crescimento na pesquisa de aprendizado de máquina, que tem alcançado avanços no reconhecimento de discurso, texto e imagem. ▸ Número elevado de camadas ocultas ▸ Permite que um computador aprenda tarefas, organize informações e encontre padrões sozinho
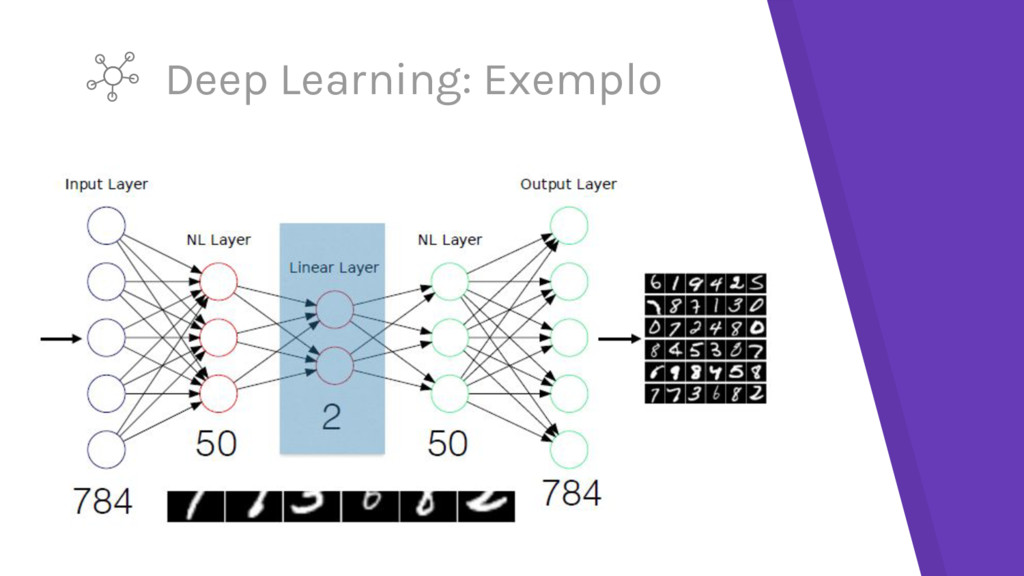
aprender características de nível mais alto pela composição de características de nível mais baixo – Tendo o cérebro humano como inspiração ▸ Aprender características automaticamente em múltiplos níveis de abstração permite ao sistema mapear funções complexas sem depender de características intermediárias inteligíveis aos humanos – Essa habilidade é necessária porque o tamanho dos dados tende a crescer
como processos de aprendizagem que descobrem múltiplos níveis de abstração ▸ As representações mais abstratas podem ser mais úteis em extrair informações para classificadores ou preditores – características intermediárias aprendidas podem ser compartilhadas entre diferentes tarefas
o que é feito com camadas escondidas em uma MLP, mas em uma arquitetura rasa ▸ Treinamento não supervisionado entre camadas podem decompor o problema em sub-problemas (com níveis mais altos de abstração) a serem decompostos mais uma vez pelas camadas subsequentes
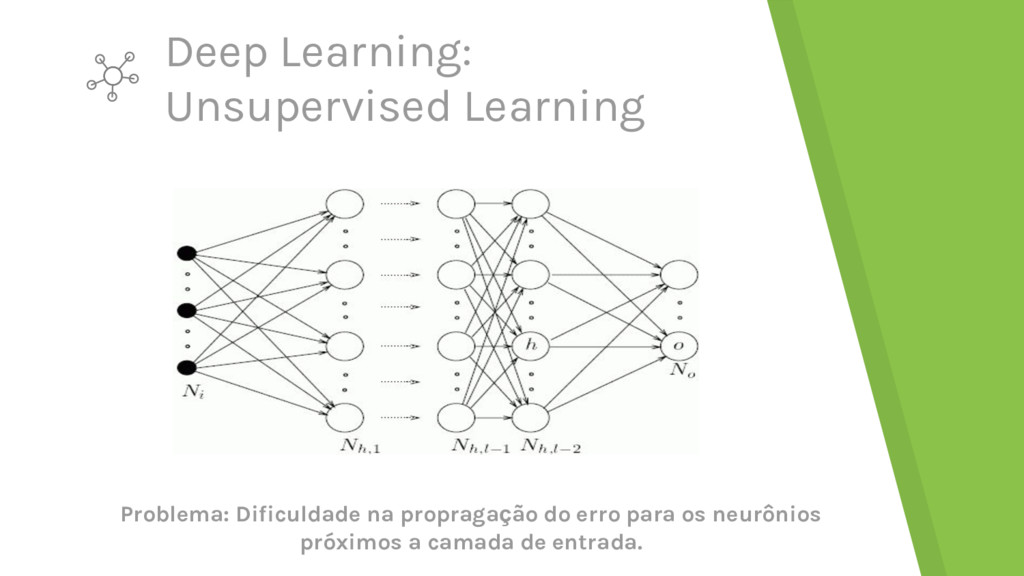
