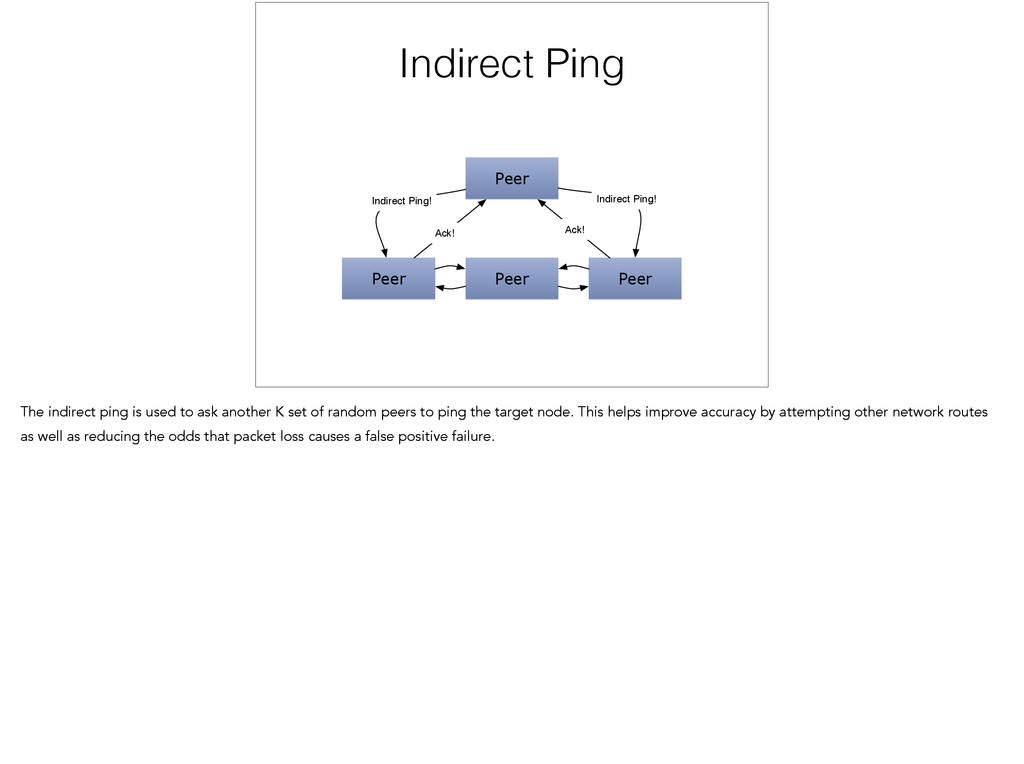
the first contributions of the SWIM paper is their failure detector. It is also fairly simple at the core. Given that we have a list of known peers, on every interval, we select a random peer and send it a ping message. If it is alive, it should respond by sending an ack back. If the node has failed, we don't receive an ack back and we can now mark the node as failed. However, if the ping or ack was dropped, or our peer was momentarily busy, we would also mark it as failed. So to improve accuracy, the authors add an indirect ping.
Ack! Ack! The indirect ping is used to ask another K set of random peers to ping the target node. This helps improve accuracy by attempting other network routes as well as reducing the odds that packet loss causes a false positive failure.
• Speed of detection: 1*Interval • False Pos: ~(1-Delivery%^2)*(1-Delivery%^4)^K • Accuracy (D=.95, K=3) = 99.9% • Network Load - (4*K+2)*N - O(N) Now, let’s evaluate this simple ping based approach with our old rubric. The completeness property can be seen because we are selecting the node to ping at random, so we expect given enough time all nodes will be pinged. We tighten this up later to be Time Bounded. The speed of detection is a single interval, and the accuracy given sane parameters if very high. Most importantly however, the network load is linear! This is the biggest win here, as it practical to apply to clusters of thousands of nodes.
Dead} messages • Broadcast / Multicast • Gossip We’ve covered the failure detector introduced by SWIM and seen that it has the properties we want. But now we still have the issue of managing state updates. We need to be able to send Alive messages to have new nodes join, and Dead messages once our failure detector notices a failed node. While broadcast or multicast could be used, as we mentioned, they are rarely available. Another option is to use gossip to update state. Again the authors had a good insight, that this can be done by piggybacking on the existing messages
B Ping! New Node B Ack! Meet C The ping/ack system already sends messages between random nodes, so state updates can be done by simply adding additional messages about nodes to the same packets. The key messages are alive and dead allowing nodes to learn about new nodes and remove nodes that have left or failed.
(Weakly) Consistent • Updates sent peer-to-peer All information dissemination is done on the piggy back of the random ping and ack messages. Because these are sent to a random peer, the state is being shared in a gossip, infection, or epidemic style. Thinking about this, nodes will learn about new nodes and failed nodes at different times, meaning the state is only eventually or weakly consistent.
