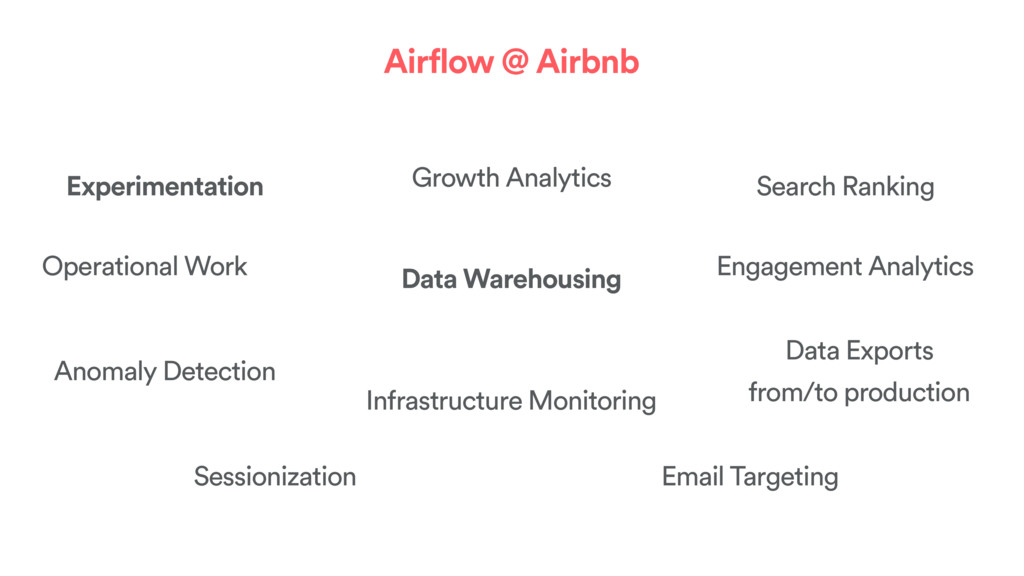
that have intricate dependencies. • Analytics & batch processing are mission critical. They serve decision makers and power machine learning models that can feed into production. • There is a lot of time invested in writing and monitoring jobs and troubleshooting issues. Why does Airflow exist? 7
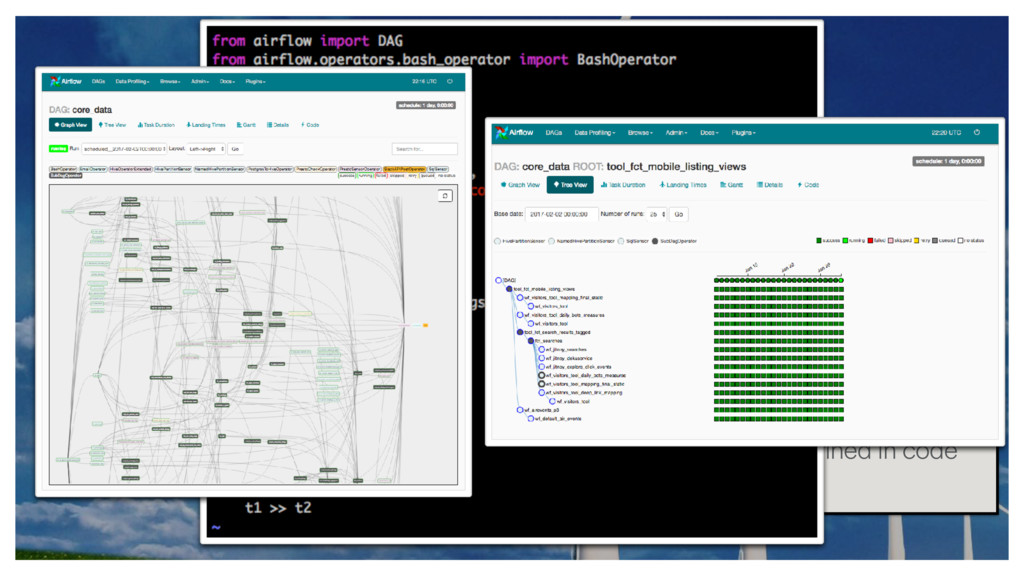
processes • It’s the glue that binds your data ecosystem together • It orchestrates tasks in a complex networks of job dependencies • It’s Python all the way down • It’s popular and has a thriving open source community • It’s expressive and dynamic, workflows are defined in code What is Airflow? 8
• Operators can do pretty much anything that can be run on the Airflow machine. • We tend to classify operators in 3 categories : Sensors, Operators, Transfers.
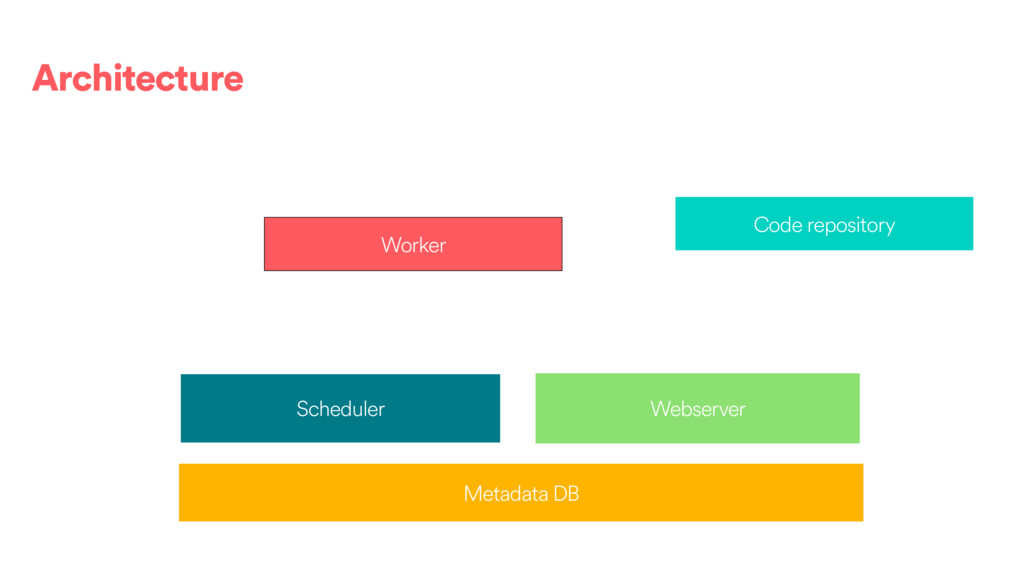
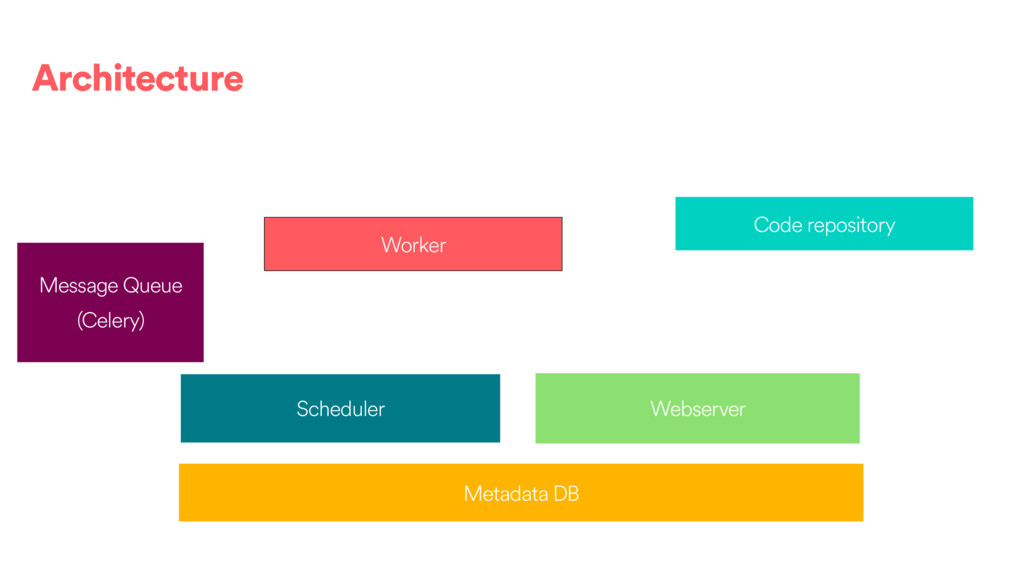
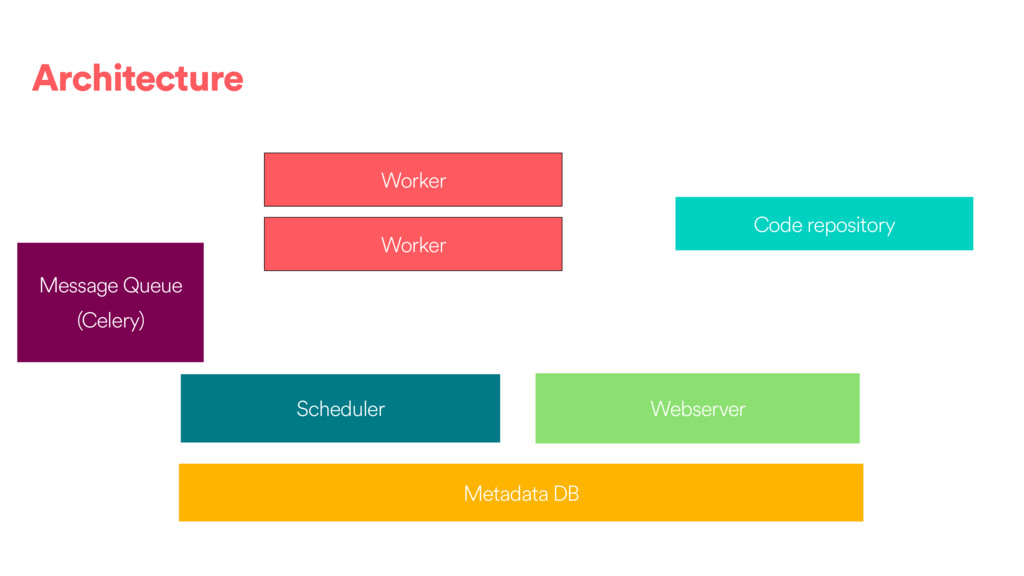
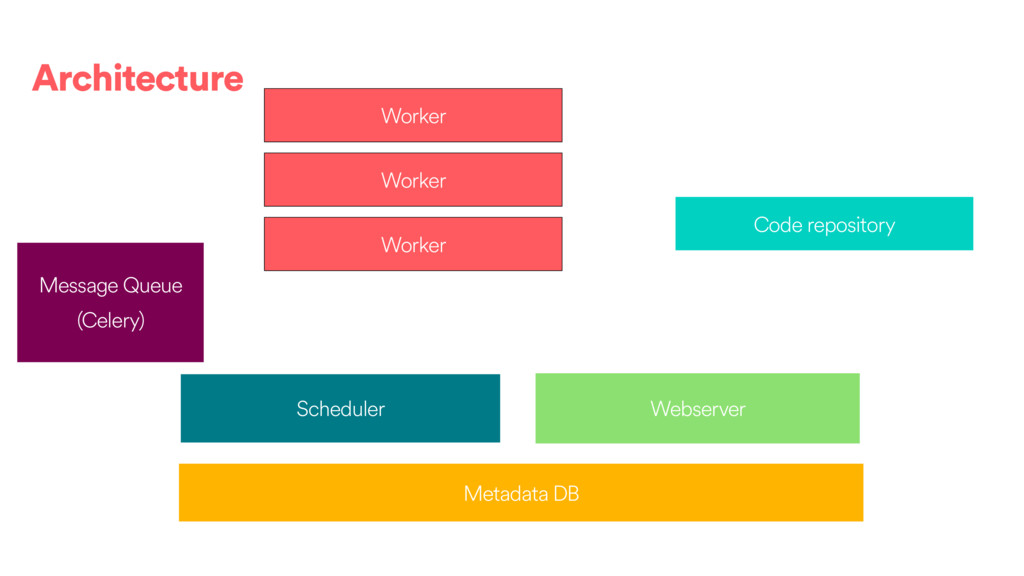
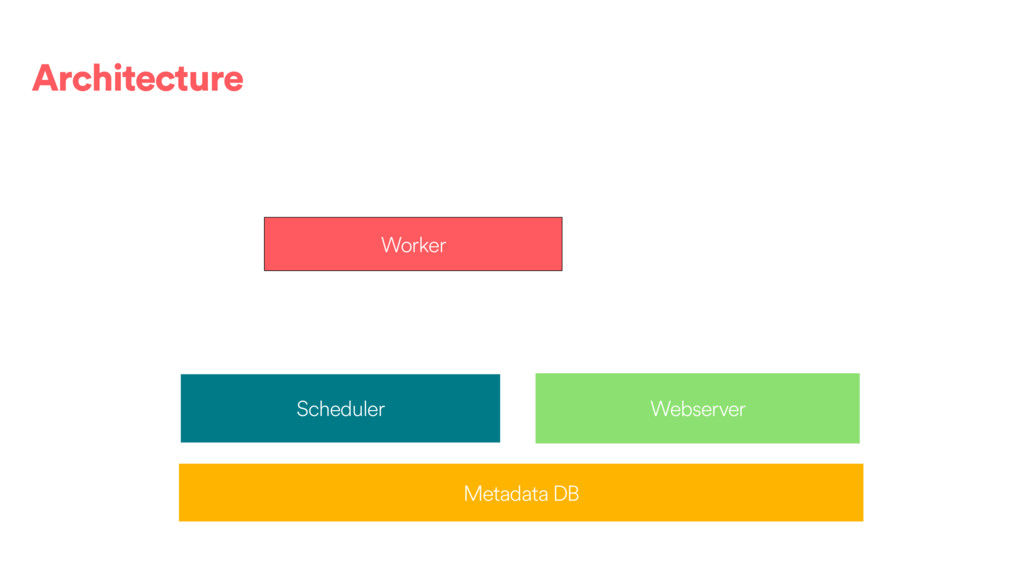