profundas – As camadas no MLP não aprendem bem ▸ Difusão do gradiente ▸ Treinamento muito lento ▸ Camadas mais baixas tendem a fazer um mapeamento aleatório - Frequentemente há mais dados não rotulados do que dados rotulados - Mínimo local
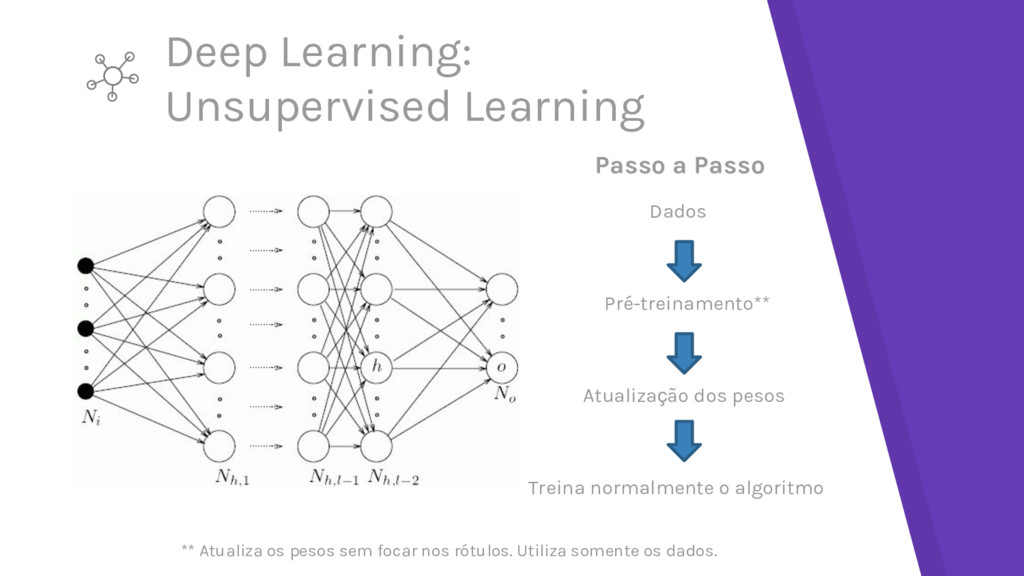
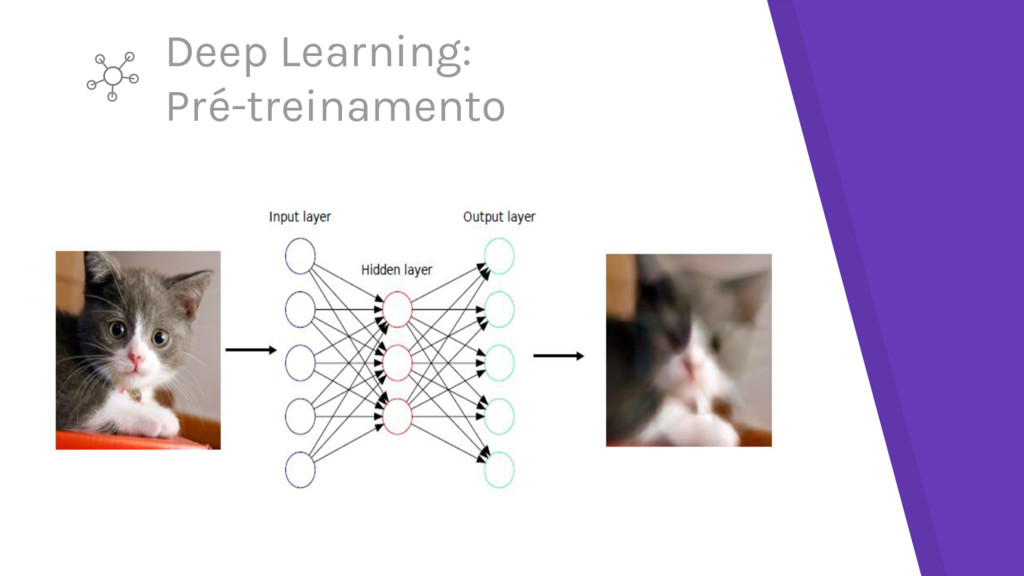
dados sem rótulos (Já que não há targets nesse nível, rótulos não importam) 2. 2. Fixar os parâmetros da primeira camada e começar a treinar a segunda usando a saída da primeira camada como entrada não supervisionada da segunda camada 3. 3. Repetir 1 e 2 de acordo com o número de camadas desejada (construindo um mapeamento robusto) 4. 4. Usar a saída da camada final como entrada para uma camada/modelo supervisionada e treinar de modo supervisionado (deixando pesos anteriores fixos) 5. 5. Liberar todos os pesos e realizar ajuste fino da rede como um todo uJlizando uma abordagem supervisionada
ao treinamento de uma rede profunda de modo totalmente supervisionado ▸ Cada camada toma foco total no processo de aprendizagem ▸ Pode tomar vantagem de dados não rotulados ▸ Quando a rede completa é treinada de modo supervisionado, os pesos já estão minimamente ajustados (evita mínimos locais) As duas abordagens mais comuns desse processo ▸ Stacked Auto-Encoders ▸ Deep Belief Nets