“Suspicion” State • Time-Bounded Completeness Using the ping based failure detector provides a scalable failure detector, and combined with the piggybacked updates we have a full membership protocol. However, SWIM also adds two additional twists to improve accuracy
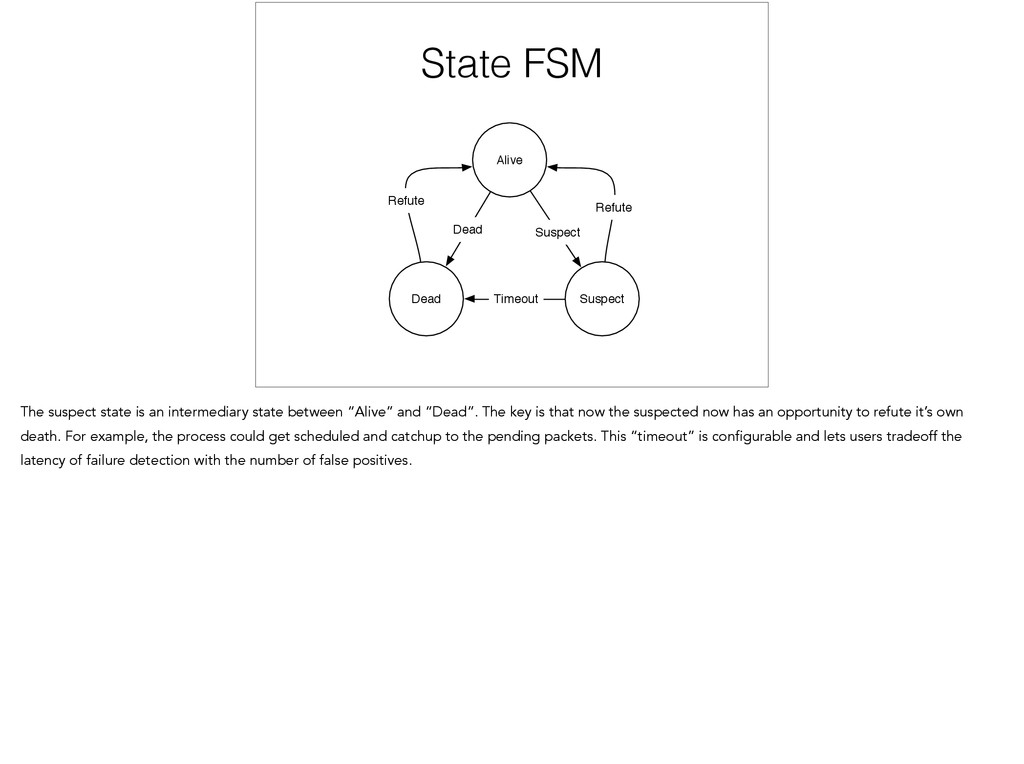
• Failure Detection Time vs False Positives • Additional “Suspicion” state The ping detector effectively makes K+1 attempts per interval to reach a peer that is being health checked. As we computed earlier, this increases the accuracy to a very high value when the only concern is network packet loss. However, if we have processes that could be very busy, or machines that are overloaded, then it is possible that the packets are being delivered but not processed in time. This is more likely to be an issue with shorter interval durations. One tradeoff that can be made is to reduce the false positive rate by increasing the time to failure detection, thereby giving a node longer to recover. SWIM does this by adding an addition Suspicion state.
Ping! Again, as before we make use of both ping and indirect pings to check if the node is alive. However, because the node is busy, it is not responding. Previously, at the end of the interval, we would assume our peer has failed and gossip indicating that to our peers.
The suspect state is an intermediary state between “Alive” and “Dead”. The key is that now the suspected now has an opportunity to refute it’s own death. For example, the process could get scheduled and catchup to the pending packets. This “timeout” is configurable and lets users tradeoff the latency of failure detection with the number of false positives.
out of order • Packets lost Unfortunately, this seemingly simple modification has a small wrinkle. Namely, state updates are done using gossip. The gossip is randomized, but more over, the network is free to deliver packets out of order or drop them all together.
Alive A Alive A Dead A Suspect A Alive Message Queue 2: Message Queue 1: As an example of how this can wreak havoc, the two message queues above can be caused by just reordering delivery of the last two messages. However, the meaning is very different. With message queue one, we believe that Node A died, and then refuted it’s death. With message queue 2, we believe Node A was suspected, refuted that, but died at some point after that.
not required • “Happens Before” / Causal Ordering To fix this issue, we need to establish some kind of ordering between messages. This will allow us to disambiguate situations like the one we just saw. It is important to note that we don’t need a total ordering of all messages in the system, only between messages about a single node. This simplifies the problem and allows us to use a logical timestamp.