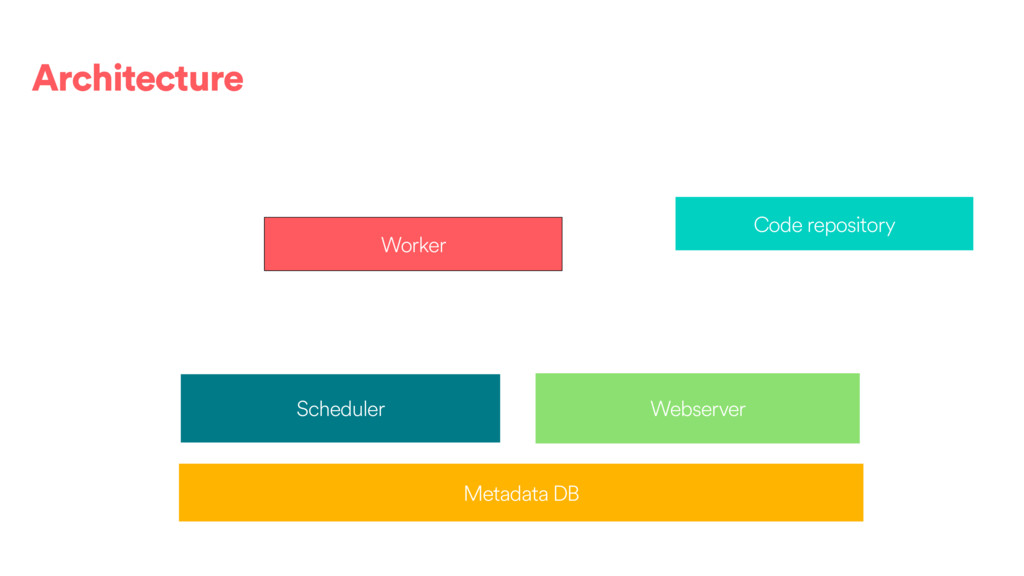
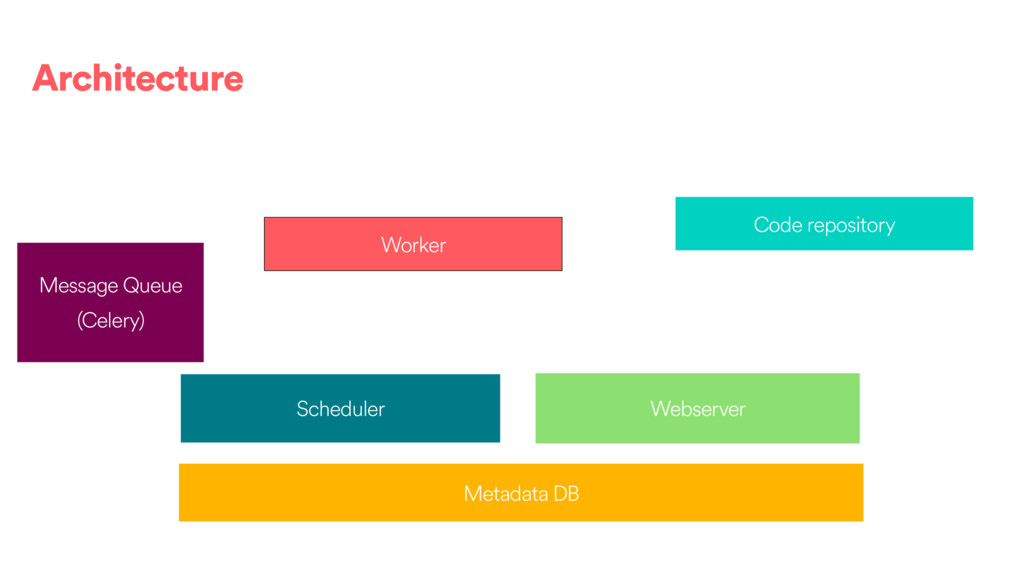
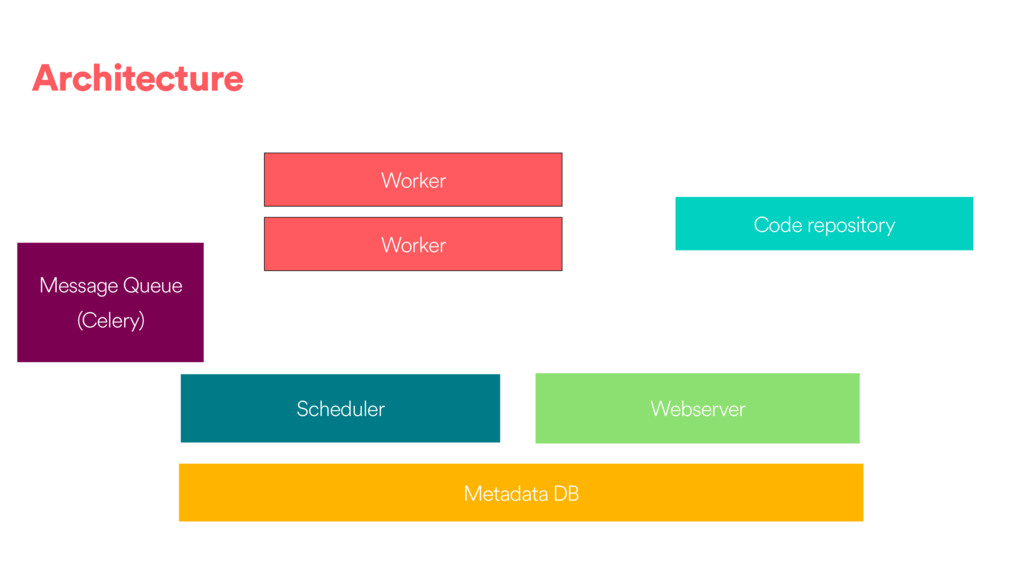
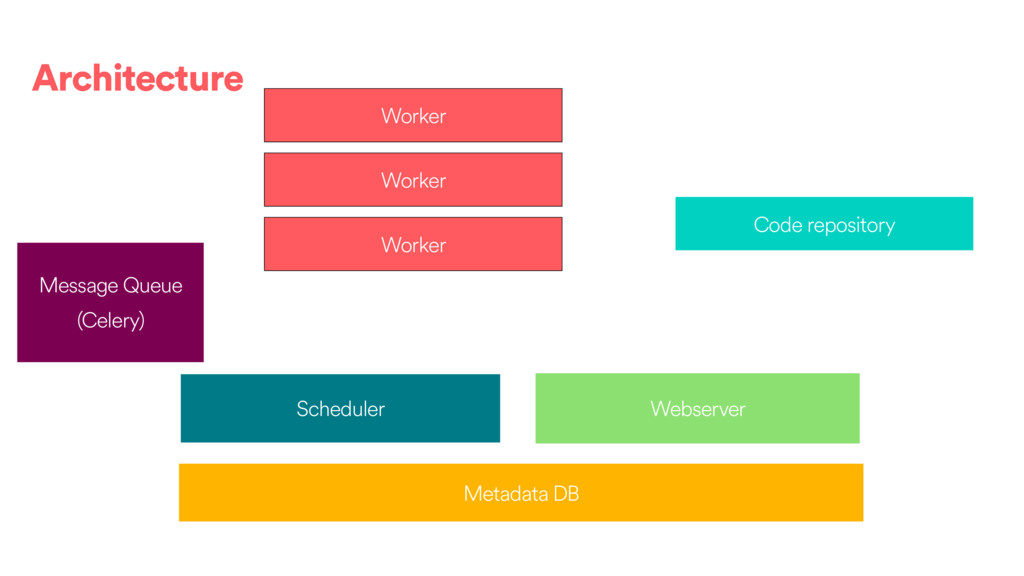
DAGs and about ~80k tasks as day. • We have DAGs running at daily, hourly and 10 minute granularities. We also have ad hoc DAGs. • About 100 people @ Airbnb have authored or contributed to a DAG directly and 500 have contributed or modified a configuration to one of our frameworks. • We use the Celery executor with Redis as a backend.