investigação nesta área tenta fazer melhores representações e criar modelos para aprender essas representações a partir de dados não rotulados em larga escala. ▸ Algumas das representações são inspirados pelos avanços na neurociência: - Interpretação do processamento de informações e padrões de comunicação em um sistema nervoso: codificação neural que tenta definir uma relação entre vários estímulos e respostas neuronais associados no cérebro.
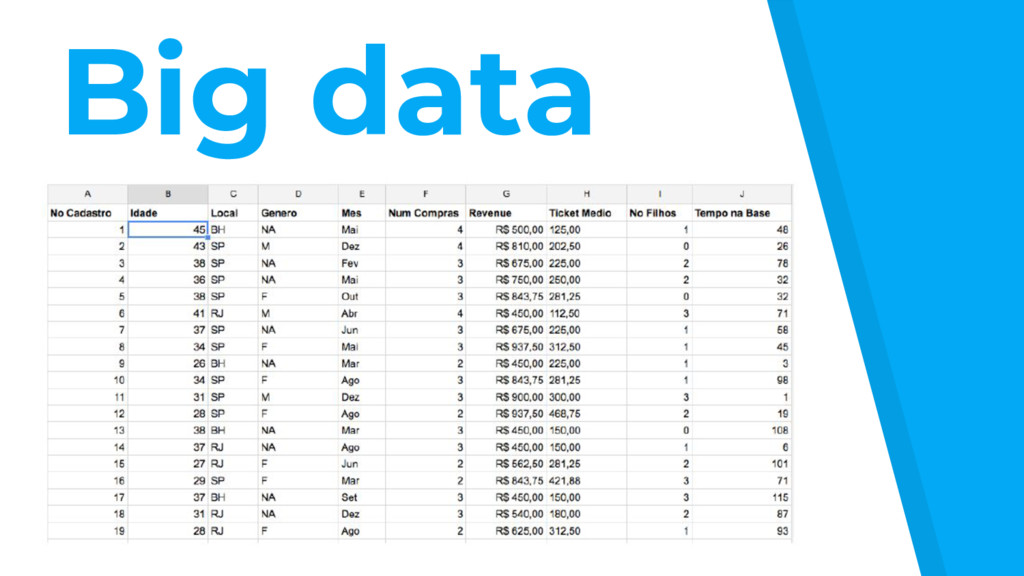
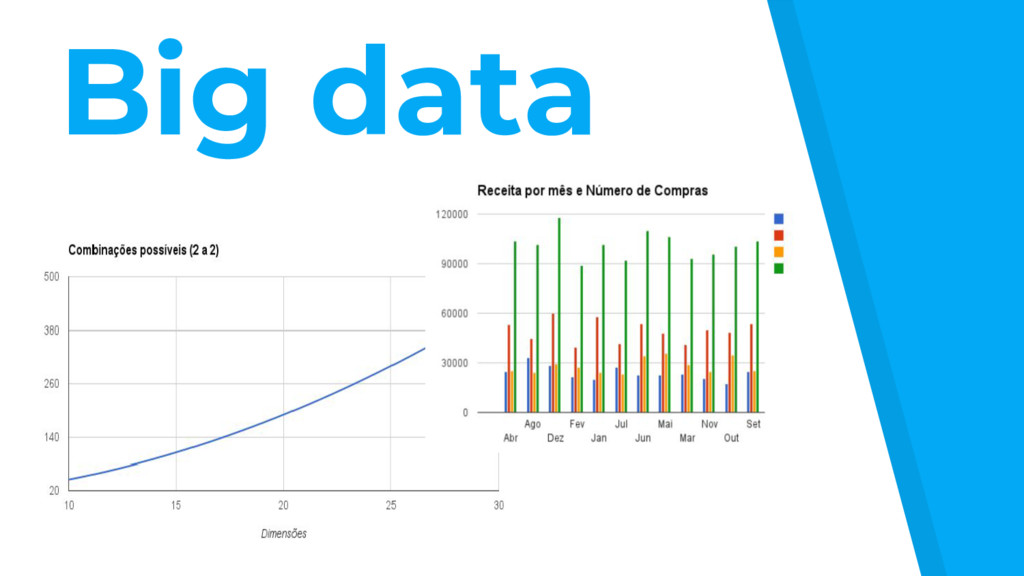
para nomear conjuntos de dados muito grandes ou complexos, que os aplicativos de processamento de dados tradicionais ainda não conseguem lidar. ▸ Este termo muitas vezes se refere ao uso de análise preditiva e de alguns outros métodos avançados para extrair valor de dados, e raramente a um determinado tamanho do conjunto de dados. ▸ Maior precisão nos dados pode levar à tomada de decisões com mais confiança. Além disso, melhores decisões podem significar maior eficiência operacional, redução de risco e redução de custos.
de dimensionalidade é pré-processamento de dados – Redução da dimensionalidade (às vezes por humanos) – Desafiante e altamente dependente da tarefa ▸ Se pensarmos no cérebro humano, não há indícios de que ele resolve esse problema dessa forma