Alive, Peer: A, Time: 0} • Global maintained • Peer specific • Only incremented by peer! The authors make use of an “incarnation number”, which is a logical timestamp in effect. When a node first joins, it’s incarnation number is 0. So the initial message sent to the cluster is the tuple of Alive, Peer A, and time 0. If the node is ever suspected of failure, it the suspect message includes the current incarnation number. If it is refuted, the peer sends Alive message with a higher incarnation number. This supersedes any previous suspect message. The death message also includes an incarnation number, but it takes highest precedence, since a peer could have missed the refutation and the death would be using an older incarnation number.
A Dead 1 A Suspect 0 A Alive 0 A Alive 0 A Dead 1 A Suspect 0 A Alive 0 If we revisit our old message queues, but this time annotate them with incarnation numbers, we can see that the ambiguity has been removed. Now it is clear that the first node has received the alive message out of order, and that peer A should be considered dead.
latency • Plan for slow processes & degraded networks • Completeness? By adding a new suspicious state, we are able to trade the latency of failure detection for lower false positives. Effectively, we can give nodes a period to refute their death which is longer than the single Interval otherwise provided by the original ping system. This allows us to increase accuracy in the face of both degraded networks and slow processes and overwhelmed systems. We covered the scalability, speed of detection, and accuracy of SWIM but what about completeness.
by every non-faulty process eventually • Randomly ping nodes • Expect to ping every node eventually The definition we need to meet is that every faulty process is eventually detected by every non-faulty process. So far this is done by randomly pinging nodes. We just hand wave a bit and assume every node will be pinged at some point, eventually. But that is a rather soft guarantee.
order • Amortized O(1) • Worst Case: Interval*N • Expected Case: Interval The fix to this is surprisingly simple. Instead of randomly picking a peer, we sort our peers in a random order. Then, we do the failure checking in a round- robin order. Once we reach the end, we re-sort the list. Because the sorting is done only once per N operations, the amortized cost is constant. As a result, we can provide a guarantee of time-bounded completeness, meaning we are sure to ping every node in Interval*N. Expected case is still O(1).
SuspicionRounds • Accuracy: “High” • Network Load: O(N) With all the modifications in place, we can do a final tally of SWIM. We just showed that the randomized round-robin gives us Time-Bounded strong completeness, that detection speed can be a tunable number of Intervals, Accuracy is very high, and lastly the load on the network is linear to the number of nodes. Based on a purely theoretical analysis, SWIM looks like it gives us everything technically feasible. The question is how does it do in the real world.
Constant Load • Low false positive rate • Constant time to failure detection • Logarithmic increase in latency In the paper, the authors do a real world evaluation of SWIM. However, based on our all be it modified implementation, we’ve tested real-world Serf clusters with over 2K nodes. The results seem to hold: there is a constant load on the network per machine, very low false positive rate, a constant failure detection latency, and a logarithmic increase in latency of update information.
vs Fail • (Re-)Joining • Custom Payloads • Peer metadata • Encryption • Fixed in Serf! Although SWIM is a great membership protocol, it does have several limitations. Briefly, these are real limitations that we’ve worked to address in our work on Serf.
timer in Serf • 200msec gossip • 1s failure detection SWIM relies exclusively on piggybacking messages. As a result, the effective throughput of state updates is limited by the frequency of the failure detector. We found that this is a major bottle neck when many nodes join or fail, for example when a switch fails or rack comes online. With Serf, we make use of the piggybacking technique, but we also have a separate gossip timer that runs more frequently. If there are no state updates, then nothing is sent. This does not increase the network load, but does dramatically reduce the latency of state updates, especially under load or with large networks.
SWIM will do the right thing, and both A & B will mark C and D as having failed. On the other side of the partition, nodes C &D will mark A and B as having failed. This is what we expect given the network topology and condition. However, the problem is that SWIM relies only on refutation to undo a false positive failure. Once the partition heals, there is no mechanism by which the two sides of the cluster can rediscover each other.
Periodically attempt to re-join failed nodes • When to retry? Serf makes a few changes to support this. Firstly, we do not purge a node when we get a “death” announcement. Instead, we keep those nodes around and attempt to re-connect to them periodically. However, this raises the question of when to retry.