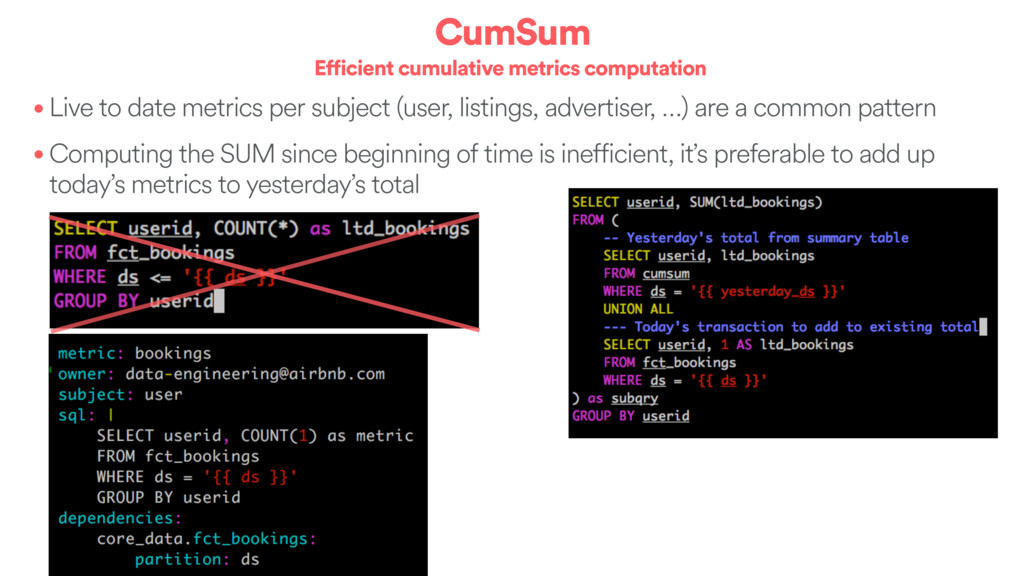
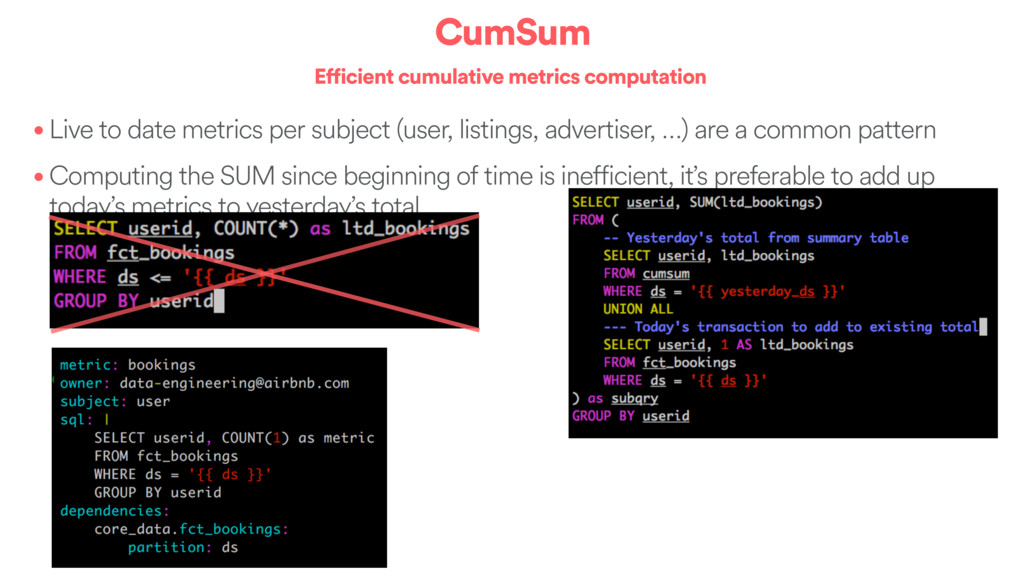
per subject (user, listings, advertiser, …) are a common pattern • Computing the SUM since beginning of time is inefficient, it’s preferable to add up today’s metrics to yesterday’s total
per subject (user, listings, advertiser, …) are a common pattern • Computing the SUM since beginning of time is inefficient, it’s preferable to add up today’s metrics to yesterday’s total Outputs • An efficient pipeline • Easy / efficient backfilling capabilities • A centralized table, partitioned by metric and date, documented by code • Allows for efficient time range deltas by scanning 2 partitions
course materials is here: • https://github.com/artwr/airflow-workshop-dataengconf-sf-2017 • Some of the materials have been ported as a Sphinx documentation • https://artwr.github.io/airflow-workshop-dataengconf-sf-2017/
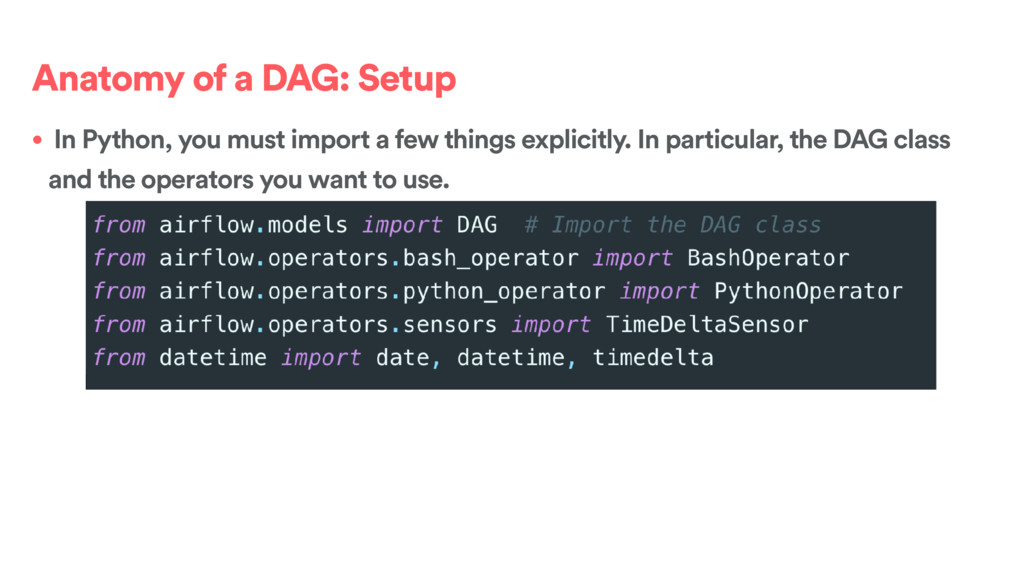
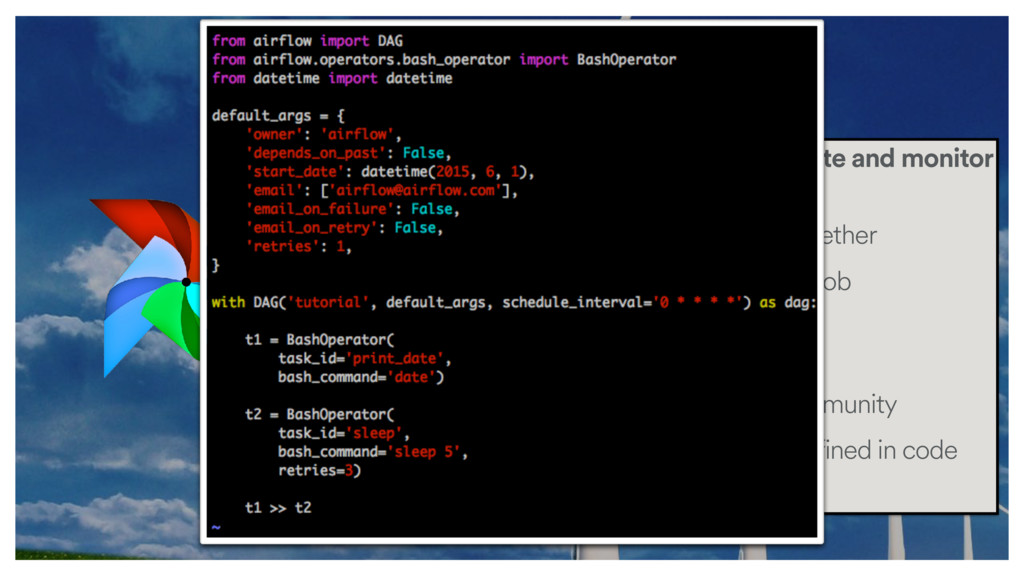
some parameters that you can use for all tasks, like the owner, the start_date, the number of retries. Most of these arguments can be overwritten at the task level.
operators. Sensors usually require a time or a particular resource to check. Operators will require either a simple command or a path to a script (In the BashOperator below, bash_command could be “path/to/script.sh”).
to define how operators relate to each other in the DAG. You can choose store the task objects and use the set_upstream or set_downstream. A common pattern for us is to store the dependencies as a dictionary, iterate over the items and use set_dependency.
different ways to distribute tasks (See : https://airflow.incubator.apache.org/configuration.html#): • SequentialExecutor • LocalExecutor • CeleryExecutor • MesosExecutor (community contributed) •The SequentialExecutor will only execute one task a a time in process. •The LocalExecutor uses local processes. The number of processes can be scaled with the machine. •Celery and Mesos are a way to handle multiple worker machines to scale out.