no experimento de Stanford e do Google levou a um computador de 16.000 processadores. ▸ A tecnologia de “Deep Learning” também beneficiou do método de divisão de tarefas de computação entre as muitas máquinas da empresa para que elas pudessem ser feitas muito mais rapidamente. ▸ Esse compartilhamento de processamento acelera muito o “treinamento” de redes neurais de DL, bem como, permite que o Google execute redes maiores e alimentem os dados para elas.
An Overview, Jurgen Schmidhuber ▸ Deep Learning of RepresentaJons - Looking Forward, Yoshua Bengio ▸ Learning Deep Architectures for AI, Yoshua Bengio Alguns exemplos podem ser encontrados em: ▸ Exemplos http://deeplearning.net/demos/ Considerações Finais
pensa que Deep Learning pode mover a Inteligência Artificial (AI) na direção de rivalizar com a inteligência humana. ▸ Alguns críticos da tecnologia dizem que o Deep Learning e a AI em geral ignoram muito da biologia do cérebro humano em favor de uma força-bruta computacional Considerações Finais
a modelagem do cérebro humano, é inevitável que uma técnica não vai resolver todos os desafios. Mas, por agora, a tecnologia de Deep Learning está liderando o caminho da Inteligência Artificial. ▸ Deep Learning é uma metáfora muito poderosa para aprender sobre o mundo.” - Jeff Dean (Google Senior Fellow in the Systems and Infrastructure Group) O que vem a seguir? Considerações Finais
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}