Failing • Possible Partition, Auto-healing • “Intents” - Broadcast intent to leave We need to make a distinction between leaving a cluster and failing. The difference is important, because a failed node may be the result of a network partition, which can be fixed by rejoining the cluster after the partition heals. If a node voluntarily leaves, then there is nothing to do. This is solved in Serf by making use of intents. A node beings to broadcast a message with its intent to leave. When the failure detector notices the node has failed, it checks for a recent intent matching the node’s current incarnation and instead marks it as left.
of members • Partition healing • Incarnation Number recovery • Push/Pull Anti-Entropy • Bimodal Multicast SWIM has a number of issues around joining or rejoining a cluster. The first is getting a list of initial members. It is implicit that this list can be slowly materialized by collecting all the incoming ping messages, but this will take N*Interval to construct the list of peers. This is exceedingly slow, especially for large clusters. This same issue exists after a partition is healed, since the two sides may have diverged, and convergence will be very slow. Lastly, there is the issue of recovering an incarnation number. If a node rapidly joins, leaves, and re-joins, the cluster may have a non-zero incarnation number, while the newly joined node believes the global value is 0. To fix all these issues, Serf makes use of a push/pull anti-entropy system. This is similar to the system in Bimodal Multicast. On join, Serf makes a TCP connection and pushes the current state, recent intent, and recent event buffers, and pulls the same down from the remote node. This serves to quickly initialize the member list and recover the incarnation number. However, partition recovery operates exactly like a join, allowing fast convergence and even replay of any messages or intents that were recently sent. This allows Serf to converge much faster than SWIM standalone.
systems • Existing components Lastly, Serf adds support for custom payloads. Because a membership protocol is not useful in isolation, it is by nature meant to be embedded. Once we have all the machinery in place to do gossip based delivery of messages with anti-entropy, it is nice to support application specific payloads as well.
Lamport Clocks Supporting user payloads is non-trivial as they introduce several new issues. Their state is unbounded. Unlike the peer state which is a simple FSM limited by the number of nodes, user payloads can be continuously fired and unbounded storage is not possible. State updates are trivial to de-duplicate as they are just a state transition with a specific incarnation number. User events can be arbitrary, and worse the same payload could be fired multiple times on purpose. Lastly, ordering state updates is done with incarnation numbers. User events have no such luxury since they are global and not node specific. Serf makes use of lamport clocks to provide a global causal ordering of payloads.
overcome these issues, Serf uses a number of techniques. Nodes maintain a recent event buffer. This is used instead of unbounded state and allows for highly reliable delivery without a state explosion. Event de-duplication is done by comparing the message name, payload and lamport time. Events that are duplicated can be dropped, but Serf also provides richer coalescing logic to allow similar payloads to be merged together. Lastly, because of the recent-event buffer and the push/pull mechanism, events can be replayed to recover from network partitions or to prevent delivery of old events to new nodes.
metadata • Injected into “Alive” • “Versioned” by Incarnation Number A final limitation of SWIM is the lack of metadata per node. All you get is an IP address. This is not particularly useful, especially when using Serf/SWIM as a discovery layer in a larger system. Serf provides additional metadata per node. This is hitched onto the “Alive” messages in the system, and can be updated by incrementing the incarnation number.
SSL/TLS • AES-GCM • Key Rotation SWIM also does not cover the issue of security. Unfortunately it turns out this is a particularly thorny issue for gossip systems. They don’t have long lived connections making SSL/TLS difficult. Even just attempting Diffie-Helmen would require N^2 key exchanges, quickly becoming impractical. Instead Serf uses a symmetric key encryption system based on AES-GCM. We also support key rotation so that keys can be changed without downtime. Due to the nature of gossip, all peers communicate with each other so an attacker can discover all the peers by just observing source and destination addresses. Protecting against that is outside the scope of our project.
(http://www.serfdom.io) • Consul (http://www.consul.io) While implementing Serf and SWIM we wanted to keep as true to SWIM as possible. We implemented the SWIM logically separately in a library we call Memberlist. All of the modifications we’ve made to SWIM can be disabled. The Serf library (confusingly different than the Serf CLI) adds many of the enhancements we’ve discussed and is generally much more usable as an embeddable interface.
orchestration • Agent • RPC • Custom Events • Request/Response Queries Confusingly enough Serf the CLI is separate from Serf the library. The CLI makes it possible to leverage the library and provides an executable agent, RPC system, custom event framework, “Queries” which is a request/response mechanism. All these together provide a lightweight system for cluster membership, failure detection and orchestration tasks.
Multi-Datacenter • Discovery of nodes • Event bus • Distributed failure detector • Distributed locking! Consul is a much heavier tool, but has a much larger scope. It provides service discovery, configuration, and orchestration features while supporting multiple data centers. It uses Serf underneath to provide support for cross-WAN gossip, node discovery (including using meta data to distinguish clients from servers), as an event bus, and lastly as a distributed failure detector. This final piece is crucial to the design of Consul’s distributed locking as it avoids the costly heartbeating of systems like ZooKeeper and Chubby.
of limitations, addressed by Serf • Distributed Systems <3 Gossip based membership In closing, SWIM is a fantastic membership protocol. It solves all the hard problems and gives you a really nice toolset of features. It does have a handful of limitations, but all are solvable, and we ship our solutions as part of Serf. Lastly, Distributed systems love gossip based membership. It is easy to integrate, robust in practice, and provides a great foundation to build upon.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}