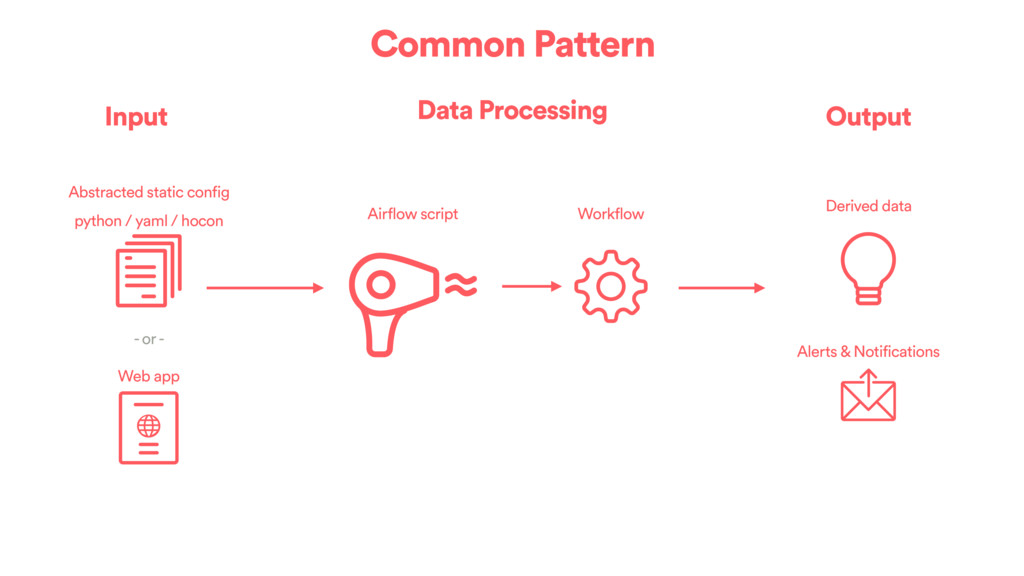
•A common pattern that we use are DAG factories to create DAGs based on configurations. •The configuration can live in static config files or a Database. •One thing to remember is that Airflow is geared towards slowly changing DAGs.
•Multiple states to handle helpful things like automated retries, skipping tasks, detecting scheduling locks. (https://github.com/apache/incubator- airflow/blob/master/airflow/utils/state.py#L26-L57) •We have addressed a decent amount of those issues but are still discovering edge cases.
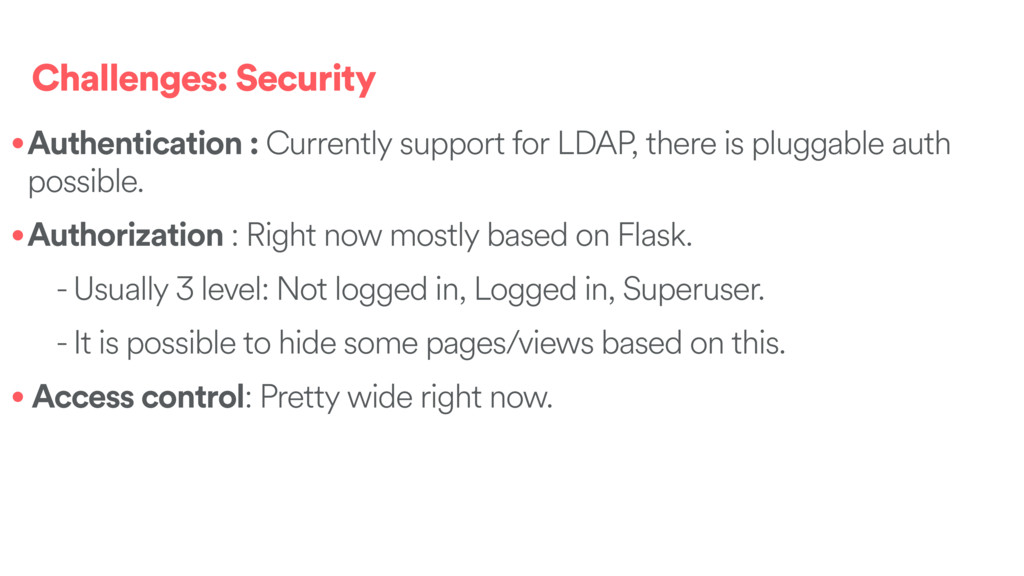
pluggable auth possible. •Authorization : Right now mostly based on Flask. - Usually 3 level: Not logged in, Logged in, Superuser. - It is possible to hide some pages/views based on this. • Access control: Pretty wide right now.
of concept with running the LocalExecutor. •In this case you need to have a production ready metadata db like MySQL or Postgres. •The scheduler is still the weakest link. Enabling service monitoring using something like runit, monit etc…
Airflow increases, so does the load on the Airflow database. It is not uncommon for the Airflow database to require a decent amount of CPU if you execute a large number of concurrent tasks. (We are working on reducing the db load) •SQLite is used for tutorials but cannot handle concurrent connections. We highly recommend switching to MySQL/MariaDB or Postgres. •Some people have tried other databases, but we cannot currently test against them, so it might break in the future.
several methods to get them to the worker machines : - Pulling from a SCM repository with cron. - Using a deploy system to unzip an archive of the DAGs. •The main things to remember is that Python processes will keep the version they have in memory unless specifically refreshed. This can be a problem for a long running web server, where you can see a lag between the web server and what is deployed. A refresh can be triggered via the UI or API.
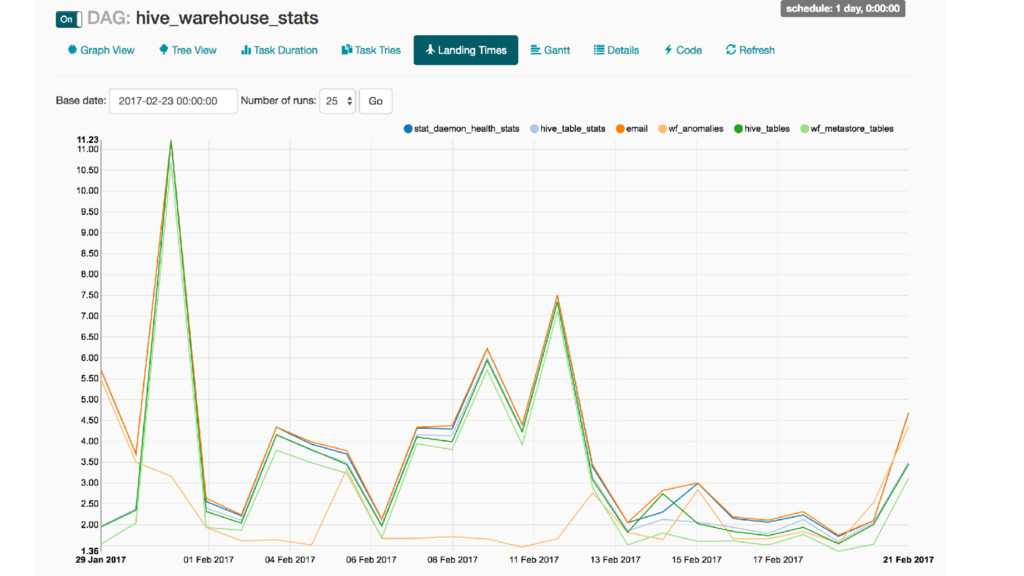
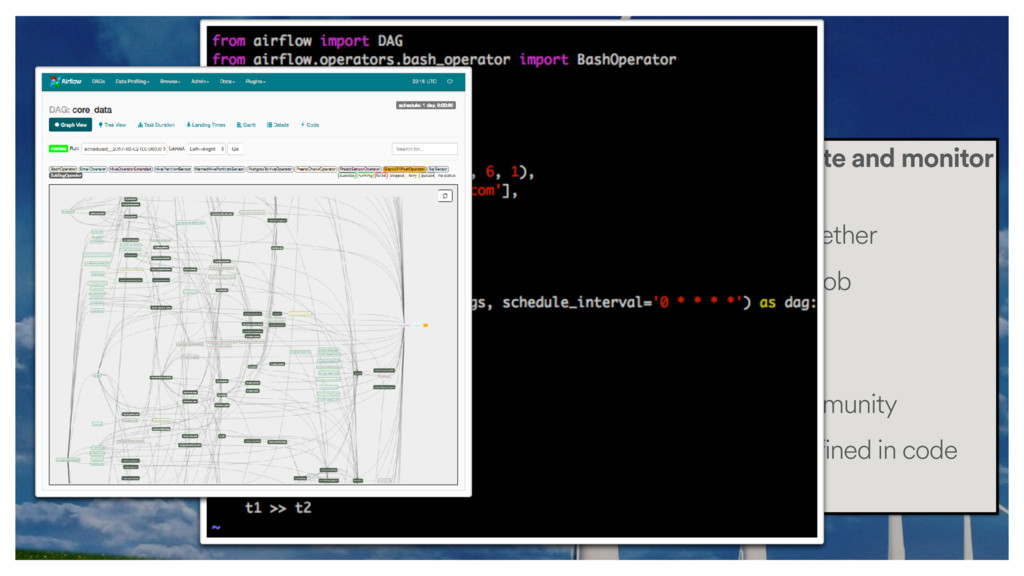
and EmailOperator/SlackOperator for monitoring completion and failure. •Ease of monitoring will help you keep track of your jobs as their number grows. •Checkout the SLA feature to know when your jobs are not completing on time. •If you have more custom needs, airflow supports arbitrary callbacks in Python on success, failure and retry.
tasks idempotent (drop partition/insert overwrite/delete output files before writing them). Airflow will then be able to handle retrying for you in case of failure. •Common patterns are : - Sensor -> Transfer (Extract) -> Transform -> Store results (Load) - Stage transformed data -> run data quality checks -> move to final location.
pools for resource management. Pools are a way to limit the concurrency of expensive tasks across DAGs (For instance running Spark jobs, or accessing a RDBMS). They can be setup via the UI. •If you need specialized workers, the CeleryExecutor allows you to setup different queues and workers consuming different types of tasks. The LocalExecutor is does not have this concept, but a similar result can be obtained by sharding by DAGs on separate boxes. •If you use the cgroup task runner, you have the opportunity to limit resource usage (CPU, memory) on a per task basis.
or worse: drag and drop tools • Code is more expressive, powerful & compact • Reusable components (functions, classes, object factories) come naturally in code • An API has a clear specification with defaults, input validation and useful methods • Nothing gets lost into translation: Python is the language of Airflow. • The API can be derived/extended as part of the workflow code. Build your own Operators, Hooks etc… • In its minimal form, it’s as simple as static configuration
for long running jobs on top of Mesos. • Defining data dependencies was near impossible. Debugging why data was not landing on time was really difficult. • Max Beauchemin joined Airbnb and was interested in open sourcing an entirely rewritten version of Data Swarm, the job authoring platform at Facebook. • Introduced Jan 2015 for our main warehouse pipeline. • Open sourced in early 2015, donated to the Apache Foundation for Incubation in march 2016. Quick history of Airflow @ Airbnb 52
be released soon. • The focus has been on stability and performance enhancements. • We hope to graduate to Top Level Project this year. • We are looking for contributors. Check out the project and come hack with us. Apache Airflow 53
has a lot of user to user help. • If you have more advanced questions, the dev mailing list at http://mail- archives.apache.org/mod_mbox/incubator-airflow-dev/ has the core developers on it. • The documentation is available at https://airflow.incubator.apache.org/ • The project also has a wiki : https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Home 55
https://www.meetup.com/Bay-Area-Apache-Airflow-Incubating-Meetup/ • Matt Davis at PyBay 2016: https://speakerdeck.com/pybay2016/matt-davis-a-practical-introduction-to-airflow • Laura Lorenz at PyData DC 2016 How I learned to time travel, or, data pipelining and scheduling with Airflow : https://www.youtube.com/watch?v=60FUHEkcPyY 56
has written some thoughts about ETL with Airflow https://gtoonstra.github.io/etl-with-airflow/ • Laura Lorenz at PyData DC 2016 How I learned to time travel, or, data pipelining and scheduling with Airflow : https://www.youtube.com/watch?v=60FUHEkcPyY 57
batch processes • It’s the glue that binds your data ecosystem together • It orchestrates tasks in a complex networks of job dependencies • It’s Python all the way down • It’s popular and has a thriving open source community • It’s expressive and dynamic, workflows are defined in code
batch processes • It’s the glue that binds your data ecosystem together • It orchestrates tasks in a complex networks of job dependencies • It’s Python all the way down • It’s popular and has a thriving open source community • It’s expressive and dynamic, workflows are defined in code
batch processes • It’s the glue that binds your data ecosystem together • It orchestrates tasks in a complex networks of job dependencies • It’s Python all the way down • It’s popular and has a thriving open source community • It’s expressive and dynamic, workflows are defined in code
batch processes • It’s the glue that binds your data ecosystem together • It orchestrates tasks in a complex networks of job dependencies • It’s Python all the way down • It’s popular and has a thriving open source community • It’s expressive and dynamic, workflows are defined in code
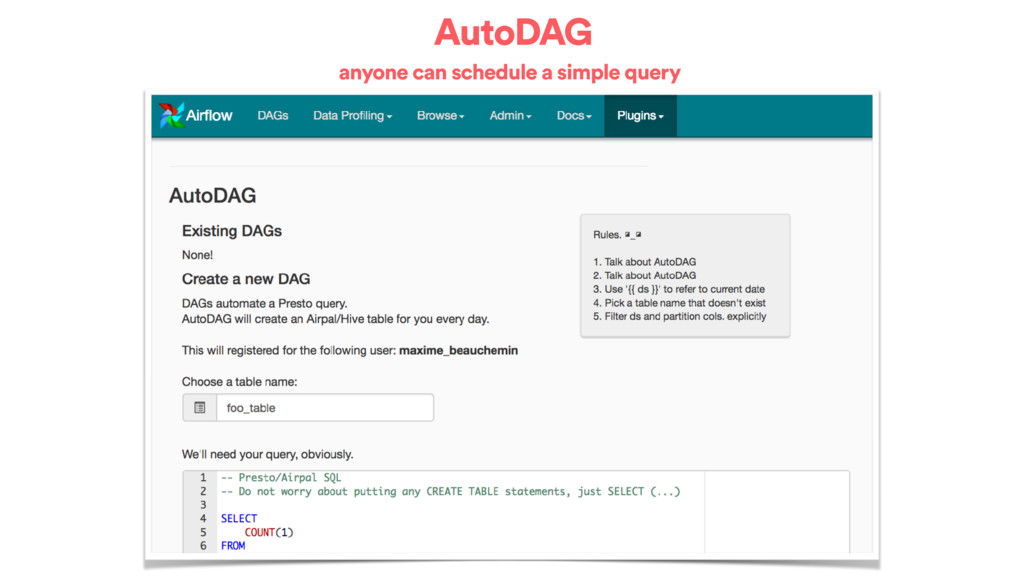
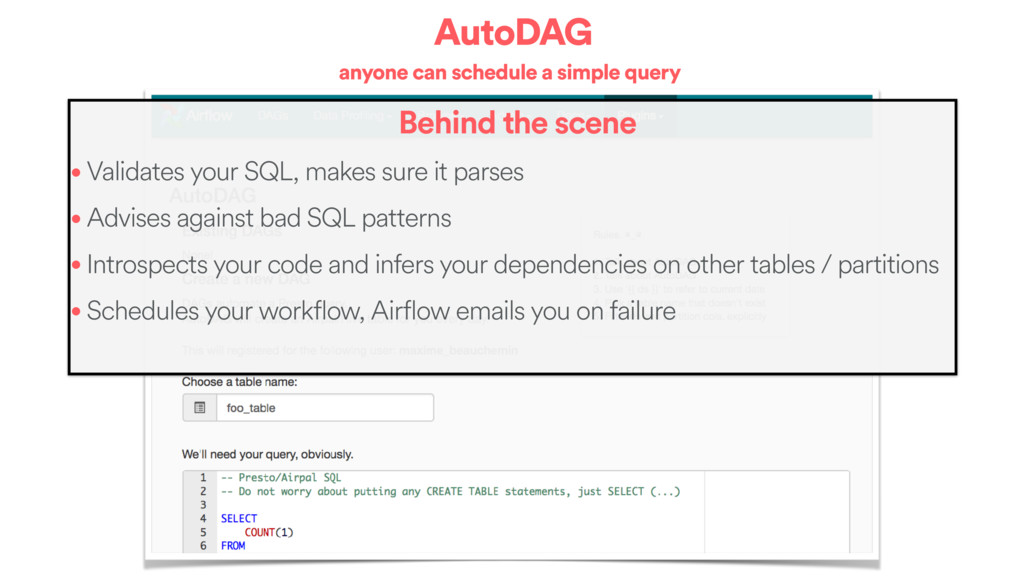
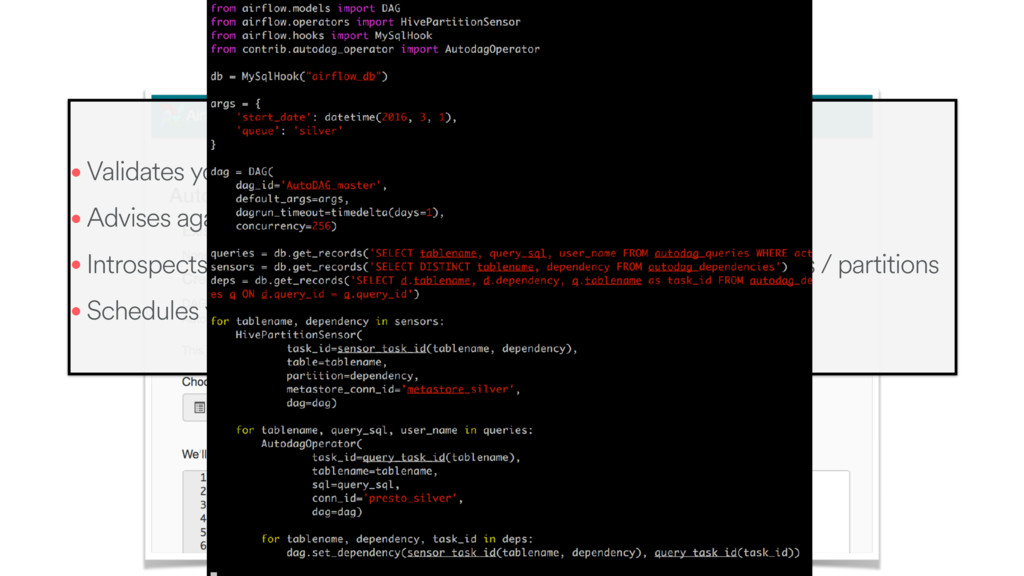
• Validates your SQL, makes sure it parses • Advises against bad SQL patterns • Introspects your code and infers your dependencies on other tables / partitions • Schedules your workflow, Airflow emails you on failure
• Validates your SQL, makes sure it parses • Advises against bad SQL patterns • Introspects your code and infers your dependencies on other tables / partitions • Schedules your workflow, Airflow emails you on failure
resurrected, stale and active users • COUNT DISTINCT metrics are complex to compute efficiently • Web companies are obsessed with these metrics! • Typically needs to be computed for many sub-products and many core dimensions
resurrected, stale and active users • COUNT DISTINCT metrics are complex to compute efficiently • Web companies are obsessed with these metrics! • Typically needs to be computed for many sub-products and many core dimensions Behind the scene • Translates into a complex workflow is issued for each entry • “Cubes” the data by running multiple groupings • Joins to the user dimension to gather specified demographics • “Backfills” the data since the activation date • Leaves a useful computational trail for deeper analysis • Runs optimized logic • Cuts the long tail of high cardinality dimensions as specified • Delivers summarized data to use in reports and dashboards
per subject (user, listings, advertiser, …) are a common pattern • Computing the SUM since beginning of time is inefficient, it’s preferable to add up today’s metrics to yesterday’s total
per subject (user, listings, advertiser, …) are a common pattern • Computing the SUM since beginning of time is inefficient, it’s preferable to add up today’s metrics to yesterday’s total Outputs • An efficient pipeline • Easy / efficient backfilling capabilities • A centralized table, partitioned by metric and date, documented by code • Allows for efficient time range deltas by scanning 2 partitions
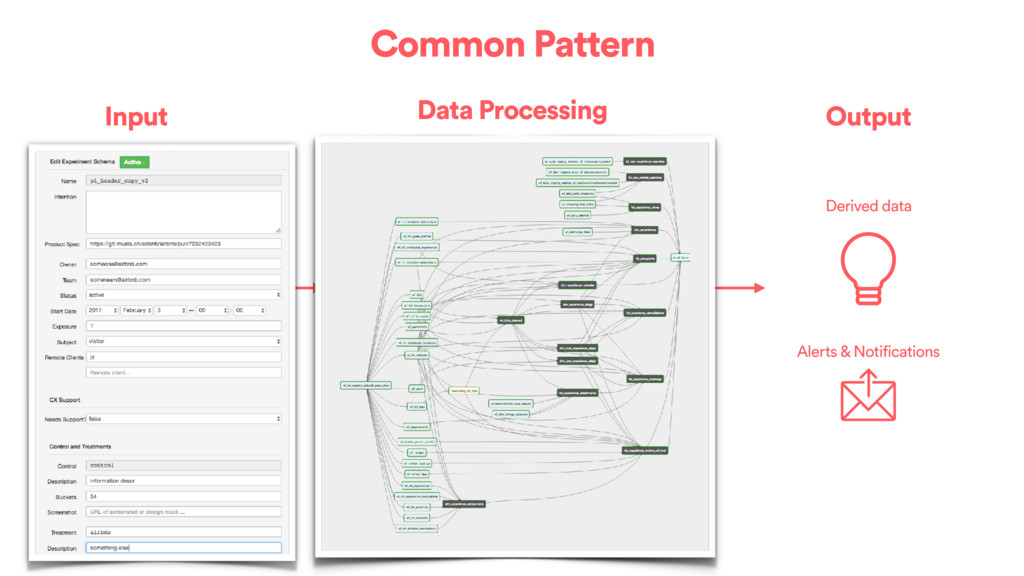
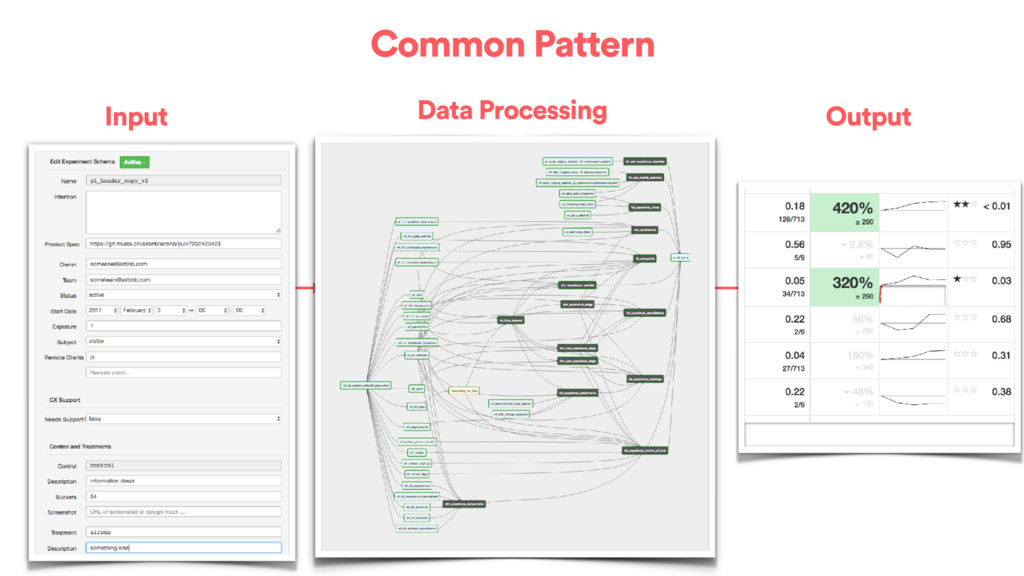
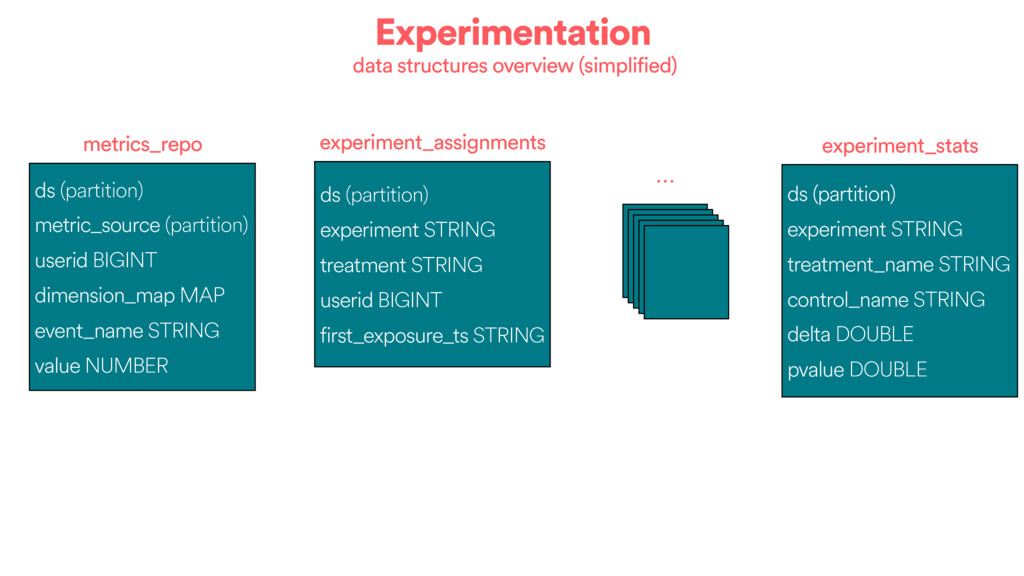
backing an individual experiment Wait for source partitions Load into metrics repository Compute atomic data for the experiment Aggregate metric events and compute stats Conceptually Export summary to MySQL
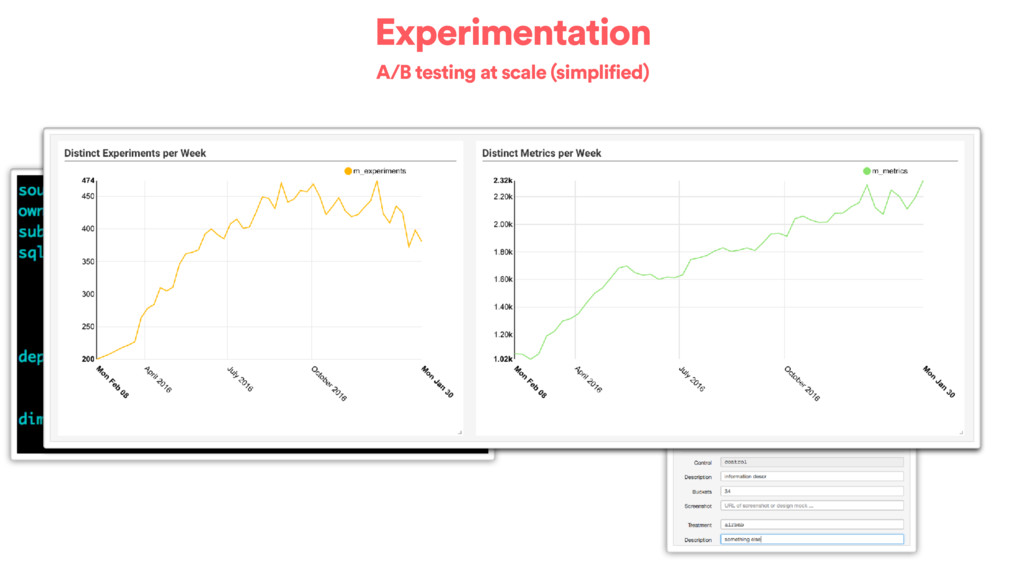
or weeks to go through our main flows • cookie -> userid mapping • event level attributes, dimensional breakdowns • different types of subjects (host, guests, listing, cookie, …) • different types of experimentation (web, mobile, emails, tickets…) • “themes” are defined as sets of metrics • Statistics beyond pvalue and confidence intervals: preventing bias, global impact, time-boxing
Monitor the Hive metastore’s partition table for last updated time stamp • for each recently modified partition, generate a single scan query that computes loads of metrics * for numeric value, compute MIN, MAX, AVG, SUM, NULL_COUNT, COUNT DISTINCT, … * for strings, count the number of characters, COUNT_DISTINCT, NULL_COUNT, … * based on naming conventions, add more specific rules * whitelist / blacklist namespaces, regexes, … • Load statistics into MySQL • Used for capacity planning, data quality monitoring, debugging, anomaly detection, alerting, … cluster STRING database STRING table BIGINT partition STRING stat_expr STRING value NUMBER partition_stats
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}